tensorflow学习
简介
TensorFlow,这是个很形象的比喻,意思是 张量(Tensor)在神经网络中流动(Flow)。
- 在数学中,张量是一种几何实体(对应的有一个概念叫矢量),广义上可以表示任何形式的数据。在NumPy等数学计算库或TensorFlow等深度学习库中,我们通常使用多维数组来描述张量,所以不能叫做矩阵,矩阵只是二维的数组,张量所指的维度是没有限制的。线性代数/矩阵的几何意义 未读完
- 张量这一概念的核心在于,它是一个数据容器。它包含的数据几乎总是数值数据,因此它是数字的容器。
- 在物理实现时(TensorFlow)是一个句柄,它存储张量的元信息以及指向张量数据的内存缓冲区指针。
- 张量是执行操作时的输入输出数据,用户通过执行操作来创建或计算张量,张量的形状不一定在编译时确定,可以在运行时通过形状推断计算出。
TensorFlow 使用库模式(不是框架模式),工作形态是由用户编写主程序代码,调用python或其它语言函数库提供的接口实现计算逻辑。用户部署和使用TensorFlow 时,不需要启动专门的守护进程,也不需要调用特殊启动工具,只需要像编写普通本地应用程序那样即可上手。
核心概念
TensorFlow on Kubernetes的架构与实践
数据节点
Tensorflow底层最核心的概念是张量,计算图以及自动微分。
- Tensor
- Variable,特殊的张量, 维护特定节点的状态,一般对应w、b,模型的复杂、变大即 tf.Variable 变多,且在分布式场景下由各个节点共享。tf.Variable 方法是Op,返回时是变量。与
session.run(tf.global_variables_initializer())配合使用 进行真正的初始化。与Tensor 不同在于 - 普通Tensor 的生命周期通常随依赖的计算完成而结束,内存也随即释放。
- 变量常驻内存, 在每一步训练时不断更新其值,以实现模型参数的更新。
- placeholder 占位符,一般对应 x、 y_hat、需要变化的超参数等,使用
session.run(...,feed_dict={xx:xx})为占位符赋值
计算图
动态图与静态图的浅显理解 PS: 笔者个人的学习路径是先 pytorch 后tensorflow
x = tf.constant("hello")
y = tf.constant("world")
z = tf.strings.join([x,y],separator=" ")
print(z)
# output
# Tensor("StringJoin:0", shape=(), dtype=string)
可以看到,在tensorflow1.0 静态图场景下,z 输出为空。z = tf.strings.join([x,y],separator=" ") 没有真正运行(我们发明一个叫tensorflow的deep learning dsl,并且提供python api,让用户在python中通过元编程编写tensorflow代码),只有运行session.run(z) z 才会真正有值。在TensorFlow1.0时代,采用的是静态计算图,需要先使用TensorFlow的各种算子创建计算图,然后再开启一个会话Session,显式执行计算图。模型搭建和训练分为两个阶段,由两种语言分别实现编程接口和核心运行时,还涉及到计算图的序列化及跨组件传输。而在TensorFlow2.0时代,采用的是动态计算图,模型的搭建和训练放在一个过程中,即每使用一个算子后,该算子会被动态加入到隐含的默认计算图中立即执行得到结果,不需要使用Session了,像原始的Python语法一样自然。
会话
Session 提供求解张量和执行操作的运行环境,它是发送计算任务的客户端,所有计算任务都由它分发到其连接的执行引擎(进程内引擎)完成。
# 创建会话 target =会话连接的执行引擎(默认是进程内那个),graph= 会话加载的数据流图,config= 会话启动时的配置项
sess = tf.session(target=...,graph=...,config=...)
# 估算张量或执行操作。 Tensor.eval 和 Operation.run 底层都是 sess.run
sess.run(...)
