GPU与CUDA
简介
绝大部分的 AI 应用,的确不需要我们手写数学计算的 GPU 代码。但为了满足模型创新的需求,有必要学习 GPU 编程。例如 Meta 发布的 HSTU 生成式推荐模型,核心的 hstu_attn 计算,如果直接用 PyTorch 框架算子组合实现,则时间复杂度为 O(M * N²) ,其中 M 和 N 是一个数量级,相当于O(N³) 。但是通过自定义内核,可以优化到 O(N²)。我们习惯于传统 CPU 编程处理串行的计算任务,通过多线程提高并发度。而 GPU 采用 SIMT 架构,有大量计算单元(CUDA Cores)和数万个线程,但是被分组后的线程同一时刻只能执行相同的指令。这与传统CPU的串行思维、不同线程处理不同任务,存在根本性冲突,导致 GPU 编程学习难度大。现在推荐使用 Triton 编程语言完成 GPU kernel 的开发,它提供类似 Python 的语法,无需深入理解 GPU 硬件细节(如线程调度、共享内存管理),而且和 PyTorch 深度学习框架的生态结合更好。
NVIDIA 率先在 GPU 中引入了通用计算能力,使得开发者能利用 CUDA 编程语言来驱动。这时候 GPU 的核心都是 CUDA Core。由于一个 GPU 里面有大量的 CUDA Core,使得并行度高的程序获得了极大的并行加速。但是,CUDA Core 在一个时钟周期只能完成一个操作,矩阵乘法操作依然需要耗费大量的时间。NVIDIA 为了进一步加速“加乘运算”,在 2017 年推出了 Volta 架构的 GPU,从这个架构开始 Tensor Core 被引入。它可以在一个时钟周期完成两个 4×4x4 半精度浮点矩阵的乘法(64 GEMM per clock)。
前奏——并行计算
不会 CUDA 也能轻松看懂的 FlashAttention 教程(算法原理篇)考虑这样一个向量加法任务:假设向量数组 a, b, c 的长度都是 16,我们要在 4 个 GPU 计算单元上实现 c=a+b 的操作,应该怎么为每个计算单元编写程序呢?最直观的想法肯定是把向量平均拆成四组,让每个计算单元计算 4 个分量的加法结果。这是因为如果任务分配不均匀,任务完成的总时间会取决于任务最多的那个计算单元,这个时间会比平均分更久。因此,我们可以为每个计算单元各自编写如下所示的程序。
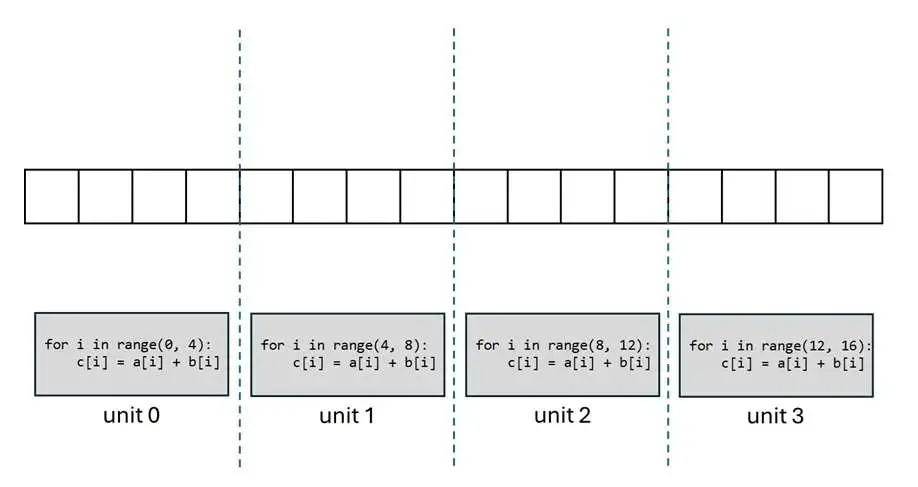
为每个计算单元单独写一段程序太累了,能不能只写一段程序,然后让所有计算单元都执行同一段程序呢?这当然可以,但还有一个小小的额外要求:由于现在所有计算单元共用一段程序,我们需要额外输入当前计算单元的 ID 来告知程序正在哪个计算单元上运行。得知了这个额外信息后,我们就可以自动算出当前计算单元应该处理的数据范围,写出下面的程序。
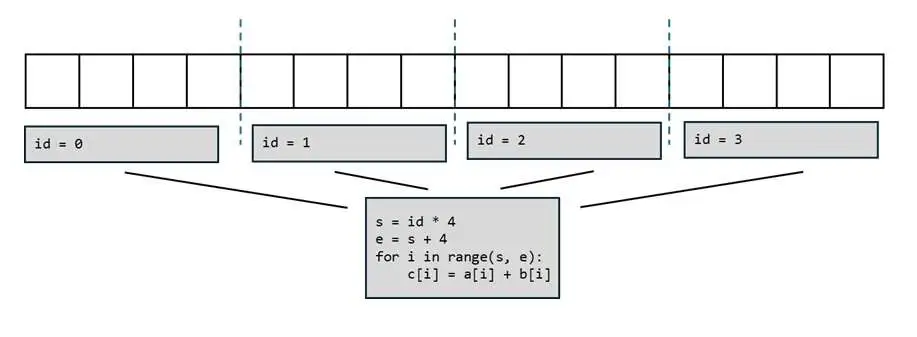
有了这段通用的程序,我们其实就可以实现任意长向量的加法运算。比如当向量的长度变成 32 时,我们可以分配 8 个计算单元来计算。可见,并行编程的目标就是写一段通用的程序,并根据计算单元的 ID 选取同样数量的数据做计算。
在上面的例子中,我们让每个计算单元都计算 4 个数据。实际情况中,应该给每个计算单元分配多少数据呢?一般来说,一个计算单元的并行计算器和存储空间都是有限的,应该尽可能用满它的计算资源。比如一个计算单元最多能并行算 4 个数据,且内存也只够存 4 个数据,那么我们就给它分配 4 个数据。在学习和设计并行算法时,我们不需要知道每个计算单元具体分配多少数据,但要设计把数据拆分进每个计算单元的方式。比如对于形状为N*M的二维矩阵,计算单元一次能计算d个数据,我们要决定是把数据在两个维度上拆分,得到 $\frac{N}{\sqrt{d}} \times \frac{M}{\sqrt{d}}$组,还是只在第二维上拆分,得到$N \times \frac{M}{d}$组。
向量加法只是一个非常简单的运算,由于每个分量之间的计算是独立的,它天然就支持并行计算。而其他的运算就不一定满足这个性质了。比如向量求和:对于一个长度 16 的向量,我们要求出其 16 个分量之和。如果是串行算法,我们会写成这样:
sum = 0
for i in range(0, 16):
sum = sum + a[i]
在每一步运算中,我们都需要读取当前的 sum,并更新 sum 的值。每步运算之间不是独立的,实现并行计算的方式不是很直观。用 GPU 编程实现更复杂的算子时,我们要仔细分析运算的过程,区分哪块运算像向量加法一样,是互相独立的;而哪些运算像向量求和一样,不好进行并行计算。之后,我们就要巧妙地对数据拆分,分配到各个计算单元中。比如,我们要求二维矩阵第二维(每一行)的和,我们发现矩阵每行之间的运算是独立的。因此,我们可以在第一维把数据拆分,让每个计算单元串行计算矩阵某一行的和。
相比使用高级语言编程,在 GPU 编程时,我们要多考虑两件事:1)访存开销;2)将可并行的运算拆分。具体的知识点有:
- GPU 的存储从顶到底分为三层: GPU SRAM, GPU HBM, CPU DRAM,它们的访存速度依次递减。编程时我们一般只考虑前两层之间的读写开销。 通过观察算子本身的性质,我们可以利用算子融合技术减少访存开销。不反复读取同一批数据、不读写中间结果是两个常见的优化场景。
- GPU 由许多独立的计算单元组成,且每个计算单元本身也可以并行计算多个数据。但每个计算单元一次能并行处理的数据是有限的。如果数据量超过了计算单元的显存,要设法拆分数据。
- 实现并行编程,实际上就是写一个输入参数包含计算单元 ID 的程序。我们要根据 ID 选取同样长度的一段数据,仅考虑这段数据该如何运算。
- 并行编程的一大难点在于观察哪些运算是独立的,并把可以独立运算的部分分配仅不同计算单元。
基本概念
以下是一个使用 CUDA 1.0 语法编写的简单向量加法示例。
- GPU内存申请和复制。先调用 cudaMalloc 完成 GPU 全局内存申请。接着再调用 cudaMemcpy 函数将数据从主机复制到 GPU 设备。
- 设置线程快和网格维度,并让 GPU 执行核函数,在 CUDA 中引入了核函数(Kernel)的概念。所谓核函数,是用
__global__修饰的函数,由 CPU 调用并在 GPU 上并行执行。 - 将结果拷贝回 CPU 内存中。
#include <stdio.h>
#include <cuda_runtime.h>
// CUDA 核函数定义:向量加法
__global__ void vectorAdd(const float *a, const float *b, float *c, int n) {
// 计算全局线程索引
int idx = threadIdx.x + blockIdx.x * blockDim.x;
if (i < N) c[i] = a[i] + b[i];
}
int main() {
// 分配主机内存并初始化
float *h_a, *h_b, *h_c;
h_a = (float*)malloc(size);
h_b = (float*)malloc(size);
h_c = (float*)malloc(size);
...
