分布式训练的一些问题
简介
单个GPU的显存上限,限制了训练时的参数规模及batch size,导致训练效率无法达到预期。分布式训练的本质是分布式计算,分布式计算跟着任务切分、存算分离、数据加速、分布式通信等一系列事儿。
关于深度学习框架的一些自己见解我觉得做深度学习框架其实有两个派别的人,一派是从分布式系统的人来做的,另外一派是从做算法的人来做的。不同的人的背景不同,所以做这个事情的角度也会不同,从而产生不同门派。tensorflow属于系统派,而pytorch属于算法派。
- TensorFlow从设计之初就在考虑超大的模型分布式训练的场景,设想这个框架需要能够从规模上很好支持分布式,能够很好的扩展到任意大的深度模型的框架。很自然会把模型的开发过程分成构图和执行两个阶段。构图的时候只是生成一个逻辑执行计划,然后通过显式方式的提交(或者execute),系统再根据用户指定的或者系统智能的决定的placement进行分图,并在这些分图中添加合适的Send-Recv的Op从而构成一个分布式的执行计划。但是这样的设计理念也会带来一些困恼,我们在模型训练时候有时候有些类似控制图的部分,在这种设计理念下,我们必须要把这些控制流图的代码也op化,然后把这些op也整体串联在Tensor的Flow执行图中。但是这种方式会使得一些习惯单机开发的研究人员觉得比较晦涩。
- 框架的另外一派是算法派,特别是感知类模型(图像,语音,语言类)训练,因为这类训练一般都是同步训练,且是数据并行,这样我们就可以利用MPI的AllReduce的通讯源语来进行梯度的汇集计算。因为面向是数据并行的场景,这样话在神经网络部分其实都是单机程序,从而可以利用任何python的语法糖去构建任何的动态的训练控制逻辑(大家也把这种称作动态图)。对于算法研究人员来讲,这种方式写代码比较随性也方便debug,所以在研究界pytorch得到大量的关注和使用。
利用多 GPU 加速深度学习模型训练 从GPU 说到 horovod,很不错的文章
基本理念
分布式TensorFlow入门教程 https://zhuanlan.zhihu.com/p/35083779
炼丹师的工程修养之四: TensorFlow的分布式训练和K8S无论是TensorFlow还是其他的几种机器学习框架,分布式训练的基本原理是相同的。大致可以从以下五个不同的角度来分类。
- 并行模式(任务切分), 对于机器学习的训练任务,原来的“大”问题主要表现在两个方面。
- 一是模型太大,我们需要把模型“拆”成多个小模型分布到不同的Worker机器上;
- 二是数据太大,我们需要把数据“拆”成多个更小的数据分布到不同Worker上。PS:梯度广播
- 架构模式,通过模型并行或数据并行解决了“大问题”的可行性,接下来考虑“正确性”。以数据并行为例,当集群中的每台机器只看到1/N的数据的时候,我们需要一种机制在多个机器之间同步信息(梯度),来保证分布式训练的效果与非分布式是一致的(N * 1/N == N)。相对成熟的做法主要有基于参数服务器(ParameterServer)和基于规约(Reduce)两种模式。Tensorflow 既有 PS 模式又有对等模式,PyTorch 以支持对等模式为主,而 MXNET 以支持 KVStore 和 PS-Lite 的 PS 模式为主。 快手八卦 — 机器学习分布式训练新思路(1)
- 在worker与parameter server之间模型参数的更新有同步(Synchronous)、异步(Asynchronous)和混合三种模式。 在梯度同步时还要考虑“木桶”效应,即集群中的某些Worker比其他的更慢的时候,导致计算快的Worker需要等待慢的Worker,整个集群的速度上限受限于最慢机器的速度。因此梯度的更新一般有同步(Sync)、异步(Async)和混合三种范式。
- 同步模式中,在每一次迭代过程中,所有工作节点都需要进行通信,并且下一步迭代必须等待当前迭代的通信完成才能开始。确保所有的设备都是采用相同的模型参数来训练,需要各个设备的计算能力要均衡,而且要求集群的通信也要均衡。
- 反之,异步式分布算法 则不需要等待时间:当某个节点完成计算后就可直接传递本地梯度,进行模型更新。
- 物理架构,这里主要指基于GPU的部署架构,基本上分为两种:单机多卡和多机多卡
- 通信技术,要讨论分布式条件下多进程、多Worker间如何通信,分为以分为 Point-to-point communication 和 Collective communication 两类,Collective communication常见的技术有MPI,NCCL,GRPC,RDMA等
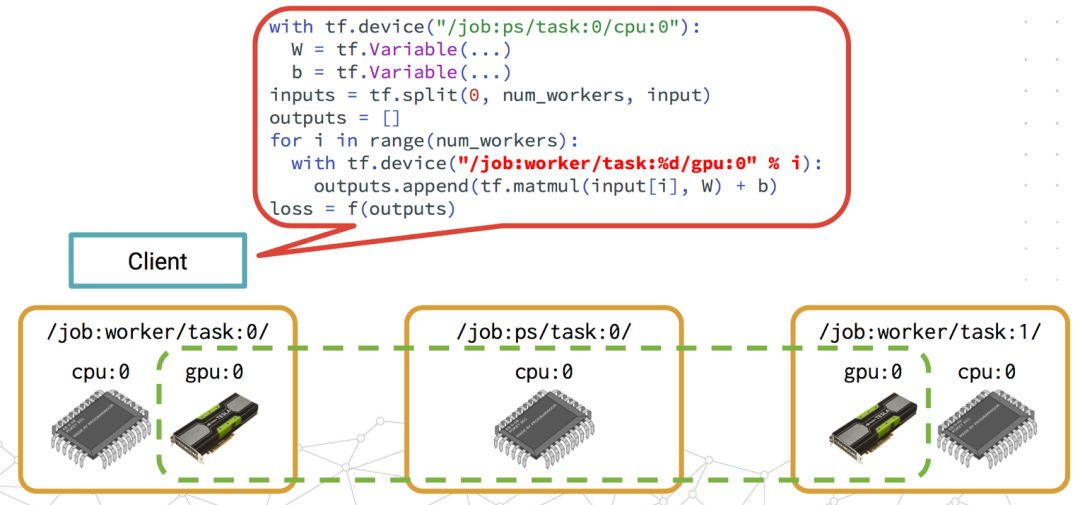
并行模式
单个GPU卡内存有限,从而引发的各种问题,可分为两个维度来看:
- 数据维度:对于小模型而言,虽然单卡能放下一个模型,但没法放下一个batch所要的全部数据,所以数据得切分到不同卡上计算最终汇总,从而引入数据并行DP
- 模型维度:对于大模型而言,单卡无法放下一个模型,必须将模型切分到多张卡上,由此引入了除DP之外的各种并行(TP/PP/EP/SP),可统称为模型并行 如果模型又小,单个batch数据不多,一张卡跑就够了,也不需要各种并行。如果模型一张卡能放下,但单个batch的数据放不下,那只需要DP,这样计算效率最高。在这种情况下再加入其他并行策略反而拖累训练效率。只有在模型单卡也放不下的时候,这时才必须考虑DP之外的并行。不同的并行策略根据模型结构的不同,采取的策略也不一样。
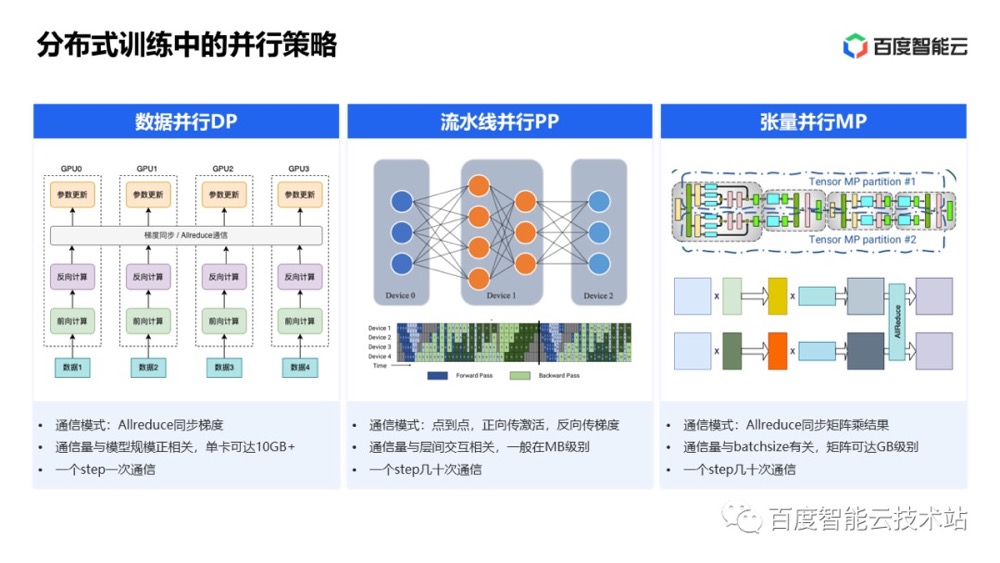
各种并行
- 数据并行:它遵循单一程序多数据(SPMD)编程模型。因为训练费时的一个重要原因是训练数据量很大。数据并行就是在很多设备上放置相同的模型,并且各个设备采用不同的训练样本对模型训练。训练深度学习模型常采用的是batch SGD方法,采用数据并行,可以每个设备都训练不同的batch,在反向传播时,模型参数有多个worker副本,为了能将结果共享——确保整个模型参数能够在不同的GPU之间进行同步,所有的梯度都将进行全局归纳(如梯度平均或参数服务器,all_reduce 操作是实现此目的的最快方式之一)。所有worker共享ps 上的模型参数,并按照相同拓扑结构的数据流图进行计算。(将不同的data 拆分到不同的设备上)
- 几乎所有的训练框架都支持这种方法,早期比较流行的开源实现是horovod。现在pytorch ddp和tensorflow mirror strategy都原生的支持了。
- 当batch size=1时,传统方法无法继续切分。
- 对于parameter, optimizer state等batch size无关的空间开销是无能为力的。每个GPU上依然需要一份完整的parameter等副本。
