业务程序猿眼中的微服务管理
简介
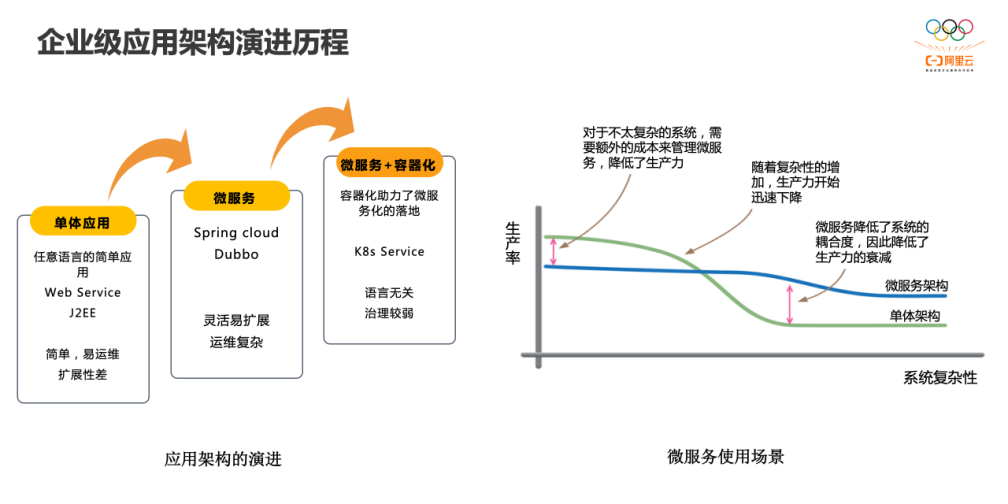
容器和 Kubernetes 降低了服务(应用)的部署和升级成本,在微服务中,会直接把单个服务拆分成多个服务,服务之间用 API 调用。这里也可以看到,在微服务中,架构设计的重要性降低,API 设计的重要性提高。随着微服务的发展,服务变得太多了,管理负责度又上升了,比如怎么去解决服务发现的问题、怎么控制流量、服务之间怎么做隔离,服务状态怎么观测等等。这时候又出现了「服务治理」的概念。
包括哪些工作
服务治理的核心目标是考虑如何确保这些软件能够真正做到 24 小时不间断的服务。服务治理没有简洁的抽象问题模型,我们需要面对的是现实世界的复杂性。但是,它们的确已经在被解决的边缘。相关领域的探索与发展,日新月异。
本文主要以框架实现的角度 来阐述微服务治理,主要包括两个方面:“业务层面”(微服务应该有什么)和工程层面(如何code实现)。此外,篇幅有限,多从客户端(即业务使用方)角度来阐述问题。
服务治理在猫眼的演进之路-Service Mesh服务治理的包含了非常多的能力,比如服务通讯、服务注册发现、负载均衡、路由、失败重试等等
2019.12.13补充:What is Istio?The term service mesh is used to describe the network of microservices that make up such applications and the interactions between them. As a service mesh grows in size and complexity, it can become harder to understand and manage. Its requirements can include discovery, load balancing, failure recovery, metrics, and monitoring. A service mesh also often has more complex operational requirements, like A/B testing, canary rollouts, rate limiting, access control, and end-to-end authentication. 理解: service mesh 可以理解为 the network of microservices, 随着service mesh 规模的扩大, 会产生 discovery, load balancing, failure recovery, metrics, monitoring, A/B testing, canary rollouts, rate limiting, access control, and end-to-end authentication 等一系列问题。
- 服务注册发现
- 路由,流量转移。 红绿灯是一种流量控制;黑白名单也是一种流量控制
- 弹性能力(熔断、超时、重试)
- 安全
- 可观察性(指标、日志、追踪)。四个基本的服务监控需求:延迟、流量、错误、 饱和
整体架构
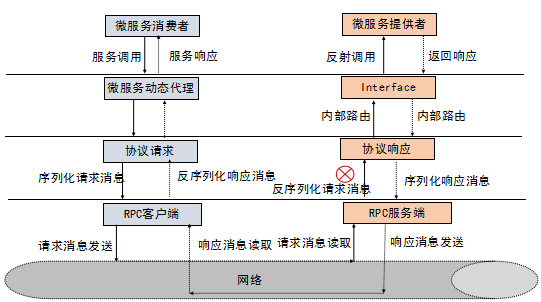
三大基本套路
RPC 就是把拦截到的方法参数,转成可以在网络中传输的二进制,并保证在服务提供方能正确地还原出语义,最终实现像调用本地一样地调用远程的目的。微服务架构是什么
- rpc、调用信息序列化 等基本能力
- 服务发现、路由、监控报警 等旁路系统
- 分拆业务 的一种方式
服务发现、路由、监控报警 等事情 谁去干呢?
