http那些事
简介
超文本传输协议,这决定了协议传输的内容。如果你想了解一个http协议,就用一门语言基于socket包写一个特定的响应,然后基于浏览器访问它。
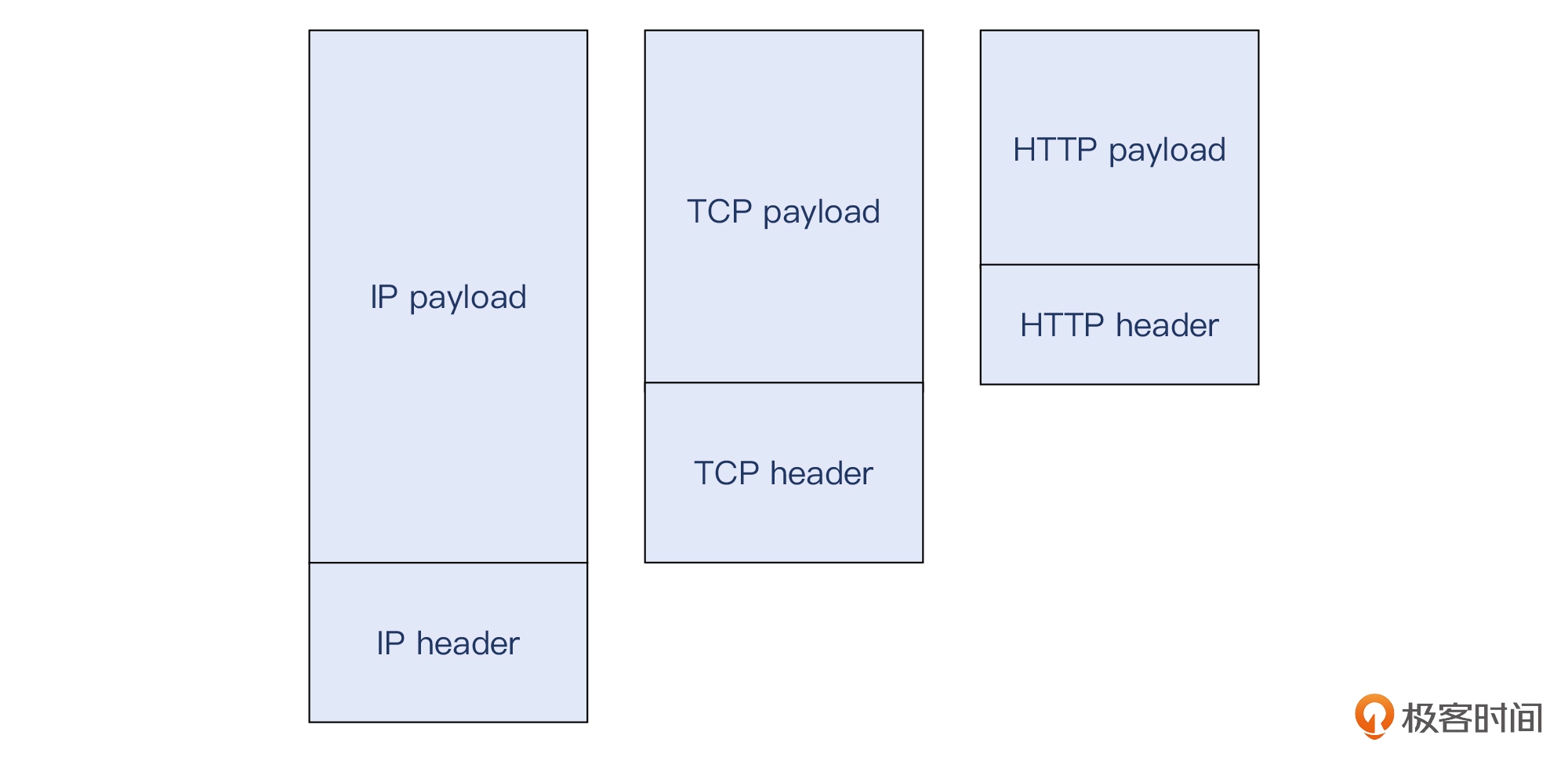
- HTTP 也分为头部(headers)和载荷(body 或者 payload)。载荷的长度一般也是由一个 HTTP header也就是 Content-length 来表示的。头部和载荷的分界线是两次 CRLF。
是什么驱动了http 协议的变革
- 对于同一个域名,浏览器限制只能开6~8多个连接 ==> 连接复用
- 复杂,现在的页面,一个页面上有几十个资源文件是很常见的事儿 ==> 并行请求,请求压缩,优先处理CSS、后传图片
- 安全
- 服务器推送,服务器在客户端没有请求的情况下主动向客户端推送消息。

http1.0
基本特点是“一来一回”:客户端发起一个TCP连接,在连接上发一个http request 到服务器,服务器返回一个http response,然后连接关闭。
主要有两个问题
- 性能问题,连接的建立、关闭都是耗时操作。为此设计了Keep-Alive机制实现Tcp连接的复用。
- 服务器推送问题
http1.1
一些改进:
- Keep-Alive 成为默认。请求头中携带 Connection: Keep-Alive
- 支持Chunk 机制
TCP 的 Keepalive 和 HTTP 的 Keep-Alive 是一个东西吗?HTTP 协议采用的是「请求-应答」的模式,一个 HTTP短连接请求:建立 TCP -> 请求资源 -> 响应资源 -> 释放连接,实在太累人了,能不能在第一个 HTTP 请求完后,先不断开 TCP 连接,让后续的 HTTP 请求继续使用此连接?HTTP 的 Keep-Alive 就是实现了这个功能,可以使用同一个 TCP 连接来发送和接收多个 HTTP 请求/应答(请求头/header添加Connection: Keep-alive),避免了连接建立和释放的开销,这个方法称为 HTTP 长连接。HTTP 长连接的特点是,只要任意一端没有明确提出断开连接(请求头/header添加 Connection:close),则保持 TCP 连接状态。为了避免资源浪费的情况,web 服务软件一般都会提供keepalive_timeout 参数,用来指定 HTTP 长连接的超时时间。web 服务软件就会启动一个定时器,如果客户端在完后一个 HTTP 请求后,在 60 秒内都没有再发起新的请求,定时器的时间一到,就会触发回调函数来释放该连接。注意:HTTP/1.1默认就是长连接。PS: 应用程序实现定时器
TCP 的 Keepalive 这东西其实就是 TCP 的保活机制(socket 接口设置SO_KEEPALIVE 选项),如果两端的 TCP 连接一直没有数据交互,达到了触发 TCP 保活机制的条件,那么内核里的 TCP 协议栈(每隔一段时间)就会发送探测报文。如果对端主机崩溃,或对端由于其他原因导致报文不可达,连续几次,达到保活探测次数后,TCP 会报告该 TCP 连接已经死亡。如果对端会正常响应,这样 TCP 保活时间会被重置,等待下一个 TCP 保活时间的到来。TCP 保活机制可以在双方没有数据交互的情况,通过探测报文,来确定对方的 TCP 连接是否存活,这个工作是在内核完成的。PS: 内核实现定时器