- 数据并行的优点是在所有并行中效率最高,除了一次allreduce之外,没有任何额外通信开销。其通信量为 $2Mdtype$,M是模型大小,dtype是数据类型,2是因为allreduce的特性(allreuce=reducescatter+allgather,他们各自通信量参数都是M)。

- 模型并行(model parallelism),对模型内部的参数矩阵切分,然后利用分块矩阵乘进行计算得到正确结果,由于参数矩阵是以tensor表示,故叫张量并行。从不同视角看
- 网络拆分为层:神经网络模型通常都是多层神经元的组合,如果要采用模型并行策略,一般需要将不同的层运行在不同的设备上,但是实际上层与层之间的运行是存在约束的:前向运算时,后面的层需要等待前面层的输出作为输入,而在反向传播时,前面的层又要受限于后面层的计算结果。所以除非模型本身很大,一般不会采用模型并行,因为模型层与层之间存在串行逻辑。但是如果模型本身存在一些可以并行的单元,那么也是可以利用模型并行来提升训练速度,比如GoogLeNet的Inception模块。PS:不同层因为参数量不同,切分方式不同,TP带来的开销要逐层分析。
- 计算图拆分为子图: 就是把计算图分成多个最小依赖子图,然后放置到不同的机器上,同时在上游子图和下游子图之间自动插入数据发送和数据接收节点,并做好网络拓扑结构的配置,各个机器上的子图通过进程间通信实现互联。
- 单纯的把模型的参数切分到多个GPU上,在使用时通过数据驱动的方式,每个GPU从其他GPU上拉取需要的那部分。比如大embedding参数如果有100GB,可以切分成8份放在8个GPU上。每个minibatch计算时embedding层仅需要gather 100GB中很少的一部分。节省了显存,代价是增加了通信量,是一种时间换空间的手法。
- TensorFlow可以说是支持MP的典型框架,通过将device placement暴露给用户,开放了几乎所有的玩法。但是弊端就是大部分用户其实并不能合理的使用,反而是经常因为配置错误导致性能急剧下降。
- 一个比较大的问题是GPU利用率低。一条链上只有一个 GPU 在干活,剩下的都在干等,当没有计算到某个GPU上的模型分片时,这个GPU常常是闲着的。pipeline parallelism一定程度上解决了这个问题,可以把一个 batch 分为若干个 mini-batch,每个节点每次只处理一个 mini-batch 的数据,并且只有当整个批次都训练完成后才会进行参数更新。
- 在张量并行中,也称为层内模型并行,用于在多个GPU上训练LLMs。将不同的算子拆分到不同的设备上,每个设备执行算子的部分操作,最终聚合得到某个算子的计算结果(引入f(广播)与g(All-reduction)操作,f与g引入的通信量可以通过BSH估算,其中B是Batch,S是sequence,H是Hidden层维度)。与数据并行不同,张量并行通常需要高带宽连接进行通信,因此更常用于单个GPU节点内(多个gpu)。比如矩阵相乘就可以根据其数学性质进行拆分:$XA=\begin{bmatrix}X_1 & X_2\end{bmatrix}\begin{bmatrix}A_1\A_2\end{bmatrix}=X_1A_1 + X_2A_2 = Y_1 + Y_2 = Y$

- 流水并行,也称为层间模型并行,被提出以适应大型模型在多个GPU上,特别是在不同节点上的分布。流水线并行将模型的层划分为多个阶段,每个阶段由模型中的一组连续层组成,并映射到一组GPU(将不同的layer 拆分到不同的设备上)。例如一个模型是80层,切分到8张卡上,每一张卡放10层。与通常需要高带宽连接进行通信的张量并行不同,流水线并行只需要在指定的切割点交换中间张量,因此通信需求较少。因此,流水线并行适用于在连接带宽较小的多个GPU节点上扩展LLM训练。由于不同阶段的数据依赖性,流水线并行通常将输入数据拆分为多个微批次以实现流水线化,从而有效训练大型模型。但pp会带来一个严重的问题,那就是气泡率较高,可以将GBS切分为多个micro_batch,尽量将pipeline填满,从而一定程度减缓气泡率问题。另外没有使用梯度累加,导致显存消耗比较高,和micro-batchs成正比。
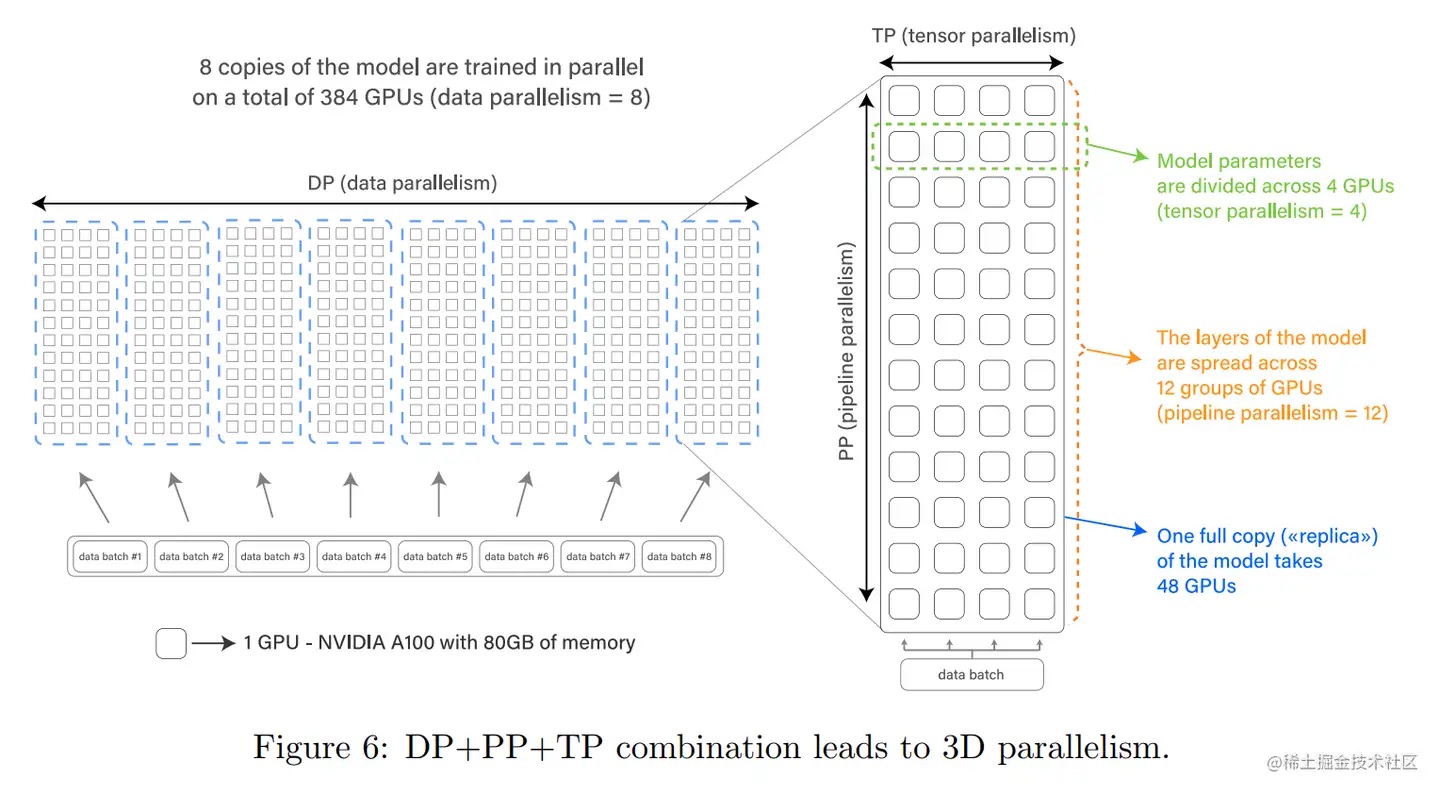
由于DP效率最高,DP为所有并行中首选且必带的。同时只要一张卡放不下一个batch中的数据(以及其产生的激活值),DP也是必选的。针对千亿规模的大语言模型,通常,在每个服务器内部使用张量并行策略(TP不能超过8。为什么?一台机器就8张卡),由于该策略涉及的网络通信量较大,因此需要利用服务器内部的不同计算设备之间的高速通信带宽(只有单机内nvlink这种高带宽才能支持)。通过流水线并行将模型的不同层划分为不同阶段,每个阶段由不同的机器负责计算。这样可以充分利用多台机器的计算能力,并通过机器之间的高速通信传递计算结果和中间数据,以提高整体的计算速度和效率。最后在外层叠加数据并行策略,将训练数据发到多组服务器上进行并行处理,每组服务器处理不同的数据批次,以增加并发数量,加快整体训练速度。通过数据并行
- 中心化分布式,存在一个中心节点,它的作用是汇总并分发其他计算节点的计算结果,更进一步,中心节点可以采用同步更新策略(Synchronous updating),也可以采用异步更新策略(Asynchronous updating)。一般情况下,参数服务器数目远少于工作机器,导致参数服务器端极易成为网络瓶颈。
- 去中心化分布式
embedding 场景下架构模式选择: 参数服务器适合的是高纬稀疏模型训练,它利用的是维度稀疏的特点,每次 pull or push 只更新有效的值。但是深度学习模型是典型的dense场景,embedding做的就是把稀疏变成稠密。所以这种 pull or push 的不太适合。而网络通信上更优化的 all-reduce 适合中等规模的深度学习。又比如由于推荐搜索领域模型的 Embedding 层规模庞大以及训练数据样本长度不固定等原因,导致容易出现显存不足和卡间同步时间耗费等问题,所以 all-reduce 架构很少被用于搜索推荐领域。
代码示例
数据并行可以直接使用pytroch DataParallel或DistributedDataParallel,模型并行示例代码
import torch
import torch.nn as nn
class SimpleModel(nn.Module):
def __init__(self):
super(SimpleModel,self).__init__()
self.layer1 == nn.Linear(10,20).to('cuda:0')
