kv系统
简介
在计算机和网络领域,缓存无处不在。可以这么说,只要硬件性能不对等的地方都会有缓存的身影。最快的 CPU 缓存与最慢的网络传输,有 1 亿倍的速度差距!因此,我们会使用高速的存储介质创建缓冲区,通过预处理、批处理以及缓冲数据的反复命中,提升系统的整体性能。
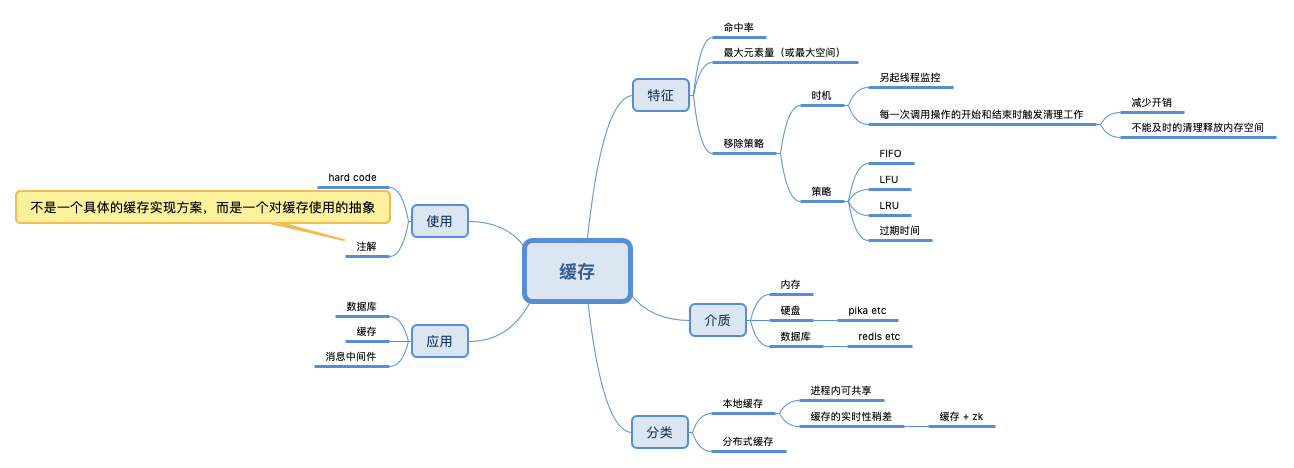
《系统性能调优必知必会》在分布式系统中,缓存无处不在。比如,浏览器会缓存用户 Cookie,CDN 会缓存图片,负载均衡会缓存 TLS 的握手信息,Redis 会缓存用户的 session,MySQL 会缓存 select 查询出的行数据,HTTP/2 会用动态表缓存传输过的 HTTP 头部,TCP Socket Buffer 会缓存 TCP 报文,Page Cache 会缓存磁盘 IO,CPU 会缓存主存上的数据,等等。
只要系统间的访问速度有较大差异,缓存就能提升性能。如果你不清楚缓存的存在,两个组件间重合的缓存就会带来不必要的复杂性,同时还增大了数据不一致引发错误的概率。比如,MySQL 为避免自身缓存与 Page Cache 的重合,就使用直接 IO 绕过了磁盘高速缓存。
缓存提升性能的幅度,不只取决于存储介质的速度,还取决于缓存命中率。为了提高命中率,缓存会基于时间、空间两个维度更新数据。在时间上可以采用 LRU、FIFO 等算法淘汰数据,而在空间上则可以预读、合并连续的数据。如果只是简单地选择最流行的缓存管理算法,就很容易忽略业务特性,从而导致缓存性能的下降。
缓存系统
这篇文章把大型系统的缓存设计问题说清楚了在真实的业务场景中,我们业务的数据——例如订单、会员、支付等——都是持久化到数据库中的,因为数据库能有很好的事务保证、持久化保证。但是,正因为数据库要能够满足这么多优秀的功能特性,使得数据库在设计上通常难以兼顾到性能,因此往往不能满足大型流量下的性能要求,像是 MySQL 数据库只能承担“千”这个级别的 QPS,否则很可能会不稳定,进而导致整个系统的故障。
使用缓存系统,最理想的效果是:应用系统尽量只与缓存系统交互,只有在查询缓存失败时,才访问数据库。进而,将读写压力从数据库转移到缓存系统上。
缓存系统有以下几类:
- 作为一个组件存在(或者说,本地缓存。比如一个jar提供的java类)
- 单机的、独立的应用
- 跨主机的、独立的应用
一个缓存系统应该考虑如下特性:
- 是否可以线性扩展,即通过增加主机,来增加缓存系统的存储能力,这涉及到分布式缓存系统。一旦涉及到分布式缓存系统,那么涉及到
- 如何将缓存的数据均摊到所有缓存节点
- 如果某个节点失效,如何处理
- 线程安全,在线程操作时,维护数据的一致性
- 当实际数据发生改变时,如何及时感知并更新缓存
- 如果缓存系统容量一定,当添加新的数据时,没有剩余空间,如何处理?数据是否有有效期?
