不同层面的异步
简介
如何定义一个系统的性能,参见性能调优攻略
Servlet 3.0 实战:异步 Servlet 与 Comet 风格应用程序
2018.9.26补充,《左耳听风》提到:异步系统主要通过消息队列来对请求做排队处理,把调用方请求的“峰值”给削平了,后端通过自己能够处理的速度来处理请求。这样会增加系统的吞吐量,但实时性就差很多。同时还会引入消息丢失的问题,所以要对消息做持久化,这会造成“有状态”的节点,从而增加服务调度的难度。
2019.1.24补充:异步实现绝大多数时候离不开队列和回调,刚好对应操作系统的 task_struct[] 和 中断处理。
异步的价值
为什么异步web可以提高吞吐量
首先,异步不是突然出现一个异步就牛了,而是一系列手段加持的结果
- 长连接
- Web 线程不需要同步的、一对一的处理客户端请求,能做到一个 Web 线程处理多个客户端请求。同步的实质是线程数限制了连接数,假设tomcat有100个线程,某个请求比较耗时,那么第101个请求就无法创建连接。
举个例子,一个请求建立连接要1s,请求处理要1s,每秒到达100个请求。
| 同步 | 异步 | |
|---|---|---|
| 第1s | 100个请求连接成功 | 100个请求连接成功 |
| 第2s | 100个请求处理成功 | 100个请求连接成功,100个请求处理成功 |
| 第3s | 100个请求连接成功 | 100个请求连接成功,100个请求处理成功 |
| 第4s | 100个请求处理成功 | 100个请求连接成功,100个请求处理成功 |
| 4s小计 | 处理200个请求,50qps | 100个请求连接成功,300个请求处理成功,65qps |
三高
深入剖析通信层和 RPC 调用的异步化(上) 值得读N遍。
传统同步阻塞通信(BIO)面临的主要问题如下:
- 性能问题:一连接一线程模型导致服务端的并发接入数和系统吞吐量受到极大限制。
- 可靠性问题:由于 I/O 操作采用同步阻塞模式,当网络拥塞或者通信对端处理缓慢会导致 I/O 线程被挂住,阻塞时间无法预测。
- 可维护性问题:I/O 线程数无法有效控制、资源无法有效共享(多线程并发问题),系统可维护性差。
《从0开始学架构》笔记 提到设计任何架构都要考虑“三高”,由此看,使用异步也是“三高”的需要。
线程资源是系统中非常重要的资源,在一个进程中线程总数是有限制的,提升线程使用率就能够有效提升系统的吞吐量,在同步 RPC 调用中,如果服务端没有返回响应,客户端业务线程就会一直阻塞,无法处理其它业务消息。
应用场景
- 缩短长流程的调用时延
- 服务调用耗时波动较大场景。RPC 调用的超时时间配置是个比较棘手的问题。如果配置的过大,一旦服务端返回响应慢,就容易把客户端挂死。如果配置的过小,则超时失败率会增加。通过异步 RPC 调用,就不用再担心调用方业务线程被阻塞,超时时间可以相应配置大一些,减少超时导致的失败。
- 第三方接口调用,对于大部分的第三方服务调用,都需要采用防御性编程,防止因为第三方故障导致自身不能正常工作。Hystrix 的第三方故障隔离就是采用类似机制,只不过它底层创建了线程池,通过 Hystrix 的线程池将第三方服务调用与业务线程做了隔离,实现了非侵入式的故障隔离。此处,“通过线程池实现调用线程和业务线程隔离”的表述很有感觉。
- 性能和资源利用率提升,尤其针对io密集型的rpc服务,所谓的效率提升就是从io等待的时间中挖来的。
异步编程的在各个层面的支持
| 特性 | 效果 | 备注 | |
|---|---|---|---|
| 操作系统 | |||
| NIO | 利用 Selector 的轮询以及 I/O 操作的非阻塞特性 | 使用更少的 I/O 线程处理更多的客户端连接 | |
| Netty | NIO + 队列 + 线程池 | 异步 + io回调 | 单纯NIO还是同步IO(只是说进行了IO复用),Netty在语言层实现了操作系统层的AIO效果 |
| rpc | 异步 + 业务回调 | ||
