tensorflow原理——python层分析
简介
我们知道python 层作为Client 主要作用是构建GraphDef 交给 Master 处理,但很明显,我们写的 训练代码 跟GraphDef 构建工作并没有一一对应,也没有直接操作OP,这里仍然有很多的抽象工作,包括Model/Layer/feature_column/optimizer 等工作,从上到下依次是
- 构建模型,模型训练
session.run - feature_column/layer 拼接为模型
- tensor 转换构成layer / feature_column
- tensor 读取和计算通过op,op 调用 实质是 构建GraphDef。PS: 就好比 client rpc 的方法调用 实质是 socket.write
# model parameters
W = tf.Variable(0.3, tf.float32)
b = tf.Variable(-0.3, tf.float32)
# model inputs & outputs
x = tf.placeholder(tf.float32)
y = tf.placeholder(tf.float32)
# the model
out = W * x + b
# loss function
loss = tf.reduce_sum(tf.square(out - y))
# optimizer
optimizer = tf.train.GradientDescentOptimizer(0.001)
train = optimizer.minimize(loss)
# training data
x_train = np.random.random_sample((100,)).astype(np.float32)
y_train = np.random.random_sample((100,)).astype(np.float32)
# training
init = tf.global_variables_initializer()
with tf.Session() as sess:
sess.run(init)
for i in range(1000):
sess.run(train, {x:x_train, y:y_train})
current_loss = sess.run(loss, {x:x_train, y:y_train})
print("iter step %d training loss %f" % (i, current_loss))
print(sess.run(W))
print(sess.run(b))
上层model 与底层数据流图/graph,layer1 ==> layer2 ==> …layern 被展开成了 op,tenor 在layer 之间的流动 转换为了 dag op 间的流动。在执行层面的体现就是计算机按顺序运行一个个 OP。
源码结构
本文主要来自 tf r1.4 分支的代码
tensorflow
c
cc // c++ 前端接口
java // java 前端接口
python // python 前端接口
layers // layer组件
feature_column // 特征列组件
training // 包括optimizer/saver/checkpoint 等组件
keras
estimator
client
ops // op算子
user_ops // 用户自定义算子
stream_executor // 运行时环境,对cuda和opencl进行统一封装,屏蔽他们的区别
compiler // 运行时优化,分析计算图,对op 进行融合,提升运行效率,XLA技术
contrib // 三方库,成熟后会移到core python中
core // tf的核心,基本都是c++,包括运行时、图操作、op定义、kernel实现等
结合tf 原生api(自己定义Variable 乘一乘,计算 output/loss,使用optimizer) 实际例子来看下
# 返回 _NumericColumn
price = numeric_column('price')
keywords_embedded = embedding_column(categorical_column_with_hash_bucket("keywords", 10K), dimensions=16)
columns = [price, keywords_embedded, ...]
features = tf.parse_example(..., features=make_parse_example_spec(columns))
dense_tensor = input_layer(features, columns)
for units in [128, 64, 32]:
dense_tensor = tf.layers.dense(dense_tensor, units, tf.nn.relu)
prediction = tf.layers.dense(dense_tensor, 1) # 也是output
feature_column
在r1.4 分支,所有关于feature_column 的代码都在这一个python 文件 tensorflow/tensorflow/python/feature_column/feature_column.py 里。
对外使用的函数
分为两类:根据feature key(str) 构建FeatureColumn;根据输入特征数据 features 和FeatureColumn 构建layer
#
# Returns a dense `Tensor` as input layer based on given `feature_columns`
def input_layer(features,feature_columns,...):
# features: A mapping from key to tensors. `_FeatureColumn`s look up via these
# keys. For example `numeric_column('price')` will look at 'price' key in
# this dict. Values can be a `SparseTensor` or a `Tensor` depends on
# corresponding `_FeatureColumn`.
...
builder = _LazyBuilder(features)
output_tensors = []
for column in sorted(feature_columns, key=lambda x: x.name):
tensor = column._get_dense_tensor(builder,...)
tensor = array_ops.reshape(tensor, shape=(batch_size, num_elements))
output_tensors.append(tensor)
return array_ops.concat(output_tensors, 1)
def linear_model(features,feature_columns,...)
def _transform_features(features, feature_columns,...)
def make_parse_example_spec(feature_columns)
# 构建FeatureColumn
def embedding_column(categorical_column, dimension,...):
...
return _EmbeddingColumn(categorical_column=categorical_column,...)
def numeric_column(key,...):
...
return _NumericColumn(key,shape=shape,...)
def bucketized_column(source_column, boundaries, ...)
def categorical_column_with_hash_bucket(key,...)
def categorical_column_with_vocabulary_file(key, vocabulary_file, vocabulary_size,...)
def crossed_column(keys, hash_bucket_size, ...)
