从Transformer到DeepSeek
简介
从最早的Transformer架构来看, Attention Block的计算量为$N^2d$, MLP Block的计算量为$Nd^2$。 针对模型规模扩大下的算法优化自然就盯着这两个block来做了。例如针对Attention Block的MHA,DeepSeek MLA以及Stepfun MFA等。 很多的优化主要是前期针对长文本的优化。而针对MoE的优化, 开源的生态上主要是以Mistral的Mixtral 8x7B开始的,但是很遗憾几个大厂一开始的阶段都选择了Dense的MLP。
发展脉络
讲一讲这两年大模型这整个领域到底发展了哪些方面更高的性能 ==> 更高质量输出/决策 ==> 使用工具 ==> 商业价值
- 在2023年初,LLM领域的发展遵循着一条清晰而有力的轨迹,规模决定能力,所以当年的爆火词就是Scaling Laws,更大的参数,更大的计算量,更大的数据规模。
- 随后到2024年,直到年底,一年多的时间该挖的数据、该买的算力、该请的人才都到位了,但还没出现GPT5,唯规模论的范式,迎来了深刻反思和系统性挑战。
- 对效率的迫切需求 ==> 架构改进:传统Transformer架构的注意力机制具有与序列长度成二次方关系的计算复杂度(O(L^2)复杂度),加之密集型(Dense)模型高昂的推理成本,共同构成了一个严重的性能瓶颈。这极大地限制了上下文长度的扩展和模型的实际部署,从而催生了对稀疏架构和新型注意力机制的迫切需求。
- 对推理的迫切需求 ==> 需要提升可解释性,找到新的增长范式:业界逐渐认识到,单纯的规模扩张并不能赋予模型强大的、多步骤的逻辑推理能力。模型在面对需要复杂规划和逻辑演绎的任务时,依然表现不佳。这一瓶颈促使研究方向发生根本性转变,从完全依赖预训练阶段的计算投入,转向在推理阶段分配额外计算资源,即思考(thinking)模型的诞生。在推理时进行thinking,也就是让模型在给出最终答案前进行一系列内部的、复杂的思考步骤,只有在底层架构已经足够高效的前提下才具有经济可行性,没有MoE或线性注意力等技术降低基础成本,为每一次查询增加数倍乃至数十倍的thinking计算量是无法想象的。
- 智能体的迫切需求 ==> 需要有商业价值,有用:随着模型推理能力的增强,下一个重点目标是让模型能够根据推理结果采取行动。这要求模型不仅能思考,还能与外部工具和环境进行交互,从而执行复杂任务,这标志着智能体AI(Agentic AI)时代的产生。因此,Agent能力的开发,成为应用推理能力的自然延伸。它是这条因果链的第三个环节,也是最高阶的体现。一个模型只有在能够高效地进行深度思考之后,才能可靠地决定何时、如何以及使用何种工具来完成任务。
- 2025年来推理Thinking走向台前。核心理念是,模型在生成最终答案之前,花费额外的计算资源来生成一段内部的思考链(CoT,chain of thought),从而在需要逻辑、数学和规划的复杂任务上实现性能的巨大飞跃。这标志着模型从静态的知识检索向动态的问题解决能力的演进。
- 强化学习(RL)的角色在这一时期发生了根本性的转变。它不再仅仅是用于对话对齐(如RLHF)的工具 ,而是成为了教授模型如何进行推理的核心方法,推理时间也成为了新的Scaling Laws。o系列及同类模型证明,对于一组固定的模型权重,通过增加推理期间使用的计算量,可以极大地提升模型在复杂任务上的表现。这一转变带来了深远的、高阶的影响。首先,它预示着对推理硬件的需求将大规模增长,而不仅仅是训练硬件。运行一次查询的成本不再是固定的,而是根据问题的难度动态变化,这为硬件市场带来了新的增长点。其次,它将研究重点从单纯地扩大预训练规模,转向开发更高效的推理算法(如在思考链中进行更优的搜索或规划)和更有效的RL技术来引导推理过程。