| 业务层,比如Java8 的 CompletableFuture | 对多个异步操作结果进行逻辑编排 |
业务代码
public class Client{
private Executor executor;
Future<String> hello(final String name){
Future<String> future = executor.subimit(new Callable<String>(){
public String call(){
return "hello " + name;
}
});
return future;
}
}
通过聚合一个Executor, 外部调用时,client就可以给人支持异步接口的感觉
Future<String> future = client.hello();
纯异步接口通过添加listener 或callback,也能构成复杂的业务逻辑。
public class Busienss{
private Client client;
public Future<String> greet(String name){
Future<String> future = new xx;
Future<String> clientFuture = client.hello(name);
clientFuture.addSuccessListener(new onSuccess(String clientResult){
String result = handle(clientResult);
future.set(result)
});
return future;
}
private String handle(String clientResult){
return clientResult + ", greet you";
}
}
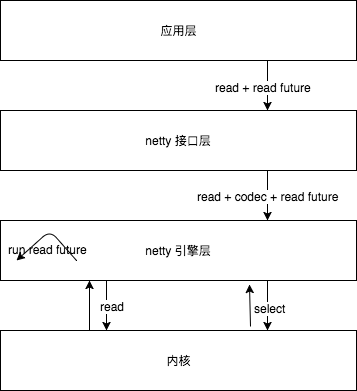
操作系统和语言层面
强烈推荐这篇文章有关异步编程框架的讨论,基本要点:
-
操作系统就像一个大型的中断处理库。cpu响应中断,运行中断处理程序。操作系统为了最大化利用cpu,一个进程在等待I/O时,另一个进程可以利用CPU进行计算。因此,进行阻塞操作时,进程会执行Schedule让出对cpu的控制权(goroutine也是如此),io设备操作完成后通过中断 ==> 中断处理函数(很像异步回调函数) 告知进程。中断提供了 进程 调用的外设的 异步执行机制。
while(true){ 执行任务 // 因为时间片限定,执行时间不长 执行任务期间,有中断{ 保存上下文 执行中断处理程序 } 如果任务完毕,结束 } - 虽然知道计算机组成原理,但还是经常误以为计算机只有cpu可以“驱动”逻辑。实际上,cpu触发网络io操作后,自有网卡当组件负责实际的io读写,并在结束时通知cpu。类比下文的rpc框架实现的话,cpu是业务线程,网卡是io线程。从这个角度看,上层和底层实现异曲同工。
-
从业务方线程的立场看,肯定想一直占用cpu。但如果线程直接执行的代码中,调用了可能阻塞的系统调用,失去cpu就在所难免。
- golang直接实现了一个调度器,碰上阻塞操作(重写了阻塞操作的逻辑,不会直接调用系统调用),挂起的是goroutine,实际的物理线程执行下调度程序,找下一个goroutine接着跑。
- python twisted, Java Netty, Nodejs libuv 这些框架没有深入到语言层,没办法推翻重来(r/w或者nio的select操作还是得调用系统调用),而是做一个自己的事件驱动引擎。
-
事件驱动引擎。业务操作分为阻塞操作(差不多就是io操作)和非阻塞操作
- 通过重构整体逻辑,自由控制阻塞和非阻塞操作比例。比如netty eventloop中有io ratio
- 将阻塞操作和非阻塞操作 分派给不同的线程池来执行,甚至io操作分门别类给不同的线程池来执行,比如netty中的boss和worker。