...
FeatureColumn
_FeatureColumn specifies how to digest an input column to the network.
class _FeatureColumn(object):
def name(self):
def _transform_feature(self, inputs): # inputs 是一个_LazyBuilder,返回一个tensor
class _DenseColumn(_FeatureColumn):
def _variable_shape(self):
def _get_dense_tensor(self, inputs, weight_collections=None, trainable=None):
class _CategoricalColumn(_FeatureColumn):
IdWeightPair = collections.namedtuple( 'IdWeightPair', ['id_tensor', 'weight_tensor'])
def _num_buckets(self):
def _get_sparse_tensors(self,inputs,...): # Returns an IdWeightPair
LazyBuilder
辅助对象 _LazyBuilder : Some feature columns require data transformations. This class caches those transformations. 此外,一些feature 也不只使用一次。
class _LazyBuilder(object):
def __init__(self, features):
self._features = features.copy() # 真正的input(dict)
self._feature_tensors = {} # 缓存作用
def get(self, key):
if key in self._feature_tensors:
# FeatureColumn is already transformed or converted.
return self._feature_tensors[key]
if key in self._features:
feature_tensor = self._get_raw_feature_as_tensor(key)
self._feature_tensors[key] = feature_tensor
return feature_tensor
... # 此时key 是一个 _FeatureColumn
column = key
transformed = column._transform_feature(self)
self._feature_tensors[column] = transformed
return transformed
从_LazyBuilder.get实现逻辑看, 先尝试从 input _features 和 _feature_tensors 查看是否包含对应的key(str),若不存在,且此时key 是一个_FeatureColumn ,则调用 key/column. _transform_feature 方法,根据_FeatureColumn.key 从_LazyBuilder 中获取 input_tensor ,并转换为 _FeatureColumn 对应的output_tensor.
class _NumericColumn(_DenseColumn,
collections.namedtuple('_NumericColumn', [
'key', 'shape', 'default_value', 'dtype',
'normalizer_fn'
])):
def _transform_feature(self, inputs):
input_tensor = inputs.get(self.key)
# 将input_tensor 转换为float 数据
return math_ops.to_float(input_tensor)
EmbeddingColumn
为了计算 [batch_size, vocab_size] * [vocab_size, embed_size] = [batch_size, embed_size]
_EmbeddingColumn 聚合了 _CategoricalColumn
- 通过 _CategoricalColumn 将原始 input tensor 转换为 [batch_size, vocab_size]
- 新建一个 [vocab_size, embed_size]
- 计算
[batch_size, vocab_size] * [vocab_size, embed_size]返回[batch_size, embed_size]
class _EmbeddingColumn(
_DenseColumn,
collections.namedtuple('_EmbeddingColumn', (
'categorical_column', 'dimension', 'combiner', 'initializer',
'ckpt_to_load_from', 'tensor_name_in_ckpt', 'max_norm', 'trainable'
))):
def _transform_feature(self, inputs):
return inputs.get(self.categorical_column)
def _get_dense_tensor(self, inputs, weight_collections=None, trainable=None):
# Get sparse IDs and weights. 比如构建 one-hot 向量
sparse_tensors = self.categorical_column._get_sparse_tensors( # pylint: disable=protected-access
inputs, weight_collections=weight_collections, trainable=trainable)
sparse_ids = sparse_tensors.id_tensor
sparse_weights = sparse_tensors.weight_tensor
# 新建一个 embedding_weights 权重矩阵
embedding_weights = variable_scope.get_variable(name='embedding_weights',...)
...
# 根据 sparse_ids/sparse_weights 从权重 矩阵中检索 降维后的矩阵
return _safe_embedding_lookup_sparse(embedding_weights=embedding_weights,sparse_ids=sparse_ids,sparse_weights=sparse_weights,...)
def _safe_embedding_lookup_sparse(embedding_weights,sparse_ids,sparse_weights=None,...):
... # 对输入参数 进行处理
result = embedding_ops.embedding_lookup_sparse(embedding_weights,sparse_ids,sparse_weights,...)
final_result = array_ops.reshape(result,...)
return final_result
总结一下
- 总的调用链条 input_layer ==> _FeatureColumn._get_dense_tensor ==> _LazyBuilder.get(_FeatureColumn) ==> _FeatureColumn._transform_feature ==> _LazyBuilder.get(str key) + 转换逻辑
- input_layer 负责汇总所有 _FeatureColumn 组成“特征层”,将原始input tensor 转换为 特征转换后的 给densor layer 使用的tensor
- _FeatureColumn._transform_feature 负责转换 原始 input tensor,_LazyBuilder 负责缓存
- 对于 _EmbeddingColumn 来说复杂一点
_EmbeddingColumn._get_dense_tensor categorical_column._get_sparse_tensors ==> _LazyBuilder.get(categorical_column) embedding_weights = variable_scope.get_variable _safe_embedding_lookup_sparse
StateManager
在较新版本的tf中,Some FeatureColumns(比如EmbeddingColumn) create variables or resources to assist their computation. The StateManager is responsible for creating and storing these objects since FeatureColumns are supposed to be stateless configurationonly.