- 从理想到行动:智能体工具使用的黎明。一旦模型具备了推理和规划的能力,合乎逻辑的下一步就是让它能够通过与外部工具交互来执行计划。这正是AI智能体的定义。OpenAI的o3和o4-mini是首批被描述为具备“智能体工具使用”(agentic tool use)能力的模型。它们能够自主地决定何时以及如何组合使用网页搜索、Python代码分析和DALL-E图像生成等工具来解决一个复杂的用户请求。Claude 4的发布伴随着一套专为构建智能体而设计的新API功能:一个代码执行Sandbox、一个用于访问本地文件的Files API和一个MCP工具。这些功能,再结合独特的“计算机使用”(computer use)能力(即生成鼠标和键盘操作),使Claude成为构建能够与数字信息和图形用户界面(UI)进行交互的强大智能体的理想平台。
- 未来轨迹与结论。
- 也许是具身智能与世界模型。当前在推理和智能体方面的趋势,是通向具身智能(Embodied AI)的直接前导。感知、推理、规划和行动的闭环,正是具身智能体的核心工作流程。像Claude 4这样直接就是Product应用能力的模型,以及OpenAI的智能体框架,是模型从控制软件工具迈向控制机器人执行器的第一步。核心挑战在于将模型从数字世界迁移到物理世界。物理世界施加了严格的实时约束,而当前LLM的顺序执行、逐帧处理的架构并非为此设计。未来的研究,如Corki框架所提出的,将致力于算法与硬件的协同设计,通过让LLM预测未来的运动轨迹而非单一的、离散的动作,来解耦高延迟的LLM推理与低延迟的机器人控制。这预示着“世界模型”(World Models)——即能够理解和预测物理世界动态的AI系统将成为下一个研究热点。
- 对后Transformer架构的探索
回顾2023年至2025年6月的这段关键时期,可以清晰地看到,大型语言模型领域完成了一次深刻的战略转向。它不再是单一地追求规模(Scale),而是转向了一个由三大新支柱构成的、更加复杂和强大的多维发展策略:
- 效率(Efficiency):通过稀疏化(MoE)和先进的注意力机制(MLA、混合注意力)实现。效率创新使得巨大的模型规模和超长的上下文处理在经济上变得可行,为后续发展奠定了基础。
- 推理(Reasoning):通过将计算资源重新分配到推理阶段(“思考预算”)以及利用先进的强化学习技术训练模型涌现出解决问题的能力来实现。这使得模型从知识的存储器转变为问题的解决者。
- 智能体(Agency):作为推理能力的应用,它使模型能够自主地使用工具与数字乃至物理世界进行交互。这是将模型智能转化为实际行动的关键一步。 这一演进将大型语言模型从复杂的文本预测器,转变为初具形态的通用问题解决系统,为未来十年的人工智能发展奠定了坚实的架构基础。在这场新的竞赛中,胜利不再仅仅属于规模最大的模型,而是属于那些最有效率、思考最深刻、行动最强大的系统。
MoE
MoE 模型存在的原因
Moe已成为现阶段LLM的新标准MoE即 Mixture of Experts,是一种人工智能训练技术。它实质上将神经网络的某些部分(通常是LLM)“分解”为不同的部分,我们将这些被分解的部分称为“专家”。这种技术出现的原因有三个主要方面:
- 神经网络的稀疏性: 在特定层中,神经网络可能会变得非常稀疏,即某些神经元的激活频率远低于其他神经元。换句话说,很多神经元并非每次都会被使用到,这和人类大脑中的神经元是类似的。神经网络实际上对于它们所做的大多数预测来说都太大了(而且模型的规模越大,其稀疏性也越强)。例如我们让其帮忙总结一篇文章的内容,而模型训练的参数不仅仅“吸纳了”这些能力的数据,还包括了物理、数学,天文等等的知识内容。这意味着我们每次预测都要运行整个网络,但实际上模型中只有很小的一部分能够发挥作用。
