大模型推理tips
简介
万字详解大模型推理加速核心原理:分形规律与资源计算公式 未细读
AI Infra 和传统 Infra 断代了吗?从表面看起来,AI Infra 确实和传统 Infra 很不一样
- 传统 Infra 处理的是 web request,数据存储,和分布式服务协调,而 AI Infra(特别是大模型)更多围绕的是 GPU 推理,KV Cache 管理,以及大模型训练框架等全新领域。
- 请求形态也不一样:web request通常是毫秒级的request,stateless,而 LLM 推理一个 session 往往持续数秒甚至更久(随着context window 和模型大小增加),还要动态维护 token-level 的上下文状态。
- tech stack 看起来也不同:传统用的是 Kubernetes + Docker,现在大家在用 GPU, vLLM, DeepSpeed, FlashAttention, Triton, NCCL 这些仅仅从名字上听起来就很高大上的架构。 本质其实没变,仍然是系统设计和资源调度的问题。回到工程本身,其实我们仍然在面对和传统 Infra 极其类似的问题:
- 如何调度资源(从CPU/内存 变成了 GPU 显存)
- 如何处理高并发请求(从http resource request ,变成了 prompt request) 拿 vLLM 举个例子:它像是给 LLM 写了一个操作系统,用来调度“页面”(KV Cache),管理“进程”(requests), 本质上是引用了OS 的内存管理principles用来管理 kv cache。
Infra 的“三大难题”:Scaling, Sharding, and Copying所有系统的底层挑战,基本都绕不开这三个关键词:
- Scaling(扩展):系统如何支持更大的规模和更高的并发?
- 在传统 Infra 中,这意味着如何横向扩展服务器,部署更多容器,使用负载均衡 (load balancing) 来分散请求
- 在 AI Infra 中,这些问题转化为如何通过 数据并行, 模型并行,流水线并行 来分布和执行 GPU workload,以支持超大模型的训练以及 large number of inference requests
- Sharding(切片):系统如何切分状态和计算,以实现并行处理?
- 在数据库系统中,这是将数据按照主键或范围切分到不同的分区,以支持高吞吐访问
- 在 AI Infra 中,sharding 变成了对模型参数,KV Cache,activation,gradients,以及optimizer states的split,比如tensor parallelism和KV paging等,是实现分布式推理和训练的前提
- Copying(复制):系统如何高效同步数据或状态?
- 传统系统中,复制体现在数据库副本同步或者缓存预热,以及Kafka Replication
- 在 AI Infra 中,复制的代价更加显著,比如data parallelism 怎么copy model to different GPUs(所以会有ZeRO optimization 来shard 参数,gradient 等等),通常需要依赖高性能通信机制(比如 RDMA和NCCL) 这些挑战的本质没有变:仍然是如何高效并且低成本地协调跨不同机器的资源。但在 AI Infra 中,由于gpu显存limited,large context window,以及模型参数量大,它们变得更加脆弱和重要,也更需要更好的工程策略去解决这些问题。
真正有经验的 Infra 工程师,不仅仅是能搭件一个working的系统,而是有能力去从头到尾追踪每一个延迟点,把系统之间的关联和可能存在的bottleneck拆解成一系列可量化的问题,并在上线后持续做 cost/performance profiling。这正是 AI Infra (或者传统 Infra)对工程基本功要求极高的原因。
基础
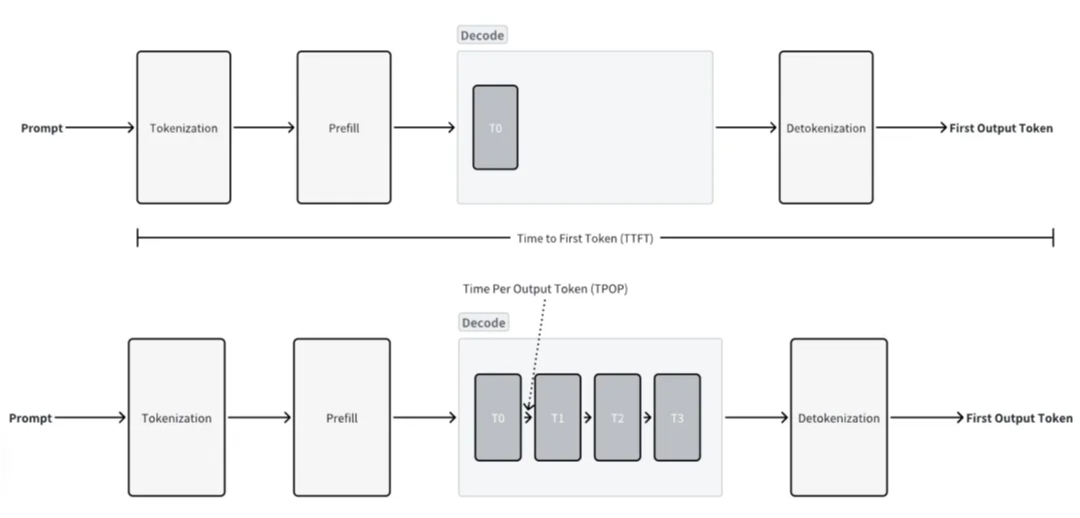
模型的计算过程
理解llama.cpp怎么完成大模型推理的LLM 通过每次迭代生成一个标记,然后将其添加到输入提示中,不断重复该过程,直到生成完整的输出。这就是 LLM 如何从输入提示生成文本的基础。
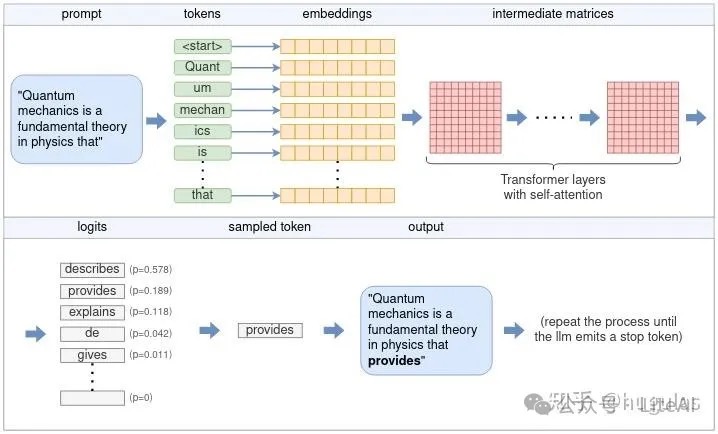
- 理解张量及其在 ggml(llama.cpp 使用的是 ggml,这是一种纯 C++ 实现的张量库) 中的应用。
- 张量的基本结构
- 张量操作
- 一系列张量操作构建了一个计算图
- 分词Tokenization(封装了词汇表/vocab)。
- 嵌入embedding/输入层。把离散的“token”,映射为一些连续的“数值”,两个token id之间是没有关系的,但两个Embedding的向量可以有距离、关联度等关系。
-
Transformer,自注意力机制是LLM架构中唯一计算词元间关系的地方,因此它构成了语言理解的核心,涵盖了对词汇关系的理解。由于涉及跨词元的计算,从工程角度来看,它也是最有趣的部分,尤其是对于较长序列来说,计算量可能会非常大。自注意力机制的输入是n_tokens x n_embd的嵌入矩阵,其中每一行或向量表示一个独立的词元。这些向量中的每一个都将被转换为三个不同的向量,分别称为“键”(key)、“查询”(query)和“值”(value)向量。这种转换通过将每个词元的嵌入向量与固定的wk、wq和wv矩阵(这些矩阵是模型参数的一部分)相乘来实现:
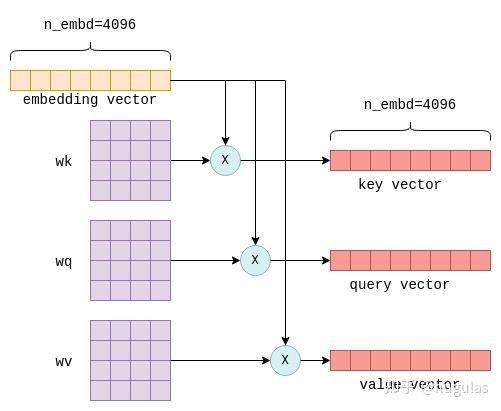 这个过程会对每个词元重复进行,也就是执行n_tokens次。理论上可以通过循环来完成,但为了提高效率,所有行会通过矩阵乘法在一次操作中进行转换。最终,我们得到三个矩阵 K、Q 和 V,它们的大小均为 n_tokens x n_embd,分别包含每个词元的键(key)、查询(query)和值(value)向量堆叠在一起。
