《用户增长》笔记
简介
从开发视角看数据分析 精细化运营的一个典型案例。
什么叫用户增长?以终为始,利用一切资源让更多用户更高频的使用核心产品功能。
- 更多
- 更高频
- 核心产品功能,虽然大家平时经常说拉新、促活, 但如果用户在使用某个产品时没有体验到该产品的核心产品功能,这对产品而言绝对是一个损失,对用户而言也没有意义。
如何做用户增长?
用户增长的本质是通过数据驱动的迭代测试把主观认知变成客观认知(PS:从感觉有用变成数据上的成果),用测试的冗余性换取增长的确定性。如果不能实现快速迭代测试,是无法形成增长势能的。靠提需求、走产研、大排期,是不可能实现快速迭代测试的,必须要有一定的组织保障。
自然界的进化其实也是这样的,用基因变异的冗余性来换取进化的确定性。生物基因会发生各种突变,最终有利于生存的基因被遗传下来,从而促进生物的不断进化。要是没有这种冗余的突变,生物的进化一定不会像今天这样。要想用冗余性来对抗不确定性,就要多次尝试低概率的事儿,这是一个基本规律。
增长项目的类型
- 漏斗型增长,把用户在产品中的体验流程拆分为一个个细小的环节,通过优化每个环节的转化效率,提升用户整体的LTV
- 功能型增长,给产品增加某个功能,从来带来用户的增长和活跃。
- 策略型增长,以给用户发Push为例,让BI 分析下用户数据,形成一些用户标签或画像,给部分用户发某种类型的消息,不断测试,就能找到一部分特别适合推送某种消息的用户。还可以进一步把这一策略自动化,积累足够多的用户,足够多的个性化内容,再把两者配对。以红包车功能为例,功能只是一个外壳,真正带来无限可能和想象力的是实时调整的红包策略(什么场景、什么人拿的红包多),这是靠人力来实现迭代的,但这种迭代比改产品功能要容易很多。
- 整合型增长,线上与线下一起构成一个完整的体验闭环。
针对平常就爱分享的KOL用户,尤其是那些分享后还能带来很多用户点击的KOL用户,要提升他们的中奖概率。
用户增长基本方法论
在把用户拉进一个产品生态后,用户增长团队的主要工作就是提升用户LTV。如果该团队面对的业务是交易类的,那就是要想办法让用户多下订单,从而产生更多的GMV;如果面对的是广告变现类业务,那就要增加用户的在线时长和PV。
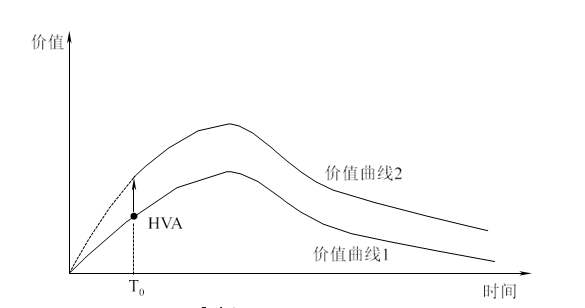
假设有一个电商平台“货最美”,有个叫小美的用户经常在上面买衣服,她对平台的价值贡献符合曲线1。货最美除了很多衣服,还有很多3C产品, 货最美的用户增长人员经过数据分析, 发现一旦用户在平台上发生过3C产品的购买行为,后续一般都会复购。也就是说,如果小美产生一次3C 购买行为, 小美对平台的价值贡献就会从价值曲线1跃迁到价值曲线2,让小美第一次购买3C产品就是一个典型的HVA。一般比较常见且比较有效地方式就是给小美发一张货最美3C品类的折扣券。此外,还可以物质激励与内容运营相结合,前期给小美推送一系列消息,例如“网上买东西不能被骗”(灌输识别3C正品的方式),“购买哪家在线商品不用担心售后”,这些前期内容的推送可以让小美不断在心中对货最美的3C产品产生认可。
一个收获:要能计算用户价值, 这样你就知道投入多少钱来拉新。如果你的app 有多个价值点,要能计算不同价值点的用户价值,这样你就知道投入多少钱来发放“优惠券”来引导用户从一个价值点走向另一个价值点。在决定优先引导用户产生哪个HVA时,需要在HVA价值、补贴成本、实现难易度之间做一个平衡。
对用户HVA的引导,其实质就是对用户生命周期的管理。既然是对用户整个生命周期的管理,那从新用户进入的第一天开始,就要对他们进行正向引导,直到他们离开我们的产品。例如在用户激活以后,我们是否有合适的新手护航策略来引导他们一步步沿着HVA链条往下走。
用慢思考来设计引导用户产生HVA的快思考产品逻辑:做各种用户增长的相关功能,其核心是引导用户产生我们期望的决策,从而产生我们期望的行动。所以我们需要对大脑的决策机制做深入了解,利用一些经典的决策理论来指导我们设计相应的增长逻辑。丹尼尔.卡尼曼在《思考,快与慢》一书中提出了广为认知的双系统理论,介绍了系统1和系统2的概念,系统1是快思考,它的运作是快速、无意识的,就像条件反射。系统2是慢思考,需要我们耗费大量脑力去专注思考,我们的大脑通常不倾向于用系统2来解决问题。从进化的角度看,为了生存繁衍,我们一般都会尽可能让自己处于低功耗状态。
