Long-horizon Agent
简介(未完成)
2026年,模型的推理能力、tool calling 能力、长上下文处理能力都已经达到了一个临界点。Long-horizon Agent 不再是”酷炫的 demo”,而是真正能够产出价值的工具。
- 不变的:在正确的时机,以正确的格式,向 LLM 提供正确的信息。
- 变化的:构建 Long-horizon Agent 涉及很多微妙的工程细节(compaction 策略、subagent 通信、error handling 等)
- 上下文管理
- Compaction 策略:当上下文窗口不够时如何压缩
- Memory 管理:如何在跨会话中保持关键信息。像“经验库”,增强稳定性、抗遗忘与长期一致性。
- Subagent 通信:如何让主 Agent 和子 Agent 高效协作
- Tool 选择:什么时候使用什么工具。pi的agent loop 只提供了4个工具:read/write/edit/bash。有bash 就可以安装世界上所有软件,有read/write/edit就有了读写、做事儿、记忆的能力。我们可以去掉一些工具,更多依赖 Skill。PS:文件系统权限
如果目标只是让模型在一轮对话里回答得更像样,Prompt Engineering 依然重要;但如果目标变成“让 Agent 连续几十分钟完成一个真实任务”,只优化提示词通常是不够的。很多失败并不是模型不会写,而是它不知道该看什么、能用什么、错了以后怎样自我校正。它缺少了一些运行的环境和良好的规范。本质:怎么让AI可靠地完成超出单次上下文窗口的复杂工程任务。重点从提示词工程转向运行时工程。
场景
完成任何一个任务,都需要确定目标和路径两个因素。按照workflow模式(也是传统软件的思路),我们需要在编程时指定具体的路径,也可以包含一个动态的算法来动态计算出一条路径(路径可能不只一条,只需要指出一条路径就行)。而按照自主agent模式,我们就没有必要提前指定一条路径。我们只需要指定任务的目标然后LLM会自动找到路径。这里的关键在于:对于workflow模式来说,如果执行路径中出现的障碍是它非预期的,它就无法解决。但是,agent模式却可以处理非预期的障碍或情况。
| 目标明确 | 目标不明确 | |
|---|---|---|
| 执行路径明确 | 确定性编码/workflow模式 | agent模式 |
| 执行路径不明确 | agent模式 | agent模式 |
Long Horizon Task(LHT)
- Coding。编程在大多数用例中现在已经解决了。
- AI SRE,能够进行深度日志分析和故障排查
- Deepresearch
- assistant agnet, openclaw
|来源|性质|经典类比|可消除?| |—|—|—|—| | LLM 输出概率性|认知不确定性(epistemic) |传感器噪声| 部分 (约束/微调)| | Tool 调用可能失败|偶然不确定性 (aleatoric)|网络丢包|部分 (重试/冗余)| |环境状态变化|外部扰动| 硬件故障|不可消除| | Context Window 有限|观测约束|传感器视野有限|不可消除 (物理极限)| |多 Agent 并发|竞争条件|分布式并发|可管理 (协议)| |模型升级行为漂移|平台演变| ABI 变更|不可消除 (持续演进)| 好消息是:面对不确定性,计算机领域几十年来积累了丰富的对抗经验,比如经典分布式系统的 8 个核心问题(状态一致性-多节点看到不同版本/容错-节点崩溃/分区容忍-网络断裂时继续工作/幂等性-重试产生副作用/因果排序-事件时序混乱/状态恢复- 从故障点接续/可观测性-跨节点因果追踪/协调-多参与者达成一致)
特点
- 运行时间更长,中间状态很多,需要记忆与上下文管理。