# tensorflow/python/feature_column/feature_column_v2.py
class StateManager(object):
def create_variable(self,feature_column,name,...)
def add_variable(self, feature_column, var):
def get_variable(self, feature_column, name):
def add_resource(self, feature_column, name, resource):
def has_resource(self, feature_column, name):
def get_resource(self, feature_column, name):
class _StateManagerImpl(StateManager):
def __init__(self, layer, trainable):
self._trainable = trainable
self._layer = layer
if self._layer is not None and not hasattr(self._layer, '_resources'):
self._layer._resources = data_structures.Mapping() # pylint: disable=protected-access
self._cols_to_vars_map = collections.defaultdict(lambda: {})
self._cols_to_resources_map = collections.defaultdict(lambda: {})
Variable
Variable 是一个特殊的 OP,它拥有状态 (Stateful)。从实现技术探究,Variable 的 Kernel(c++层) 实现直接持有一个 Tensor 实例,其生命周期与变量一致。相对于普通的 Tensor 实例,其生命周期仅对本次迭代 (Step) 有效;而 Variable 对多个迭代都有效,甚至可以存储到文件系统,或从文件系统中恢复。
- 从设计角度看,Variable 可以看做 Tensor 的包装器,Tensor 所支持的所有操作都被Variable 重载实现。也就是说,Variable 可以出现在 Tensor 的所有地方。
- 存在几个操作 Variable 的特殊 OP 用于修改变量的值,例如 Assign, AssignAdd 等。Variable 所持有的 Tensor 以引用的方式输入到 Assign 中,Assign 根据初始值 (Initial Value)或新值,就地修改 Tensor 内部的值,最后以引用的方式输出该 Tensor。
# tensorflow/tensorflow/python/ops/variables.py
class Variable(object):
def __init__(self, initial_value=None, trainable=True,collections=None, name=None, dtype=None):
...
self._init_from_args(initial_value=initial_value,trainable=trainable,...)
def _init_from_args(self,initial_value=None,...):
...
# initial_value: 初始值,为一个tensor,或者可以被包装为tensor的值
# trainable:是否可以训练,如果为false,则训练时不会改变
# collections:变量要加入哪个集合中,有全局变量集合、本地变量集合、可训练变量集合等。默认加入全局变量集合中
self._variable = state_ops.variable_op_v2(shape,self._initial_value.dtype.base_dtype,name=name)
self._initializer_op = state_ops.assign(self._variable,self._build_initializer_expr(self._initial_value),...)
def read_value(self):
return array_ops.identity(self._variable, name="read")
def eval(self, session=None):
return self._variable.eval(session=session)
def assign(self, value, use_locking=False):
return state_ops.assign(self._variable, value, use_locking=use_locking)
def assign_add(self, delta, use_locking=False):
return state_ops.assign_add(self._variable, delta, use_locking=use_locking)
...
class PartitionedVariable(object):
...
W = tf.Variable(tf.zeros([784,10]), name='W') ,TensorFlow 设计了一个精巧的变量初始化模型。
- 初始值,tf.zeros返回一个Tensor(并未承载数据,仅表示Operation输出的一个符号句柄),初始化时将initial_value初始值赋予Variable内部持有的Tensor,它确定了 Variable 的类型为 int32,且 Shape为 [784, 10]。
- 初始化器,,变量通过初始化器 (Initializer) 在初始化期间,将初始化值赋予 Variable 内部所持有 Tensor,完成 Variable 的就地修改。W.initializer 实际上为 Assign的 OP,这是 Variable 默认的初始化器。更为常见的是,通过调用 tf.global_variables_initializer() 将所有变量的初始化器进行汇总,然后启动 Session 运行该 OP。
- 事实上,搜集所有全局变量的初始化器的 OP 是一个 NoOp,即不存在输入,也不存在输出。所有变量的初始化器通过控制依赖边与该 NoOp 相连,保证所有的全局变量被初始化。
Variable 由_VariableStore 管理(在较新的版本可能去掉了)
# tensorflow/tensorflow/python/ops/variable_scope.py
class _VariableStore(object):
def __init__(self):
"""Create a variable store."""
self._vars = {} # A dictionary of the stored TensorFlow variables.
self._partitioned_vars = {} # A dict of the stored PartitionedVariables.
self.variable_scopes_count = {} # Count re-used variable scopes.