很多时候,我们的大脑通过启发性思考,直接调用系统1,以减轻我们的认知负担,降低能量消耗。启发性思考的本质就是想办法让遇到的新问题符合大脑中存储的一些加工规则,一旦这些新问题找到匹配的加工规则,我们就能快速利用现有加工规则来处理已知数据并得出结论。如果找不到匹配的加工规则,我们就要调用系统2来思考。我们究竟调用系统1 还是系统2,是受信息呈现方式影响的。比如政府公布了购房贷款利息的减税政策,从购房者的角度说,这肯定是一件好事,但租房者不能享受这种减税优惠,相当于对“租房者的罚金”。“房屋抵押贷款应该享受税收优惠吗?” 比“应该让租房者缴纳更多赋税吗?” 更容易让大家认可这个政策。
如何才能设计出相关的页面和功能,让用户运用快思考流畅的按照我们设想的步骤一步步产生HVA呢?这就需要我们调动慢思考,设计信息呈现框架。有一些原则可以遵循
- 引导用户产生强烈情感,强烈的情感会遮蔽系统2
- 默认选项引导
- 先寸后尺
- 欲取先予——引发损失厌恶
- 创造认知引力场
如何搭建用户增长中台
很多时候,我们觉得只要能找到做增长的优秀人才,就能马上实现可观的增长。但实际上,用户增长是一个系统性工程,如果缺乏必要的基础能力,再厉害的增长专家也会到处被掣肘,难以发挥自己的能力
- AB测试
- 流量控制平台
- 激励券营销系统
- LTV计算跟踪系统
增长中台在获取平台用户的过程中,要遵守两个原则
- 如果能把钱给到用户,就尽量不要给渠道、流量平台或广告公司
- 如果能给主业优惠券,就尽量不要给红包等现金激励
曲哓音:增长的核心在于减少用户阻力,减少阻力的三个办法
- 自动完成
- 告诉用户他们会失去什么
- 聪明的整合
其它
增长那些事儿增长力=价值力* 价值传递效率 * 覆盖群体量*场景频度。价值决定了客户能够感知到的价值,它是增长的基础; 价值传递效率、覆盖群体量与场景频度决定了事物的增长空间,我们做增长和产品,不能站在自己的视角自High,我们往往做了一个自认为很有价值的产品(经过市场调研能覆盖大量的用户,场景也足够高频),但客户感觉不到产品的价值,这样的结果也是增长无力。
做决定的过程就是发散与收敛,一个决定做得好不好,关键看发散和收敛这两步做的质量。
- 发散:尽可能挖掘更多的情景和信息。我们可以从”痛点、痒点、爽点”这个方面进行发散,他们都可能是产品的机会点,都有可能成为对用户有价值的东西。
- 收敛:用有效的逻辑从发散的信息收敛出结论。
- 一是看受众规模,受众规模决定了一个事物能够发展的规模,比如综合性的电商网站的增长空间一定比垂直类的网站大。如果我们找到的机会点的受众规模很小,这样的可以大胆排除。
- 二看场景频度,:频度是判断一个机会点是否有增长空间的很重要的因素,比如女装的市场要比男装大得多,是因为女性换衣服的频率要大得多,大家去商场里也可以关注下,女装的店也多很多。做增长我们都要关注LTV(Long Time Value),当LTV大于获客成本时,这个产品才可能做下去。
- 三反向验证:反向验证就是我们将收剑得到的结论去找用户验证,问下他们在生活中、工作中是否有这样的问题,如果有对应的产品来解决他们的这些问题,他们感觉如何。
当我们通过前面发散、收剑、反向验证找到了一些可能的价值点后,我们开始进行产品化,我们开发后会推向市场,拿到市场上去验证,但如果确认一个产品是否成功呢,我们需要有个指标来度量,比如APP的日活、成交的GMV,定单量。一个业务发展过程中会有多个部门相互协同,不同的部门的自己的关注的指标,有时不同指标会相互打架,但整个业务需要一个北极星指标(唯一的关键性)来指引,否则大家会迷失在错综复杂的指标里。值得一提的北极星不是永远不变的,这个会随着业务的发展会发生变化的。
我们要衡量产品的一个变动对于业务的影响,需要有一个有效的度量方式,这个绝对不能主观判断,人经常会高估自己的主观判断,用《原则》的作者,桥水基金创始人达里欧的话来说:“做一个无比现实的人”。最为科学的方式就是通过实验的方式来进行。
小的增长机会靠上面的方法论可以找到,但要找到大的增长机会,需要提升知识与认识结构,看历史,所谓借古鉴今。要得到更快的增长需要从组织能力、行业创新、生态赋能等方面来做增长,要实现产品的增长,需要有三级火箭
- 搭建高频的头部流量,第一级火箭是高频的应用,三级火箭是依次递推,一定是高频推低频。这一级火箭只是助推器,自身可以不考虑变现,它是为后面的商业化场景的落地打前锋的,现实的互联网有很多这样的例子。
- 沉淀用户的商业场景,这个商业化场景需要实现用户的价值,客户留下来是因为客户对这个场景有依赖,或者说这个依赖的替代成本比较高,所以我们,否则用户无法沉淀下来,后面就不可能有构建商业的闭环。
- 实现商业的闭环。
阿里国际站用户增长技术探索与实践 未读。对比了B端和C端增长的异同。
留下评论