- 上下文窗口是有限的。Agent工作时间一长,早期的信息就会被遗忘,这叫“上下文失忆症”;或者,在长长的对话中,信息变得混乱,模型开始“跑偏”,这叫“上下文腐化”。甚至,当模型意识到上下文快要耗尽时,会产生“上下文焦虑”,急于草草收尾。
- 上下文重置 + 结构化交接 被明确当成长期任务的一等能力。不是只靠压缩上下文,而是允许直接换一个新 agent 接班,靠 handoff 保连续性。这比“死磕一个超长上下文 session”更工程化。
- 自主决策能力,需要长期规划,而不是局部贪心。
- 它要么试图一步到位,把所有事情都干了(结果往往是半途而废);要么就是做到一半,比如建了个功能,然后就停下了,留下一堆烂摊子。
- 判断力(Judgment)。模型极不擅长客观地评判自己的输出。它天生有一种“谄媚”倾向,会告诉你它认为你想听的话。如果一个系统无法准确评估自己的工作成果,那么任何长期的、多步骤的任务都注定会因为错误的累积而崩溃。
- 中途接受外部的信息、纠正指令等
- 假设执行一个任务分5步,每一步执行成功的概率是90%,那么整体执行成功的概率只有59%。
这使得模型的上下文规模呈指数级膨胀。文件内容、构建日志、多轮工具输出、任务中间状态、先前讨论……这些都逐步挤进了 Prompt,使得原本相对可控的短对话场景,变成了复杂的多源异构大上下文输入。结果非常直接:
- 模型需要处理更长的 Token → 推理时延增加,成本上升;
- 有效信息被噪声淹没或被截断 → 输出质量下降;
- Agent 在长流程中“忘记”关键上下文 → 任务失败率上升;
模型缺点
- 一口吃成胖子。你给AI一句”做个Web应用”,它会尝试一次性把所有功能都怼出来。写到一半context用完了,下一轮的AI继续接手——但它对前任的工作一无所知。代码烂尾在那,而AI头也不回。
- 过早宣布胜利。 搞了几个功能之后,AI审视了一下当前状态,得出结论:”看起来差不多了”,然后收工。打开一看,核心逻辑却根本就是空壳。
之前的解法比较朴素:一个初始化Agent负责拆任务,一个编码Agent每次只做一个功能,做完写进度文件、提交git。相当于给AI发了一本固定化手册,但天花板很快到了。 现在的解法:
- Generator之外给一个Evaluator,批评别人比自我批评容易,在AI身上也一样。
- Agent之间怎么沟通?写文件一个Agent把内容写到一个文件里,另一个Agent打开那个文件来读。
- AGI-pilled 到刚刚好的程度。那种相信”模型马上就会无所不能”的 PM——他们设计的产品本质上就是一个文本框,假设模型自己会调工具、自己会问澄清问题、自己会兜底。这种产品在今天的模型能力下根本跑不起来。反过来把模型当成普通 SaaS 来设计,给所有边界情况都加复杂逻辑,结果半年后模型能力一升级,整套设计就变成了累赘。
- Claude Code 最早的时候,模型不太能稳定完成一个大重构——它会列出”要改 20 个调用点”,然后改了 5 个就停下来。团队为此专门做了一个 to-do list 工具,强行让模型把 20 个点全列出来,再一个一个划掉。这个 to-do list 在当时是救命的功能。Opus 4 之后,模型自己就能稳定地把 20 个点全部完成了。再往后,整个 to-do list 变成了一个可有可无的可视化辅助——不是模型需要它,是用户喜欢看到进度。每次模型升级,团队会一行一行重读 system prompt,把不再需要的提醒删掉。
- Sonnet 4.5在上下文窗口接近极限时,会表现出一种类似”焦虑”的行为模式——开始草草收尾、匆忙总结、过早宣布完成。Anthropic试过上下文压缩,比如把前面的对话总结缩短,让同一个Agent继续干,但发现不够。压缩之后Agent虽然context宽裕了,但这种”快到极限了”的行为惯性并没有消失。最后的解法相当暴力——直接重置。 起一个全新的Agent,什么都不记得,交接靠的是结构化文件——上一个Agent留下进度报告和状态文件。到了Opus 4.6,这个”上下文焦虑”的问题基本没了。于是重置机制被砍掉,换成了SDK内置的自动压缩来处理context增长。一个在4.5上不得不存在的核心机制,在4.6上就成了冗余组件。