# 关闭会话
sess.close()
使用示例
import tensorflow as tf
a = tf.constant(5.0)
b = tf.constant(6.0)
c = a * b
sess = tf.Session()
print(sess.run(c))
demo
# model parameters
W = tf.Variable(0.3, tf.float32)
b = tf.Variable(-0.3, tf.float32)
# model inputs & outputs
x = tf.placeholder(tf.float32)
y = tf.placeholder(tf.float32)
# the model
out = W * x + b
# loss function
loss = tf.reduce_sum(tf.square(out - y))
# optimizer
optimizer = tf.train.GradientDescentOptimizer(0.001)
train = optimizer.minimize(loss)
# training data
x_train = np.random.random_sample((100,)).astype(np.float32)
y_train = np.random.random_sample((100,)).astype(np.float32)
# training
init = tf.global_variables_initializer()
with tf.Session() as sess:
sess.run(init)
for i in range(1000):
sess.run(train, {x:x_train, y:y_train})
current_loss = sess.run(loss, {x:x_train, y:y_train})
print("iter step %d training loss %f" % (i, current_loss))
print(sess.run(W))
print(sess.run(b))
当我们调用 sess.run(train_op) 语句执行训练操作时,程序内部首先提取单步训练操作依赖的所有前置操作,这些操作的节点共同组成一幅子图。然后程序将子图中的计算节点、存储节点和数据节点按照各自的执行设备分类(可以在创建节点时指定执行该节点的设备),相同设备上的节点组成了一幅局部图。每个设备上的局部图在实际执行时,根据节点间的依赖关系将各个节点有序的加载到设备上执行。
房价预测
df = pd.read_csv('data.csv',names=['square', 'bedrooms', 'price'])
ones = pd.DataFrame({'ones': np.ones(len(df))})# ones是n行1列的数据框,表示x0恒为1
df = pd.concat([ones, df], axis=1) # 根据列合并数据
| |ones| square| bedrooms| price| |—|—|—|—|—| |0| 1.0| 0.130010| -0.223675| 0.475747| |1| 1.0| -0.504190| -0.223675| -0.084074|
特征 + batch 组成一个矩阵, 其shape 和 计算图 X_data 的shape 一致。
X_data = np.array(df[df.columns[0:3]])
y_data = np.array(df[df.columns[-1]]).reshape(len(df), 1)
# 输入 X,形状[47, 3]
X = tf.placeholder(tf.float32, X_data.shape)
# 输出 y,形状[47, 1]
y = tf.placeholder(tf.float32, y_data.shape)
# 权重变量 W,形状[3,1]
W = tf.get_variable("weights", (X_data.shape[1], 1), initializer=tf.constant_initializer())
# 假设函数 h(x) = w0*x0+w1*x1+w2*x2, 其中x0恒为1
# 推理值 y_pred 形状[47,1]
y_pred = tf.matmul(X, W)
# 损失函数采用最小二乘法,y_pred - y 是形如[47, 1]的向量。
loss_op = 1 / (2 * len(X_data)) * tf.matmul((y_pred - y), (y_pred - y), transpose_a=True)
opt = tf.train.GradientDescentOptimizer(learning_rate=alpha)
train_op = opt.minimize(loss_op)
with tf.Session() as sess:
# 初始化全局变量
sess.run(tf.global_variables_initializer())
# 开始训练模型,
# 因为训练集较小,所以每轮都使用全量数据训练
for e in range(1, epoch + 1):
sess.run(train_op, feed_dict={X: X_data, y: y_data})
数据读取
- 数据源: csv/TFRecord/Tensor/numpy/dataFrame/自定义格式
- 读取方式:批量,多线程
- 读取的数据如何给到模型使用: 作为 tensor 给feed_dict;新的Dataset
y_hat = model(x)。
读取的 X/Y 更多是作为 符号引用,描述了数据来源 及方式(batch_size、线程数等),只有session.run 后才会真正有值。
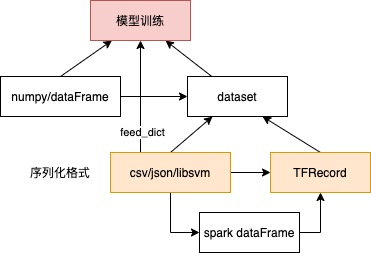
feed_dict 读取csv(不建议)
file_queue = tf.train.string_input_producer(["xx.csv"])
reader = tf.TextLineReader()
_, value = reader.read(file_queue)
record_defaults=[["1.0"], ["1"],["2.0"]]
column1, column2, column3 = tf.decode_csv(content, record_defaults)
# column1_batch, column2_batch, column3_batch = tf.train.batch([column1, column2], batch_size=9, num_threads=1, capacity=9)
features = tf.stack([column1, column2])
...
