跨主机容器通信
简介
调试Kubernetes集群中的网络停顿问题顶级文章,建议多次拜读。
容器网络是Kubernetes最复杂部分,同时也是设计精华所在:
- 对于相同宿主机共享底层硬件设备问题,通常是借助虚拟化技术来实现,通过虚拟设备来实现灵活的管理,再将虚拟化设备连接到真实的物理设备上实现网络通信;
- 对于跨宿主机网络通信问题,采用SDN软件定义网络的思路,灵活使用底层网络通信协议,同时结合各种虚拟化隧道通信技术,实现容器集群内外部通信。
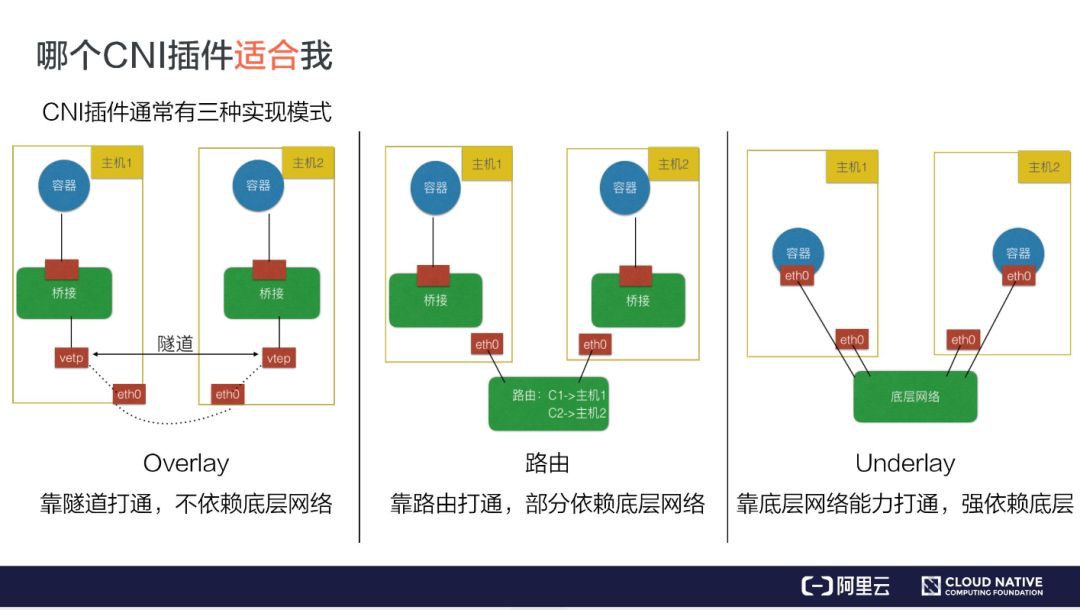
Macvlan和IPvlan基础知识运行裸机服务器时,主机网络可以很简单,只需很少的以太网接口和提供外部连接的默认网关。但当我们在一个主机中运行多个虚拟机时,需要在主机内和跨主机之间提供虚拟机之间的连接。一般,单个主机中的VM数量不超过15-20个。但在一台主机上运行Containers时,单个主机上的Containers数量很容易超过100个,需要有成熟的机制来实现Containers之间的网络互联。概括地说,容器或虚拟机之间有两种通信方式。在底层网络方法中,虚拟机或容器直接暴露给主机网络,Bridge、macvlan和ipvlan网络驱动程序都可以做到。在Overlay网络方法中,容器或VM网络和底层网络之间存在额外的封装形式,如VXLAN、NVGRE等。
容器的一个诉求:To make a VM mobile you want to be able to move it’s physical location without changing it’s apparent network location.