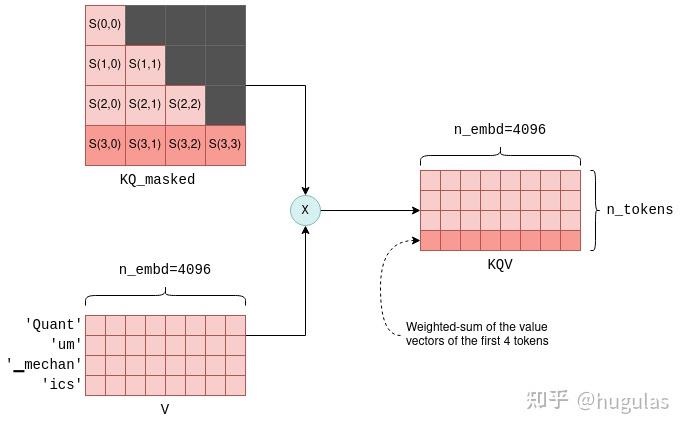
这个过程会对每个词元重复进行,也就是执行n_tokens次。理论上可以通过循环来完成,但为了提高效率,所有行会通过矩阵乘法在一次操作中进行转换。最终,我们得到三个矩阵 K、Q 和 V,它们的大小均为 n_tokens x n_embd,分别包含每个词元的键(key)、查询(query)和值(value)向量堆叠在一起。自注意力机制的下一步是将包含查询向量的矩阵 Q 与包含键向量的矩阵 K 的转置相乘。对于不太熟悉矩阵操作的人来说,此操作实际上是为每对查询和键向量计算一个联合得分。我们使用符号 S(i,j) 来表示查询 i 与键 j 的得分。这个过程生成了 n_tokens^2 个得分,每个查询-键对都有一个得分,并将其打包在一个称为 KQ 的矩阵中。随后,该矩阵会进行掩码操作,以移除对角线以上的元素:
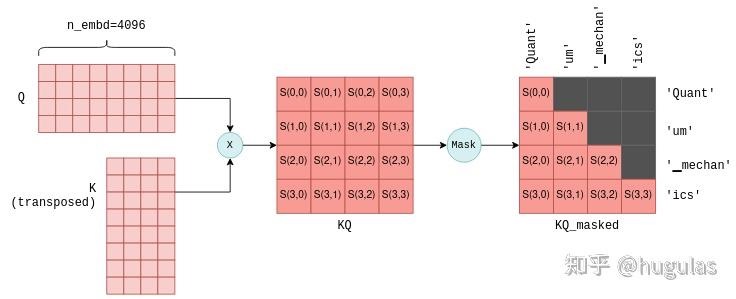 掩码操作是一个关键步骤。对于每个词元,它只保留与其前面词元之间的得分。在训练阶段,这一约束确保LLM仅根据之前的词元预测当前词元,而不是未来的词元。
掩码操作是一个关键步骤。对于每个词元,它只保留与其前面词元之间的得分。在训练阶段,这一约束确保LLM仅根据之前的词元预测当前词元,而不是未来的词元。自注意力机制的最后一步是将掩码后的得分矩阵KQ_masked与之前的值向量相乘。这样的矩阵乘法操作会生成所有前面词元值向量的加权和,其中权重是得分S(i,j)。例如,对于第四个词元“ics”,它会生成“Quant”、“um”、“▁mechan”和“ics”这几个词元的值向量的加权和,权重为S(3,0)到S(3,3),这些得分是由“ics”的查询向量与之前所有词元的键向量计算出来的。
每一层除了自注意力机制外,还包含多个其他的张量操作,主要是矩阵加法、乘法和激活函数操作,这些都是前馈神经网络的一部分。
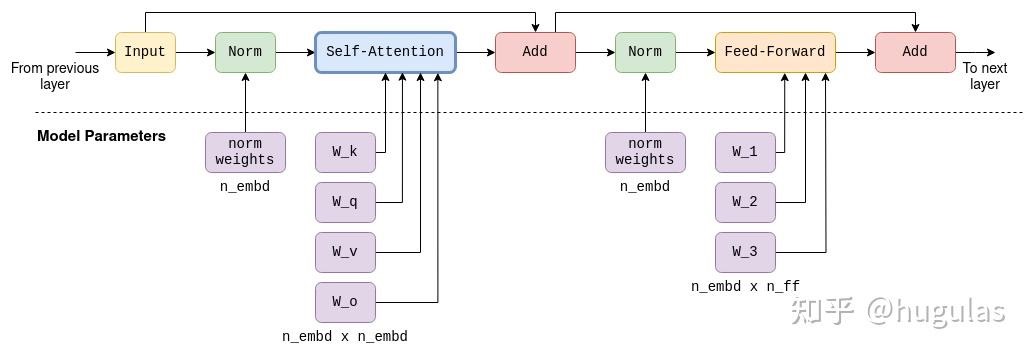
在Transformer架构中有多个层。这些层是相同的,除了每层都有自己的一组参数矩阵(例如用于自注意力机制的各自的wk、wq和wv矩阵)。第一层的输入是上文描述的嵌入矩阵。第一层的输出随后被用作第二层的输入,依此类推。我们可以将其看作每一层都生成了一组嵌入,但这些嵌入不再直接与单个词元相关,而是与词元关系的某种更复杂的理解相关联。
-
输出层/Transformer的最后一步是计算logits。logits的计算是通过将最后一个Transformer层的输出与一个固定的n_embd x n_vocab参数矩阵(在llama.cpp中也称为output)相乘来完成的。这个操作为词汇表中的每个词元生成一个logit。例如,在LLaMA中,它会生成n_vocab=32000个logits:
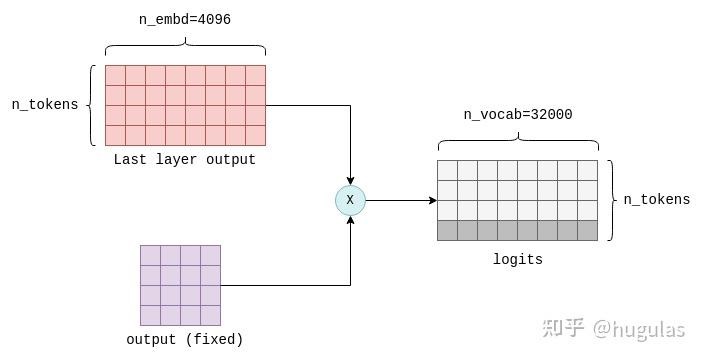 这里只关注结果的最后一行,它包含词汇表中每个可能的下一个词元的logit值。PS: 几乎所有模型最后一层都是这么一个Linear 层,它的用途是把我们中间各种layer算出来的结果,最终映射到vocab_size 维的向量里去。因为我们最终要算的,就是vocab_size 个词里,每个词出现的概率。
这里只关注结果的最后一行,它包含词汇表中每个可能的下一个词元的logit值。PS: 几乎所有模型最后一层都是这么一个Linear 层,它的用途是把我们中间各种layer算出来的结果,最终映射到vocab_size 维的向量里去。因为我们最终要算的,就是vocab_size 个词里,每个词出现的概率。 - 拿到logits列表后,下一步是根据它们选择下一个词元。这个过程称为采样。贪婪采样;温度采样;语法采样
-
KV缓存。每个词元都有一个关联的嵌入向量,该嵌入向量通过与参数矩阵wk和wv相乘进一步转化为键(key)和值(value)向量。KV缓存是用来缓存这些键和值向量的,通过缓存它们,我们可以节省每次迭代重新计算所需的浮点运算。
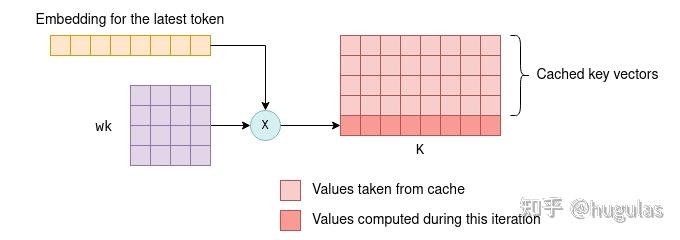 缓存的工作方式如下:
缓存的工作方式如下:- 在初始迭代期间,所有词元的键和值向量都会按照之前的描述进行计算,并保存到KV缓存中。
- 在后续迭代中,仅需要计算最新词元的键和值向量。缓存的键值向量与新词元的键值向量一起被拼接,形成K和V矩阵。这避免了重新计算所有先前词元的键值向量,从而大大提高了效率。 能够使用键和值向量的缓存,是因为这些向量在迭代之间保持不变。例如,如果我们首先处理四个词元,然后处理五个词元,而最初的四个词元没有变化,那么前四个键和值向量在第一次和第二次迭代中将保持相同。因此,在第二次迭代中不需要重新计算前四个词元的键和值向量。这一原则在Transformer的所有层中都成立,而不仅仅是在第一层。在所有层中,每个词元的键和值向量仅依赖于先前的词元。因此,当在后续迭代中添加新词元时,现有词元的键和值向量保持不变。 你可能会疑惑,既然我们缓存了键和值向量,为什么不缓存查询向量呢?答案是,实际上,除了当前词元的查询向量外,后续迭代中不再需要之前词元的查询向量。有了kv缓存后,我们实际上只需要将最新词元的查询向量传入自注意力机制即可。这个查询向量将与缓存的K矩阵相乘,计算最后一个词元与所有之前词元的联合得分。然后,它与缓存的V矩阵相乘,只计算KQV矩阵的最新一行。这个过程在所有层中重复,利用每一层的kv缓存。因此,在这种情况下,Transformer的输出是一个包含n_vocab个logit的向量,用于预测下一个词元。通过这种优化,我们节省了在KQ和KQV矩阵中计算不必要行的浮点运算,这种节省在词元列表增大时尤为显著。
格式
一些常见的大模型权重存储格式:
- PyTorch格式,pth, .pt, .bin:这是PyTorch框架的原生格式,广泛使用但安全性相对较低。
- Safetensors格式,.safetensors:由Hugging Face开发,安全性更高,加载速度更快,支持内存映射,是目前推荐的格式。
- GGUF格式,.gguf:由Georgi Gerganov定义的一种大模型文件格式,旨在快速加载和保存模型,适用于CPU推理。
- ONNX格式,.onnx:开放神经网络交换格式,旨在实现不同深度学习框架之间的互操作性。
- TensorFlow格式,.h5, .pb, .ckpt:TensorFlow使用的格式,包括HDF5格式、Protocol Buffers格式和Checkpoint文件。
- 量化格式,.gguf (llama.cpp使用), .ggml (旧版GGML), model-q4_0.bin (4-bit量化), model-q8_0.bin (8-bit量化):量化格式通过降低权重和激活值的精度来减小模型大小和内存占用,但可能略微降低精度。
- 分片格式, pytorch_model-00001-of-00003.bin:用于存储超大型模型,将权重文件分割成多个部分。
框架抽象
当我们谈论 AI 推理的 KV Cache,我们在说什么?回过头来看,vLLM 最大的贡献是什么呢?我认为更多地在于它定义了一个推理框架应该具备的基础功能模块,譬如围绕着虚拟内存建设的高效 KV Cache 管理模块,譬如考虑 KV Cache 分布情形来做相应请求路由的灵活的 Scheduler 调度模块,譬如对各类解码算法的支持,parallel sampling,beam search,等等,譬如一个多级存储架构(从 GPU VRAM,到 CPU DRAM,再到 NVMe Storage,甚至是 Storage Backends)以支持 KV Cache 根据其热度在不同层之间的高效流动,……更为重要的是,vLLM 展示了 KV Cache 的确可以是 LLM Inference 的性能胜负手,此处的优化空间巨大。此番意义,不亚于茫茫的淘金时代,当众人在苦苦找寻的时候,忽然有人喊了一声:“我这里发现金子了!”,于是乎,众人皆蜂拥而至 ……
通用流程的抽象
前处理 → DNN推理 → 后处理,无论是分类(classification)、检测(detection)、分割(segmentation)还是姿态估计(pose estimation)等任务,这一流程都是适用的。差异主要体现在前处理和后处理的具体实现上。
引擎创建: builder → network → config → parser → serialize → save file。 network 估计指的model 计算图解析和加载
引擎推理:load file → deserialize → engine → context → enqueue。file 估计指的是图片文件
为实现代码的可复用性,我们可以采用面向对象的编程思想,将通用的流程和操作封装在基类中,不同的任务通过继承和重写基类的方法,实现各自的特定逻辑。
class InferenceEngine {
public:
virtual void buildEngine() = 0;
virtual void loadEngine(const std::string& engineFile) = 0;
virtual void preprocess(const cv::Mat& image) = 0;
virtual void infer() = 0;
virtual void postprocess() = 0;
virtual ~InferenceEngine() {}
};
请求调度
- 静态请求级调度,传入的请求在到达时被分组到批次中并一同处理。批次中的所有请求都会并行处理,新请求需要等到当前批次的所有请求完成后才能被处理。这种方法虽然简单,但会导致低效,尤其是当单个请求具有不同的输入和输出长度时。较短序列的请求会因为批次内最长运行请求的完成而受到显著延迟。
- 迭代级调度。将任务分解为更小的单位,称为“ iterations”,而非对整个请求进行调度。在自回归模型中,迭代通常被定义为生成一个单独的 token。迭代级调度能显著提升计算效率,因为请求的 token 长度通常不同。提前完成的请求可以让新的请求加入批次,而不必等到整个批次完成。这种方式减少了硬件资源的空闲时间,并提高了整体吞吐量,尤其是在请求之间的 token 数量不同的工作负载中。
- Packed Batching是高效执行已调度请求的另一个关键组件,尽管它本身并不是一种调度技术。迭代级调度通常需要在同一迭代中处理预填充阶段和解码阶段。这两个阶段在输入 token 大小方面差异显著:预填充阶段一次处理多个 token,而解码阶段每次只处理一个 token,即前一迭代的输出 token。当预填充阶段的请求和解码阶段的请求被分组到同一批次中时,这种 token 长度的不一致会导致大量填充。即使所有批次请求都处于预填充阶段,由于输入 token 长度不同,也会产生填充。这种填充会降低计算效率,因为填充的额外计算实际上是无效的。
- Continuous Batching 或 In-flight Batching,通过集成迭代级批处理和Packed Batching,我们得到了 vLLM 和 TensorRT-LLM 调度器的核心:Continuous Batching(也称为“In-flight Batching”)。这种方法旨在最大限度地减少队列等待时间并减少填充开销,从而提高硬件利用率和服务性能。
