LLamaIndex入门
简介
构建在LLM模型之上的应用程序通常需要使用私有或特定领域数据来增强这些模型。不幸的是,这些数据可能分布在不同的应用程序和数据存储中。它们可能存在于API之后、SQL数据库中,或者存在在PDF文件以及幻灯片中。LlamaIndex应运而生,为我们建立 LLM 与数据之间的桥梁。
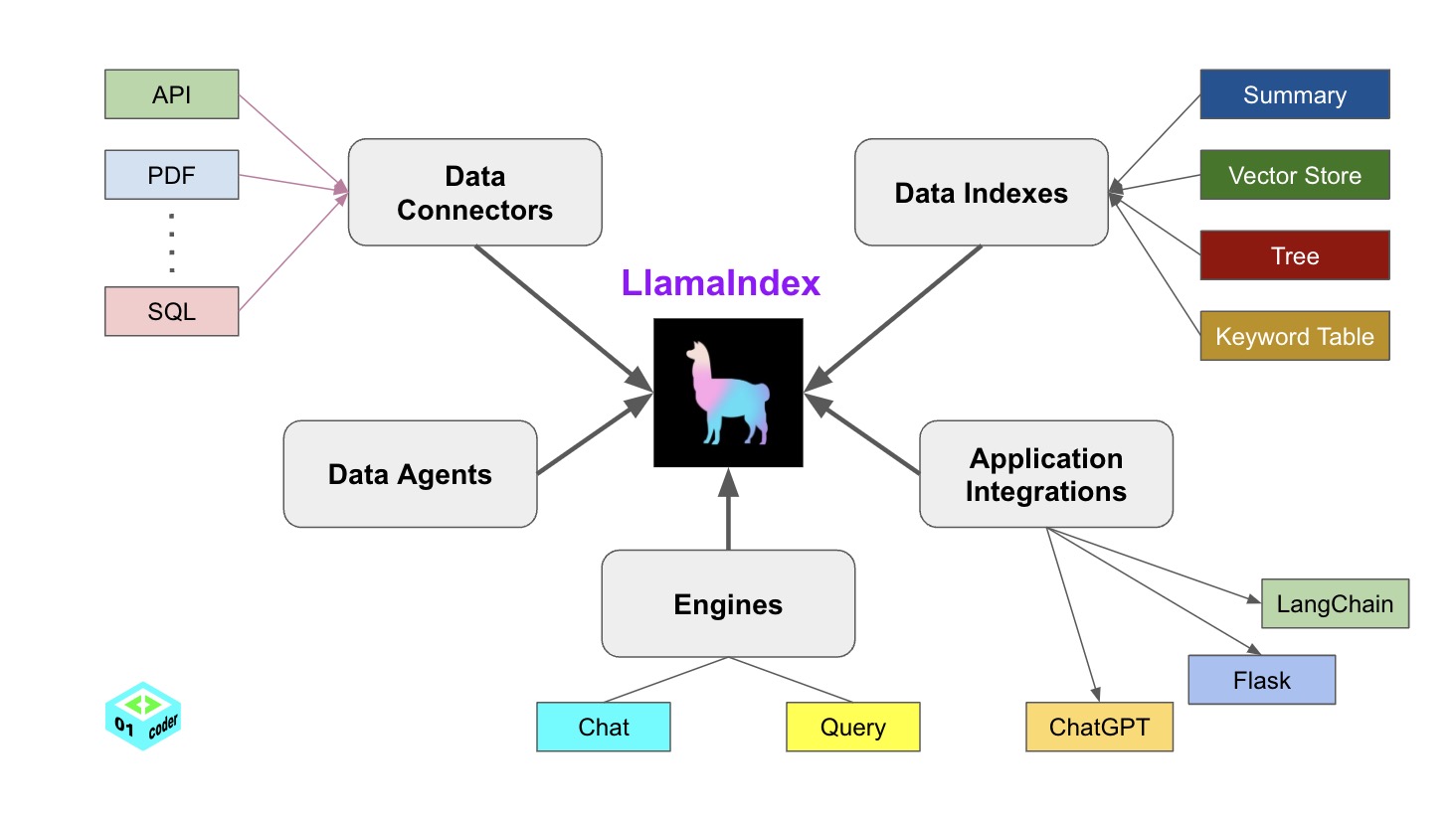
LlamaIndex 提供了5大核心工具:
- Data connectorsj。将不同格式的数据源注入llamaindex
- Data indexes。将数据转为 llm 可以非常容易理解且高效处理、消费的数据。
- Engines。
- Data agents。对接生态的其它工具,比如Langchain、Flask等
- Application integrations
基本概念/llama-index-core
与langchain类似,一般都分为 基础组件 + 组织组件(来llamaindex 对应pipeline/agent/workflow)
模型
对于llm api来说,一般分为/completion和 /chat/completion 两个api,langchain BaseLLM和BaseChatModel 是分开的,llamaindex 的complete 和 chat 接口都在BaseLLM下。
- 对于输入,待进一步对比
- 对于输出, langchain 的stream 输出是笼统的
Iterator[Output],BaseLLM 则做了专门定义。
class BaseLLM(ChainableMixin, BaseComponent, DispatcherSpanMixin):
def chat(self, messages: Sequence[ChatMessage], **kwargs: Any) -> ChatResponse:
def complete(self, prompt: str, formatted: bool = False, **kwargs: Any) -> CompletionResponse:
def stream_chat(self, messages: Sequence[ChatMessage], **kwargs: Any) -> ChatResponseGen:
def stream_complete(self, prompt: str, formatted: bool = False, **kwargs: Any) -> CompletionResponseGen:
# 上面4个方法还分别对应一个异步方法
从LLM 的抽象看,与langchain 相比,llm 将很多能力内置了,比如结构化输入输出(对应langchain prompt | llm | output_parser),agent 调用等。
class LLM(BaseLLM):