// 分配设备内存
float *d_a, *d_b, *d_c;
cudaMalloc((void**)&d_a, size);
cudaMalloc((void**)&d_b, size);
cudaMalloc((void**)&d_c, size);
// 将数据从主机复制到设备
cudaMemcpy(d_a, h_a, size, cudaMemcpyHostToDevice);
cudaMemcpy(d_b, h_b, size, cudaMemcpyHostToDevice);
// 设置线程块和网格维度
// CUDA 1.0 要求每个线程块的线程数不超过512
int threadsPerBlock = 256;
int blocksPerGrid = (n + threadsPerBlock - 1) / threadsPerBlock;
// 执行核函数
vectorAdd<<<blocksPerGrid, threadsPerBlock>>>(d_a, d_b, d_c, n);
// 将结果从设备复制到主机
cudaMemcpy(h_c, d_c, size, cudaMemcpyDeviceToHost);
}
编程模型:
- CUDA 提供主机 - 设备(Host-Device)编程范式,CPU 作为主机(Host)负责控制逻辑,GPU 作为设备(Device)执行并行计算。设计实现了三大块功能
- GPU 内存的管理。cudaMalloc/cudaMemcpy/cudaFree
- 核函数定义
- GPU核的抽象。CUDA对硬件进行了抽象。将 GPU 的流处理器抽象为线程(Thread)、线程块(Thread Block)和线程束(Warp)。
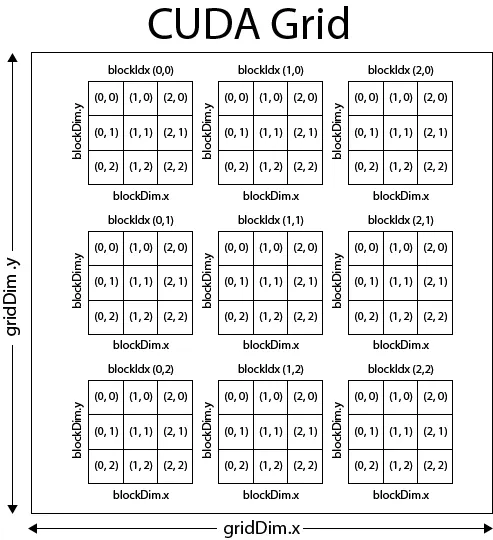
- 将一个待批量并发的数据组织成Grid、Thread Block、Thread的结构。Grid和Thread Block可以是1维的也可以是2维或者3维的。这里这么设计,感觉主要是为了让程序员可以根据实际处理的结构能够更自然的思考,同时可以覆盖数据局部性需求,比如,我要处理一个1维数据,自然的我们就可以把Grid和Thread Block定义为1维的。
|CUDA软件抽象|对应硬件组件|Demo 中的参数| |—|—|—| |线程(Thread)|流处理器(SP)|threadIdx.x| |线程块(Block)|流多处理器(SM)|threadsPerBlock = 256| |网格(Grid)|整个 GPU|blocksPerGrid = ceil(n/256)| PS:访问慢内存(例如全局内存)较多的 Kernel,想隐藏延迟,适合较大 threadsPerBlock,提升吞吐。计算密集,寄存器使用多,那么较大的 threadsPerBlock 会导致寄存器爆表,反而使得SM 上只能调度少量的 Warp,导致性能下降。
int blockSize = 256;
int numBlocks = (N + blockSize - 1) / blockSize;
add<<<numBlocks, blockSize>>>(N, d_x, d_y);
__global__ void add(int n, float *x, float *y)
{
int index = blockIdx.x * blockDim.x + threadIdx.x;
if (index < n) {
y[index] = x[index] + y[index];
}
}
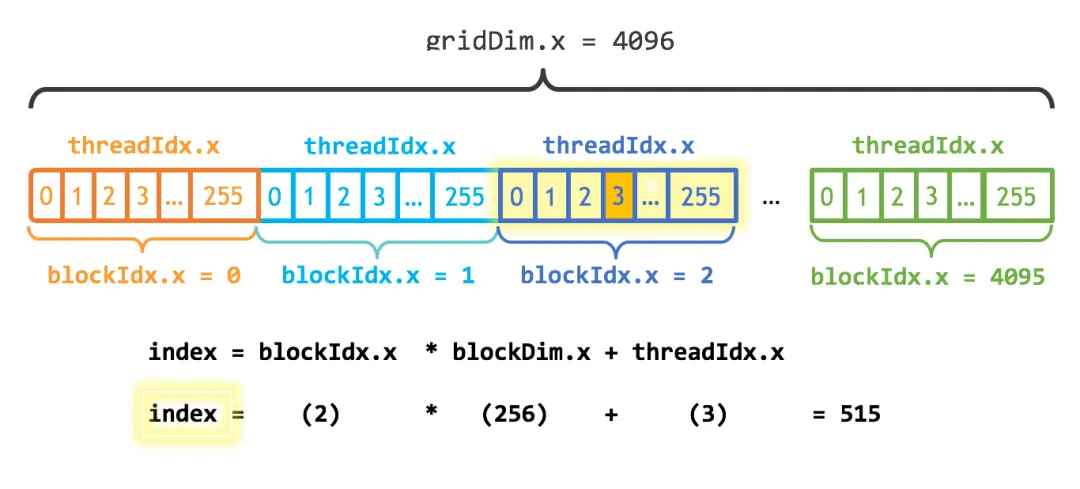
这行代码是CUDA编程的基石(SIMT),它将软件层面的线程坐标映射到数据上的全局索引。表面上在编写拥有独立控制流的线程,但底层硬件将其分组为 32 个线程的 warp(线程束),并在底层同步运行 warp,每个线程都有自己的程序计数器、寄存器和控制流。其内存层次结构会奖励你保持数据在内存中的稳定,并惩罚你随意管理数据的行为。
- gridDim.x: Grid 在 x 维度上有多少个 Block。
- blockIdx.x: 当前 Block 在 Grid 中的 x 坐标。范围是 0 到 gridDim.x - 1。
- blockDim.x: 每个 Block 在 x 维度上有多少个 Thread。(在我们例子中是256)。
- threadIdx.x: 当前 Thread 在其 Block 内的 x 坐标。范围是 0 到 blockDim.x - 1。
blockIdx.x * blockDim.x计算出了当前线程块之前所有线程块包含的线程总数(偏移量),再加上threadIdx.x,就得到了当前线程在整个Grid中的全局唯一ID。这保证了比如一个一维数组10亿个元素,每个都能被一个特定的线程处理到。
这里解释下上面提到的数据局部性: y[index] = x[index] + y[index]; 可以合并访存 (Coalesced Memory Access)。即一个Warp中的32个线程访问连续的32个内存地址,GPU硬件可以将其合并成一次或少数几次宽内存事务,极大提升访存效率。
而当我们要处理一个二维矩阵或图像时,最自然的思考方式就是二维的。这时候我们可以用2维的Grid和Thread Block。
dim3 blockSize(16, 16); // 16x16 = 256 线程/块
dim3 gridSize((N + blockSize.x - 1) / blockSize.x, (N + blockSize.y - 1) / blockSize.y);
__global__ void matrixMulGPU(const float* A, const float* B, float* C, int N) {
int row = blockIdx.y * blockDim.y + threadIdx.y;
int col = blockIdx.x * blockDim.x + threadIdx.x;
if (row < N && col < N) {
float sum = 0.0f;
for (int k = 0; k < N; ++k) {
sum += A[row * N + k] * B[k * N + col];
}
C[row * N + col] = sum;
}
}
Kernel函数add会被启动成茫茫多的线程执行。每个线程通过计算 blockIdx 和 threadIdx 来处理不同的数据。从程序员的角度看,我们似乎是在编写多线程(Multiple Threads)程序。PS:有点算法里的多路归并有木有。
示例
CUDA编程指北:从入门到实践 未读完,可继续。 CUDA 程序一般使用 .cu 后缀,编译 CUDA 程序则使用 nvcc 编译器。一般而言,一个 CUDA 程序的结构如下:
int main() {
主机代码; // 负责 CPU 和 GPU数据传输、GPU内存管理、以及启动 GPU 内核(内核启动参数指定了 GPU 上线程的数量和分布方式)等
核函数调用; // 每个内核函数在 GPU 的众多 CUDA 核心上并行执行,在 GPU 的多个线程上同时执行
主机代码;
核函数调用;
......