- 以框架为中心
- 以PaaS 平台为中心,将 公共的 技术能力沉淀到 PaaS层,运维不再只是提供 物理机/jvm 虚拟机,而是提供一个服务,服务的访问形式是ip:port/http url。PaaS 内部负责服务发现、负载均衡等能力等
- service mesh
从0 到 1 实现一个服务治理框架
基本能力
包括且不限于以下问题:
- io通信
- 序列化协议
io 通信包括同步模型和异步模型。
同步模型的调用流程为:请求 ==> 线程 ==> 获取一个连接 ==> 阻塞。此时一个请求将占用一个线程、一个连接。阻塞分为两种情况
- io阻塞,比如connect、read 等
- 业务阻塞,服务端bug或负载很大,无法及时返回响应,会表现为客户端read 一直阻塞
异步模型的调用流程为:请求 ==> 线程 ==> 获取一个连接 ==> 发请求 ==> 接口调用结束。 异步的问题在于,通过队列缓冲了请求,若是客户端请求的速度远超服务端响应的速度, 队列会增长,会oom
rpc 就好像函数调用一样,有数据有状态的往来。也就是需要有请求数据、返回数据、服务里面还可能需要保存调用的状态。 调用端为每一个消息生成一个唯一的消息 ID,通过消息ID关联请求跟响应。
qiankunli/pigeon 笔者基于netty 实现了一个具备基本能力的rpc 框架,推荐用来熟悉上述过程。
旁路系统
《RPC实战与核心原理》
-
客户端,从上到下依次是:
- 熔断,别人有问题 放弃调用别人。当调用端调用下游服务出现异常时,熔断器会收集异常指标信息进行计算,当达到熔断条件时熔断器打开,这时调用端再发起请求是会直接被熔断器拦截,并快速地执行失败逻辑;当熔断器打开一段时间后,会转为半打开状态,这时熔断器允许调用端发送一个请求给服务端,如果这次请求能够正常地得到服务端的响应,则将状态置为关闭状态,否则设置为打开。RPC 框架可以在动态代理的逻辑中去整合熔断器。
- 服务发现。 RPC 框架的服务发现,在服务节点刚上线时,服务调用方是可以容忍在一段时间之后(比如几秒钟之后)发现这个新上线的节点的。对于目标节点存在已经下线或不提供指定接口服务的情况,放到了 RPC 框架里面去处理,在服务调用方发送请求到目标节点后,目标节点会进行合法性验证,如果指定接口服务不存在或正在下线,则会拒绝该请求。服务调用方收到拒绝异常后,会安全重试到其它节点。所以我们可以牺牲掉 CP(强制一致性),而选择 AP(最终一致),来换取整个注册中心集群的性能和稳定性。
- 路由。IP 路由;参数路由。
- 负载均衡。权重;智能负载(服务调用者收集与之建立长连接的每个服务节点的指标数据,如服务节点的负载指标、CPU 核数、内存大小、请求处理的耗时指标(如请求平均耗时、TP99、TP999)、服务节点的状态指标(如正常、亚健康)。通过这些指标,计算出一个分数,比如总分 10 分,如果 CPU 负载达到 70%,就减它 3 分,当然了,减 3 分只是个类比,需要减多少分是需要一个计算策略的)。RPC 的负载均衡完全由 RPC 框架自身实现,RPC 的服务调用者会与“注册中心”下发的所有服务节点建立长连接,在每次发起 RPC 调用时,服务调用者都会通过配置的负载均衡插件,自主选择一个服务节点,发起 RPC 调用请求。
- 异常重试
-
服务端
- 服务注册
- 线程隔离。在没有汽车的年代,我们的道路很简单,就一条,行人、洋车都在上边走。那随着汽车的普及以及猛增,我们的道路越来越宽,慢慢地有了高速、辅路、人行道等等。通过分组的方式隔离调用方的流量,从而避免因为一个调用方出现流量激增而影响其它调用方的可用率。
- 限流。自己有问题,阻断别人调用自己。计数器、滑动窗口、漏斗、令牌桶。应用维度;ip维度。
- 超时控制。A ==> B ==> C ==> D,A 设置了全链路超时为 100ms,C 或 D 发现超时时间超过了100ms ,就放弃执行。
- 优雅关闭。服务对象在关闭过程中,会拒绝新的请求,直接返回一个特定的异常给调用方(比如ShutdownException),同时根据引用计数器等待正在处理的请求全部结束之后才会真正关闭。
- 优雅启动。刚启动的服务提供方应用不承担全部的流量,让负载均衡在选择连接的时候根据启动时间 慢慢放大权重;延迟暴露,注册中心在收到新上线的服务提供方地址的时候,服务提供方可能并没有启动完成,可以在服务提供方应用启动后,接口注册到注册中心前,预留一个 Hook 过程,让用户可以实现可扩展的 Hook 逻辑。
每一个点都有一系列的策略实现,比如调用策略,假设一个服务有3个实例ABC,称为集群cluster,客户端去调用A
- failfast,A 实例故障,则调用失败
- failover,A 实例故障,则重试BC
- failsafe,A 实例故障,返回实现配置的默认值
额外提一个问题:框架实现的哪些功能部分适合下放到PaaS 层去做?
2018.12.15 补充:个推基于Docker和Kubernetes的微服务实践服务发现的几种实现方式
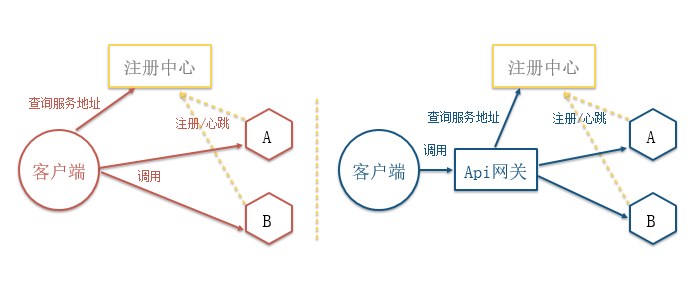
第一种是客户端通过向服务的注册中心查询微服务的地址与其通信,第二种是增加统一的API网关来查询。前者会增加客户端的复杂度,开发成本高,后者操作会更加简洁,但网关可能会成为瓶颈。
RPC 框架真正强大的地方在于它的治理功能,而治理功能大多都需要依赖一个注册中心或者配置中心,我们可以通过 RPC 治理的管理端进行配置,再通过注册中心或者配置中心将限流阈值的配置下发到服务提供方的每个节点上,实现动态配置。
工程实现
实现基本能力
假设存在一个web服务,接收请求,调用rpc 服务处理请求,则按照传统controller-service-dao 的方式,会如何组织代码?