def structured_predict(self, output_cls: Type[BaseModel],prompt: PromptTemplate,llm_kwargs, **prompt_args: Any,) -> BaseModel:
def stream_structured_predict(...)-> Generator[Union[Model, List[Model]], None, None]:
def predict( self,prompt: BasePromptTemplate,**prompt_args: Any, ) -> str:
def predict_and_call(self,tools: List["BaseTool"], tools: List["BaseTool"], chat_history: Optional[List[ChatMessage]] = None,...) -> "AgentChatResponse":
结构化输出,实质是对 LLM.structured_predict 的封装。
class StructuredLLM(LLM):
llm: SerializeAsAny[LLM]
output_cls: Type[BaseModel]
def chat(self, messages: Sequence[ChatMessage], **kwargs: Any) -> ChatResponse:
chat_prompt = ChatPromptTemplate(message_templates=messages)
output = self.llm.structured_predict(output_cls=self.output_cls, prompt=chat_prompt, llm_kwargs=kwargs))
return ChatResponse(
message=ChatMessage(
role=MessageRole.ASSISTANT, content=output.model_dump_json()
),
raw=output,
)
llm 底层是text in text out。但是结构化输出也是越来月重要的特性,所以框架封装上则是 struct in struct out,对应到llamaindex 则进一步封装为messages in ChatResponse out。 PS:智能体的基础是增强型LLM
数据(未完成)
RAG
索引阶段
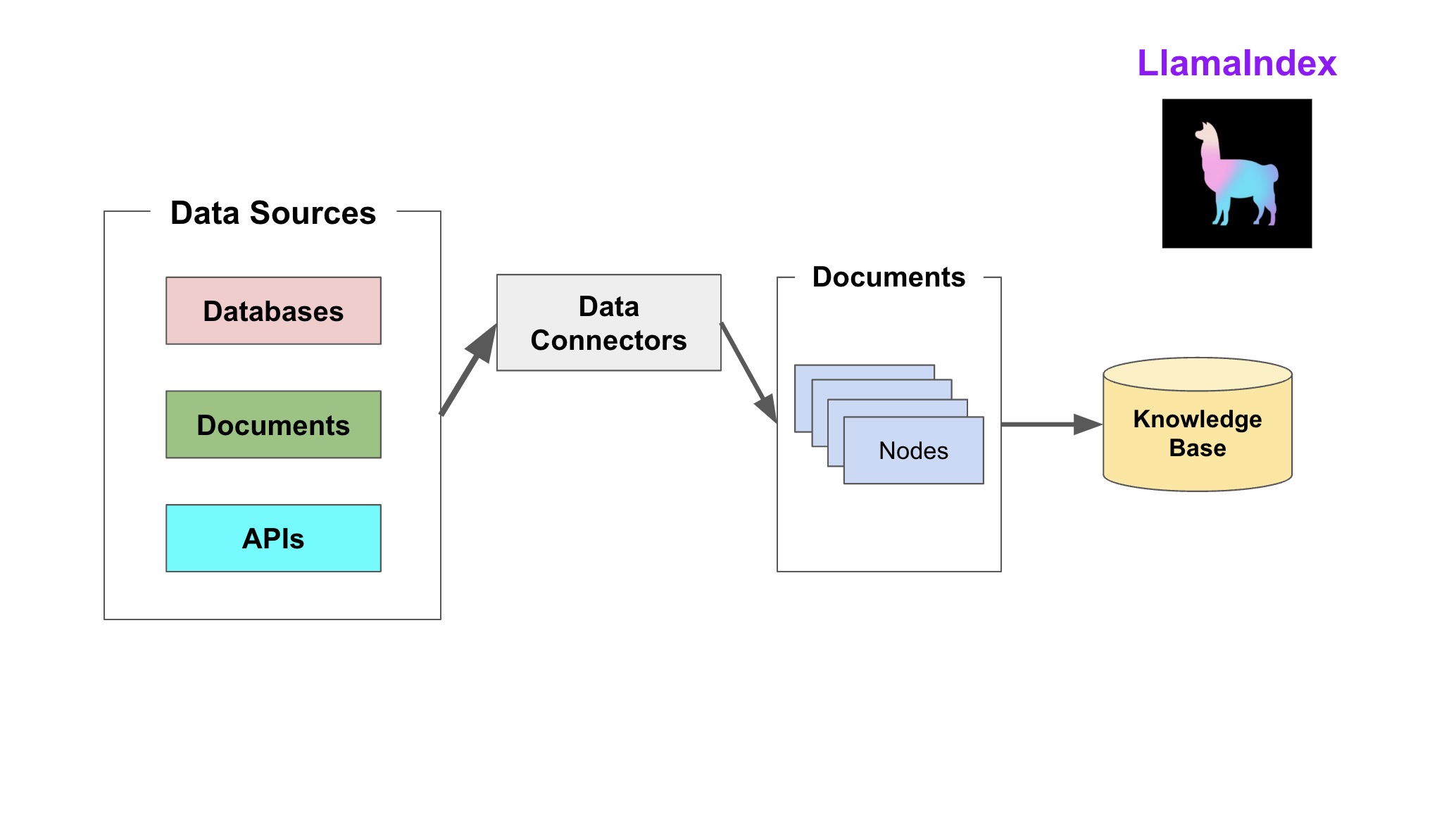
在 LlamaIndex 中,Document 和 Node 是最核心的数据抽象。
- Document 是任何数据源的容器:
- 文本数据
- 属性数据:元数据 (metadata);关系数据 (relationships)
- Node 即一段文本(Chunk of Text),是 LlamaIndex 中的一等公民。基于 Document 衍生出来的 Node 也继承了 Document 上的属性,同时 Node 保留与其他 Node 和 索引结构 的关系。