long polling
Polling(轮询):由于 http1.x 没有服务端 push 的机制,为了 Watch 服务端的数据变化,最简单的办法当然是客户端去 pull:客户端每隔定长时间去服务端拉数据同步,无论服务端有没有数据变化。但是必然存在通知不及时和大量无效的轮询的问题。 Long-Polling(长轮询):就是在这个 Polling 的基础上的优化,当客户端发起 Long-Polling 时,如果服务端没有相关数据,会 hold 住请求,直到服务端有数据要发或者超时才会返回。
Content-Type
Content-Type实体首部字段基本要点:
- Content-Type说明了http body的MIME类型的 header字段。
- MIME类型由一个主媒体类型(比如text,image,audio等)后面跟一条斜线以及一个子类型组成,子类型用于进一步描述媒体类型。
对于post请求,默认情况下, http 会对表单数据进行编码提交。笔者实现分片文件上传时,上传分片二进制数据,若是不指定Content-Type: application/octet-stream 则http对二进制进行了一定的变化,导致服务端和客户端对不上。
Content-Encoding
http协议中有 Content-Encoding(内容编码)。Content-Encoding 通常用于对实体内容进行压缩编码,目的是优化传输,例如用 gzip 压缩文本文件,能大幅减小体积。内容编码通常是选择性的,例如 jpg / png 这类文件一般不开启,因为图片格式已经是高度压缩过的。
内容编码针对的只是传输正文。http是无状态的,所以每一次通信 header 都要带上所有信息,在 HTTP/1 中,头部始终是以 ASCII 文本传输,没有经过任何压缩 HTTP/2 采用HPACK 来减少HEADER 大小。
Transfer-Encoding
Transfer-Encoding 用来改变报文格式。这涉及到一个通信协议的重要问题:如何定义协议数据的边界
- 发送完就断连接(非持久连接)
- 协议头部设定content-length
- 以特殊字符结尾
content-length有几个问题:
- 发送数据时,对某些场景,计算数据长度本身是一个比较耗时的事情,同时会占用一定的memory。
- 接收数据时,从协议头拿到数据长度,接收不够这个长度的数据,就不能解码后交给上层处理。
Transfer-Encoding 当下只有一个可选值:分块编码(chunked)。这时,报文中的实体需要改为用一系列分块来传输。每个分块包含十六进制的长度值和数据,长度值独占一行,长度不包括它结尾的 CRLF(\r\n),也不包括分块数据结尾的 CRLF。最后一个分块长度值必须为 0,对应的分块数据没有内容,表示实体结束。
require('net').createServer(function(sock) {
sock.on('data', function(data) {
sock.write('HTTP/1.1 200 OK\r\n');
