golang性能分析及优化
前言
我们或许都有这样的体会,自己思考明白,设计出来的程序,可以很清晰明了的将细节解释明白,对功能的增删改也是可以做到灵活应对。可是让我们一下子去修改别人写的功能或模块的时候,很多时候会一脸懵逼,这也不敢动,那也不敢动,在不理解的情况下,有疑问,一定要问清楚原理和逻辑,否则搞不好就是线上问题。如上情况,最重要的一个原因就是自己对当前模块/功能的熟悉程度,以及自己的思维模型是否可迁移。
性能优化流程
阿姆达尔定律指出,性能优化要找出全链路中真正有性能瓶颈的地方,找出哪些无法并行,或者最耗时的串行部分。
- 理清待优化代码的常用逻辑与场景
- 根据实际场景编写压测用例
- 使用pprof 或者火焰图等工具取得数据
- 找到热点代码重点优化
监控不仅要关注均值,也要留意尾部情况,比如 P95 甚至 P99,正常监控是分钟级平均数,偶尔几百毫秒毛刺被分母均摊后“消失”。进而监控指标看起来都正常,但偶尔就有那么几个用户页面刷新会慢一些。因为无法复现,很多时候会归为网络抖动而被忽略。
Profiling
pprof 是用于可视化和分析性能分析数据的工具。为什么pprof可以帮助我们分析Go程序性能呢?因为它可以采集程序运行时数据:比如说协程栈,这样服务阻塞在哪里是不是一目了然了;比如说内存分配情况包括调用栈,这样哪里耗费内存也清楚了。有两种类型的 profiler :
- 追踪型:任何时候触发提前设定的事件就会做测量,例如:函数调用,函数退出,等等
- 采样型:常规时间间隔做一次测量
Go CPU profiler 是一个采样型的 profiler。也有一个追踪型的 profiler,Go 执行追踪器,用来追踪特定事件像请求锁,GC 相关的事件,等等。
采样型 profiler 通常包含两个主要部分:
- 采样器:一个在时间间隔触发的回调,一个堆栈信息一般会被收集成 profiling data。不同的 profiler 用不同的策略去触发回调。
- 数据收集:这个是 profiler 收集数据的地方:它可能是内存占用或者是调用统,基本上跟堆栈追踪相关的数据
Profiling 这个词比较难翻译,一般译成画像。比如在案件侦破的时候会对嫌疑人做画像,从犯罪现场的种种证据,找到嫌疑人的各种特征,方便对嫌疑人进行排查;还有就是互联网公司会对用户信息做画像,通过了解用户各个属性(年龄、性别、消费能力等),方便为用户推荐内容或者广告。在计算机性能调试领域里,profiling 就是对应用的画像,这里画像就是应用使用 CPU 和内存的情况。也就是说应用使用了多少 CPU 资源?都是哪些部分在使用?每个函数使用的比例是多少?有哪些函数在等待 CPU 资源?知道了这些,我们就能对应用进行规划,也能快速定位性能瓶颈。
CPU Profiling 是如何工作的?stack trace + statistics 的模型。当我们准备进行 CPU Profiling 时,通常需要选定某一时间窗口,在该窗口内,CPU Profiler 会向目标程序注册一个定时执行的 hook(有多种手段,譬如 SIGPROF 信号),在这个 hook 内我们每次会获取业务线程此刻的 stack trace。我们将 hook 的执行频率控制在特定的数值,譬如 100hz,这样就做到每 10ms 采集一个业务代码的调用栈样本。当时间窗口结束后,我们将采集到的所有样本进行聚合,最终得到每个函数被采集到的次数,相较于总样本数也就得到了每个函数的相对占比。借助此模型我们可以发现占比较高的函数,进而定位 CPU 热点。