- Continuous batching 还有个别名,叫做:batching with iteration-level scheduling,这里的 iteration 就是指一次 decode 计算。也就是说在每次 decode 的迭代过程中,做 batch 的调度调整。但调度本身不是无代价的,它可能涉及到接收和处理新的输入请求,重新组织输入数据的形状,甚至各种状态的重新初始化,这些都需要消耗 CPU 时间。这也就意味着在这段时间里,GPU 是闲着的,GPU 没有得到充分利用。所以在实现时,程序并不会真的每个 iteration 都做 scheduling,目前看到有两种做法:间隔调度:比如每 16 次 decode 计算后,检查一下是否有新的输入,以及是否有空闲的槽位,然后对 batch 做一次调度调整。排队比例调度。比如当前 batch 中有 10 个请求的 decode 正在进行,而排队中有 12 个请求,超过了排队比例 1.2,那么就启动一次调度调整。
- vllm在continuous batching基础上引入了两项独特的改进:不使用混合批处理(no mixed batching)以及优先处理 prefill 请求(prefill prioritization)。PS:分成共存派(每个iteration中既有prefill又有decode)和独立派(每个iteration中只有prefill或decode)
- 不使用混合批处理,这意味着 prefill 请求只会与其他 prefill 请求一起进行批处理,而 decode 请求只会与其他 decode 请求一起处理。这种设计简化了计算路径,因为每个批次仅处理相同阶段的请求。由于没有混合批处理,调度器必须采用另一种策略:优先处理 prefill 请求。
- 为什么需要优先处理 prefill 请求:假设当前批次中的某个请求完成了,而请求池中还有新的请求等待加入批次。由于不支持混合批处理,新的请求无法直接加入当前批次,因为它需要先完成 prefill 阶段,才能进入 decode 阶段。因此,新的请求无法与当前正在处理的 decode 请求一起被批处理。这种限制破坏了连续批处理的概念。为了解决这一问题,当前批次的 decode 请求需要暂时延后处理,先处理 prefill 请求,以确保连续批处理的流程不被中断。因此,为了在后续的 decode 迭代中确保有足够的 decode 请求可以处理,必须优先调度 prefill 请求。但是会设置一个阈值防止 decode 一直等待。也就是优先确保 TTFT,然后设置一个阈值来保证 TPOT 不会太差。很明显,这只是一个折中的方法。
- 导致在decode中会被插入prefill从而导致decode卡顿以及decode阶段MFU低下这两个问题。
以下参数决定了请求如何被分组到批次中:
- 最大批次大小(max batch size)
- 最大 token 数量(max number of tokens)
- KV 缓存(KV Cache)的大小。如果没有足够的剩余 KV 缓存存储请求的上下文,该请求将无法被调度。
管理 KV 缓存大小并非确定性的——它会随着每个生成的 token 增长,最终可能扩展到最大输出 token 长度。因此,管理剩余 KV 缓存涉及一定程度的估算。与其他估算挑战类似,我们可以采用悲观或乐观的方式分配 KV 缓存。这两种策略分别称为预分配(preallocation)和按需分配(on-demand allocation)。
- 在预分配中,一旦请求被调度,其 KV 缓存的内存空间会基于输入 token 数量和最大生成 token 数量之和进行保留。这种方法确保了在解码阶段不会出现内存不足的情况,因为所需的最大 KV 缓存内存已经提前分配
- 按需分配随着 token 的生成动态分配 KV 缓存内存,而不是预先为最大值保留内存。但它引入了 KV 缓存耗尽(preemption)的风险。在这种情况下,批次中的某些请求必须被中断,其 KV 缓存需要被清除以释放内存,从而避免死锁。清除可以通过两种方式实现:将 KV 缓存交换到主存储器(host memory)或完全丢弃缓存。与交换相比,丢弃更常被优先选择,因为主存储器的读写操作会引入显著的开销。而丢弃仅需要一次预填充迭代,将先前生成的 token 与原始输入 token 连接即可,因此在大多数情况下是一种更高效的选项。
可调优能力LLM 推理服务往往用于生产环境,而生产环境面临的情况是复杂多样的。
- 对于做阅读理解的应用来说,Prompt 可能会非常长,但生成的内容可能会非常短,开发人员可能会更追求吞吐;
- 对于聊天应用来说,Prompt 可能较短,生成的内容也不会太长,开发人员可能会更追求延迟;
- 对于创作类应用来说,Prompt 可能很短,生成的内容会更长,开发人员可能会更追求首 Token 延迟。 对 Continuous Batching 实现来说,就要求它调度策略尽量清晰,并且参数可调。所以更灵活的实现,未来可能会更受欢迎。
一些已成为LLM 推理引擎中事实标准的方法 建议细读。
模型文件加载
如果使用c++ 来写推理或训练引擎的话,就没有python调用c这个复杂的事儿了。对于一个推理框架,大概可以理解为,
- 专用的推理框架入口是onnx/pnnx等模型文件,只需要graph、节点/等概念,不需要pytorch 中类似layer概念(那是为了编程上抽象复用的)。
- 先基于onnx/pnnx等模型文件,自己提一套抽象/对象比如RuntimeGraph+RuntimeGraph+Operator等(为此有一个全局的算子注册机制),将模型权重、参数加载进来 构成计算图对象/内存表示,Operator 分为有参数算子和无参数算子,weight也就是tensor会赋值给有参数 Operator.weight。
- RuntimeGraph.run 按拓扑排序执行,执行到某个节点RuntimeNode时,RuntimeNode为算子准备入参、拿到出参(也就是tensor),可能跨节点通信,Operator为 cuda 函数准备入参(cuda 函数的入参、出参也就是tensor,必须事先准备好 指针形式传给cuda函数)。概念上从大到小是Graph ==> node ==> Operator ==> cuda 函数。