with tf.Session() as sess:
sess.run(...,feed_dict = {X = features, Y = column3})
Dataset
在训练我们的model的时候,需要把训练数据input到我们的算法model中。但有时候训练数据不是说只有几百条,而是成千上万的,这样如果直接把这些数据load到内存中的Tensor肯定是吃不消的,所以需要一种数据结构让算法能够批量地从disk中分批读取,然后用它们来训练我们的model, Dataset正是提供这种机制(transformation)来满足这方面的需求(建立input pipelines)。可以将Dataset理解成一个数据源,指向某些包含训练数据的文件列表,或者是内存里面已有的数据结构(比如Tensor objects)。类似Spark RDD或DataFrame
feed-dict 被吐槽太慢了 ,如何在TensorFlow上高效地使用Dataset推荐使用dataset API的原因在于,他提供了一套构建数据Pipeline的操作,包括以下三部分
- 从数据源构造dataset(支持TFRecordDataset,TextLineDataset, CsvDataset等方式)
- 数据处理操作 (通过map操作进行转化,tfrecord格式需要对Example进行解析)
- 迭代数据 (包括batch, shuffle, repeat, cache等操作)
Tensorflow封装了一组API来处理数据的读入,它们都属于模块 tf.data
- 从numpy 读取
# create a random vector of shape (100,2) x = np.random.sample((100,2)) # make a dataset from a numpy array dataset = tf.data.Dataset.from_tensor_slices(x) - 从磁盘/内存中获取源数据,比如直接读取特定目录的下的 xx.png 文件,使用 dataset.map 将输入数据转为 dataset 要求
- 读入TFrecords数据集,
dataset = tf.data.Dataset.TFRecordDataset("dataset.tfrecords")
Iterator 是对应的Dataset迭代器。如果 Dataset 是一个水池的话,那么它其中的数据就好比是水池中的水,Iterator 可以把它当成是一根水管。
features, labels = (np.random.sample((100,2)), np.random.sample((100,1)))
dataset = tf.data.Dataset.from_tensor_slices((features,labels))
# 描述 了数据的来源 batch size 等
dataset = tf.data.Dataset.from_tensor_slices((features,labels)).repeat().batch(BATCH_SIZE)
# 创建迭代器
iter = dataset.make_one_shot_iterator()
x, y = iter.get_next()
# 定义模型
net = tf.layers.dense(x, 8, activation=tf.tanh) # pass the first value
net = tf.layers.dense(net, 8, activation=tf.tanh)
prediction = tf.layers.dense(net, 1, activation=tf.tanh)
loss = tf.losses.mean_squared_error(prediction, y)
train_op = tf.train.AdamOptimizer().minimize(loss)
with tf.Session() as sess:
sess.run(tf.global_variables_initializer())
for i in range(EPOCHS):
_, loss_value = sess.run([train_op, loss])
训练机器学习模型的时候,会将数据集遍历多轮(epoch),每一轮遍历都以mini-batch的形式送入模型(batch),数据遍历应该随机进行(shuffle)。
dataset 由 elements 组成,elements 由component 组成
- elements include tuple, dict, NamedTuple, and OrderedDict。dataset 实现了python Iterable,一次
next()输出一个element。比如[<component,component>,...] [dict(component,component),] - Individual components of the structure can be of any type representable by tf.TypeSpec, including tf.Tensor, tf.sparse.SparseTensor, tf.RaggedTensor, tf.TensorArray, or tf.data.Dataset.