sock.write('Transfer-Encoding: chunked\r\n');
sock.write('\r\n');
sock.write('b\r\n');
sock.write('01234567890\r\n');
sock.write('5\r\n');
sock.write('12345\r\n');
sock.write('0\r\n');
sock.write('\r\n');
});
}).listen(9090, '127.0.0.1');
server push
服务器可以对一个客户端请求发送多个响应。服务器向客户端推送资源无需客户端明确地请求。
http2
从语义上说,HTTP/2 跟 HTTP/1.x 是保持一致的。HTTP/2 不同,主要是在传输过程中,在 TCP 和 HTTP 之间,增加了一层传输方面的逻辑。什么叫做“语义上是一致的”呢?举个例子,在 HTTP/2 里面,header 和 body 的定义和规则,就跟 HTTP/1.x 一样。
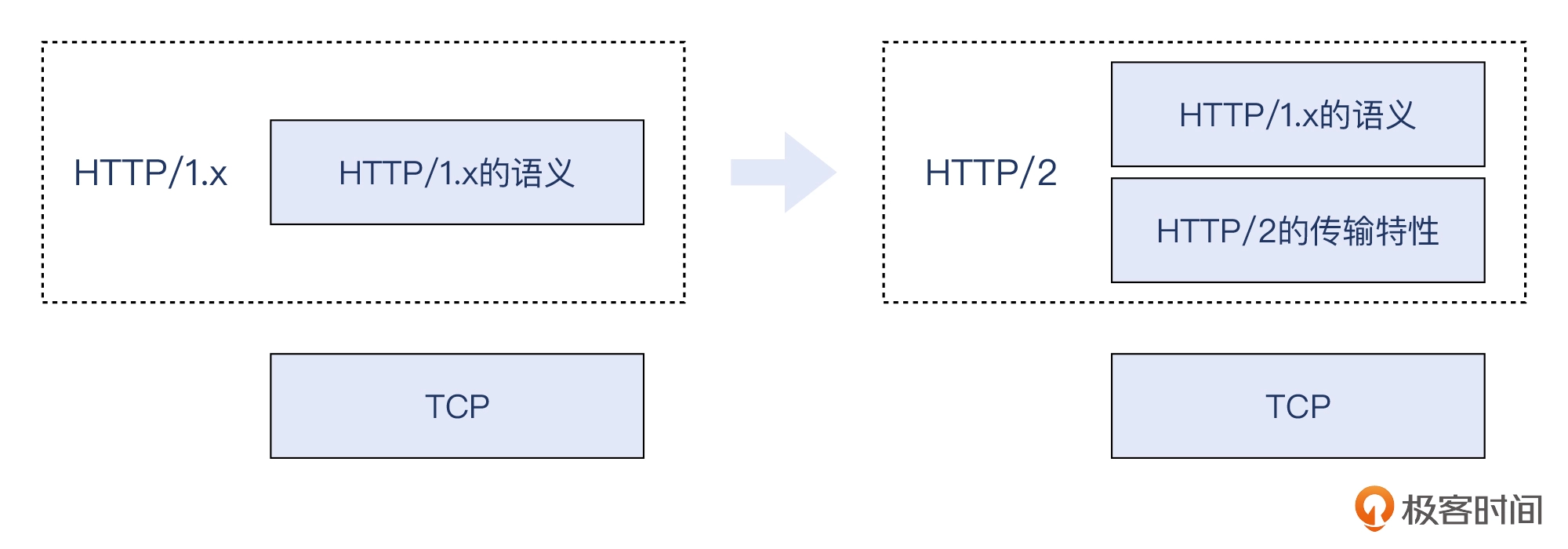
HTTP/1.1 发明以来发生了哪些变化
- 从几kb大小消息到几MB大小的消息
- 每个页面小于10个资源到每个页面100多个资源
- 从文本为主的内容到富媒体(图片、声音、视频) 为主的内容
- 对页面内容实时性高要求的应用越来越多
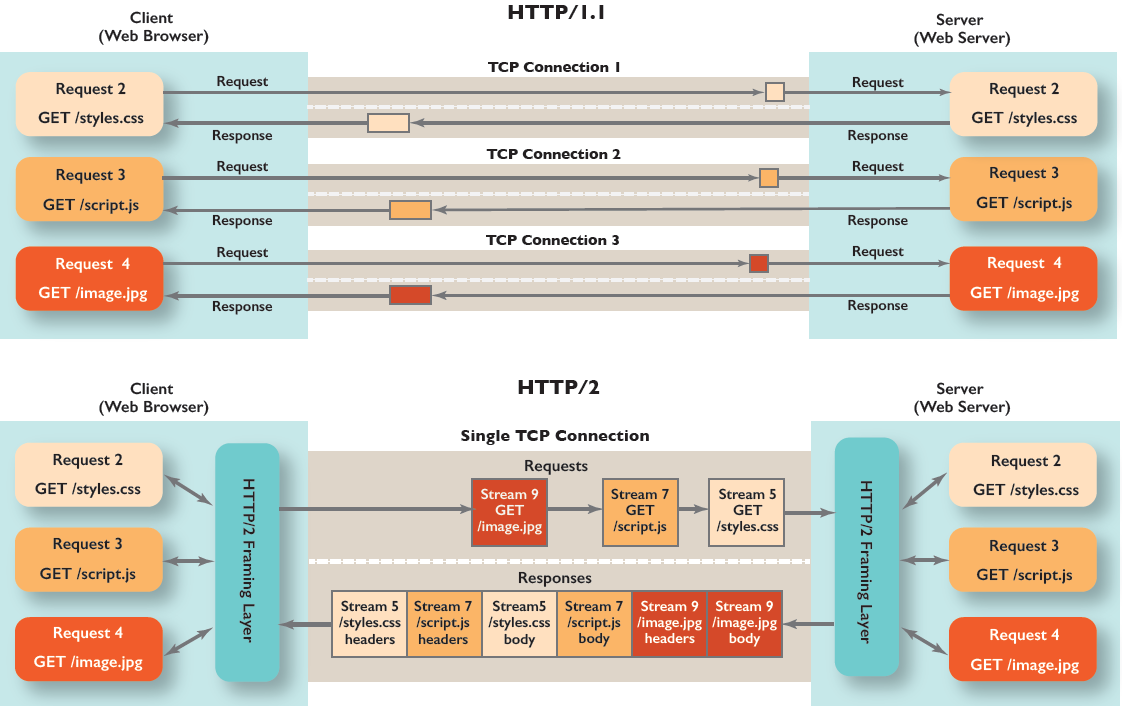
假设浏览器基于 HTTP/1.1上 请求js 和 css文件,下图显示了服务器对该请求的响应。
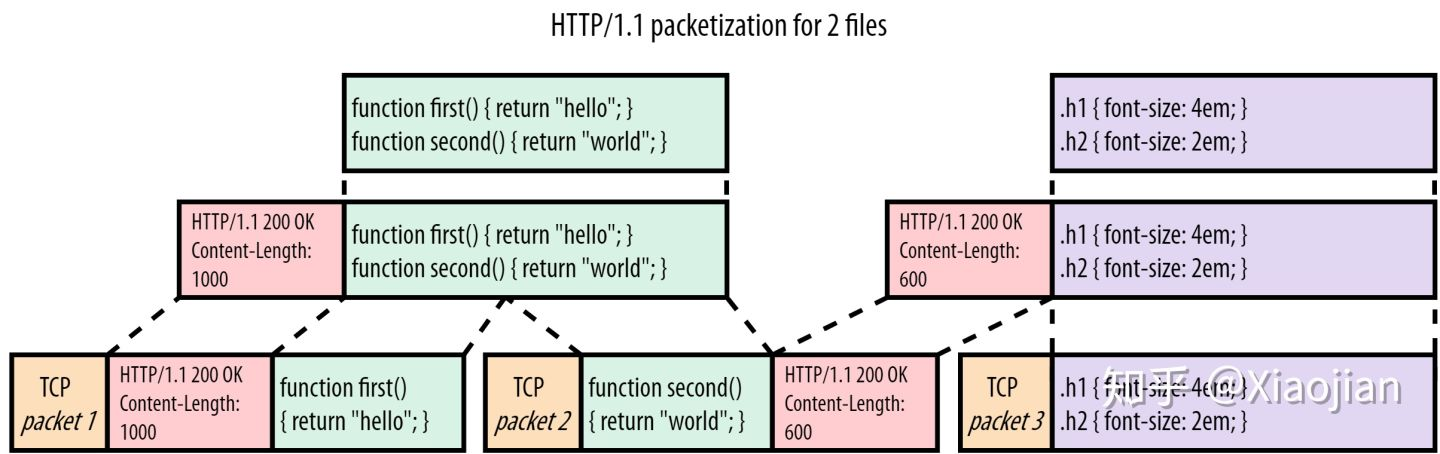
假设 JS 文件比 CSS 大得多,在下载整个JS文件之前,CSS 必须等待,如果TCP packet2 丢失,还要等待TCP packet2 重传后内核 才会将 TCP packet3 交给浏览器处理(TCP队头阻塞),尽管它要小得多,其实可以更早地解析/使用。
即便 HTTP/1.1 解决了一部分连接性能问题,它的效率仍不是很高,而且 HTTP 还有一个队头阻塞问题(HOLB/Head-of-Line Blocking)。
- HTTP 协议属于无状态协议,客户端无法对请求和响应进行关联。假如有五个请求被同时发出,如果请求1没有处理完成,那么 2 3 4 5 这四个请求会直接阻塞在客户端,等到请求 1 被处理完毕后,才能逐个发出。
- HTTP/1.1 协议本质上是纯文本的,它只在有效荷载(payload)的前面附加头(headers),不会进一步区分单个(大块)资源与其他资源,在切换到发送新资源之前,必须完整地传输前面的资源响应,如果前面的资源很大,这些问题可能会引起队头阻塞问题。作为一种解决办法,浏览器为 HTTP/1.1 上的每个页面加载打开多个并行 TCP 连接(通常为6个),这既不高效,也不可扩展。
- 虽然 HTTP/1.1 使用了 pipline 的设计用于解决队头阻塞问题,但是在 pipline 的设计中,每个请求还是按照顺序先发先回,并没有从根本上解决问题。
HTTP/2.0 解决队头阻塞的问题是采用了 连接内分stream和stream内分帧的方式。
- 采⽤帧的传输⽅式可以将请求和响应的数据分割得更⼩,且⼆进制协议可 以被⾼效解析。⽽消息由⼀个或多个帧组成。