|网络方案|网络上跑的什么包|辅助机制|优缺点|
|—|—|—|—|
|基于docker单机|NAT包/目的ip变为物理机|
|overlay+隧道|封装后的udp包|解封包进程
就像运行vpn要启动一个进程才能登陆公司内网一样|不依赖底层网络
就像你的电脑连上网就可以连公司的vpn|
|overlay+路由|主机路由后的包/目的mac变为物理机
容器所在物理机上一堆路由表(主要是直接路由)让物理机变为了一个路由器|直接路由机制需要二层连通|
|underlay|原始数据包|linux相关网络驱动
网络设备支持|性能最好
强依赖底层网络|
笔者最惊喜的就是以“网络上跑的什么包” 来切入点来梳理 容器网络模型。
docker 单机
怎么从传统的Linux网络视角理解容器网络?单主机容器网络是已知的Linux功能的简单组合,并且不需要任何代码就可以让这样的网络魔法发生。
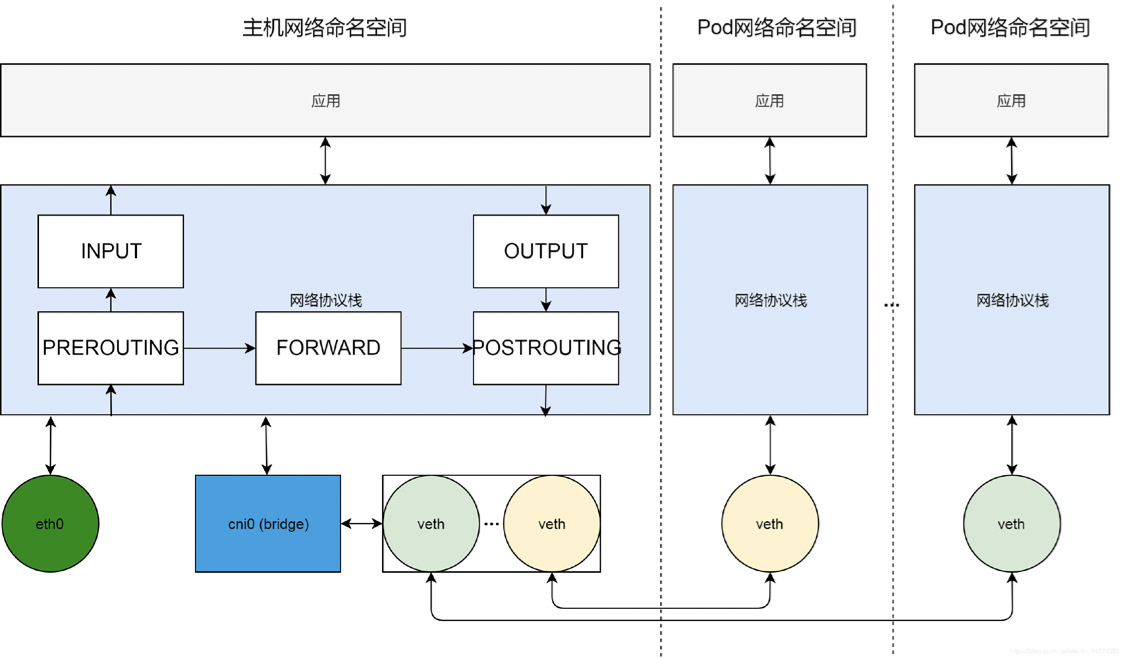
Kubernetes 网络模型进阶容器网络发端于 Docker 的网络。Docker 使用了一个比较简单的网络模型,即内部的网桥加内部的保留 IP。这种设计的好处在于容器的网络和外部世界是解耦的,无需占用宿主机的 IP 或者宿主机的资源,完全是虚拟的。
它的设计初衷是:当需要访问外部世界时,会采用 SNAT 这种方法来借用 Node 的 IP 去访问外面的服务。比如容器需要对外提供服务的时候,所用的是 DNAT 技术,也就是在 Node 上开一个端口,然后通过 iptable 或者别的某些机制,把流导入到容器的进程上以达到目的。简称:出宿主机采用SNAT借IP,进宿主机用DNAT借端口。
该模型的问题在于:网络中一堆的NAT 包,外部网络无法区分哪些是容器的网络与流量、哪些是宿主机的网络与流量。
由于网桥是虚拟的二层设备,同节点的 Pod 之间通信直接走二层转发,跨节点通信才会经过宿主机 eth0
Kubernetes IP-per-pod model
深入理解 Kubernetes 网络模型 - 自己实现 kube-proxy 的功能主机A上的实例(容器、VM等)如何与主机B上的另一个实例通信?有很多解决方案:
- 直接路由: BGP等
- 隧道: VxLAN, IPIP, GRE等。
- ipip:利用了Linux 的tun/tap设备,在 IP 头部外面再包上一层 IP 头部实现的一种overlay模式。
- gre: 主机互相维护对端的隧道地址
- vxlan 通过主机的内核路由
- NAT: 例如docker的桥接网络模式
- 其它方式
Rather than prescribing a certain networking solution, Kubernetes only states three fundamental requirements:
- Containers can communicate with all other containers without NAT.
- Nodes can communicate with all containers (and vice versa) without NAT.
- The IP a container sees itself is the same IP as others see it. each pod has its own IP address that other pods can find and use. 很多业务启动时会将自己的ip 发出去(比如注册到配置中心),这个ip必须是外界可访问的。 学名叫:flat address space across the cluster.