- 神经元的多语义性: 神经元的设计使其具有多语义性,这意味着它们可以同时处理多个主题或概念。举个例子来说,在神经网络数十亿个神经元中的一个神经元可能每次在输入主题涉及“苹果”被激活,而当输入主题涉及“电话”时,这个神经元也可能被激活。这不仅使神经网络难以解释,而且也不是一个理想的情况。因为单个神经元必须精通各种彼此几乎毫无关系的主题。更糟糕的是,学习曲线可能相互矛盾,学习一个主题的更多知识可能会影响神经元获取另一个主题知识的能力。那么,如果我们能使用一种技术来拆分、消除或至少减少这两个问题,会怎么样呢?PS:“专家”这个名字是有原因的
- 计算资源的有限性:模型规模是提升模型性能的关键因素之一。而不管在什么阶段,资源一定是有限的,在有限的计算资源预算下,用更少的训练步数训练一个更大的模型,往往比用更多的步数训练一个较小的模型效果更佳。
- 由于神经网络的稀疏性,以及当前Transformer的二次障碍问题,大模型网络中进行了大量不必要的计算,使得我们更大的 LLM 成为世界上最低效和最耗能的系统之一。
Scaling Law模型不断增大,计算量随参数线性增大,而参数占比的大头又在MLP层,因此就把MLP层拆分,美其名曰不同专家,每次执行仅激活部分参数, 其本质就是在将现有FFN层拆分成多个,然后增加路由,每次可以激活不同专家组,以减少计算量。
实现
在构建MoE语言模型时,通常会将Transformer中的某些FFN替换为MoE层(MOE FFN,陆续还出现了MOE Attention,在某些情况下,并非所有 FFN 层都被 MoE 取代,例如Jamba模型具有多个 FFN和MoE 层)。具体来说,MoE层由多个专家组成,每个专家的结构与标准的FFN相同。MoE 的核心思想源于 “分而治之”:将模型的FFN/MLP拆分为多个独立的 “专家”(Expert),每个输入 token 仅由部分专家(TOPK个)处理,再通过门控网络聚合结果。这种设计使模型参数量随专家数量线性增长,却无需按比例增加计算量(因每个 token 仅激活少数专家)。MoE模型的推理过程主要包含三个阶段:
- 路由计算:通过路由器计算专家选择概率
- 专家选择:基于概率选择Top-K个专家
- 并行计算:选中的专家并行处理输入并聚合结果
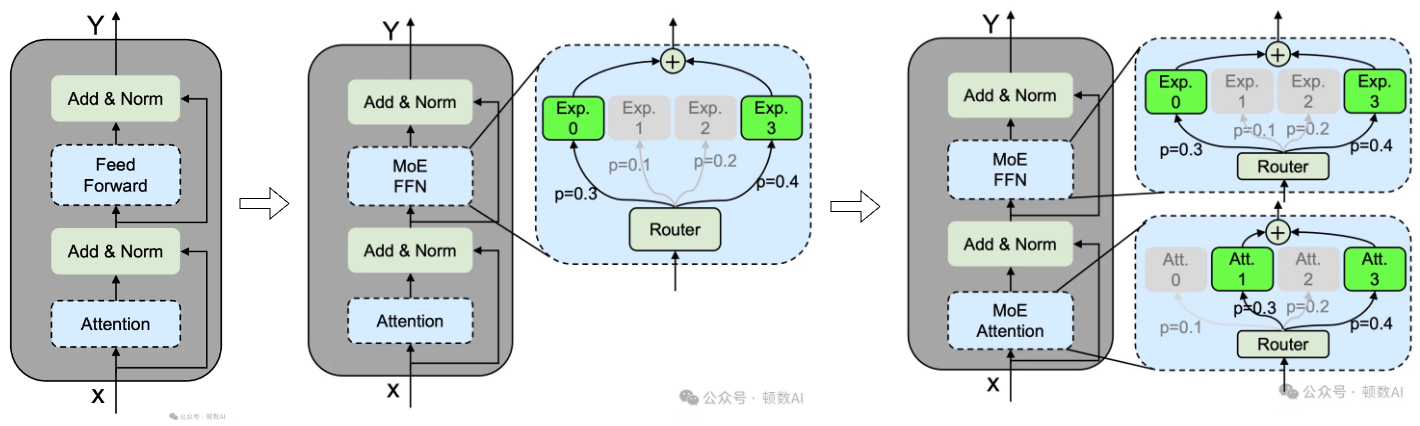
分析一下DeepSeek每一代MoE的演进 建议细读。
苏剑林 MoE环游记:1、从几何意义出发
- 一个常规的Dense模型FFN,可以等价改写为n个Expert向量$v_1,v_2,…,v_n$之和;
- 为了节省计算量,我们试图挑出k个向量求和来逼近原本的n个向量之和;
- 转化为数学问题求解后,我们发现挑选规则是模长最大的k个向量;
- 直接去算n个Expert的模长然后选k个实际上是不省计算量的,所以要重新设计Expert;
- 将$v_i$归一化得到$e_i$,然后用另外的小模型(Router)预测模长$p_i$,最终的Expert为$p_ie_i$;
- 此时,我们就可以先算全体$p_i$,挑出k个后才去计算$e_i$,达到节省计算量的目的。
挑战
MoE架构的主要优势在于其能够通过激活部分专家来降低计算成本,从而在扩展模型参数的同时保持计算效率。然而,现有的MoE架构在专家专业化方面面临挑战,具体表现为知识混杂和知识冗余。这些问题限制了MoE模型的性能,使其无法达到理论上的性能上限。
- 知识混杂(Knowledge Hybridity):现有的MoE实践通常使用较少的专家(例如8或16个),由于专家数量有限,每个专家最终都要处理广泛的知识,这就产生了知识混合性。这种广泛性阻碍了专家们在特定领域进行深入的专业化。
- 知识冗余(Knowledge Redundancy):当 MoE 模型中的不同专家学习相似的知识时,就会出现知识冗余,这首先就违背了对模型进行划分的意义。