- Opus 4.6升级到Opus 4.7,实际上Opus 4.7并不是一个全方位的提升。一种解释是,Opus 4.7的RL阶段更多使用了类似目前Claude Code的使用范式,也就是主Agent调用子Agent的方式来处理任务。以及从实际使用上来说,如果你仍然按照之前单Agent session的long context方式来使用的话,会发现Opus 4.7变懒了一些,在context较长时候表现很明显。所以单单一个小版本的模型升级,就可能导致上层的Harness设计要进行调整适配才能保持原有的效果。那么问题就变成,Harness这个层面,我们攒下的到底是技术资产,还是技术债?知道什么时候该往Harness里加东西,更要知道什么时候该从里面删东西。
- 如何获得一个保质期更长的方案呢?一个常用的思路就是:提升抽象程度,寻找一个更稳定的抽象层面,然后对它以下的内容进行自动适配/生成。那么Harness之上还有什么更抽象的层面呢?一个答案是:生成Harness的方法论,或者说生成Harness的Harness。从Harness变成从高层Harness生成Harness,缺了什么呢?缺的是解决当前问题的最佳实践的经验,这被不少人笼统地称为know-how。这个信息并非不可获得的,如果是一个公开知识比较多的领域,这个know-how很可能已经被模型所知晓,那么就可以期待模型生成Harness时自动关联相关的知识。如果模型不能自主召回,但有公开的信息,也可以依赖于模型进行调研。那么剩下的场景呢?如果模型的智力强大到能够根据当前场景推理出最佳实践,则也可以,这一般被称为第一性原理思维。剩下的部分就只能指望用户进行反馈了,对于用户并非该领域专家的场景,产品效果就是退化了。实际上只要我们比用户已经能使用明白的产品一般交付的效果明显更好就可以了。这个模式曾经出现过。Manus至于ChatGPT,就能对于一般用户交付更好的效果。熟练使用Claude Code的人不用Manus,但大部分人不是。PS: 模型已知道 ==> 模型能找到 ==> 模型能推理 ==> 靠反馈摸索
- 文章作者自己写到了自己走了弯路——他一开始想大刀阔斧地简化框架,一次性砍掉了好几个组件,结果性能直接崩了。后来改成一个一个地拆,每拆一个就跑一遍完整测试,看这个组件到底是真正承重还是历史遗留。其实这个方法论适用任何复杂系统的简化都该这么做:别猜,一个一个拆,让结果说话。每一个被砍掉的组件,本质上都是对”模型做不到X”这个假设的一次推翻。你今天写的所有AI相关的”最佳实践”,本质上都是”当前模型的补丁集”。 新模型一出,有些补丁该删,有些新的需要打。
- 今天你需要评估Agent来兜底,明年模型可能自己就能做好自评了。但明年你可能在让AI做更复杂十倍的任务,又会冒出新的失败模式,需要新的框架组件来应对。
trace ==> 价值
小龙虾用 MEMORY.md 加每日笔记(这周刚新增了 Dreaming 功能),所有记忆都是纯 Markdown,透明可编辑。但写入依赖模型主动判断”值得存”, 经常漏存。Hermes 换了个思路,做了三层记忆:每隔 10 轮对话,Hermes 会在后台悄悄 Fork 出一个安静进程,用同款模型、8 轮迭代上限、静默模式,对你们刚才的对话做一次复盘。这个后台小号做两件事:一是问自己”用户透露了什么偏好?值得记住吗?”,二是问自己”这个任务用了什么好方法?值得固化成技能吗?”有价值的,写进 MEMORY.md(记环境事实,上限 2200 字符)或者 USER.md(记你的偏好和习惯,上限 1375 字符);有价值的方法论,写成技能文件存档。这两个文件每次对话自动注入上下文。第三层是 Session Search——所有历史对话存在 SQLite 里,用全文检索(FTS5)加大模型摘要,几周前聊过的东西也能精准找回来。AI 助理的终极形态不是”更聪明”,而是”不需要你重复说第二遍”。