Kubernetes requires each pod to have an IP in a flat networking namespace with full connectivity to other nodes and pods across the network. This IP-per-pod model yields a backward-compatible way for you to treat a pod almost identically to a VM or a physical host(ip-per-pod 的优势), in the context of naming, service discovery, or port allocations. The model allows for a smoother transition from non–cloud native apps and environments. 这样就 no need to manage port allocation
Kubernetes 网络大致分为两大类,使用不同的技术
- 一类是 Cluster IP,是一层反向代理的虚拟ip;service/ingress,早期 kube-proxy 是采用 iptables,后来引入 IPVS 也解决了大规模容器集群的网络编排的性能问题。
- 一类是 Pod IP,容器间交互数据
针对docker 跨主机通信时网络中一堆的NAT包,Kubernetes 提出IP-per-pod model ,这个 IP 是真正属于该 Pod 的,对这个 Pod IP 的访问就是真正对它的服务的访问,中间拒绝任何的变造。比如以 10.1.1.1 的 IP 去访问 10.1.2.1 的 Pod,结果到了 10.1.2.1 上发现,它实际上借用的是宿主机的 IP,而不是源 IP,这样是不被允许的。在通信的两端Pod看来,以及整个通信链路中<source ip,source port,dest ip,dest port> 是不能改变的。设计这个原则的原因是,用户不需要额外考虑如何建立Pod之间的连接,也不需要考虑如何将容器端口映射到主机端口等问题。
Kubernetes 对怎么实现这个模型其实是没有什么限制的,用 underlay 网络来控制外部路由器进行导流是可以的;如果希望解耦,用 overlay 网络在底层网络之上再加一层叠加网,这样也是可以的。总之,只要达到模型所要求的目的即可。因为<source ip,source port,dest ip,dest port>不能变,排除NAT/DAT,其实也就只剩下路由和解封包两个办法了。
跨主机通信
Kubernetes 网络模型基础指南通常集群中的每个节点都分配有一个 CIDR,用来指定该节点上运行的 Pod 可用的 IP 地址。一旦以 CIDR 为目的地的流量到达节点(xx技术),节点就会将流量转发到正确的 Pod(xx技术)。换个说法,如果要求所有 Pod 具有 IP 地址,那么就要确保整个集群中的所有 Pod 的 IP 地址是唯一的。这可以通过为每个节点分配一个唯一的子网(podCIDR)来实现,即从子网中为 Pod 分配节点 IP 地址。从 podCIDR 中的子网值为节点上的 Pod 分配了 IP 地址。由于所有节点上的 podCIDR 是不相交的子网,因此它允许为每个 pod 分配唯一的IP地址。PS:理解 overlay 方案的核心就是 每个node 多有一个cidr,进而每个node 可以根据目的pod ip 找到其所在node。