- 最近一个有趣的趋势是添加“共享专家”的概念,例如DeepSeek 的DeepSeekMoE 家族。“共享专家”是掌握更加泛化或公共知识的专家,从而减少每个细粒度专家中的知识冗余,共享专家的数量是固定的且总是处于被激活的状态。而超专业专家(对于此特定模型最多可达 64 位) 掌握更细粒度的知识。
- 负载不均衡,如果路由器(Router)在训练中,总是倾向于选择少数几个“明星专家”,那么这些专家会得到过多的训练,而其他专家则长期“坐冷板凳”。破解MoE训练“均衡”与“性能”的两难:DeepSeek与Qwen的破局之道
- 在MoE模型中,路由器不会把所有参数都用上,而是会根据每个输入token的特征,挑几位在该领域更擅长的“专家”出来干活,从而可以节省不少资源。这种动态模式会让模型在训练阶段和推理阶段得出的最佳策略大相径庭(PS:训练和推理时选了不同的专家?),比传统的稠密模型要“飘忽”得多。
- 一种实践(Rollout Routing Replay),在推理时把路由分布记录下来,等到训练时再把这些分布原封不动地“重放”进去。这样,训练和推理就走同一条路线,不再各干各的。
- 在强化学习中,模型会不断重复“生成→获得奖励→更新→再生成”的飞轮,一个完整过程下来,可能要跑上几十万、甚至上百万次推理。要是每次生成都要从头计算上下文,算力与时间成本将呈几何式增长。为应对这种情况,主流推理引擎普遍采用KVCache前缀缓存策略:把之前算好的上下文保存下来,下次直接“接着算”。不过,除了上下文不一致,MoE架构还涉及到路由选择不一致的问题——按照传统的解决方案,即便是重复的上下文,每一次计算,模型还是要重新选专家、激活专家。因此在KVCache的基础上又加了一招——路由掩码(routing mask)。既然对于对相同的上下文,MoE的路由结果应该一样,那干脆,把推理阶段的路由掩码和前缀KVCache一起缓存起来。这样当相同上下文再次出现时,模型就能直接用上次的掩码,不必重算。PS:kvcache加速attention层,routing mask加速moe层。 PS:训练不稳定、负载不均衡
deepseek
论文 模型架构;优化方法;基础设施。
边际创新
- 无辅助损失的负载均衡策略(Auxiliary-loss-free Load Balancing Strategy)
- 多头潜在注意力架构(Multi-head Latent Attention, MLA),减少了注意力部分的 KV 缓存. Low rank。
- DeepSeekMoE架构
- FP8混合精度训练框架
- 跨节点混合专家(MoE)训练的通信与计算重叠
首次验证
- 多标记预测训练目标(Multi-Token Prediction, MTP)对模型性能的显著提升
- FP8训练在超大规模模型上的可行性及有效性
- 强化学习可完全激励LLMs的推理能力(无SFT依赖)
- 蒸馏后的小型密集模型性能优于直接强化学习的小模型
DeepSeek-V3
- 模型架构设计:MLA、DeepSeekMoE;创新的负载均衡策略(优化MoE训练);MTP
- 并行策略:大量专家并行(EP)、不使用TP;Dualpipe流水线并行;ZeRO-1(DP)并行策略
- 通信优化:MoE All2All优化
- 显存优化:FP8低精度训练;选择重计算;EMA显存优化;头尾参数共享(emebedding & lm_head)。 DeepSeek 的优化策略分为两大类。第一类是底层优化,即在已知算法模型和底层硬件的情况下,通过软件优化来提升硬件效率,比如通信优化或内存优化。这些优化不会改变程序执行的正确性,但能显著提升性能。第二类是协同优化,包括混合精度、量化和 MLA 等技术,这些优化不仅涉及原有算法模型的修改,还可能需要调整底层硬件,从而扩展硬件优化的空间。