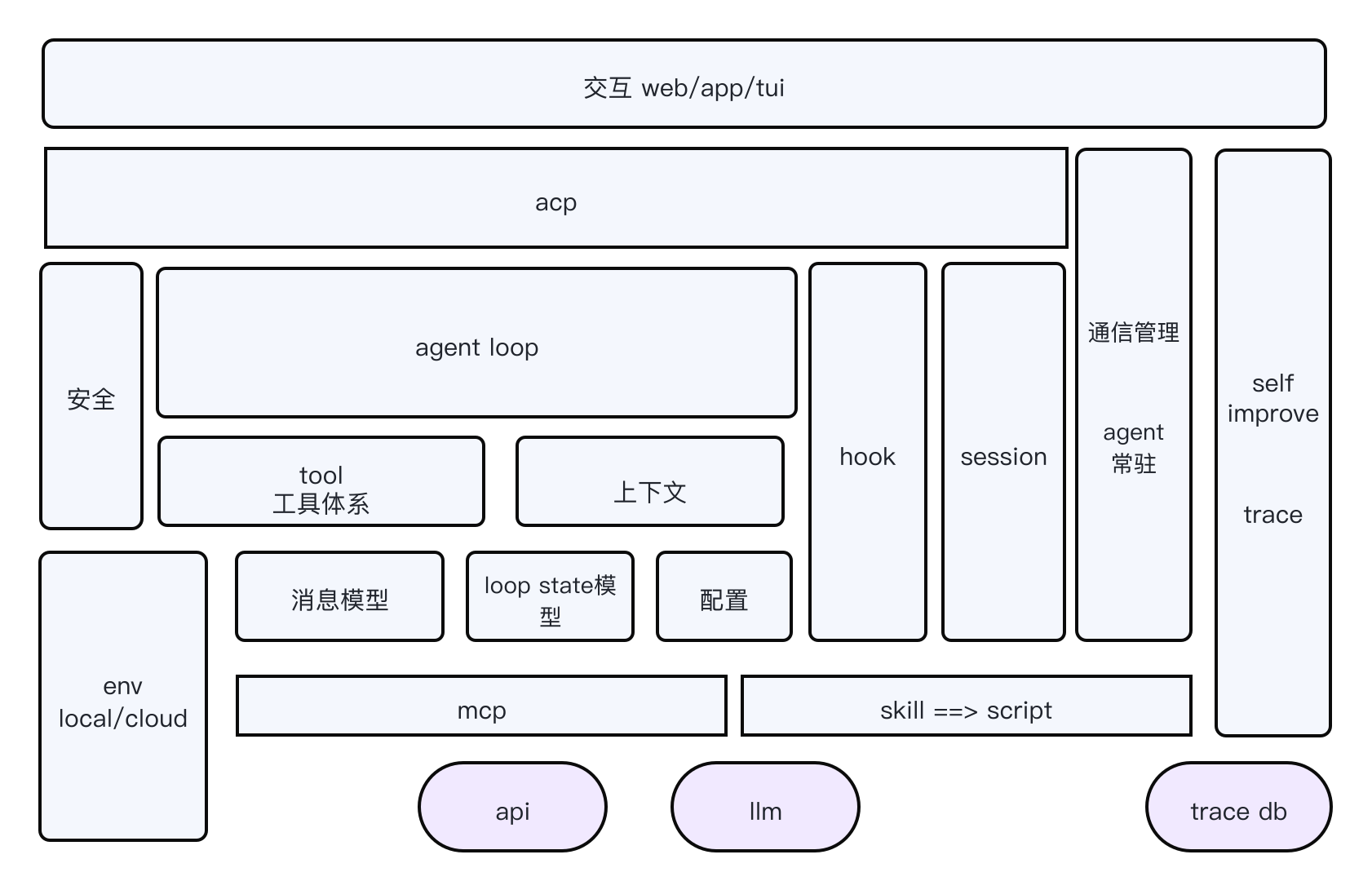
Harness
从2026来说,除了定制场景,llm能力的提升推动了agentic成为主要范式,工作开始转向支持agent loop运行的subagents、skills、memory、compaction,这些都是 context engineering 的不同形式。
Harness是一个相对较新的概念可以理解为“batteries included”的 Agent 运行时环境。与 Framework 相比,Harness 更加”opinionated”——它不仅提供抽象,还内置了最佳实践。一个好的 Harness 套件几乎可以做到开箱即用,同时又可以做到高度定制。过去一年里,围绕 agent coding 的讨论几乎全部集中在同一个问题上:模型到底够不够聪明?上下文窗口够不够长?工具调用够不够灵活?Anthropic Harness Design for Long-Running Apps这篇文章把注意力拽到了一个完全不同的方向——外层系统该怎么设计(llm依然拥有自主规划/Planning和循环迭代/Looping的权利)。也有观点认为Harness不过是最佳工程实践下的common sense,但社区却给它造词。
|prompt|framework|| |—|—|—| |Prompt Engineering|openai chat api|关注一次 LLM 调用的提示词编写| |Context Engineering|agent framework|记忆、状态、领域知识相关| |Harness Engineering ||正确性、效率、稳定性、安全| 确性、效率、稳定性、安全不是和agent编排并列的模块,而是包裹在编排之外、让编排结果可信的基础设施。Harness 这个词来自马具:缰绳、轭具、挽带构成的完整配件组,把马的力量引导到车辆上。马凭自己的判断决定往哪里跑、跑多快;马具不参与这个决策,它在外部管控马的力量如何被传导、约束越界行为、防止脱轨。而Agent harness 对应的就是:存在于 agent 的推理逻辑外部,不干预 agent 内部如何决策,但确保agent的行动在受控的环境中被执行、被追踪、被约束在安全边界内。PS:所以有MAS harness,也有SAS harness. agent= model +harness。
单纯把 prompt 写得更好已经到头了。prompt 和 CLAUDE.md 里的规则最终都只是 context 里的 token。每一个 token 都要跟其他 token 竞争注意力。靠写更好的 prompt 解决这个问题,等于用更多的 token 跟 token 打架。正确的方向是:把可以不放进 prompt 的东西拉出去,放在模型看不见的地方做确定性约束。PS:比较典型的Harness能力体现在Hook系统