- 最重要的一点,不能太复杂,如果访问延迟稍高,缓存系统便失去了存在的意义。
缓存系统与数据库的一致性
-
数据加入缓存
- 客户端查询缓存,如果缓存中没有,则查询数据库,并将查询结果加入到缓存中。
- 独立的定时任务 负责数据库与缓存之间的数据同步
-
数据从缓存清除或更新
- 客户端在向数据库写入数据的同时,告诉缓存该数据应失效
- 缓存中数据设置过期时间
这篇文章把大型系统的缓存设计问题说清楚了为什么我们几乎没办法做到缓存和数据库之间的强一致呢?正常情况下,我们需要在数据库更新完后,把对应的最新数据同步到缓存中,以便在读请求的时候,能读到新的数据而不是旧的数据(脏数据)。但是很可惜,由于数据库和 Redis 之间是没有事务保证的,所以我们无法确保写入数据库成功后,写入 Redis 也是一定成功的;即便 Redis 写入能成功,在数据库写入成功后到 Redis 写入成功前的这段时间里,Redis 数据也肯定是和 MySQL 不一致的。这个时间窗口是没办法完全消灭的,除非我们付出极大的代价,使用分布式事务等各种手段去维持强一致,但是这样会使得系统的整体性能大幅度下降,甚至比不用缓存还慢,这样不就与我们使用缓存的目标背道而驰了吗?不过虽然无法做到强一致,但是我们能做到的是缓存与数据库达到最终一致,而且不一致的时间窗口我们能做到尽可能短,按照经验来说,如果能将时间优化到 1ms 之内,这个一致性问题带来的影响我们就可以忽略不计。
奇怪的缓存一致性问题 未读
缓存系统的数据模型
很多事情联系起来想很有意思,比如rpc,跨主机进程通信。然后一些大牛搞出redis,可以理解为跨主机访问内存,360推出一个pika,可以理解为跨主机访问磁盘(支持redis协议)。
跨主机通信,当然免不了网络通信协议的一些约定,这不是本文的重点,所以不多谈。不管跨主机访问内存还是磁盘,都不是提供一个byte[]让客户端随便用,而是像rpc一样,传输一些约定好的数据结构。区别是,rpc传输的数据结构描述了调用信息,redis的客户端与服务端传输的数据结构是为了存储和使用。
把一些数据结构存在本机或存在远程主机,有一些隐含的意味:
- “本机的”数据结构包括:基本数据类型,复合类型(string,list,map等)。基本数据类型往往用不着跨主机存储,因为不值当。
- 对于本地访问内存而言,访问一个数据结构要指明两个要素:内存地址和类型。内存地址说明去哪取数据,类型说明取多少数据,取出的数据如何处理。远端访问内存类似,只不过”地址“不再是一个内存地址,而是一个具备唯一性的key,由远端主机完成key到该主机的内存地址的映射。
上述逻辑或许能够解释,很多类似redis的工具为什么是key-value的,并且value可以是各种数据结构。
缓存系统带来的一些问题
-
穿透,主要有两种情况
- 比如系统刚启动时,缓存中没有数据,突如其来的大量请求直接冲过缓存访问数据库
- 对于一个热门数据,缓存中没有,在第一个线程还未完成“查询数据库,写入缓存”过程时,便有多个线程冲过缓存访问数据库
解决办法主要是做请求合并
-
非法查询,缓存中存的大多数是有效的数据,那么对于一个非法的数据(或者说合法,但数据库中没有),缓存中没有,则查询压力还是由数据库承担。
缓存数据一致性探究 值得细读。
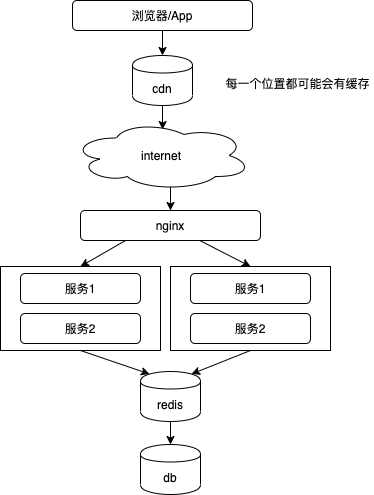
不同位置的缓存
本地缓存
Java本地高性能缓存实践 未读。
在java中,经常拿来当缓存用的是HashMap。不过,建议使用WeakHashMap,而不是HashMap,当然,更好的选择是使用框架,例如Guava Cache Guava 学习笔记。
public void TestLoadingCache() throws Exception{
// Cache 类更加灵活
LoadingCache<String,String> cahceBuilder=CacheBuilder
.newBuilder()
.build(new CacheLoader<String, String>(){
// 如果key值不在缓存中,则调用该方法获取key的实际值
@Override
public String load(String key) throws Exception {
String strProValue="hello "+key+"!";
return strProValue;
}
});
}
使用时,事先设定缓存的大概容量,可以有效地提高性能。
2018.12.02 补充:guava cache 的清理逻辑 When Does Cleanup Happen?