- tensor/显存的申请、释放都是上层组件负责(cuda 函数内不管,cuda 函数是无状态的),会有一个DeviceAllocator(分别对应cpu和gpu)组件负责内存和显存的分配和释放、内存和显存之间的copy等接口(比如tensor.to_cuda。再复杂一点先提前申请一个大的,内部再复用一下),对DeviceAllocator封装后提供tensor对象(tensor持有DeviceAllocator 引用,初始化时调用DeviceAllocator.allocate,析构时调用DeviceAllocator.release)。只是给算子函数传入input/weight/output 指针,算子也分为cpu和gpu实现。
资源管理的抽象
对于资源的申请和释放,例如内存的分配和释放,我们也可以进行封装,使得这些操作对使用者透明。这不仅提高了代码的可复用性,也减少了内存泄漏的风险。
class MemoryManager {
public:
MemoryManager(size_t size) {
cudaMalloc(&devicePtr_, size);
}
~MemoryManager() {
cudaFree(devicePtr_);
}
void* getDevicePtr() const { return devicePtr_; }
private:
void* devicePtr_;
};
我们希望我们的代码比较好的可读性,就意味着我们在设计的时候尽量通过接口来暴露或者隐蔽一些功能。比如说,我们可以使用worker作为接口进行推理。在main中,我们只需要做到创建一个worker -> woker读取图片 -> worker做推理就好了。同时,worker也只暴露这些接口。在worker内部,我们可以让worker根据main函数传入的参数,启动多种不同的task(分类、检测、分割)。
class Worker {
public:
Worker(const std::string& taskType, const std::string& modelPath);
void loadImage(const std::string& imagePath);
void infer();
void displayResult();
private:
std::shared_ptr<InferenceEngine> engine_;
cv::Mat image_;
};
在主程序中,我们只需要与 Worker 类交互:
int main() {
Worker worker("classification", "model.engine");
worker.loadImage("image.jpg");
worker.infer();
worker.displayResult();
return 0;
}
为框架设计插件机制,允许用户自定义前处理、后处理等步骤。插件可以在运行时加载,方便功能的扩展。
class Plugin {
public:
virtual void execute() = 0;
virtual ~Plugin() {}
};
class CustomPreprocessor : public Plugin {
void execute() override {
// 自定义前处理逻辑
}
};
以kvcache为核心的分布式架构
传统的推理服务架构采用同构部署模式,即所有的GPU节点既负责Prefill也负责Decode。随着长上下文场景的增加,这种模式暴露出了严重的性能缺陷。在同构集群中,当一个长Context的Prefill请求(例如处理一本小说的输入)被调度到某张GPU上时,该GPU会被长时间占用(可能长达数秒)。此时,该GPU上原本正在进行的Decode任务会被强制挂起,导致正在等待生成下一个Token的用户感受到明显的卡顿,即Token间延迟(Inter-Token Latency, ITL)激增。这种现象被称为“队头阻塞”(Head-of-Line Blocking)或“干扰效应”(Interference Effect)。PD分离架构将GPU资源划分为两个独立的池,Prefill 侧计算 Prompt 并产出 KV;Decode 侧接收 KV 后持续生成 token,从架构上隔离长 Prefill 对短 Decode 的干扰。
LLM PD 分离背后的架构问题 未细读。
Mooncake 采用了以 KVCache 为中心的分离式推理架构,主要由三个核心部分组成:
- Prefill 池:这个部分负责集中管理所有的预填充阶段的计算任务。
- Decoding 池:这个部分集中处理所有解码阶段的任务。
- KVCache 池:这个部分负责存储所有中间过程中应用到的 KVCache,并决定何时使用这些缓存,何时释放它们。
prefill-decode 分离(PD 分离)架构主要是考虑到了 LLM 的 prefill 和 decode 的两个阶段的特性不同,prefill 阶段是 compute bound(对于上下文的embeding和自注意力计算,模型会并行处理输入提示中的所有 Token,一次性计算出整个输入序列的 Attention 状态),decode 阶段是 memory bound(需要结合上下文以及当前token之前生成的token对应的KV值进行计算,过程是串行的),prefill 阶段的能力我们用 TTFT 首 token 时延来衡量,decode 的能力我们用 TPOT 生成每个 token 的时间来衡量。
- 但是在同一张卡上做 prefill 和 decode 会出现问题,在机器的算力等条件固定的情况下,你增加 bsz,prefill 阶段机器到算力瓶颈了,反而影响 TTFT,你减小 bsz,decode 阶段又是访存瓶颈的,decode 阶段可以比 prefill 阶段承载更大的 bsz。那么问题来了,到底要不要增大 bsz?