2020.4.18补充:很多文章都是从跨主机容器如何通信 的来阐述网络方案,这或许是一个很不好的理解曲线,从实际来说,一定是先有网络,再为Pod “连上网”。
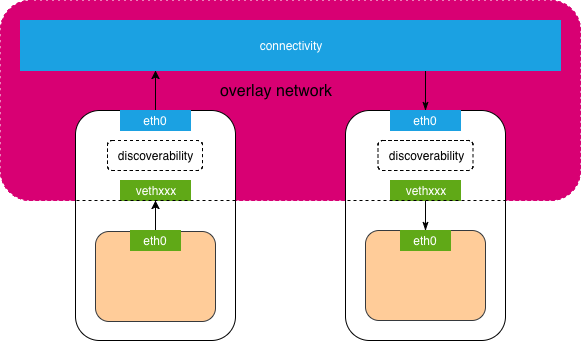
Network是一组可以相互通信的Endpoints,网络提供connectivity and discoverability.
there are two ways for Containers or VMs to communicate to each other.
- In Underlay network approach, VMs or Containers are directly exposed to host network. Bridge, macvlan and ipvlan network drivers are examples of this approach.
- In Overlay network approach, there is an additional level of encapsulation like VXLAN, NVGRE between the Container/VM network and the underlay network
一个容器的包所要解决的问题分为两步:第一步,如何从容器的空间 (c1) 跳到宿主机的空间 (infra);第二步,如何从宿主机空间到达远端。容器网络的方案可以通过接入、流控、通道这三个层面来考虑。
从容器的空间 跳到宿主机的空间
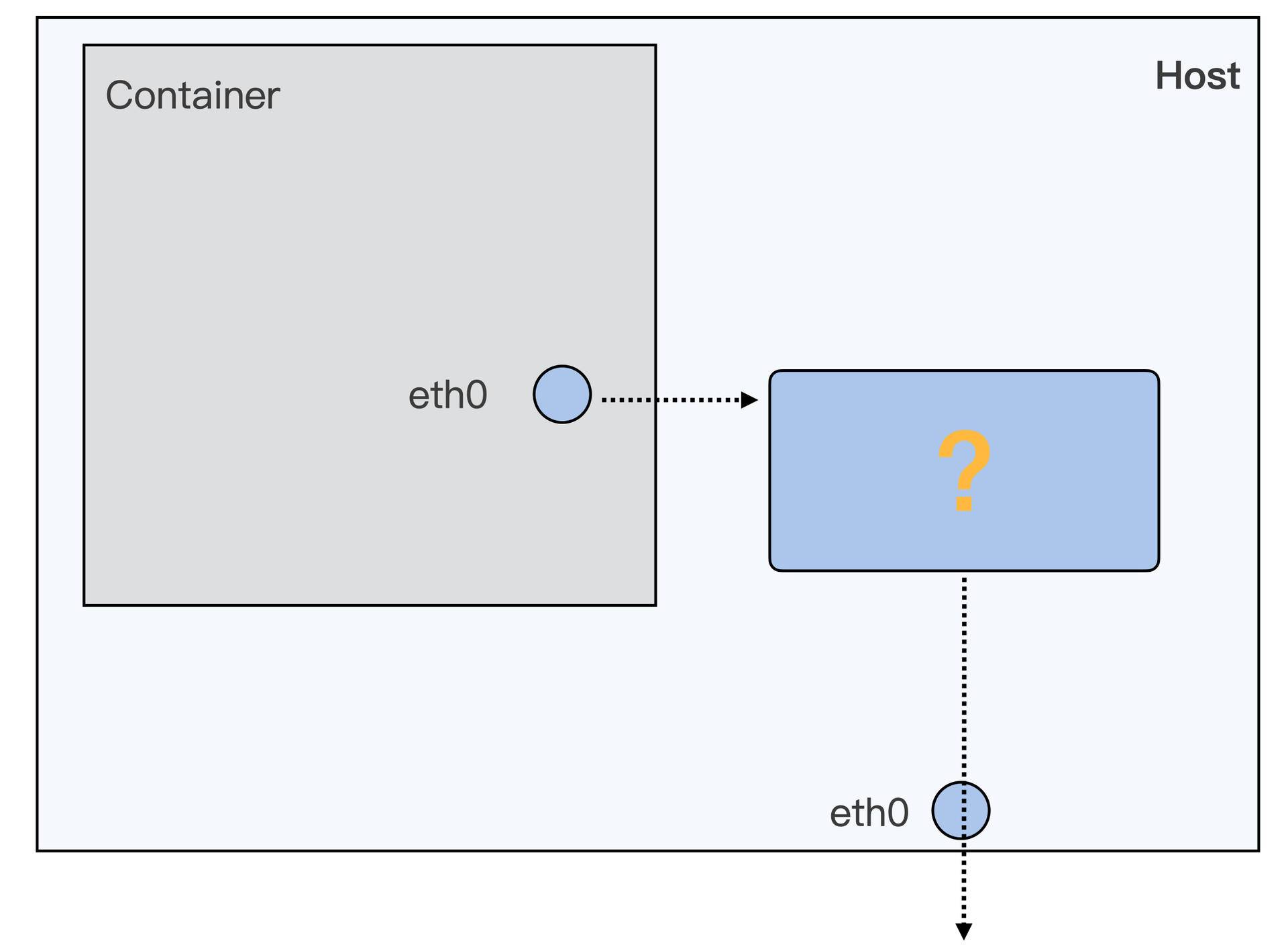
接入,就是说我们的容器和宿主机之间是使用哪一种机制做连
- Veth + bridge、Veth + pair 这样的经典方式
- 利用高版本内核的新机制等其他方式(如 mac/IPvlan 等),来把包送入到宿主机空间;
数据包到了 Host Network Namespace 之后呢,怎么把它从宿主机上的 eth0 发送出去?
- nat。比如容器地址是 172.16.0.2,这是个内网地址。往出发包可以找到目的 IP,但是响应回来的时候公网上可找不到你这个内网地址。所以这里我们需要进行 NAT 转换技术,简单说就是先把你的内网 IP 转变成网卡的公网 IP,发出去,等响应数据包回来时,再把公网 IP 转变成内网 IP,在主机内流转到你的容器中的虚拟网卡上。实际上一般云服务器网卡的 ip 地址( 比如10.0.24.5) 仍然是个内网 ip,需要经过云服务提供商的一个更大层面的路由器 NAT 之后才能走到真正的外网环境。
- 建立 Overlay 网络发送
- 通过配置 proxy arp 加路由的方法来实现。
宿主机之间
- 通道,即两个主机之间通过什么方式完成包的传输。我们有很多种方式,比如以路由的方式,具体又可分为 BGP 路由或者直接路由。还有各种各样的隧道技术等等。最终我们实现的目的就是一个容器内的包通过容器,经过接入层传到宿主机,再穿越宿主机的流控模块(如果有)到达通道送到对端。