return 0;
}
__global__ void 核函数1(parameters) {
// 在设备代码中,计算任务被分解为多个线程,这些线程组成线程块(Block),多个线程块组成一个线程网格(Grid)。CUDA 提供了 threadIdx、blockIdx 等内置变量来获取线程的索引,从而让每个线程在数据中找到属于自己的计算任务。
......
}
__global__ void 核函数2(parameters) {
......
}
前缀__global__用来定义一个核函数,在 CUDA 中,核函数只能返回 void 类型(无返回值),这意味着当我们需要写计算结果时,应该在参数列表中传入一个用来存放计算结果的指针,然后将计算结果写回到这个指针指向的存储空间中。CUDA 核函数传入的参数必须是指向设备内存,因此,我们必须预先在主机代码中分配设备内存并初始化。分配设备内存可以使用 cudaMalloc 函数,初始化设备内存则可以将一段已经初始化好的主机内存拷贝到刚分配好的设备内存中,这可以使用 cudaMemcpy 函数实现,这两个函数的函数原型如下:
cudaError_t cudaMalloc(void** d_ptr, unsigned int size);
cudaError_t cudaMemcpy(void* d_ptr, void* h_ptr, unsigned int size, enum cudaMemcpyKind)
PS:所以在推理框架中,显存管理是推理框架负责。核函数 都是被封装后,注册到算子里,被类似op.forward 触发执行。 核函数是无状态的。 核函数的调用语法(内核启动语法)如下所示:
// CUDA 使用特殊的语法 <<<Grid, Block>>> 启动内核函数。
kernel_function<<<grid_size, block_size>>>(parameters)
// 也可以认为是
kernel<<<numBlocks, threadsPerBlock>>>(parameters)
// numBlocks 表示线程块的数量,threadsPerBlock 表示每个线程块中包含的线程数。
// 通过指定线程块数和线程数,内核启动控制了 GPU 的并行粒度。较大的数据集通常需要更多的线程和线程块来充分利用 GPU 的并行能力。
CUDA 的核函数设计一般遵循如下范式:data1,data2 … 表示需要处理的数据指针,index1 和 index2 … 用来定位需要计算的数据的位置,some_operation 对这些数据进行指定的计算操作,然后写回到参数列表中传入的用于记录结果的 result 指针中。总结下来就是两部曲:确定线程和数据的对应; 对需要处理的数据执行操作。PS:CUDA 最难的是并行思想。并行思想其中难上加难的东西是数据分组。并行计算中,最重要的一点是为数据分组成多个小数据块,每个线程(进程)再去实现SPMD或者SIMD/T。而这个数据分组的方式,存储方法等等直接的影响到你这个并行程序最终的性能。大部分的并行程序,解决了数据分组问题,其本身的问题就解决了,算法本身的优化反倒是不是那么的重要了。
__global__ void kernel_function(data1, data2, ..., result) {
index1, index2, ... = get_index(thread_info)
result = some_operations(data1[index1], data2[index2], ...)
}
内核启动后,GPU 可以异步执行任务,CPU 继续进行其他操作,直至需要等待 GPU 完成。开发者可以利用这种异步特性,使程序在 CPU 和 GPU 间并行执行,达到更高的并行效率。此外,CUDA 提供了同步函数(如 cudaDeviceSynchronize),确保 CPU 在需要时等待 GPU 完成所有操作,避免数据不一致的问题。
编译 CUDA 程序:编译 CUDA 程序需要使用 Nvidia 官方提供的编译器 nvcc。nvcc 会先将所有源代码先分离成主机代码和设备代码,主机代码完整支持 C++ 语法,设备代码只部分支持 C++ 语法。nvcc 先将设备代码编译为 PTX(parallel thread execution)伪汇编代码,再将 PTX 代码编译为二进制的 cubin 目标代码。CUDA 中核函数也因此不能直接作为类的成员函数,如果希望使用面向对象,我们一般通过包装函数调用核函数,然后将这个包装函数作为成员函数。
cuda的寄存器存储和共享内存
// 静态声明shared memory
__global__ void my_kernel() {
__shared__ int i;
}
// 动态声明shared memory
my_kernel(grid_dim, block_dim, 8) // 调用的时候指定动态内存的大小。这里8就是动态分配的。
__global__ void my_kernel() {
extern __shared__ int arr[];
}
// kernel函数中寄存器分配的场景一般有如下几种:临时变量,循环中分配的变量,函数调用和函数返回值。
__device__ int do_something(int x) {
return x*100; //返回值会被存放在register上。
}
__global__ void my_kernel() {
int a; //临时变量.a会被存放在register中
// for中的变量i会被存放在register中
for(int i=0;i<100;++i){
...