controller
service
CircuitBreaker
route
loadbalance
serialize/codec
socket
很明显service 层以下,是框架应该解决的部分,不应该直接暴露在业务代码中,因此类似于传统访问db 的方式:
controller
service
micro service
自然的,service 与 micro service 之间会定义一个接口(下文称为Iface),客户端调用该接口,服务端则提供接口实现。
我们先只考虑基础能力的实现,则对于客户端来说,Iface 实现(下文称为Impl)的实现逻辑大体是
- 将参数序列化
- 使用socket 发送调用数据,包括但不限于类名、方法名、方法参数及其它信息,比如为分析调用链路 而设置的链路id
- 读取服务端返回,并将返回结果反序列化
在实际的实现中,这一步骤通常是自动生成的,比如thrift。
客户端的核心——桩
在客户端,业务代码得到的 Iface的实例,并不是我们在服务端提供的真正的实现类(实现类写在服务端) 的一个实例。它实际上是由 RPC 框架提供的一个代理类的实例。这个代理类有一个专属的名称,叫“桩(Stub)”。在不同的 RPC 框架中,这个桩的生成方式并不一样,有些是在编译阶段生成的,gRPC 它是在编译 IDL 的时候就把桩生成好了、再和业务代码使用目标语言的编译器一起编译的,有些(Dubbo)是在运行时动态生成的,这个和编程语言的语言特性是密切相关的。
public interface StubFactory {
<T> T createStub(Transport transport, Class<T> serviceClass);
}
StubFactory工厂接口只定义了一个方法 createStub,它的功能就是创建一个桩的实例,这个桩实现的接口可以是任意类型的,也就是上面代码中的泛型 T。这个方法有两个参数,第一个参数是一个 Transport 对象,是用来给服务端发请求的时候使用的。第二个参数是一个 Class 对象,它用来告诉桩工厂:我需要你给我创建的这个桩,应该是什么类型的。createStub 核心逻辑是把方法名和参数封装成请求,发送给服务端,然后再把服务端返回的调用结果返回给调用方。
要解耦调用方和实现类,需要解决一个问题:谁来创建实现类的实例?我们上面定义的 StubFactory 它是一个接口,假如它的实现类是 DynamicStubFactory,调用方是 NettyRpcAccessPoint,调用方 NettyAccessPoint 并不依赖实现类 DynamicStubFactory,就可以调用 DynamicStubFactory 的 createStub 方法。一般来说,都是谁使用谁创建,但这里面我们为了解耦调用方和实现类,调用方就不能来直接创建实现类,因为这样就无法解耦了。这个问题怎么来解决?使用 Spring 的依赖注入是可以解决的。Java 语言内置的更轻量级的解决方案SPI也行。
服务端
RPC 服务
- 服务端的业务代码把服务的实现类注册到 RPC 框架中 ;
@Singleton public class RpcRequestHandler implements RequestHandler, ServiceProviderRegistry { @Override public synchronized <T> void addServiceProvider(Class<? extends T> serviceClass, T serviceProvider) { serviceProviders.put(serviceClass.getCanonicalName(), serviceProvider); logger.info("Add service: {}, provider: {}.", serviceClass.getCanonicalName(), serviceProvider.getClass().getCanonicalName()); } // ... } - 接收客户端桩发出的请求,调用服务的实现类并返回结果。
@Override protected void channelRead0(ChannelHandlerContext channelHandlerContext, Command request) throws Exception { RequestHandler handler = requestHandlerRegistry.get(request.getHeader().getType()); if(null != handler) { Command response = handler.handle(request); if(null != response) { channelHandlerContext.writeAndFlush(response).addListener((ChannelFutureListener) channelFuture -> { if (!channelFuture.isSuccess()) { logger.warn("Write response failed!", channelFuture.cause()); channelHandlerContext.channel().close(); } }); } else { logger.warn("Response is null!"); } } else { throw new Exception(String.format("No handler for request with type: %d!", request.getHeader().getType())); } } @Override public Command handle(Command requestCommand) { Header header = requestCommand.getHeader(); // 从payload中反序列化RpcRequest RpcRequest rpcRequest = SerializeSupport.parse(requestCommand.getPayload()); // 