Harness Engineering 这个概念最早由 HashiCorp 联创 Mitchell Hashimoto 在 2026 年 2 月 5 号提出,Hashimoto 对 Harness Engineering 的定义只有一句话:每当你发现 Agent 犯了一个错误,你就花时间设计一个解决方案,使 Agent 永远不再犯同样的错误。也就是给Agent加反馈闭环,再进一步在 Agent 应用里,定义「什么叫做错」,比实现「如何纠错」,难一个数量级。Agent 应用里最常见的失败,不仅是「没有反馈循环」,更是根本没有人认真定义误差函数。工程师说「让它写好代码」,但什么叫「好」?什么叫「设计合理」?这些判断存在于工程师的头脑里,从未被写下来。1948 年 Norbert Wiener 创立控制论(Cybernetics)时的核心洞察就一句话:复杂系统的稳定性不来自精准的预测,而来自持续的反馈与纠偏。瓦特的离心调速器不需要「知道」蒸汽机下一秒的转速,它只需要在转速偏离时收紧阀门 —— 瓦特的离心调速器就是最早的闭环机制。但 LLM Agent 和蒸汽机有一个关键差别:你没有办法对 LLM 做系统辨识(System Identification),因此经典的「对被控对象建模 → 设计控制器」这条路走不通。Harness Engineering 的深刻之处,是它在放弃「对 Agent 建模」的前提下,依然找到了一条让系统收敛的路径 —— 不是通过理解 Agent 会怎么做,而是通过设计环境使得 Agent 只能做对的事。人的价值到底落在哪?
Coding Agent 里有一个数学意义上的非对称性:生成一个正确答案,远比验证一个答案是否正确要难。这个非对称性给工程师指明了方向:你不需要比 Agent 更快地写代码,你需要比 Agent 更擅长定义「什么是正确」。在 Harness Engineering 的范式下,工程师的核心工作从「写代码」变成了三件事:
- 显性化判断标准,把脑子里关于「好」和「坏」的判断写成机器可读的规则和评分标准;
- 设计可信的误差信号,确保 Evaluator 不是自我赞美的复读机,而是可校准的测量装置;
- 定义系统边界,通过架构约束、Linter 规则、分层依赖,让坏的行为在结构上不可达。 仔细看这三件事,会发现一个有意思的地方:这不只是工程师的工作,也是产品经理的工作。定义「好的输出是什么」是产品设计,设计验证机制是质量标准,划定系统边界是架构决策也是产品边界。AI 之前这两个角色之所以分开,是因为「执行」本身足够复杂,需要专人来做。当执行被 Agent 承接后,剩下的工作天然地把产品思维和工程思维压到了同一个人身上。有产品思维的研发和有技术思维的产品,正在变成同一种角色 —— 系统的架构者,而非执行者。
工程师和产品的价值,不再是执行能力本身,而是定义「什么叫做做对了」的判断力。这件事 AI 替代不了,也不该替代 —— 因为它本质上是人类对自己想要什么的回答。
为什么要 Harness Engineering:它不是补丁,是分工两个思路
- 模型现在还不够好,所以需要在它外面套一层东西补它的缺陷。等模型变得足够强,这一层东西就会消失,大家又可以回到”直接把任务丢给模型”的简单世界。按这个理解,harness 就是一种临时补丁,是从 AI 辅助编码 到 AI 独立工作 这条路上的过渡形态。
- harness 不在补模型的短处,它在承担结构上模型不应该承担的那部分工作。这个分工不是临时的,是结构性的。就像 CPU 再强也需要操作系统,再快的硬盘也需要文件系统,不是因为 CPU 和硬盘不够好,是因为调度和持久化这类事本来就不该由它们来做。模型也一样。有些事情它做不好不是因为它弱,是因为它的工作方式从根本上不适合做这些事。一个 LLM 的基础工作方式可以被压缩成三条事实:自回归生成、无状态推理、对环境的单向读取。
- 自回归生成意味着已经生成的 token 就是既成事实,只能在后面补救,不能回去撤销。
- 无状态推理。它没有”上一次对话的记忆”,没有”昨天做过的判断”,没有任何跨调用持久化的东西。开发者看到的”连续对话”,本质上是每一轮都把完整历史重新塞进上下文再调一次。模型以为自己在经历一段连续的交流,实际上它每次只是在看一份被精心编排过的剧本快照。