# 利用节点解析器生成节点 from llama_index import Document from llama_index.node_parser import SimpleNodeParser text_list = ["hello", "world"] documents = [Document(text=t) for t in text_list] parser = SimpleNodeParser.from_defaults() nodes = parser.get_nodes_from_documents(documents)首先将数据能读取进来,这样才能挖掘。之后构建可以查询的索引,llamdaIndex将数据存储在Node中,并基于Node构建索引。索引类型包括向量索引、列表索引、树形索引等;
- List Index:Node顺序存储,可用关键字过滤Node
- Vector Store Index:每个Node一个向量,查询的时候取top-k相似
- Tree Index:树形Node,从树根向叶子查询,可单边查询,或者双边查询合并。
- Keyword Table Index:每个Node有很多个Keywords链接,通过查Keyword能查询对应Node。
查询阶段
有了索引,就必须提供查询索引的接口。通过这些接口用户可以与不同的 大模型进行对话,也能自定义需要的Prompt组合方式。
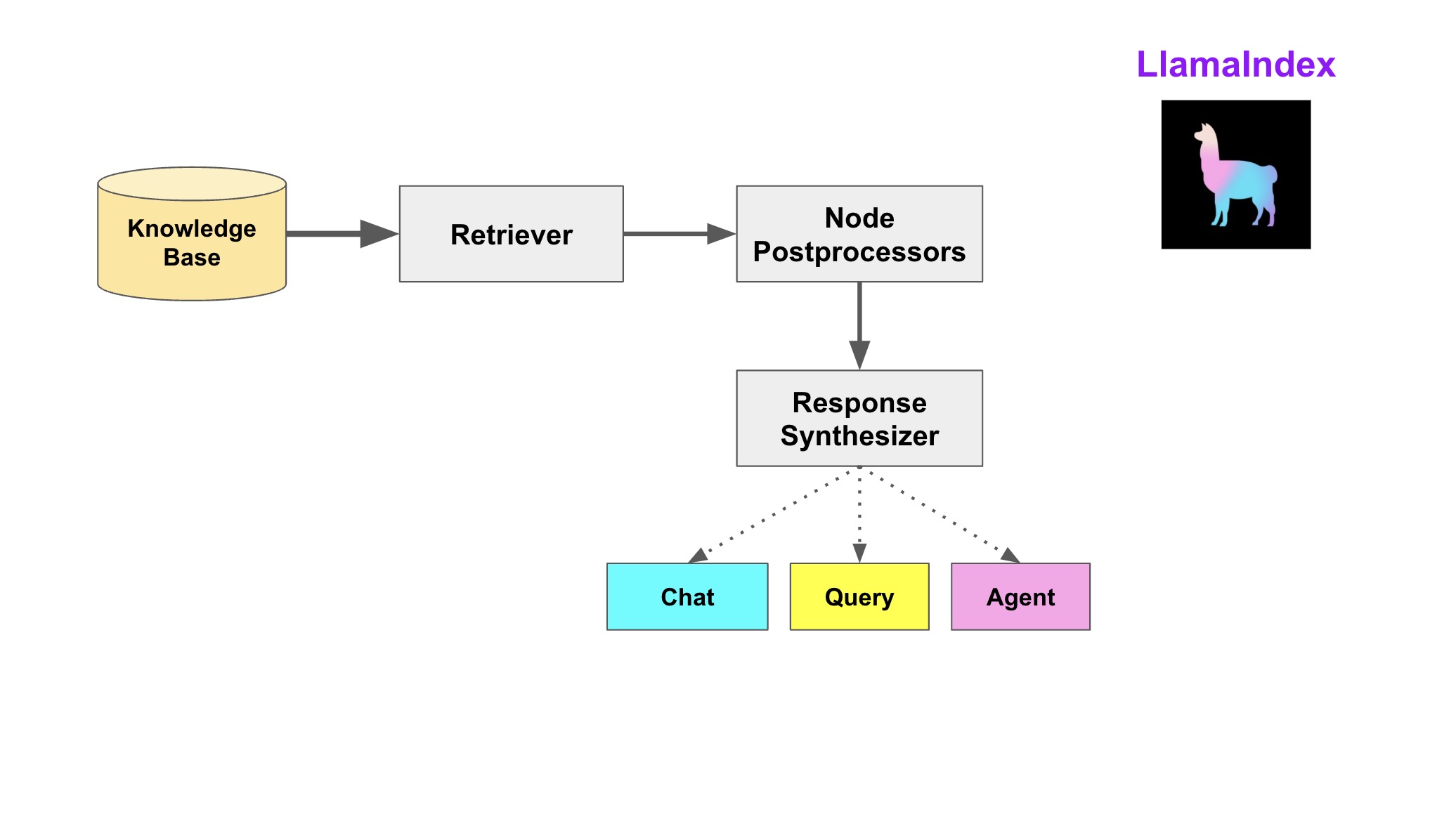 所有查询的基础是查询引擎(QueryEngine)。获取查询引擎的最简单方式是通过索引创建一个,如下所示:
所有查询的基础是查询引擎(QueryEngine)。获取查询引擎的最简单方式是通过索引创建一个,如下所示:
query_engine = index.as_query_engine()
response = query_engine.query("Write an email to the user given their background information.")
print(response)
查询的三个阶段检索(Retrieval),允许自定义每个组件。
- 在索引中查找并返回与查询最相关的文档。常见的检索类型是“top-k”语义检索,但也存在许多其他检索策略。
- 后处理(Postprocessing):检索到的节点(Nodes)可以选择性地进行排名、转换或过滤,例如要求节点具有特定的元数据,如关键词。
- 响应合成(Response Synthesis):将查询、最相关数据和提示结合起来,发送给LLM以返回响应。
class BaseQueryEngine(ChainableMixin, PromptMixin, DispatcherSpanMixin):
@dispatcher.span
def query(self, str_or_query_bundle: QueryType) -> RESPONSE_TYPE:
...
query_result = self._query(str_or_query_bundle)
...