Heap Profiling 也是stack trace + statistics 的模型。数据采集工作并非简单通过定时器开展,而是需要侵入到内存分配路径内,即直接将自己集成在内存分配器内,当应用程序进行内存分配时拿到当前的 stack trace,最终将所有样本聚合在一起,这样我们便能知道每个函数直接或间接地内存分配数量了。由于 Heap Profiling 也是采样的(默认每分配 512k 采样一次),所以展示的内存大小要小于实际分配的内存大小。同 CPU Profiling 一样,这个数值仅仅是用于计算相对占比,进而定位内存分配热点。
如何看懂火焰图(以从下到上为例)
如何看懂火焰图火焰图的调用顺序从下到上,每个方块代表一个函数,它上面一层表示这个函数会调用哪些函数,方块的大小代表了占用 CPU 使用的长短。火焰图的配色并没有特殊的意义,默认的红、黄配色是为了更像火焰而已。
- 每一列代表一个调用栈,每一个格子代表一个函数
- 纵轴/Y轴展示了栈的深度,按照调用关系从下到上排列。最顶上格子代表采样时,正在占用 cpu 的函数。
- 横轴/X轴的意义是指:火焰图将采集的多个调用栈信息,通过按字母横向排序的方式将众多信息聚合在一起。需要注意的是它并不代表时间。
- 横轴格子的宽度代表其在采样中出现频率(不会直接显示每个方法执行耗时),但是可以通过相对宽度,估算大概耗时,所以一个格子的宽度越大,说明它是瓶颈原因的可能性就越大。但上述也仅是能大概估算,如果仔细想想,就能分析出一些例外。火焰图默认采样是 On-CPU 时间,如果是 IO 操作,其实是 Off-CPU。这种情况下,即便宽度很窄,也不能直接得出不耗时结论。此时,可以借助 wall(Wall-clock Time)挂钟时间模式,实际耗费时间,除 CPU 实际占用,还包括各种等待时间(本身不占 CPU 分片,处于休眠或等待状态,但是会影响最终耗时),比如网络 I/O、磁盘 I/O、同步阻塞(synchronized)等耗时。所以日常使用时,要明确排查问题是 CPU 利用率高,还是耗时长。
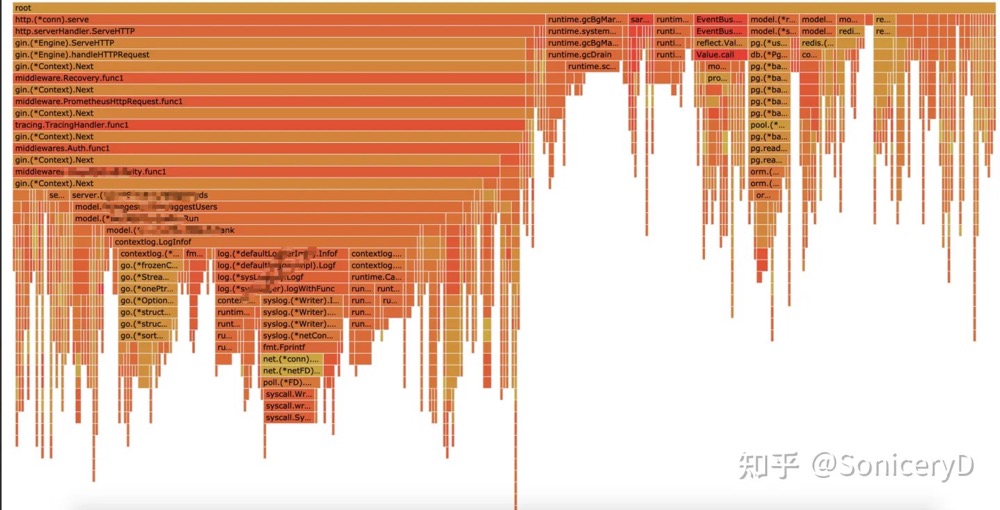
总的来说
- 颜色本身没有什么意义(默认情况下,颜色通常是随机的,只是为了区分不同的函数矩形)
- 水平顺序(从左到右)没有意义(火焰图会将函数名按字母顺序排序,所以两个相邻的矩形,不代表它们在时间上有先后调用关系)
- 纵向表示调用栈的深度
- 横向表示消耗的时间
为什么 perf 火焰图看不到 Java 调用栈?Java 运行过程并不像其他 AOT 编译语言比如 C++,有一个显现编译过程(或者更准确说法是,没有一个显现编译成可执行机器码的过程,javac 解释执行之后,得到中间产物 class 文件,真正编译成机器码是由 JIT 完成,等于是解释器 + JIT 模式),在 make 之后产生 ELF 文件,其中就包括符号映射表,而 perf 采样得到内存地址,这种情况下,它会通过映射表反查符号,从而得到具有可读性的火焰图。Java 是通过 JIT,在运行阶段编译,满足一定条件后保存在 CodeCache 中。这种情况下,perf 就无法反向映射回符号,所以看到的往往是二进制地址,除少量 JVM 相关调用(本质 JVM 是 C++ 编写)可以看到符号,如 libjvm.so。perf-map-agent 作为切在 JIT 编译过程的临时进程,注册 JIT 编译事件回调,记录得到符号映射表。async-profiler 是更高一层封装,可以更方便地得到 Java 进程内部 CPU 火焰图,而 Arthas 火焰图相关能力是基于 async-profiler 实现。
实操
import (
... ...
"net/http"
_ "net/http/pprof" // 会自动注册handler到http server,方便通过http 接口获取程序运行采样报告
... ...
)
... ...
func main() {
go func() {