- 对环境的单向读取意味着模型能看到环境给它的信息,但不能主动感知环境。它知道工具返回了什么,但不知道工具是怎么执行的;它知道文件内容是什么,但不知道这个文件在磁盘上什么位置、被谁读过、是否还会变化。环境对它来说是一组静态输入,不是一个动态过程。 这三条事实合在一起,会自动决定几件模型做不好的事。
- 第一件做不好的事是维持连续状态。自回归和无状态放在一起意味着,一段任务如果需要跨多次调用才能完成,模型自己是不知道”前面发生过什么”的。它靠的是被塞进来的对话历史,而对话历史有上限、会稀释、会被后来的内容污染。
- 第二件做不好的事是判断停止条件。自回归生成的本能是继续吐字。模型在任何一个 token 上都面临”继续还是停”的选择,而它被训练出来的默认偏好是继续,因为训练数据里”把一件事讲完”比”及时停下”出现得频繁得多。让模型自己决定什么时候应该结束一个任务,相当于让一个本能是跑的动物自己决定什么时候该刹车。它也许能做到,但需要付出额外的控制代价,而这个代价往往比在外面装一个刹车要贵。
- 第三件做不好的事是对全局一致性负责。单向读取意味着模型看到的永远是环境的一个切片。它可以非常细致地处理这个切片内的一切,但它不知道这个切片和其他切片之间的关系。让模型”在修 A 的时候考虑到所有可能受影响的 B”,本质上是在要求它同时持有一张它从未见过的全局依赖图。它做不到这件事。不是因为不够聪明,是因为它的信息来源决定了它不可能拥有那张图。
- 第四件做不好的事是对自己的工作进行独立验证。一个刚写完代码的模型,在下一个 token 预测的时候,它对”这段代码好不好”的判断会被”我刚写的”这个事实强烈影响。这不是缺陷,是概率生成器的工作本性:已经被生成的内容会成为后续生成的前提。让同一个模型既实现又验证,等于让同一条概率链在两个阶段都为同一个结论服务。结果往往是它在实现时写出一个看起来像那么回事的东西,然后在验证时给这个东西打一个”看起来像那么回事”的分。
分工一旦成立,它就不会因为能力进步而消失。CPU 是一个经典的例子。早期计算机没有操作系统,每个程序自己管理内存、自己调度 I/O、自己负责和外设通信。随着 CPU 变强,程序变复杂,这种”每个程序自己管”的模式很快维持不下去。于是操作系统被发明出来,把调度、内存管理、文件系统、中断处理这些事从程序里接管过来,放到一个专门的层里。后来 CPU 变得更强,主频从几 MHz 提到几 GHz,内存从几 KB 提到几十 GB,但操作系统没有消失,反而变得更厚、更复杂、更不可或缺。为什么?因为操作系统本来就不是在补 CPU 的能力短板。它是在承担 CPU 不应该承担的工作。CPU 的工作是执行指令,不是记住昨天发生过什么,不是决定哪个进程先跑,不是维护文件在磁盘上的物理布局。这些事从结构上就不是 CPU 该做的。CPU 再强也不会让它们变成 CPU 的工作。
Harness engineering 和 LLM 的关系是完全同构的。LLM 的工作是在给定上下文里生成最可能的下一段 token,不是记住昨天对话里的结论,不是决定一个任务应该什么时候结束,不是维护项目里所有文件之间的依赖图,不是独立地评估自己的输出质量。这些事从结构上就不是 LLM 该做的。LLM 再强也不会让它们变成 LLM 的工作。这个同构关系能直接推出一个重要的推论:随着模型能力提升,harness 的形态会变化,但它不会消失。会消失的是那些针对具体弱点的临时补丁,不会消失的是那些承担结构性分工的基础设施。新假设带来新组件。分工没有消失,只是重新分配。这个观察有一个听起来反直觉但其实很自然的推论:模型越强,harness 的必要性反而更高,不是更低。一个能力弱的模型造成的破坏是局部的、容易被察觉的:它写的代码通不过编译,它的回答明显离题,它调用工具会报错。这些问题虽然让人头疼,但至少可见。一个能力强的模型造成的破坏是系统的、难以察觉的:它写出看起来没问题的代码,但引入了一个隐蔽的竞态条件;它做出看起来很合理的架构决策,但违反了你项目里一个它不知道的约束;它在一个小任务里顺手重构了一整个模块,每一行改动单看都是改进。弱模型会让你在第一分钟就发现它不行,强模型会让你在一周后才发现它做了什么。能力的进步没有让”刹车”变得不必要,反而让”刹车”变得更重要,因为这辆车跑得比以前快得多。