@abstractmethod
def _query(self, query_bundle: QueryBundle) -> RESPONSE_TYPE:
pass
class RetrieverQueryEngine(BaseQueryEngine):
def __init__(
self,retriever: BaseRetriever,response_synthesizer: Optional[BaseSynthesizer] = None,node_postprocessors: Optional[List[BaseNodePostprocessor]] = None,callback_manager: Optional[CallbackManager] = None, ) -> None:
self._retriever = retriever
self._response_synthesizer = response_synthesizer or get_response_synthesizer(...)
self._node_postprocessors = node_postprocessors or []
@dispatcher.span
def _query(self, query_bundle: QueryBundle) -> RESPONSE_TYPE:
nodes = self.retrieve(query_bundle)
response = self._response_synthesizer.synthesize(query=query_bundle,nodes=nodes,)
def retrieve(self, query_bundle: QueryBundle) -> List[NodeWithScore]:
nodes = self._retriever.retrieve(query_bundle)
return self._apply_node_postprocessors(nodes, query_bundle=query_bundle)
query_engine 可以被封装为 QueryEngineTool 进而作为 初始化一个更复杂 query_engine 的query_engine.query_engine_tools。这是一种简化的工具调用形式,稍微复杂一点的还要推断工具调用的参数,比如在rag检索中,可以让llm 根据用户表述,推断查询时对元数据的过滤参数。再进一步,如果用户提出的是由多个步骤组成的复杂问题或需要澄清的含糊问题呢?这需要用到代理循环。
带历史记录
BaseChatEngine 提供 chat 方法,支持传入历史记录
class BaseChatEngine(ABC):
@abstractmethod
def chat(self, message: str, chat_history: Optional[List[ChatMessage]] = None) -> AGENT_CHAT_RESPONSE_TYPE:
带路由
RouterQueryEngine提出了 BaseSelector(可以EmbeddingSingleSelector) summarizer(BaseSynthesizer子类) 抽象,有分有合。
class RouterQueryEngine(BaseQueryEngine):
def __init__( self,
selector: BaseSelector,
query_engine_tools: Sequence[QueryEngineTool],
llm: Optional[LLM] = None,
summarizer: Optional[TreeSummarize] = None,
) -> None:
...
多步推理
class MultiStepQueryEngine(BaseQueryEngine):
def _query(self, query_bundle: QueryBundle) -> RESPONSE_TYPE:
nodes, source_nodes, metadata = self._query_multistep(query_bundle)
final_response = self._response_synthesizer.synthesize(
query=query_bundle,
nodes=nodes,
additional_source_nodes=source_nodes,
)
return final_response
def _query_multistep(self, query_bundle: QueryBundle) -> Tuple[List[NodeWithScore], List[NodeWithScore], Dict[str, Any]]:
while not should_stop:
路由 + 工具 + 多步推理。
最复杂场景下的RAG文档:路由 + 工具 + 多步推理。
class BaseAgent(BaseChatEngine, BaseQueryEngine):
def _query(self, query_bundle: QueryBundle) -> RESPONSE_TYPE:
agent_response = self.chat( query_bundle.query_str,chat_history=[],)
return Response(response=str(agent_response), source_nodes=agent_response.source_nodes)
class BaseAgentRunner(BaseAgent):
@abstractmethod
def run_step(self,task_id: str,input: Optional[str] = None,step: Optional[TaskStep] = None,**kwargs: Any,) -> TaskStepOutput:
class AgentRunner(BaseAgentRunner):
def _run_step(self,task_id: str,step: Optional[TaskStep] = None,...)-> TaskStepOutput:
task = self.state.get_task(task_id)
step_queue = self.state.get_step_queue(task_id)
cur_step_output = self.agent_worker.run_step(step, task, **kwargs)
next_steps = cur_step_output.next_steps
step_queue.extend(next_steps)
return cur_step_output
def _chat(self,message: str,chat_history: Optional[List[ChatMessage]] = None,)-> AGENT_CHAT_RESPONSE_TYPE:
task = self.create_task(message)
while True:
cur_step_output = self._run_step(task.task_id, mode=mode, tool_choice=tool_choice)
if cur_step_output.is_last:
result_output = cur_step_output
break
result = self.finalize_response(task.task_id,result_output,)
return result
Step-Wise Agent Architecture: The step-wise agent is constituted by two objects, the AgentRunner and the AgentWorker.
- Our “agents” are composed of AgentRunner objects that interact with AgentWorkers. AgentRunners are orchestrators that store state (including conversational memory), create and maintain tasks, run steps through each task, and offer the user-facing, high-level interface for users to interact with.
- AgentWorkers control the step-wise execution of a Task. Given an input step, an agent worker is responsible for generating the next step. They can be initialized with parameters and act upon state passed down from the Task/TaskStep objects, but do not inherently store state themselves. The outer AgentRunner is responsible for calling an AgentWorker and collecting/aggregating the results.
chat 方法由一个while true 循环组成,循环内执行 _run_step, AgentRunner维护了一个step_queue,AgentRunner._run_step 主要是维护 step 与step_queue 的关系、记录step的输入输出,step的具体执行委托给agent_worker 负责。
个性化配置
个性化配置主要通过 LlamaIndex 提供的 ServiceContext 类实现。PS:后来是Settings?