}
// do_something()的返回值会被存放在register中
int b = do_something(a);
// 大数组不会被存放在register上
int arr[1000];
}
大数组、结构体、动态分配的数组不会被存放在register上,而是存放在local memory中。local memory是global memory中的一块区域,由cuda自动分配,专门用来存放线程私有的数据。很显然,它的访问速度会比register 和shared memory慢很多。
cuda的同步有两种:
- 系统级同步:同步host和device的工作,用cudaDeviceSynchronize()接口。这个接口会阻塞所有host的工作,直到cuda端的工作完成。
- block线程同步。同步同一个block内的线程,用__synthreads()接口。同一个block内的线程用register和shared memory 进行通信。 cuda不同block之间的线程无法同步。如果需要,只能使用系统级同步方式,,使用cudaDeviceSynchronize()进行等待,在不同block的线程达到checkpoint后结束当前的kernel,开启新的kernel。
执行过程
CUDA C++ 编程指北-第一章:入门以及编程模型 未读。
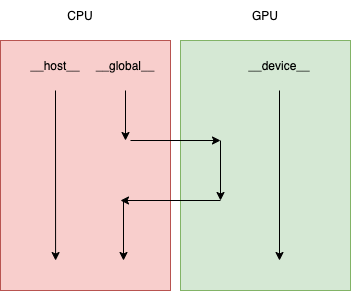
device 函数和global函数因为需要在GPU上运行,因此不能调用常见的一些 C/C++ 函数(因为这些函数没有对应的 GPU 实现)。
| 限定符 | 执行 | 调用 | 备注 |
|---|---|---|---|
| global | 设备端执行 | 可以从主机调用也可以从某些特定设备调用 | 异步操作,host 将并行计算任务发射到GPU的任务调用单之后,不会等待kernel执行完就执行下一步 |
| device | 设备端执行 | 设备端调用 | |
| host | 主机端执行 | 主机调用 |
典型的CUDA程序的执行流程如下:
- 分配host内存,并进行数据初始化;
- 分配device内存,并从host将数据拷贝到device上;
- 调用CUDA的核函数在device上完成指定的运算;
- 将device上的运算结果拷贝到host上;
- 释放device和host上分配的内存。
矩阵加法示例
// __global__ 表示在device上执行,从host中调用
// 两个向量加法kernel,grid和block均为一维
// 为每个线程分配了一个其所属的向量元素,然后驱动线程分别完成计算
__global__ void add(float* x, float * y, float* z, int n){
// 计算线程的编号,根据自己的线程编号,读取数据源不同位置的元素,执行计算,并将结果写入结果的不同位置。
// 这样,我们就为不同线程安排了独立的工作,让他们并发地完成工作。
int index = threadIdx.x + blockIdx.x * blockDim.x;
// 步长
int stride = blockDim.x * gridDim.x;
for (int i = index; i < n; i += stride){ // cuda编程经常会跨步长,每个thread 只计算数据的局部和/积/xx。
z[i] = x[i] + y[i]; // 每个线程都执行这条指令,每个线程读取不同元素执行相同计算
}
}
int main(){
int N = 1 << 20;
int nBytes = N * sizeof(float);
// 申请host内存
float *x, *y, *z;
x = (float*)malloc(nBytes);
y = (float*)malloc(nBytes);
z = (float*)malloc(nBytes);
// 初始化数据
for (int i = 0; i < N; ++i){
x[i] = 10.0;
y[i] = 20.0;
}
// 申请device内存
float *d_x, *d_y, *d_z;
cudaMalloc((void**)&d_x, nBytes);
cudaMalloc((void**)&d_y, nBytes);
cudaMalloc((void**)&d_z, nBytes);
// 将host数据拷贝到device
cudaMemcpy((void*)d_x, (void*)x, nBytes, cudaMemcpyHostToDevice);
cudaMemcpy((void*)d_y, (void*)y, nBytes, cudaMemcpyHostToDevice);
// 定义kernel的执行配置
dim3 blockSize(256);
dim3 gridSize((N + blockSize.x - 1) / blockSize.x);
// 执行kernel
add << < gridSize, blockSize >> >(d_x, d_y, d_z, N); # 第一个数字指明改程序分配多少个block,第二个数字程序指明每个block中的thread个数
// 将device得到的结果拷贝到host
cudaMemcpy((void*)z, (void*)d_z, nBytes, cudaMemcpyDeviceToHost);
// 检查执行结果
float maxError = 0.0;
for (int i = 0; i < N; i++)
maxError = fmax(maxError, fabs(z[i] - 30.0));
std::cout << "最大误差: " << maxError << std::endl;
// 释放device内存
cudaFree(d_x);
cudaFree(d_y);
cudaFree(d_z);
// 释放host内存
free(x);
free(y);
free(z);
return 0;
}
如何在 CPU 之上调用 GPU 操作?可以通过调用 __global__ 方法来在GPU之上执行并行操作。我的第一份CUDA代码 - xcyuyuyu的文章 - 知乎 kernel在调用时也必须通过执行配置<<<grid, block>>>来指定kernel所使用的线程数及结构。一个thread需要两个内置的坐标变量(blockIdx,threadIdx)来唯一标识,其中blockIdx指明block在grid中的位置,而threaIdx指明线程所在block中的位置。
main函数中的cudaMalloc、cudaMemcpy,是CPU操作GPU内存的操作,在分离式GPU架构(也就是独显)中,CPU分配内存用于GPU计算,再将数据传输到分配的内存空间,然后在GPU上启动内核函数。GPU执行的内核函数只能从分配的GPU内存空间读取数据。代码中的host向量对应CPU内存的数据,而device向量则代表GPU内存的数据。完成内存分配和数据拷贝后,CPU触发GPU执行add内核函数。触发时同时指定了执行内核函数的线程的组织形式。在CUDA编程中,线程以thread,thread block,grid的层级结构进行组织。一个线程块由多少个线程组成可以指定,线程块本身的数量则是由计算规模决定的,比如根据向量的长度计算了线程块的数量:int blocks_num = (n + t - 1) / t; // thread block数量,这样计算的目的是保证线程数量足够,即每一个计算单元都有一个线程负责计算。add内核函数就是以SIMT模型进行编程的,安排所有线程执行相同的指令,但每个线程执行指令时的指令操作数均不同,这便是SIMT。
同步机制
当我们Warp间或者同一个Warp中的不同thread间需要同步时,怎么办呢?