self.layer2 == nn.Linear(20,1).to('cuda:1')
def forward(self,x):
# 第一层在0号卡上的运行
x1 = x.to('cuda:0')
x1 = self.layer1(x1)
# 将第一层输出移动到1号卡,并在1号卡上执行第二层计算
x2 = x1.to('cuda:1')
x2 = self.layer2(x2)
return x2
model = SimpleModel() # 创建模型示例
input_data = torch.randn(64,10)
output_data = model(input_data)
print(output_data,shape)
张量并行
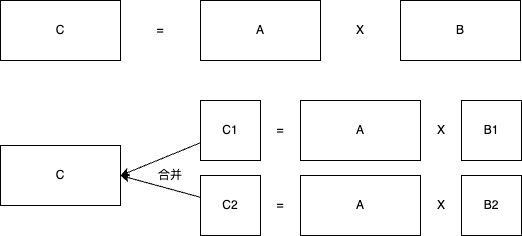
import torch
import torch.nn as nn
class TensorParallelModel(nn.Module):
def __init__(self,input_size,output_size):
super(TensorParallelModel,self).__init__()
self.input_size = input_size
self.output_size = output_size
self.linear == nn.Linear(input_size,output_size).to('cuda:0')
def forward(self,x):
# 将输入数据切分为两个子张量,分别将x1、x2置于不同的设备上
split_size = x.shape[0] // 2
x1,x2 = x[:split_size].to('cuda:0'), x[split_size:].to('cuda:1')
# 将模型权重和偏差复制到第二个设备
linear2 = self.linear.to('cuda:1')
# 在两个设备上并行计算线性层
y1 = self.linear(x1)
y2 = linear2(x2)
# 合并计算结果并返回
y = torch.cat([y1.to('cuda:1'),y2],dim=0)
return y
model = TensorParallelModel(10,20) # 创建模型示例
input_data = torch.randn(64,10)
output_data = model(input_data)
print(output_data,shape)
框架
阿里云机器学习平台大模型训练框架 EPLEPL(EasyParallelLibrary) 是一个统一多种并行策略、易用的分布式深度学习训练框架,它将不同的并行策略进行了统一抽象。在一套分布式训练框架中,支持多种并行策略,包括数据并行、流水并行和算子拆分并行,并支持不同策略的组合和嵌套使用。同时 EPL 提供了灵活应用的接口,用户只需要添加几行代码就可以实现丰富的并行化策略。模型侧不需要去做任何的代码改动。除了用户手动标记并行策略之外,EPL 也支持自动的并行策略探索,包括自动的算子拆分策略以及流水并行中的自动 layer 切分策略等等。EPL 在框架层面也提供了全方位的优化,包括多维度的显存优化、计算优化、通信优化等,从而实现高效的分布式训练性能。
巨型AI模型背后的分布式训练技术(二)DP,TP,PP,Sharding, Offload,这么多的分布式优化技术,需要怎么用?
Galvatron项目原作解读:大模型分布式训练神器,一键实现高效自动并行稠密大模型拥有着动辄数十亿、百亿甚至万亿规模的参数量,面临高昂的计算、存储、以及通信成本,为 AI 基础设施带来了巨大的挑战。人们研发了很多工具(如 Megatron、DeepSpeed、FairSeq 等)来实现如数据并行、张量模型并行、流水并行、分片数据并行等各种并行范式。但这种粗粒度的封装逐渐难以满足用户对系统效率和可用性的需要。如何通过系统化、自动化的方式实现大模型分布式训练,已经成为了当前 MLSys 领域最为重要的问题之一。最近已经有一些系统开始提及“自动并行”的概念,但它们大部分都还停留在对 API 和算子进行工程上的封装,仍然依赖用户人工反复尝试或系统专家经验才能完成部署,并没有从根本上解决自动并行难题。近日,北大河图团队提出了一套面向大模型的自动并行分布式训练系统 Galvatron,相比于现有工作在多样性、复杂性、实用性方面均具有显著优势,性能显著优于现有解决方案。
目前,流水线并行(PP)和张量(TP)并行需要进行架构更改和/或调整模型的前向传播过程。此外,由于Transformers库为每个模型实现了数十种特性,这使得对其进行集成变得非常复杂。如果确实需要流水线并行和张量并行,那么目前最好的选择是使用Megatron-LM,并专注于他们支持的模型(如BERT、GPT-2、T5、Llama)。
存储
分布式训练所需的数据集通常占用的存储空间都很大,如果为每个计算节点都配备一个足够大的存储单元来存放完整数据集的副本,其成本将及其高昂,也使得数据集的管理、更新和同步十分复杂和耗时。所以在构建集群时通常会构建一个独立的大规模存储系统,存储系统上的数据对每个计算节点都可见,减少不必要的数据拷贝和同步的开销,同时存储系统的搭建还需要考虑AI分布式计算在I/O负载方面一些不同的特性,比如数据以大量的小文件读为主,数据请求频率高,并发量大等问题。
因为现在的语言模型,核心是把整个世界的数据压进模型里面,那模型就被搞得很大,几百 GB 的样子。在运行的时候,它的中间变量也很大,所以它就需要很多的内存。现在我们可以做到一个芯片里面封装近 192 GB 的内存。下一代带宽会更高一点。但这个东西目前已经被认为是一个瓶颈了。这是因为内存占面积 —— 一个芯片就那么大,划一块给算力,划一块给内存之后就放不下什么东西了。所以很有可能在未来几年之内,一个芯片就 200GB 内存,可能就走不动了。这个要看工艺有没有突破。
通信技术
对于模型训练来说,不管是哪一种并行策略其本质上包括将模型进行“纵向”或“横向”的切分,然后将单独切分出来的放在不同的机器上进行计算,来充分的利用计算资源。在现在的 AI 框架中,通常都是采取的多种策略的混合并行来加速模型训练的。而要支持这种多种并行策略的训练模型,就需要涉及不同“切分”的模型部分如何通信。除此以外,在分布式的模型训练中,由于模型的切分我们也需要将模型参数放在不同模型部分所在的机器上,在训练过程中我们会涉及到不同模型节点参数的交互和同步,那也需要跨节点的同步数据和参数。PS:切分后需要通信,参数多副本也需要通信来同步。