- 将多个资源请求分到了不同的 stream 中(JS和CSS 使用不同的stream),每个 stream间可以不用保证顺序乱序发送(我们就可以在网络上混合或“交错”这些片,为 JS 发送一个块,为 CSS 发送一个块,然后再发送另一个用于 JS,等等,使用这种方法,较小的CSS文件将更早地下载),到达服务端后,服务端会根据每个 stream 进行重组,而且可以根据优先级来优先处理哪个 stream。stream 之间是相互隔离的,不会阻塞其他 stream 数据的处理。如果我们把资源用 1 和 2 来表示,我们会发现对于 HTTP/1.1,唯一的选项是11112222(我们称之为顺序的/sequential),HTTP/2 有更多的自由:
- 公平多路复用(例如两个渐进的 JPEGs):12121212
- 加权多路复用(2是1的两倍):22122122121
- 反向顺序调度(例如2是密钥服务器推送的资源):22221111
- 部分调度(流1被中止且未完整发送):112222
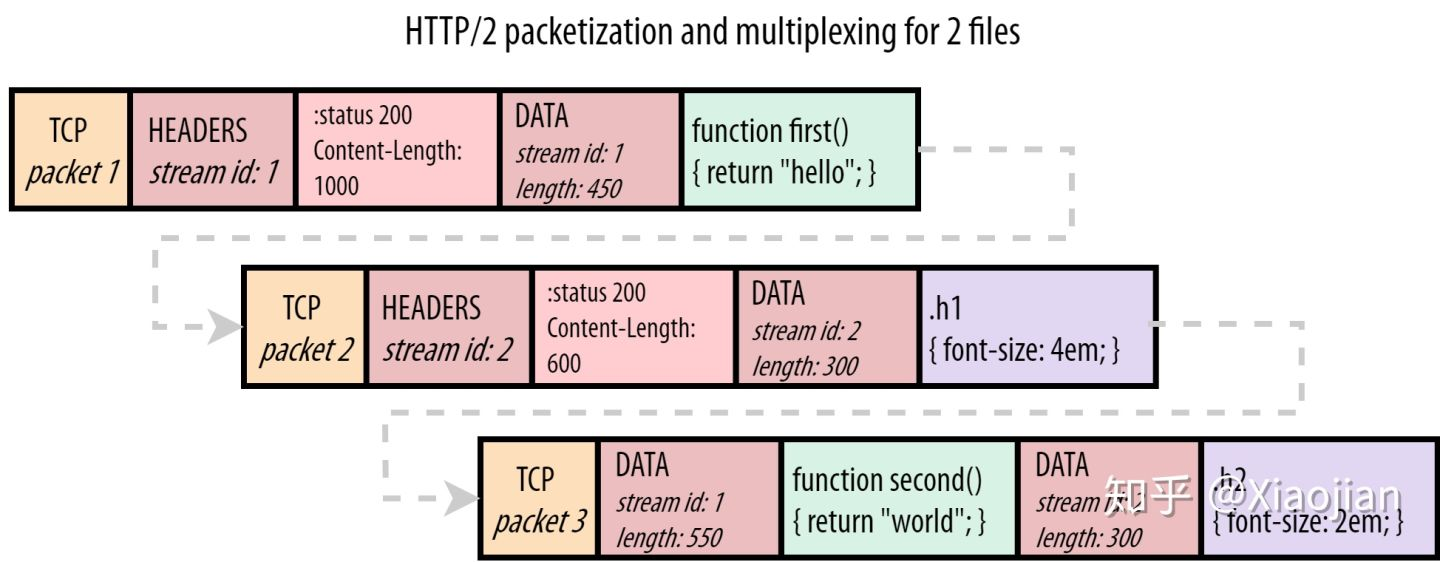
HTTP/2协议–特性扫盲篇HTTP/2的通过支持请求与响应的多路复用来减少延迟,通过压缩HTTP首部字段将协议开销降至最低,同时增加对请求优先级和服务器端推送的支持。
HTTP/2 把 HTTP 分解成了“语义”和“语法”两个部分
- “语义”层不做改动,与 HTTP/1 完全一致(即 RFC7231)。比如请求方法、URI、状态码、头字段等概念都保留不变,这样就消除了再学习的成本,基于 HTTP 的上层应用也不需要做任何修改,可以无缝转换到 HTTP/2。
- HTTP/2 在“语法”层做了“天翻地覆”的改造
备注:语义是对数据符号的解释,而语法则是对于这些符号之间的组织规则和结构关系的定义。http/2中文版 根据rfc7540翻译
HTTP2引入了三个新概念:
- Frame:HTTP2通信的最小单位,二进制头封装,封装HTTP头部或body
- Message:逻辑/语义上的HTTP消息,请求或者响应,可以包含多个 frame
- Stream: 已经建立连接的双向字节流,用唯一ID标示,可以传输一个或多个frame。stream 内frame 串行,stream 间frame 并行。StreamID 是接收端组装 frame的关键。
HTTP/2 in GO(一)Message 和 Stream 只在端上存在,链路中只存在 frame,这些概念的关系是这样的:
- 所有的通信都在一个 tcp 链接上完成,会建立一个或多个 stream 来传递数据
- 每个 stream 都有唯一的 id 标识和一些优先级信息,客户端发起的 stream 的 id 为单数,服务端发起的 stream id 为偶数。PS: 类似于 RPC 调用端为每一个消息生成一个唯一的消息 ID,通过消息ID关联请求跟响应
- 每个 message 就是一次 Request 或 Response 消息,包含一个或多个帧,比如只返回 header 帧,相当于 HTTP 里 HEAD method 请求的返回;或者同时返回 header 和 Data 帧,就是正常的 Response 响应。
