做配置中心要想好的几个基本问题
简介
阅读本文时,可以先查看 平台支持类系统的几个点。配置中心 本质上也属于一个平台支持系统,很多设计问题 也是平台支持系统 面临的问题。
本文是从客户端和服务端两个方面一起说配置中心,大部分开源配置中心只关注服务端配置中心。
需求
- 客户端:app启动时,访问客户端配置中心,拉取一系列开关、数值等配置
- 服务端:业务模块启动时,访问服务端配置中心,拉取一系列开关、数值等配置并注册监听事件。业务无需 重启 便可以应用配置
工程层面
- 如何表示配置
- 如何存储配置
- 发布/回滚配置
- 配置的下发 ==> 配置不可能一股脑全给用户 ==> 配置的组织
-
如何生效
- 对于客户端,提供config client sdk,对上层提供 config access api
- 对于服务端,提供config-client,支持将信息注入到bean、spring xml 中
-
安全
- 操作配置需要权限及审计
- 和客户端的通信过程中,不被第三方篡改
- 后台crud管理操作中,不被无关用户操作
- 服务端、业务方客户端、app客户端的高可用
- 实时性
配置中心的对外接口问题
以新增配置为例,实际的实现中,新增配置完毕后,通常不意味着新增的配置能够立即对客户端或业务模块可见。比如对于客户端配置中心,此配置或许还需要经过审核与发布流程。如果将审核发布流程做在配置中心里,那么业务方通过接口新增配置时,add接口是自动审核?还是新增审核接口,然后由用户手动调用?带来的另一个问题是:对于无需此流程的上层业务模块(如果有的话),便意味着不便与难以理解。
可见,配置中心适合单纯的作为一个存储组件,支持配置的crud,其它的事情交给上层业务来处理。类似的api接口可以参考Apollo开放平台
具体接口可以提供restful api和rpc等选项,甚至封装jdbc的jar。
业务和配置中心的结合问题
利用配置中心做配置下发
如果配置中心只是单纯的作为一个存储组件?那么将配置(通常表现为key value)存储在配置中心,与存储在redis、db中有何不同?笔者认为的重点是:支持配置的自动下发。
从另一个角度看,配置中心既然作为存储组件,那么业务模块可否将所有配置都存储在配置中心上呢?当然可以。这样一来,业务模块负责定制化业务界面,将用户输入encode为key value交由配置中心存储。同时利用配置中心的下发功能,将下发的key value decode为业务数据,进行下一步处理。
操作界面是否共用的问题
配置中心一般会提供一个ui界面以方便手动的crud,既然选择将业务模块数据存入配置中心,那么是否可以直接在配置中心操作业务模块配置呢?笔者的教训是,可以,但大多数时候是受限的。
笔者曾试图将一些复杂的数据结构交给配置中心来直接存储,比如
<a id="a_id_1">
<b name=""/>
<c>
<d id="d_id_1" name="" value=""/>
<d id="d_id_2" name="" value=""/>
</c>
<a>
根据配置中心kv的存储方式,有以下方式可以存储上述数据
- 将xml序列化为model,配置中心新增一个key,value为model json后的字符串
-
创建以下几个key
a.ida.a_id_1.b.namea.a_id_1.c.d.ida.a_id_1.c.d.d_id_1.namea.a_id_1.c.d.d_id_1.value
对于后一种方式,一个复杂结构转换为一个kv set,总是可以想办法做到。但考虑到这样的配置晦涩难懂,用户很难通过直接操作配置中心来设置业务配置。如此一来,共享界面的意义便不复存在,同时增加了配置下发的难度。