def get_variable(self, name, shape=None, dtype=dtypes.float32,...):
def _true_getter(name, shape=None, dtype=dtypes.float32,...):
if partitioner is not None and not is_scalar:
return self._get_partitioned_variable(name=name,shape=shape,dtype=dtype,...)
return self._get_single_variable(name=name, shape=shape, dtype=dtype,...)
if custom_getter is not None:
return custom_getter(**custom_getter_kwargs)
else:
return _true_getter(name, shape=shape, dtype=dtype,...)
def _get_single_variable(self,name,shape=None,...):
if name in self._vars:
found_var = self._vars[name]
return found_var
if use_resource:
v = resource_variable_ops.ResourceVariable(initial_value=init_val,name=name,...)
else:
v = variables.Variable(initial_value=init_val,name=name,...)
self._vars[name] = v
return v
Variable被划分到不同的集合中,方便后续操作。常见的集合有
- 全局变量:全局变量可以在不同进程中共享,可运用在分布式环境中。变量默认会加入到全局变量集合中。通过tf.global_variables()可以查询全局变量集合。其op标示为GraphKeys.GLOBAL_VARIABLES
- 运行在进程内的变量,不能跨进程共享。通常用来保存临时变量,如训练迭代次数epoches。通过tf.local_variables()可以查询本地变量集合。其op标示为GraphKeys.LOCAL_VARIABLES
- 可训练变量:一般模型参数会放到可训练变量集合中,训练时,做这些变量会得到改变。不在这个集合中的变量则不会得到改变。默认会放到此集合中。通过tf.trainable_variables()可以查询。其op标示为GraphKeys.TRAINABLE_VARIABLES
Layer
A layer is a class implementing common neural networks operations, such as convolution, batch norm, etc. These operations require managing variables,losses, and updates, as well as applying TensorFlow ops to input tensors. Users will just instantiate it and then treat it as a callable. tf 自己定义几个 variable 乘一乘,然后直接用就行了,但对常用模型来说,这些都是重复工作。Layer是一组简单的可重复利用的代码,可以认为是一系列op的集合,与op一样也是输入tensor并输出tensor的。
# tensorflow/tensorflow/python/layers/base.py
class Layer(object):
def __init__(self, trainable=True, name=None, dtype=None,activity_regularizer=None, **kwargs):
self.trainable = trainable # Whether the layer should be trained (boolean).
self.built = False
self.input_spec = None # specifying the constraints on inputs that can be accepted by the layer.
self._trainable_weights = [] # List of trainable variables.
self._non_trainable_weights = [] # List of non-trainable variables.
self._updates = [] # List of update ops of this layer.
self._losses = [] # List of losses added by this layer.
self._reuse = kwargs.get('_reuse')
self._graph = ops.get_default_graph()
self._dtype = ... # Default dtype of the layer (default of `None` means use the type of the first input).
self._name = ... # The name of the layer (string).
self._scope = ...
def add_variable(self, name, shape, dtype=None,...):
...
variable = vs.get_variable(name,shape=shape,...)
if variable in existing_variables:
return variable
if trainable:
self._trainable_weights.append(variable)
else:
self._non_trainable_weights.append(variable)
return variable
def __call__(self, inputs, *args, **kwargs):
...
if not self.built:
self.build(input_shapes)
...
outputs = self.call(inputs, *args, **kwargs)
...
# Add an inbound node to the layer, so it can keep track of this call.
self._add_inbound_node(input_tensors=inputs, output_tensors=outputs, arguments=user_kwargs)
...
self.built = True
return outputs
# 一般由子类覆盖
def call(self, inputs, **kwargs):
return inputs
def apply(self, inputs, *args, **kwargs):
return self.__call__(inputs, *args, **kwargs)
执行逻辑 : Layer() ==> Layer.call ==> Layer.call。 这个其实也就是 机器学习中的forward 逻辑,至于backward 逻辑 则是在 OP 粒度 在数据流图层面 自动实现。
Dense Layer 实现了计算 outputs = activation(inputs * kernel + bias) 的逻辑。
# tensorflow/tensorflow/python/layers/core.py
class Dense(base.Layer):
def build(self, input_shape):
input_shape = tensor_shape.TensorShape(input_shape)
self.input_spec = base.InputSpec(min_ndim=2, axes={-1: input_shape[-1].value})
self.kernel = self.add_variable('kernel',shape=[input_shape[-1].value, self.units],...)
if self.use_bias:
self.bias = self.add_variable('bias',shape=[self.units,],...)
else:
self.bias = None
self.built = True
def call(self, inputs):
inputs = ops.convert_to_tensor(inputs, dtype=self.dtype)
...