- 流控,就是说我的这个方案要不要支持 Network Policy,如果支持的话又要用何种方式去实现。这里需要注意的是,我们的实现方式一定需要在数据路径必经的一个关节点上。如果数据路径不通过该 Hook 点,那就不会起作用;
overlay / underlay
在云网络的语境中
- Underlay 底层网络是云网络的物理基础,它通常由一系列的物理网络设备,如路由器、交换机、光纤线缆等构成,是实实在在存在于数据中心或网络基础设施中的硬件连接部分。
- Overlay 覆盖网络是构建在 Underlay 底层网络之上的虚拟网络,它通过软件和虚拟化技术实现,对底层物理网络资源进行抽象和整合,从而创建出逻辑上独立、隔离的虚拟网络环境,类似于在已有的道路(Underlay 网络)基础上,通过规划不同的行车路线、设置特殊标识等方式构建出专属于某些车辆类型(不同虚拟网络)的虚拟交通网络。可以实现多租户之间的网络隔离,不同租户在云环境中虽然共用底层的物理网络设备,但通过 Overlay 网络能拥有各自独立、安全的虚拟网络空间,彼此的数据不会相互干扰。
overlay网络
overlay 网络主要有隧道 和 路由两种方式
- 容器网卡不能直接发送/接收数据,而要通过双方容器所在宿主机网卡发送/接收数据
- “容器在哪个主机上“ 这个信息都必须专门维护。kubectl 创建 Pod 背后到底发生了什么?overlay 网络是一种动态同步多个主机间路由的方法。
- 容器内数据包必须先发送目标容器所在的宿主机上(通过linux 路由机制或者 发送者node 专门进程 发给 目的node 专门进程),那么容器内原生的数据包便要进行改造(解封包或根据路由更改目标mac)
- 数据包到达目标宿主机上之后,目标宿主机要进行一定的操作转发到目标容器。
覆盖网络如何解决connectivity and discoverability?connectivity由物理机之间解决,discoverability由容器在物理机侧的veth 与 宿主机eth 之间解决,一般由主机上网络协议栈具体负责(一般网络组件除解封包外,不参与通信过程,只是负责向网络协议栈写入routes和iptables)。
封包方式
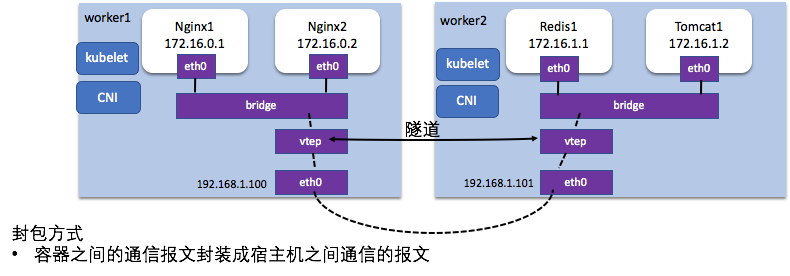
隧道一般用到了解封包,那么问题来了,谁来解封包?怎么解封包?
| overlay network | 包格式 | 解封包设备 | 要求 |
|---|---|---|---|
| flannel + udp | ip数据包 package | flanneld 更新路由 + tun 解封包 | 宿主机三层连通 |
| flannel + vxlan | 二层数据帧 Ethernet frame | flanneld 更新路由 + VTEP解封包 | 宿主机二层互通 |
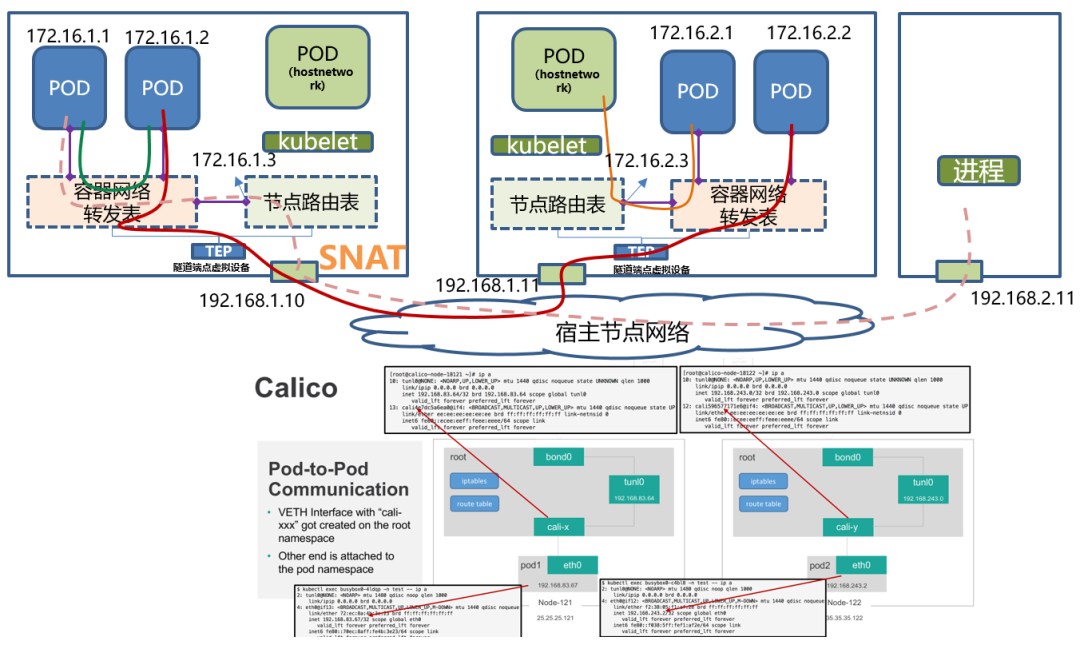
| calico + ipip | ip数据包 package | bgp 更新路由 + tunl0 解封包 | 宿主机三层连通 |
flannel + udp 和flannel + vxlan 有一个共性,那就是用户的容器都连接在 docker0网桥上。而网络插件则在宿主机上创建了一个特殊的设备(UDP 模式创建的是 TUN 设备,VXLAN 模式创建的则是 VTEP 设备),docker0 与这个设备之间,通过 IP 转发(路由表)进行协作。然后,网络插件真正要做的事情,则是通过某种方法,把不同宿主机上的特殊设备连通,从而达到容器跨主机通信的目的。