漫谈DeepSeek及其背后的核心技术 对上面技术有细节介绍,未细读。
R1训练过程
先前的大型语言模型(LLMs)相关的很多工作里都依赖大量的人工标注的数据去提升模型性能。但在Deep Seek R1这篇论文中指出:模型的推理能力(reasoning capabilities)可以通过大规模的强化学习(Reinforcement learning)来提升,甚至不需要用SFT(supervised fine-tune)来完成冷启部分的工作。强化学习(RL)的角色在这一时期发生了根本性的转变。它不再仅仅是用于对话对齐(如RLHF)的工具 ,而是成为了教授模型如何进行推理的核心方法,推理时间也成为了新的Scaling Laws。PS. 通过少量的SFT完成模型的冷启(cold-start)可以进一步提升模型表现。
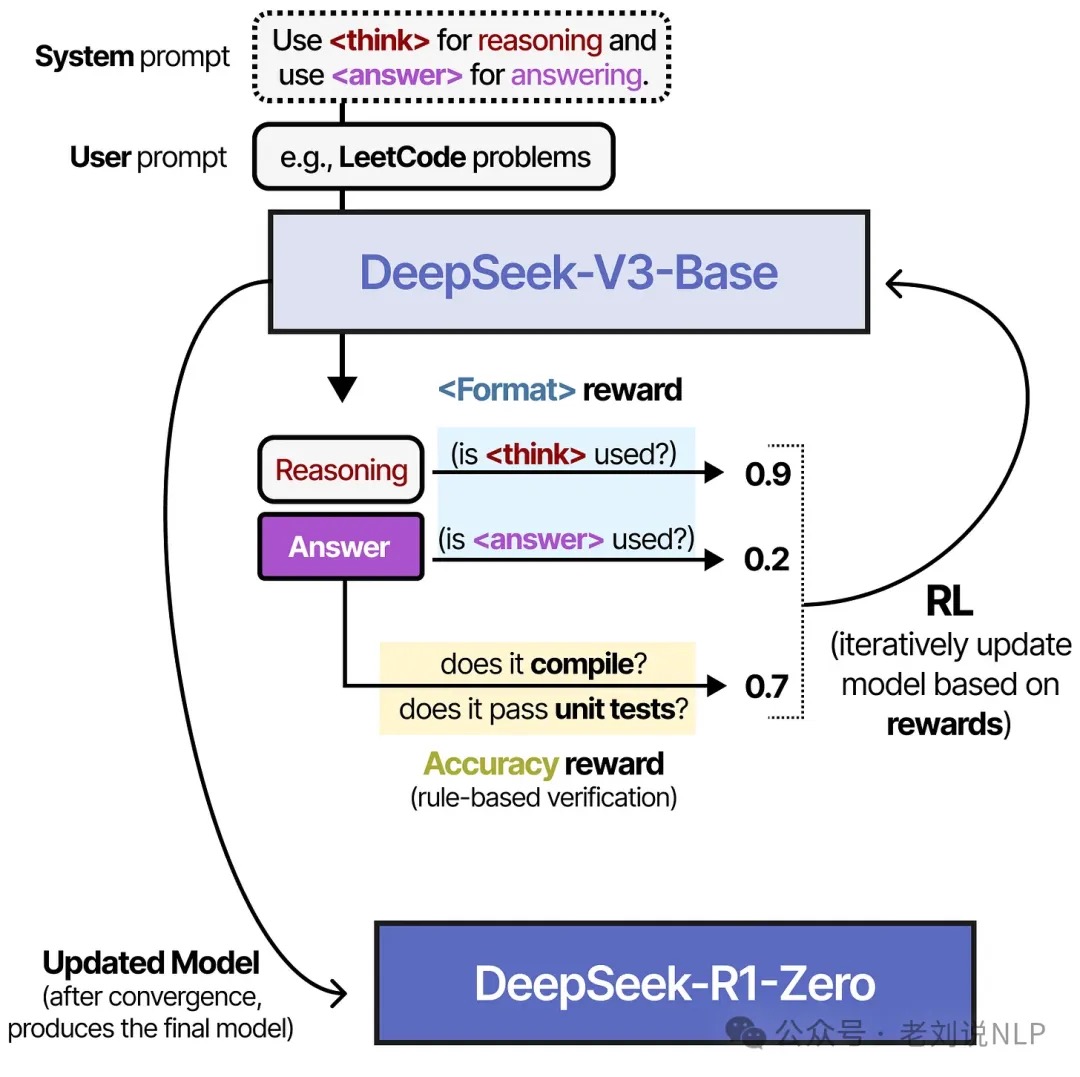
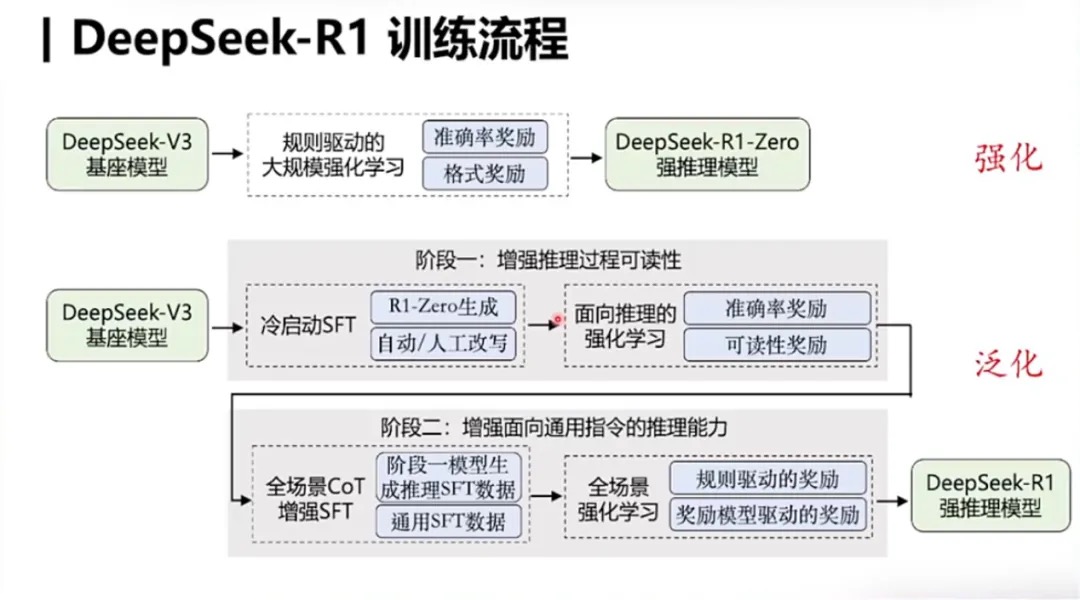
一个以RL为中心的多阶段流程,迭代式训练: PS: base-> rl -> sft 数据集 -> sft base-> rl -> sft 数据集。论文提到包含2个rl 过程和2个sft过程。PS: 先增强生成cot/think能力(一个sft+rl),再进行更多的SFT和一个最终用于通用对齐的RL阶段。
- 先收集了一部分高质量冷启动数据(约几千条),使用该数据fine-tune DeepSeek-V3-Base模型,记为模型A。PS: 最开始没有冷启动这个步骤,而是直接对DeepSeek-V3-Base进行了GRPO训练,发现虽然CoT能力提升比较大,但是回复的内容鱼龙混杂,甚至有多个语言同时出现的情况
- 使用A模型用GRPO训练(论文用了一个词 reasoning-oriented RL),使其涌现推理能力,收敛的模型记为B
- 使用B模型产生高质量SFT数据,并混合DeepSeek-V3产生的其他领域的高质量数据,形成一个高质量数据集
- 使用该数据集训练原始DeepSeek-V3-Base模型,记为模型C
- 使用C模型重新进行步骤2,但是数据集变为所有领域(常规的rl,常规的reward model,提高helpfulness and harmlessness),收敛后的模型记为D,这个模型就是DeepSeek-R1
- 训练C模型的数据对小模型做蒸馏,效果也非常好
这个训练过程是不需要任何监督数据的,只需要准确评估最终结果。GRPO的reward并没有采用PRM,而是使用了基于正则的ORM。其中包括了两个点:
- 评估最终答案是否正确。包含最终结果比对、代码运行结果等
- 格式奖励:模型需要将CoT过程放在
<think></think>之间
有人说sft不存在了。不可能的,最多是人类标注的sft不存在了。那么取而代之的是什么呢?ai标注的sft。模型rl得到的思维链做sft训练新模型,大模型的思维链训练小模型。ybq大佬:post training 最关键的并不是 sft 和 rl 谁更重要,恰恰就是 multi_stage 的设计。既可以是多阶段的 sft,也可以是多阶段的 rl,亦或者是相互交叉的多阶段。不同 topic 的多阶段,不同任务难度的多阶段,不同训练方法的多阶段,不同 seq_len 的多阶段等等,都需要做实验去设计,也往往都能让模型的效果有所提升。pretrain 的技术方法正在全面入侵 post training(退火、课程学习、多阶段训练 ……)。
Open R1是由Hugging Face团队开发的完全开源的DeepSeek-R1复现项目 未读。
MTP(Multi-Token Prediction)
