当我在说PaaS时,我在说什么
简介
2023
一个paas 包括以下几个部分
- 工作流。工作流是一个偏上层的概念,先发哪再发哪,几个实例,再发几个实例,流量先切多少,再切多少。下一层负责当前阶段意图的具体实现,比如实例配置、发到哪个集群。workflow vs 手工管理
- 多集群。
- Workload 在联邦层要有一个抽象/载体。
- 集群调度。
- 应用管理
- 应用配置。包括label、运行时,挂载资源等。
- 应用的载体 1. 描述应用本身,deployment 不够,openkruise 的cloneset。 2. 应用的运维,比如hpa 等组件。一个应用会对应一个workload 集合。
- 应用渲染 1. Kubevela 表达应用的方式是:所有属性都是kv,内部建立deployment/cloneset 模版引用kv,最后渲染成workload crd。 2. 常见方式是,给用户提供表达ui,定义view struct,view struct 转为 crd struct。
- 给用户提供一个paas界面,假设支持100个操作(工作流的价值之一就是可以规范这些动作),有两种实现方式 1. 每种操作对应一个或多个k8s 原生对象的增删改 2. 几乎所有操作只对应 一个object 的增删改,主要是改。
一次应用部署要解决哪些问题
- 一次应用部署由哪些部分构成
- 如何构建workload?镜像、configmap、端口,资源。workload 静态配置
- 如何分发worklaod?部署到哪里,甚至多个集群分别部署几个实例
- 如何访问worklaod?流量管理
- 上述配置有一部分想抽成模版,以便复用。哪些要经常应用间复用、哪些是应用独有的?哪些经常变,哪些不经常变?
- 应用部署完成后,有一些部署后才知道的状态,比如ip、实例名等
- 一次应用部署 由上述多个 领域的概念揉和组成,构建workload = workload 静态配置 + 目标集群+ 流量管理 + 模版配置。
- 是统一弄一个静态模版以此构建worklaod,还是每次构建workload时东拼西凑?
- 上述领域配置可能会更新,但应用部署一旦执行 需要固化应用部署时的状态 以便追溯,因此要上述配置要维护多版本。
实现架构
- 基于db 实现 workfow 和step,k8s 只是一种数据源:一次发布会对应一系列的任务,如:初始化环境,构建镜像,分批发布等等。这些任务会被有序地扔给 JAVA Executor 来进行实际的业务逻辑,比如,往 Kubernetes 中下发资源,以及与 MySQL 数据库进行当前任务的状态同步,等等。在当前的任务完成后,JAVA Executor 会从 任务库/编排引擎中获取下一个任务。这个架构中最大的问题就在于轮询调用, JAVA Executor 会每隔一秒从 任务列表中进行获取,查看是否有新任务;同时,JAVA Executor 下发了 Kubernetes 资源后,也会每隔一秒尝试从集群中获取资源的状态。
- 并不是 Kubernetes 生态中的控制器模式,如果将编排引擎层升级为事件监听的控制器模式,就能更好地对接整个 Kubernetes 生态,同时提升效率。
- 如果使用的是传统的以容器为基础下发的云原生工作流的话(很多活儿用容器干,比如打镜像),就需要将原本的业务逻辑打包成镜像,维护并更新一大堆镜像制品
- 基于k8s 实现 workfow 和step,crd 部分具有监听能力 : 创建了发布单之后,业务侧会将模型写入数据库,进行模型转换,生成一条 KubeVele Workflow,KubeVela Workflow 在执行时,每个步骤都是 IaC 化的,底层实现是 CUE 语言。这些步骤有的会去调用 业务微服务 API,有的则会直接与底层 Kubernetes 资源进行交付。而步骤间也可以进行数据传递。如果调用出错了,可以通过步骤的条件判断,来进行错误处理。
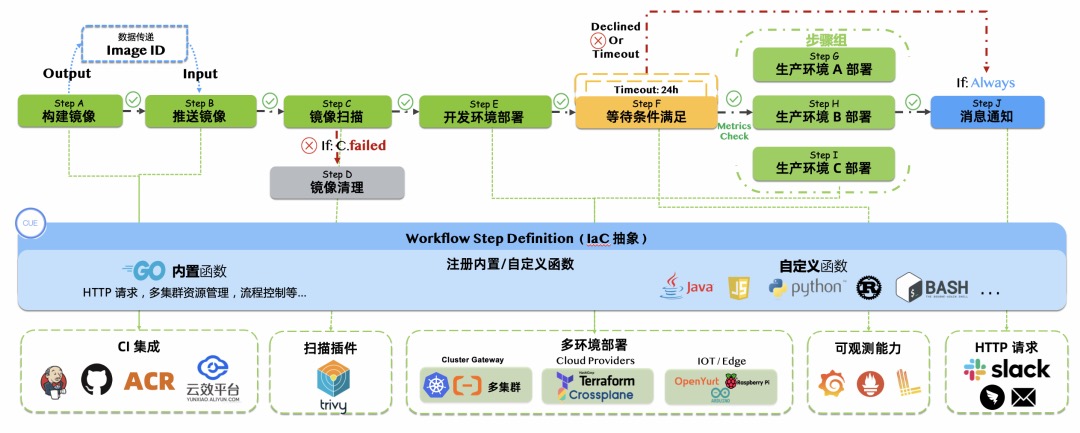