Flannel 支持三种后端实现,分别是: VXLAN;host-gw; UDP。而 UDP 模式,是 Flannel 项目最早支持的一种方式,也是性能最差的一种方式。所以,这个模式目前已经被弃用。我们在进行系统级编程的时候,有一个非常重要的优化原则,就是要减少用户态到内核态的切换次数,并且把核心的处理逻辑都放在内核态进行。这也是为什么,Flannel 后来支持的VXLAN 模式,逐渐成为了主流的容器网络方案的原因。图解 VXLAN 容器网络通信方案
路由方式
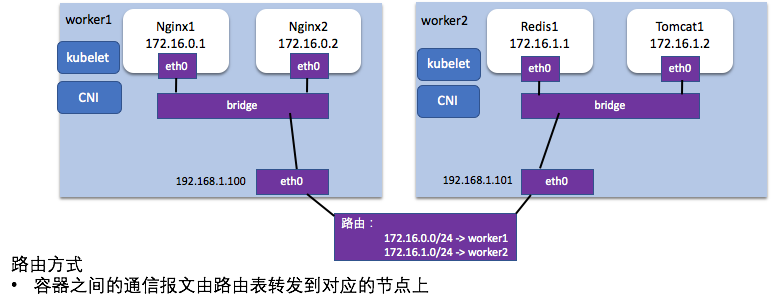
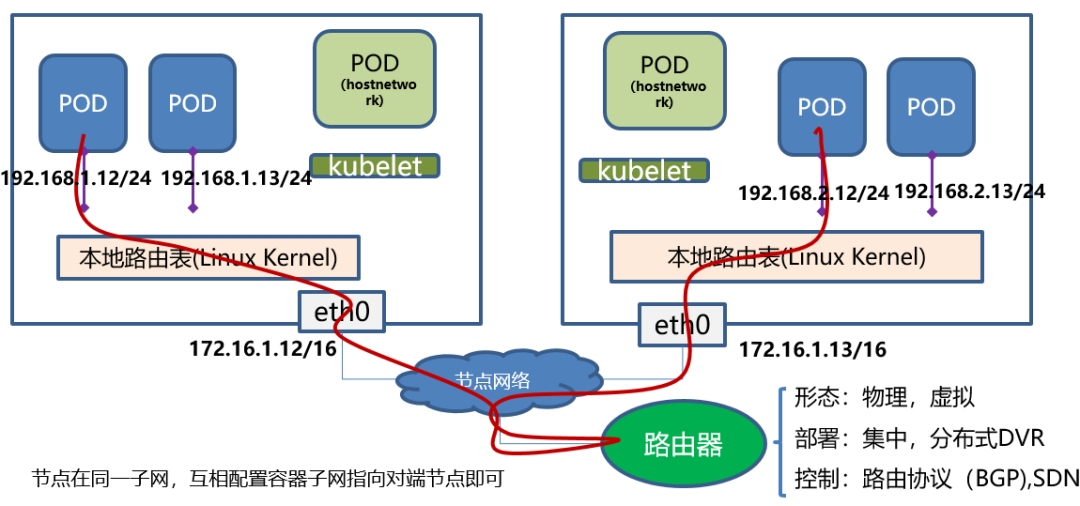
容器互通主要基于路由表打通,把路由表分发到子网的每一台物理主机,所有的物理主机都拥有整个容器网络的路由数据。这样当跨主机访问容器时,Linux 主机可以根据自己的路由表得知,该容器具体位于哪台物理主机之中,从而直接将数据包转发过去。路由网络要求要么所有主机都位于同一个子网之内,都是二层连通的;要么不同二层子网之间由支持边界网关协议(Border Gateway Protocol,BGP)的路由相连,并且网络插件也同样支持 BGP 协议去修改路由表。
一般配套设计是 一个物理机对应一个网段。路由方案的关键是谁来路由?路由信息怎么感知?路由信息存哪?Kubernetes/etcd/每个主机bgp分发都来一份。calico 容器在主机内外都通过 路由规则连通(主机内不会创建网桥设备);flannel host-gw 主机外靠路由连通,主机内靠网桥连通。
| overlay network | 路由设备 | 路由更新 | 要求 |
|---|---|---|---|
| flannel + host-gw | 宿主机 | flanneld | 宿主机二层连通 |
| calico + Node-to-Node Mesh | 宿主机 | bgp 更新路由 | 宿主机二层连通 |
| calico + 网关bgp | 网关 | bgp 更新路由 | 宿主机三层连通 |
-
flannel + udp/flannel + vxlan(tcp数据包),udp 和tcp 数据包首部大致相同 从 Flannel 学习 Kubernetes overlay 网络
frame header frame body host1 mac host2 mac container1 mac container2 mac container1 ip container1 ip body -
flannel + host-gw/calico
frame header frame body container1 mac host2 mac container1 ip container2 ip body
A container networking overview How do routes get distributed?Every container networking thing to runs some kind of daemon program on every box which is in charge of adding routes to the route table.
