大模型Post-Training
简介
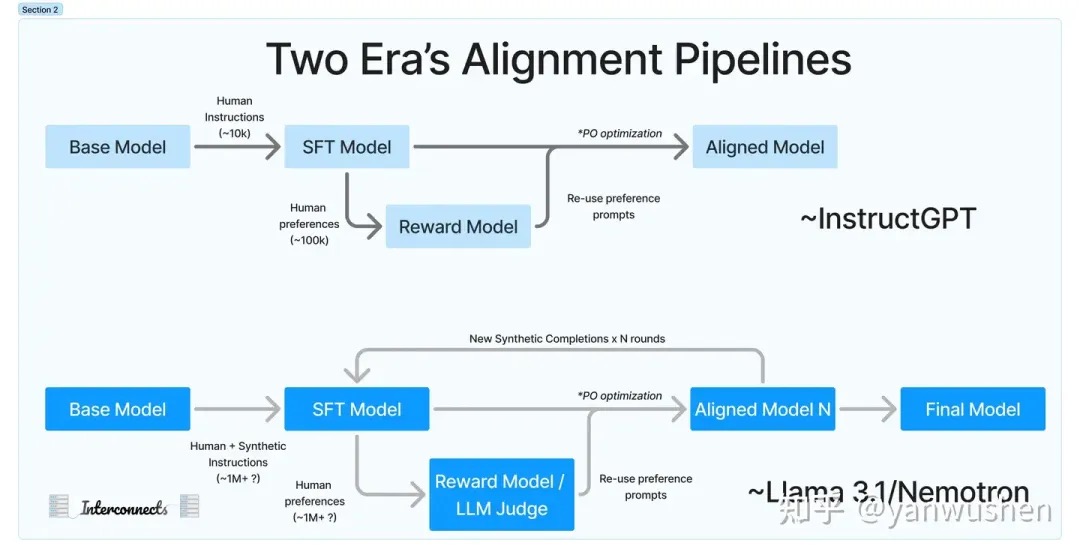
关于post-training和一些思考在GPT刚问世的时候,业界对于RLHF的作用还存在质疑。许多公司发现,仅仅使用SFT就足以满足他们的需求。甚至在Meta内部,对于是否应该使用RL技术也存在分歧。但是随着DPO等算法的推出,以及开源社区更多经验的分享,业界逐渐接受了RLHF这一训练环节的重要性。学术界提出了各种XPO方法,而工业界也提出了多种PPO的替代算法。逐渐认识到RLHF的价值:RLHF能够在各种评测榜单中显著提高模型分数(刷分利器),在定制化这块也很有前景,对聊天风格的转换这一点很重要,它使得OpenAI发布的mini小模型都能在Arena中排前三,这一点也许正是国内大模型欠缺的。总结来说post-training的转变可以参照下图,可以明显的看出alignment阶段规模的扩大。
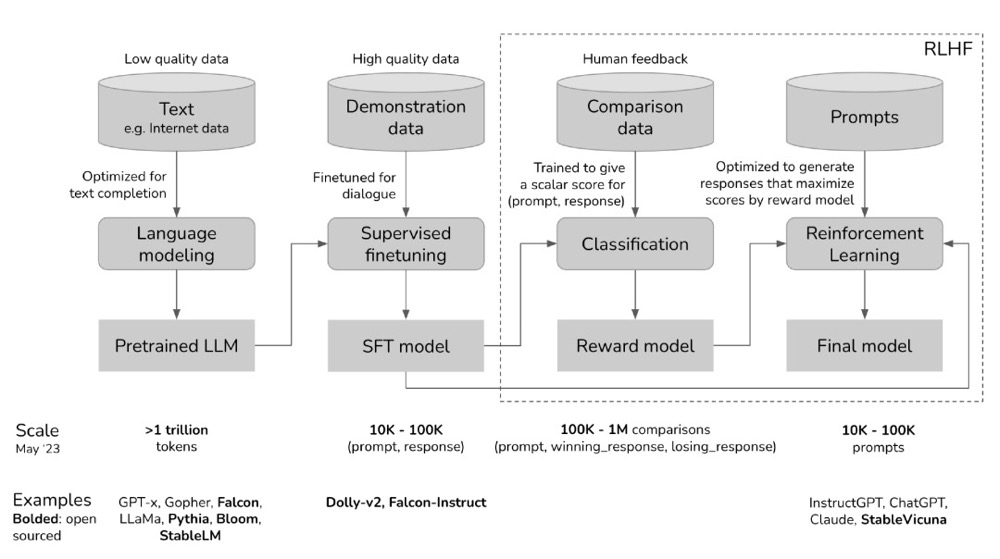
- 预训练模型是一个未加控制的“怪物”,因为其训练数据来源于对互联网内容的无差别抓取,其中可能包括点击诱导、错误信息、政治煽动、阴谋论或针对特定人群的攻击等内容。
- 在使用高质量数据进行微调后,例如StackOverflow、Quora或人工标注,这个“怪物”在某种程度上变得可被社会接受。
- 然后通过RLHF进一步完善微调后的模型,使其更符合客户的需求,例如,给它一个笑脸。 你可以跳过这三个阶段中的任何一个阶段。例如,你可以直接在预训练模型的基础上进行RLHF,而不必经过SFT(Supervised Fine-Tuning,监督微调)阶段。然而,从实证的角度来看,将这三个步骤结合起来可以获得最佳性能。预训练是资源消耗最大的阶段。对于InstructGPT模型,预训练阶段占据了整体计算和数据资源的98%。可以将SFT和RLHF视为解锁预训练模型已经具备、但仅通过提示难以触及的能力。
解析大模型中的Scaling Law在大模型的研发中,通常会有下面一些需求:
- 计划训练一个10B的模型,想知道至少需要多大的数据?
- 收集到了1T的数据,想知道能训练一个多大的模型?
- 老板准备1个月后开发布会,能用的资源是100张A100,那应该用多少数据训一个多大模型最终效果最好?
- 老板对现在10B的模型不满意,想知道扩大到100B模型的效果能提升到多少?