- 基于db 和事件驱动实现。对第二点的泛化。
Pets vs Cattle 以及数据中心时代
本小节内容来自 《Container-Networking-Docker-Kubernetes》笔记
DevOps Concepts: Pets vs Cattle
想让服务可靠,有两种方式:把机器搞可靠;部署多个实例。
| 特点 | 详情 | Examples | |
|---|---|---|---|
| Pets | scale up | you trait the machines as individuals,you gave each (virtual)machine a name. when a machine gets ill you nurse it back to health and manually redeploy the app. | mainframes, solitary servers, load balancers and firewalls, database systems, and so on. |
| Cattle | scale out | your machines are anonymous;they are all identical,they have numbers rather than names, and apps are automatically deployed onto any and each of the machines. when one of the machines gets ill, you don’t worry about it immediately | web server arrays, no-sql clusters, queuing cluster, search cluster, caching reverse proxy cluster, multi-master datastores like Cassandra, big-data cluster solutions, and so on. |
PS:the Cloud Age, virtualized servers that are programmable through a web interface。
with the cattle approach to managing infrastructure,you don’t manually allocate certain machines for running an application.Instead,you leave it up to an orchestrator to manage the life cycle of your containers. 一个服务部署多个(几十个/上百个)实例带来许多挑战:如何部署?如何发现?挂了怎么办(总不能还靠人工)?通常依靠一个资源管理和调度平台辅助管理,如何选用和部署这个调度平台?从 “Evolution of Cattle” 的视角来看待 运维技术的演进。
| 描述 | technologies | 部署cattle service需要什么 | 备注 | |
|---|---|---|---|---|
| Iron Age | 物理机 | Robust change configuration tools like Puppet (2005), CFEngine 3 (2008), and Chef | ||
| The First Cloud Age | IaaS that virtualized the entire infrastructure (networks, storage, memory, cpu) into programmable resources. | Amazon Web Services (2006), Microsoft Azure (2010), Google Cloud Platform | push-based orchestration tools like Salt Stack (2011), Ansible (2012), and Terraform (2014). | |