There are two main ways they do it:
- the routes are in an etcd cluster, and the program talks to the etcd cluster to figure out which routes to set
- use the BGP protocol to gossip to each other about routes, and a daemon (BIRD) listens for BGP messages on every box
容器所在主机的路由表 让linux 主机变成了一个路由器,路由表主要由直接路由构成,将数据包中目的mac 改为直接路由中下一跳主机 的mac 地址。
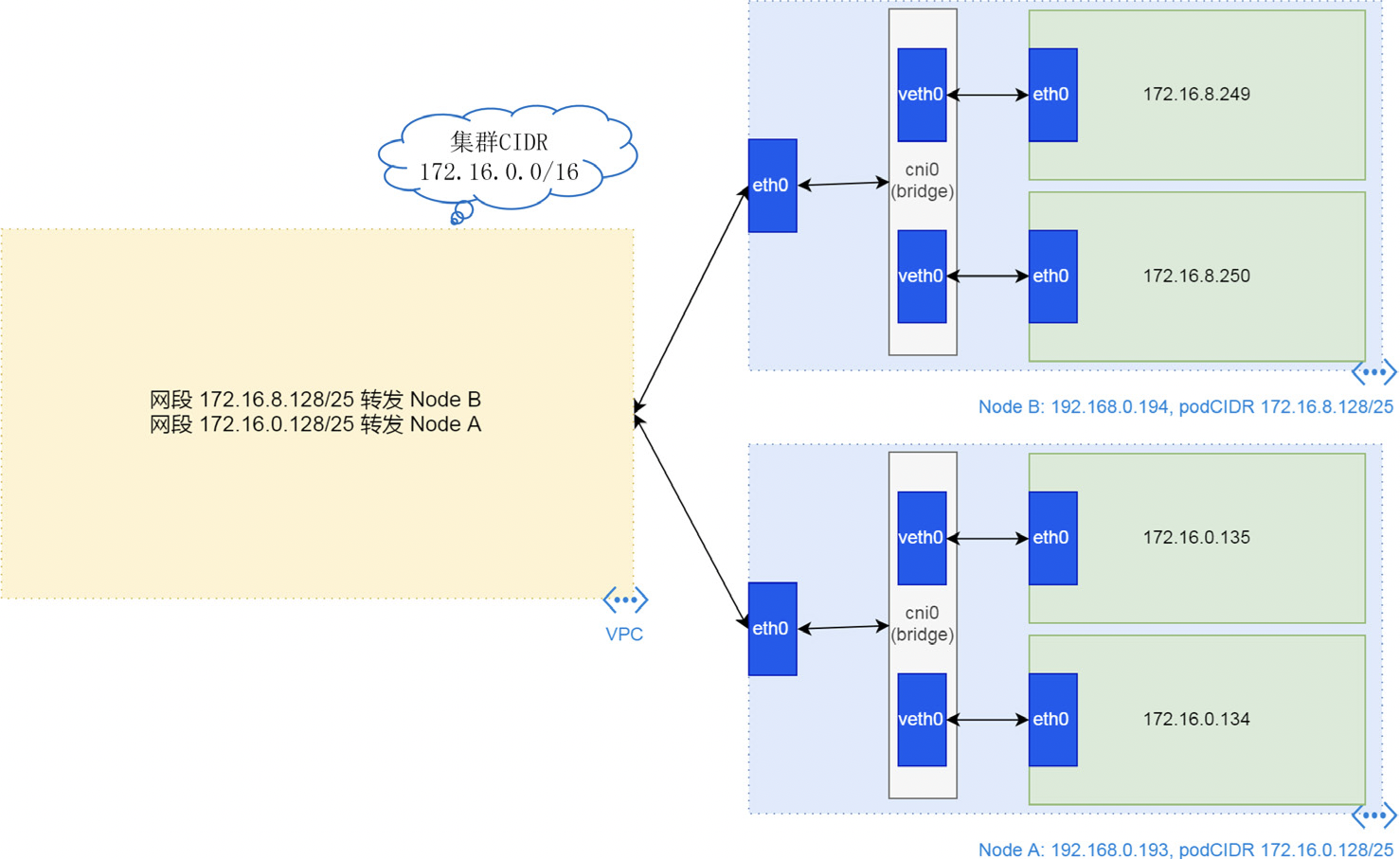
underlay/physical 网络
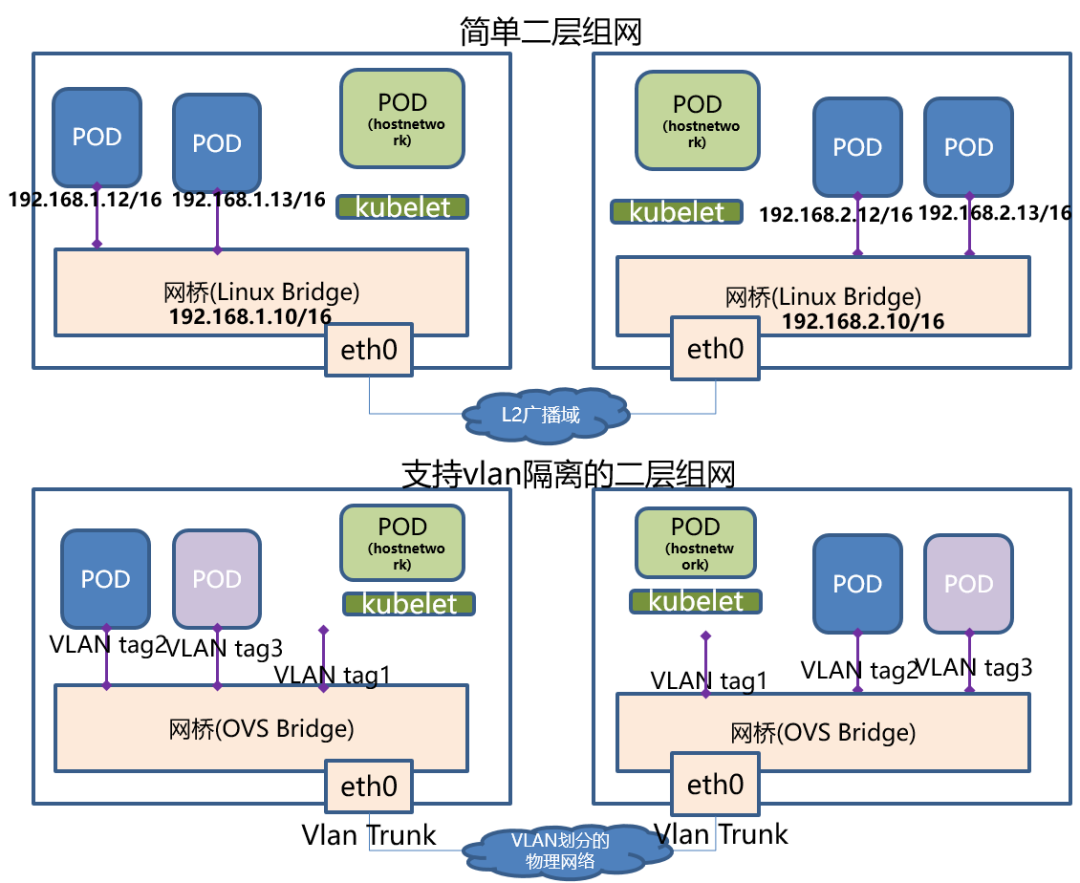
这里的 Underlay 模式特指让容器和宿主机处于同一网络,两者拥有相同的地位的网络方案。Underlay 网络要求容器的网络接口能够直接与底层网络进行通信,因此这个 ** 模式是直接依赖于虚拟化设备与底层网络能力的。可以直接在硬件层面虚拟多张网卡,并且以硬件直通(Passthrough)的形式,交付给容器使用。