从 PPO 到 GRPO,RL 算法(也算是一种Optimizer)基于奖励信号更新策略模型参数,平衡“性能提升”与“策略稳定性”。
演进
在线学习,离线学习两种微调方法在数学上是等价的,它们理想的训练终点都是达到最大似然拟合。在线强化学习(两阶段训练 RM, RL), 明显好于离线学习(DPO,SFT,IPO)。在线强化学习更有效的原因是由于,验证模型与生成模型的不对称性。也可以说是对于验证容易问题, 验证模型能提供有效的反馈信号, 让模型更有效的学习。
如何理解 LLM 中的 RL 算法? 非常经典,值得细读。好的文章越读越清晰、收敛。 ybq:我不在乎算法是 sft 或 rlhf,也不纠结监督学习和强化学习在理论上有何本质区别。我只关心,哪种 loss 能让模型达到更好的效果。因此,“直接对模型上 ppo 算法就能起效果”这一结论对算法从业者来说完全不吃惊。sft 本就不是训 LLM 的必备环节,但如果说 sft 完全无用也属实是过激了,毕竟只看 loss 函数的话完全可以这么理解:sft 就是在每个 token 粒度都有一个 reward_model 的 ppo 算法。deepseek在技术报告里指出过,sft 和 rlhf 算法在 loss 函数的设计上没有本质区别。具体来说,deepseek 认为 post training 算法包括三要素:启动数据,reward function,token 粒度的 gradient coefficient。sft 的 Gradient Coefficient 是 1,ppo 的 Gradient Coefficient 是 Advantage。既然两种算法在 loss 函数上没有本质区别,他们的区别又体现在哪里呢?我个人的观点是:explore。rl鼓励模型去explore。
- sft是数据质量不足(或者不可判别任务)下的一种妥协。如果有质量很高的rule reward数据,那其实做rlhf更好一点。 PS: SFT有类似ground truth,而rl 只是给出多个采样结果的好坏,但都是转为loss。
- sft 的训练过程,是每个 token 都有一个明确的 target 存在的,其优化目标很纯粹,增大这个 target 的概率。但 rl 不同,每个 token 的 reward 是由整个句子的 reward 回传回来的(带上 value function 的预测),试想一个句子“中国的首都不是南京,是北京”,因为太过啰嗦被打上了一个较低的 reward,那问题是“是南京”这三个 token 做错了什么,在上个 token 的回答是“不”的情况下,这三个 token 已经是当下最优的 token 了。此时,如果 value function 能救回来还好,但显然不太容易。这里注意,传统的 rl,每一个 action 是能有一个及时回报的,但 rlhf 算法中是没有的,它只有折扣累积回报(rlhf 中,每个 action 的及时回报,要么被设置成 0,要么被设置成 kl_penalty),这也进一步导致了 token 级别 reward 的不准确。就这,还都是建立在整个 response 的 reward 打分准确的基础上,打不准就更头大了。如何给每个 token 一个正确的打分,那就是 ppo / grpo / rloo 等算法各自的努力方向了,它们的出发点和实现方式各不相同,甚至对 KL_penalty 施加的位置都不同,有的放进 reward 中,有的放进 advantage 中。熟优熟劣,就要靠各位的实验结论和理论推导了,我暂时没有结论。其实就是想说因为 label 不准, rl 天生比 sft 不太好训练,因此才需要那么多的调参工作。再次提醒,不管什么算法,你只要把 reference_model 的 KL_penalty 开得足够大,都会稳如泰山。
- reward hacking 其实就是模型以训练者不期望的方式找到了提高 reward 的方法。我们想要的是模型按照某种方法提高 reward,但我们设计的 reward 函数却只在乎 reward,而不在乎“按照某种方法”,那么自然而然的就会不符合预期。万变不离其宗,有多少人工就有多少智能。sft 要时刻留意数据质量,rlhf 则是要时刻留意 reward 的打分是否准确或者说是 reward 的设计是否合理,后者一点都不比洗数据轻松。
RLHF 是一个完整技术框架,PPO 仅仅是其中强化学习算法模块的一种实现方式。人类反馈构造出偏好对齐数据集以便训练RM,正因为有了RM,才能让强化学习有了发挥的空间,让sft后的模型有了进一步的提升。但偏好对齐一定需要RL嘛?偏好对齐一定需要人类反馈吗?偏好对齐一定需要训练RM嘛?偏好对齐一定需要大量偏好样本么?
系统梳理LLM+RLHF发展脉络 非常经典,建议细读。 chatgpt所用的RLHF流程,首先BT模型的假设来训练Reward model。BT模型假设可以对每个query-response对(x,y)单独打分,即可以采用point-wise形式的reward来表述一个(x,y)的好坏。然后我们就可以基于该假设,训练出为每个query-response对(x,y)打分的reward model了。在获得reward model后,为了避免RL算法过度优化reward model所学习的偏好,从而使LLM出现“胡言乱语”的表现,通常会在优化目标中加入对原有策略的KL惩罚,这样我们就得到了最初的优化目标(Optimization Gaol)了。对于response层级的reward,最终,我们会将其转成token-level的累积reward。
如何用一个统一的视角,分析RLHF下的各种算法? PS:大佬们一直在试图寻找统一脉络。思路一般不是突变的。
系统梳理LLM+RLHF发展脉络 未细读。
PPO(Proximal Policy Optimization)
PPO & GRPO 可视化介绍PPO(proximal policy optimization),包含三部分:
- Policy: 已预先训练/SFT 的 LLM;
- Reward model:一个经过训练和冻结的网络,在对提示做出完全响应的情况下提供标量奖励;
- Critic:也称为值函数,它是一个可学习的网络,它接受对提示的部分响应并预测标量奖励。比如有些步骤很重要,那么score就很高。对于一些既定好的工作流肯定是适用的,但是LLM如果要思考不定长步骤,那么这个模型并不好定义,更不好训练。
具体工作流程:
- Generate responses: LLM 为给定的prompt生成多个response;
- Score responses: reward model 给每个 response 分配 reward;
- Compute advantages: 使用 GAE 计算 advantages (it’s used for training the LLM);
- Optimise policy: 通过优化总目标来更新 LLM;
- Update critic: 训练 value function以更好地预测给定部分响应的奖励。
General Advantage Estimation (GAE) Our policy is updated to optimise advantage,直观解释,它定义了一个特定的动作$a_t$与policy 在状态$s_t$决定采取的average action相比 “how much better”。 \(A_t = Q(s_t,a_t)-V(s_t)\) 估计这种Advantage有两种主要方法,每种方法各有优劣:
- Monte-Carlo (MC):使用reward of the full trajectory(完整轨迹的奖励)(即完整响应)。由于奖励稀疏,这种方法具有很高的方差——从 LLM 中获取足够的样本来使用 MC 进行优化是昂贵的,但它确实具有低偏差,因为我们可以准确地对奖励进行建模;
- Temporal difference (TD):使用 one-step trajectory reward(一步轨迹奖励)(即根据提示测量刚刚生成的单词有多好)。通过这样做,我们可以在token级别上计算奖励,这大大降低了方差,但与此同时,偏差也会增加,因为我们无法准确地预测部分生成的响应的最终奖励。
如果响应不完整,奖励模型将返回 0(只有对于 LLM 的完整响应,奖励模型才会返回非零标量分数),在不知道奖励在生成单词之前和之后会如何变化的情况下,我们将如何计算 TD?因此,我们引入了一个模型来做到这一点,我们称之为 “the critic”。The critic 受过训练(critic在训练中对奖励模型的分数进行了简单的 L2 损失),可以预期仅给出部分状态的最终奖励,以便我们可以计算 TD。虽然奖励模型R在 PPO 之前进行了训练并被冻结,尽管R的工作只是预测奖励,但 critic 与 LLM 一起进行了训练。这是因为 value 函数必须估计给定当前策略的部分响应的奖励;因此,它必须与 LLM 一起更新,以避免其预测过时和不一致。这就是actor-critic in RL。通过critic V,我们现在有办法预测部分状态的奖励。
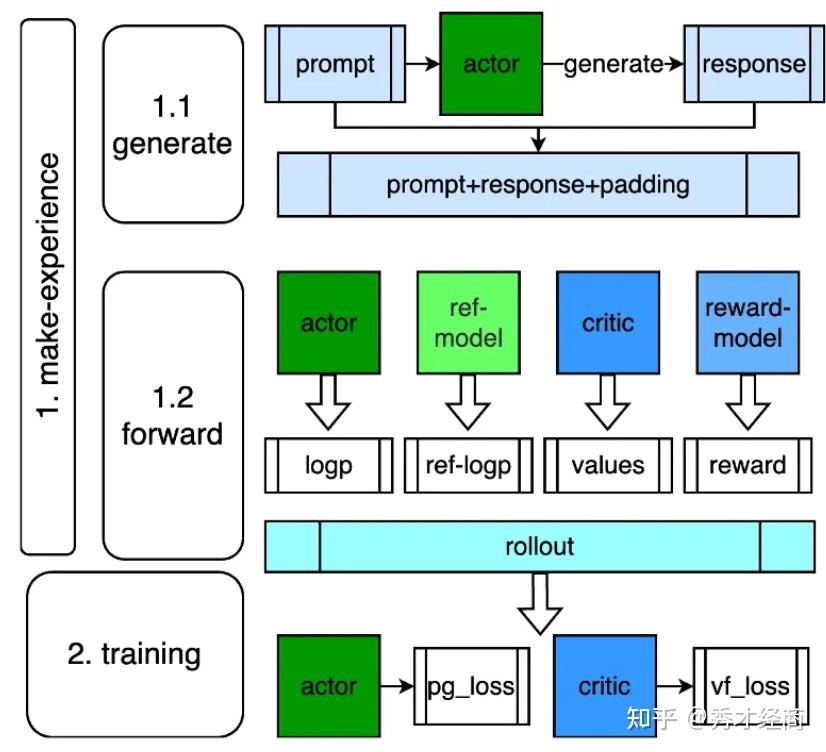
使用PPO优化pipeline,有几个明显挑战,比如需要在学习过程中启动4个模型:actor model,reference model,reward model,critic model。如果为了提升训练效率,还可额外部署infer model。在游戏、机器人等领域,这几个模型通常size都比较小,为了效果多部署几个模型可以接受。但在LLM领域中,为了效果导致模型size剧增,同时也需要更为复杂的调度方式,总体来说,PPO优化pipeline对资源使用和调度带来了不小挑战。
人人都能看懂的RL-PPO理论知识 未读,建议细读。
拆解大语言模型RLHF中的PPO 先用一段伪代码把大语言模型RLHF中的PPO 三部分采样、反馈和学习的关系简要说明一下
policy_model = load_model()
for k in range(20000):
# 采样(生成答案)
prompts = sample_prompt()
data = respond(policy_model, prompts)
# 反馈(计算奖励)
rewards = reward_func(reward_model, data)
# 学习(更新参数)
for epoch in range(4):
policy_model = train(policy_model, prompts, data, rewards)
明确一个概念——策略(policy,有点地方叫actor,就是我们想要训练出来的大模型),它就是RLHF中的“学生”。policy由两个模型组成,一个叫做演员模型(Actor),另一个叫做评论家模型(Critic)。它们就像是学生大脑中的两种意识,一个负责决策,一个负责总结得失。评论家/Critic就是将演员/Actor模型的倒数第二层连接到一个新的全连接层上。除了这个全连接层之外,演员和评论家的参数都是共享的
policy_model = load_model()
ref_policy_model = policy_model.copy()
for k in range(20000):
# 采样
prompts = sample_prompt()
responses, old_log_probs, old_values = respond(policy_model, prompts)
# 反馈
scores = reward_model(prompts, responses)
ref_log_probs, _ = analyze_responses(ref_policy_model, prompts, responses)
rewards = reward_func(scores, old_log_probs, ref_log_probs)
# 学习
advantages = advantage_func(rewards, old_values)
for epoch in range(4):
log_probs, values = analyze_responses(policy_model, prompts, responses)
actor_loss = actor_loss_func(advantages, old_log_probs, log_probs)
critic_loss = critic_loss_func(rewards, values)
loss = actor_loss + 0.1 * critic_loss
train(loss, policy_model.parameters())
PS:actor model根据prompt 产生response,reward model 根据(prompt, response)得出reward score,简单情况下,我们根据loss=loss_func(score) 得到loss 就可以更新actor model了。但是考虑到,actor model 不合适偏差ref model太远,所以引入actor_loss,loss=loss_func(score,actor_loss)。又是基于啥考虑引入critic_model 和critic_loss 呢?
算法的一些缺点也越来越被注意到:
- PPO需要四个模型协同训练(policy、critic、ref、reward),显存耗费比较大。PS:GRPO 移除了critic,找了一个新的策略替代critic
- PPO在训练过程是policy-critic的交叉更新,容易导致训练过程的不稳定
DPO(Direct Preference Optimization)
在训练奖励模型RM的过程中,我们就已经在考虑“什么回答是好的,什么回答是不好的”这个问题了。而对齐模型依然是在考虑这个问题。所以,我们能不能避开奖励模型的训练,直接一步到位训练对齐模型呢?
- RLHF算法包含奖励模型(reward model)和策略模型(policy model,也称为演员模型,actor model),基于偏好数据以及强化学习不断迭代优化策略模型的过程。RLHF常使用PPO作为基础算法,整体流程包含了4个模型,且通常训练过程中需要针对训练的actor model进行采样,因此训练起来,稳定性、效率、效果不易控制。
- 在实际rlhf-ppo的训练中,存在【显存占据大】、【超参多】、【模型训练不稳定】等一系列问题。所以,在考虑“一步到位训练对齐模型”的过程中,我们是不是也能顺手做到绕过强化学习,采用一个更简单的方式(比如类似于sft)来使用偏好数据训练对齐模型呢?