- 有了 PD 分离之后,我们可以把 prefill 阶段放在 H800 这样的算力高的机器,decode 阶段放在 H20 这样算力低的机器但是访存能力不会差太多的机器(毕竟显卡更新换代过程中算力增长是遥遥领先访存能力增长的),这样我们的如何 bsz 如何均衡的问题似乎可以得到解决,不同机器只负责一个阶段,bsz 也只需要根据你这个阶段的特性来设置就好了。decode 阶段可以比 prefill 阶段承载更大的 bsz。
- P和D的并行策略可以不一样,比如,P实例处理请求数一般较少,DP设置小;而decode需将并发打上去,DP数量设置大; P实例的MoE层可使用TP并行,D实例则一般使用EP并行。
- 但是 PD 分离有个很重要的问题,增加了通信和网络传输的成本(KV cache从prefill节点到decode节点),如果是卡间分离那么会增加通信的成本,如果是不同机器上进行分离那么就会增加网络传输 KV Cache 的成本。
DeepSeek V3采用的也是PD 分离部署方式(prefill-32张卡,decode-320张卡),由于集群分开增加的中间状态数据的传输,在NVLink这类传输技术的加持下,有开销但是可控。prefill和decode两个集群的GPU数量需要按照实际场景调整,大部分在1:2到1:4之间,具体看实际场景中TTFT和TPOT的表现和要求。
Context Caching

AI 推理场景的痛点和解决方案 未细读。
大模型推理框架RTP-LLM P-D分离之道:从思考到实战 未读
浅谈基于 Kubernetes 的 LLM 分布式推理框架架构:概览
- KV Cache Offloading。KV Cache Offloading 指的是将 GPU 显存中的 KV Cache 卸载到 CPU 内存或是外部存储的过程,当 LLM 需要访问被卸载的 KV Cache 时,它会按需将这些 Block 重新加载回 GPU 显存中。AIBrix 提供了多层 KV Cache 的缓存框架,默认情况下会使用 DRAM 中的 L1 Cache,在需要共享 KV Cache 的场景下则可以使用 L2 Cache,即分布式的外部存储。Dynamo 与 llm-d 等框架同样也支持使用 LMCache 等框架将不常用的 KV Cache 卸载到 CPU 内存与外部存储中。
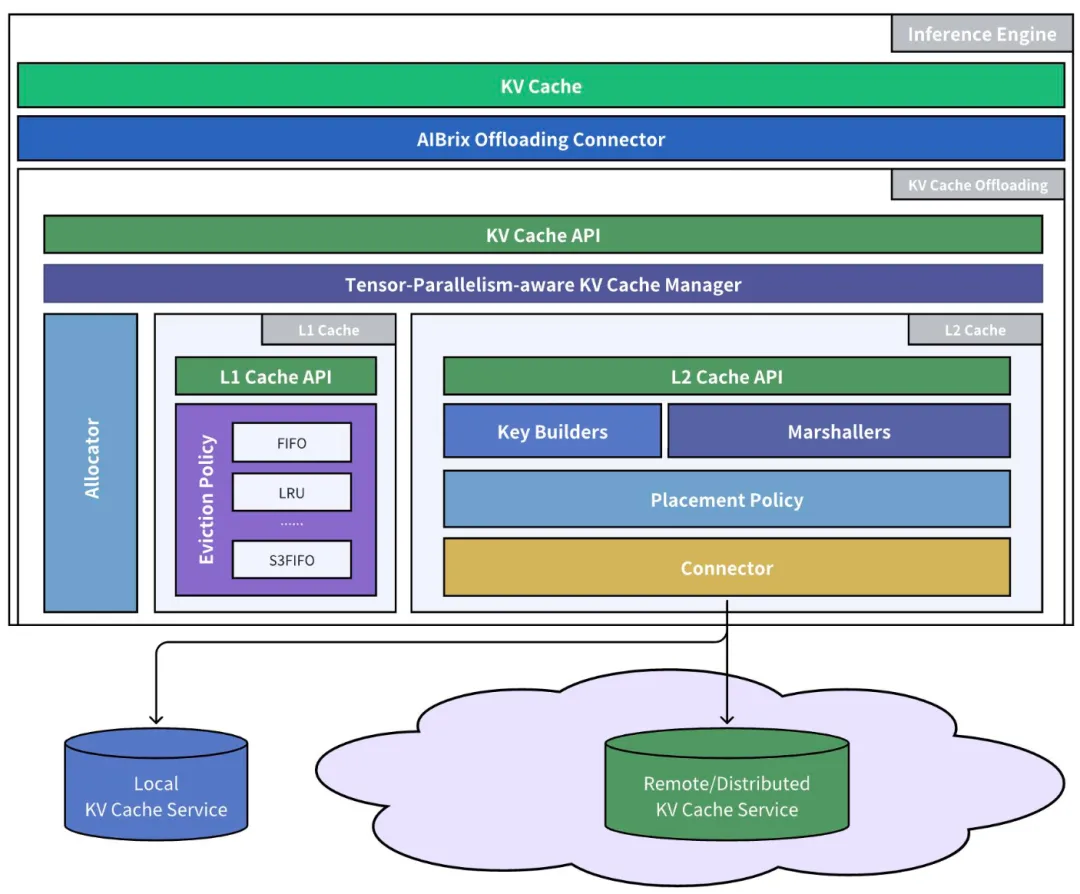
- KV Cache Sharing。随着 KV Cache Offloading 的引入,如何在不同的 LLM 推理实例共享 KV Cache 也是个被广泛研究的问题。
- Centralized:即通过一个中心化的 KV Cache 的池来管理不同实例的 KV Cache,其优点在于能够最大化地共享 KV Cache,可以更好地利用 Prefix Caching 的能力,但是在高并发的场景之下其可能会成为单点的性能瓶颈。
- Peer-to-Peer:即直接通过 P2P 通信机制在不同实例间传输 KV Cache,避免了中心化的存储,且具有更好的容错与动态扩缩容的能力的支持。
- 从分布式推理到分离式推理。目前基于基础设施层的分离式推理(Disaggregated Inference)也是被广泛讨论的话题,即模块化地拆分推理的各个模块形成分离式的部署,彼此之间通过协议传输数据。
- 基于Attention的LLM模型通常由注意力模块和前馈网络模块组成,解码阶段中,注意力模块的参数量少但需要大量KV交互,是访存密集型的,而前馈网络模块参数量大,是计算密集型的,因此Step-3模型论文提出了AFD(Attention - FFN Disaggregation)架构,即将注意力模块和前馈网络模块部署在不同的设备上,在PD分离的基础上进一步优化资源的利用率和推理服务效率。
- MoE模型由若干专家模型组成,主流的大模型拥有几千甚至更多的专家数量,例如DeepSeek V3系列有约1.4万个专家模型,如果所有的专家模型全部部署在一张GPU卡,或一台服务器上是远远无法承载的。由于MoE模型的稀疏激活特性,在多机部署时GPU之间的通信(all-to-all)仅需按需传输,仅把对应的token传给激活的专家模块。仅用NCCL在这种通信模型效率很低,导致带宽资源大量浪费,原因是NCCL更擅长全量而密集的通信。由DeepSeek开发的DeepEP是专门为混合专家模型(MoE)+专家并行(EP)设计的通信库。
