基于k8s的工作流
简介
看似非常碎片化和复杂的各类应用交付与管理场景,其背后确实是有一个非常本质的基础模型存在的。这个基础模型就是“工作流”。
Kruise Rollout:灵活可插拔的渐进式发布框架 K8s 当中所有的 Pod 都是由工作负载来管理的,其中最常见的两个工作负载就是 Deployment 和 statefulset。Deployment 对于升级而言提供了 maxUnavailable 和 maxSurge 两个参数,但是本质上来讲 Deployment 它只支持流式的一次性发布,用户并不能控制分批。StatefulSet 虽然支持分批,但是跟我们想要的渐进式发布的能力还有比较大的距离。
当我们说到工作流时,一般涉及到几个问题
- 一个workflow 对象代表一个工作流,workflow 里包含多个step,step 记录了上游和下游step
- 一个执行引擎 按照拓扑排序 执行workflow下的step,需要采集step的运行状态,并将上游step的运行结果传递给下游,一般情况下,一个step失败即终止整个workflow 并标记workflow 失败,也可能有其他成功、失败策略。
- step 可以是一些预定义的工作,也可以是一些自定义工作。一般用代码实现,有时也支持dsl(这就要求附带一个dsl引擎)。可以由一个pod封装运行,或者其它workload(比如tfjob、 vcjob等),或者controller 本身直接触发执行(按约定的模版编写逻辑)。 一个常规的workflow工具,要提供workflow与step抽象,包括step的形式(pod等workload或其它dsl,如果有一个dsl引擎的话),step之间的依赖关系,采集step的运行状态、结果传给下一个step,某个step的成功、失败策略等等,越通用就越臃肿,针对具体业务域就可以相对简化一些。
其实机器学习平台 因为有明显的工作流:样本生成 ==> 训练 ==> 评估 ==> 推理,顺理成章的用上了工作流。体现在微服务的paas上,构建 ==> 灰度 ==> 集群1全量 ==> 集群2全量。 新人加入一个公司,如果没有明确的流程抽象,就要靠冗长的说明文档来操作平台了,
渐进式发布
Argo Rollout 和 Flagger
Argo Rollout 是 Argo 公司推出的 Workload,它的实现思路是:重新定义一个类似于 Deployment 的工作负载,在实现 Deployment 原有能力的基础上,又扩展了 Rollout 的相关能力。它的优点是工作负载内置了 Rollout 能力,配置简单、实现也会比较简单,并且目前支持的功能也非常的丰富,支持各种发布策略、流量灰度和 metrics 分析,是一个比较成熟的项目。但是它也存在一些问题,因为它本身就是一个工作负载,所以它不能适用于社区 Deployment,尤其是针对已经用 Deployment 部署的公司,需要一次线上迁移工作负载的工作。
Argo 为 Kubernetes 提供 container-native(工作流中的每个步骤是通过容器实现)工作流程。可以让用户用一个类似于传统的 YAML 文件定义的 DSL 来运行多个步骤的 Pipeline。该框架提供了复杂的循环、条件判断、依赖管理等功能,这有助于提高部署应用程序的灵活性以及配置和依赖的灵活性。使用 Argo,用户可以定义复杂的依赖关系,以编程方式构建复杂的工作流、制品管理,可以将任何步骤的输出结果作为输入链接到后续的步骤中去,并且可以在可视化 UI 界面中监控调度的作业任务。
另一个社区项目是 Flagger,它的实现思路跟 Argo-Rollout 完全不同。它没有单独的实现一个 workload,而是在现有 Deployment 的基础之上,扩展了流量灰度、分批发布的能力。Flagger 的优势是支持原生 Deployment 、并且与社区的 Helm、Argo-CD 等方案都是兼容的。但是也存在一些问题,首先就是发布过程中的 Double Deployment 资源的问题,因为它是先升级用户部署的 Deployment,再升级 Primary,所以在这过程中需要准备双倍的 Pod 资源。第二呢,针对一些自建的容器平台需要额外对接,因为它的实现思路是将用户部署资源都 copy 一份,且更改资源的名字以及 Label。PS:当年我也尝试过用两个Deployment 实现分批发布
Kruise Rollout
Kruise Rollout: 让所有应用负载都能使用渐进式交付
在设计 Rollout 过程中有以下几个目标:
- 无侵入性:对原生的 Workload 控制器以及用户定义的 Application Yaml 定义不进行任何修改,保证原生资源的干净、一致
- 可扩展性:通过可扩展的方式,支持 K8s Native Workload、自定义 Workload 以及 Nginx、Isito 等多种 Traffic 调度方式
- 易用性:对用户而言开箱即用,能够非常方便的与社区 Gitops 或自建 PaaS 结合使用
apiVersion: rollouts.kruise.io/v1alpha1
kind: Rollout
spec:
strategy:
objectRef: # 用于表明 Kruise Rollout 所作用的工作负载,例如:Deployment Name
workloadRef:
apiVersion: apps/v1
# Deployment, CloneSet, AdDaemonSet etc.
kind: Deployment
name: echoserver
canary: # 定义了 Rollout 发布的过程
steps:
# routing 5% traffics to the new version
- weight: 5
# Manual confirmation, release the back steps
pause: {}
# optional, The first step of released replicas. If not set, the default is to use 'weight', as shown above is 5%.
replicas: 1
- weight: 40
# sleep 600s, release the back steps
pause: {duration: 600}
- weight: 60
pause: {duration: 600}
- weight: 80
pause: {duration: 600}
# 最后一批无需配置
trafficRoutings: # 流量灰度所需要的资源 Name,例如:Service、Ingress 或 Gateway API
# echoserver service name
- service: echoserver
# nginx ingress
type: nginx
# echoserver ingress name
ingress:
name: echoserver
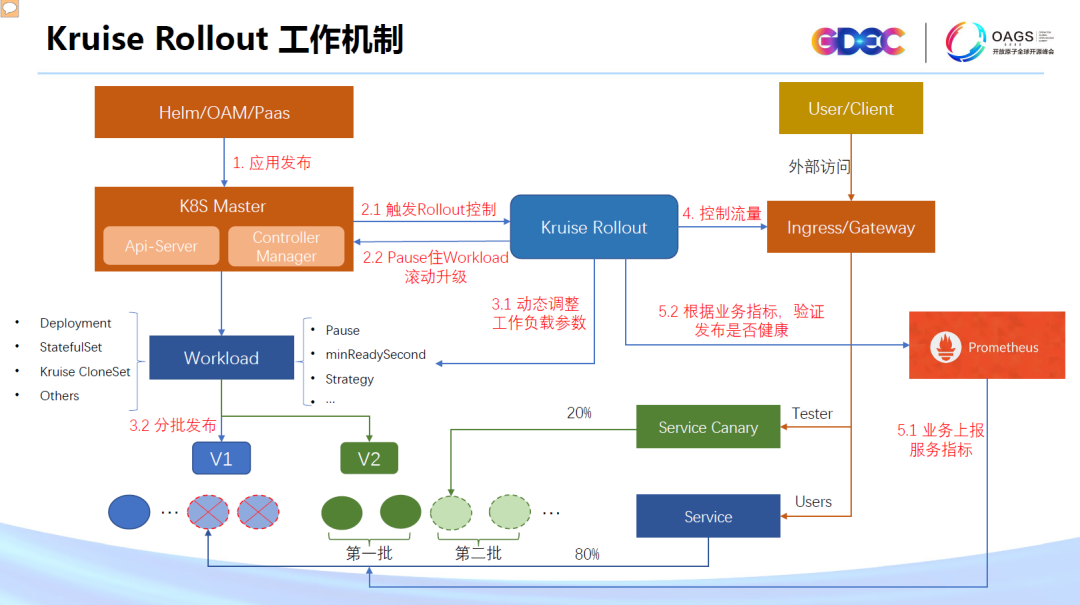
Kruise Rollout 的工作机制
- 首先,用户基于容器平台做一次版本发布(一次发布从本质上讲就是将 K8s 资源 apply 到集群中)。
- Kruise Rollout 包含一个 webhook 组件,它会拦截用户的发布请求,然后通过修改 workload strategy 的方式 Pause 住 workload 控制器的工作。
- 然后,就是根据用户的 Rollout 定义,动态的调整 workload 的参数,比如:partition,实现 workload 的分批发布。
- 等到批次发布完成后,又会调整 ingress、service 配置,将特定的流量导入到新版本。
- 最后,Kruise Rollout 还能够通过 prometheus 中的业务指标判断发布是否正常。比如说,对于一个 web 类 http 的服务,可以校验 http 状态码是否正常。
- 上面的过程,就完成了第一批次的灰度,后面的批次也是类似的。完整的 Rollout 过程结束后,kruise 会将 workload 等资源的配置恢复回来。 所以说,整个 Rollout 过程,是与现有工作负载能力的一种协同,它尽量复用工作负载的能力,又做到了非 Rollout 过程的零入侵。
kubevela workflow
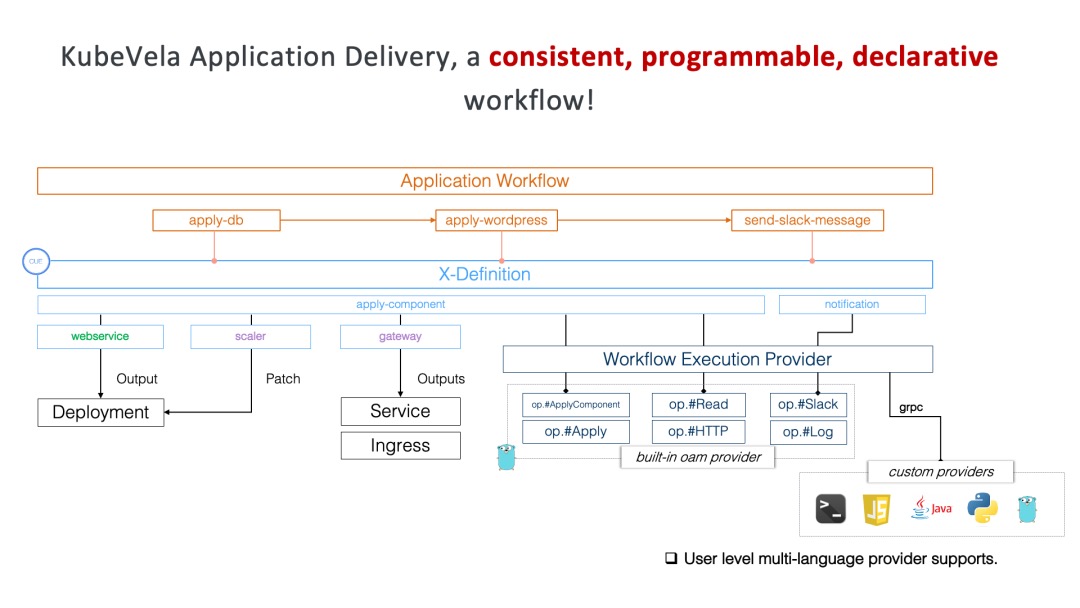
为什么要用Kubevela Workflow?因为 KubeVela Workflow 在设计上有一个非常根本的区别:工作流中的步骤面向云原生 IaC 体系设计,支持抽象封装和复用,相当于你可以直接在步骤中调用自定义函数级别的原子能力,而不仅仅是下发容器(前几个工具都只是分批灰度发布pod?)。在 KubeVela Workflow 中,每个步骤都有一个步骤类型,而每一种步骤类型,都会对应 WorkflowStepDefinition(工作流步骤定义)这个资源。你可以使用 CUE 语言(一种 IaC 语言,是 JSON 的超集) 来编写这个步骤定义,或者直接使用社区中已经定义好的步骤类型。
你可以简单地将步骤类型定义理解为一个函数声明,每定义一个新的步骤类型,就是在定义一个新的功能函数。函数需要一些输入参数,步骤定义也是一样的。在步骤定义中,你可以通过 parameter 字段声明这个步骤定义需要的输入参数和类型。当工作流开始运行时,工作流控制器会使用用户传入的实际参数值,执行对应步骤定义中的 CUE 代码,就如同执行你的功能函数一样。有了这样一层步骤的抽象,就为步骤增添了极大的可能性。
- 如果你希望自定义步骤类型,就如同编写一个新的功能函数一样,你可以在步骤定义中直接通过 import 来引用官方代码包,从而将其他原子能力沉淀到步骤中,包括 HTTP 调用,在多集群中下发,删除,列出资源(crd 的crud),条件等待,等等。这也意味着,通过这样一种可编程的步骤类型,你可以轻松对接任意系统
- 如果你只希望使用定义好的步骤,那么,就如同调用一个封装好的第三方功能函数一样,你只需要关心你的输入参数,并且使用对应的步骤类型就可以了。如,一个典型的构建镜像场景。首先,指定步骤类型为 build-push-image,接着,指定你的输入参数:构建镜像的代码来源与分支,构建后镜像名称以及推送到镜像仓库需要使用的秘钥信息。