- DPO算法不包含奖励模型和强化学习过程,通过对成对偏好数据直接优化模型,无需在微调时从模型采样生成数据,因此整个训练过程简单、高效,主要的改进之处体现在于损失函数。DPO算法仅包含RLHF中的两个模型,即演员模型(actor model)以及参考(reference model),且训练过程中不需要进行数据采样。DPO算法的目的是最大化奖励模型(此处的奖励模型即为训练的策略),使得奖励模型对chosen和rejected数据的差值最大,进而学到人类偏好。
偏好数据,可以表示为三元组(提示语prompt, 良好回答chosen, 一般回答rejected)。
Self-Play RL(细节移步其它文章)
OpenAI-O1之下,我们技术该何去何从o1 则再次证明了强化学习的重要性。dpo 是我这种没有强化基础的老 nlp 从业者的一块遮羞布,o1 则完全撕下了这张遮羞布。不学强化,不训 reward_model 是吧,那就抱着 sft / dpo 这些老古董一辈子技术落后别人吧。
GRPO(Group Relative Policy Optimization)
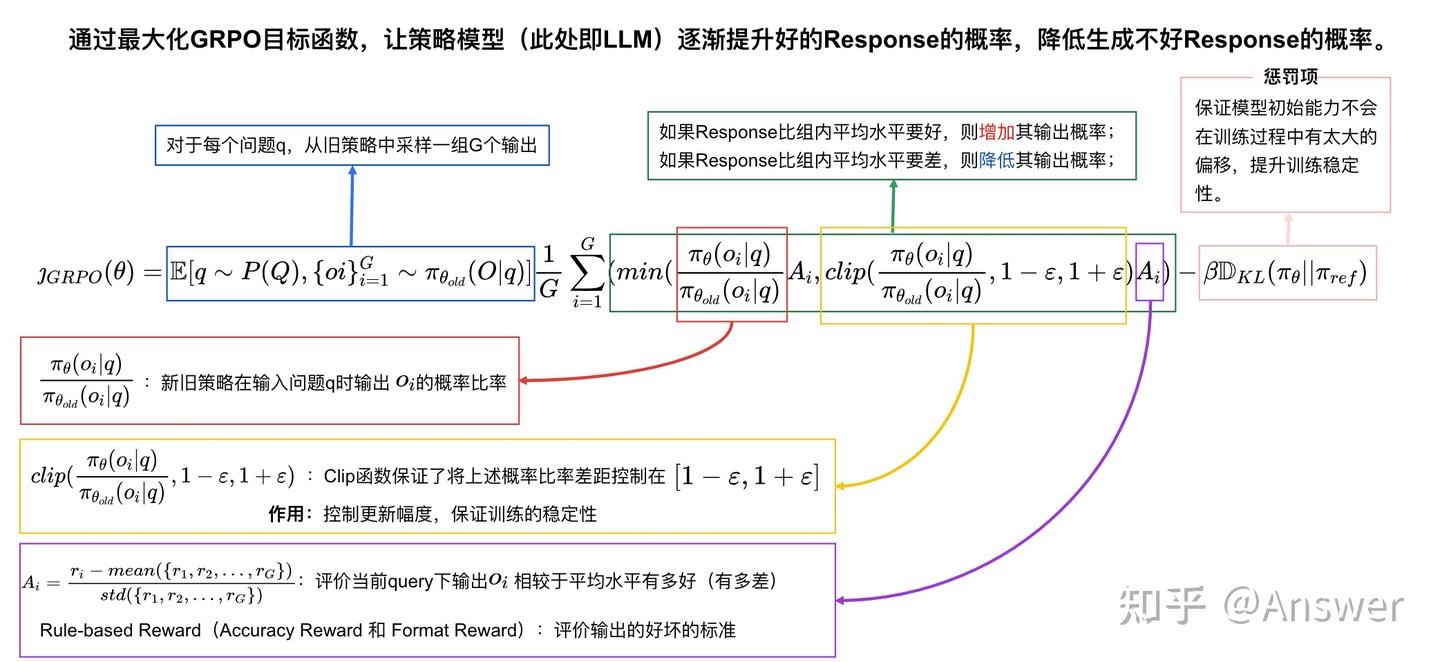
DeepSeek-R1 核心强化学习算法 GRPO 详解 PS:base llm对一个prompt 生成batch 个结果(O1,O2,…),基于规则(而不是reward)打分,如果某个Ox 比batch平均分高,则增加其输出概率,否则降低其输出概率。
- GRPO 对 PPO 的改进,其动机是 PPO 需要 4 个大模型,即策略、价值函数、奖励模型和参考模型。GRPO 消除了对价值模型的需求。为此,它首先为每个查询生成多个响应。然后,在计算advatage时,它将 value 函数替换为样本的奖励,该奖励由同一查询的所有响应的 mean 和 std 标准化。此外,它还将 KL 惩罚移动到损失函数中(RLHF 通常将 KL 惩罚添加到奖励中),从而简化了优势的计算。
- DPO会整体计算并优化某个response,无法发现具体错误并针对单个step进行独立优化
- 基于相对优势:GRPO 算法关注的是组内样本之间的相对优势,而非绝对的奖励值。在一个批次的样本中,它通过比较不同样本的奖励来确定每个样本的相对优劣,以此作为优化策略的依据。这种相对优势的计算可以减少奖励函数的偏差和方差,使训练更加稳定。
案例
- Qwen2.5的后训练路径是SFT + Two-stage Reinforcement Learning,即PPO->DPO->GRPO。
- TULU 3的后训练路径是SFT->DPO->RLVR。
- DeepSeek-V3的后训练路径是DPO->PPO->GRPO。RM的策略也在不断演进,rule-based RM与model-based RM并重,同时最新的DeepSeek-V3中还使用了self-rewarding策略,使得模型能够不断自我改进。
- Llama 3后训练方法是迭代式的,总共做了6轮。每轮的核心操作是:Reward Modeling,Rejection Sampling,SFT,DPO。
有几点结论:
- GRPO/PPO 与 DPO之争,似乎还没有明确的高下之分。LLaMA偏向DPO,DeepSeek偏向使用GRPO,Qwen则是两者相结合。
- 不管使用GRPO/PPO还是使用DPO, RM都是特别关键的(即便采用DPO进行RL,也需要使用RM进行Rejection Sampling),各个模型每次更新几乎都会提及一些RM的优化点和关键。
- RL阶段几乎是必须的,尤其是对于代码/数学等强推理场景,RL对于模型能力提升起到关键作用。
张俊林:MCST树搜索会是复刻OpenAI O1/O3的有效方法吗 讲的很详细。post-trainning 分为几个阶段,每个阶段准备什么样的数据。尤其是有几张图,很有借鉴意义。
常见技术
拒绝采样(Rejection Sampling)
通俗解释:是通过一个已知的、易于采样的提议分布(proposal distribution)来近似目标分布,并通过接受或拒绝样本的机制(基于规则或者reward?),最终得到符合目标分布的样本集。比如 想从一个目标分布(每个事件的概率为$\frac{1}{7}$)中采样,但直接实现较为困难。于是,我们从另一个易于采样的分布(单次掷骰子,概率为$\frac{1}{6}$)中生成样本。由于该分布无法完全覆盖目标分布,我们通过扩展它(即掷两次骰子),将样本空间扩大到6*6=36种可能性,从而包含目标分布。接下来,按照某种规则丢弃不符合条件的样本(例如,双六的组合)。对于剩余的样本,我们重新调整概率分布(平均分成7组),使其匹配目标分布。最终,接受的样本可以视为从目标分布中采样得到的。
数学解释:假设我们想从一个复杂的目标分布 p(x)中采样,但直接采样难度很高。我们引入一个辅助分布 q(x),它满足:
- 易采样性,我们可以轻松从 q(x)中生成样本。
- 包络条件,存在一个常数 M使得对任意 x,目标分布满足 p(x)≤Mq(x)
步骤:
- 从 q(x)中生成一个候选样本 $x^*$。
- 计算样本的接受概率:$Paccept(x^∗)=p(x^∗)/Mq(x^∗)$
- 生成一个随机数$u∼U(0,1)u$ (从均匀分布中采样)。
- 如果 $u≤Paccept(x^∗)u$,接受这个样本;否则拒绝并重新采样。