与之对应的是DeepSeek-V3 发布之前业界普遍使用的单令牌预测(Single - Token Prediction,STP),STP 一次仅预测一个Token,而 MTP 可同时预测多个 Token。为什么要做MTP? 当前主流的大模型(LLMs)都是decoder-base的模型结构,也就是无论在模型训练还是在推理阶段,对于一个序列的生成过程,都是token-by-token的。每次在生成一个token的时候,都要频繁跟访存交互,加载KV-Cache,再通过多层网络做完整的前向计算。对于这样的访存密集型的任务,通常会因为访存效率形成训练或推理的瓶颈。
MTP核心思想(一般涉及到model改动):通过解码阶段的优化,将1-token的生成,转变成multi-token的生成,从而提升训练和推理的性能。具体来说,在训练阶段,一次生成多个后续token,可以一次学习多个位置的label,进而有效提升样本的利用效率,提升训练速度;在推理阶段通过一次生成多个token,实现成倍的推理加速来提升推理性能。
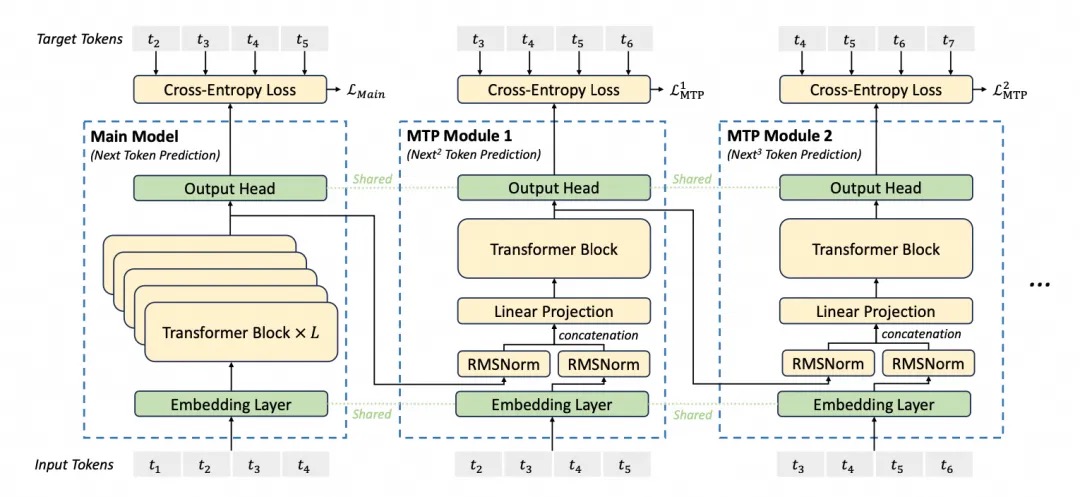 mtp 需要在representation 上、在训练信号上、在 loss 设计上都适应“远距离预测”。
mtp 需要在representation 上、在训练信号上、在 loss 设计上都适应“远距离预测”。
蒸馏/distilled
知识蒸馏本质上是一种模型压缩的方法,其核心思想是利用一个大模型(教师模型)来指导小模型(学生模型)的训练。蒸馏有几种方法,每种方法都有各自的优点:
- 一种是数据蒸馏,在数据蒸馏中,教师模型生成合成数据或伪标签,然后用于训练学生模型。这种方法可以应用于广泛的任务,即使是那些 logits 信息量较少的任务(例如开放式推理任务)。
- 一种是Logits蒸馏,Logits 是应用 softmax 函数之前神经网络的原始输出分数。在 logits蒸馏中,学生模型经过训练以匹配教师的 logits,而不仅仅是最终预测。这种方法保留了更多关于教师信心水平和决策过程的信息。
- 一种是特征蒸馏,特征蒸馏将知识从教师模型的中间层转移到学生。通过对齐两个模型的隐藏表示,学生可以学习更丰富、更抽象的特征。
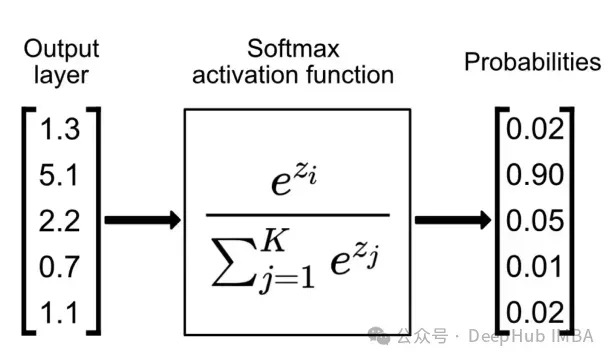
考虑一个输出三类别概率的神经网络模型。假设教师模型输出以下logits值: [1.1, 0.2, 0.2], 经过softmax函数转换后得到: [0.552, 0.224, 0.224]。 此时,类别0获得最高概率,成为模型的预测输出。模型同时为类别1和类别2分配了较低的概率值。这种概率分布表明,尽管输入数据最可能属于类别0,但其特征表现出了与类别1和类别2的部分相关性。在传统的模型训练中,仅使用独热编码标签(如[1, 0, 0])会导致模型仅关注正确类别的预测。这种训练方式通常采用交叉熵损失函数。而知识蒸馏技术通过引入教师模型的软标签信息,为学生模型提供了更丰富的学习目标。
低概率信息的利用价值:在传统分类任务中,由于最高概率(0.552)显著高于其他概率值(均为0.224),次高概率通常会被忽略。而知识蒸馏技术的创新之处在于充分利用这些次要概率信息来指导学生模型的训练过程。以动物识别任务为例,当教师模型处理一张马的图像时,除了对”马”类别赋予最高概率外,还会为”鹿”和”牛”类别分配一定概率。这种概率分配反映了物种间的特征相似性,如四肢结构和尾部特征。虽然马的体型大小和头部轮廓等特征最终导致”马”类别获得最高概率,但模型捕获到的类别间相似性信息同样具有重要价值。
其它
让base model 生成推理过程的prompt
A conversation between User and Assistant. The user asks a question, and the Assistant solves it.