训练框架面临的是 单机CPU与GPU 之间、单机多GPU之间、多机CPU 之间、多机GPU 之间的通信问题,有各种优化方案,但要对上层提供统一通信接口,并进一步结合机器学习的特点提供 collective Communication 接口。
AI分布式集群中计算节点之间通常使用InfiniBand或Myrinet等高性能网络互连和通信,每个计算节点内的多个加速卡(比如GPU、TPU、NPU等)通过PCI-E进行通信。在一个完整AI分布式训练过程中包两个链路的数据传输:训练数据从磁盘到主机内存、加速卡存储的I/O网络链路,训练参数在节点内不同加速卡和不同节点上的传输的参数传输链路,所以分布式训练通常包含多种不同的通信协议和技术的混合应用。
- 机器内通信:高效的数据通信需要选择合适的通信协议和网络拓扑,并且需要根据任务特性进行优化,以减少通信开销引入的系统延迟。以CPU+GPU的异构集群为例,节点与节点之间是高性能网络通信,节点内CPU和CPU之间是通过总线共享内存、CPU和GPU之间则通过PCI-E总线通信、GPU与GPU之间通过NVLink直连模式通信等。
- 机器间通信。在多节点网络通信中,传统的以太网通常采用TCP/IP协议进行网络通信,数据发送方把原始的数据分割成以Packet为单位的数据包,每个数据包在发送前要先经过TCP协议、IP协议、UDP协议等多层网络协议处理和封装后再交由物理层进行数据发送,接收方从网络中接收到数据包后需要经过对应的多层网络协议解析后才能获取到原始的数据包。远程直接内存访问(Remote Direct Memory Access, RDMA)是一种高性能低延迟的网络通信方案,它可以通过网络把数据直接传入计算机的存储单元中,数据的封装、搬运和解析都是由硬件直接完成不需要CPU和操作系统的参与。相比于传统TCP/IP网络通信,RDMA在执行数据读写请求时数据直接从应用程序发送到本地网卡缓冲区,数据发送过程不需要CPU进行额外的处理,本地网卡获取到数据后通过网络传送到目标网卡,目标网卡在确认接收到数据后直接将其写入到应用程序的缓存中。RDMA实现了一个虚拟的I/O通道,应用程序可通过RDMA方式直接对远程虚拟内存进行zero copy的读写,大幅降低了网络通信的延迟和CPU的负载。
英伟达的网络连接主要有两种,实现卡间互联的 NVLinks,实现服务器间互联的 Infiniband。虽然从以太网技术本身来讲,想超过 Infiniband 很难,但 infiniband 体系封闭,成本高昂。AI Infra 现状:一边追求 10 万卡 GPU 集群,一边用网络榨取算力 在LLM训练集群中,网络架构被结构化为前端和后端组件(见图3)。前端网络处理各种流量,如作业管理、模型推理和存储活动,而后端网络专门用于训练过程中产生的大量流量。我们在优化LLM训练的主要关注点在于提高后端网络的性能和效率,以便将AI加速器扩展到数万个。
硬件和协议层
360智算中心:万卡GPU集群落地实践 对网络这块有一些直观描述和图。
TCP vs RDMA
海思专家如何看待RDMA技术? 比较好的一篇文章
DMA全称为Direct Memory Access,即直接内存访问。是一种外设绕开CPU独立直接访问内存的机制。
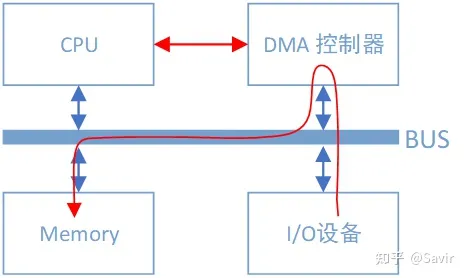
CPU的最主要工作是计算,而不是进行数据复制。可以看到总线上又挂了一个DMA控制器,它是专门用来读写内存的设备。有了它以后,当我们的网卡想要从内存中拷贝数据时,除了一些必要的控制命令外,整个数据复制过程都是由DMA控制器完成的。过程跟CPU复制是一样的,只不过这次是把内存中的数据通过总线复制到DMA控制器内部的寄存器中,再复制到I/O设备的存储空间中。CPU除了关注一下这个过程的开始和结束以外,其他时间可以去做其他事情,不需要消耗CPU的处理能力。DMA控制器一般是和I/O设备在一起的,也就是说一块网卡中既有负责数据收发的模块,也有DMA模块。
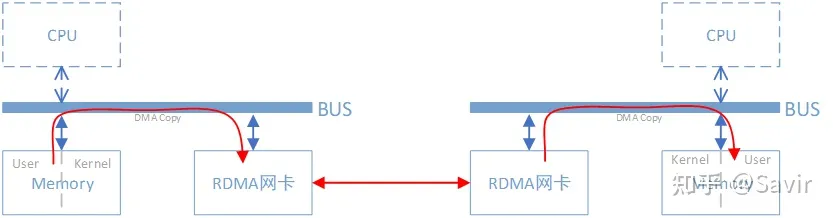
rdma 即remote dma。同样是把本端内存中的一段数据,复制到对端内存中,在使用了RDMA技术时,两端的CPU几乎不用参与数据传输过程(只参与控制面)。本端的网卡直接从内存的用户空间DMA拷贝数据到内部存储空间,然后硬件进行各层报文的组装后,通过物理链路发送到对端网卡。对端的RDMA网卡收到数据后,剥离各层报文头和校验码,通过DMA将数据直接拷贝到用户空间内存中。PS:RDMA 网卡一般很贵。
RDMA本身指的是一种技术,具体协议层面,包含Infiniband(IB),RDMA over Converged Ethernet(RoCE)和internet Wide Area RDMA Protocol(iWARP)。三种协议都符合RDMA标准,使用相同的上层接口,在不同层次上有一些差别。上述几种协议都需要专门的硬件(网卡)支持。
- Infiniband规定了一整套完整的链路层到传输层(非传统OSI七层模型的传输层,而是位于其之上)规范,但是其无法兼容现有以太网,除了需要支持IB的网卡之外,企业如果想部署的话还要重新购买配套的交换设备。
- RoCE从英文全称就可以看出它是基于以太网链路层的协议,v1版本网络层仍然使用了IB规范,而v2使用了UDP+IP作为网络层,使得数据包也可以被路由。
- iWARP协议是IETF基于TCP提出的
| tcp/ip | rdma | |
|---|---|---|
| 硬件 | 以太网卡 | RDMA 网卡 |
| 驱动 | rdma-core | |
| 接口 | socket | libibverbs |
在多节点网络通信中,传统的以太网通常采用TCP/IP协议进行网络通信,数据发送方把原始的数据分割成以Packet为单位的数据包,每个数据包在发送前要先经过TCP协议、IP协议、UDP协议等多层网络协议处理和封装后再交由物理层进行数据发送,接收方从网络中接收到数据包后需要经过对应的多层网络协议解析后才能获取到原始的数据包。在这个过程数据需要消耗CPU资源进行多次数据拷贝和网络协议处理,因而会引入一定的延迟。由于AI分布式训练对网络的吞吐量和延迟都有比较高的要求,所以需要有更高效的通信协议和通信方式来降低网络的通信延迟。远程直接内存访问(Remote Direct Memory Access, RDMA)是一种高性能低延迟的网络通信方案,它可以通过网络把数据直接传入计算机的存储单元中,数据的封装、搬运和解析都是由硬件直接完成不需要CPU和操作系统的参与。相比于传统TCP/IP网络通信,RDMA在执行数据读写请求时数据直接从应用程序发送到本地网卡缓冲区,数据发送过程不需要CPU进行额外的处理,本地网卡获取到数据后通过网络传送到目标网卡,目标网卡在确认接收到数据后直接将其写入到应用程序的缓存中。RDMA实现了一个虚拟的I/O通道,应用程序可通过RDMA方式直接对远程虚拟内存进行zero copy的读写,大幅降低了网络通信的延迟和CPU的负载。