apiVersion: core.oam.dev/v1alpha1 kind: WorkflowRun metadata: name: build-push-image namespace: default spec: workflowSpec: steps: - name: build-push type: build-push-image properties: context: git: github.com/FogDong/simple-web-demo branch: main image: fogdong/simple-web-demo:v1 credentials: image: name: image-secret
在这样一种架构下,步骤的抽象给步骤本身带来了无限可能性。当你需要在流程中新增一个节点时,你不再需要将业务代码进行“编译-构建-打包”后用 Pod 来执行逻辑,只需要修改步骤定义中的配置代码,再加上工作流引擎本身的编排控制能力,就能够完成新功能的对接。在可扩展的基础之上,才能充分借助和发挥生态的力量,加速产品的升级。在工作流中,每个步骤的步骤类型都是可复用的。这也意味着,当你开发新步骤类型时,你也在为下一次,下下次的新功能上线打下了基础。PS:有点Makefile target的感觉
Control the delivery process of multiple applications
apiVersion: core.oam.dev/v1alpha1
kind: WorkflowRun
metadata:
name: apply-applications
namespace: default
annotations:
workflowrun.oam.dev/debug: "true"
spec:
workflowSpec:
steps:
- name: check-app-exist ## 查看 webservice-app
type: read-app
properties:
name: webservice-app
- name: apply-app1
type: apply-app
if: status["check-app-exist"].message == "Application not found" # 如果 webservice-app 不存在 部署 webservice-app
properties:
data:
apiVersion: core.oam.dev/v1beta1
kind: Application
metadata:
name: webservice-app
spec:
components:
- name: express-server
type: webservice
properties:
image: crccheck/hello-world
ports:
- port: 8000
- name: suspend # 暂停,除非手动操作 vela workflow resume apply-applications 恢复
type: suspend
timeout: 24h
- name: apply-app2
type: apply-app
properties:
ref:
name: my-app
key: application
type: configMap
KubeVela Workflow 也提供了一个可视化的 Dashboard,运维人员只需要配置一次流水线模板,之后就可以通过触发执行,或者在每次触发执行时传入特定的运行时参数,来完成流程的自动化。
虽然OAM定义了应用程序的组成,但在实际情况下,组成部分的交付过程仍然可能有很大的差异。例如,一个应用程序中的不同组件可能具有相互依赖或数据传递,其交付步骤必须按特定顺序执行。此外,交付过程有时还涉及除资源交付之外的更多操作,例如升级或通知。因此,一个可扩展的工作流被设计了出来,以满足 KubeVela 中流程定制的需求。与组件和特征一样,KubeVela 工作流程也利用 CUE 来定义工作流程步骤,提供了灵活性、可扩展性和可编程性。它可以被视为基础设施即代码(IaC)的另一种形式。与 KubeVela 中的组件和特征定义不同,工作流步骤定义不会将模板渲染成资源。相反,它描述了在步骤中要执行的操作,该操作调用各种提供程序中的底层原子函数。
kubevela workflow 源码分析
workflow
/cmd
/main.go
/controllers
/workflowrun_controller.go
/pkg
/cue # cue相关处理逻辑
/executor # executor 执行引擎
/tasks # 内置或自定义 step
/builtin
/custom
/template
/discover.go
Reconcile逻辑
缘起 WorkflowRun 的Reconcile,先将 WorkflowRun 转为 WorkflowInstance,然后基于WorkflowInstances 生成taskRunners(一个Workflow Step对应一个taskRunner),最后由executor 执行taskRunners。
// workflow/controllers/workflowrun_controller.go