TFRecord 文件
TFRecord是Tensorflow训练和推断标准的数据存储格式之一,将数据存储为二进制文件(二进制存储具有占用空间少,拷贝和读取(from disk)更加高效的特点),而且不需要单独的标签文件了,其本质是一行行字节字符串构成的样本数据。一条TFRecord数据代表一个Example,一个Example就是一个样本数据,每个Example内部由一个字典构成<key,Feature>,key为字段名,Feature为字段名所对应的数据,Feature有三种数据类型:ByteList、FloatList,Int64List。TFRecord并不是一个self-describing的格式,也就是说,tfrecord的write和read都需要额外指明schema。
- 小规模生成TFRecord: python 代码将图像、文本等写入tfrecords文件需要建立一个writer对象,创建这个对象的是函数
tf.python_io.TFRecordWriter - 大规模生成TFRecord:如何大规模地把HDFS中的数据直接喂到Tensorflow中呢?Tensorflow提供了一种解决方法:spark-tensorflow-connector,支持将spark DataFrame格式数据直接保存为TFRecords格式数据。
为计算图加入控制逻辑
从数据流图中取数据、给数据流图加载数据等 一定要通过session.run 的方式执行(全部或部分),没有在session 中执行之前,整个数据流图只是一个壳(符号)。 python 是一门语言,而tensorflow 的python api 并不是python ,而是一种领域特定语言/符号式编程框架,负责描述 TensorFlow的前端,没有跟python 解释器打通, 也因此tensorflow python中不能直接使用if 等(而是使用tf.cond, tf.case, tf.while_loop),“python代码”都会send 到一个执行引擎来跑。除了TensorFlow 自身外,keras(更高层api) 也可以作为TensorFlow 的前端。
TensorFlow 记录每个运算符的依赖,根据依赖进行调度计算。数据流图上节点的执行顺序的实现参考了拓扑排序的设计思想
- 以节点名称作为关键字,入度作为值,创建一张散列表,并将此数据流图上的所有节点放入散列表中。
- 为此数据流图创建一个可执行节点队列,将散列表中入度为0的节点加入到该队列,并从散列表中删除这些节点
- 依次执行该队列中的每一个节点,执行成功后将此节点输出指向的节点的入度值减1,更新散列表中对应节点的入度值
- 重复2和3,知道可执行节点队列变为空。 这也导致了 运算符执行顺序可能和 代码顺序不同。
var = tf.Variable(...)
top = var * 2
bot = var.assign_add(2)
out = top + bot
其中 var 为一个变量,在对 bot 求值时,var 本身自增 2,然后将自增后的值返回。这时 top 语句执行顺序就会对 out 结果产生不同影响,结果不可预知。为此需要增加依赖关系
var = tf.Variable(...)
top = var * 2
with tf.control_dependencies([top]):
bot = var.assign_add(2)
out = top + bot
条件分支 tf.cond(a < b,lambda: tf.add(3,3),lambda:tf.sqaure(3))
可视化
用户在程序中使用 tf.summary 模块提供的工具,输出必要的序列化数据,FileWriter 保存到事件文件,然后启动 Tensorboard 加载事件文件,从而在各个面板中展示对应的可视化对象。
- summary,在定义计算图时,在适当位置加上一些summary 操作。 summary 操作输入输出也是张量,只是输出是汇总数据。
- merge,在训练时可能加入了 多个summary 操作,此时需要使用 tf.summary.merge_all 将这些summary 操作 合成一个操纵
- run,执行session.run 时,需要通过 tf.summary.FileWrite() 指定一个目录告诉程序把产生的文件放到指定位置,然后使用
add_summary()将某一步summary 数据记录到文件中 tensorboard --logdir=path/to/log-directory启动tensorboard 然后在浏览器打开页面
可以记录和展示的数据形式
- 可视化数据流图
sess = xx writer = tf.summary.FileWriter("/tmp/summary/xx",sess.graph) ... writer.close() - 可视化度量指标和模型参数 ```python tf.summary.scalar(‘name’,’tensor’)
for i in range(FLAGs.max_step): summary, acc = sess.run(…) writer.add_summary(summary,i)
3. 可视化图形和音频数据
4. 可视化高维数据,用于展示高维embedding 数据的分布情况