拒绝采样LLM 的拒绝采样操作起来非常简单:让自己的模型针对 prompt 生成多个候选 response(rollout?),然后用 reward_model 筛选出来高质量的 response (也可以是 pair 对),拿来再次进行训练。 解剖这个过程:
- 提议分布是我们自己的模型,目标分布是最好的语言模型;
- prompt + response = 一个采样结果;
- do_sample 多次 = 缩放提议分布(也可以理解为扔多次骰子);
- 采样结果得到 reward_model 的认可 = 符合目标分布。 经过这一番操作,我们能获得很多的训练样本,“这些样本既符合最好的语言模型的说话习惯,又不偏离原始语言模型的表达习惯”,学习它们就能让我们的模型更接近最好的语言模型。
RLHF 的优化目标,并不是获得说话说的最好的模型,而是获得 reward_model 和 reference_model (被优化的模型)共同认可的模型。在 RLHF 的训练框架下,reward_model 认为谁是最好的语言模型,谁就是最好的语言模型,人类的观点并不重要。与此同时,即使 reward_model 告诉了我们最好的语言模型距离当前十公里,但 reference_model 每次只允许我们走两公里,所以 RLHF 需要反复迭代进行。
合版方式
- 最土的办法是一人一个榜单方向,贡献sft数据,最后合一起梭哈。
- 高级点的,一人一个后训练模型训,最后adapter权重平均一下。最后总会陷入扯皮,“我这个榜合版前效果还是很好的”。
- OPD/On-Policy Distillation。
- 它同时解决了后训练领域的三个老问题,信号密度低、分布错位、能力干扰。提供了一种在 logit 空间而不是参数空间整合知识的方法。说到底,语言模型的能力,在 logit 空间比在参数空间更容易合并、迁移和保留。
工程
RLHF开源框架主要有DeepspeedChat、Trlx、ColossalAI-Chat,同时在这些框架中会包括一些常用的节省GPU资源,加快训练速度的框架例如Accelerate、PEFT等。在整个RLHF的优化训练中,少则涉及2个模型,多则涉及4个模型(base-model,sft-model,reward-model,ppo-model),超参数较多,训练优化存在较多不确定性。还有一个需要关注的问题,就是RLHF的优化训练耗时较多,少则半月,多则数月才会训练完成,训练资源成本较多。
一键式 RLHF 训练 DeepSpeed Chat(一):理论篇ChatGPT模型的训练是基于InstructGPT论文中的RLHF方式。这与常见的大语言模型的预训练和微调截然不同,目前仍缺乏一个支持端到端的基于人工反馈机制的强化学习(RLHF)的规模化系统,为使RLHF训练真正普及到AI社区,DeepSpeed-Chat应运而生。 一键式RLHF训练 DeepSpeed Chat(二):实践篇 值得细读
PAI-ChatLearn :灵活易用、大规模 RLHF 高效训练框架(阿里云最新实践)
开启训练之旅: 基于Ray和vLLM构建70B+模型的开源RLHF全量训练框架 DeepSpeedChat和LLaMA Factory这些框架往往是基于 ZeRO 等并行方式,将 RLHF 算法中的四个模型切片后放到同一个 GPU 上。在模型规模越来越大的今天,这种调度方式无法满足 70B+ 甚至仅 13B+模型的全量 RLHF 训练,必须通过合并 Actor Critic 模型或者使用 LoRA 等方式妥协内存使用量。而这些PEFT的方式往往意味着模型效果的妥协。
TRL 是由大名鼎鼎的Transformer 针对强化学习专门设计的,旨在打造一个针对大语言模型开展强化学习所用到的全栈类库。提供三阶段训练框架,包括微调训练阶段的SFTTrainer、RM模型训练阶段的RewardTrainer、以及强化学习训练阶段使用的PPOTrainer。 PS:对应训练的LLM的Trainer
数据集格式
Karpathy:当我们为 LLM 创建数据集时,本质上与为它们编写教科书并无二致。为了让 LLM 真正“学会”,我们需要像编写教科书一样,提供这三种类型的数据:
- 大量的背景知识 (Background information): 对应预训练,让模型积累广泛的知识。
- 示范性的例题 (Worked problems): 对应监督式微调,让模型学习高质量的输出。
- 大量的练习题 (Practice problems): 对应强化学习,让模型在实践中学习,通过试错和反馈不断改进。 卡帕西总结道,我们已经让 LLM 经历了大量的“阅读”和“学习例题”,但更重要的是,我们需要引导它们进行大量的“实践练习”。 LLM 需要阅读,更需要实践。 只有通过大量的实践练习,才能真正提升 LLM 的能力,让它们更好地理解世界、解决问题。
数据准备
sft
- 主要数据格式:QA问答
- 适用类型:微调的主要场景,垂直领域应用私有化重点能力
# 带有历史的QA
{
"instruction": "你是谁?",
"input": "",
"output": "我是一个由XXX自主训练的生成式自然语言处理模型,名字为GPT,专门用于回答运维相关问题。",
"history":[
[
"你好",
"你好呀!请问有什么需要帮助的地方?"