- 自定义文档分块
- 自定义向量存储
- 自定义检索
index = VectorStoreIndex.from_documents(documents) query_engine = index.as_query_engine(similarity_top_k=5) - 指定 LLM
service_context = ServiceContext.from_defaults(llm=OpenAI()) - 指定响应模式
query_engine = index.as_query_engine(response_mode='tree_summarize') - 指定流式响应
query_engine = index.as_query_engine(streaming=True)
workflow
LlamaIndex Workflows是LlamaIndex近期推出的用来替代之前Query Pipeline(查询管道)的新特性。与LangGraph不同的是,其没有采用类似LangCraph基于图结构的流程编排模式(它没有显式地定义「边」的概念),而是采用了一种事件驱动的工作流编排方式:工作流中的每个环节被作为step(步骤,代表一个处理动作),每个step可以选择接收(类似订阅)一种或多种event(事件)做处理,并同样可以发送一种或多种event给其他step。通过这种方式,把多个step自然的连接起来形成完整的Workflow。在这种架构中,工作流的运行不是由框架来根据预先的定义(比如Graph)来调度任务组件执行,而是由组件自身决定:你想接收什么event,做什么处理,并发出什么event。如果组件B接受了A发出的某种event,那么B就会在A发出event后触发执行。
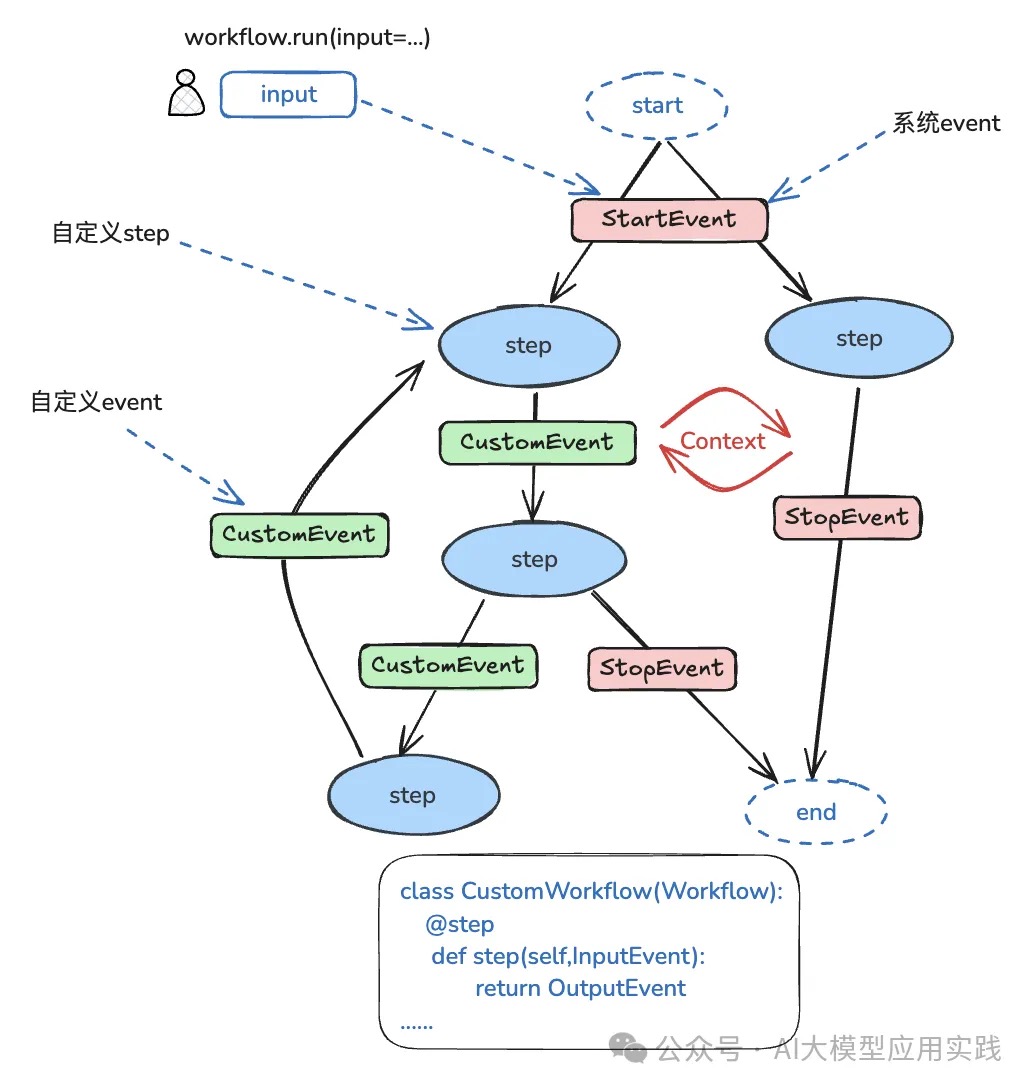
图中涉及到LlamaIndex Workflows中的一些关键概念:
- Workflow(工作流)工作流代表一个复杂的RAG、Agent或者任意复合形式的LLM应用的端到端流程。创建完工作流后,调用run方法,并输入任务即可启动。Workflow类似LangGraph中的Graph。
- Step(步骤)步骤代表工作流中的单个任务,你可以自由的定义步骤内容。每个步骤接收输入事件(订阅),并返回输出事件。当输入事件发生时,这个步骤就会自动执行。步骤使用Python函数定义。Step类似LangGraph中的Node。
- 将条件路由逻辑保留在step中而不是langgraph.conditional_edge中
- Event(事件)事件是一个步骤的输入输出,也是工作流各个步骤之间的数据载体。当事件发生时,“订阅”该事件的步骤就会执行,同时从事件中取出必要数据。事件是一个Pydantic类型对象,可以自由定义结构。注意两个特殊事件:StartEvent与StopEvent是两个系统事件,代表工作流开始与结束。StartEvent由框架派发,代表工作流的开始。StopEvent由框架接收,发送StopEvent的步骤代表没有后续步骤。
- Context(上下文),Context是一个用来在整个工作流内自动流转的上下文状态对象,放入Context中的数据可以被所有步骤接收和读取到,可以理解为全局变量。
- LangGraph使用全局状态在节点之间共享数据;而LlamaIndex一方面使用event在step之间传递数据,一方面也支持通过全局状态来共享数据(以Context的形式)。 PS:一个workflow 引擎,两个关键字是workflow/step(task),三个关键字是workflow/step/context(全局的和step间的信息传递)。四个关键词就再带一个驱动机制:顺序驱动(按序执行,就没法循环了)、图驱动、事件驱动。
#定义两个事件
class RetrieverEvent(Event):
nodes: list[NodeWithScore]
class RerankEvent(Event):
nodes: list[NodeWithScore]
#workflow定义
class RAGWorkflow(Workflow):
@step
async def retrieve(self, ctx: Context, ev: StartEvent) -> RetrieverEvent | None:
query = ev.get("query")
index = ev.get("index")
return RetrieverEvent(nodes=nodes)
@step
async def rerank(self, ctx: Context, ev: RetrieverEvent) -> RerankEvent:
ranker = LLMRerank(
choice_batch_size=5, top_n=3, llm=OpenAI(model="gpt-4o-mini")
)
new_nodes = ranker.postprocess_nodes(
ev.nodes, query_str=await ctx.get("query", default=None)
)
return RerankEvent(nodes=new_nodes)
@step
async def generate(self, ctx: Context, ev: RerankEvent) -> StopEvent:
llm = OpenAI(model="gpt-4o-mini")
summarizer = CompactAndRefine(llm=llm, streaming=True, verbose=True)