查找所有已注册的服务提供方,寻找rpcRequest中需要的服务 Object serviceProvider = serviceProviders.get(rpcRequest.getInterfaceName()); // 找到服务提供者,利用Java反射机制调用服务的对应方法 String arg = SerializeSupport.parse(rpcRequest.getSerializedArguments()); Method method = serviceProvider.getClass().getMethod(rpcRequest.getMethodName(), String.class); String result = (String ) method.invoke(serviceProvider, arg); // 把结果封装成响应命令并返回 return new Command(new ResponseHeader(type(), header.getVersion(), header.getRequestId()), SerializeSupport.serialize(result)); // ... }
如何聚合旁路系统
基于上节的基本实现,很直观的,我们可以将聚合旁路系统的问题 抽象为一个 如何在已有代码上 “加私货” 的问题。很自然的,会想到使用java 代理 拦截Iface 方法执行,然后加入旁路系统的相关代码。
每一个旁路子系统都有一系列的配置,在聚合的过程中,还需拉取这些配置。配置有以下来源
- xml 文件
- 后端管理界面 及其存储数据的 db
- zk node
- 用户代码中的注解
进阶篇——三高设计
- 单单解决有无问题很简单,解决好用不好用很难
- 这里充分体现了 基础知识多么的重要,比如linux io、tcp 流控等,当程序出现问题后,你才能有更广阔的排查方向。
如何轻松应对偶发异常 未读。
高性能设计
使用netty
- 框架启动时,预热内存。netty 的 pooledThreadcache比如arena获取内存有个锁,项目启动时大量请求突然打过来,会等着arena 分配内存,等待锁。千军万马在这个地方过了独木桥,排到后面的线程 便会处理超时。
- FixedChannelPool 在io线程里干 申请连接 以及 borrow、return 的活儿,效率低(是这个思维方向,细节待确认)
- WriteBufferWaterMark 含义重新理解。WriteBufferWaterMark 是从内存大小角度控制发送速度,netty还有一个 任务队列的长度限制,通常配置一个就行了,两者有一个很tricky的关系。(细节待确认)
- ioloop 里不能阻塞,甚至连写日志的逻辑都不能有,log4j 存在性能问题
- 快慢线程池,一个客户端可能依赖多个下游服务端,一开始无差别的处理各种服务端调用,但这些调用有快有慢,彼此影响。因此根据阈值,将比较慢的服务端调用放入慢线程池中。理由,netty 的 eventloop 会根据io和cpu 时间占比 来调整每次select 的阻塞时间。 这类似于 jvm heap 根据对象的有效期 将内存划分为 年轻代 和老年代。
- 根据监控,按照4个9的响应时间来设置超时时间,甚至可以考虑支持自动设置超时时间
对异步的支持
- 一次 RPC 调用的本质就是调用端向服务端发送一条请求消息,服务端收到消息后进行处理,处理之后响应给调用端一条响应消息,调用端收到响应消息之后再进行处理,最后将最终的返回值返回给动态代理。对于调用端来说,向服务端发送请求消息与接收服务端发送过来的响应消息,这两个处理过程是两个完全独立的过程,这两个过程甚至在大多数情况下都不在一个线程中进行。对于 RPC 框架,无论是同步调用还是异步调用,调用端的内部实现都是异步的。
- 调用端异步。调用端发送的每条消息都一个唯一的消息标识,实际上调用端向服务端发送请求消息之前会先创建一个 Future,并会存储这个消息标识与这个 Future 的映射,当收到服务端响应的消息时,通过之前存储的映射找到对应的 Future,将结果注入给那个 Future,动态代理所获得的返回值最终就是从这个 Future 中获取的;
- 服务端异步。
- RPC 服务端接收到请求的二进制消息之后会根据协议进行拆包解包,之后将完整的消息进行解码并反序列化,获得到入参参数之后再通过反射执行业务逻辑。IO 和 拆解包放在 处理网络 IO 的线程中,业务逻辑交给专门的业务线程池处理
- 业务线程池的线程数都是有限制的,如果业务逻辑处理得就是比较慢,当访问量逐渐变大时,业务线程池很容易就被打满了,比较耗时的服务很可能还会影响到其它的服务。需要 RPC 框架能够支持服务端业务逻辑异步处理,这是个比较难处理的问题,因为服务端执行完业务逻辑之后,要对返回值进行序列化并且编码,将消息响应给调用端,但如果是异步处理,业务逻辑触发异步之后方法就执行完了,来不及将真正的结果进行序列化并编码之后响应给调用端。需要 RPC 框架提供一种回调方式,可以让 RPC 框架支持 CompletableFuture
服务接口定义的返回值是 CompletableFuture 对象,在调用端与服务端之间完全异步,整个调用过程会分为这样几步:
- 调用方发起 RPC 调用,直接拿到返回值 CompletableFuture 对象,之后就不需要任何额外的与 RPC 框架相关的操作了
- 在服务端的业务逻辑中创建一个返回值 CompletableFuture 对象,之后服务端真正的业务逻辑完全可以在一个线程池中异步处理,业务逻辑完成之后再调用这个 CompletableFuture 对象的 complete 方法,完成异步通知;
- 调用端在收到服务端发送过来的响应之后,RPC 框架再自动地调用调用端拿到的那个返回值 CompletableFuture 对象的 complete 方法,这样一次异步调用就完成了。
合并部署:微服务过微,传输和序列化开销越来越大,将亲和性强的服务实例尽可能调度到同一个物理机,远程rpc 调用优化为本地rpc调用。
扩展性设计
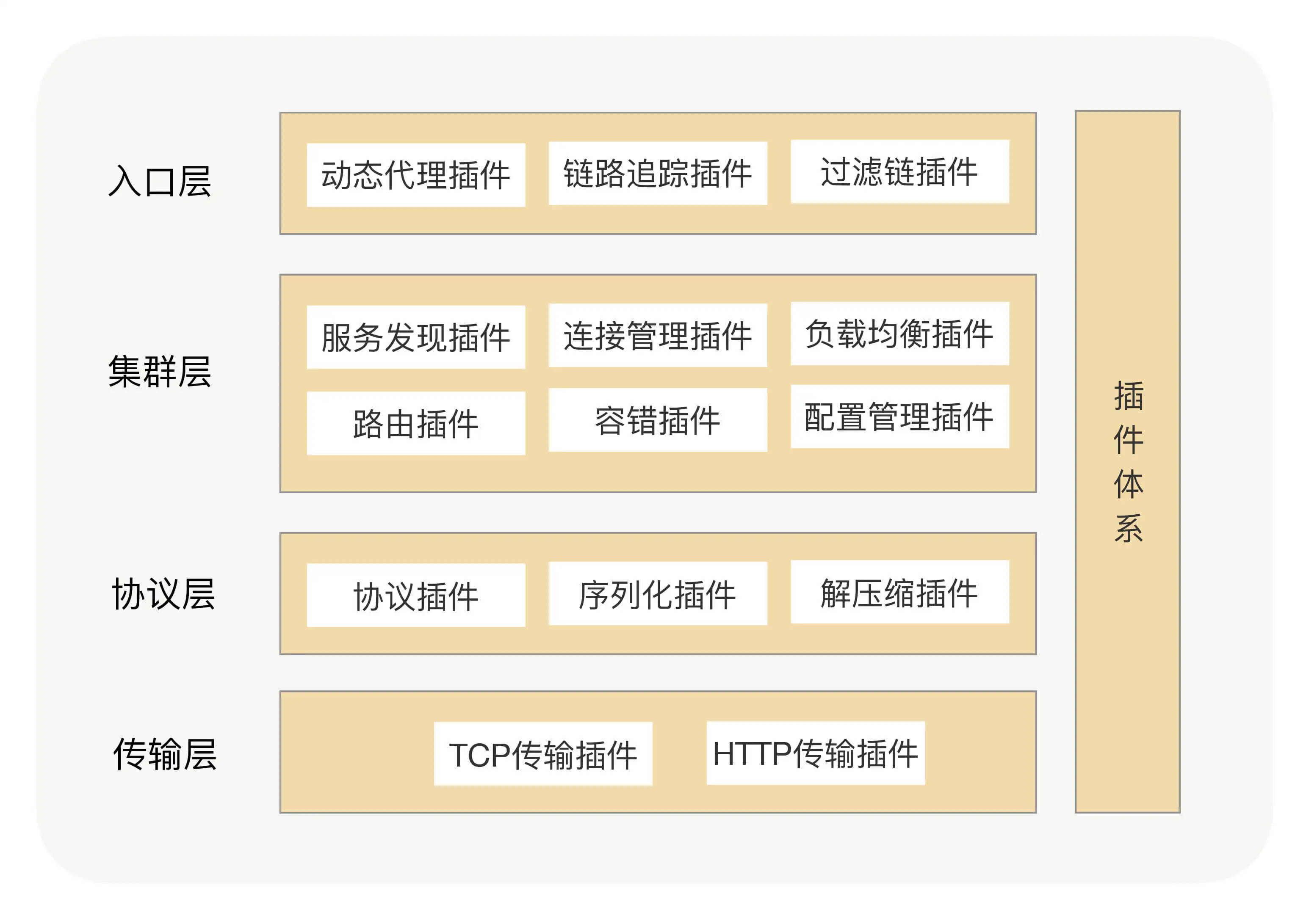 在 RPC 框架里面,我们是怎么支持插件化架构的呢?
