forkjoin 泛谈
简介
应用 fork-join 框架 基本要点:硬件趋势驱动编程语言,一个时代的主流硬件平台形成了我们创建语言、库和框架的方法,语言、库和框架形成了我们编写程序的方式。
| 语言 | 类库 | 硬件的并行性越来越高 | |
|---|---|---|---|
| synchronized、volatile | Thread | 大部分是单核,线程更多用来异步 | |
| java1.5/1.6 | java.util.concurrent 包 | 多核,适合粗粒度的程序,比如web服务器、数据库服务器的多个独立工作单元 | |
| java1.7 | fork-join | 多核、每核多逻辑核心,细粒度的并行逻辑,比如分段遍历集合 |
一个任务分解为可并行执行的多个任务,Divide and conquer
Result solve(Problem problem) {
if (problem.size < SEQUENTIAL_THRESHOLD)
return solveSequentially(problem);
else {
Result left, right;
INVOKE-IN-PARALLEL {
left = solve(extractLeftHalf(problem));
right = solve(extractRightHalf(problem));
}
return combine(left, right);
}
}
forkjoin 之前
Fork and Join: Java Can Excel at Painless Parallel Programming Too! 详细解释了引入 fork join的初衷,要点如下:
-
java1.5 之前,只有一个Thread和Runnable
- manipulating low-level primitives to implement complex operations opens the door to mistakes
- you have to deal with thread synchronization and the pitfalls of shared data
-
java1.5/1.6进步了,Rich Primitives with the java.util.concurrent Packages
- Executors are a big step forward compared to plain old threads because executors ease the management of concurrent tasks.
- Thread-safe queues
- Rich synchronization patterns( such as semaphores or synchronization barriers)
- Efficient, concurrent data collections
- Atomic variables
- A wide range of locks,, for example, support for re-entrance, read/write locking, timeouts, or poll-based locking attempts.
fork/join 为何如此有意义
- concurrency(并发) 和 parallelism(并行). 现在的多核cpu,并发是不够的,要并行。后面会详述。
- The problem with the executors for implementing divide and conquer algorithms is not related to creating subtasks, because a Callable is free to submit a new subtask to its executor and wait for its result in a synchronous or asynchronous fashion. The issue is that of parallelism: When a Callable waits for the result of another Callable, it is put in a waiting state, thus wasting an opportunity to handle another Callable queued for execution.
- The core addition is a new ForkJoinPool executor that is dedicated to running instances implementing ForkJoinTask. ForkJoinTask objects support the creation of subtasks plus waiting for the subtasks to complete. With those clear semantics, the executor is able to dispatch tasks among its internal threads pool by “stealing” jobs when a task is waiting for another task to complete and there are pending tasks to be run. 任务内创建子任务; ForkJoinTask的阻塞不会导致 线程的阻塞。
- forkjoin 和子任务(依赖任务)交互,是
callballResult = subForkJoinTask.join(),join 不会导致当前task“阻塞”,但不会让线程阻塞。已经有点goroutine 的意思了,虽然对io 之类的操作还是会让 线程阻塞。