__syncthreads()它保证一个Block内的所有线程都执行到这个Barriers后,才能一起继续往下执行。__syncwarp()它保证一个Warp内的32个线程都执行到这个Barriers后,才能继续往下执行。
指令集与编译
编译-Fat Binary
上面CUDA C语言编写的add 只是到了高级语言层面,众所周知,高级语言需要转换为机器码才能被机器执行,本节将简单介绍CUDA C/C++的程序的编译流程,以及CUDA的PTX、SASS指令集。
- 主机代码编译: 将C/C++代码(在CPU上运行的部分)交由系统的主机编译器(如GCC、MSVC)编译成标准的CPU目标代码。
- 设备代码编译: 将在
__global__函数(如add)中定义的GPU代码,编译成两种主要格式:- SASS(Streaming Assembly)是GPU的机器指令集,是实际在GPU上执行的指令。SASS指令集直接对应GPU架构(Maxwell、Pascal等),虽然不是严格的一一对应,但通常每个GPU架构有专属的SASS指令集,因此需要针对特定架构进行编译。
- PTX(Parallel Thread Execution)是一种中间表示形式,位于高级GPU编程语言(如CUDA C/C++)和低级机器指令集(SASS)之间。PTX与GPU架构基本无耦合关系,它本质上是从SASS上抽象出来的一种更上层的软件编程模型,PTX的存在保证了代码的可移植性(同一份PTX分发到不同架构上转为对应SASS)与向后兼容性(可将PTX代码转为最新GPU架构对应的SASS)。PTX是开发者可编程的最底层级,而SASS层则是完全闭源的,这也是NVIDIA的“护城河”之一。
这两种设备代码连同主机代码一起,被打包进一个可执行文件中,形成所谓的胖二进制 (Fat Binary)。它“胖”在包含了一份主机代码和多份针对不同GPU架构的设备代码。
CUDA程序的编译由NVCC(NVIDIA CUDA Compiler)完成。

首先,NVCC完成预处理;随后分类代码为设备代码和主机代码,NVCC驱动传统的C/C++编译器主机代码的编译和汇编;对于设备代码,NVCC将其编译针对某架构的SASS,编译过程中涉及C –> PTX –> SASS的转化,但通常不显式表现出来,生成的PTX/SASS码也会被直接嵌入最终的可执行文件。
 运行期,GPU会优先查找可执行文件中是否有适合当前架构的SASS,如有则直接执行。若无,则GPU驱动(driver)会使用JIT(Just-In-Time)编译手段,将PTX码编译为当前架构对应的SASS再执行(前提是可执行文件必须包含PTX)。
运行期,GPU会优先查找可执行文件中是否有适合当前架构的SASS,如有则直接执行。若无,则GPU驱动(driver)会使用JIT(Just-In-Time)编译手段,将PTX码编译为当前架构对应的SASS再执行(前提是可执行文件必须包含PTX)。
程序加载cubin loading
- 程序启动。操作系统加载可执行文件,CPU 开始执行主机代码。
- 首次 CUDA 调用。当代码第一次调用任何 CUDA API 函数时(比如 cudaSetDevice, cudaMalloc,或者第一个Kernel函数启动),CUDA 运行时库 (CUDA Runtime Library) 会被初始化。此处就是所谓的GPU上下文初始化/CUDA上下文初始化,主要步骤:
- 硬件准备与唤醒。从低功耗的待机模式唤醒,进入高性能的计算模式;加载驱动模块(如NVIDIA CUDA Driver或AMD ROCm),并检测可用GPU设备及其属性(如显存大小、计算能力、NVLink连接)。
- CUDA上下文数据结构创建。CPU侧创建上下文信息的数据结构:创建一个统一虚拟地址空间(UVA),这个空间可以将所有的系统内存和所有GPU的内存都映射进来,共享一个单一的虚拟地址空间。(每次cudaMalloc都会增加一条记录)
- 特定GPU上创建上下文。
- 在显存中为当前进程分配并建立页表结构。NVIDIA驱动程序(在CPU上)查询其内部维护的、用于管理GPU物理显存的数据结构(即VRAM Allocator,跨进程维护),以找到一个空闲的物理地址。CPU本地软件操作,不涉及与GPU的硬件通信。CPU在自己的内存(RAM)里,准备好了要写入的数据内容;NVIDIA驱动程序(在CPU上)命令DMA引擎将对应数据复制到显存;
- 分配Pinned Memory命令缓冲区
- 通过MMIO配置GPU的MMU硬件(PMMU 控制寄存器),告诉它页表的起始位置
- 上下文就绪。上下文完全建立,后续的Kernel函数启动、内存拷贝等命令可以通过流 (Stream) 机制提交到其命令缓冲区,由GPU异步执行。
- 首次调用
add<<<...>>>()时,进行Kernel函数加载- 检测硬件。它会查询当前的 GPU,识别出具体架构。
- 寻找最佳匹配 (SASS)。然后,它会在 Fat Binary 的设备代码段中进行搜索,寻找有没有预编译好的、针对 sm_75 的 SASS 代码。
- 没有找到完全匹配的 SASS 代码。如果没有找到完全匹配的 SASS 代码运行时会找到 PTX 中间代码,并调用集成在 GPU 驱动中的 JIT (Just-In-Time) 编译器将其即时编译(JIT)为目标GPU的SASS代码; (cpu上完成);为了避免每次运行程序都重新进行 JIT 编译,NVIDIA 驱动通常会缓存 JIT 编译的结果。NVIDIA驱动会在用户的home目录下创建一个计算缓存,通常是 ~/.nv/ComputeCache。
- cubin loading (cubin 是 CUDA binary 的缩写)。将准备好的 SASS 代码(无论是来自 Fat Binary 还是 JIT 编译的结果)申请显存空间;通过DMA复制到显存;驱动程序在其内部的表格中,将Kernel函数 add 与其在 VRAM 中的地址关联起来。后续调用
add<<<...>>>()时,运行时会将一个包含该 VRAM 地址的启动命令提交到流中,由 GPU 异步执行。
程序执行 - Kernel Launch
一个常见的误解是CPU会直接、实时地控制GPU。实际上,考虑到CPU和GPU是两个独立的处理器,并且通过PCIe总线连接,直接的、同步的控制会带来巨大的延迟和性能开销。因此,现代GPU采用了一种高效的异步通信模型,其核心就是 命令缓冲区(Command Buffer)与门铃(Doorbell)机制。这也是CUDA Streaming的底层通讯机制。
- cpu先把需要执行的命令写到ring buffer命令缓冲区(Pinned Memory,位于主机内存); 更新w_ptr
- 在适当的时候通过MMIO设置Doorbell Register,告诉GPU有新任务需要处理
- GPU上的DMA引擎将ring buffer命令缓冲区
[r_ptr, w_ptr)复制到显存中,然后开始执行;(其中w_ptr和r_ptr可以理解为相对于 Ring Buffer 基地址 (Base Address) 的偏移量)
下面对于部分有代表型的API的执行逻辑进行单独阐述。
CPU 执行到cudaMalloc。cudaMalloc 是一个同步阻塞调用,它不使用上述的流式命令缓冲区机制。(CUDA 11.2+支持cudaMallocAsync可实现异步分配)
- CPU 线程调用 cudaMalloc()。CUDA 运行时库将此请求转发给 NVIDIA 驱动程序
- 驱动程序向物理VRAM Allocator请求物理内存,向 UVA Manager 请求虚拟地址,更新UVA映射表;(物理VRAM Allocator是跨进程的,维护整个GPU 物理显存的使用情况)
- 更新 GPU page table[Command Buffer + Doorbell方式,特定的、高优先级的通道,非默认的Stream],刷新TLB
- 返回虚拟内存指针
与malloc的不同之处