5. 可视化性能与资源占用 [使用 Profiler 优化 TensorFlow 性能](https://tensorflow.google.cn/guide/profiler#best_practices_for_optimal_model_performance)。 除了跟TensorBoard 一起使用外, profiler 也可以单独 执行和分析 [tensorflow Profile分析神经网络性能](https://asphelzhn.github.io/2019/03/26/tensor_06_profile/)。
1. 使用 tf.profiler Function API 的编程模式
```python
tf.profiler.experimental.start('logdir') # 会保存为json 格式文件
# Train the model here
tf.profiler.experimental.stop()
```
2. 使用 TensorBoard Keras 回调 (tf.keras.callbacks.TensorBoard) 的编程模式
```python
# Profile from batches 10 to 15
tb_callback = tf.keras.callbacks.TensorBoard(log_dir=log_dir,profile_batch='10, 15')
# Train the model and use the TensorBoard Keras callback to collect performance profiling data
model.fit(train_data,steps_per_epoch=20,epochs=5,callbacks=[tb_callback])
```
## TensorFlow自定义算子
[TensorFlow 模型准实时更新上线的设计与实现](https://mp.weixin.qq.com/s/JGbELXp0aLn9n7JE1wQXvA)计算图结构由模型的算法结构决定,对数据的操作即为 operation( op )。当模型结构确定的情况下,我们的增强就需要对 op 进行定制。 PS:介绍了针对 embedding 参数的特点,如何通过自定义op 对其进行优化。
[tensorflow:自定义op简单介绍](https://blog.csdn.net/u012436149/article/details/73737299)
一个Op可以接收一个或者多个输入Tensor,然后产生零个或者多个输出Tensor,分别利用Input和Output定义。在注册一个Op之后,就需要继承OpKernel,实现他的计算过程Compute函数,在Compute函数中,我们可以通过访问OpKernelContext来获得输入和输出信息。当我们需要申请新的内存地址时,可以通过OpKernelContext去申请TempTensor或者PersistentTensor。一般Tensorflow的Op都采用Eigen来操作Tensor
[Adding a New Op](https://chromium.googlesource.com/external/github.com/tensorflow/tensorflow/+/r0.10/tensorflow/g3doc/how_tos/adding_an_op/index.md)对于 TensorFlow,可以自定义 Operation,即如果现有的库没有涵盖你想要的操作, 你可以自己定制一个。为了使定制的 Op 能够兼容原有的库,你必须做以下工作:
1. 在一个 C++ 文件中注册新 Op. Op 的注册与实现是相互独立的. 在其注册时描述了 Op 该如何执行. 例如, 注册 Op 时定义了 Op 的名字, 并指定了它的输入和输出。
```c
// 最终Op被注册到了一个static变量global_op_registry中
REGISTER_OP("ZeroOut")
.Input("to_zero: int32")
.Output("zeroed: int32")
.SetShapeFn([](::tensorflow::shape_inference::InferenceContext* c) {
c->set_output(0, c->input(0));
return Status::OK();
});
- 使用 C++ 实现 Op. 每一个实现称之为一个 “kernel”, 可以存在多个 kernel, 以适配不同的架构 (CPU, GPU 等)或不同的输入/输出类型.
- bazel(tf编译工具) 会检索所有op 并创建一个 Python wrapper. 这个wrapper是创建 Op 的公开 API. 当注册 Op 时, 会自动生成一个默认 默认的包装器. 既可以直接使用默认包装器, 也可以添加一个新的包装器.
- (可选) 写一个函数计算 Op 的梯度,在Python 中注册.
@ops.RegisterGradient("ZeroOut") def _zero_out_grad(op, grad): xxxxxxxxx - (可选) 写一个函数, 描述 Op 的输入和输出 shape. 该函数能够允许从 Op 推断 shape.
- 测试 Op, 通常使用 Pyhton。如果你定义了梯度,你可以使用Python的GradientChecker来测试它。
There are two main mechanisms for op and kernel registration:
- Static linking into the core TensorFlow library, and static initialization.