- 异步编程与顺序编程差异非常大,代码要重新组织,将业务逻辑分派在不同的线程中(有点分布式系统中把任务分发到不同node的感觉,每个node上也跑了一个任务执行引擎),并对中间结果进行组合/编排。
文章最后小结提到:其实从某种程度来说,异步框架是程序试图跳出操作系统界定的同步模型,重新虚拟出一套执行机制,让框架的使用者看起来像一个异步模型。另外通过把很多依赖操作系统实现的笨重功能换到程序内部使用更轻量级的实现。 全面异步化:淘宝反应式架构升级探索 提到:异步化会将操作系统中的队列情况显式地提升到了应用层,使得应用层可以显式根据队列的情况来进行压力负载的感知。
通信层面——以netty 为例
2018.6.30 补充。拿netty 和 go 类比一下,可以看到,调用go语言的阻塞方法(io方法不确定是不是这样),相当于
read(){
保存上下文
让出goroutine 执行权
}
go 中实际的 阻塞 操作实际是go语言层完成的,goroutine 调度本身是对 内核系统调用的模仿。只是软中断变成了方法调用,线程阻塞改成 goroutine 阻塞。
netty 因为不能改写 io 语言的系统调用,为此 不敢向你直接暴露 io 方法,封装了一个channel 出来,你调用channel.write() 不是真正的java.nio.channels.SocketChannel.write。 所以netty 也只能提供 一个 单独的层次,与上图竖着画驱动线程与事件驱动引擎(线程)的关系不同
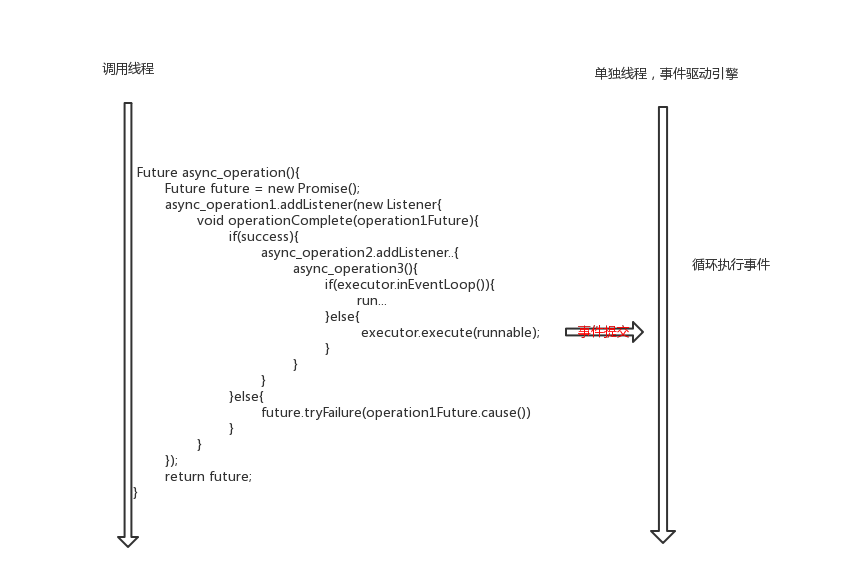
相当于netty 提供了一个全异步 io 操作(也包括一般的任务执行)的抽象层,支持类似AIO的”系统调用“。所以上图竖着画,就是另一番滋味了。
rpc 层
RPC 框架异步调度模型
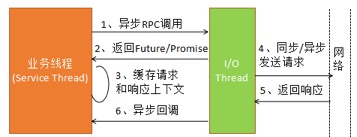
异步 RPC 调用的关键点有 2 个:
- 不能阻塞调用方线程
- 请求和响应的上下文关联,大部分二进制协议的 TCP 链路都是多路复用的,请求和响应消息的发送和接收顺序是无序的。所以,异步 RPC 调用需要缓存请求和响应的上下文关联关系,以及响应需要使用到的消息上下文。
请求和响应的上下文缓存 相当于rpc 层与io 通信层的 “缓冲层”,双方各干各的。
rpc层 的异步实现
-
直接使用异步框架,异步直接反应在接口上。Future/Promise,比较常用的有 JDK8 之前的 Future,通过添加 Listener 来做异步回调,JDK8 之后通常使用 CompletableFuture,它支持各种复杂的异步处理策略,例如自定义线程池、多个异步操作的编排、有返回值和无返回值异步、多个异步操作的级联操作等。
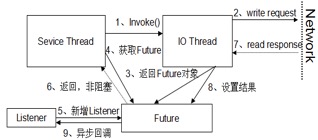
-
业务逻辑不动,异步分装。线程池 +RxJava,最经典的实现就是 Netflix 开源的 Hystrix 框架,使用 HystrixCommand(创建线程池)做一层异步封装,将同步调用封装成异步调用,利用 RxJava API,通过订阅的方式对结果做异步处理
异步化在工程上的推进
| io通信层 | 业务处理 | |
|---|---|---|
| tomcat | nio/bio | servlet |
| rpc server base on netty | nio | xxHandler |
不同层次的同步异步之间,没有必然关系。future 因为分层之间本质关联的是数据(回调的本质是下层给上层传递数据),不是数据的获取方式。异步也是要拿到结果的,这一点与同步没有差异。
tomcat 和 异步servlet
Tomcat 支持 NIO,与 Tomcat 的 HTTP 服务是否是异步的,没有必然关系。
- HTTP 消息的读写:即便采用了 NIO,HTTP 请求和响应的消息处理(也就是业务处理部分)仍然可能是同步阻塞的,这与协议栈的具体策略有关系。