- Lazy Allocation vs. Eager Allocation。malloc支持overcommit,实际物理内存的分配发生在访问时(Lazy Allocation),通过缺页中断(Page Fault)按需映射到物理内存;而cudaMalloc是同步分配连续的物理显存(Eager Allocation),保证了后续使用的确定性,但初始开销更高。
- system call overhead。cudaMalloc直接陷入内核,调用GPU驱动分配物理内存;而malloc本身是C库函数(用户态), 向操作系统“批发”大块内存,然后在用户程序请求时“零售”出去。避免内存分配时昂贵的系统调用和缺页异常开销
- 申请<128KB内存时,会优先在freelist中查找是否有合适的空闲 Chunk,没有找到,才会通过brk系统调用向操作系统申请内存
- 申请>=128KB内存时,会直接通过mmap系统调用向操作系统申请内存,free时也会直接释放
- 释放策略。cudaFree会直接释放,而free对于brk/sbrk分配的内存不会直接释放(物理内存和虚拟内存都不释放,为了避免Page Fault引入的性能开销就没有释放物理内存),用户态维护freelist,同时会合并连续空闲的虚拟地址空间,有效减少内存碎片(coalescing)。
CPU 执行到 cudaMemcpy、cudaMemset。通过Command Buffer + Doorbell 机制提交命令到GPU; 然后同步或者异步等待
CPU 执行到Kernel函数add<<<...>>>()。
- CPU侧:命令打包与提交。
- 驱动将Kernel函数启动所需信息打包成一个命令。命令包括:启动Kernel函数,Kernel函数对应的add SASS 代码的入口地址,执行配置(Grid 维度、Block 维度、共享内存大小等)、参数指针(GPU虚拟地址)
- 将命令写入主机端的 Pinned Memory Ring Buffer
- 通过 MMIO 写 Doorbell 寄存器,通知 GPU
- GPU侧: 命令获取与运行。
- 通过 DMA 从 Pinned Memory 读取Ring buffer部分内容
- 命令解码。GPU 的命令处理器 (Front-End) 从其内部队列中取出命令包。它开始解码这个命令包,识别出这是一个“Kernel函数启动”任务,并解析出所有的执行参数(Grid/Block 维度、Kernel函数地址等)。
- 工作分发。命令处理器根据 Grid 的维度,将整个计算任务分发成一个个独立的Thread Blocks。GPU的全局调度器(GigaThread Engine),将Thread Blocks分配给有空闲资源的 SM。一个线程块从生到死都只会在一个 SM 上执行,不会迁移。
int blockSize = 256; int numBlocks = (N + blockSize - 1) / blockSize; add<<<numBlocks, blockSize>>>(N, d_x, d_y);
- 线程块调度与执行。每个 SM 接收到一个或多个线程块,SM 内部的硬件调度器 (Scheduler)进一步将每个线程块内部的线程,按照threadIdx的顺序,每 32 个线程划分成一个 Warp。比如,一个有 256 个线程的线程块,会被划分为 8 个 Warps (Warp 0: 线程 0-31, Warp 1: 线程 32-63, …)。SM 内部的硬件调度器 (Scheduler) Warps分配给 SM 内的CUDA Cores 和其他执行单元(如 Tensor Cores)去执行。CUDA 核心开始执行位于指定 SASS 地址的机器指令,进行实际的计算。
__global__ void add(int n, float *x, float *y){ int index = blockIdx.x * blockDim.x + threadIdx.x; if (index < n) { y[index] = x[index] + y[index]; } } - 完成与资源回收。当一个线程块完成了所有计算,它所占用的 SM 资源(如寄存器、共享内存)会被释放,SM 可以接收新的线程块。当整个 Grid 的所有线程块都执行完毕,这个Kernel函数启动任务就算完成了。 PS:必须得结合cuda执行流程来看gpu硬件架构。Thread Blocks ==> SM 类似cpu 场景thread给cpu core。cpu scheduler调度thread,sm scheduler(硬件实现) 调度wrap。cpu thread 用到cpu core内的加法器等,wrap(32个thread) 用到sm内的cuda core或tensor code等。
SIMD和SIMT
在传统的标量计算模型中,CPU的一条指令一次只能操作单个数据。例如,一次浮点加法就是double + double;当处理如图形、音频或科学计算中常见的大规模数据集时,这种“一次一个”的模式效率极低,因为我们需要对海量数据重复执行完全相同的操作,这暴露了标量处理的瓶颈。为了打破这个瓶颈,现代CPU集成了SIMD(单指令,多数据)架构。CPU增加了能容纳多个数据元素的宽向量寄存器(如256位的YMM寄存器),以及能够并行处理这些数据的执行单元。比如cpu可以同时进行4对double的加法运算(256位的寄存器, 256/64=4),为了加速多媒体和科学计算,Intel不断引入更强大的SIMD指令集,从MMX的64位 -> SSE的128位 -> AVX的256位 -> AVX-512的512位。但是SIMD偏硬件底层,编程不友好
- 手动打包解包向量
- 手动处理if else逻辑
为了解决编程不友好的问题,NVIDIA提出SIMT(Single Instruction, Multiple Threads)。SIMT是CUDA编程的基石,是GPU从一种处理图形计算的专用硬件,进化为GPGPU的基础。具体实现简单来说就是:同一时刻,Warp调度器只发布一条指令,后端仍然以SIMD的模式执行,而具体哪些线程执行依赖活动掩码控制。PS: SIMT通过线程编程模型隐藏了底层SIMD的执行细节
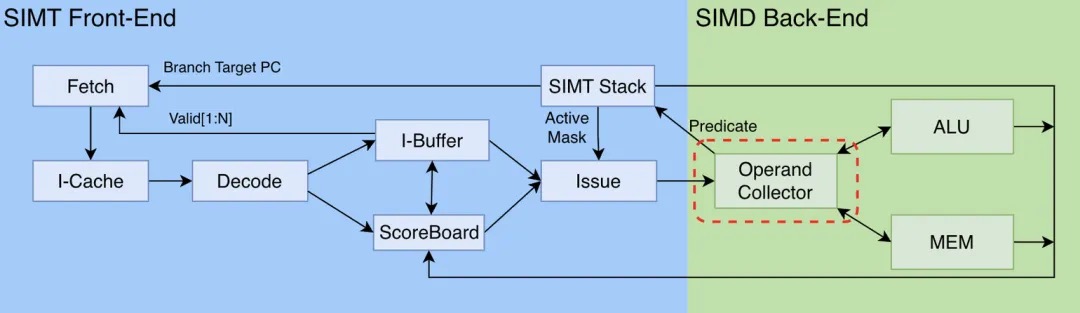
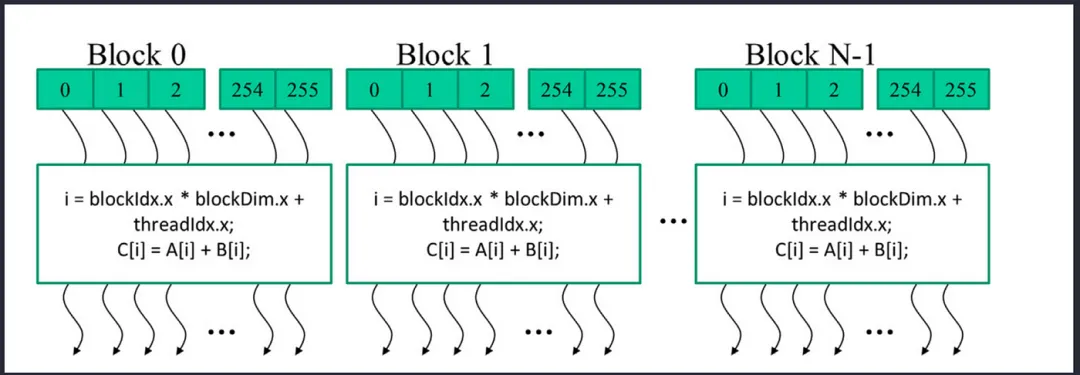
SIMT巧妙的隐藏了SIMD的复杂性,程序员只需要思考单个线程的逻辑,大大降低了心智负担。比如,如下代码每个thread都执行相同的代码,但是由于每个thread都会计算出特有的index,所有其实都在处理不同的数据。
int i = blockIdx.x * blockDim.x + threadIdx.x;
C[i] = A[i] + B[i];
Warp Divergence:每个Warp中的32个线程必须同步的执行相同的指令序列(SIMT是基于Warp的SIMD),这就导致在处理if-else时,GPU需要串行执行每个分支,导致算力浪费。在Pre-Volta架构中,一个Warp(32个线程)共享同一个程序计数器(PC)。这意味着它们在代码中的位置必须时刻保持一致。由于硬件需要串行执行不同的代码分支,导致一部分线程在另一部分执行时只能空闲(Stall),造成了严重的并行效率损失。Warp具体是怎么处理分支逻辑的呢? 利用SIMT Stack记录所有可能执行路径的上下文,遇到分支时,通过活动掩码标记需要执行的活跃线程。当前分支执行完时,硬件会去检查SIMT Stack是否还有其他可执行分支。最终所有分支执行完成后,在汇合点(Reconvergence Point)恢复Warp中所有线程的执行。这里有个问题,如上图,如果执行B的时候因为等待内存而暂停时,有没有可能切到另外一个分支执行X;Thread层面的隐藏延迟?在Pre-Volta架构中,答案是不能。因为整个Warp共享一个程序计数器和状态,需要为每个线程配备独立的程序计数器(PC)和栈(Stack)。