- Frame 是最小的通信单位,承载着特定类型的数据,例如 Headers, Data, Ping, Setting 等等。 来自不同 stream 的 frame 可以交错发送,然后再根据每个 Frame 的 header 中的数据流标识符重新组装。

二进制格式
http2把原来的“Header+Body”的消息“打散”为数个小片的二进制“帧”(Frame),用“HEADERS”帧存放头数据、“DATA”帧存放实体数据。这种做法有点像是“Chunked”分块编码的方式,也是“化整为零”的思路,但 HTTP/2 数据分帧后“Header+Body”的报文结构就完全消失了,协议看到的只是一个个的“碎片”。
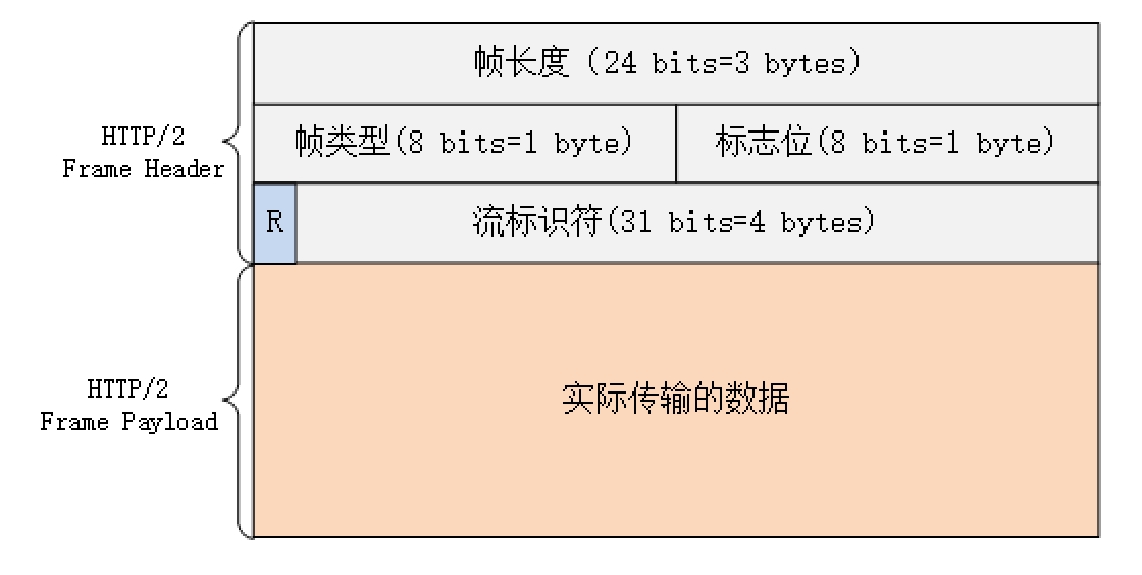
Http2Frame 类型
| type值 | |||
|---|---|---|---|
| data | 0x0 | ||
| header | 0x1 | ||
| PRIORITY | 0x2 | ||
| RST_STREAM | 0x3 | 流结束帧,用于终止异常流 | |
| SETTINGS | 0x4 | 连接配置参数帧 | 设置帧由两个终端在连接开始时发送,连接生存期的任意时间发送;设置帧的参数将替换参数中现有值;client和server都可以发送;设置帧总是应用于连接,而不是一个单独的流; |
| PUSH_PROMISE | 0x5 | 推送承诺帧 | |
| PRIORITY | 0x6 | 检测连接是否可用 | |
| GOAWAY | 0x7 | 通知对端不要在连接上建新流 | |
| WINDOW_UPDATE | 0x8 | 实现流量控制 | |
| CONTINUATION | 0x9 |
我们可以将frame笼统的分为data frame和 control frame,每一种类型的payload都是有自己的结构。可以参考下 go http2 实现 HTTP/2 in GO(三)
多路复用
消息的“碎片”到达目的地后应该怎么组装起来呢?HTTP/2 为此定义了一个“流”(Stream)的概念,它是二进制帧的双向传输序列,同一个消息往返的帧会分配一个唯一的流 ID。
因为流是虚拟的,实际上并不存在(除了Frame 结构里有一个StreamId),所以 HTTP/2 就可以在一个 TCP 连接上用“流”同时发送多个“碎片化”的消息,这就是常说的“多路复用”( Multiplexing)——多个往返通信都复用一个连接来处理。
在“流”的层面上看,消息是一些有序的“帧”序列,而在“连接”的层面上看,消息却是乱序收发的“帧”。在概念上,一个 HTTP/2 的流就等同于一个 HTTP/1 里的“请求 - 应答”。在 HTTP/1 里一个“请求 - 响应”报文来回是一次 HTTP 通信,在 HTTP/2 里一个流也承载了相同的功能。
浏览器渲染一个页面需要一个html文件,一个css文件,一个js文件,n个图片文件
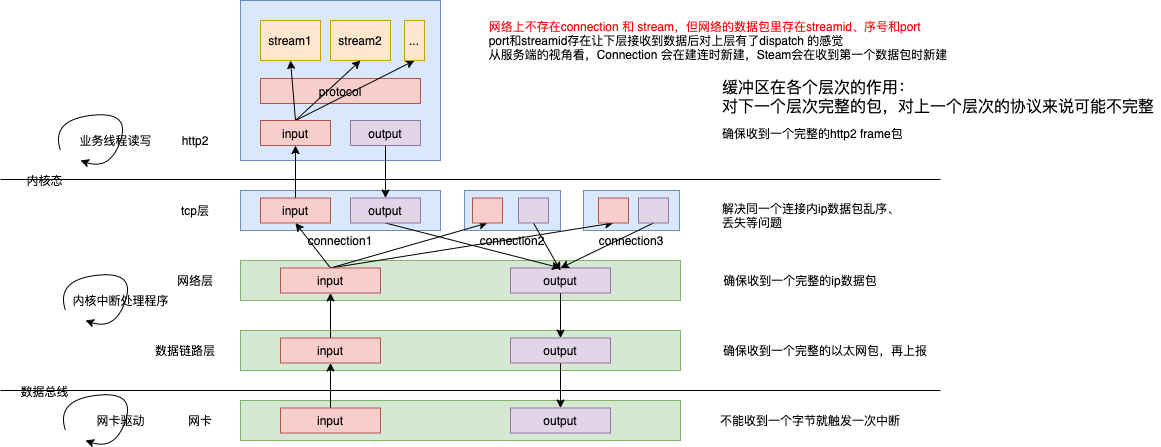
备注:对于接收来说,缓冲区让 接收数据从字节到数据包有了完整性,port和streamid 则为数据包 赋予了“身份”。
HTTP/2 的流有哪些特点呢?