| The Second Cloud Age | virtualize aspects of the infrastructure,This allows applications to be segregated into their own isolated environment without the need to virtualize hardware, which in turn duplicates the operating system per application. | OpenVZ (2005), Linux Containers or LXC (2008), and Docker (2015). | A new set of technologies evolved to allocate resources for containers and schedule these containers across a cluster of servers:Apache Mesos (2009), Kubernetes (2014), Nomad (2015), Swarm | Immutable Production(应用的每一次更改都是重新部署,所以本身是Immutable),disposable containers are configured at deployment. 容器在部署的时候被配置 |
PaaS
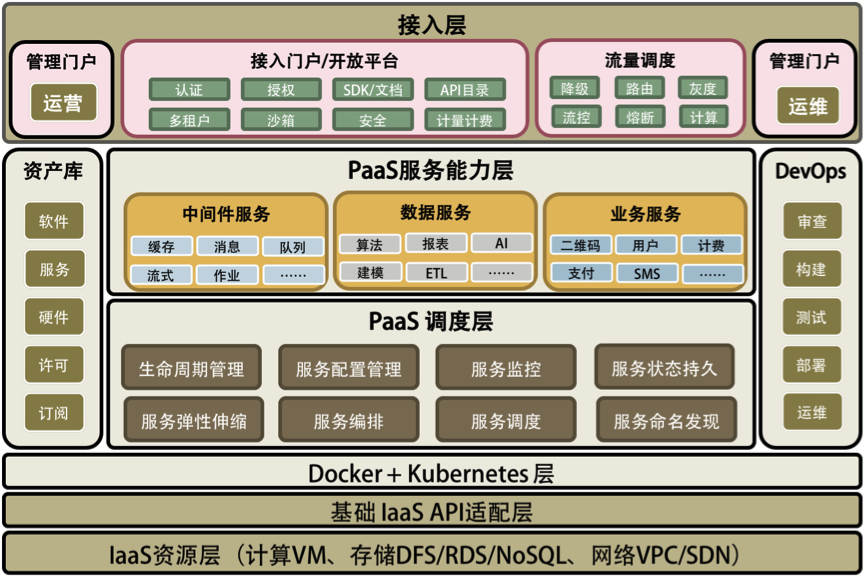
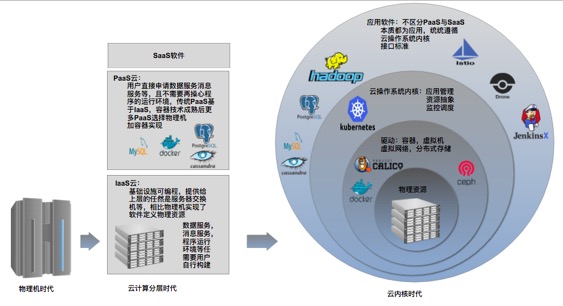
基本可以总结出如下几点:
-
PaaS 由IPaaS 和 APaaS 组成
- IPaaS提供服务编排、调度、监控、发现、弹性伸缩等,使得服务本身可以可靠 和 高性能运行。
- APaaS提供消息队列、分布式计算、存储、缓存等中间件,一个是为服务提供存储等基本资源;一个是为服务之间 提供交互手段,毕竟不像单机进程或线程通信那么方便了。
- APaaS 需要 IPaaS 提供支持,因为消息队列、分布式计算等本身也是一种服务
-
多租户弹性是PaaS区别于传统应用平台的本质特性
- 多租户,一个软件系统可以同时被多个实体所使用,每个实体之间是逻辑隔离、互不影响的。
- 弹性(Elasticity)是指一个软件系统可以根据自身需求动态的增加、释放其所使用的计算资源。
多租户有如下几种实现方式:
- Shared-Nothing
- Shared-Hardware,共享物理机,即以拟机是弹性资源调度和隔离的最小单位
- Shared-OS,共享操作系统,进程是弹性资源调度和隔离的最小单位
- Shared-Everything,基于元数据模型以共享一切资源
不准确的说,可以认为PaaS 是一个基于集群的操作系统,在这个操作系统中:
- “程序”文件如何表示。因为在分布式环境下,还涉及到”程序”文件分发的问题。
- “进程”如何体现
- “磁盘”如何体现,“进程”如何访问“磁盘”
- “进程”之间如何通信
结合上文、docker + k8s,会对这几个问题有一些体会。
自己的理解
与IaaS对比起来,可以看作是服务化层次 不同的问题。
办一个酒席有哪些事情
- 原材料,菜、烟、酒
- 桌椅板凳等
- 知客
- 传菜员、厨师、刷碗等
农村酒席的演变
- 自己去菜市场买菜、去批发市场买酒、去请厨子、联系帮忙的、去租座椅板凳,资源都在,被动的等你去取用。
- 出现承包队,自带桌椅板凳、厨师、传菜员等,但仍需要你根据购物清单来购买原料
- 在酒店办酒席,你只需告知菜单即可,八大菜系、酒席档次、大厅装修(有没有投影等)均可以指定。