func (r *WorkflowRunReconciler) Reconcile(ctx context.Context, req ctrl.Request) (ctrl.Result, error) {
run := new(v1alpha1.WorkflowRun)
r.Get(ctx, client.ObjectKey{Name: req.Name,Namespace: req.Namespace,}, run)
instance, err := generator.GenerateWorkflowInstance(ctx, r.Client, run)
runners, err := generator.GenerateRunners(logCtx, instance, types.StepGeneratorOptions{
PackageDiscover: r.PackageDiscover,
Client: r.Client,
})
executor := executor.New(instance, r.Client)
state, err := executor.ExecuteRunners(logCtx, runners)
isUpdate = isUpdate && instance.Status.Message == ""
run.Status = instance.Status
run.Status.Phase = state
switch state {
case v1alpha1.WorkflowStateSuspending:
case v1alpha1.WorkflowStateFailed:
case v1alpha1.WorkflowStateTerminated:
case v1alpha1.WorkflowStateExecuting:
case v1alpha1.WorkflowStateSucceeded:
case v1alpha1.WorkflowStateSkipped:
}
return ctrl.Result{}, nil
}
task 生成
// workflow/pkg/types/types.go
type WorkflowInstance struct {
WorkflowMeta
OwnerInfo []metav1.OwnerReference
Debug bool
Context map[string]interface{}
Mode *v1alpha1.WorkflowExecuteMode
Steps []v1alpha1.WorkflowStep
Status v1alpha1.WorkflowRunStatus
}
// workflow/pkg/types/types.go
type TaskRunner interface {
Name() string
Pending(ctx monitorContext.Context, wfCtx wfContext.Context, stepStatus map[string]v1alpha1.StepStatus) (bool, v1alpha1.StepStatus)
Run(ctx wfContext.Context, options *TaskRunOptions) (v1alpha1.StepStatus, *Operation, error)
}
一个workflow由多个step组成,每个step 有name/type/if/timeout/dependsOn/inputs/outputs/properties 等属性(对应 WorkflowStep struct),之后将 WorkflowStep 转为 TaskRunner,由executor 驱动执行。
// workflow/pkg/generator/generator.go
func GenerateRunners(ctx monitorContext.Context, instance *types.WorkflowInstance,...) ([]types.TaskRunner, error) {
taskDiscover := tasks.NewTaskDiscover(ctx, options)
var tasks []types.TaskRunner
for _, step := range instance.Steps {
opt := &types.TaskGeneratorOptions{...}
task, err := generateTaskRunner(ctx, instance, step, taskDiscover, opt, options)
tasks = append(tasks, task)
}
return tasks, nil
}
func generateTaskRunner(ctx context.Context,instance *types.WorkflowInstance,step v1alpha1.WorkflowStep,...) (types.TaskRunner, error) {
if step.Type == types.WorkflowStepTypeStepGroup {