Caches built with CacheBuilder do not perform cleanup and evict values “automatically,” or instantly after a value expires, or anything of the sort. Instead, it performs small amounts of maintenance during write operations, or during occasional read operations if writes are rare.
The reason for this is as follows: if we wanted to perform Cache maintenance continuously, we would need to create a thread, and its operations would be competing with user operations for shared locks. Additionally, some environments restrict the creation of threads, which would make CacheBuilder unusable in that environment.
Instead, we put the choice in your hands. If your cache is high-throughput, then you don’t have to worry about performing cache maintenance to clean up expired entries and the like. If your cache does writes only rarely and you don’t want cleanup to block cache reads, you may wish to create your own maintenance thread that calls Cache.cleanUp() at regular intervals.
If you want to schedule regular cache maintenance for a cache which only rarely has writes, just schedule the maintenance using ScheduledExecutorService.
你对缓存设置一个最大容量(entry/key的个数)之后, guava cache 只有在write 操作时才会去清理 过期的expire。如果是读多写少的业务,read 操作也会触发清理逻辑occasionally。在一些场景下,guava cache put the choice in your hands,所以不可无脑使用。
单机缓存系统
在不考虑任何异常、简化特性的情况下,以下Go代码便可以实现一个简单的缓存系统。
服务端
package main
import (
"fmt"
"github.com/gorilla/mux"
"net/http"
"strings"
)
var m map[string]string //缓存key-value
func main() {
m = make(map[string]string, 10)
r := mux.NewRouter()
r.HandleFunc("/", HomeHandler) // 将客户端发来的请求交给HomeHandler处理
fmt.Println("listen...")
http.ListenAndServe(":8080", r)
}
func HomeHandler(rw http.ResponseWriter, r *http.Request) {
// 解析客户端发来的命令
argStr := r.RequestURI
argStartIndex := strings.LastIndex(argStr, "?") + 1
args := strings.Split(argStr[argStartIndex:], "|")
for _, arg := range args {
fmt.Println(arg)
}
command := args[0]
// 处理命令
switch command {
case "get":
fmt.Fprintf(rw, "%s = %s\n", args[1], handleGet(args[1]))