因此,笔者还是建议做定制化的界面开发,配置中心的ui界面,只当做数据展示就好了。
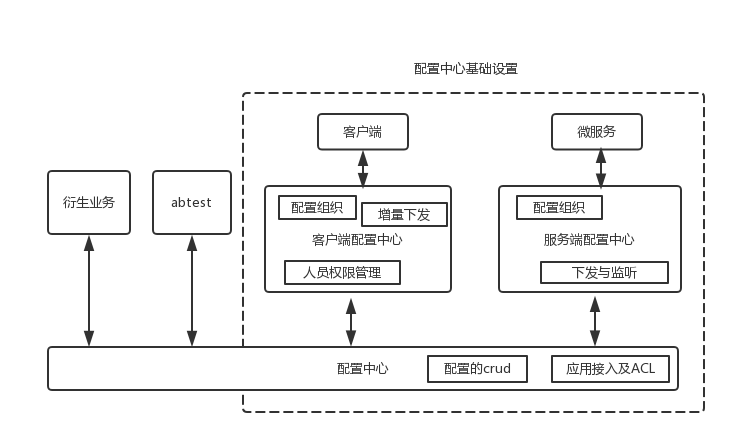
配置中心的多环境支持问题
- 多环境共用界面。配置通常具备一定的组织关系,比如以
app==> group ==> item多环境集成在一起时,新增一个app,则三个环境都新增一个app,省去了事后同步组织关系的麻烦。对于配置值的更改,则各个环境依旧保持独立。 - 共用界面对系统设计的影响 ==> api接口的提供
-
两类数据库表:
- 每个环境独有的
- 多个环境共用的表,比如账号权限表。PS,对于一些唯一name的domain,在引用domain记录时,在某些场景下,使用name关联比id更好些。
独有和公有有一个边界,那就是每个环境独有的数据表可以形成一个最小的可用配置中心。
- 账号权限系统设计。
长连接
但后端管理界面上 改掉配置中心的值后, 多长时间才能让所有用户 拿到最新的值?
- 对于客户端来说:不能 保证用户 最新一次启动后,一定用的是最新值。因为从客户端实现来说,部分业务请求时间比较靠前,此时配置中心请求 尚未返回。
- 对于服务端来说,根据实现的技术方案,基本可以做到。
现有方案的研究
| [干货 | 配置中心,让微服务『智能』](https://mp.weixin.qq.com/s?__biz=MjM5MDI3MjA5MQ==&mid=2697267852&idx=2&sn=e39b40bc4a7a3bc11ee8d5f980c5ef9e&chksm=8376f5b8b4017cae29aee9b49cce6c1c0ee113d2ebc99a3b8592adc7a949e0b39b8e768fe4c1&mpshare=1&scene=23&srcid=1212c80r7NMkfZlBDVF3OYyf%23rd) |
通过配置中心,我们可以方便地管理微服务在不同环境中的配置,从而可以在运行时动态调整服务行为,真正实现配置即『控制』的目标。 所以,在一定程度上,配置中心就成为了微服务的大脑
配置中心的核心功能点:将配置同步到需要它的地方。
配置中心的一些应用场景:
- 发布开关,某个功能带上,但是不打开
- 实验开关,AB测试
- 运维开关,大促前可以把一些非关键功能关闭来提升系统容量;当系统出现问题时可以关闭非关键功能来保证核心功能正常工作
- 黑白名单,某个调用方代码有问题导致超大量调用,对服务稳定性产生了影响,可以通过配置黑名单来暂时屏蔽这个调用方或IP
- 动态日志级别 https://github.com/ctripcorp/apollo-use-cases/tree/master/spring-cloud-logger
- 动态数据源
- 动态网关路由 https://github.com/ctripcorp/apollo-use-cases/tree/master/dynamic-datasource
小结
根据笔者一些片面的实践,本文尝试理清配置中心、下发系统及其与衍生业务的关系。在实践过程中,往往难以按照理想状态来实施,都是根据初始的任务要求,进行了一定程度的耦合(妥协)。比如携程的ctripcorp/apollo即侧重于服务端配置中心。
现在看来,笔者实践的过程中,主要有以下失误:
- 配置中心、abtest耦合开发。或者说,当时根本就没有理清楚各个业务模块的关系。
-
过分看重增量下发,后来发现,在一两年内都没有实际的需要。
2018.6.28 补充。当配置中心支持了restful接口后,有一些服务依托配置中心 向客户端送达大批量的业务数据(很长的json),此时每次全量下载配置数据 则有些力有不逮了。当配置中心 作为一个 数据送达工具存在时,还以“配置下发”来看待它就有点不合时宜了。
留下评论