...
}
genTask, err := taskDiscover.GetTaskGenerator(ctx, step.Type)
task, err := genTask(step, options)
return task, nil
}
基于自定义cue模版生成task
示例demo yaml 中的 read-app/apply-app/suspend 都是一个task type,有些是builtin的,有些是自定义扩展实现的。buildin的比较简单,直接实现了TaskRunner 接口方法,初始化taskDiscover时直接写入,custom 则由 TaskLoader 负责管理
// workflow/pkg/tasks/discover.go
type taskDiscover struct {
builtin map[string]types.TaskGenerator
customTaskDiscover *custom.TaskLoader
}
func NewTaskDiscover(ctx monitorContext.Context, options types.StepGeneratorOptions) types.TaskDiscover {
return &taskDiscover{
builtin: map[string]types.TaskGenerator{
types.WorkflowStepTypeSuspend: builtin.Suspend,
types.WorkflowStepTypeStepGroup: builtin.StepGroup,
},
customTaskDiscover: custom.NewTaskLoader(options.TemplateLoader.LoadTemplate, options.PackageDiscover, ...),
}
}
func (td *taskDiscover) GetTaskGenerator(ctx context.Context, name string) (types.TaskGenerator, error) {
tg, ok := td.builtin[name] // 如果是自建的则直接返回
if ok {
return tg, nil
}
if td.customTaskDiscover != nil { // 否则从custom 里寻找
tg, err = td.customTaskDiscover.GetTaskGenerator(ctx, name)
return tg, nil
}
return nil, errors.Errorf("can't find task generator: %s", name)
}
对于自定义 task type,从 static 目录里扫描模版文件,如果还找不到,查询对应type 的WorkflowStepDefinition 中拿到cue 模版文件。
TaskLoader.GetTaskGenerator(ctx, name) # 此处的name值为step.Type
templ, err := WorkflowStepLoader.LoadTemplate
files, err := templateFS.ReadDir(templateDir)
staticFilename := name + ".cue"
for _, file := range files { # 找到对应的cue模版文件
if staticFilename == file.Name() {
fileName := fmt.Sprintf("%s/%s", templateDir, file.Name())
content, err := templateFS.ReadFile(fileName)
return string(content), err
}
}
getDefinitionTemplate
definition := &unstructured.Unstructured{}
definition.SetAPIVersion("core.oam.dev/v1beta1")
definition.SetKind("WorkflowStepDefinition")
cli.Get(ctx, types.NamespacedName{Name: definitionName, Namespace: ns}, definition)
d := new(def)
runtime.DefaultUnstructuredConverter.FromUnstructured(definition.Object, d)
d.Spec.Schematic.CUE.Template
TaskLoader.makeTaskGenerator(templ)
return func(...)(TaskRunner,error){
paramsStr, err := GetParameterTemplate(wfStep) # 从 WorkflowStep 获取用户参数
tRunner := new(taskRunner)