http.ListenAndServe(":6060", nil)
}()
... ...
}
以空导入的方式导入 net/http/pprof 包,并在一个单独的 goroutine 中启动一个标准的 http 服务,就可以实现对 pprof 性能剖析的支持。pprof 工具可以通过 6060 端口采样到我们的 Go 程序的运行时数据。然后就可以通过 http://192.168.10.18:6060/debug/pprof 查看程序的采样信息,但是可读性非常差,需要借助pprof 的辅助工具来分析。
// 192.168.10.18为服务端的主机地址
$ go tool pprof -http=:9090 http://192.168.10.18:6060/debug/pprof/profile?seconds=30
Fetching profile over HTTP from http://192.168.10.18:6060/debug/pprof/profile
Saved profile in /Users/tonybai/pprof/pprof.server.samples.cpu.004.pb.gz
Serving web UI on http://localhost:9090
实现
cpu采样
- 采样对象: 函数调用和它们占用的时间
- 采样率:100次/秒,固定值
- 采样时间:从手动启动到手动结束
深究 Go CPU profiler在Linux中,Go runtime 使用setitimer/timer_create/timer_settime API来设置SIGPROF 信号处理器。这个处理器在runtime.SetCPUProfileRate 控制的周期内被触发,默认为100Mz(10ms)。一旦 pprof.StartCPUProfile 被调用,Go runtime 就会在特定的时间间隔产生SIGPROF 信号。内核向应用程序中的一个运行线程发送 SIGPROF 信号。由于 Go 使用非阻塞式 I/O,等待 I/O 的 goroutines 不被计算为运行,Go CPU profiler 不捕获这些。顺便提一下:这是实现 fgprof 的基本原因。fgprof 使用 runtime.GoroutineProfile来获得等待和非等待的 goroutines 的 profile 数据。
一旦一个随机运行的goroutine 收到 SIGPROF 信号,它就会被中断,然后信号处理器的程序开始运行。被中断的 goroutine 的堆栈 在这个信号处理器的上下文中被检索出来,然后和当前的 profiler 标签一起被保存到一个无锁的日志结构中(每个捕获的堆栈追踪都可以和一个自定义的标签相关联,你可以用这些标签在以后做过滤)。这个特殊的无锁结构被命名为 profBuf ,它被定义在 runtime/profbuf.go 中,它是一个单一写、单一读的无锁环形缓冲 结构,与这里发表的结构相似。writer 是 profiler 的信号处理器,reader 是一个 goroutine(profileWriter),定期读取这个缓冲区的数据,并将结果汇总到最终的 hashmap。这个最终的 hashmap 结构被命名为 profMap,并在 runtime/pprof/map.go中定义。PS:goroutine 堆栈信息 ==> sigProfHandler ==write==> profBuf ==read==> profWriter ==> profMap
heap 采样
- 采样程序通过内存分配器 在堆上分配和释放内存,记录分配/释放的大小和数量
- 采样率:每分配512KB 记录一次,可在运行开头修改,1为每次分配均记录。