- Dynamic linking at runtime, using the
tf.load_op_library()function. 读取op 对应的 python wrapper文件 作为python module 注册到python module中
tensorflow/custom-op
Bazel BUILD文件如下,执行 bazel build ${BAZEL_ARGS[@]} 可以得到 tensorflow/core/user_ops/zero:zero_out.so PS: 类似于执行了 上文中的g++ 编译得到so 文件。
load("//tensorflow:tensorflow.bzl", "tf_custom_op_library")
tf_custom_op_library(
name = "zero_out.so", # target name
srcs = ["zero_out.cc"], # the list of the sources to compile,
)
得到so 文件后,tf.load_op_library 动态加载so作为 module 使用(可以参考python module 动态加载加载)。
import tensorflow as tf
# 返回一个 A python module, containing the (op对应的)Python wrappers for Ops defined in the plugin.
# Python Module,是一个 Python 文件,以 .py 结尾,包含了 Python 对象定义和Python语句
zero_out_module = tf.load_op_library('zero_out.so')
with tf.Session():
print(zero_out_module.zero_out([1,2,3,4,5])).eval() # eval 底层执行 session.run
zero_out_module.zero_out 可能仅用于演示,正规的ops 比如tf.matmul (matrix multiplication,简称 matmul)等实现(对应到 编译tf生成的代码 gen_math_ops.py)会涉及到生成opDef (graphDef 的一部分)等逻辑。
tensornet框架 自定义ops 示例
- 运行时访问链路: import gen_xx_ops.py ==>
gen_xx_ops.opxx==>_op_def_library._apply_op_helper==> 向graph中添加对应名字的Op节点 - gen_xx_ops 生成:bazel build ==> 使用 python_op_gen_main 生成 gen_xx_ops.py。PS: 有点系统调用的意思,用户态存在一个对系统调用的 封装(glibc 函数),比如调用read 其实只是传递了一个read 系统调用号,要靠内核去执行真正的read函数。
tensornet
/core
/kernels
/sparse_table_ops.cc # kernel实现
/ops
/sparse_table_ops.cc # REGISTER_OP
/BUILD
/tensornet
/core
/gen_sparse_table_ops.py # Bazel tf_gen_op_wrapper_py生成
Python的调用方式
# tensornet/layers/embedding_features.py
from tensornet.core import gen_sparse_table_ops
pulled_mapping_values = gen_sparse_table_ops.sparse_table_pull(...)
gen_sparse_table_ops 中的定义
# tensornet/core/gen_sparse_table_ops.py
def sparse_table_pull(resources, values, table_handle, name=None):
...
_, _, _op, _outputs = _op_def_library._apply_op_helper("SparseTablePull", resources=resources, values=values,
table_handle=table_handle, name=name)
...
return _op
...
_op_def_library._apply_op_helper的作用是在graph中添加对应名字的Op节点。需要注意的是,Op的梯度计算节点并不是在这里加入到graph中的,这里仅仅加入了前向计算节点。
gen_sparse_table_ops.py 文件是在bazel构建过程中生成的,BUILD 文件内容
// 生成 生成op的lib,即so文件
cc_library(
name = "sparse_table_ops_kernels",
srcs = [
"kernels/sparse_table_ops_dummy.cc",
"ops/sparse_table_ops.cc",
],
hdrs = [
"//core/utility:semaphore",
],
linkstatic = 1,
deps = [
"@org_tensorflow//tensorflow/core:framework",
"@org_tensorflow//tensorflow/core:lib",
"@org_tensorflow//tensorflow/core:protos_all_cc",
],
alwayslink = 1,
)
// 生成python的接口,即gen_sparse_table_ops.py 文件
tf_gen_op_wrapper_py(
name = "sparse_table_ops",
deps = [":sparse_table_ops_kernels"],
cc_linkopts = ['-lrt']
)
Op定义分析python_op_gen_main(tensorflow/python/framework/python_op_gen_main.cc)工具通过链接对应的so,得到对应的OpRegistry,从而生成对应的gen_xx_ops.py文件。
tensorflow c++ op 生成 python调用接口
TensorFlow 模型准实时更新上线的设计与实现定制好 op 后,如何替换模型计算图中原生的 op 呢?TensorFlow 在模型保存时,会生成 meta_graph_def 文件,文件内容是采用类似 json 的格式描述计算图的结构关系。当加载此文件时,TensorFlow 会根据文件中描述的结构信息构建出计算图。可以修改模型保存的 meta_graph_def 文件,将其中的 op 替换为我们定制的 op,同时修改每个 node 的 input 和 output 关系,以修改 op 之间的依赖关系。PS: 当然这里说的替换原有的op
留下评论