在 RPC 框架里面,我们是怎么支持插件化架构的呢?
- 我们可以将每个功能点抽象成一个接口,将这个接口作为插件的契约,然后把这个功能的接口与功能的实现分离,并提供接口的默认实现。
- 在 Java 里面,JDK 有自带的 SPI(Service Provider Interface)服务发现机制,它可以动态地为某个接口寻找服务实现。使用 SPI 机制需要在 Classpath 下的 META-INF/services 目录里创建一个以服务接口命名的文件,这个文件里的内容就是这个接口的具体实现类。但在实际项目中,我们其实很少使用到 JDK 自带的 SPI 机制,首先它不能按需加载;如果依赖其它的扩展,那就做不到自动注入和装配
应用分组:在调用方复杂的情况下,如果还是让所有调用方都调用同一个集群的话,很有可能会因为非核心业务的调用量突然增长,而让整个集群变得不可用了,进而让核心业务的调用方受到影响。为了避免这种情况发生,我们需要把整个大集群根据不同的调用方划分出不同的小集群来,从而实现调用方流量隔离的效果,进而保障业务之间不会互相影响。某个分组的调用方流量突增,而这个分组所预留的空间也不能满足当前流量的需求,但是其它分组的服务提供方有足够的富余能力。我们可以调整分组配置,让一个分组瞬间拥有不同规模的集群能力。
泛化调用:关键在于要理解接口定义在 RPC 里面的作用。只要调用端将服务端需要知道的信息,如接口名、业务分组名、方法名以及参数信息等封装成请求消息发送给服务端,服务端就能够解析并处理这条请求消息。我们可以定义一个统一的接口(GenericService),调用端在创建 GenericService 代理时指定真正需要调用的接口的接口名以及分组名,而 GenericService 接口的 $invoke 方法的入参就是方法名以及参数信息。这个通过统一的 GenericService 接口类生成的动态代理,来实现在没有接口的情况下进行 RPC 调用的功能。通过泛化调用的方式发起调用,由于调用端没有服务端提供方提供的接口 API,不能正常地进行序列化与反序列化,我们可以为泛化调用提供专属的序列化插件,来解决实际问题。
class GenericService {
Object $invoke(String methodName, String[] paramTypes, Object[] params);
CompletableFuture<Object> $asyncInvoke(String methodName, String[] paramTypes, Object[] params);
}
Kitex 泛化调用案例:基于 API 网关的支付开放平台 未细读。
可靠性设计
-
通信层可靠性设计。
- 链路有效性检测——心跳机制。
- 客户端断连重连——为了保证服务端能够有充足的时间释放句柄资源,在首次断连时客户端需要等待 INTERVAL 时间之后再发起重连,而不是失败后就立即重连。无论什么场景下的重连失败,客户端都必须保证自身的资源被及时释放。
- 缓存重发
- 客户端超时保护。每次创建一个 Future,我们都记录这个 Future 的创建时间与这个 Future 的超时时间,并且有一个定时任务进行检测,当这个 Future 到达超时时间并且没有被处理时,我们就对这个 Future 执行超时逻辑。那定时任务该如何实现呢?使用时间轮机制。
- 针对客户端的并发连接数流控
- 内存保护
-
rpc 层可靠性设计
- rpc调用异常,服务路由失败;服务端超时;服务端调用失败
-
第三方服务依赖故障隔离
- 依赖隔离
- 异步化
其它
- 安全保证:服务提供方收到请求后,不知道这次请求是哪个调用方发起的,没法判断这次请求是属于之前打过招呼的调用方还是没有打过招呼的调用方,所以也就没法选择拒绝这次请求还是继续执行。我们需要给每个调用方设定一个唯一的身份,每个调用方在调用之前都先来服务提供方这登记下身份,只有登记过的调用方才能继续放行,没有登记过的调用方一律拒绝。HMAC 就是其中一种具体实现。服务提供方应用里面放一个用于 HMAC 签名的私钥,在授权平台上用这个私钥为申请调用的调用方应用进行签名,这个签名生成的串就变成了调用方唯一的身份。服务提供方在收到调用方的授权请求之后,我们只要需要验证下这个签名跟调用方应用信息是否对应得上就行了,这样集中式授权的瓶颈也就不存在了。
- 快速定位问题:在 RPC 框架打印的异常信息中,是包括定位异常所需要的异常信息的,比如是哪类异常引起的问题(如序列化问题或网络超时问题),是调用端还是服务端出现的异常,调用端与服务端的 IP 是什么,以及服务接口与服务分组都是什么等等。一款优秀的 RPC 框架要对异常进行详细地封装,还要对各类异常进行分类,每类异常都要有明确的异常标识码,并整理成一份简明的文档。并且异常信息中要包含排查问题时所需要的重要信息,比如服务接口名、服务分组、调用端与服务端的 IP,以及产生异常的原因。总之就是,要让使用方在复杂的分布式应用系统中,根据异常信息快速地定位到问题。
- 分布式链路跟踪,分布式链路跟踪就是将一次分布式请求还原为一个完整的调用链路,我们可以在整个调用链路中跟踪到这一次分布式请求的每一个环节的调用情况,比如调用是否成功,返回什么异常,调用的哪个服务节点以及请求耗时等等。这样如果我们发现服务调用出现问题,通过这个方法,我们就能快速定位问题,哪怕是多个部门合作,也可以一步到位。RPC 在整合分布式链路跟踪需要做的最核心的两件事就是“埋点”和“传递”。
- 全链路灰度 全链路灰度在数据库上我们是怎么做的? 挺好玩的
- 给流量打标:
```yaml
apiVersion: traffic.opensergo.io/v1alpha1
kind: TrafficLabelRule
metadata:
name: my-traffic-label-rule
labels:
app: spring-cloud-zuul
spec:
selector:
app: spring-cloud-zuul
trafficLabel: gray
match:
- condition: “==” # 匹配表达式 type: header # 匹配属性类型 key: ‘location’ # 参数名 value: cn-shenzhen # 参数值 ```
- 给 Workload 打标签:
apiVersion: traffic.opensergo.io/v1alpha1 kind: WorkloadLabelRule metadata: name: gray-sts-label-rule spec: workloadLabels: ['gray'] selector: db: mse-demo table: mse_demo_table_gray
- 给流量打标:
```yaml
apiVersion: traffic.opensergo.io/v1alpha1
kind: TrafficLabelRule
metadata:
name: my-traffic-label-rule
labels:
app: spring-cloud-zuul
spec:
selector:
app: spring-cloud-zuul
trafficLabel: gray
match:
对公司内rpc的观察:
- 熔断,熔断时99.99% 流量返回默认值,剩余的继续调用,作为探测
- 熔断恢复,慢恢复,探测成功后,每隔10s恢复10%的流量
- rpc client server 是否可以像tcp 一样流控一下,部分解决client发送速率 和 server 消费能力不一致的问题。
- 发生熔断时(失败率、超时超过一定量级),(client 包括业务线程和io线程),业务线程走降级逻辑,使得等待队列不再有或只有探测请求进来, 同时清理等待队列中的消息,清理连接池(因为连接很有可能已经不健康了)
限流的套路
限流有哪些套路?哪些坑?