- 采样时间:从程序运行开始到结束
- 采样指标:alloc_space,alloc_objects,inuse_space,inuse_objects
- 计算方式: inuse = alloc - free
goroutine
- 记录所有用户发起且在运行中的goroutine(即入口非runtime开头的)的调用栈信息
- runtime.main 的调用栈信息
- 采样方式:stop the world ==> 遍历 allg slice ==> 输出创建g的堆栈 ==> start the world ThreadCreate
- 记录程序创建的所有系统线程信息
- 采样方式:stop the world ==> 遍历 allm 链表 ==> 输出创建m的堆栈 ==> start the world
block
- 采样阻塞操作的次数和耗时
- 采样率:阻塞耗时超过阈值的才会被记录。1 为每次阻塞均记录
- 采样方式:阻塞操作 ==> Profiler 上报调用栈和消耗时间(时间未到阈值则丢弃) ==> 遍历阻塞记录 ==> 统计阻塞次数和耗时
锁竞争
- 采样争抢锁的次数和耗时
- 采样率:只记录固定比例的锁操作,1 为每次加锁均记录
- 采样方式:阻塞操作 ==> Profiler 上报调用栈和消耗时间(比例未命中则丢弃) ==> 遍历锁记录 ==> 统计锁竞争次数和耗时
trace
虽然CPU分析器做了一件很好的工作,告诉你什么函数占用了最多的CPU时间,但它并不能帮助你确定是什么阻止了goroutine运行。这里可能的原因:被syscall阻塞 、阻塞在共享内存(channel/mutex etc)、阻塞在运行时(如 GC)、甚至有可能是运行时调度器不工作导致的。这种问题使用pprof很难排查。
go tool trace 能够跟踪捕获各种执行中的事件,例如:
- Goroutine 的创建/阻塞/解除阻塞。
- Syscall 的进入/退出/阻止,GC 事件。
- Heap 的大小改变。
- Processor 启动/停止等等。

- 时间线: 显示执行的时间单元 根据时间的纬度不同 可以调整区间
- stats 区域
- 堆,显示执行期间内存的分配和释放情况(折线图)
- 协程(Goroutine),显示每个时间点哪些Goroutine在运行 哪些goroutine等待调度 ,其包含 GC 等待(GCWaiting)、可运行(Runnable)、运行中(Running)这三种状态。
- Threads,显示在执行期间有多少个线程在运行,其包含正在调用 Syscall(InSyscall)、运行中(Running)这两种状态。
- proc区域,虚拟处理器Processor:每个虚拟处理器显示一行,虚拟处理器的数量一般默认为系统内核数。数量由环境变量GOMAXPROCS控制。 分两层
- 上一层表示Processor上运行的goroutine的信息,一个P 某个时刻只能运行一个G,选中goroutine 可以查看特定时间点 特定goroutine的执行堆栈信息以及关联的事件信息
- 下一层表示processor附加的事件比如SysCall 或runtime system events
其它
Linux perf 使用 PMU(Performance Monitor Unit)计数器进行采样。你指示 PMU 在某些事件发生 N 次后产生一个中断。一个例子,可能是每 1000 个 CPU 时钟周期进行一次采样。一旦数据收集回调被定期触发,剩下的就是收集堆栈痕迹并适当地汇总。Linux perf 使用 perf_event_open(PERF_SAMPLE_STACK_USER,...) 来获取堆栈追踪信息。捕获的堆栈痕迹通过 mmap’d 环形缓冲区写到用户空间。
留下评论