- 每个响应对象只有在 Servlet 的 service 方法或 Filter 的 doFilter 方法范围内有效,该方法一旦调用完成,Tomcat 就认为本次 HTTP 消息处理完成,它会回收 HttpServletRequest 和 HttpServletResponse 对象再利用,如果业务异步化之后再处理 HttpServletResponse,拿到的实际就不是之前请求消息对应的响应,会发生各种非预期问题
如果使用的是支持 Servlet3.0+ 版本的 Tomcat,可以开启异步处理模式。Servlet3 之前一个 HTTP 请求消息的处理流程,包括:HTTP 请求消息的解析、Read Body、Response Body,以及后续的业务逻辑处理都是由 Tomcat 线程池中的工作线程处理。Servlet3 之后可以让 I/O 线程和业务处理线程分开,进而对业务做隔离和异步化处理。还可以根据业务重要性进行业务分级,同时把业务线程池分类,实现业务的优先级处理,隔离核心业务和普通业务,提升应用可靠性。PS: 从这个角度,tomcat异步实现与rpc框架实现是一样一样的。
Servlet3.1 以后增加了对非阻塞 I/O 的支持,根据 Servlet3.1 规范中描述:非阻塞 I/O 仅对在 Servlet 中的异步处理请求有效。Servlet3.1 对非阻塞 I/O 的支持是对之前异步化版本的增强,配套 Tomcat8.X 版本。
springmvc 异步化

SpringMVC 支持多种异步化模式,常用的有两种:
-
Controller 的返回值为 DeferredResult, Controller 方法内构造 DeferredResult 对象,然后将请求封装成 Task 投递到业务线程池中异步执行,业务执行完成之后,构造 ModelAndView,调用 deferredResult.setResult(ModelAndView) 完成异步化处理和响应消息的发送。
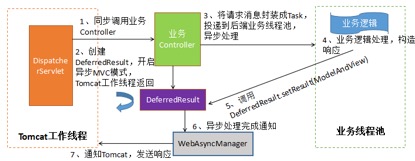
-
Controller 的返回值为 WebAsyncTask,实现 Callable, 在 call 方法中完成业务逻辑处理,由 SpringMVC 框架的线程池来异步执行业务逻辑(非 Tomcat 工作线程)。
rpc 框架异步化
RPC 异步与 I/O 的异步没有必然关系,当 RPC 调用请求消息发送到 I/O 线程的消息队列之后,业务线程就可以返回,至于 I/O 线程采用同步还是异步的方式读写消息,与 RPC 调用的同步和异步没必然的关联关系。当然,在大多数场景下,RPC 框架底层会使用异步 I/O,实现全栈异步, 整体性能和可靠性会更好一些。
Apache ServiceComb/gRPC
技术难点
- 异步异常传递
- 超时控制
- 上下文传递,传统的同步 RPC 调用时,业务往往通过线程变量来传递上下文,例如:TraceID、会话 Session、IP 等信息。
- 回调地狱问题,如果使用的是 JDK8 的 CompletableFuture,它支持对异步操作结果做编排以及级联操作
异步的作用是释放阻塞的线程,用来处理其它的任务,等阻塞的资源准备就绪后再处理。这样能提高系统的吞吐,因为等待的时间减少了。但是这相当于隐式地使用了“无限”的缓冲,用来存储处于等待状态的任务。由此带来的问题就是:队列满了(资源用完了)怎么办?或者即使队列未满但等待时间过长了怎么办?所以要进行流量控制(背压、丢弃)
小结
异步为什么性能更好?
- 在开发层面给予更多选择,可以不让线程让出cpu。开发者往往比操作系统知道怎样更高效利用线程。这也是java、netty中一脉相承的思路,比如AQS、CAS来减少线程切换,common-pool、netty中的arena手动管理内存。
- 事件驱动引擎是一种编程模型,可以不处理io事件。但加入io事件的处理后,select集中等待,并可以在io任务和cpu任务中控制开销比例,进而可以做到更高效。
留下评论