outputs = standard_ops.matmul(inputs, self.kernel)
if self.use_bias:
outputs = nn.bias_add(outputs, self.bias)
if self.activation is not None:
return self.activation(outputs) # pylint: disable=not-callable
return outputs
def dense(inputs, units,activation=None,...):
layer = Dense(units,activation=activation,use_bias=use_bias,...)
return layer.apply(inputs)
Optimizer
整体实现
Tensorflow的底层结构是由张量组成的计算图。计算图就是底层的编程系统,每一个计算都是图中的一个节点,计算之间的依赖关系则用节点之间的边来表示。计算图构成了前向/反向传播的结构基础。给定一个计算图,前向部分 为张量读取与计算,表现为Variable的计算方法 和Layer的堆叠,TensorFlow 使用自动微分 (反向传播) 来进行梯度运算,再具体的说,自动求导的部分是靠 Optimizer 串起来的。tf.train.Optimizer允许我们通过minimize()函数自动进行权值更新,此时tf.train.Optimizer.minimize()做了两件事:
- 计算梯度。即调用
compute_gradients (loss, var_list …)计算loss对指定val_list的梯度,返回元组列表list(zip(grads, var_list))。 - 用计算得到的梯度来更新对应权重。即调用
apply_gradients(grads_and_vars, global_step=global_step, name=None)将compute_gradients (loss, var_list …)的返回值作为输入对权重变量进行更新;
将minimize()分成两个步骤的原因是:可以在某种情况下对梯度进行修正,防止梯度消失或者梯度爆炸。
# tensorflow/tensorflow/python/training/optimizer.py
class Optimizer(object):
def minimize(self, loss, global_step=None, var_list=None,...):
grads_and_vars = self.compute_gradients(loss, var_list=var_list, ...)
vars_with_grad = [v for g, v in grads_and_vars if g is not None]
return self.apply_gradients(grads_and_vars, global_step=global_step,name=name)
# Compute gradients of `loss` for the variables in `var_list
def compute_gradients(self, loss, var_list=None,...):
...
# 根据原本计算图中所有的 op创建一个顺序的list,然后反向遍历这个list,对每个需要求导并且能够求导的op(即已经定义好了对应的梯度函数的op)调用其梯度函数,然后沿着原本计算图的方向反向串起另一部分的计算图(输入输出互换,原本的数据 Tensor 换成梯度 Tensor)
grads = gradients.gradients(loss, var_refs, grad_ys=grad_loss,...)
grads_and_vars = list(zip(grads, var_list))
return grads_and_vars
# apply_gradients函数根据前面求得的梯度,把梯度更新到参数上
def apply_gradients(self, grads_and_vars, global_step=None, name=None):
converted_grads_and_vars = []
for g, v in grads_and_vars:
if g is not None:
# Convert the grad to Tensor or IndexedSlices if necessary.
g = ops.convert_to_tensor_or_indexed_slices(g)
# _get_processor函数可理解为一种快速更新variables的方法,每个processor都会包含一个update_op这样的函数来进行variable更新操作
p = _get_processor(v)
converted_grads_and_vars.append((g, v, p))
converted_grads_and_vars = tuple(converted_grads_and_vars)
var_list = [v for g, v, _ in converted_grads_and_vars if g is not None]
# 创建一些优化器自带的一些参数,比如AdamOptimizer的m和v
self._create_slots([_get_variable_for(v) for v in var_list])
update_ops = []
self._prepare()
for grad, var, processor in converted_grads_and_vars:
update_ops.append(processor.update_op(self, grad)) # 核心部分
if global_step is None:
apply_updates = self._finish(update_ops, name)
else:
with ops.control_dependencies([self._finish(update_ops, "update")]): # 用来控制计算流图的,给图中的某些节点指定计算的顺序
with ops.colocate_with(global_step): # 保证每个参数var的更新都在同一个device上
apply_updates = state_ops.assign_add(global_step, 1, name=name).op
train_op = ops.get_collection_ref(ops.GraphKeys.TRAIN_OP)
if apply_updates not in train_op:
train_op.append(apply_updates)
return apply_updates