query = await ctx.get("query", default=None)
response = await summarizer.asynthesize(query, nodes=ev.nodes)
return StopEvent(result=response)
w = RAGWorkflow()
result = await w.run(query="你的问题", index=index)
async for chunk in result.async_response_gen():
print(chunk, end="", flush=True
深入解析LlamaIndex Workflows【下篇】:实现ReAct模式AI智能体的新方法 未细读
并发
开发AI Agent到底用什么框架——LangGraph VS. LlamaIndexLangGraph和LlamaIndex的Workflow,都天然支持并发。因为它们都是异步驱动的,在每一个step或superstep执行期间,具备执行条件的多个节点天然是并发执行的。而在多个节点并发执行结束后,同步 (sync) 等待执行结果的操作,LangGraph和LlamaIndex的Workflow采取了完全不同的方案。
- 在LangGraph中需要通过如下形式的调用,来指定框架内部的waiting_edge:
graph_builder.add_edge(["node2","node3"],"node4") - 而在LlamaIndex的Workflow中,则需要使用Context来指明同时等待多个事件(Context同时承载了太多的逻辑)。代码示例如下:
data = ctx.collect_events(ev,[QueryEvent,RetrieveEvent])
对streaming的支持
LangGraph和LlamaIndex的Workflow,都允许通过 asyncfor的方式来深入到执行过程中去,这个能力被称为「streaming」。有一些常见的功能,比如汇报执行进度,就可以通过这种方式来实现。
在LangGraph中,可以通过async for逐步遍历各个superstep;而在LlamaIndex的Workflow中,则可以通过async for遍历各个事件。对streaming的支持,本质上是对于执行过程按照时间线性分步执行的一种追踪方式。这种在时间维度展开的线性遍历,在LangGraph中体现为superstep;在LlamaIndex的Workflow中则体现为每一步的驱动事件(称为streaming events)。
原理
@step 可以用于workflow 的方法或独立的方法。PS:实质是一个猴版的消息总线
- Workflows make async a first-class citizen
- 对于workflow方法,
@step将当前func 构造为 StepConfig,并保存到func 对应Callbale.__step_config 里 - Workflow 第一个step的入参是StartEvent,
handler = workflow.run(kwargs)中的kwargs 会传给StartEvent。最后一个step的出参是StopEvent。StopEvent.result 作为整个workflow 的返回值(handler 实质一个是future子类)。 - 每个step 入参除了event,还可以传入ctx,用来传递一些全局信息。比如用户的原始query,多个step都需要。
- 将每个step func封装为_task,协程触发启动,所有的_step 都开始监听queue(这样才可以有广播给所有step_task效果),拿到自己对口的event就开始干活儿。不是传统的通过DAG拓扑排序的方式依次驱动step(langgraph 疑似是这样)。
- _task 可以返回event 触发下一步step。实际是ctx.send_event 广播给所有_step
- _task 可以使用ctx.write_event_to_stream 发送event,这样可以被
handler = workflow.run(kwargs); handler.stream_events捕获到。
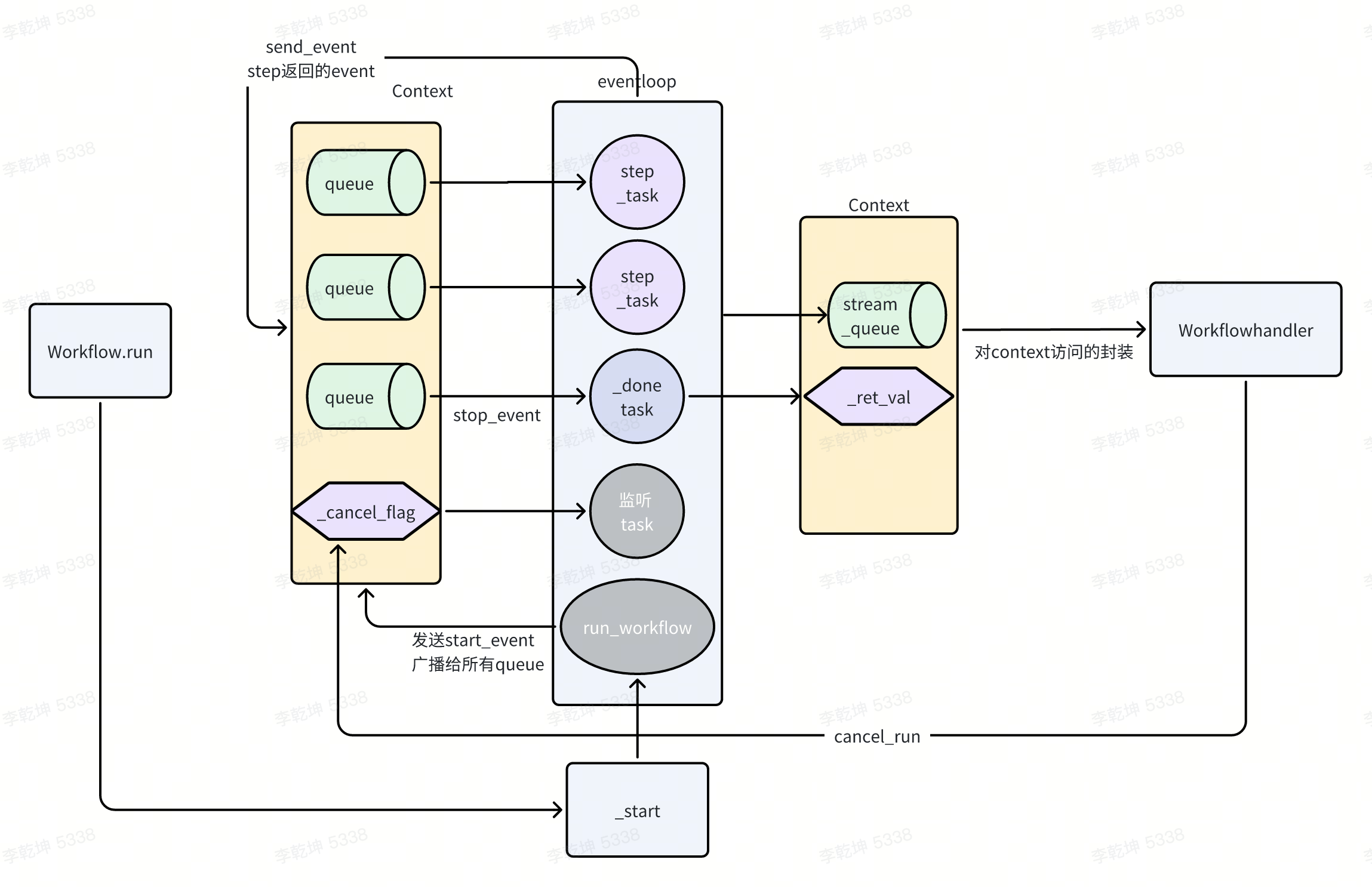
class Workflow(metaclass=WorkflowMeta):
@dispatcher.span
def run(self, ctx,stepwise: bool = False, checkpoint_callback, **kwargs: Any,) -> WorkflowHandler:
# 触发start 干活
ctx, run_id = self._start(
ctx=ctx, stepwise=stepwise, checkpoint_callback=checkpoint_callback
)
result = WorkflowHandler(ctx=ctx, run_id=run_id)
asyncio.create_task(_run_workflow())
return result
- workflow._start 将所有step func都封装为_task 并(作为协程)触发执行,还启动了一个监听workflow取消的协程。
- _task 对对step func进行了封装,主要是一个轮询逻辑:从queue(一个step 对应一个queue)里取出event,触发step func,成功最好(得到new_ev 发出去),不成功处理下重试。