The assistant first thinks about the reasoning process in the mind and then provides the user
with the answer. The reasoning process and answer are enclosed within <think> </think> and
<answer> </answer> tags, respectively, i.e., <think> reasoning process here </think>
<answer> answer here </answer>. User: {question}. Assistant:
自动推理
Qwen3-RL训练详解将思考模式和非思考模型集成到一个统一的框架中,这使得模型既拥有拥有复杂多步骤推理的能力(例如QwQ-32B),也能够基于上下文进行快速响应(例如GPT-4o)。
Open AI 二款开源模型分别为gpt-oss-120b (117B 参数 激活5.1B)与gpt-oss-20b(21B参数 激活3.6B)都支持推理,具有以下三种 reasoning level(推理深度):
- 低(Low):快速响应,适合通用对话。
- 中(Medium):速度与细节兼顾的平衡选择。
- 高(High):进行深入且详尽的分析。
线性注意力
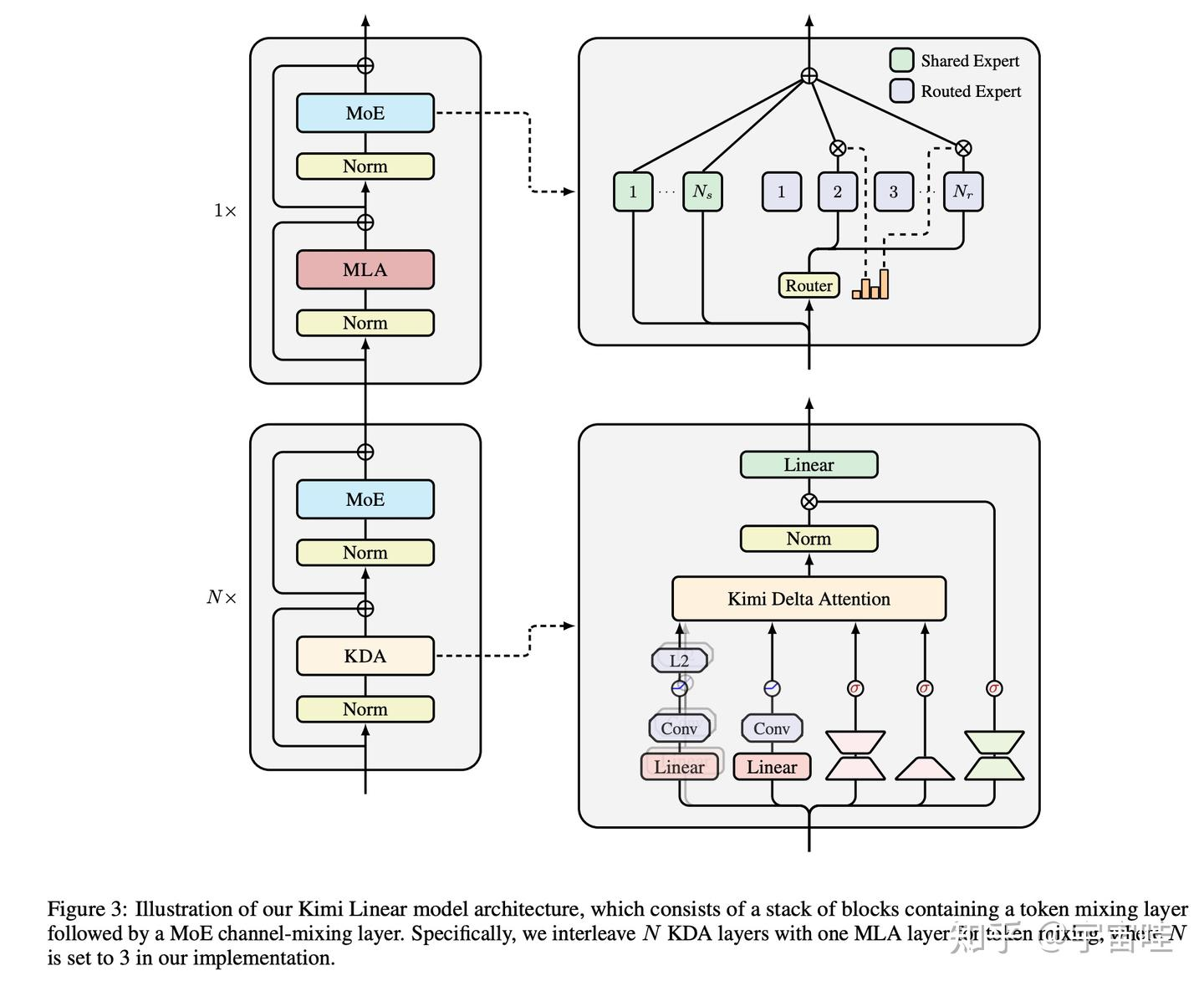
Kimi Linear学习笔记:让Attention又快又好我们能否创造一种架构,既有线性注意力的超高效率,又能达到甚至超越全注意力的性能呢?