| 容器的网卡 来自哪里? | 真正与外界通信的网卡是哪个? external connectivity | 容器与物理机网卡的关系及数据连通 | |
|---|---|---|---|
| bridge | veth | 物理机网卡 | veth pair 挂在bridge上,NAT 连通 物理机网卡 |
| macvlan | macvlan sub-interfaces | macvlan sub-interfaces | |
| ipvlan | ipvlan sub-interfaces | ipvlan sub-interfaces |
阿里云如何构建高性能云原生容器网络?云原生容器网络是直接使用云上原生云资源配置容器网络:
- 容器和节点同等网络平面,同等网络地位;
- Pod 网络可以和云产品无缝整合;
- 不需要封包和路由,网络性能和虚机几乎一致。
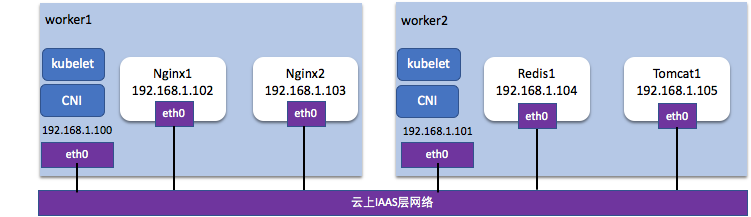
配图
网络隔离
Kubernetes 对 Pod 进行“隔离”的手段,即:NetworkPolicy,NetworkPolicy 实际上只是宿主机上的一系列 iptables 规则。在具体实现上,凡是支持 NetworkPolicy 的 CNI 网络插件,都维护着一个 NetworkPolicy Controller,通过控制循环的方式对 NetworkPolicy 对象的增删改查做出响应,然后在宿主机上完成 iptables 规则的配置工作。
留下评论