- 固定时间窗口限流算法。限流策略过于粗略,无法应对两个时间窗口临界时间内的突发流量。假设我们的限流规则是,每秒钟不能超过 100 次接口请求。第一个 1s 时间窗口内,100 次接口请求都集中在最后 10ms 内。在第二个 1s 的时间窗口内,100 次接口请求都集中在最开始的 10ms 内。虽然两个时间窗口内流量都符合限流要求(≤100 个请求),但在两个时间窗口临界的 20ms内,会集中有 200 次接口请求。固定时间窗口限流算法并不能对这种情况做限制,所以,集中在这 20ms 内的 200 次请求就有可能压垮系统。
- 滑动时间窗口限流算法。流量经过滑动时间窗口限流算法整形之后,可以保证任意一个 1s的时间窗口内,都不会超过最大允许的限流值,从流量曲线上来看会更加平滑。假设限流的规则是,在任意 1s 内,接口的请求次数都不能大于K 次。我们就维护一个大小为 K+1 的循环队列,用来记录1s 内到来的请求。当有新的请求到来时,我们将与这个新请求的时间间隔超过 1s 的请求,从队列中删除。然后,我们再来看循环队列中是否有空闲位置。如果有,则把新请求存储在队列尾部(tail 指针所指的位置);如果没有,则说明这 1 秒内的请求次数已经超过了限流值K,所以这个请求被拒绝服务。 但对细粒度时间上访问过于集中的问题也只是部分解决
- 令牌桶算法
- 令牌生成,按照设定的速率生成令牌并放入桶中,桶满则丢弃。 静态限流,按固定速率生成token。动态限流:利用当前令牌的消耗速率去预估未来的消耗速率。自适应限流,在低流量场景下采用静态算法,在高流量场景下采用动态算法。
- 请求处理,当请求到达时,检查桶中是否有可用的令牌。如果有,消耗一个令牌并处理请求,如果没有,拒绝请求或将请求延迟处理。
- 桶存放选型:redis
- 漏桶算法
一个大牛开源的限流框架:wangzheng0822/ratelimiter4j
如果是同步发送请求,客户端需要等待服务端返回响应,服务端处理这个请求需要花多长时间,客户端就要等多长时间。这实际上是一个天然的背压机制(Back pressure),服务端处理速度会天然地限制客户端请求的速度。但是在异步请求中,客户端异步发送请求并不会等待服务端,缺少了这个天然的背压机制,如果服务端的处理速度跟不上客户端的请求速度,客户端的发送速度也不会因此慢下来,就会出现在途的请求越来越多,这些请求堆积在服务端的内存中,内存放不下就会一直请求失败。服务端处理不过来的时候,客户端还一直不停地发请求显然是没有意义的。为了避免这种情况,我们需要增加一个背压机制,在服务端处理不过来的时候限制一下客户端的请求速度。这个背压机制的实现也在 InFlightRequests (map<requestId,responseFuture>)类中,在这里面我们定义了一个信号量:private final Semaphore semaphore = new Semaphore(10);这个信号量有 10 个许可,我们每次往 inFlightRequest 中加入一个 ResponseFuture 的时候,需要先从信号量中获得一个许可,如果这时候没有许可了,就会阻塞当前这个线程,也就是发送请求的这个线程,直到有人归还了许可,才能继续发送请求。我们每结束一个在途请求,就归还一个许可,这样就可以保证在途请求的数量最多不超过 10 个请求,积压在服务端正在处理或者待处理的请求也不会超过 10 个。这样就实现了一个简单有效的背压机制。
只在系统存在不止一方,就有流量产生,就需要流量控制。多余的流量无处可去。于是自然地衍生出三种策略:
- 控制(Control),也就是背压。降低生产速率,从源头减少流量。
- 丢弃(Drop)。消费者将无暇处理的流量丢弃。在微服务架构中,通常有一个断路器(Circuit Breaker)的角色,在某个服务压力过大或系统不可用时,不再请求而直接返回默认值,可以认为是一种丢弃策略。
- 缓冲(Buffer)。管道将多余的流量存储起来。缓冲不应该是无限的(unbounded)。一方面如果生产者的速率长期大于消费者的速率,那么多余的流量将无限增加,即使流量可以用某种方式存储,这些流量预期被消费的时间也无限增加,满足不了业务需求。另一方面事实上无法实现真正的“无限”缓冲,它们最终都将受限于物理资源(内存、硬盘等),资源耗尽时,就不仅仅是流量丢失的问题了。如果是有限的缓冲,则当缓冲满了以后,又回到了背压和丢弃策略了。而丢弃可不可行通常得看业务需求,于是早晚我们又得实现背压策略。
如何实现背压?分为隐式背压(如 Callstack blocking)和显式背压(如 pull 模式)。