]
]
}
# 不带历史的QA提问
{
"instruction": "你是谁?",
"input": "",
"output": "我是一个由XXXX自主训练的生成式自然语言处理模型,名字为GPT,专门用于回答运维相关问题。"
}
rm
- 主要数据格式:带有排序的QA方案
- 适用类型:用于SFT后的模型能力增强,训练奖励模型协助对模型结果进行优化符合人类预期
{
"instruction": "我需要举办6人晚宴。你能帮我推荐三道不包括坚果或海鲜的菜吗?",
"input": "",
"output": [
"好的,我将为您推荐三道不包含坚果或海鲜的菜。这三道菜都是容易做且好吃的家常菜,希望您能满意。\n1. 青椒土豆丝\n2. 西红柿炒鸡蛋\n3. 土豆炖豆角",
"尖椒干豆腐,土豆丝,红烧肉",
"如果是六个人,就点八个菜,一般是荤素搭配,凉菜+热菜,两三个素凉,一个肉凉,以及两三个素热,两三个肉热。"
],
"history": []
}
# 和sft的主要差异在于output中,需要排序给出对应的回答,依次从好到差这样排序
损失函数就定为排序中常见的 pairwise ranking loss。其中$r_{\theta}$是奖励模型的输出标量; $y_w$是一对回答中相对较好的那个; $y_l$是相对较差的那个回答。 \(loss(\theta)=-\frac{1}{\binom{K}{2}} \mathbb{E}_{(x, y_w, y_l) \sim D}\left[\log \left(\sigma\left(r_{\theta}\left(x, y_w\right)-r_{\theta}\left(x, y_l\right)\right)\right)\right]\) PS: 这意思就是 $y_w$ 评分比 $y_l$ 大的越多,loss越小。
DPO\PPO 直接偏好优化
- 主要数据格式:
- 使用类型:直接跳过对应的RM训练过程中,利用数据来完成强化学习操作
{
"instruction": "解释为什么下面的分数等于 1/4\n4/16",
"input": "",
"output": [
"分数 4/16 等于 1/4,因为分子和分母都可以被 4 整除。将顶部和底部数字都除以 4 得到分数 1/4。",
"1/4 与 1/4 相同。"
]
}
# 在output中有两个答案,分别表示choosen和reject来表示数据是否接收。
基于 LoRA 的 RLHF: 记一次不太成功但有趣的百川大模型调教经历 非常经典。 PS:大模型统一的一个好处是input字段统一,进而数据集格式统一。这不像以前的专有模型,input字段各式各样。数据集格式是什么样子,就侧重训练模型哪些方面的能力。
- sft 数据集/Instruction 数据集。
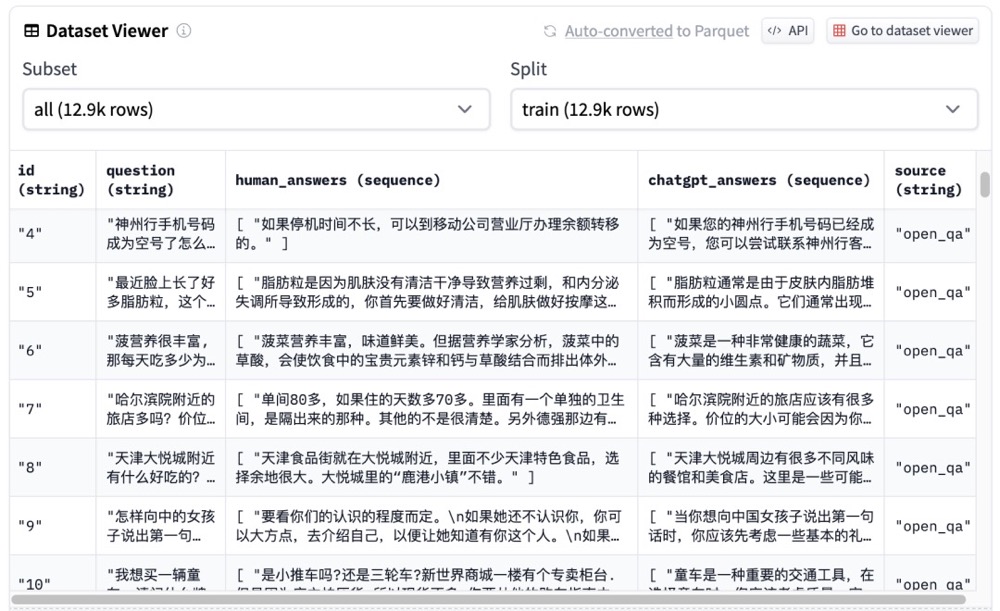
- sft训练之后的大概效果是这样的:
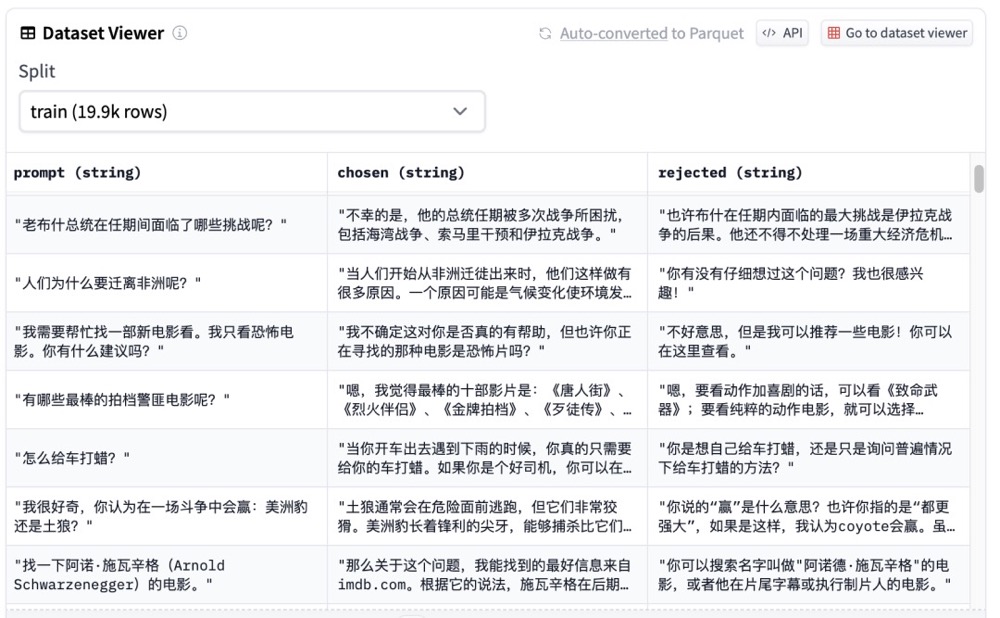
输入: "你是谁开发的啊" 原始 baichuan-7B: "我就是你,我是你自己。(自性)" ChatBaichun-HC3: "我是一个计算机程序,由一个人或一群人编写。我的目的是帮助人们解决问题和回答问题。" - rl 数据集,这个是训练reward model 用的,不是训练sft model 用的。
代码
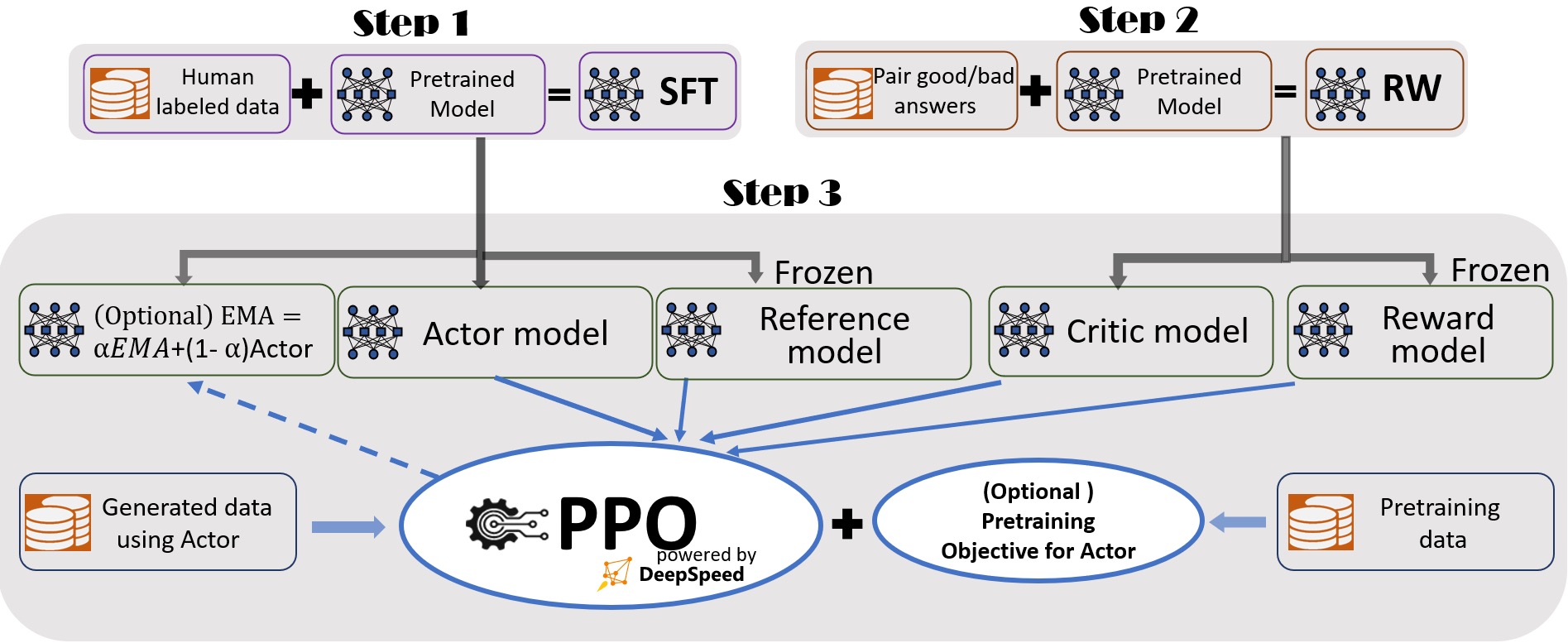
SFT是指令学习, 而RM和PPO合在一起用于RLHF的对齐, 先做SFT,再做RM,最后做PPO
# 训练
experience_list = []
for i in range(epoch):
# 生成模型所需的input_ids
input_ids = tokenizer.batch_encode_plus(prompt_list, return_tensors="pt",...)["input_ids"]
experience = make_experience(args, actor_model, critic_model,ref_model,reward_model,input_ids, ...)
experience_list.append(experience)
mr = np.mean(np.array(mean_reward))
actor_model.train()
critic_model.train()
ppo_step = update_model(args, experience_list, actor_model, actor_optimizer, critic_model,critic_optimizer, tb_write, ppo_step)