- 由目前 AIBrix 与 llm-d 等框架的设计上来看,将负载均衡与 KV Cache 管理等功能由推理引擎的层面上升到集群编排的层面去解决是目前的主流趋势,编排侧能够更好地与现有的集群资源管理系统(如 Kubernetes)的生态系统集成,避免一些重复性的工作,推理引擎也可以关注在内部的推理过程优化,只需要暴露一些特定的抽象与接口供编排侧对接。
vLLM 与 SGLang鏖战正酣时,小强 LMCache 盯上了具体的 KV Cache 这一块,专注于缓存层的抽象与优化,与两强的关系都不赖。LMCache 自身以一种分布式的方式,有效地管理起计算侧的 GPU 缓存。向下,LMCache 充分地利用各种存储后端(Mooncake,Redis,InfiniStore,……),适时地将 KV Cache offloading,从而提供更具水平扩展性的 KV Cache Layer。LMCache 归纳总结的 KV Cache 两个主要场景
- Context Caching,这里缓存的 KV Cache 来自公共的 System Prompt,以及专业知识库相关的 RAG Context 等等,通常这部分 KV Cache 比较大,甚至需要 offloading 至 CPU Memory,乃至 Local Disk;
- P/D Disaggregation Caching,这个架构的一个强依赖就是 Prefill 引擎与 Decode 引擎之间的高效通信,分享 Prefix KV Caches。 旨在统一 KV Cache Layer 的 LMCache 祭出了何等大杀器?无他,惟如下三点:
- 模块化的 KV Cache Connector,提供标准化的访问接口,将 KV Cache Layer 从快速演进的 LLM Inference 框架中脱离出来。
- 有关 KV Cache 的高效管理,包括高效地 storing KV Cache,包括高效地 loading KV Cache。一大优化是 pipelining 技术,涉及到 GPU compute 与 data loading/storing 之间的 pipelining,以及 KV Cache 的 storing 与 loading 之间的 pipelining;另一大优化是 batching 技术;以 chunk 为单位(远大于具体操作的 page 页大小)store/load KV Caches,以充分地利用存储设备与 GPU 内存之间的网络带宽;在不同存储层之间移动 KV Cache 数据时候,应用 zero-copy 零拷贝技术,减少内存拷贝;
- 面向 KV Cache 的管控平面,,用户可以针对 KV Caches 做诸如 pinning, lookup, cleanup, movement, and compression 等操作。譬如 2025 年早些时候,某金融公司即在生产场景下给 LMCache 提出需求,希望能够 pin 住 KV Cache 中经常需要访问的金融类文档信息; LMCache是一个两层的架构,中心化的 Cache Controller,与散落在每个节点上的 LMCache Worker 共同组成。
控制面
vLLM通过PagedAttention等技术,极大地提升了单机或单节点的LLM推理吞吐量。它完美地解决了“数据平面”的效率问题。但当你尝试将vLLM部署到成百上千张GPU的生产环境,服务海量模型和用户时,新的挑战出现了:
- 「路由(Routing)」:如何将请求智能地分发到最合适的模型副本?简单的轮询(Round-Robin)远远不够。
- 「自动伸缩(Autoscaling)」:如何根据真实负载动态调整GPU资源?传统的QPS指标在LLM场景下几乎失效。
- 「容错与管理」:如何处理硬件故障,如何高效地管理成百上千个LoRA适配器? 这些问题,vLLM本身并不直接解决。它们属于“「控制平面」”的范畴。
路由与负载均衡