比如计算1到n的和,有两种方式
- 将1~n划分为m份儿,分别执行。这个Executor 和forkjoin 都可以做到
-
以树的方式层层划分任务
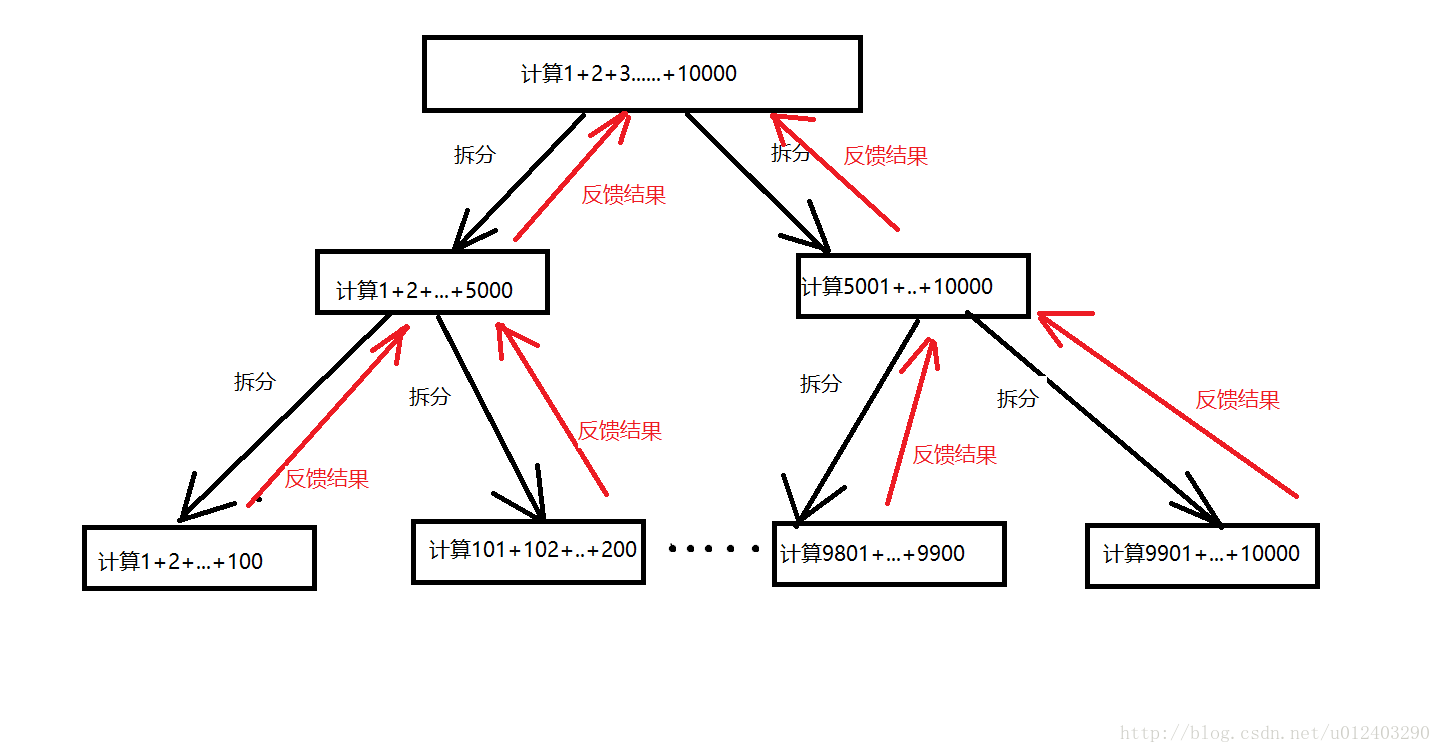
叶子和非叶子节点都占用一个线程,但非叶子节点要等待 叶子节点执行完毕,Executor 的方式就会导致很多线程阻塞。也就是说,Executor 更适合并发处理 不相关的子任务,forkjoin 在此基础上更进一步。
Fork/Join框架 聊聊并发(八)——Fork/Join框架介绍
Fork/Join使用两个类:ForkJoinTask和ForkJoinPool 来完成fork(分割子任务)和join(合并子任务):
ForkJoinTask:Abstract base class for tasks that run within a ForkJoinPool.A ForkJoinTask is a thread-like entity that is much lighter weight than a normal thread. Huge numbers of tasks and subtasks may be hosted by a small number of actual threads in a ForkJoinPool, at the price of some usage limitations.
具体细节
Java 并发编程笔记:如何使用 ForkJoinPool 以及原理 基本要点
- fork,把任务推入当前工作线程的工作队列里
- join,查看任务的完成状态,如果任务尚未完成,但处于自己的工作队列内,则完成它。如果任务已经被其他的工作线程偷走,则窃取这个小偷的工作队列内的任务(以 FIFO 方式),执行,以期帮助它早日完成欲 join 的任务。反正就是不会像
Thread.join那样干等
fork-join和ExecutorService,执行细粒度并行任务的差别,可以细细体会一下。比如计算一个1到n的和
- ExecutorService main 方法将所有的任务划分好,每个线程的任务是清晰的,然后执行
- fork-join main 会将任务分为left(1~n/2)和right(n/2+1~n),然后执行。子任务看情况执行或继续分解子任务。
java8 in action,从代码上看,ForkJoin 定义了抽象方法protected abstract R compute();, the method defines both the logic of splitting the task at hand into subtasks and algorithm to produce the result of a single subtask when it’s no longer possible or convenient to further divide it. ForkJoinTask 在compute 方法中划分子任务,这和Runnable 的 run 方法也是极不一样的。
从ForkJoinPool的使用也可以看出 ForkJoinTask 的不同,其默认的线程数跟cpu 核心数相同,其象征意味就很浓厚。同时,jdk8 in action指出 新建多个 ForkJoinPool 实例是没有意义的。由此可以看到,ForkJoinTask 不是用来处理网络连接等请求的,也不为了并发,Executor 哪怕有100个线程,1个任务也只占了一个线程,一个cpu。 ForkJoinPool 哪怕只有一个ForkJoinTask,也可以让所有的cpu 都忙碌起来,it is parallelism。
换个角度看 forkjoin
引用Oracle官方定义的原文:
The fork/join framework is an implementation of the ExecutorService interface that helps you take advantage of multiple processors. It is designed for work that can be broken into smaller pieces recursively. The goal is to use all the available processing power to enhance the performance of your application. As with any ExecutorService implementation, the fork/join framework distributes tasks to worker threads in a thread pool. The fork/join framework is distinct because it uses a work-stealing algorithm. Worker threads that run out of things to do can steal tasks from other threads that are still busy. The center of the fork/join framework is the ForkJoinPool class, an extension of the AbstractExecutorService class. ForkJoinPool implements the core work-stealing algorithm and can execute ForkJoinTask processes.