def _resource_apply_sparse_duplicate_indices(self, grad, handle, indices):
# _deduplicate_indexed_slices 处理重复的index, 如果当前batch的行号是[0, 201, 201, 301],有重复的index号怎么办呢?其实只需将重复位置的梯度加起来即可(_deduplicate_indexed_slices)。
summed_grad, unique_indices = _deduplicate_indexed_slices(values=grad, indices=indices)
return self._resource_apply_sparse(summed_grad, handle, unique_indices)
def _create_slots(self, var_list):
pass
一个简单的总结,当调用 Optimizer.minimize 方法时,使用 compute_gradients 方法,实现反向计算图的构造;使用 apply_gradients 方法,实现参数更新的子图构造。参数更新子图以 grads_and_vars 为输入,执行梯度下降的更新算法;最后,通过 train_op 完成 global_step 值加 1,至此一轮 Step 执行完成。
compute_gradients
compute_gradients 将根据 loss 的值,求解 var_list=[v1, v2, …, vn] 的梯度,如果不传入var_list,那么默认就是所有trainable的variable。最终 返回的结果为:[(grad_v1, v1), (grad_v2, v2), …, (grad_vn, vn)]。其中,compute_gradients 将调用 gradients 方法,构造反向传播的子图,可以形式化地描述为
def compute_gradients(loss, grad=I):
vrg = build_virtual_reversed_graph(loss)
for op in vrg.topological_sort():
# 对每个正 向子图中的 OP 寻找其「梯度函数」
grad_fn = ops.get_gradient_function(op)
# 调用该梯度函数,该梯度函数将构造该 OP 对 应的反向的局部子图。
grad = grad_fn(op, grad)
def apply_gradients(grads_and_vars, learning_rate):
for (grad, var) in grads_and_vars:
# 对于每个 (grad_vi, vi),构造一个更 新 vi 的子图
apply_gradient_descent(learning_rate, grad, var)
综上述,正向的一个 OP 对应反向的一个局部子图,并由该 OP 的梯度函数负责构造。 一般地,梯度函数满足如下原型:
@ops.RegisterGradient("op_name")
def op_grad_func(op, grad)
对于一个梯度函数,第一个参数 op 表示正向计算的 OP,根据它可以获取正向计算时 OP 的输入和输出;第二个参数 grad,是反向子图中上游节点传递过来的梯度,它是一个 已经计算好的梯度值 (初始梯度值全为 1)。一般地,正向子图中的一个 OP,对应反向子图中的一个局部子图。因为,正向 OP 的 梯度函数实现,可能需要多个 OP 才能完成相应的梯度计算。例如,Square 的 OP,对应梯 度函数构造了包含两个 2 个乘法 OP。
@ops.RegisterGradient("Square")
def SquareGrad(op, grad):
x = op.inputs[0]
with ops.control_dependencies([grad.op]):
x = math_ops.conj(x)
return grad * (2.0 * x)
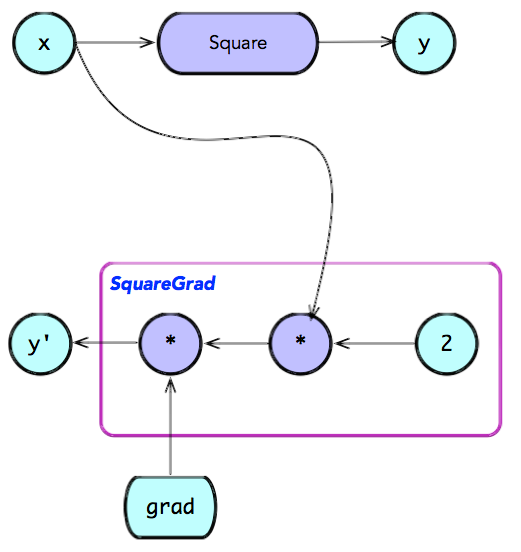
apply_gradients
《Tensorflow内核剖析》
class Optimizer(object):
def minimize(self, loss, var_list=None, global_step=None):
"""Add operations to minimize loss by updating var_list.
"""
grads_and_vars = self.compute_gradients(loss, var_list=var_list)
# 将梯度apply到变量上,具体梯度如何更新到变量,由 _apply_dense、_resource_apply_dense、_apply_sparse、_resource_apply_spars这四个方法实现。
return self.apply_gradients(grads_and_vars,global_step=global_step)
Optimizer 基类为每个实现子类预留了_create_slots(),_prepare(),_apply_dense(),_apply_sparse()四个接口出来,后面新构建的 Optimizer 只需要重写或者扩展 Optimizer 类的某几个函数即可。
apply_gradients()核心的部分就是对每个 variable 本身应用 assign,体现在update_ops.append(processor.update_op(self, grad))
# tensorflow/tensorflow/python/training/optimizer.py
def _get_processor(v):
"""The processor of v."""
if context.in_eager_mode():
return _DenseResourceVariableProcessor(v)
if v.op.type == "VarHandleOp":
return _DenseResourceVariableProcessor(v)
if isinstance(v, variables.Variable):
return _RefVariableProcessor(v)
if v.op.type == "SubmodelPort":
return _StreamingModelPortProcessor(v)
raise NotImplementedError("Trying to optimize unsupported type ", v)
class _DenseResourceVariableProcessor(_OptimizableVariable):
"""Processor for dense ResourceVariables."""