- 流是可并发的,一个 HTTP/2 连接上可以同时发出多个流传输数据,也就是并发多请求,实现“多路复用”;
- 客户端和服务器都可以创建流,双方互不干扰;
- 流是双向的,一个流里面客户端和服务器都可以发送或接收数据帧,也就是一个“请求 - 应答”来回;
- 流之间没有固定关系,彼此独立,但流内部的帧是有严格顺的;
- 流可以设置优先级,让服务器优先处理,比如先传 HTML/CSS,后传图片,优化用户体验;
- 流 ID 不能重用,只能顺序递增,客户端发起的 ID 是奇数,服务器端发起的 ID 是偶数;
- 在流上发送“RST_STREAM”帧可以随时终止流,取消接收或发送;
- 第 0 号流比较特殊,不能关闭,也不能发送数据帧,只能发送控制帧,用于流量控制。
流量控制
为什么需要Http2应用层流控?多路复用意味着多个Stream 必须共享TCP 层的流量控制。
简单说,就是发送方启动是有个窗口大小(默认64K-1),发送了10K的DATA帧,就要在窗口里扣血(减掉10K),如果扣到0或者负数,就不能再发送;接收方收到后,回复WINDOW_UPDATE帧,里面包含一个窗口大小,数据发送方收到这个窗口大小,就回血,如果回血到正数,就又能发不超过窗口大小的DATA帧。
这种流控方式就带来一些问题:
- 如果接收方发的WINDOW_UPDATE frame丢了,当然tcp会保证重传,但在WINDOW_UPDATE重传之前,就限制了发送方发送数据
- 一旦发送方初始windows size确定,那么发送方的发送速度是由接收方 + 网络传输决定的,如果发送方的速度大于接收方的应答,那么就会有大量的数据pending。
流控只限定data类型的frame,其它限定参见http2-frame-WINDOW_UPDATE
https
HTTPS其实不是某个独立的协议,而是 HTTP over TLS,也就是把 HTTP 消息用 TLS 进行加密传输。两者相互协同又各自独立,依然遵循了网络分层模型的思想:
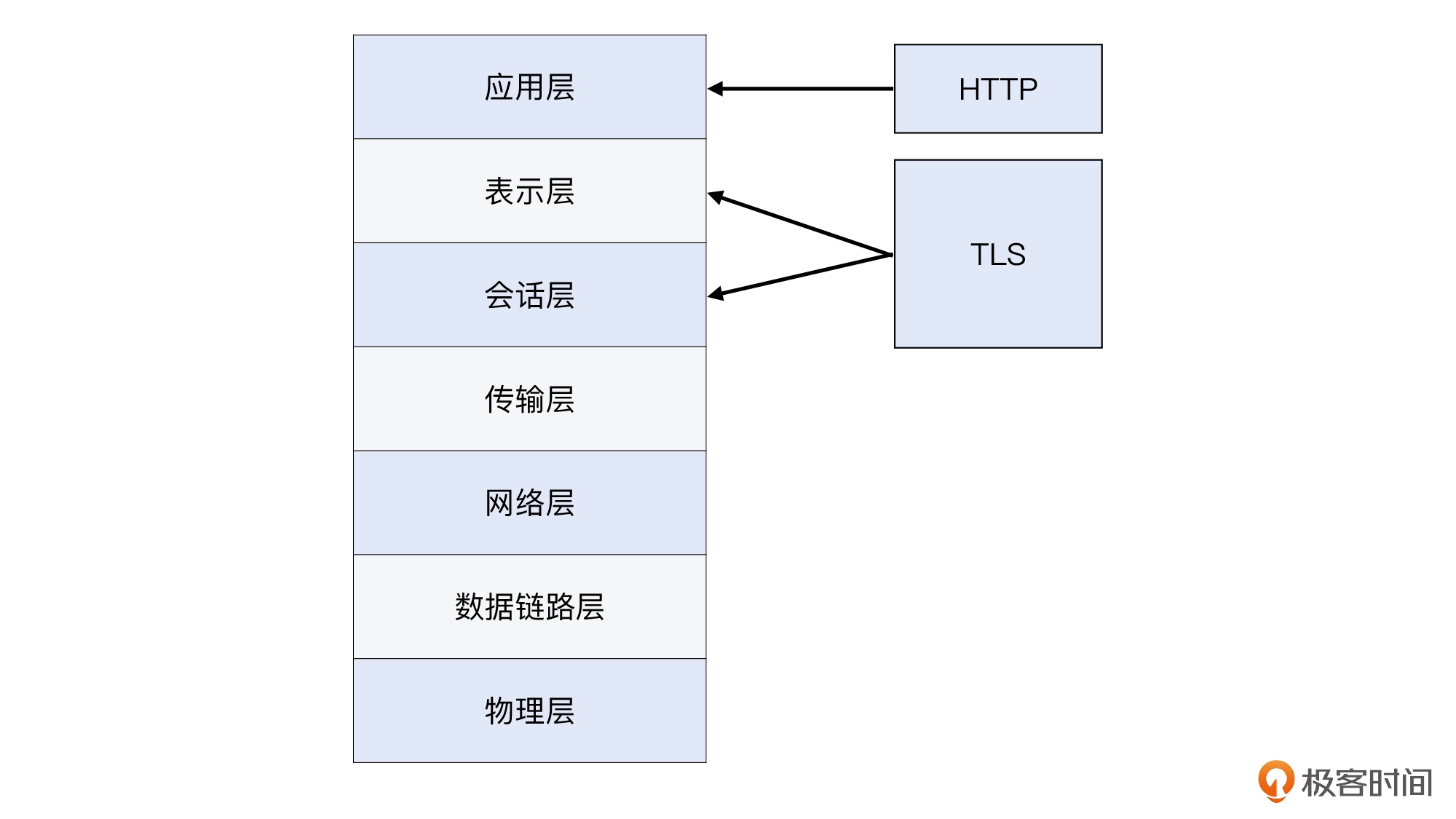
对web服务器发起请求时,我们需要一种方式来告知web服务器去执行http的安全协议版本,这是通过url中设定http或https来实现的。
- 如果是http,客户端就会打开一条到服务器80端口的连接
- 如果是https,客户端就会打开一条到服务器443端口的连接,一旦建立连接,client和server就会初始化ssl layer,对加密参数进行沟通,并交换密钥。ssl握手(SSLHandshake)完成之后,ssl layer初始化完成了。剩下的就是,browser将数据从http layer发到tcp layer之前,要经过ssl layer加密。
Java 和 HTTP 的那些事(四) HTTPS 和 证书
QUIC:让传输层知道不同的、独立的流
Tcp 有一些痼疾诸如队头阻塞、重传效率低等,因此Google 基于UDP 提出了一个QUIC(quick udp internet connection),在重传效率、减少RTT次数、连接迁移(以客户端生成的64位标识而不是4元组来表示一个连接,更适合移动客户端频繁建立连接的场景)等方面做了一些工作。QUIC 协议在蚂蚁落地综述