- _run_workflow 负责触发扳机(发出StartEvent),并等待所有的step执行完成。
还有一个很关键的组件是Context
- Context 持有了workflow 对象,所以它获取所有的step情况。
- Context 持有了_retval,结果写到这里。
- Context 持有了_queues,key=step name,value=asyncio.Queue
- Context 持有了_step_flags,key=step name,value=asyncio.Event
- Context 提供了一些工具方法,比如等待上游的多个step 都执行完成。 Emit event 不只是workflow内部(驱动step 执行时),也可以手动在step 内部、workflow.run 外部手动通过ctx.send_event 来发送event。
与LangChain 对比
人工智能和LLM正在快速变化的领域,每周都会出现新的概念和想法,设计经得起时间考验的抽象是非常困难的。更安全的选择是仅对较低级别的构建块使用抽象。
LlamaIndex的重点放在了Index上,也就是通过各种方式为文本建立索引,有通过LLM的,也有很多并非和LLM相关的。LangChain的重点在 Agent 和 Chain 上,也就是流程组合上。可以根据你的应用组合两个,如果你觉得问答效果不好,可以多研究一下LlamaIndex。如果你希望有更多外部工具或者复杂流程可以用,可以多研究一下LangChain。
Build and Scale a Powerful Query Engine with LlamaIndex and Ray 未读
trace
常规的观察者模式是 Subject(被观察者) 持有Observer,Observer 统一抽象为接口,notify的内容随业务而定。在trace 场景,notify的内容统一为event,Observer一般为EventHandler。进一步在llamaindex中,会从Subject 中剥离一个dispatcher(或其它名字),Subject ==> dispatcher ==> Observer。
class Subject:
"""被观察者类"""
def __init__(self):
self._observers = [] # 保存观察者列表
def notify(self, message):
"""通知所有观察者"""
for observer in self._observers:
observer.update(message)
在trace 方面,双方的共同点通过callbackhandler(本质就是观察者模式)来暴漏内部执行数据,但差别很大,主要体现在使用event 还是handler 表达差异 llamaindex Instrumentation
- langchain 没有明确提出event 概念,按照领域的不同,整了几个xxcallbackhandler
class _TracerCore(ABC): # CallbackHandler的公共父类 ... def _on_retriever_start(self, run: Run) -> Union[None, Coroutine[Any, Any, None]]: def _on_retriever_end(self, run: Run) -> Union[None, Coroutine[Any, Any, None]]: def _on_retriever_error(self, run: Run) -> Union[None, Coroutine[Any, Any, None]]: - llamaindex 的思路是定义各种event(类似ReRankStartEvent/ReRankEndEvent 定义了几十个),callbackhandler 则很纯粹(就一个)
class BaseEventHandler(BaseModel): def class_name(cls) -> str: return "BaseEventHandler" @abstractmethod def handle(self, event: BaseEvent, **kwargs: Any) -> Any: ... dispatcher = instrument.get_dispatcher(__name__) dispatcher.add_event_handler(MyEventHandler()) - hierarchy 体系。一般一个trace系统都会有hierarchy,组件之间的迁移都会有一个新的run_id/span_id
- langchain, 当从组件a 进入组件b时,会生成一个新的run_id, a_run_id 则作为parent_run_id。
- llamaindex,event 和span 发出依靠Dispatcher (通过
dispatcher = instrument.get_dispatcher(__name__)创建)- 全局有一个root_manager 持有了
Dict[str, Dispatcher],所有被创建的Dispatcher 都会注册到里面。根据__name__可以依据python module的层级关系构建父子关系。logger 也是这么玩的。 - Dispatcher 持有event_handlers 和 span_handlers
- Dispatcher.event/span_xx 会触发 自己的event_handlers 以及所有父Dispatcher 的event_handlers执行。PS:也就意味着,我们监听llamaindex的时候,主要监听root Dispatcher即可得到所有event?