系列解读SMC-R:透明无感提升云上TCP应用网络性能Shared Memory Communication over RDMA (SMC-R) 是一种基于 RDMA 技术、兼容 socket 接口的内核网络协议,由 IBM 提出并在 2017 年贡献至 Linux 内核。SMC-R 能够帮助 TCP 网络应用程序透明使用 RDMA,获得高带宽、低时延的网络通信服务。
基于阿里云 eRDMA 的 GPU 实例如何大幅提升多机训练性能eRDMA 技术由阿里云在 2021 年云栖大会发布,与 RDMA 生态完全兼容。
- 在服务器节点间的数据通信过程中,CPU 仅负责指定 RDMA 通信的源及目的物理地址,并触发通信动作,其余工作全部由物理网卡上的 DMA 引擎负责完成。相比传统的 TCP 通信,近端及远端的物理网卡通过协作可以直接将本地的内存数据写入远端的内存地址空间,或从远端的物理内存空间读取数据到本地内存,待数据传输全部完成后,再通知 CPU 进行下一步动作,将数据传输和计算分开,从而实现高效的并行计算处理。
- DMA 引擎同样可以对设备地址进行直接访问。在异构计算的应用场景中,服务器节点间同步的不仅是内存的数据,还有 GPU 显存的数据。GDR 便是为了实现物理绑卡在服务节点间直接搬移 GPU 显存的数据而实现。为了支持该功能,NVIDIA 的 GPU 驱动提供了一套标准接口,用于获取应用层申请的显存对应的物理地址。物理网卡可以使用这一物理地址完成 DMA 的直接访问。
- eRDMA 基于阿里云的 VPC 网络,因此不论是纯粹的 CPU 服务器还 GPU 服务器,均可以通过添加 eRDMA 设备激活 eRDMA 功能。在神龙底层的实现上,它由神龙 CIPU 模拟出 VirtIO 网卡设备和 ERI 设备,通过神龙的虚拟化层分配给弹性服务器。在用户视角有两个设备,分别为 VirtIO 和 ERI,底层物理设备的访问对用户完全透明,用户仅需要安装阿里云提供的 eRDMA 驱动即可使用。
RDMA数据收发
深入理解 RDMA 的软硬件交互机制RDMA (Remote Direct Memory Access) 技术全称远程直接内存访问,是为了解决网络传输中服务器端数据处理的延迟而产生的。RDMA通过网络将数据从一个系统快速移动到另一个系统中,而不需要消耗计算机的处理能力。它消除了内存拷贝和上下文切换的开销,因而能解放内存带宽和 CPU 周期用于提升系统的整体性能。先看看最常见的 Kernel TCP,其收数据的流程主要要经过以下阶段:
- 网卡驱动从内核分配 dma buffer,填入收队列
- 网卡收到数据包,发起 DMA,写入收队列中的 dma buffer
- 网卡产生中断
- 网卡驱动查看收队列,取出 dma buffer,交给协议栈
- 协议栈处理报文
- 操作系统通知用户态程序有可读事件
- 用户态程序准备 buffer,发起系统调用
- 内核拷贝数据至用户态程序的 buffer 中
- 系统调用结束
可以发现,上述流程有三次上下文切换(中断上下文切换、用户态与内核态上下文切换),有一次内存拷贝。虽然内核有一些优化手段,比如通过 NAPI 机制减少中断数量,但是在高性能场景下, Kernel TCP 的延迟和吞吐的表现依然不佳。使用 RDMA 技术后,收数据的主要流程变为(以send/recv为例):
- 用户态程序分配 buffer,填入收队列
- 网卡收到数据包,发起 DMA,写入收队列中的 buffer
- 网卡产生完成事件(可以不产生中断)
- 用户态程序 polling 完成事件
- 用户态程序处理 buffer
上述流程没有上下文切换,没有数据拷贝,没有协议栈的处理逻辑(卸载到了RDMA网卡内),也没有内核的参与。CPU 可以专注处理数据和业务逻辑,不用花大量的 cycles 去处理协议栈和内存拷贝。从上述分析可以看出,RDMA 和传统的内核协议栈是完全独立的,且由于 RDMA 要直接让硬件读写用户态程序的内存,这带来了很多问题:
- 安全问题:用户态程序能否利用网卡读写任意物理内存?不能,RDMA 通过 PD 和 MR 机制做了严格的内存保护。
- 地址映射问题:用户态程序使用的是虚拟地址,实际的物理地址是操作系统管理的。网卡怎么知道虚拟地址和物理地址的映射关系?驱动会告诉网卡映射关系,后续数据流中,网卡自己转换。
- 地址映射会变化:操作系统可能会对内存做 swap、压缩,操作系统还有一些复杂的机制,比如 Copy-On-Write。这些情况下,怎么保证网卡访问的地址的正确性?通过驱动调用 pin_user_pages_fast 保障。另外,用户态驱动会给注册的内存打上 DONT_FORK 的标志,避免 Copy-On-Write 发生。
RDMA 的软硬交换的基础单元是 Work Queue。Work Queue 是一个单生产者单消费者的环形队列。Work Queue 根据功能不同,主要分为 SQ(发送)、RQ(接收)、CQ(完成)和 EQ(事件)等。
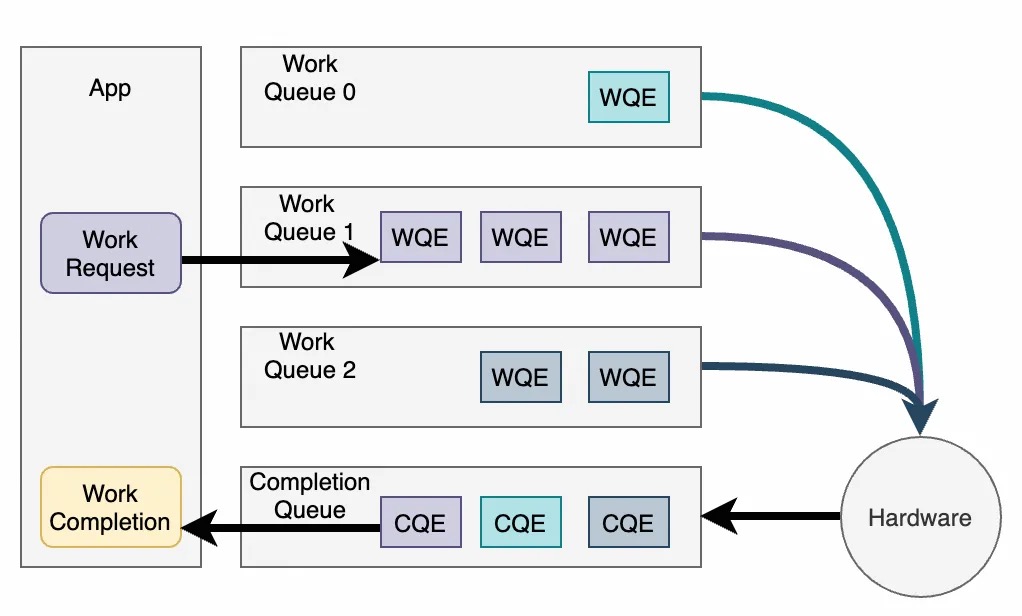
发送一个 RDMA 请求的大致流程为:
- 软件构造 WQE (Work Queue Element),提交至 Work Queue 中
- 软件写 Doorbell 通知硬件
- 硬件拉取 WQE,处理 WQE
- 硬件处理完成,产生 CQE,写入 CQ
- 硬件产生中断(可选)
- 软件 Polling CQ
- 软件读取硬件更新后的 CQE,得知 WQE 完成
上述流程没有上下文切换,没有数据拷贝,没有协议栈的处理逻辑(卸载到了RDMA网卡内),也没有内核的参与。CPU 可以专注处理数据和业务逻辑,不用花大量的 cycles 去处理协议栈和内存拷贝。深入理解 RDMA 的软硬件交互机制
RDMA 和传统的内核协议栈是完全独立的,因此其软件架构也与内核协议栈很不一样,包含以下部分:
- 用户态驱动(libibverbs、libmlx5等)
- 内核态IB软件栈:内核态的一层抽象,对应用提供统一的接口。这些接口不仅用户态可以调用,内核态也可以调用。
- 内核态驱动:各个厂商实现的网卡驱动,直接和硬件交互。 由于 RDMA 要直接让硬件读写用户态程序的内存,这带来了很多问题:
- 安全问题:用户态程序能否利用网卡读写任意物理内存?
- 地址映射问题:用户态程序使用的是虚拟地址,实际的物理地址是操作系统管理的。网卡怎么知道虚拟地址和物理地址的映射关系?
- 地址映射会变化:操作系统可能会对内存做 swap、压缩,操作系统还有一些复杂的机制,比如 Copy-On-Write。这些情况下,怎么保证网卡访问的地址的正确性?