case "set":
handleSet(args[1], args[2])
fmt.Fprintf(rw, "%s = %s\n", args[1], args[2])
default:
fmt.Println("command error")
}
}
func handleGet(key string) string {
if val, ok := m[key]; ok {
return val
}
return ""
}
func handleSet(key, val string) {
m[key] = value
}
客户端
package main
import (
"flag"
"fmt"
"io/ioutil"
"net/http"
"strings"
)
func main() {
flag.Parse()
reqStr := strings.Join(flag.Args(), "|")
fmt.Printf("reqStr = %s\n", reqStr)
httpGet(reqStr)
}
func httpGet(reqStr string) {
resp, err := http.Get("http://localhost:8080?" + reqStr)
if err != nil {
// handle error
}
defer resp.Body.Close()
body, err := ioutil.ReadAll(resp.Body)
if err != nil {
// handle error
}
fmt.Println(string(body))
}
执行过程为:
$ mycache set name lqk
# “客户端”解析命令行,并向服务端发送“http://localhost:8080/?get|name”
# “服务端”解析出"get|name"并返回key为name的值
$ name = lqk
分布式缓存系统
如果cache system架在多个主机上,问题就复杂了,因为会有主机宕机,也有的新的主机加进来。因此,要尽可能(有些损失无法避免)满足以下四个特性:
- 平衡性,每个主机存储的key(或者说负载)都差不多
- 单调性,当增加新的主机时,能够将某些key(旧有的或新的)弄到新的主机上