拆解下
- ExecutorService 的一种实现
- It is designed for work that can be broken into smaller pieces recursively。 ExecutorService 运行的 任务本身可以递归分解
- 目标是,充分利用cpu
- work-stealing
让我们把本小节的主角给 ExecutorService,ExecutorService 主要有以下几种实现
- newCachedThreadPool
- newFixedThreadPool
- newScheduledThreadPool
- newSingleThreadExecutor
- newWorkStealingPool() 实际返回 ForkJoinPool,jdk1.8 新增这个方法
从这个角度看,forkjoin 只能算是 ExecutorService 新增了一种线程及任务管理策略的实现,这个策略在一些具体的场景下比较有用罢了。对于netty 等事件驱动场景来说,单线程模型意义也很重大呢。
work-stealing
所谓的 充分利用cpu, work-stealing更多是 其它线程较为清闲时的一个优化策略。
可以看到,若是使用寻常的ExecutorService 实现
- 一个复杂任务 由一个线程运行完成,该线程或许很忙,但本身没啥线程安全问题(跟其它线程交互的数据除外)。
- 缺点就是,其它线程即使很闲,也得在旁边干看着。
forkjoin 支持 递归拆解任务
- 一个任务的多个子任务会被不同线程执行,任务拆解产生的共享数据 可能带来线程安全问题。 这也是java8 在 提供 parallel stream(底层实现是forkjoin) 时特别强调 不要 运行 有状态逻辑的 原因。
- 优点是,因为任务粒度可以变细拆解,其它线程闲下来也可以搭把手。场面话就是 redistribute and balance the tasks among the worker threads in the pool.
为什么是一个线程一个队列
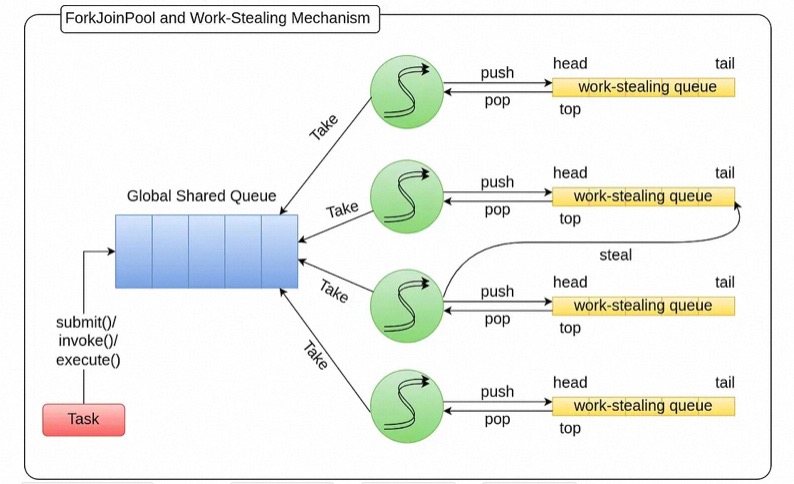
forkjoinpool 像 ThreadPoolExecutor 一样,所有线程共用一个队列,不就是天然的 work-stealing 算法了么?
ForkJoinTask.fork() 确保 task 和subtask 在一个队列中,而一个线程对应一个队列,也就是 Executor executor = Executors.newWorkStealingPool(); executor.execute(runnable) 仍然是尽 最大可能保证 一个task 交由一个线程执行,这个跟其它Executor 实现是一样的。此时,所有线程还共享一个队列,则不能保证该效果。 这样做的一个好处是,减少并发的可能性。
PS: 一个线程一个队列 就跟goroutine 调度很像了。golang从设计上就支持协程,goroutine是默认的并行单元,单独开辟线程反而要特别的代码。不像java有历史负担,fork-join着眼点更多在于,基于现有的基本面,如何提高并发性 ==> 需要先分解任务等。fork-join只是提高在特定场景(可以进行子任务分解与合并)下的并行性。所以,goroutine和fork-join根本就不是一回事。前者是匹敌进程、线程的并发模型,后者是特定问题的并发框架
小结
脉络就是:任务拆解 ==> work-stealing ==> 充分利用多线程。
留下评论