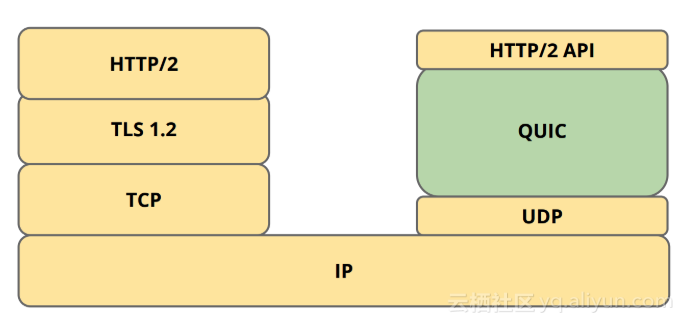
如何看待谷歌 Google 打算用 QUIC 协议替代 TCP/UDP?QUIC 相比于 HTTP/2.0 来说,具有下面这些优势
- 使用 UDP 协议,不需要三次连接进行握手,而且也会缩短 TLS 建立连接的时间。
- 实现动态可插拔,在应用层实现了拥塞控制算法,可以随时切换。而TCP 协议的具体实现是由操作系统内核来完成的,应用程序只能使用,不能对内核进行修改,由于操作系统升级涉及到底层软件和运行库的更新,所以也比较保守和缓慢。
- 报文头和报文体分别进行认证和加密处理,保障安全性。
- 连接能够平滑迁移
- 解决了队头阻塞问题。关于队头阻塞(Head-of-Line blocking),看这一篇就足够了
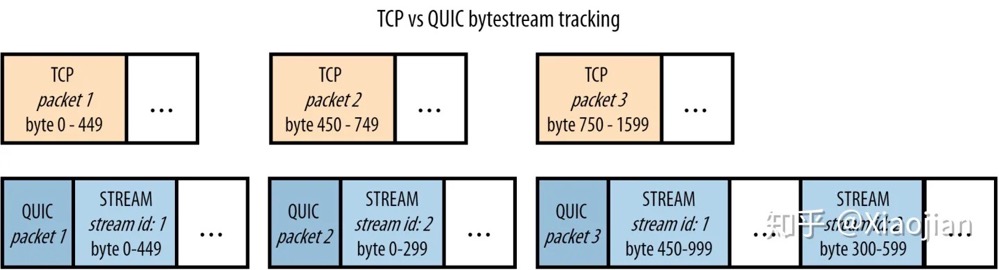
多个资源流同时活动时消除队头阻塞
- 如果 TCP 数据包2在网络中丢失,但数据包1和数据包3已经到达,会发生什么情况?请记住,TCP并不知道它正在承载 HTTP/2,只知道它需要按顺序传递数据。因此,它知道数据包1的内容可以安全使用,并将这些内容传递给浏览器。然而,它发现数据包1中的字节和数据包3中的字节(放数据包2 的地方)之间存在间隙,因此还不能将数据包3传递给浏览器。TCP 将数据包3保存在其接收缓冲区(receive buffer)中,直到它接收到数据包2的重传副本(这至少需要往返服务器一次),之后它可以按照正确的顺序将这两个数据包都传递给浏览器。换个说法:丢失的数据包2 队头阻塞(HOL blocking)数据包3!如果一个 TCP 包丢失,所有后续的包都需要等待它的重传,即使它们包含来自不同流的无关联数据。因此,在某些情况下,单个连接上的 HTTP/2 很难比6个连接上的 HTTP/1.1 快,甚至与 HTTP/1.1 一样快。 TCP 将 HTTP/2 数据抽象为一个单一的、有序的、但不透明的流。QUIC 在单个资源流中保留了顺序,但不再跨单个流(individual streams)进行排序。
- 如果 QUIC 数据包2丢失,而 1 和 3 到达会发生什么?与 TCP 类似,数据包1中流1(stream 1)的数据可以直接传递到浏览器。然而,对于数据包3,QUIC 可以比 TCP 更聪明。它查看流1的字节范围,发现这个流帧(STREAM frame)完全遵循流id 1的第一个流帧 STREAM frame(字节 450 跟在字节 449 之后,因此数据中没有字节间隙)。它可以立即将这些数据提供给浏览器进行处理。然而,对于流id 2,QUIC确实看到了一个缺口(它还没有接收到字节0-299,这些字节在丢失的 QUIC 数据包2中)。它将保存该流帧(STREAM frame),直到 QUIC 数据包2的重传(retransmission)到达。再次将其与 TCP 进行对比,后者也将数据流1的数据保留在数据包3中!
- 类似的情况发生在另一种情形下,数据包1丢失,但2和3到达。QUIC 知道它已经接收到流2(stream 2)的所有预期数据,并将其传递给浏览器,只保留流1(stream 1)。我们可以看到,对于这个例子,QUIC 确实解决了 TCP 的队头阻塞!