- 分散性,有待进一步了解,大意是尽量避免重复存储相同的key值
- 负载,有待进一步了解
关键:将一个key存在哪个节点上。
- 取模算法(
hash(key)%N)其弊端很明显:当某个主机宕机时,其存储的数据将无法找到(这个是任何缓存系统都无法避免的),问题是,其保有的存储地址空间也将失效(即该主机宕机后,一些key值还是会继续被映射到该主机,然后发现无法存储)。 - 一致性哈希算法
分布式存储在B站的应用实践 未细读
varnish 缓存
位于服务与 nginx 之间
全站缓存
cdn位于站点和用户之间, 也是一种变相的缓存系统。看不见摸不着的cdn是啥
运维
百度信息流和搜索业务中的KV存储实践 部分总结
- 作为有状态服务,集群的故障机处理、服务器升级、资源扩缩容都需要专人跟进,运维人力随集群规模呈正比增长。彼时又逢推荐业务完成了微服务化改造,业务资源交付和上线都能当天完成,存储资源动辄周级的交付能力也成了业务上线效率的瓶颈。这些都促使我们对原来的系统架构进行彻底升级,通过提升单机引擎性能和云原生化有效降低资源成本和运维人力成本。同时我们还要满足业务对服务的敏捷性要求,通过云基础设施提供的资源编排能力,使系统具备小时级服务交付能力。
- 单机引擎性能是KV系统的关键指标,一般我们通过读写性能(OPS、延时(latency))和空间利用率来衡量引擎的性能,由于当前引擎架构和存储设备硬件性能的制约,我们在引擎中往往只能选择读性能、写性能和空间利用率中某个方向进行重点优化,比如牺牲空间利用率提升写吞吐,或者牺牲写吞吐、提升空间利用率和读吞吐。这类优化对于业务单一的场景比较有效,因此我们通过引擎优化,既要解决如何在降低读写放大的同时,尽可能平衡空间放大的问题;又要在引擎内实现自适应机制,解决业务充分混布场景下,吞吐模式多变的问题。
- 容器化改造方面,单机时代的KV服务以用满整机资源为目标,对内存资源和存储介质IO的使用往往不加任何限制。引擎的容器化改造,要求我们精细化控制对上述资源的使用。
个人理解,业务对kv系统有以下需求
- 低延迟、稳定性
- 监控空间使用,空间不够/业务自动扩容时,自动扩容 ==> 监控/扩容操作
- 对业务屏蔽底层升级 ==> 数据迁移/路由更新 ==> 所有业务方统一的接入协议和sdk