tRunner.name = wfStep.Name
tRunner.checkPending = ...
tRunner.run = ...
return tRunner, nil
}
workflowSpec.step 有type 和properties 等参数,WorkflowStepDefinition 有对应type的cue template 文件,两相结合先把cue template中的参数替换成真实值,再根据cue 生成taskRunner 的Run方法。这里涉及到cue 包里的细节,还未深研究,其核心意图是:通过cue 代码(感觉也是dsl的一种)表述意图 + WorkflowStepDefinition 来支持自定义step type。PS: 估计是觉得通过代码方式扩展step type太慢了。
// workflow/pkg/tasks/custom/task.go
func(ctx wfContext.Context, options *types.TaskRunOptions) (stepStatus v1alpha1.StepStatus, operations *types.Operation, rErr error) {
basicVal, basicTemplate, err := MakeBasicValue(tracer, ctx, t.pd, wfStep.Name, exec.wfStatus.ID, paramsStr, options.PCtx)
var taskv *value.Value
for _, hook := range options.PreCheckHooks {...}
for _, hook := range options.PreStartHooks {...}
// refresh the basic template to get inputs value involved
basicTemplate, err = basicVal.String()
taskv, err = value.NewValue(strings.Join([]string{templ, basicTemplate}, "\n"), t.pd, "", value.ProcessScript, value.TagFieldOrder)
exec.doSteps(tracer, ctx, taskv)
return exec.status(), exec.operation(), nil
}
executor执行框架
先检查 tasks 是否都结束了(Done/Succeeded/Failed),结束则直接返回,否则新建 engine 执行。workflow 状态:executing/suspending/terminated/failed/succeeded。 There’re two modes of execution: StepByStep and DAG.
- all the steps will be executed sequentially and the next step will be executed after the previous one succeeded. If a step is of type step-group, it can contain a series of sub-steps, all of which are executed together when the step group is executed.
- DAG
// workflow/pkg/executor/workflow.go
func (w *workflowExecutor) ExecuteRunners(ctx , taskRunners []types.TaskRunner) (v1alpha1.WorkflowRunPhase, error) {
allTasksDone, allTasksSucceeded := w.allDone(taskRunners)
if checkWorkflowTerminated(status, allTasksDone) {
if isTerminatedManually(status) {
return v1alpha1.WorkflowStateTerminated, nil
}
return v1alpha1.WorkflowStateFailed, nil
}
if checkWorkflowSuspended(status) {
return v1alpha1.WorkflowStateSuspending, nil
}
if allTasksSucceeded {
return v1alpha1.WorkflowStateSucceeded, nil
}
e := newEngine(ctx, wfCtx, w, status)
err = e.Run(ctx, taskRunners, dagMode)
allTasksDone, allTasksSucceeded = w.allDone(taskRunners)
if status.Terminated {
...