IAAS,一个物理机或者一堆物理机/虚拟机,能给你提供什么?运行服务所需的基本资源。IaaS只关注解决基础资源云化问题(把裸卡组装成服务器、连成网络、做好运维和管理,一般也包括大规模存储系统),解决的主要是IT问题(其实就三件事:计算、通信、存储。IaaS 就是覆盖这三大件)。类似的只是解决了你村里有没有(有多大)一个菜市场、批发市场的问题,但买菜的事儿还是要你自己干。
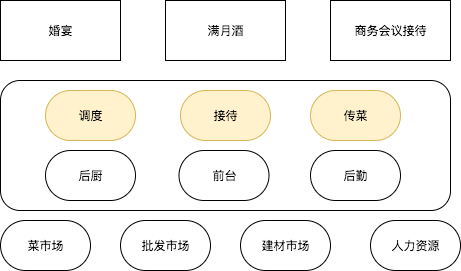
PaaS 则类似于 在酒店办酒席(调度平台、资源管控平台)
- 资源可以共用,包括物理资源,比如厨师、服务员、大厅等;软性资源,上菜次序、接待经验等,酒店可以同时接待多家客户的酒席。
- 一些要素参数化(学名叫服务化的能力供应),比如你指定川菜即可,不用亲自购买相关的原料。
- 动态调配,比如你临时加一桌,则酒店在全局范围内为你调配资源,无需你再去菜市场、批发市场跑一圈
- 要素监控,比如由酒店确保食物卫生,大厅的投影没有故障,足够的传菜员等。
这其中,承包队的作用便是:用户教育。先找一个点切入,再扩展至全局。 因为没有任何一家公司上来就按照完整的paas 来搭建运维体系。
运维的同学都知道,一般公司内的服务器会分为 应用集群、数据集群等,分别用来跑业务应用 和 大数据组件(比如hadoop、spark)等。为何呢?一个是物理机配置不一样;一个是依赖服务不一样,比如应用集群每台主机都会配一个日志采集监控agent,数据集群每台主机也有类似的agent,但因为业务属性不一样,监控的侧重点不一样,所以agent 逻辑不一样。进而,应用集群的服务 不可以随便部署在 数据集群的机器上。容器云之后,服务可以随意编排和移动, 那么物理机就单纯是提供计算了, 服务是否部署在某个机器上 只跟这个机器是否空闲有关,跟机器的划分(应用集群还是大数据集群)无关了。这个技术在阿里已经落地了数据中心日均 CPU 利用率 45% 的运行之道–阿里巴巴规模化混部技术演进
《Paas实现与运维管理》 笔记
对计算、网络和存储三大资源的管理就是运维,将运维需求进行整理,将这部分工作标准化、自动化,才能对上提供服务自API接口,集合配置管理和服务管理构建一个完备的PaaS平台。PaaS是技术实现与管理规约的双层结合。
paas,对于运维人员来说,就是将管理的内容从一系列的硬件物理机(装系统,zabbix监控等)转换为维护一个pass平台正常运行。对于开发来说,部署,从一个通知运维的过程(比较大的项目,或许还要写一个文档,盯着运维一起干),变成了自己到pass平台上提交等。
运维需求
-
软件配置
“进程”这个概念是人们抽象出来的,并没有一个客观的实体与之对应(比如block对应一个存储区域)。观察linux的进程结构体,可以看到,它包含了运算所需要一系列资源的指针(比如文件描述符)。同理,一个软件配置,包括程序、文档,运行环境等
-
服务部署,决定将一个服务部署在哪台机器上。
这个机器是否符合服务的要求(cpu,内存),有依赖的服务是否要部署在一起等
- 服务发现
- 监控恢复
资源的提供方式要提供一定的标准
| 资源分配的表现形式 | ||
|---|---|---|
| 计算 | 将原始任务拆分,子任务并行化 | |
| 存储 | 将分散的存储空间聚合成一个逻辑上的、可不断扩展的大存储 | |
| 网络 | 服务的互联与隔离、防火墙策略等 |
docker
我们从paas这个大概念下来理解docker的小概念。docker有以下特性特别适合干这个事
- 代码和环境相结合,以image的形式存在。代码通过docker registry + docker pull的形式,在各个host中流动
- 以容器的方式运行。其实你细看下公司tomcat的配置,大多数时候每个项目一个tomcat,tomcat配置最大jvm内存等,也是以容器的方式存在并运行。而容器的管理与监控,要比直接管理(增删改查)和监控一个tomcat进程方便。
留下评论