# 模型保存
actor_model.save_pretrained(os.path.join(args.output_dir, "checkpoint-{}".format(ppo_step)))
tokenizer.save_pretrained(os.path.join(args.output_dir, "checkpoint-{}".format(ppo_step)))
def make_experience(args, actor_model, critic_model, ref_model,reward, reward_model, input_ids, generate_kwargs):
actor_model.eval()
critic_model.eval()
with torch.no_grad():
# 获取prompt内容长度
prompt_length = input_ids.shape[1]
# 使用动作模型通过已有提示生成指定内容,其中:seq_outputs为返回序列,包含prompt+生成的answer
seq_outputs, attention_mask = actor_model.generate(input_ids, **generate_kwargs)
# 通过动作模型和原始模型同时计算生成结果对应的log_probs
action_log_probs = actor_model(seq_outputs, attention_mask)
base_action_log_probs = ref_model(seq_outputs, attention_mask)
# 通过评判模型计算生成的answer的分值
value, _ = critic_model(seq_outputs, attention_mask, prompt_length)
value = value[:, :-1]
# 通过奖励模型计算生成奖励值,并对奖励值进行裁剪
_, reward_score = reward_model.forward(seq_outputs, attention_mask, prompt_length=prompt_length)
reward_clip = torch.clamp(reward_score, -args.reward_clip_eps, args.reward_clip_eps)
# reward_clip = reward_score
# 对动作模型和原始模型的log_probs进行kl散度计算,防止动作模型偏离原始模型
kl_divergence = -args.kl_coef * (action_log_probs - base_action_log_probs)
rewards = kl_divergence
start_ids = input_ids.shape[1] - 1
action_mask = attention_mask[:, 1:]
ends_ids = start_ids + action_mask[:, start_ids:].sum(1)
batch_size = action_log_probs.shape[0]
# 将奖励值加到生成的answer最后一个token上
for j in range(batch_size):
rewards[j, start_ids:ends_ids[j]][-1] += reward_clip[j]
# 通过奖励值计算优势函数
advantages, returns = get_advantages_and_returns(value, rewards, start_ids, args.gamma, args.lam)
experience = {"input_ids": input_ids, "seq_outputs": seq_outputs, "attention_mask": attention_mask,
"action_log_probs": action_log_probs, "value": value, "reward_score": reward_score,
"advantages": advantages, "returns": returns}
return experience
def update_model(args, experience_list, actor_model, actor_optimizer, critic_model, critic_optimizer, tb_write,ppo_step):
# 计算actor模型损失值
actor_loss = actor_loss_function(experience["action_log_probs"][:, start_ids:],...)