}
if status.Suspend {
wfContext.CleanupMemoryStore(e.instance.Name, e.instance.Namespace)
return v1alpha1.WorkflowStateSuspending, nil
}
if allTasksSucceeded {
return v1alpha1.WorkflowStateSucceeded, nil
}
return v1alpha1.WorkflowStateExecuting, nil
}
engine 依次执行taskRunners ,并记录执行结果,每次从头开始遍历taskRunners,若已完成,则下一个。若未完成,先执行task的 Pending 方法,检查是否需要等待,若ok则执行task的Run 方法。task/step 的状态 WorkflowStepPhase:succeeded/failed/skipped/running/pending。
// workflow/pkg/executor/workflow.go
func (e *engine) Run(ctx monitorContext.Context, taskRunners []types.TaskRunner, dag bool) error {
var err error
if dag {
err = e.runAsDAG(ctx, taskRunners, false)
} else {
err = e.steps(ctx, taskRunners, dag)
}
e.checkFailedAfterRetries()
e.setNextExecuteTime()
return err
}
func (e *engine) steps(ctx monitorContext.Context, taskRunners []types.TaskRunner, dag bool) error { wf
for index, runner := range taskRunners {
if status, ok := e.stepStatus[runner.Name()]; ok {
if types.IsStepFinish(status.Phase, status.Reason) {
continue
}
}
if pending, status := runner.Pending(ctx, wfCtx, e.stepStatus); pending {
wfCtx.IncreaseCountValueInMemory(types.ContextPrefixBackoffTimes, status.ID)
e.updateStepStatus(status)
if dag {
continue
}
return nil
}
options := e.generateRunOptions(e.findDependPhase(taskRunners, index, dag))
status, operation, err := runner.Run(wfCtx, options)
e.updateStepStatus(status)
e.failedAfterRetries = e.failedAfterRetries || operation.FailedAfterRetries
e.waiting = e.waiting || operation.Waiting
// for the suspend step with duration, there's no need to increase the backoff time in reconcile when it's still running
if !types.IsStepFinish(status.Phase, status.Reason) && !isWaitSuspendStep(status) {
if err := handleBackoffTimes(wfCtx, status, false); err != nil {
return err
}
if dag {
continue
}
return nil
}
// clear the backoff time when the step is finished
if err := handleBackoffTimes(wfCtx, status, true); err != nil {
return err
}
e.finishStep(operation)
if dag {
continue
}
if e.needStop() {
return nil
}
}
return nil
}
resume 逻辑
用户触发执行vela workflow resume xx,将 处于running 状态的 suspend step 置为 succeed,之后更新 WorkflowRun 的status,触发WorkflowRun reconcile,进而触发 executor.ExecuteRunners 。
// workflow/pkg/utils/operation.go
func (wo workflowRunOperator) Resume(ctx context.Context) error {
run := wo.run
if run.Status.Terminated {
return fmt.Errorf("can not resume a terminated workflow")
}
if run.Status.Suspend {
ResumeWorkflow(ctx, wo.cli, run)
}
return wo.writeOutputF("Successfully resume workflow: %s\n", run.Name)
}
func ResumeWorkflow(ctx context.Context, cli client.Client, run *v1alpha1.WorkflowRun) error {
run.Status.Suspend = false
steps := run.Status.Steps
for i, step := range steps {
if step.Type == wfTypes.WorkflowStepTypeSuspend && step.Phase == v1alpha1.WorkflowStepPhaseRunning {
steps[i].Phase = v1alpha1.WorkflowStepPhaseSucceeded
}
for j, sub := range step.SubStepsStatus {
if sub.Type == wfTypes.WorkflowStepTypeSuspend && sub.Phase == v1alpha1.WorkflowStepPhaseRunning {
steps[i].SubStepsStatus[j].Phase = v1alpha1.WorkflowStepPhaseSucceeded
}
}
}
retry.RetryOnConflict(retry.DefaultBackoff, func() error {
return cli.Status().Patch(ctx, run, client.Merge)
})
return nil
}
留下评论