- 特殊业务的特殊需求,比如特别的引擎或参数配置;不同业务对服务的可用性、数据一致性的要求并不相同
负载均衡策略:一致性哈希算法/就近路由算法
《分布式协议与算法实战》
一致哈希本质上是一种路由寻址算法(实现上一般会有一个“路由表”,路由规则是顺时针“就近”),适合简单的路由寻址场景。
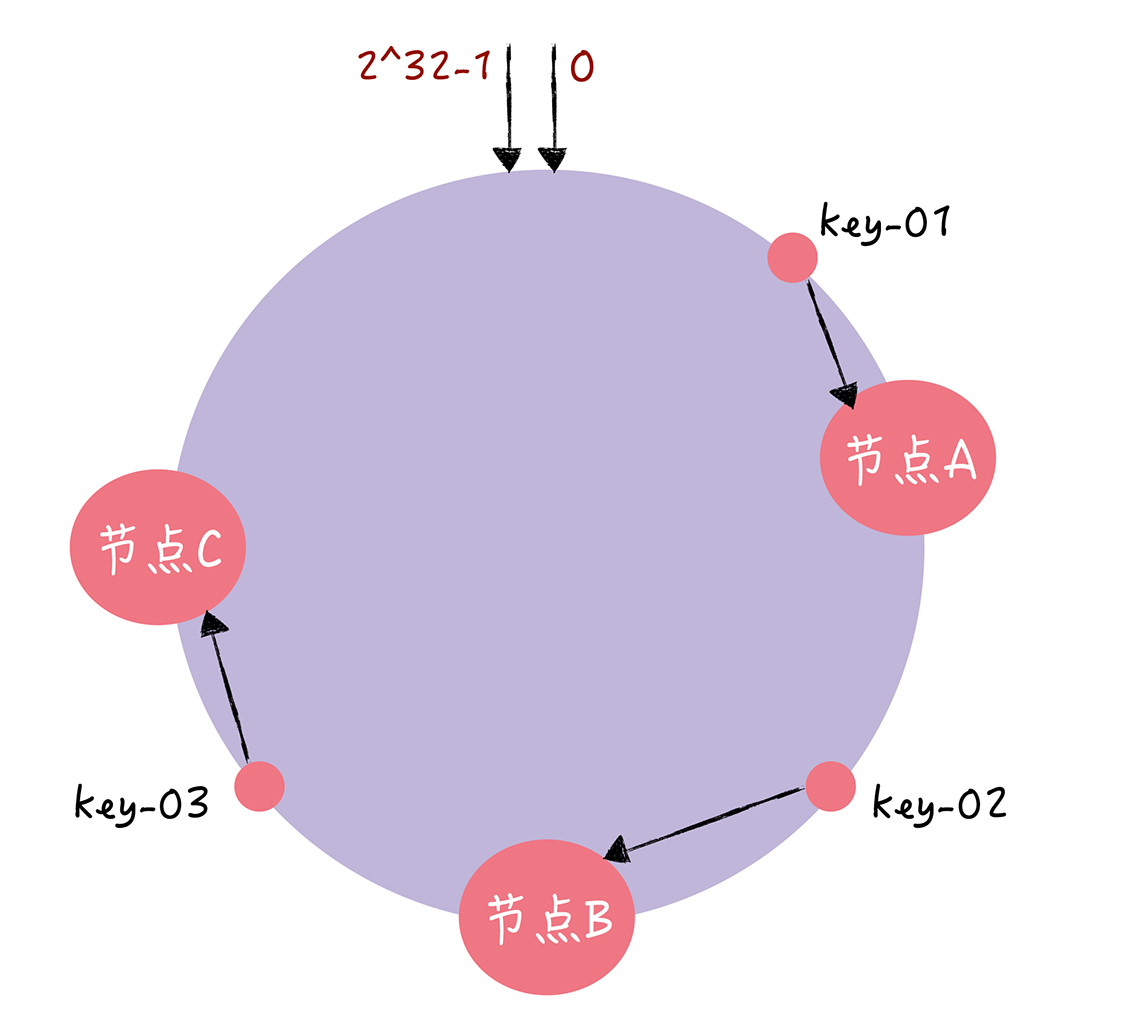
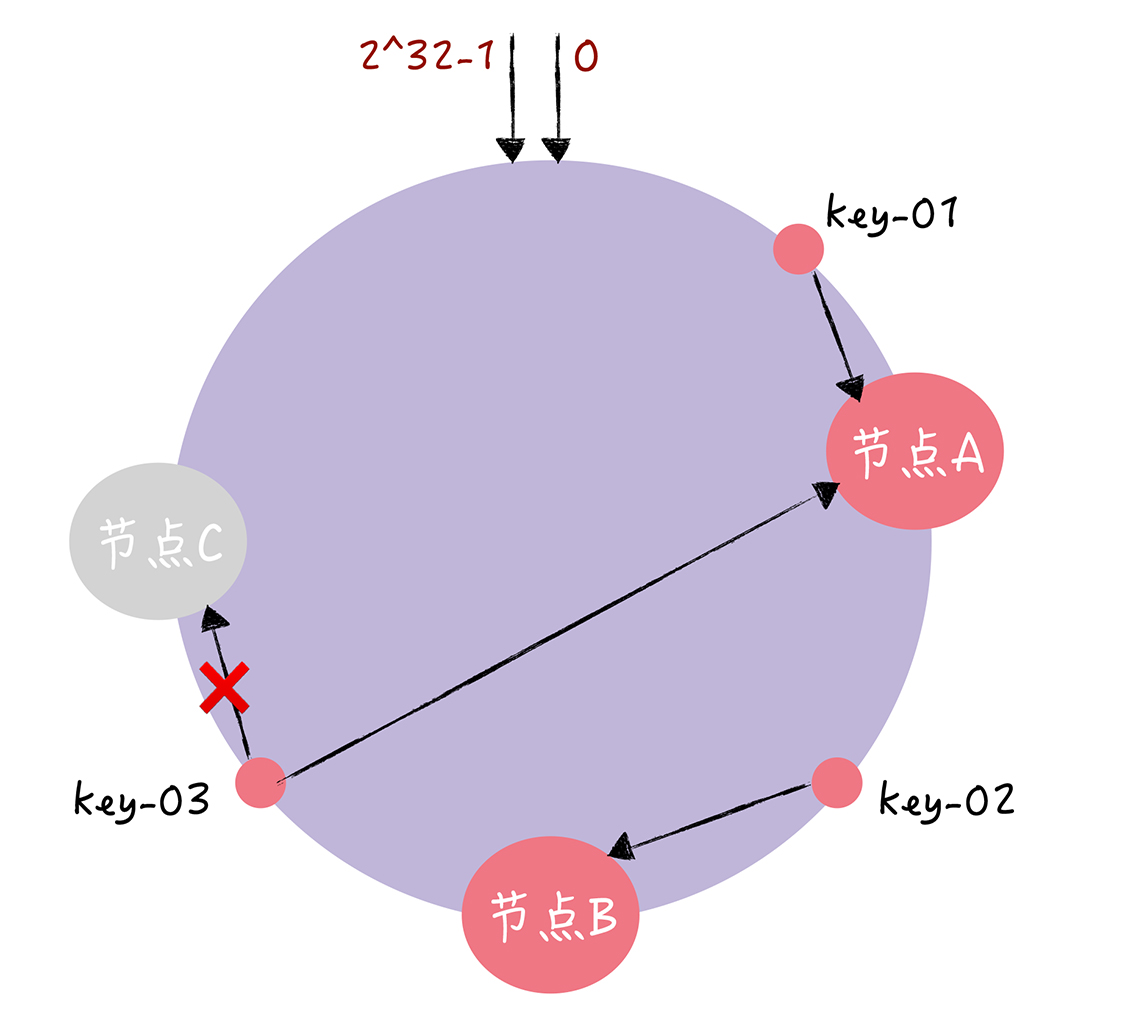
假设 key-01、key-02、key-03 三个 key,根据一致哈希算法,key-01 将寻址到节点 A,key-02 将寻址到节点 B,key-03 将寻址到节点 C。
那一致哈希是如何避免哈希算法“在节点变更的情况下要求数据迁移”的问题呢?
-
节点宕机。可以看到,key-01 和 key-02 不会受到影响,只有 key-03 的寻址被重定位到 A。受影响的数据是会寻址到节点 B 和节点 C 之间的数据(例如 key-03)。PS:挂了的节点的 请求会被打到下一个节点,只有挂了的节点请求才会被影响, 。
-
增加节点。key-01、key-02 不受影响,只有 key-03 的寻址被重定位到新节点 D。
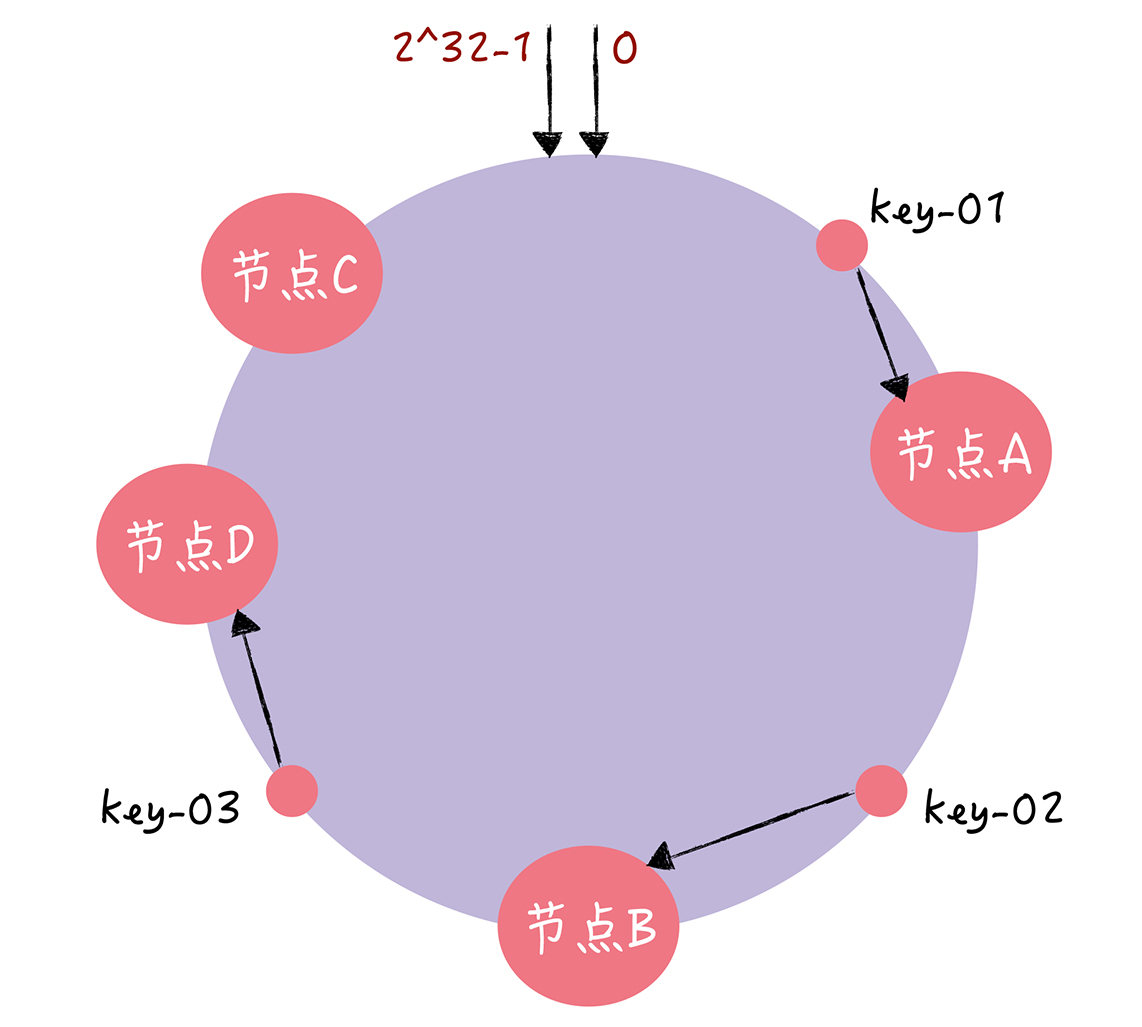
使用一致哈希的话,对于 1000 万 key 的 3 节点 KV 存储,如果我们增加 1 个节点,变为 4 节点集群,只需要迁移 24.3% 的数据。当节点数越多的时候,使用哈希算法时,需要迁移的数据就越多,使用一致哈希时,需要迁移的数据就越少。当我们向 10 个节点集群中增加节点时,如果使用了哈希算法,需要迁移高达 90.91% 的数据,使用一致哈希的话,只需要迁移 6.48% 的数据。
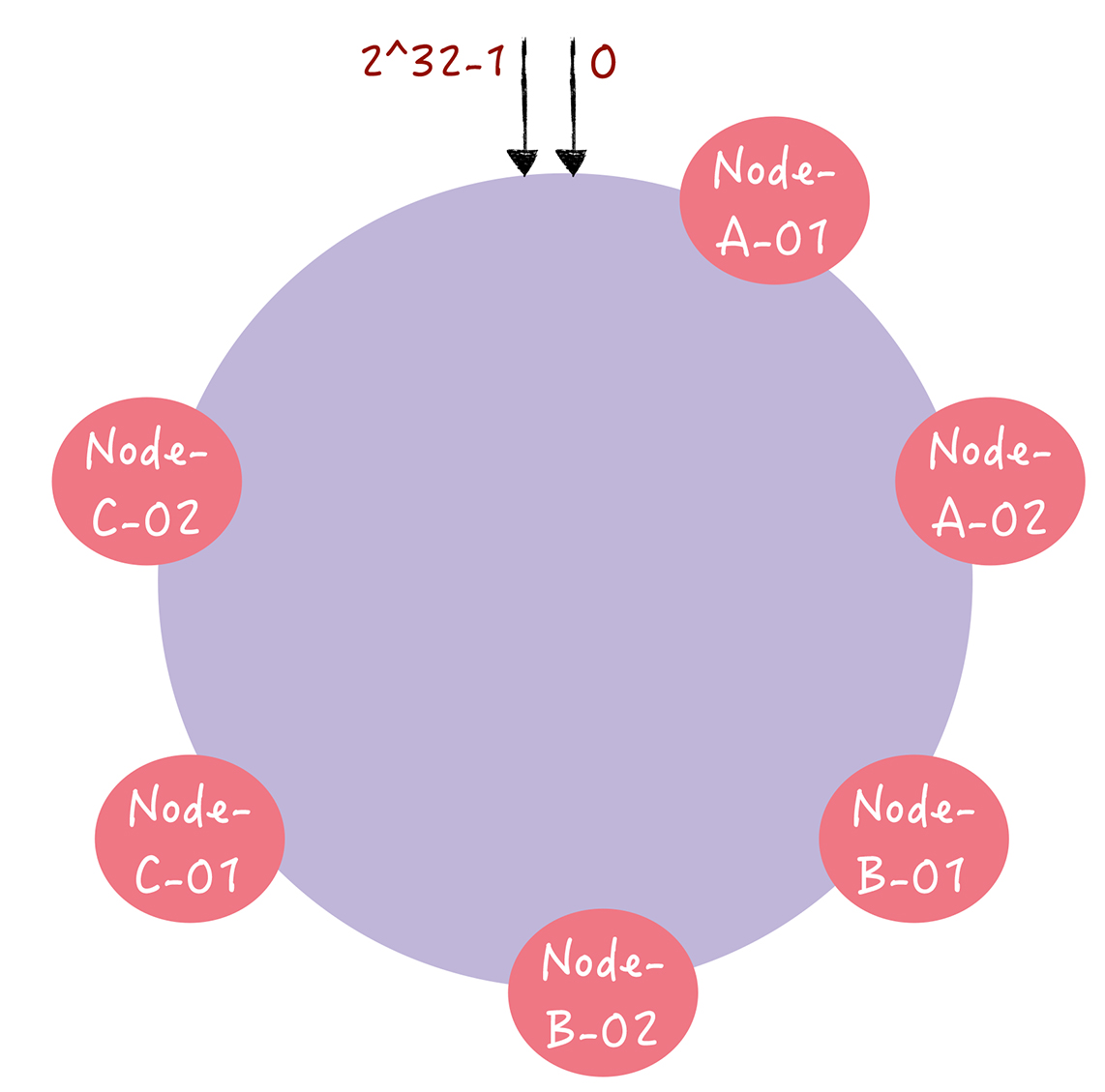
当节点数较少时,可能会出现节点在哈希环上分布不均匀的情况。这样每个节点实际占据环上的区间大小不一,最终导致业务对节点的访问冷热不均。这个问题可以通过引入更多的虚拟节点来解决:就是对每一个服务器节点计算多个哈希值,在每个计算结果位置上,都放置一个虚拟节点,并将虚拟节点映射到实际节点。比如,可以在主机名的后面增加编号,分别计算 “Node-A-01”“Node-A-02”“Node-B-01”“Node-B-02”“Node-C-01”“Node-C-02”的哈希值,于是形成 6 个虚拟节点:
一致性哈希实现
- ConsistentHash 哈希环由一个 TreeMap 表示,对输入的 key 使用
TreeMap.ceilingKey(key)找到最近的节点
《系统性能调优必知必会》
使用哈希算法扩展系统时,最大的问题在于代表哈希桶的服务器节点数发生变化时,哈希函数就改变了,数据与节点间的映射关系自然发生了变化,必须迁移改变了映射关系的数据。一致性哈希算法是通过 2 个步骤来建立数据与主机节点间映射关系的:
- 首先,将关键字经由通用的哈希函数映射为 32 位整型哈希值。这些哈希值会形成 1 个环,最大的数字 2^32 相当于 0。
- 其次,设集群节点数为 N,将哈希环由小至大分成 N 段,每个主机节点处理哈希值落在该段内的数据。
一致性哈希算法扩容、缩容动作就只影响相邻节点,大幅度减少了数据迁移量,但却遗留了两个问题没有解决
- 如果映射后哈希环中的数字分布不均匀,就会导致各节点处理的数据不均衡
- 容灾与扩容时,哈希环上的相邻节点容易受到过大影响。比如,当节点宕机后,根据一致性哈希算法的规则,其上数据全部迁移到相邻的节点上,造成相邻节点压力增大。
为此,在真实的数据节点与哈希环之间引入一个虚拟节点层。例如集群含有 4 个节点,但我们并不直接将哈希环分为 4 份,而是将它均匀地分为 32 份并赋予 32 个虚拟节点,因此每个虚拟节点会处理 2^27 个哈希值,再将 32 个虚拟节点通过某个哈希函数(比如 CRC32)映射到 4 个真实节点上。这样,宕机节点上的数据会迁移到其他所有节点上,扩容时新增节点可以分担现有全部节点的压力。
一致性哈希算法虽然将数据的迁移量从 O(M) 降为 O(M/N),却也将映射函数的时间复杂度从 O(1) 提高到 O(logN),但由于节点数量 N 并不会很大,所以一致性哈希算法的性价比还是很高的。
提升数据分布、访问的平衡性,并不是只有一致性哈希这一个方案。比如,我们将数据与节点的映射关系放在另一个服务中持久化存储,通过反向代理或者客户端 SDK,在访问数据节点前,先从元数据服务中获取到数据的映射关系,再访问对应的节点。这样做可以更加灵活的控制映射关系,但多了一个集中存储,可能会有性能及安全问题。
留下评论