Volta及后续架构为每个线程配备独立的程序计数器(PC)和栈(Stack)。但是在任何时刻,Warp调度器还是只发布一条指令,即指令缓存(I-Cache)、指令获取单元(Fetch)、指令解码单元(Decode)都是Warp级别共享的。这意味着,尽管线程拥有独立的PC,但一个Warp内的线程不能在同一时钟周期执行不同的指令。为什么不能让一个Warp中的32个线程在同一时刻执行32条不同的指令? MIMD,multiple instruction, multiple thread, 恭喜你发明了多核cpu架构。GPU的定位就是并行计算,没必要搞MIMD;另外这样搞导致硬件成本和功耗成本都大幅提升。算是硬件效率与执行灵活性的一个trade-off。这样Volta及后续架构,在Warp调度器同一时刻只发布一条指令的情况下,利用独立程序计数器(PC)和活动掩码(Active Mask)就可以实现智能调度。硬件通过在不同周期、用不同的“活动掩码”来执行不同的指令,巧妙地”编织”出了多线程独立执行的假象。说白了,就是当一个Warp中的某些线程因为等待内存操作而暂停时,调度器可以切换执行同一个Warp下的其他线程,从而实现所谓的“线程级延迟隐藏”。实际上,这样也难以避免Warp Divergence导致的算力浪费,只是通过thread层面的隐藏延迟减少了部分因等待内存而导致算力浪费。这里值得一提的是,独立PC和Stack的引入同时也解决Pre-Volta架构可能会死锁的问题。(Pre-Volta架构由于其刚性的SIMT执行模型,在处理Warp内部分线程依赖另一部分线程的场景时,易产生死锁)
cuda graph
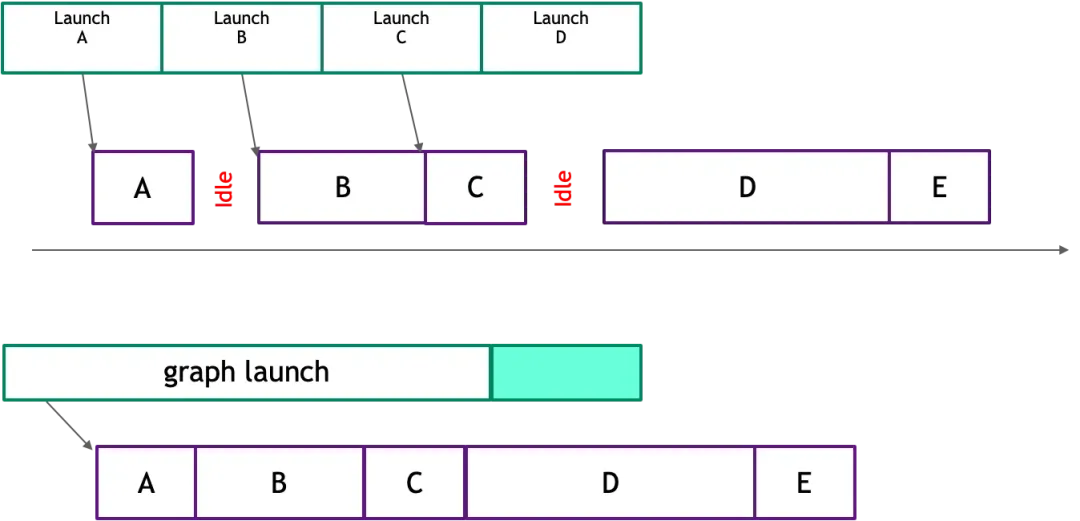
在 GPU 编程模型中,CPU 和 GPU 是异构的,CPU 通过 API(例如 CUDA API) 向 GPU 提交任务,然后异步等待 GPU 的计算结果返回。GPU 收到任务后,会执行内核启动、内存拷贝、计算等操作。这个过程中,涉及到 CPU 与 GPU 之间的通信、驱动程序的处理以及 GPU 任务的调度等环节,会产生一定的延迟。模型推理需要执行大量重复的 GPU 操作,每个的 GPU 操作都要重复执行上诉环节,这些非核心的 GPU 开销会成倍数地放大,影响最终响应时间。在传统后台服务,我们使用 Redis 的 Lua 脚本封装多个 Redis 操作和计算逻辑,一次提交,减少网络开销。与之相似,AI Infra 利用 CUDA Graph 技术将多个 GPU 操作转化为一个有向无环图(DAG),然后一次性提交整个 DAG 提交到 GPU 执行,由GPU自身来管理这些操作的依赖关系和执行顺序,从而减少 CPU 与 GPU 之间的交互开销。
与pytorch 的关系
PyTorch 提供了高级的张量运算接口(Python 层),比如:
y = x * 2
z = x @ W
loss.backward()
这些操作并不会在 Python 里计算,而是被翻译成调用 底层的 C++/CUDA 实现:
- 常见算子(加减乘除、矩阵乘、卷积、归约等)已经用CUDA写好了 kernel(kernel 源码大多在 ATen 库里)。
- 复杂算子(矩阵乘、卷积、BatchNorm、softmax):PyTorch 调用 NVIDIA 库(cuBLAS、cuDNN、cuSPARSE…),这些库本身提供了高度优化过的 CUDA kernel。
CUDA kernel = 预先实现好的核函数,核心就是一个
__global__函数,用kernel<<<grid, block>>>()的方式启动。可以说:PyTorch 是 CUDA kernel 的调度器,帮你选合适的 kernel 并启动。训练过程 = 不停地给 GPU 发 kernel 执行指令,GPU 内部再通过 Grid → Block → Warp → Thread 把计算跑完。Python 端只触发 kernel 启动,不会等它算完;GPU 是异步执行的,CPU 马上就返回继续跑 Python;只有遇到 y.cpu() 或 y.item() 这种需要数据回主机时,才会强制同步等待 GPU 完成。
矩阵计算优化(没太懂)
GPU存储可分为物理内存(硬件真实存在的)和逻辑内存(由cuda做抽象的)。 为什么要这么分呢?因为各个GPU的物理内存架构是不一样的,如果你写代码时还要考虑每个GPU的独特性,那可太痛苦了。所以cuda在这里帮了大忙:它对内存架构做了一层抽象,你只要按照它抽象后的框架写代码就可以。
每个thread占用一个SP(cuda core),即1个warp会占用1个SM上的32个SP。 有了这些前置知识,现在我们可以来看cuda矩阵优化的过程了。 假设矩阵
- A = (M,K) = (512,512)
- B = (K,N) = (512,512)
- C = AB = (M,K) * (K,N) = (512,512)
每个thread负责读取A矩阵的一行和B矩阵的一列,去计算C矩阵的一个元素。则一共需要M*N个thread。 矩阵A和矩阵B都存储在global memory,每个thread直接从global memory上进行读数,完成计算:
- 为了计算出C中的某个元素,每个thread每次都需要从global memory上读取A矩阵的一行(K个元素),B矩阵的一列(K个元素),则每个thread从global memory上的读取次数为2K
- C中共有M*N个thread,则为了计算出C,对global memory的总读取次数为: 2MNK
Naive GEMM的代码见下(完整代码见 sgemm_naive.cu ):
// 将二维数组的行列索引转成一维数组的行列索引,这样可以更高效访问数据
// row, col:二维数组实际的行列索引,ld表示该数组实际的列数
// 例:二维数组实际的行列索引为(1, 3),即第二行第四个元素,二维数据的总列数 = 5
// 返回的一位数组形式的索引为: 1*5 + 3 = 8
#define OFFSET(row, col, ld) ((row) * (ld) + (col))
// 定义naive gemm的kernel函数
__global__ void naiveSgemm(float * __restrict__ a, float * __restrict__ b, float * __restrict__ c, const int M, const int N, const int K) {
// 当前thread在C矩阵中的row
int m = blockIdx.y * blockDim.y + threadIdx.y;
// 当前thread在C矩阵中的col
int n = blockIdx.x * blockDim.x + threadIdx.x;
if (m < M && n < N) {
float psum = 0.0;
// 告知编译器自动展开循环体,这样可以减少循环控制的开销(循环次数小的时候可以这么做)
#pragma unroll
// 取出A[row]和B[col],然后逐个元素相乘累加,得到最终结果
for (int k = 0; k < K; k++) {
// a[OFFSET(m, k, K)]: 获取A[m][k]
// b[OFFSET(k, n, N)]: 获取B[k][n]
psum += a[OFFSET(m, k, K)] * b[OFFSET(k, n, N)];
}
c[OFFSET(m, n, N)] = psum;
}
}
const int BM = 32, BN = 32;
const int M = 512, N = 512, K = 512;
dim3 blockDim(BN, BM);
dim3 gridDim((N + BN - 1) / BN,(M + BM - 1) / BM);
GPU/CUDA/驱动和机器学习训练框架的关系

显卡是硬件,硬件需要驱动,否则不能调用其计算资源。CUDA又是什么?