- Callstack blocking 是指阻塞整条调用链,例如提交任务到线程池,拒绝策略是阻塞,则线程池满了以后,整个线程会阻塞在提交的动作上,它隐式地阻塞了同一个线程上游的生产者。如果处理流程不在同一个线程上则难以实现,如任务在多个线程上运行或跨越多个微服务。
- 显式背压是指在业务逻辑中显式地实现生产者和消费者间的沟通达到流量控制的目的。例如 TCP 协议中通过交换当前接收窗口的大小来完成流量控制。
- 其中拉取(pull)模式则是比较通用且重要的一种,即任务的驱动是由消费者发起的,而不是生产者。例如 Reactive Stream 里的 API 规定是由订阅者(消费者)调用 request(n) 方法向生产者请求 n 个消息,生产者再调用 onNext() 将 n 个消息提供给消费者。消费者可以按需要获取,生产者也可以按需生产,从而实现背压。
- TCP 是最经典的示例了,协议本身提供背压,内核会保存一个有限(bounded)大小的发送缓冲,当缓冲满的时候,会阻塞 send 方法,即 callstack blocking 实现背压。这样接收方的压力就可以传导到发送方的 send 方法了。消息队列(如 Kafka)相当于提供了一个巨大(接近无限)的缓冲,这样它的上下游之间就不需要有压力的传导了,多余的流量全在队列上。
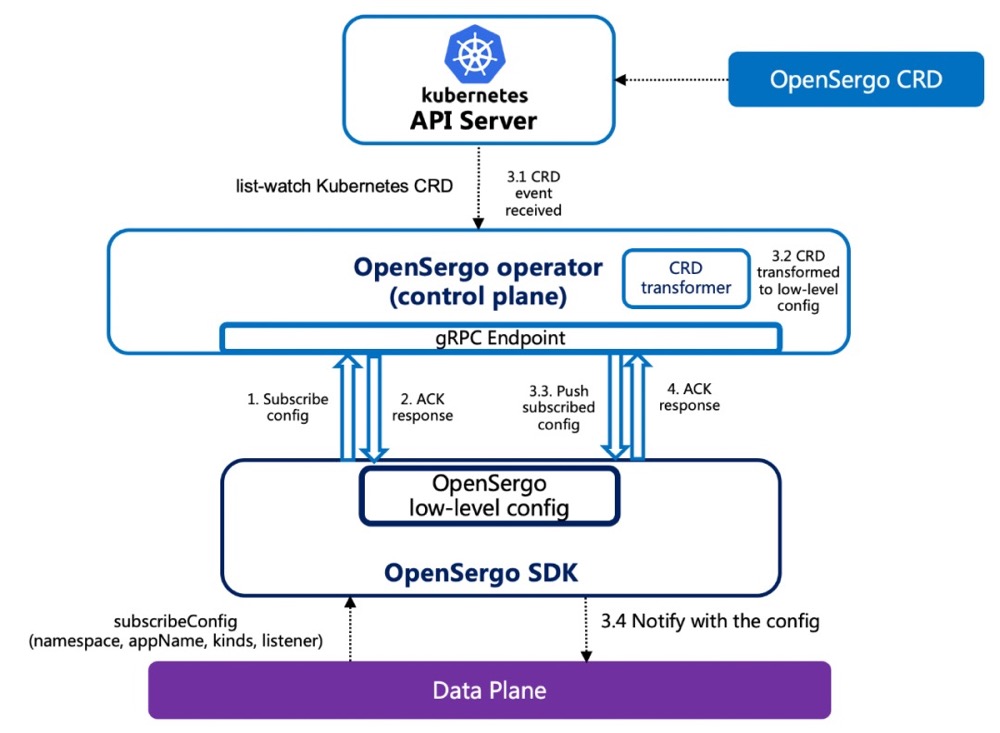
微服务治理标准OpenSergo
跨不同开发语言和技术框架,微服务治理规范OpenSergo项目正式开源
算法实战(四):剖析微服务接口鉴权限流背后的数据结构和算法开放、通用的、面向分布式服务架构、覆盖全链路异构化生态的服务治理标准 OpenSergo。在 OpenSergo 中,对流控降级与容错场景的实现抽象出标准的 CRD,只要微服务框架适配了 OpenSergo,即可通过统一 CRD 的方式来进行流控降级等治理。PS: Sentinel 是阿里巴巴开源的,面向分布式服务架构的流量控制组件,主要以流量为切入点,从流量控制、流量整形、熔断降级、系统自适应保护等多个维度来帮助开发者保障微服务的稳定性, OpenSergo 可以理解为是一个商业化版本的Sentinel。一流企业定标准。
“天猫双11”背后的流量治理技术与标准实践在 OpenSergo 中,我们结合 Sentinel 等框架的场景实践对流量防护与容错抽出标准 CRD。一个容错治理规则 (FaultToleranceRule) 由以下三部分组成:
- Target: 针对什么样的请求。可以通过通用的 resourceKey(Sentinel 中即为资源名的概念)来标识,也可以用细化的规则来标识(如具有某个特定 HTTP header 的请求)
- Strategy: 容错或控制策略,如流控、熔断、并发控制、自适应过载保护、离群实例摘除等
- FallbackAction: 触发后的 fallback 行为,如返回某个错误或状态码
无论是 Java 还是 Go 还是 Mesh 服务,无论是 HTTP 请求还是 RPC 调用,还是数据库 SQL 访问,我们都可以用这统一的容错治理规则 CRD 来给微服务架构中的每一环配置容错治理,来保障我们服务链路的稳定性。只要微服务框架适配了 OpenSergo,即可通过统一 CRD 的方式来进行流量防护等治理。
以下 YAML CR 示例定义的规则针对 path 为 /foo 的 HTTP 请求(用资源名标识)配置了一条流控策略,全局不超过 10 QPS。当策略触发时,被拒绝的请求将根据配置的 fallback 返回 429 状态码,返回信息为 Blocked by Sentinel,同时返回 header 中增加一个 header,key 为 X-Sentinel-Limit, value 为 foo。
apiVersion: fault-tolerance.opensergo.io/v1alpha1
kind: RateLimitStrategy
metadata:
name: rate-limit-foo
spec:
metricType: RequestAmount
limitMode: Global
threshold: 10
statDuration: "1s"
---
apiVersion: fault-tolerance.opensergo.io/v1alpha1
kind: HttpRequestFallbackAction
metadata:
name: fallback-foo
spec:
behavior: ReturnProvidedResponse
behaviorDesc:
# 触发策略控制后,HTTP 请求返回 429 状态码,同时携带指定的内容和 header.
responseStatusCode: 429
responseContentBody: "Blocked by Sentinel"
responseAdditionalHeaders:
- key: X-Sentinel-Limit
value: "foo"
---
apiVersion: fault-tolerance.opensergo.io/v1alpha1
kind: FaultToleranceRule
metadata:
name: my-rule
namespace: prod
labels:
app: my-app
spec:
selector:
app: foo-app # 规则配置生效的服务名
targets:
- targetResourceName: '/foo'
strategies:
- name: rate-limit-foo
fallbackAction: fallback-foo
OpenSergo & Spring Cloud Alibaba 带来的服务治理能力
微服务不是银弹
20200527 补充:一些比较好的解决方法 如何提升微服务的幸福感
带来的问题
单体服务 ==> 通过 rpc 分割为微服务 ==> 带来以下问题:
- 查看日志 定位问题要看好几台机器
- 调用链路 较长的情况下,网络通信也是一种开销
- 一个服务出现问题,容易在整个微服务网络蔓延(通过熔断器部分解决)
PS: 灰度发布服务时,停掉老服务之前,一般要等老服务处理完 已经接收到的用户请求再销毁,那么如何判断服务已经将用户请求处理完毕呢?
- 服务提供零流量检查接口
- 约定所有用户请求的最长处理时间,收到停止服务命令后,等待最长处理时间后再销毁。 解决微服务架构下流量有损问题的实践和探索 更全面的梳理无损发布的问题。 应用发布新版本如何保障流量无损
拆分服务
我们为什么要做微服务?对这个问题的标准回答是,相对于整体服务(Monolithic)而言,微服务足够小,代码更容易理解,测试更容易,部署也更简单。这些道理都对,但这是做好了微服务的结果。怎么才能到达这个状态呢?这里面有一个关键因素,怎么划分微服务,也就是一个庞大的系统按照什么样的方式分解。领域驱动。
拆分服务的几种考虑:
- 服务下沉: 将具有两个以上使用者的服务下沉,使其成为一种基础服务。
- 将负载不一致的几个服务拆分,减少彼此的相互影响
- 将关键链路的服务拆分,减少代码迭代对关键链路的影响
微服务到底要多微?CCP/共同闭包原则是说,包中包含的所有类应该是同类的变化的一个集合,也就是说,如果对包做出修改,需要调整的类应该都在这个包之内。 在微服务架构下采用CCP原则,我们就能把同样原因进行变化的服务放在一个组件内。这样,当需求发生变化时,变更和部署也更加容易。理想情况下,一个变更只会影响一个团队和一个服务。破坏CCP的场景,很容易就能发现。
服务编排
服务分层
超复杂调用网下的服务治理新思路 很多公司未来也会发展到调用网极其复杂的境地
- 内网非测试的微服务达 1000 个以上
- 至少存在一个微服务,且其实例数达到 300 个以上
- 对外 API 普遍涉及至少 10 个微服务 为了帮助业务实现健康过渡,大家最好能够做两个布局。PS: 横向分层增加复用。层内分域进行治理。
- 第一个布局是把服务分层做得足够好。
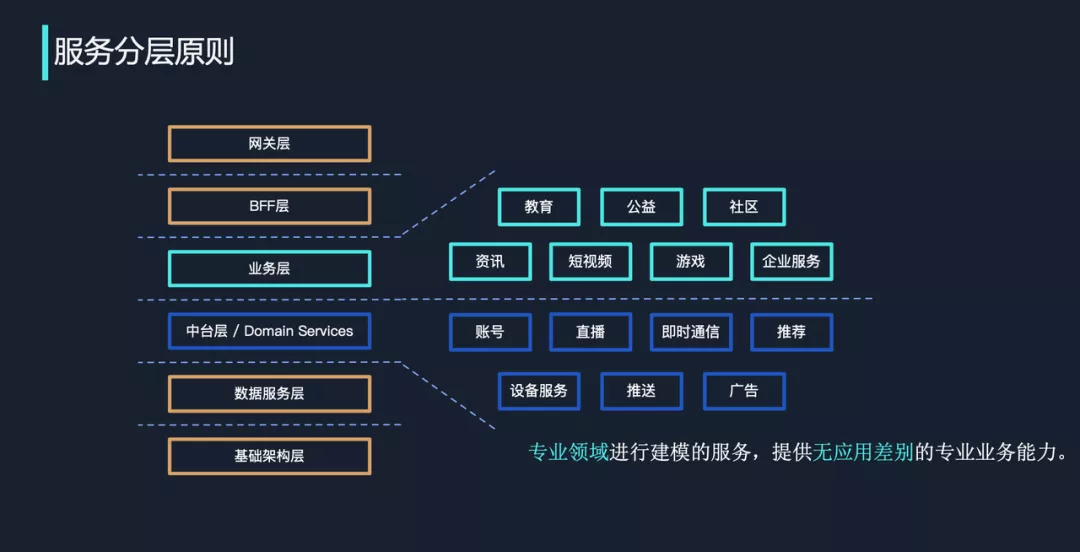
- 第二个布局是梳理调用链,根据调用链提炼服务域。服务域内一是域管理员自行决定部署策略,二是要根据目标服务域按条件分流(按地域、按uid;应对高流量)。对于服务域之间的流量,在域管理员确定部署策略之后,它会根据目标服务域的调度策略进行分流。
演化
软件架构如何“以不变应万变”微服务最近几年的一些变化
- 微服务会促进大家逐渐去用更加高效的语言。以 Golang 举例来说,Golang 特别适合在云原生场景下使用,一方面 Golang 没有 Java 那么重的启动的依赖,另一方面容器也提供了一套相对统一的执行环境,这种场景下是没有必要再去使用字节码的。而 Golang 的广泛应用也解决了一些开发效率上的问题。
- 在多运行时、Service Mesh 上的一些改变,做业务和基础设施的解耦,这给基础设施提供了更大的发展空间,对于业务和技术能力的迭代都有着非常重要的价值。
- 比较大的变化就是构建可观测性,比如 Tracing 或者 OpenTelemetry。微服务洞察,让微服务更透明 方法调用链路、方法级的请求参数等采集、汇总查看。==> 排查问题所需的任何操作是不是都可以做在页面上。
留下评论