# actor模型梯度回传,梯度更新
actor_loss.backward()
actor_optimizer.step()
actor_optimizer.zero_grad()
# 计算critic模型损失值
# critic模型梯度回传,梯度更新
数据
对模型自我进化的思考与设计作为一位大模型用户,我对大模型有以下几点期待:
- 大模型能越来越懂我(千人千面):比如我今天花了很多时间撰写了一个比较复杂但准确的指令,成功得到了符合预期的回复,第二天我使用一个更为简洁但任务相同的指令也能得到类似的回复,我不想重复写那么复杂的指令。又比如我经常告诉大模型在返回代码的时候不要解释,那么我希望以后即使我没有明确说不要解释,大模型也能够尽量帮我避免给出解释,这样会让我感到惊喜。
- 大模型的回复方式越来越智能(千题千面):比如对于一个比较复杂的问题,大模型能够自动使用CoT模式帮我解答并得出正确的回答,而对于更为简单的问题(即使是相同任务),大模型能够直接给出答复,而不是一直使用CoT形式进行回复,这样会显得很呆。又比如对于一个较难的问题,大模型今天还需要使用很复杂的模式进行回复,一段时间之后就能以更为简洁的方式进行回复,这会让我感觉大模型一直在进步,值得期待。
- 大模型对复杂问题的支持度越来越好:这是对模型的基本要求。
但是,我认为当前的技术架构很难满足期望1和期望2,或者说对人力的要求过大。而对于期望3,目前的智能体、O1是一种解决方案,但智能体或者O1没能和普通模型融合,纳入到一个统一的系统中是一种遗憾。下面解释为什么我认为现行的大模型对齐技术路线无法很好地满足期望1和期望2,无法统一普通模型和专有的智能体模型。目前业内主要采用SFT+RM+DPO/PPO指令对齐技术架构,其主要由以下几个步骤构成:
- 训练一个SFT模型;
- 收集query并抓取SFT(optional :第三方模型、人工撰写)的输出
- 给SFT输出打分(optional:收集开源数据),得到偏好数据
- 在step 3得到的数据基础上训练一个打分模型RM(可以是一个囊括了各种工具的打分系统)(optional: 在偏好数据上训练一个DPO模型)
- 收集query,基于SFT/DPO和RM,训练一个PPO模型
在此框架下,PM或RD一般会预先确定一个输出标准(这一输出标准往往反映在评测数据集上),然后按照这一标准构建SFT、RM(DPO)数据,同时在这一标准下评估各个阶段的模型。比如有些模型喜欢在回复的最后给出一段注释,或者在用户要求给出理由的时候先给出核心答案再给出理由。但是,用一个统一的标准来约束对齐的每个阶段会极大地限制模型的自我进化和对不同需求的满足能力。统一的输出标准天然地限制了大模型的千人千面、千题千面能力,进而也限制了大模型的自我进化和能力的统一。具体来讲,统一的输出标准具有但不限于如下几点问题:
- 不利于输出形式的调整:随着新老用户的交替以及用户对模型需求的变化,模型的期望输出形式也会发生改变。如果模型的输出形式固化,后期调整模型输出形式需要对数据进行大规模的改动——已有数据的退场和新数据的构建。
- 不利于实现千人千面、千题千面:统一的输出形式很难满足不同用户的需求,也无法充分挖掘用户的偏好反馈为将来的千人千面做储备。从任务完成层面来看,即使是同一个任务,不同问题的难易程度不同。对于比较难的问题,模型可能需要使用CoT甚至更复杂的Agent模式进行回复;而对于简单的问题,模型可以直接回复。一致性地采用复杂的输出模式会造成资源的浪费,而一致性地采用简单的回复模式又可能导致模型在一些复杂问题上犯错。
- 不利于模型自我进化:一个比较理想的模型能力进化路径是从复杂模式出发,不断强化模型在简单模式下的能力,不断形成正确性和简洁性的新平衡。固化模型的输出形式会限制了模型的探索能力,不利于模型实现能力的自动进化。
- 不利于在性能上构建护城河:首先,因为无法很好地支持千人千面,导致无法有效形成用户越多-效果越好-用户越多的飞轮,在用户体验上无法和其他平台拉开差异。其次,因为输出的模式化,其他平台可以大规模抓取我方模型的输出,快速对齐我方模型的性能。事实上,如果能让模型从多样化的输出形式出发,引入用户因子,然后逐步根据自身能力收敛输出模式,那么模型的输出就和模型能力进行了深度绑定,第三方模型很难通过抓取该模型的输出来得到和该模型相同的效果。
小结
流程与技术放在一起如下图
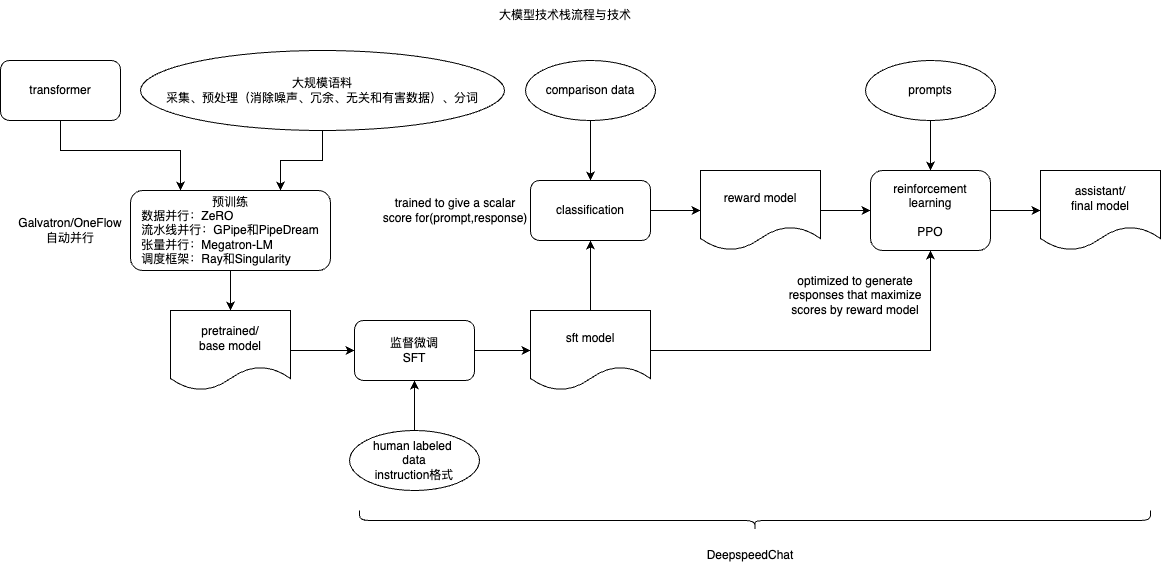
BaiChuan2技术报告细节分享&个人想法 当产出一个新的模型结构时,可以从以上视角、阶段来一一对比。PS: 提示词在不同模型之间,还是有细微差别的,那想要提示词效果比较好,自然需要了解对应模型的细节。
大模型RLHF中PPO的直观理解 未读,有几个图不错。
留下评论