GPU 卡间通信
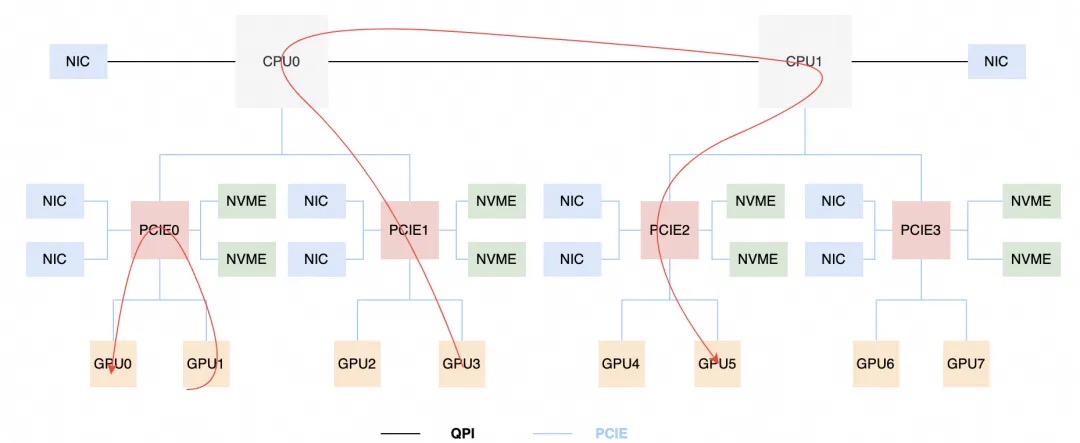
AI大模型时代的RDMA网络杂谈GPU机内通讯技术:PCIe是机内通讯最重要的组件之一,它采用的是树状拓扑结构,在这个体系结构中,CPU和内存是核心,GPU、NIC、NVMe等都是外设,NIC、NVME、GPU是共享一个PCIE的总带宽的。如下图所示。
然而,在深度学习时代,这一范式改变了,GPU成为了计算的核心,CPU反而只扮演的控制的角色,如下图所示。
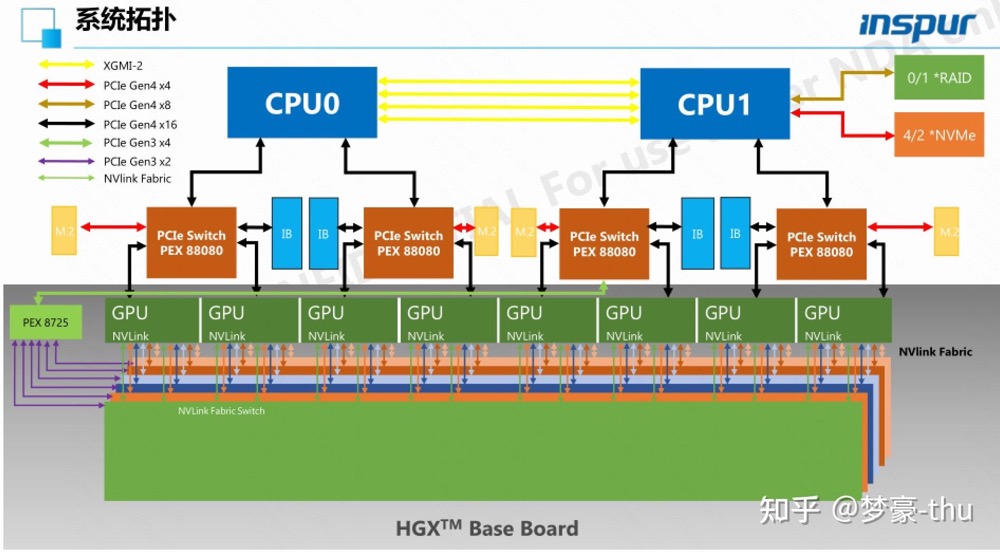
在机器内部的GPU-GPU之间,如果通讯仍然走PCIe/QPI/UPI等时,那往往会成为瓶颈;因此,NVIDIA专门提出了NVLink、NVSwitch等新的机内通讯元件,可以为同一机器的GPU之间提供几百Gbps甚至上Tbps的互联带宽。但是虽然GPU之间绕过了PCIE网卡的限制,但是GPU之间的通信能力,取决于NVLink的数量。如图所示GPU0-GPU6只有1条NVLink,GPU3-GPU5之间有2条。在Ampere架构之后,Nvidia引入了NVSwitch,使单个机器内任何GPU卡之间的带宽链路获得了一致性。可以看到,如果GPU需要使用PCIE方式去读区其他GPU上的数据,必然数据传输速度收到了PCIE的影响。从物理架构层面受到PCIE链接带宽限制,AI任务调度方面要尽可能让任务调度到NVLink的关联GPU上。这也是为什么客户AI任务需要了解底层GPU拓扑架构,不同的架构也需要适配不同的算力调度分配。
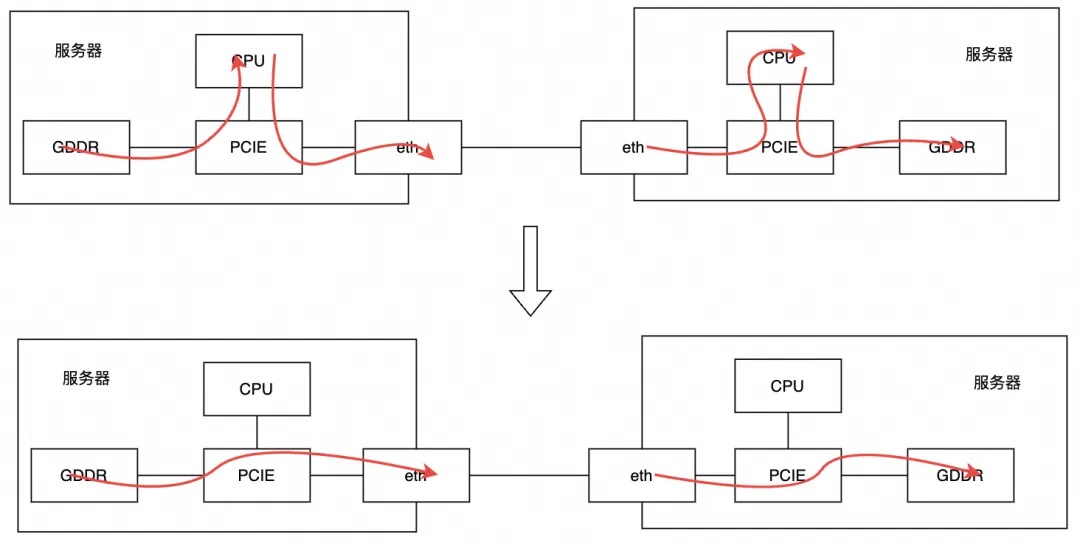
在机器之间,GPU间的通讯需要经过NIC,在没有PCIe Switch的情况下,GPU-NIC之间的通讯需要经过RC,并且会使用CPU做一次拷贝和中转,往往会成为瓶颈;为此,NVIDIA又搞出了GPU Direct RDMA(GDR)技术,它使一台计算机能够直接访问另一台计算机的内存,而无需操作系统内核或CPU的干预。
那么,一个自然的问题就是,如何判断GPU之间是的连接方式呢?NVIDIA当然想得非常周到了,提供了nvidia-smi topo -m的命令,可以查看机内的连接方式。然而,值得注意的是,并非所有机器都会组装NVLink、NVSwitch、PCIe Switch等,毕竟这都是成本。所以,在给定机型下的GPU通讯性能最优、到底开不开GDR、PCIe参数到底怎么设置都需要根据具体机型和具体通信模式而具体分析了。最好的方式还是在购买GPU服务器和搭建物理网络时,就结合模型特点和实现方式,设计好GPU服务器的GPU-GPU、GPU-NIC等机内互联和NIC-交换机-NIC的网络互联,这样才能不至于在任何一个地方过早出现瓶颈,导致昂贵GPU算力资源的浪费。
大模型要利用分布式的GPU算力,通讯库是关键环节之一。通讯库向上提供API供训练框架调用,向下连接机内机间的GPU以完成模型参数的高效传输。目前业界应用最为广泛的是NVIDIA提供的NCCL开源通讯库,各个大厂基本都基于NCCL或NCCL的改造版本作为GPU通讯的底座。NCCL是一个专门为多GPU之间提供集合通讯的通讯库,或者说是一个多GPU卡通讯的框架 ,它具有一定程度拓扑感知的能力,提供了包括AllReduce、Broadcast、Reduce、AllGather、ReduceScatter等集合通讯API,也支持用户去使用ncclSend()、ncclRecv()来实现各种复杂的点对点通讯,如One-to-all、All-to-one、All-to-all等,在绝大多数情况下都可以通过服务器内的PCIe、NVLink、NVSwitch等和服务器间的RoCEv2、IB、TCP网络实现高带宽和低延迟。
深度学习分布式训练框架 horovod (3) — Horovodrun背后做了什么 Collective communication包含多个sender和多个receiver(相对于P2P 模式只有一个sender和一个receiver),一般的通信原语包括 broadcast,All-to-one (gather),all-gather,One-to-all (scatter),reduce,all-reduce,reduce-scatter,all-to-all等。集合通信库的主要特征是:大体上会遵照 MPI 提供的接口规定,实现了包括点对点通信(SEND,RECV等),集合通信( REDUCE,BROADCAST,ALLREDUCE等)等相关接口,然后根据自己硬件或者是系统的需要,在底层实现上进行了相应的改动,保证接口的稳定和性能。
英伟达发布了一个名叫 GB200 的系统,以前你去数据中心,会看到一个机架柜可以放很多很多刀片服务器。现在换成新的 GPU 之后,一个机架位只能放两台机器。这是因为供电、散热等等一系列的问题。英伟达可以把 72 块卡压缩一个机架位里面。这里面用到了水冷工艺。之前我们其实不太用水冷,因为水冷有很多问题,比如那个阀门没做好就会漏水,整个机架位一漏水就完了。而且水冷对整个基建是有要求的,水要进来要出去。水的好处是可以带走很多热量。现在我们大部分是靠空气吹,但水的密度更高,所以它带走热量的能力更强。所以一旦用到水冷之后,你的算力就可以更密,就可以放更多机器。芯片就可以压得比较扁。压得比较扁的好处就是,每个芯片之间更近了。芯片之间直接用光纤,以光速互通。光速你看上去很快,但实际上在我们眼里已经很慢了。一台机器传输到隔壁一米之外的机器所带来的几纳秒延迟,几乎是不能忍。我们自己去设计机房的时候会考虑光纤的长度,因为一米的差距就会给分布式训练带来一个可见的性能影响。英伟达的 GB200 这个卡就可以把 GPU 都放一起,那么它们之间的通讯会变得更好一些。你可以理解成:之前我们做多核,把单核封装到一个芯片里面,现在是说多核不够,我要做多卡,多卡以前是分布在一个房间里面,现在是多卡也要尽量放在一起,这是一个趋势。还有一个通讯是 GPU 和 CPU 之间的 PCIe,它每几年也在翻倍,但是确实会慢一些。
通信库NCCL
浅析GPU分布式通信技术-PCle、NVLink、NVSwitch在了解硬件之后,实现通信不可或缺的是提供集合通信功能的库。其中,最常用的集合通信库之一是 MPI(Message Passing Interface),在 CPU 上被广泛应用。而在 NVIDIA GPU 上,最常用的集合通信库则是 NCCL(NVIDIA Collective Communications Library)。
在AI分布式训练过程中因为需要在节点内不同AI加速器以及不同节点之间传输网络模型权重参数和临时变量等,在这个过程中涉及多种通信协议和不同网络连接方式的数据传输,它要求用户根据各个厂家的硬件通信接口和通信协议来实现不同的设备之间的数据传输。分布式的通信一般有两大类:
- 点对点通信(Point to point communication, P2P)和集合通信(Collective communication, CC)。P2P通信模式包含一个sender和一个receive,是一对一的数据通信,实现起来也比较简单。
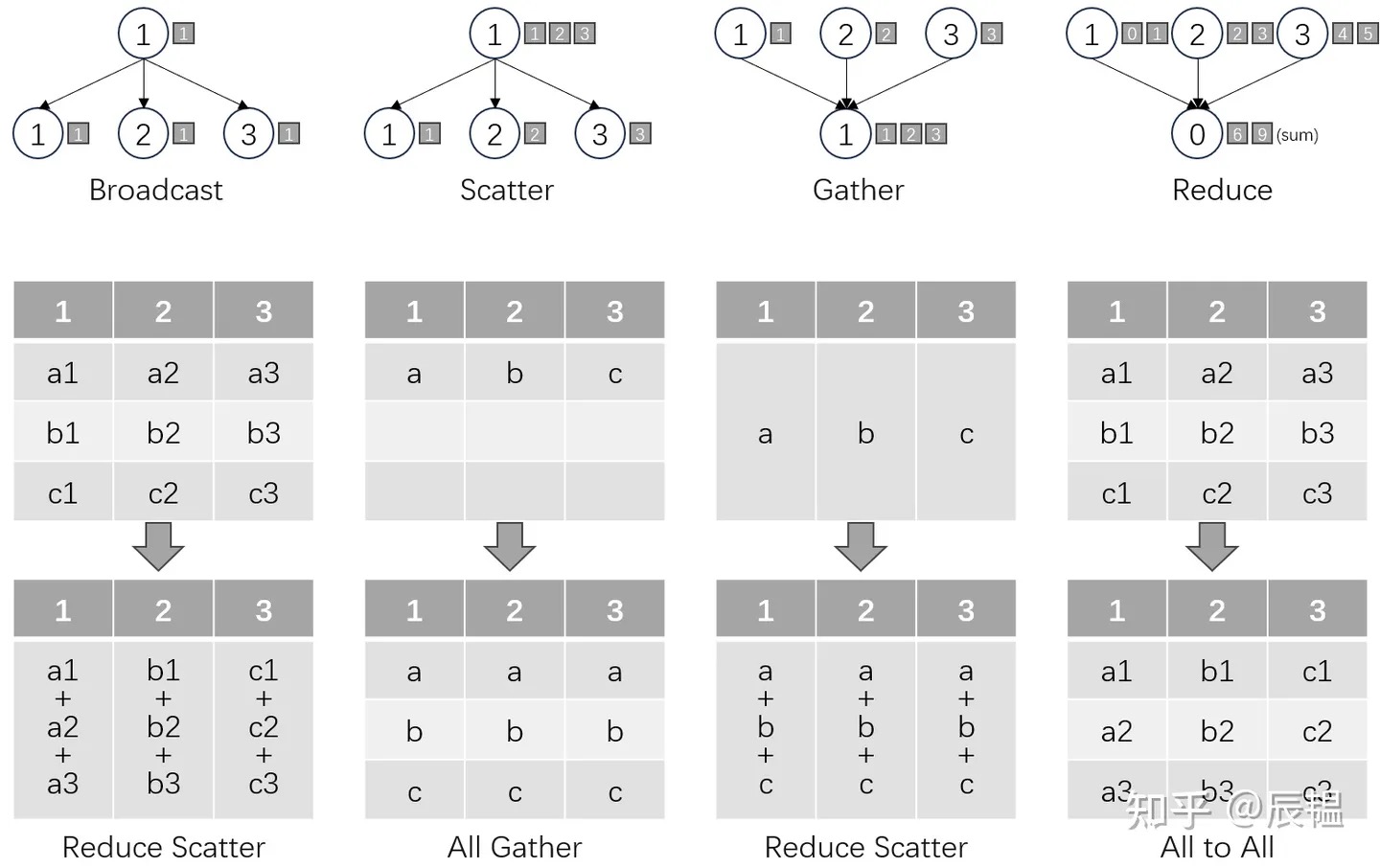
- 集合通信,是一对多或者多对多的数据通信,是一种涉及进程组中所有进程的全局通信操作。通过定义一些比较底层的通信原语操作来实现不同硬件和协议的抽象,常见的通信原语有broadcast、scatter、gather、reduce、reduce-scatter、all-gather、all-reduce、all-to-all等。
分布式集群的网络硬件多种多样,深度学习框架通常不直接操作硬件,而是使用通信库的方式来屏蔽底层硬件的细节。MPI (Massage Passing Interface)是一个消息传递的标准函数库,它提供了丰富的消息传递接口,可用于不同任务之间的通信。NCCL (Nvidia Collective Communication Library)是Nvidia提供的一个集合通信库,可实现跨节点GPU之间的直接数据通信,它在接口形式上与MPI相似,因为是针对自身硬件定制和优化的,所以在Nvidia自家GPU上会有更好的通信表现。
The NVIDIA Collective Communication Library (NCCL) implements multi-GPU and multi-node communication primitives optimized for NVIDIA GPUs and Networking. NCCL provides routines such as all-gather, all-reduce, broadcast, reduce, reduce-scatter as well as point-to-point send and receive that are optimized to achieve high bandwidth and low latency over PCIe and NVLink high-speed interconnects within a node and over NVIDIA Mellanox Network across nodes. Point-to-point communicationOne-to-all (scatter) ,All-to-one (gather) , All-to-all 都可以基于 ncclSend 和 ncclRecv 来实现。
为什么需要NCCL?或者说NCCL 都看了那些活儿?
- communication primitive
- Point-to-point communication,只有一个sender和一个receiver
- Collective communication,包含多个sender多个receiver,一般的通信原语包括broadcast,gather,all-gather,scatter,reduce,all-reduce,reduce-scatter,all-to-all等。
- ring-base collectives,传统Collective communication假设通信节点组成的topology是一颗fat tree,但实际的通信topology可能比较复杂,并不是一个fat tree。因此一般用ring-based Collective communication。将所有的通信节点通过首尾连接形成一个单向环,数据在环上依次传输。以broadcast为例, 假设有4个GPU,GPU0为sender将信息发送给剩下的GPU
- 按照环的方式依次传输,GPU0–>GPU1–>GPU2–>GPU3,若数据量为N,带宽为B,整个传输时间为
(K-1)N/B。时间随着节点数线性增长,不是很高效。 - 把要传输的数据分成S份,每次只传N/S的数据量,GPU1接收到GPU0的一份数据后,也接着传到环的下个节点,这样以此类推,最后花的时间为
S*(N/S/B) + (k-2)*(N/S/B) = N(S+K-2)/(SB) --> N/B,条件是S远大于K,即数据的份数大于节点数,这个很容易满足。所以通信时间不随节点数的增加而增加,只和数据总量以及带宽有关。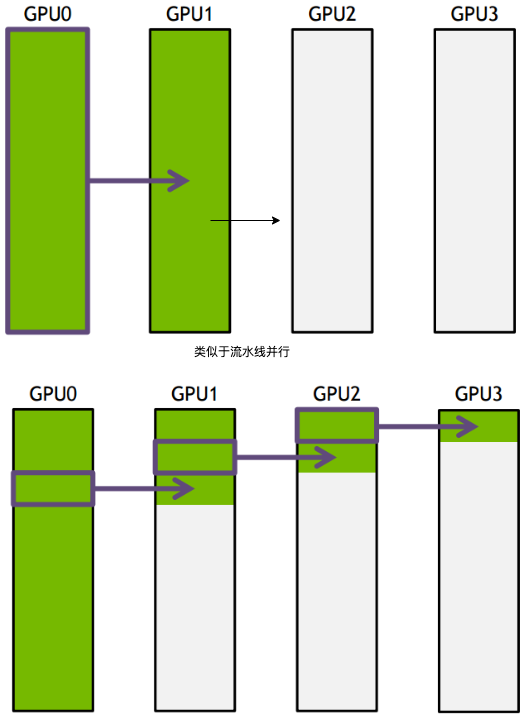
- 那么在以GPU为通信节点的场景下,怎么构建通信环呢?
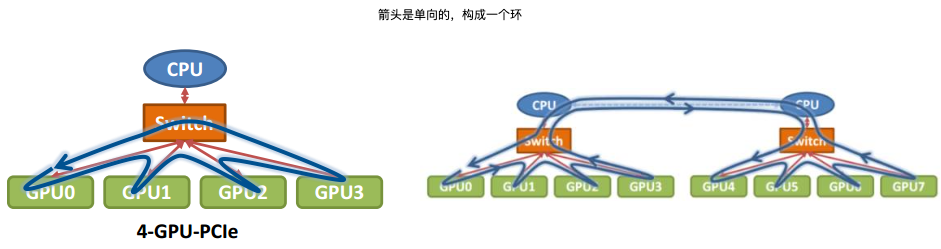
- 按照环的方式依次传输,GPU0–>GPU1–>GPU2–>GPU3,若数据量为N,带宽为B,整个传输时间为
- NCCL在单机多卡上以及多机多卡实现:单机内多卡通过PCIe以及CPU socket通信,多机通过InfiniBand通信。
// nccl/src/nccl.h.in
ncclResult_t ncclGroupStart();
ncclResult_t ncclGroupEnd();
// peer to peer
ncclResult_t ncclSend(const void* sendbuff, size_t count, ncclDataType_t datatype, int peer,ncclComm_t comm, cudaStream_t stream);
ncclResult_t ncclRecv(void* recvbuff, size_t count, ncclDataType_t datatype, int peer,ncclComm_t comm, cudaStream_t stream);
// Collective Communication
ncclResult_t ncclAllGather(const void* sendbuff, void* recvbuff, size_t sendcount,ncclDataType_t datatype, ncclComm_t comm, cudaStream_t stream);
ncclResult_t ncclReduceScatter(const void* sendbuff, void* recvbuff,size_t recvcount, ncclDataType_t datatype, ncclRedOp_t op, ncclComm_t comm,cudaStream_t stream);
...