怎么判断一个系统有没有 harness?真正能判断的是这个系统有没有承担前面说的那几类结构性分工。
- 第一个问题:这个系统对”失败”的定义是什么?一个没有 harness 的系统里,失败是未定义的。模型跑出错了,系统会崩、会卡住、会无限重试、会把错误原封不动扔给用户,或者更糟,把错误当作正常结果继续用。失败在这种系统里是一种”意外”,意外发生时系统的行为不可预测。承认失败是主路径的系统(错误路径就是主路径),会把处理失败的代码当作一等公民来写;上下文超限不是意外,是一个会触发 compact 的正常事件。工具调用失败不是意外,是一个会触发重试或降级的正常事件。
- 这个系统的停止条件写在哪里?很多早期 Agent 系统的停止条件就一条:模型说自己完成了。一个有 harness 的系统不会把停止权交给模型。它会在运行时定义一套外部终止条件,任何一个被触发都会让循环结束:任务完成信号(这是模型可以参与的,但不是唯一来源)、token 预算耗尽、最大轮次达到、工具调用连续失败、用户打断、hook 阻塞、超时熔断,等等。模型在循环里负责做事,运行时在循环外负责决定什么时候拉闸。这个设计为什么重要?因为它把”停止”这件事从一个需要判断力的问题变成了一个确定性的问题。模型不需要自己想”我是不是该停了”,它只需要继续做事,系统会在合适的时候替它停下。这种分工让模型可以专注于它擅长的事(生成),把它不擅长的事(控制)交给环境。
- 第三个问题:这个系统的状态持久化在哪里?状态持久化这件事本质上是在回答一个问题:这个项目的积累到底属于谁? 如果积累在开发者的脑子里,那项目换一个人、换一台电脑、换一个时间就从零开始;如果积累在模型的上下文里,那一次对话结束就清零;只有积累在文件系统里,项目才真正拥有自己的记忆。这件事和模型能力没关系,模型再强它也不会把自己的上下文存进 git。存进 git 是 harness 的职责。
这三个问题合在一起有一个共同的结构:它们都在问”某件事情的职责被放在了哪里”。失败处理的职责、停止判断的职责、状态持久化的职责。这些职责被放在模型内部,还是被放在模型外部?放在内部意味着依赖模型的自觉和能力,放在外部意味着依赖系统的结构和约束。前者在模型能力弱的时候行不通,在模型能力强的时候也只是看起来行得通。后者从一开始就知道自己在做什么。
Agent Loop/面向用户实时交互的 AIAgent
「感知—决策—行动—反馈」四个阶段,从最简单的客服机器人到 Claude Code 这种代码 Agent,主循环的样子几乎一字不差。那为什么有的 Agent 能干一周的活,有的连续问三句就开始胡说?差异不在循环,在三个外部接入点:
- 工具集(你给它什么手脚)
- 系统提示(你告诉它它是谁)
- 状态外化(你让它记住了什么)
messages = [{ "role": "user", "content": user_input }]
while True:
resp = llm.create(model, tools, messages)
if resp.stop_reason == "tool_use":
results = parallel_exec(resp.tool_calls)
messages += [resp, tool_results(results)]
else:
return resp.text
复杂一点
loop_state = ...
context_manager = ...
skill_manager = ...