- 在2007年之前,GPU由CPU操作,CPU把一些图形图像的计算任务交给GPU执行。程序员不需要与GPU打交道。随着GPU计算能力的发展,越来越多的计算场景由GPU完成效果会更好。但现有的程序无法直接自由控制GPU的处理器。当然程序员也可以直接写代码与显卡驱动对接,从而直接控制GPU的处理器,但这样代码恐怕写起来要让人疯掉。nvidia当然会有动力提供一套软件接口来简化操作GPU的处理器。nvidia把这一套软件定义为CUDA。
- 多核 CPU 和众核 GPU 的出现意味着主流处理器芯片现在是并行系统。挑战在于开发能够透明地扩展可并行的应用软件,来利用不断增加的处理器内核数量。CUDA 并行编程模型旨在克服这一挑战,同时为熟悉 C 等标准编程语言的程序员保持较低的学习曲线。CUDA 编程手册系列第一章:CUDA 简介
gpu 和 cuda 和 gpu driver 之间的关系:比如 TX3090需要Compute Capability在8.6以上的cuda,而满足这个要求的cuda又只有11.0以上的版本。而cuda11版本又需要版本号>450的显卡驱动。
显卡
==> Compute Capability 查看显卡支持的Compute Capability, https://developer.nvidia.com/cuda-gpus
==> cuda
==> GPU driver 查看cuda对驱动的要求 (https://docs.nvidia.com/cuda/cuda-toolkit-release-notes/index.html
==> tf/pytorch version
Compute Capability的数值和GPU的计算速度无关,但是和GPU可执行的任务种类有关。The compute capability of a device is represented by a version number, also sometimes called its “SM version”. This version number identifies the features supported by the GPU hardware and is used by applications at runtime to determine which hardware features and/or instructions are available on the present GPU.
从模型到算子,以卷积计算为例
- 从卷积到矩阵乘 将输入数据(Feature Map)和卷积核数据进行重排,卷积操作本质上可以等效理解为矩阵乘操作。卷积操作的过程大概可以描述为按照约定的窗口大小和步长,在 Feature Map 上进行不断地滑动取数,窗口内的 Feature Map 和卷积核进行逐元素相乘,再把相乘的结果累加求和得到输出 Feature Map 的每个元素结果。
- 矩阵乘分块 Tilling。卷积转换后的矩阵乘的维度非常大,而芯片里的内存空间往往是有限的(成本高),表现为越靠近计算单元,带宽越快,内存越小。为了平衡计算和内存加载的时间,让算力利用率最大化,AI 芯片往往会进行由远到近,多级内存层级的设计方式,达到数据复用和空间换时间的效果。根据这样的设计,矩阵乘实际的数据加载和计算过程将进行分块 Tilling 处理。Tiling(平铺)是一种优化技术,它涉及将大的矩阵分解成更小的块或“瓦片”(tiles),这些小块的大小通常与CPU或GPU的缓存大小相匹配,以便可以完全加载到缓存中。
- 矩阵乘的库。矩阵乘作为 AI 模型中的重要性能算子,CPU 和 GPU 的平台上都有专门对其进行优化实现的库函数。比如 CPU 的 OpenBLAS, Intel MKL 等,GPU 的 cuBLAS, cuDNN 等。实现的方法主要有 Loop 循环优化 (Loop Tiling)和多级缓存 (Memory Hierarchy)。
- 矩阵乘的优化。在具体的 AI 芯片或其它专用芯片里面,对矩阵乘的优化实现主要就是减少指令开销,可以表现为两个方面:
- 让每个指令执行更多的 MACs 计算。比如 CPU 上的 SIMD/Vector 指令,GPU 上的 SIMT/Tensor 指令,NPU 上 SIMD/Tensor,Vector 指令的设计。
- 在不增加内存带宽的前提下,单时钟周期内执行更多的 MACs。比如英伟达的 Tensor Core 中支持低比特计算的设计,对每个 cycle 执行 512bit 数据的带宽前提下,可以执行 64 个 8bit 的 MACs,大于执行 16 个 32bit 的 MACs。
cuda 之后
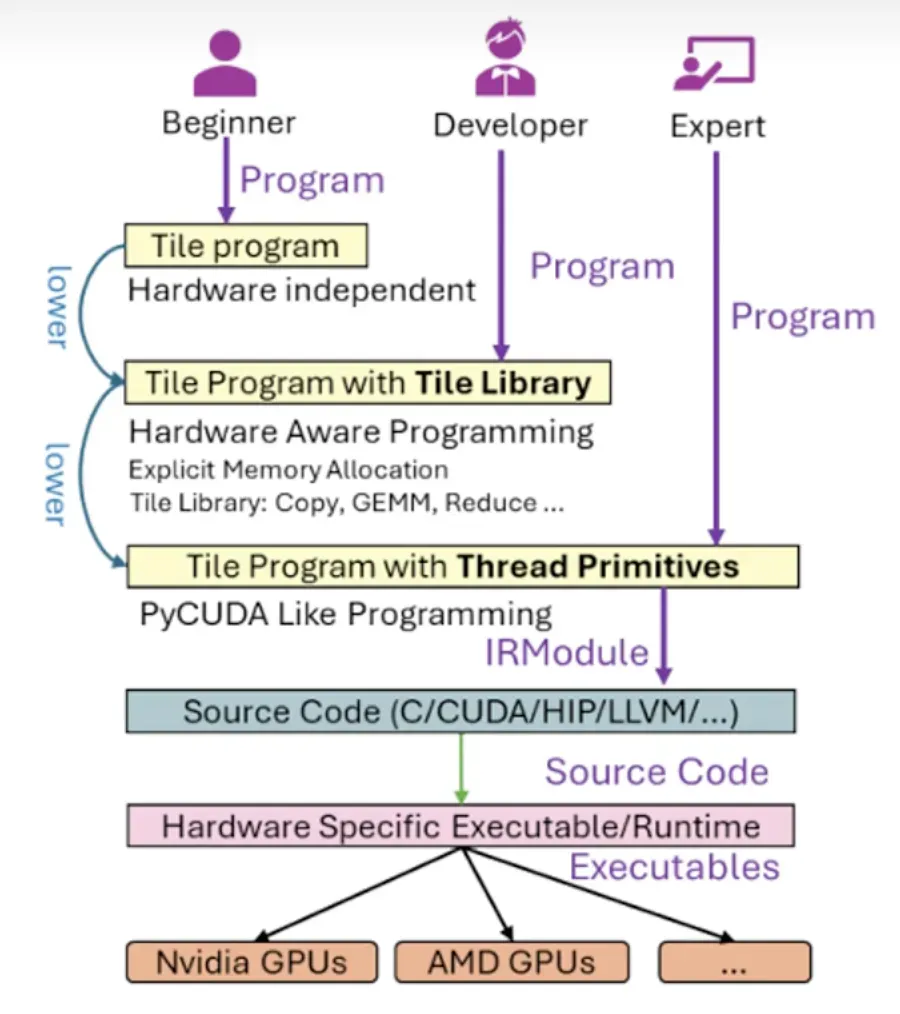
高性能训练or推理的内核或算子优化往往是一件很精细化的工作,要精确定义thread、block、grid如何调度,或各种规格硬件的的tensor计算核心如何使用,以及各级缓存如何访问。传统的优化与加速方式都是针对硬件特性的精细化设计+复杂的调优手段来实现的,这些复杂的工作的核心目的还是如何更加高效的处理数据,来提升算子或模型整体的效率。那么是否可以有一种开发语言,让开发者仅聚焦于数据流的开发,而不用过多关注更加底层的精细化调度呢?TileLang这个开发语言由TileLang这篇同名论文提出,是一种将数据流与调度逻辑彻底解耦:让开发者只需专注于数据流逻辑,而调度策略交由编译器完成,达到以更简洁的代码表达复杂计算,并获得最优性能的效果。TileLang也提供了三个层级的编程方式,来满足不同层级的开发者:
- 入门版:仅描述数据块和计算逻辑,其余硬件实现细节和优化全部由编译器完成。hardware independent
- 进阶版:在入门级的基础上,除了描述数据库和计算逻辑,可以调用一些封装的算子,兼顾开发效率和灵活性
- 精细版:可以进行精细化的线程级开发,适用于极致性能优化场景。
同时也支持几种层级混合使用。
留下评论