PS:QUIC把http2中应对 队头阻塞 的 stream方法 下放到transport层来实现。也就是只要 stream 内数据是完整的就可以直接 上交给应用层处理?多个资源分frame 传输 降低粒度,一个tcp/udp packet 内包含多个资源的frame,降低丢一个 tcp/udp packet 造成的等待范围。http 到quic 的脉络有可能是:资源传输粒度减小,尽快交给上游处理(对http是一个文章的资源文件,浏览器可以开始干活,对quic 是尽快收到一个完整的frame 数据交给应用层)。就像线程内拆协程,连接内拆stream。
其它
get 和 post 的区别
2018.05.11 补充
- GET和POST本质上就是TCP链接,并无差别。但是由于HTTP的规定和浏览器/服务器的限制,导致他们在应用过程中体现出一些不同。这个可以说出来十几条。
- 对于GET方式的请求,浏览器会把http header和data一并发送出去,服务器响应200(返回数据);而对于POST,浏览器先发送header,服务器响应100 continue,浏览器再发送data,服务器响应200 ok(返回数据)。当然,这并不是强约束,firefox对post 就还只是发了一次。
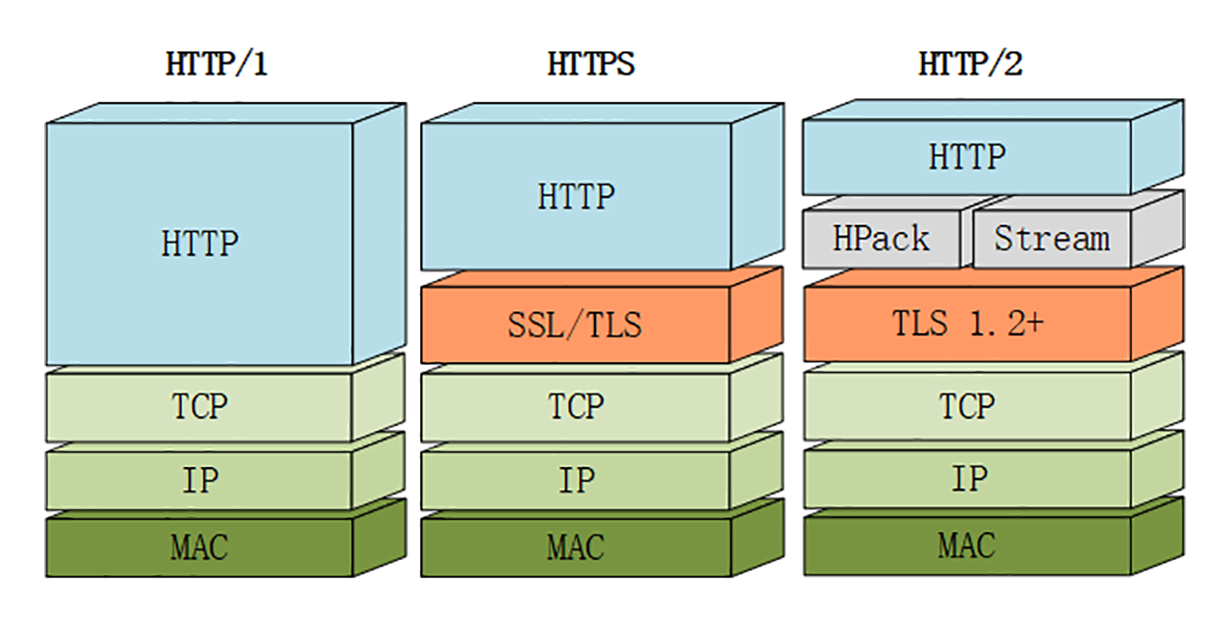
http1.1 http2 https之间的关系
cookie 和 header
accept:image/webp,image/apng,image/*,*/*;q=0.8
accept-encoding:gzip, deflate, br
accept-language:en-US,en;q=0.9
cache-control:no-cache
cookie:GeoIP=US:CA:Los_Angeles:34.05:-118.26:v4; CP=H2; WMF-Last-Access=23-Feb-2018; WMF-Last-Access-Global=23-Feb-2018
cookie 是header的一种,cookie被浏览器自动添加,特殊处理
- 浏览器自动存储cookie,存储时按域名组织,并在发送请求时自动带上cookie(这导致某些数据不适合放在cookie中,因为会浪费网络流量)
- cookie既可以由服务端来设置(通过set-cookie header),也可以由客户端来设置(js
document.cookie = "name=Jonh; ";)。 - HTTP cookieAn HTTP cookie is a small piece of data sent from a website and stored on the user’s computer by the user’s web browser while the user is browsing. Cookies were designed to be a reliable mechanism for websites to remember stateful information。The term “cookie” was coined by web browser programmer Lou Montulli. cookie 由一个 browser programmer 提出,由browser存储,目的是为了存储用户的状态信息。
对笔者个人来说,有以下几点要矫正:
-
header 分为
- 通用header,比如Date
- 请求特有header,比如Accept、Authorization、Cookie
- 响应特有header,比如Server、Set-Cookie
- body相关header,比如Content-Type
- 自定义header
因为springmvc 等framework,开发时不需要了解header,但framework确实进行了必要的设置
-
对于服务端开发,我们比较熟悉,将用户数据保存在数据库中,通过http请求改变用户记录的状态。其实,反向的过程也是支持的,常用的本地存储——cookie篇,随着浏览器的处理能力不断增强,越来越多的网站开始考虑将数据存储在「客户端」,提供了许多本地存储的手段。浏览器提供数据存储能力,服务器通过http响应来更改用户记录的状态。
并行性
对于处理多个“活儿”,每个“活儿”多个步骤:
- HTTP/1.1 with one connection,说一个活儿,干一个活儿, 干完一个再说下一个
- HTTP/1.1 with pipelining,一次说完,走排期,依次干活
- HTTP/2,一次说完,自己看着干
- HTTP/1.1 with multiple connections,把活儿分派给多个人
实现一个简单的http server
基于node.js socket写一个简单的http server
require('net').createServer(function(sock) {
sock.on('data', function(data) {
sock.write('HTTP/1.1 200 OK\r\n');
sock.write('\r\n');
sock.write('hello world!');
sock.destroy();
});
}).listen(9090, '127.0.0.1');
scala版本
object SocketServer {
def main(args: Array[String]): Unit = {
try {
val listener = new ServerSocket(8080);
val socket = listener.accept()
val data = "HTTP/1.1 200 OK\r\nContent-Length: 12\r\n\r\nhello world!"
socket.getOutputStream.write(data.getBytes())
socket.close()
listener.close()
}
catch {
case e: IOException =>
System.err.println("Could not listen on port: 80.");
System.exit(-1)
}
}
}
留下评论