while not done:
fire_before_turn()
related_skills = skill_manager.search(query)
context = context_manager.build_context(query, related_skills)
fire_before_model()
llm_result = call_llm(context)
fire_after_model()
if llm_result.tool_calls:
for call in llm_result.tool_calls:
fire_before_tool(call)
result = tool_call(call)
fire_after_tool(call)
context_manager.append(results)
else:
context_manager.append(llm_result.text)
context_manager.compact_if_need()
fire_after_turn()
AIAgent 的复杂度,不是来自“调模型”这一步,而是来自调模型失败以后怎么办、用户半路打断怎么办、上下文塞不下了怎么办。也正因为这样,这个循环体才会达到数千行。它已不是一个单纯的推理循环,而是一条完整的交互控制链。用户在前台等回复,这条链路不是只追求“能跑通”,还需要把交互过程本身兜住。源码里能直接看到这类需求留下来的痕迹:流式输出、Provider 容错、上下文压缩、用户中断、预算耗尽后的 Grace Call、子 Agent 委派、插件钩子,基本都堆在这条路径上。
- Context 是”组装出来的”,不是”写出来的”。传统 Prompt 是一段固定文字。Loop 里 Context 是根据当前状态动态拼出来的——上一轮失败日志、当前文件树、最近 N 条调用记录,全自动拼进下一轮 Prompt。这意味着你不再是”写 Prompt 的人”,而是”设计 Context 怎么自动生长”的人。
- 失败是输入,不是终点。跑挂了?把错误堆栈、报错截图、上次 Diff 全自动喂回去当下一轮的输入。Loop 把”失败”重新定义成”用来下一步推理的数据”——这跟传统编程”出错就停”是反过来的思路。
状态外部化
单个 context window 内的任务,可以用对话历史勉强维持连续性。一旦任务跨越多个 session,这种连续性就会失效。要让任务持续推进,状态必须通过 task file、progress file、git commits 等外部 artifact 存活下来。状态外部化在这里是架构基础,而不只是 memory feature 的一次升级。
一个长任务系统必须把目标、计划、已完成事项、失败尝试、阻塞点、证据、diff、测试结果和下一步动作写进可恢复事实源。这类事实源在多智能体研究里一般叫做ledger(账本):一份 append-only、只追加不覆盖、可逐条回放和审计的记录。
learning loop/ 面向 RL rollout 的 HermesAgentLoop
用户交互系统优化的是体验、鲁棒性和可恢复性;RL rollout 优化的是吞吐、并发和训练信号精度。它们都叫 Agent Loop,但回答的不是同一个工程问题。训练 rollout 关心 async、token/logprobs、reward 计算和并发调度。它不面向用户,真正看重的是另外几件事:
- 必须是 async,才能并发跑大量 rollout
- 必须拿到真实 token、logprobs、masks,供 GRPO 训练使用
- 必须把工具执行和 reward 验证放在同一个 sandbox 上下文里
- 必须保持循环本身足够轻,避免把交互系统里的复杂分支带进训练路径 它没有流式输出,没有那套完整的错误恢复,也没有 Grace Call 和子 Agent 委派。PS: 在loop层没有共享,复用点下压到工具调度层。
collect_trajectory
dataset item
format_prompt()
HermesAgentLoop.run()
server.chat_completion / managed generate
parse tool calls
execute tools
产出 AgentResult + managed_state
ToolContext.compute_reward()
在同一个 sandbox 中验证结果,得到 reward
ScoredDataItem(tokens, masks, scores)
GRPO trainer 更新模型
其它
赋予智能体计算机访问权限(文件系统+Shell环境)是能力跃迁的关键——文件系统提供持久化上下文存储,Shell使其调用工具链、CLI或自主生成代码。
iii提出用“worker、trigger、function”三个原语重新定义后端,让 agent 成为与服务、队列等同等的 worker,实现实时发现、可扩展性和统一可观测性,消除 harness 与后端的界限。
- Function, 一个带稳定标识符的工作单元, 接收输入,并且可以选择返回输出, 它可以存在于任何进程里,也可以用任何语言编写。
- Trigger 是让 function 运行的东西。它可以是对 function 的直接调用,可以是一个 HTTP endpoint,可以是 cron 调度、队列订阅、状态变化、流事件,或者任何其他东西。
- Worker 是任何连接到 engine 并注册 functions 和 triggers 的进程。一个 TypeScript API 服务是 worker。一个 Python ML pipeline 是 worker。一个 Rust microservice 是 worker。一个 agent 也是 worker。
当代码越来越便宜,”决定写什么”就越来越贵你今天写的每一行 prompt 工程、每一个兜底逻辑、每一个工具,都有可能在下一代模型来的时候变成需要清理的债。所以聪明的做法是:做一些今天还不能跑通、但你预判 6 个月后会跑通的产品。模型升级的时候直接换上去,你就比所有人快了半年。最稀缺的不是”懂模型的人”,也不是”会写 SQL 的人”,而是有 taste、能在十万个 GitHub issue 里挑出真正值得做的那一个、并且能想清楚最佳交互形态的人。一个有 taste 的工程师可以从看到 Twitter 上的反馈,到本周末把功能上线,全程几乎不需要 PM 介入。这是当下最高效的组织形态。”普通牛马”怎么办?找出你工作里那些”重复在做的、你又特别讨厌的”部分,把它们交给 AI。
- 95% 可用的自动化,不是自动化。很多人把流程跑到 90% 就放弃了,剩下那 10% 自己手动兜底。结果是这件事既没真的省时间、也没真的解放精力。真正有价值的做法是死磕到 100%——把你的偏好教给模型、给反馈、迭代 prompt、调整工具配置,直到这件事你可以闭着眼睛交出去。这一步通常比你自己做一遍慢得多,但跨过去之后是真正的杠杆。
留下评论