- 要理解KDA,我们先得知道线性注意力是怎么工作的。你可以把它想象成一个带有“记忆”的系统,类似于循环神经网络(RNN)。它在处理每个新词时,会更新一个固定大小的“记忆状态(State)”(用一个矩阵S表示,大小固定),这个状态压缩了前面所有词的信息(对前面所有内容的一个高度压缩的记忆摘要)。这样一来,它就不需要保存整个序列的KV Cache了。Kimi的研究者认为,之前的线性注意力之所以效果不够好,一个关键原因是“记忆管理”机制不够精细。而KDA就在这里做了关键改进:它引入了一种“更细粒度的门控机制”。当新的词t进来时,模型不是把新词的$k_t$和$v_t$存下来,而是用它们来更新这个记忆矩阵 S。$q_t$ 是当前第 t 个词的“查询向量”(Query Vector),代表了当前这个词对上下文的“提问”。用$q_t$ 去查询刚刚更新好的“记忆” $S_t$,两者的乘积就是提取出的最相关的信息,即输出 $o_t$。整个KDA机制,就是通过这个高效的“更新记忆-查询输出”循环,来模拟标准注意力机制的效果,从而在保持线性复杂度的同时,实现了强大的性能。PS: 单个问题内的记忆写入和存取
- 尽管KDA已经非常强大了,但纯粹的线性注意力在某些任务上,比如需要精确无误地从超长文本中检索某个细节时,仍然可能存在理论上的瓶颈。为了“取长补短”,Kimi Linear采用了一种非常务实的混合架构。它并不是把所有层都换成KDA,而是将KDA层和传统的全注意力层(论文里叫MLA, Multi-Head Latent Attention)结合起来使用。每3个KDA层之后,插入1个MLA层。
记忆
CL-bench: A Benchmark for Context LearningContext Engineering 存在一个与模型能力绑定的效果上限。作为大模型应用 / Agent 工程的基石 ——Context Engineering,从早期各类的 Prompt 方法 (few-shot、role-play),再到与工程方法结合而诞生的 RAG、Skill 等框架,本质都在解决同一件事 —— 如何帮模型更好地管理上下文。针对给 LLM 的 Context 输入,我们把 “喂什么” 和 “怎么喂” 做到了极致。但这些 Context Engineering 的努力都有一个理想化的前提:只要尽量把正确的信息放进上下文,模型就能利用它。但是
- 模型的权重天然倾向于 “相信自己已经知道的”,:越强的 “自主推理” 能力可能导致模型越倾向于依赖自身判断,而非忠实地遵循上下文中给定的规则和信息。
- 比如,Prompt + 上下文组合在简单的事实查找类任务上可能表现出色,但换成需要多步推理或多条件综合的任务,可能直接崩溃 —— 不是因为上下文有问题,而是因为模型的上下文学习能力(Context Learning)在这类任务上本就极为有限。
- 给模型更多思考时间可能没用。瓶颈不在 “找到”,而在 “整合”。这也解释了为什么很多开发者发现,把模型从 o3 换成 o3-pro、或者开启更长的 thinking budget,在上下文依赖的任务上往往达不到预期。问题不在推理深度,而在知识整合机制本身。 回到架构层面,为什么大模型在上下文学习上存在这类系统性的缺陷?人类面对一份陌生的复杂文档时,会在工作记忆中做几件事:提取关键规则、建立概念间的依赖关系、标记约束条件、构建一个结构化的内部表征。然后在这个内部模型上推理,而不是每次需要某条信息时都回到原文去 “重新看一遍”。Transformer 的前向传播本质上是一次性的信息处理。自注意力做的是加权平均 —— 能 “看到” 所有 token,但缺乏以下关键能力:迭代构建:没有机制在多轮 pass 中逐步
- 构建关于上下文的内部模型
- 主动区分:无法系统性地区分 “需要遵循的新规则” 和 “已有的旧知识”
- 结构化管理:缺乏对多条相互依赖约束的结构化表征和追踪 Chain-of-Thought 在一定程度上弥补了这个问题 —— 通过生成文本来模拟工作记忆。但它的局限也很明显:CoT 生成的中间结果自身也受 Lost in the Middle 效应影响,且当原始上下文已经很长时,额外的思考文本进一步加剧了注意力稀释。CL-Bench 的数据也印证了这一点:推理努力增加带来的收益微乎其微。
留下评论