def __init__(self, v):
self._v = v
def target(self):
return self._v
def update_op(self, optimizer, g):
if isinstance(g, ops.IndexedSlices):
return optimizer._resource_apply_sparse_duplicate_indices(g.values, self._v, g.indices) # ==> _resource_apply_sparse
update_op = optimizer._resource_apply_dense(g, self._v)
return update_op
tensorflow分布式源码解读4:AdamOptimizer原生的tf 根据 梯度/grad 的类型 来决定更新weight/ variable 的方法,当传来的梯度是普通tensor时,调用_apply_dense方法去更新参数;当传来的梯度是IndexedSlices类型时,则去调用optimizer._apply_sparse_duplicate_indices函数。Embedding 参数的梯度中包含每个 tensor 中发生变化的数据切片 IndexedSlices。IndexedSlices类型是一种可以存储稀疏矩阵的数据结构,只需要存储对应的行号和相应的值即可。
# tensorflow/tensorflow/python/framework/ops.py
# This class is a simple wrapper for a pair of `Tensor` objects:
class IndexedSlices(_TensorLike):
def __init__(self, values, indices, dense_shape=None):
"""Creates an `IndexedSlices`."""
_get_graph_from_inputs([values, indices, dense_shape])
self._indices = indices # 前向传播中取的那几个位置,也就是最后要更新的那几个位置
self._values = values # 这些位置所对应的梯度值
self._dense_shape = dense_shape # 矩阵原本的形状
# tensorflow/tensorflow/python/framework/sparse_tensor.py
class SparseTensor(_TensorLike):
def __init__(self, indices, values, dense_shape):
...
self._indices = indices
self._values = values
self._dense_shape = dense_shape
如果在前向传播过程中用了 lookup 之类的函数取了一个 Tensor 中的几行,那最后得出来的梯度就会是 IndexedSlices。这样存储有什么好处呢?比如我们的model里面的10000010大小的embedding矩阵,当前来了个batch,lookup的index行号是[0, 201, 301],那么在更新整个embedding参数的时候,其实只需更新这三行的参数即可。所以IndexedSlices其实只存储了index = [0, 201, 301],和对应310大小的梯度。
GradientDescentOptimizer
来看一下更简单点的梯度下降法(实现Optimizer 暴露的抽象方法即可)
class GradientDescentOptimizer(optimizer.Optimizer):
def __init__(self, learning_rate, use_locking=False, name="GradientDescent"):
super(GradientDescentOptimizer, self).__init__(use_locking, name)
self._learning_rate = learning_rate
def _apply_dense(self, grad, var):
return training_ops.apply_gradient_descent(
var,
math_ops.cast(self._learning_rate_tensor, var.dtype.base_dtype),
grad,
use_locking=self._use_locking).op
def _resource_apply_dense(self, grad, handle):
return training_ops.resource_apply_gradient_descent(
handle.handle, math_ops.cast(self._learning_rate_tensor,
grad.dtype.base_dtype),
grad, use_locking=self._use_locking)
def _resource_apply_sparse_duplicate_indices(self, grad, handle, indices):
return resource_variable_ops.resource_scatter_add(handle.handle, indices, -grad * self._learning_rate)
def _apply_sparse_duplicate_indices(self, grad, var):
delta = ops.IndexedSlices(
grad.values *
math_ops.cast(self._learning_rate_tensor, var.dtype.base_dtype),
grad.indices, grad.dense_shape)
return var.scatter_sub(delta, use_locking=self._use_locking)
def _prepare(self):
self._learning_rate_tensor = ops.convert_to_tensor(self._learning_rate,name="learning_rate")
Graph数据结构
Tensorflow源码解析3 – TensorFlow核心对象 - Graph 在Python前端中,Operation表示Graph的节点,Tensor表示Graph的边。
# tensorflow/tensorflow/python/framework/ops.py
class Graph(object):
def __init__(self):
self._lock = threading.Lock() # 加线程锁,使得注册op时,不会有其他线程注册op到graph中,从而保证共享graph是线程安全的
# op相关数据。
# 为graph的每个op分配一个id,通过id可以快速索引到相关op。故创建了_nodes_by_id字典
self._nodes_by_id = dict() # GUARDED_BY(self._lock)
self._next_id_counter = 0 # GUARDED_BY(self._lock)
# 同时也可以通过name来快速索引op,故创建了_nodes_by_name字典
self._nodes_by_name = dict() # GUARDED_BY(self._lock)
self._version = 0 # GUARDED_BY(self._lock)
# tensor相关数据。
self._handle_feeders = {} # 处理tensor的placeholder
self._handle_readers = {} # 处理tensor的read操作
self._handle_movers = {} # 处理tensor的move操作
self._handle_deleters = {} # 处理tensor的delete操作
# graph添加op
def _add_op(self, op):
self._check_not_finalized() # graph被设置为final后,就是只读的了,不能添加op了。
with self._lock: # 保证共享graph的线程安全
# 将op以id和name分别构建字典,添加到_nodes_by_id和_nodes_by_name字典中,方便后续快速索引
self._nodes_by_id[op._id] = op
self._nodes_by_name[op.name] = op
self._version = max(self._version, op._id)
每个Operation节点都有一个特定的标签,从而实现节点的分类。相同标签的节点归为一类,放到同一个Collection中。标签是一个唯一的GraphKey
class Operation(object):
def __init__(self,node_def,g,inputs=None,...):
self._graph = g # graph引用,通过它可以拿到Operation所注册到的Graph
# inputs
if inputs is None:
inputs = []
# input types
if input_types is None:
input_types = [i.dtype.base_dtype for i in inputs]
control_input_ops = []
# node_def和op_def是两个最关键的成员
if not self._graph._c_graph:
self._inputs_val = list(inputs) # Defensive copy.