Higress LLM 服务负载均衡的新实践在面对 LLM 服务时,这些传统方法(常见的负载均衡算法有轮询、随机、最小请求数、一致性哈希等)往往暴露出以下几个关键缺陷:
- 忽略任务复杂度差异:LLM 推理请求的复杂度差异极大。例如,一个长文本生成任务可能需要数十倍于短文本分类任务的计算资源。而传统负载均衡器无法感知这种差异,容易导致某些节点过载,而其他节点空闲,造成资源浪费和响应延迟。
- 缺乏对 GPU 资源水位的感知:在 LLM 推理服务中,计算瓶颈主要集中在 GPU 上,传统负载均衡器往往无法感知到这一细粒度的资源消耗情况,导致某些 GPU 节点因显存不足而拒绝请求或响应缓慢,而其他节点却处于空闲状态。
- 缺乏对 KV Cache 的复用能力:在并发请求处理中,如果多个请求具有相似的前缀,则它们的 KV Cache 可能存在重叠部分,可以通过共享或压缩的方式减少显存占用并提升生成速度。传统负载均衡策略并未考虑请求之间的语义相似性或 KV Cache 的可复用性,难以将具有潜在复用价值的请求分配到同一 GPU 实例上,从而错失优化机会。
LLM 推理的核心是 KV Cache,其存储了模型在 Prefill 阶段计算出的 Key 和 Value。由于不同请求的 Prompt 可能存在重叠的前缀,这些共享的前缀信息可以被多个请求复用,从而显著提升推理效率。因此,在负载均衡时需要考虑如何高效地利用这些缓存(KVCache aware),而不是简单地将请求随机分配到不同的实例上。
- Prefix-Aware。如果一个请求的前缀(Prompt)已经在某个实例的KV缓存中,就将请求路由到该实例,实现缓存复用,极大加速Prefill。这与CDN的回源策略、数据库的查询缓存有异曲同工之妙。这种策略需要负载均衡器维护每个实例的缓存状态信息,并根据请求的前缀特征进行路由。
- Profile-based SLO-aware。在异构GPU环境中,路由器会根据每个实例的性能画像(Profile)和服务等级目标(SLO),进行负载感知和队列管理,确保高优先级的请求被快速处理。
- Fairness。LLM 实例的公平调度也是负载均衡的一个重要方面,尤其是在多租户环境中,公平性确保了所有用户都能获得相对一致的服务质量,而不会因为某些实例过载而导致其他用户的请求延迟。AIBrix 基于 Sheng et al. 实现了 Virtual Token Counter (VTC) 的 Fair Queuing 调度策略。VTC 为每个客户端维护一个虚拟 Token 计数器,通过跟踪每个客户端已接受的服务量来实现公平调度,优先服务计数器值最小的客户端。
自动扩速容
目前 Kubernetes 的生态系统中被广泛使用的自动扩缩容工具主要有以下三个:
- HPA(Horizontal Pod Autoscaler):Kubernetes 的水平扩缩器
- KPA(Knative Pod Autoscaler):Knative 的水平扩缩器
- KEDA(Kubernetes Event-driven Autoscaling):事件驱动的服务扩缩器,支持服务的从零到一部署
针对 LLM 推理服务的自动扩缩容,其关键在于如何决定触发自动扩缩容的指标。AIBrix 的演讲者在 vLLM Meetup Beijing 分享了与传统的微服务的自动扩缩容不同,LLM 推理请求的 QPS 可能与产生的延迟并不是正相关的,且 SM Active 等 GPU 指标也不一定能及时反映出指标的变化。因此,如何基于 LLM 推理的特性来进行可靠的自动扩缩容仍然是需要探索的问题。长期来看,笔者认为 LLM 推理服务的自动扩缩容也有可能会由 Reactive 逐渐发展到 Proactive 甚至是 Predictive 的形态(如时间序列分析与基于强化学习的预测)。
各种并行
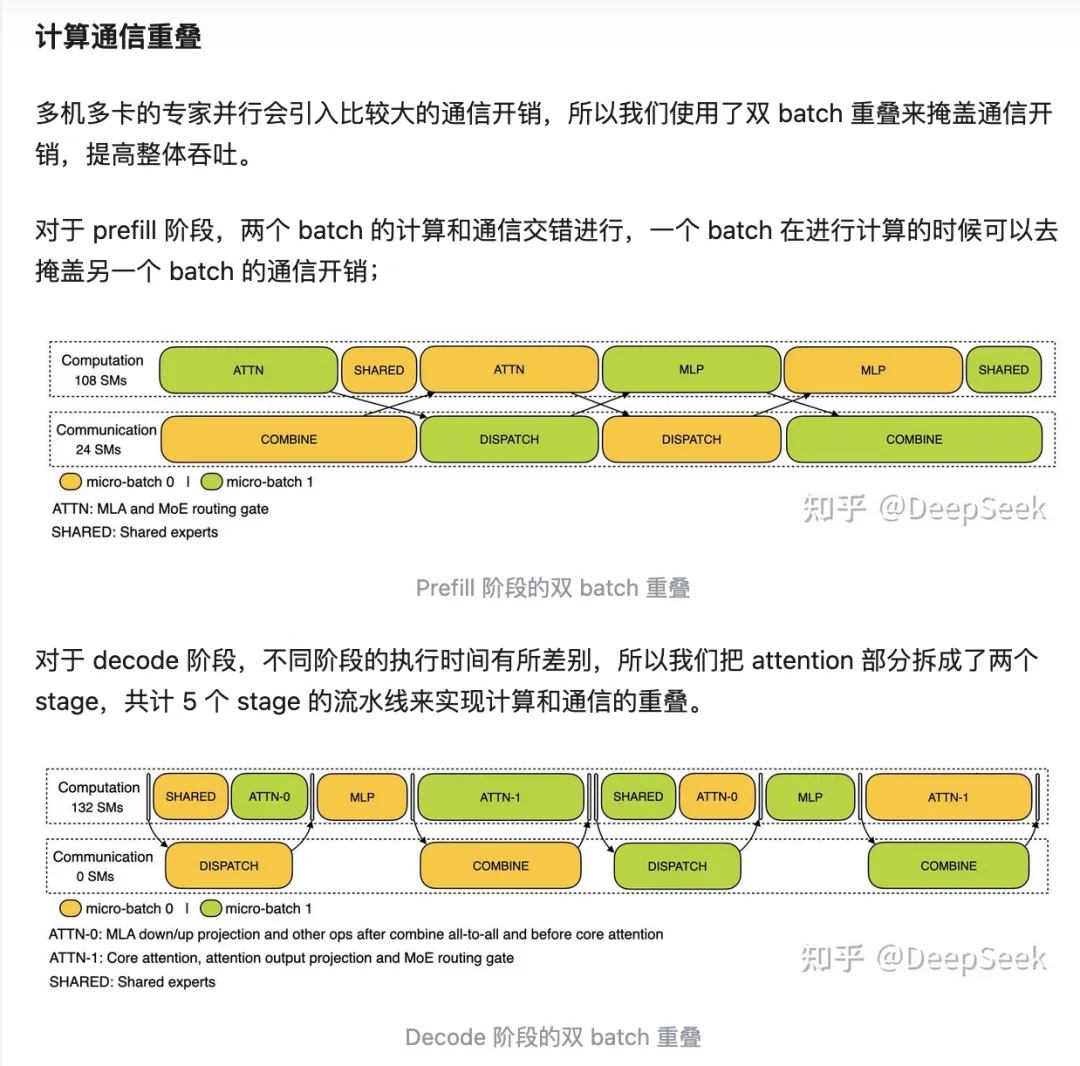
LightLLM中DeepSeek V3/R1 Two MicroBatch Overlap 实现解析 未细读(在代码上体现如何overlap)。在DeepSeek-V3/R1推理系统中,多机多卡的专家并行会引入比较大的通信开销,所以DeepSeek使用了双 batch 重叠来掩盖通信开销,提高整体吞吐。
留下评论