// 初始化
ncclResult_t ncclCommInitAll(ncclComm_t* comm, int ndev, const int* devlist);
struct ncclComm {
struct ncclChannel channels[MAXCHANNELS];
...
// Bitmasks for ncclTransportP2pSetup
int connect;
uint32_t* connectSend;
uint32_t* connectRecv;
int rank; // my rank in the communicator
int nRanks; // number of GPUs in communicator
int cudaDev; // my cuda device index
int64_t busId; // my PCI bus ID in int format
int node;
int nNodes;
int localRanks;
// Intra-process sync
int intraRank;
int intraRanks;
int* intraBarrier;
int intraPhase;
....
};
其它
- NCCL 最初只支持单机多 GPU 通信,从 NCCL2 开始支持多机多 GPU 通信。
- Gloo是facebook开源的用于机器学习任务中的集合通信库. It comes with a number of collective algorithms useful for machine learning applications. These include a barrier, broadcast, and allreduce. Gloo 为CPU和GPU提供了集合通信程序的优化实现。但如果是在使用NVIDIA-硬件的情况下,主流的选择是NVIDIA自家的NCCL。
- 利用多 GPU 加速深度学习模型训练多机软件设计一般采用 MPI(Message Passing Interface)实现数据交互。MPI 是一种消息传递库接口描述标准,规定了点对点消息传递、协作通信、组和通讯员概念、进程拓扑、环境管理等各项内容,支持 C 和 Fortran 语言。NCCL 出现得更晚一些,参考并兼容了 MPI 已有 API。NCCL 更多考虑了 GPU 的特性,例如任意两块 GPU 之间的通信开销是有区别的,跨 QPI 情况与同一 PCIe Switch 情况,以及有 NVLink/ 无 NVLink 情况就有明显差异,但 MPI 认为两种情况下 GPU 与 GPU 都是等同的,甚至 MPI 认为跨机器的 GPU 也是等同的,这对于多 GPU 通信效率会有影响。MPI 可以和 NCCL 结合,实现层次化的并行通信机制,即同一台机器上的不同 GPU 之间采用 NCCL 通信,而不同机器上的 GPU 之间采用 MPI 辅助通信。NCCL and MPI
体现在pytorch上, PyTorch 通过torch.distributed模块实现分布式计算,而 NCCL 是该模块支持的通信后端之一
import torch.distributed as dist
# 配置主进程地址和端口(多机训练需指定主节点IP)
os.environ["MASTER_ADDR"] = "localhost"
os.environ["MASTER_PORT"] = "12355"
# 初始化分布式环境:指定后端为NCCL
dist.init_process_group(backend, rank=rank, world_size=world_size)
# 每个GPU创建一个张量
tensor = torch.tensor([rank + 1.0], device=f"cuda:{rank}")
print(f"Rank {rank} 初始张量: {tensor}")
# 使用NCCL进行all-reduce(求和)
dist.all_reduce(tensor, op=dist.ReduceOp.SUM)
print(f"Rank {rank} 同步后张量: {tensor}") # 结果应为 [3.0](2个GPU时 1+2=3)
资源调度
在千卡集群下训练的难点分为两方面,AI Infra 和 Training Framework。
- AI Infra 方面:千卡训练多久挂一次,挂了之后咋弄,有效训练时间是多长。
- 网络通信训练中断 trade off Checkpoint;掉卡,会预留一部分GPU当作 Backup;存储挂载异常。网络、GPU和存储这三方面的问题都会导致训练中断或者出现异常,所以需要结合 K8S 那一套整个自动监控系统,然后自动剔除异常节点等等一些操作。
- 对于 Training Framework 方面,可以做的就是怎么更快更节省的训练大模型:提升大模型训练的速度和降低训练大模型需要的GPU个数。要么较少的卡久一点能把模型训起来,或者让训练加速(像 FlashAttention2),比如提前个 10 天训完。
- 还有一点很重要的是 Dataset,模型训练参数上来之后,数据量(Token 量)也得跟上才行。
Kubernetes 设计之初目标支撑的主要场景是无状态类工作负载(比如 Web 应用和微服务),后来随着系统稳定性和存储卷管理能力的增强,很多有状态类负载也被跑在 Kubernetes 上,比如数据库、分布式中间件等。到这里,Kubernetes 的核心架构都还没有碰到特别大的挑战。明显的变化发生在 AI 时代,尤其以深度学习为代表的 AI 任务,与以 Spark 批和 Flink 流为代表的大数据处理任务,被大家尝试运行在 Kubernetes 集群上。而在 GPU 管理和推理方面,大家首先要面对的也是最大的一个问题,就是调度和资源管理。
- 在资源调度方面,Kubernetes 需要能够针对各类异构设备的体系结构、软硬件协同手段和设备间的约束(共享、隔离、连接等),通过资源调度,最大化集群整体资源利用率。
- 任务级调度方面,Kubernetes 需要能够从面向单个 Pod 的调度,扩展到面向一组 Pods 的调度,满足 Pods 间的各种依赖、关联和约束,提升任务整体效率。Scheduler-framework 架构,就是 Kubernetes 调度管理 AI 任务的关键改进之一。本质上,需要 Kubernetes 能够高效支撑一个大规模的任务系统。从架构上,除了调度器(batch scheduler)和任务对象的生命周期控制器(job controller),还缺少重要的一个组件——任务队列(job queue)。
- 另外,AI 任务是典型的数据密集型负载,且需要 GPU 此类高性能计算资源支撑。而在存算分离架构下,必然要管理和优化计算任务使用数据的效率问题。CNCF 社区内已经有项目在着手填补这里的能力空白,比如 Fluid 提供面向 AI/ 大数据任务的弹性 Dataset 管理、调度和访问加速,最大化降低 Data IO 对 GPU 计算效率的影响。
- 在训练过程中,辅助的监控和运维系统的建设并不是特别完善。尤其是在大规模训练时,如何监控 GPU 的功率并准确判断用户的任务是停止了还是仍在训练中,仍是一个挑战。举个例子,如果用户在训练模型时,发现模型训练框架在运行过程中突然停掉了,然而,使用传统的 CPU 或 GPU 监控方案并不能有效检测到这种情况。这里可能有一个关键指标,即 GPU 的功率。当 GPU 的功率下降时,意味着任务已经停止。在这种情况下,当任务停止后,如何快速启动新任务以加速训练进程?这表明在大规模训练过程中,监控和运维系统的改进空间依然很大。
- 此外,在 GPU 虚拟化方面,目前已有一些成熟的方案,如 QGPU、VGPU、 mGPU和cGPU。然而,在 GPU 应用场景下,很少有关于 GPU 利用率的数据出现。在 CPU 利用率方面,业界通常会提到 60% 或 80% 的利用率,但对于 GPU 利用率,什么情况下算是完全压榨了 GPU 的性能,几乎没有相应的讨论和说明。这表明在这一领域的问题仍未得到充分解决,并且缺乏完整的行业解决方案。往后看的话,一旦LLM这个事情有一定冷却,有更多的实际业务场景落地并进入商业化阶段,GPU 利用率就会成为这些公司最重要的事情之一。大家就会关注在 GPU 场景下,怎么去做大规模算力的支撑,怎么去优化网络、存储和并行计算架构的高效使用,这也会成为整个容器或云原生应用未来探索的方向。而且它会带来大量的岗位和职业,也会给企业带来大量的利润。
优化手段

关于深度的分布式训练,主要工作主从技术栈上呈现从浅层到深层的一个过程。
- 前三类的优化基本上是处于框架层,需要平台为用户提供基础的框架支持。比如说在计算图的并行化策略方面,我们通过GSPMD和GPipe提供了包括数据并行、模型并行和流水线并行的通用化的并行化策略的抽象层。此外,我们通过DeepSpeed来做支持,用ZeRO (Zero Redundancy Optimizer)来优化Optimizer的显存使用,以及我们可以用低精度的压缩来加速参数的同步
-
集合通信层的一些优化,这类优化对于用户跟上层的框架完全透明,不需要改动上层的代码就能够真正落地。拿网络的协议站做一个类比的话,NCCL基本上跟IP协议一样,是整个协议栈的narrow waist的位置。Fast Socket:NCCL的高性能网络栈 提到了对NCCL 本身的优化,比较底层。
- GPipe
- ZeRO
- ZeRO-Offload
- ZeRO-Infinity
- 3D Parallelism
留下评论