self._input_types_val = input_types
self._control_inputs_val = control_input_ops
# NodeDef,深复制
self._node_def_val = copy.deepcopy(node_def)
# OpDef
self._op_def_val = op_def
# outputs输出
self._outputs = [
Tensor(self, i, output_type)
for i, output_type in enumerate(output_types)
]
def name(self):
return self._node_def_val.name
def _id(self):
return self._id_value
def device(self):
return self._node_def_val.device
def node_def(self): # NodeDef成员,获取Operation的动态属性信息,例如Operation分配到的设备信息,Operation的name等
return self._node_def_val
def op_def(self): # OpDef,获取Operation的静态属性信息,例如Operation入参列表,出参列表等
return self._op_def_val
Tensor中主要包含两类信息,一个是Graph结构信息,如边的源节点和目标节点。另一个则是它所保存的数据信息,例如数据类型,shape等。
class Tensor(_TensorLike):
def __init__(self, op, value_index, dtype):
self._op = op # 源节点,tensor的生产者,会计算得到tensor
# tensor在源节点的输出边集合中的索引。源节点可能会有多条输出边
self._value_index = value_index # 利用op和value_index即可唯一确定tensor。
self._dtype = dtypes.as_dtype(dtype) # tensor中保存的数据的数据类型
self._shape_val = tensor_shape.unknown_shape() # tensor的shape,可以得到张量的rank,维度等信息
self._consumers = [] # 目标节点列表,tensor的消费者,会使用该tensor来进行计算
self._handle_data = None
self._id = uid()
Tensorflow代码解析(三) python 部分
# 在Python脚本中定义matmul运算
tf.manual(a,b)
# 根据Ops名称MatMul从Ops库中找出对应Ops类型
_op_def_lib.apply_op('MatMul',a=a,b=b,...)
# ops/op_def_library.py
# 创建ops节点
graph.create_op(op_type_name,inputs,output_types,...)
# framework/ops.py
# 创建ops节点并指定相关属性和设备分配
node_def = _NodeDef(op_type,name,device=None,attrs=attrs)
ret = Operation(node_def,self,inputs=inputs,...)
其它
从论文源码学习 之 embedding层如何自动更新 讲的也而非常细、好。
- 前向求导关注的是输入是怎么影响到每一层的,反向求导则是关注于每一层是怎么影响到最终的输出结果的。自动求导就是每一个op/layer自己依据自己的输入和输出做前向计算/反向求导,而框架则负责组装调度这些op/layer,表现出来就是你通过框架去定义网络/计算图,框架自动前向计算并自动求导。TensorFlow的求导,实际上是先提供每一个op求导的数学实现,然后使用链式法则求出整个表达式的导数。
- 当你定义好了一个神经网络,常见的深度学习框架将其解释为一个dag(有向无环图),dag里每个节点就是op,从loss function这个节点开始,通过链式法则一步一步从后往前计算每一层神经网络的梯度,整个dag梯度计算的最小粒度就是op的 backward 函数(这里是手动的),而链式法则则是自动的。
- 构图的时候只需要写完前向的数据流图部分,TensorFlow 的做法是每一个 Op 在建图的时候就同时包含了它的梯度计算公式,构成前向计算图的时候会自动建立反向部分的计算图,前向计算出来的输入输出会保留下来,留到后向计算的时候用完了才删除。
Tensorflow代码解析(一)反向计算限制了符号编程中内存空间复用的优势,因为在正向计算中的计算数据在反向计算中也可能要用到。从这一点上讲,粗粒度的计算节点比细粒度的计算节点更有优势,而TF大部分为细粒度操作,虽然灵活性很强,但细粒度操作涉及到更多的优化方案,在工程实现上开销较大,不及粗粒度简单直接。在神经网络模型中,TF将逐步侧重粗粒度运算。
留下评论