- 全局有一个root_manager 持有了
- span的跟踪,有时候我们需要 跟踪一段逻辑的开始与结束
- langchain 采用on_xx_start, on_xx_end方式,通过run_id 来标记是同一个逻辑。
- llamaindex 采用预定义span方式(其实用XXEventStart和XXEventEnt也可以)。你可以预定义XXSpan,触发测
import llama_index.core.instrumentation as instrument dispatcher = instrument.get_dispatcher(__name__) def func(): dispatcher.span_enter(...) try: val = ... except: ... dispatcher.span_drop(...) else: dispatcher.span_exit(...) return val class MyCustomSpanHandler(BaseSpanHandler[MyCustomSpan]): def new_span(self,id_: str,)-> Optional[T]: ... def prepare_to_exit_span(self,id_: str,) -> Optional[T]:... def prepare_to_drop_span(self,id_: str,) -> Optional[T]:...HITL/human in the loop
langchain 主要是通过checkpoint 机制,遇到人工录入时,先将graph暂存,拿到human input 后再根据thread-id等resume graph运行。
llamaindex human in the loop 在llamaindex中
- workflow 本身提供了 ctx.write_event_to_stream 和 ctx.wait_for_event 作为workflow 与外部交流的手段
async def dangerous_task(ctx: Context) -> str: """A dangerous task that requires human confirmation.""" # emit an event to the external stream to be captured ctx.write_event_to_stream( InputRequiredEvent( prefix="Are you sure you want to proceed? ", user_name="Laurie", ) ) # wait until we see a HumanResponseEvent response = await ctx.wait_for_event( HumanResponseEvent, requirements={"user_name": "Laurie"} ) # act on the input from the event if response.response.strip().lower() == "yes": return "Dangerous task completed successfully." else: return "Dangerous task aborted." - 实现原理上,内置了 InputRequiredEvent and HumanResponseEvent,step 发出的InputRequiredEvent 不被任何step receive,用户的输入可以被封装到 HumanResponseEven 以被某个step 接收。
async for event in handler.stream_events(): if isinstance(event, InputRequiredEvent): # capture keyboard input response = input(event.prefix) # send our response back handler.ctx.send_event( HumanResponseEvent( response=response, user_name=event.user_name, ) ) - 如果用户输入这个过程耗时很长,llamaindex 不提供手段持久化context,需开发者自行维护。PS: 这也是为何workflow 要有一个context,因为workflow本身的执行必须是无状态的,状态全部保存到context里。
与fastapi 结合示例 https://github.com/run-llama/human_in_the_loop_workflow_demo
其它
将 Agent 连接到它们所需的工具和数据,从根本上讲是一个分布式系统问题。这种复杂性与设计微服务时面临的挑战相似,因为在微服务中,各个组件必须高效地进行通信,而不产生瓶颈或僵化的依赖关系。当然,你可以通过 RPC 和 API 将 Agent 与工具连接起来,但这会导致系统的紧耦合。紧耦合使得扩展、适应或支持多个数据消费者变得更加困难。Agent 需要灵活性。它们的输出必须无缝地流入其他 Agent、服务和平台,而不将所有内容锁定在僵化的依赖关系中。解决方案是什么?通过事件驱动架构(EDA)实现松耦合。它是允许 Agent 共享信息、实时行动并与更广泛生态系统集成的支柱——无需紧耦合带来的头痛问题。
留下评论