DDD实践——CQRS
简介
如何避免写流水账代码
@RestController
@RequestMapping("/")
public class CheckoutController {
@Resource
private ItemService itemService;
@Resource
private InventoryService inventoryService;
@Resource
private OrderRepository orderRepository;
@PostMapping("checkout")
public Result<OrderDO> checkout(Long itemId, Integer quantity) {
// 1) Session管理
Long userId = SessionUtils.getLoggedInUserId();
if (userId <= 0) {
return Result.fail("Not Logged In");
}
// 2)参数校验
if (itemId <= 0 || quantity <= 0 || quantity >= 1000) {
return Result.fail("Invalid Args");
}
// 3)外部数据补全
ItemDO item = itemService.getItem(itemId);
if (item == null) {
return Result.fail("Item Not Found");
}
// 4)调用外部服务
boolean withholdSuccess = inventoryService.withhold(itemId, quantity);
if (!withholdSuccess) {
return Result.fail("Inventory not enough");
}
// 5)领域计算
Long cost = item.getPriceInCents() * quantity;
// 6)领域对象操作
OrderDO order = new OrderDO();
order.setItemId(itemId);
order.setBuyerId(userId);
order.setSellerId(item.getSellerId());
order.setCount(quantity);
order.setTotalCost(cost);
// 7)数据持久化
orderRepository.createOrder(order);
// 8)返回
return Result.success(order);
}
}
这段代码里混杂了业务计算、校验逻辑、基础设施、和通信协议等,在未来无论哪一部分的逻辑变更都会直接影响到这段代码,长期当后人不断的在上面叠加新的逻辑时,会造成代码复杂度增加、逻辑分支越来越多,最终造成bug或者没人敢重构的历史包袱。
接口层
接口层的接口的数量和业务间的隔离:在传统REST和RPC的接口规范中,通常一个领域的接口,无论是REST的Resource资源的GET/POST/DELETE,还是RPC的方法,是追求相对固定的,统一的,而且会追求统一个领域的方法放在一个领域的服务或Controller中。刻意去追求接口的统一通常会导致方法中的参数膨胀,或者导致方法的膨胀。假设有一个宠物卡和一个亲子卡的业务公用一个开卡服务,但是宠物需要传入宠物类型,亲子的需要传入宝宝年龄。可以发现宠物卡和亲子卡虽然看起来像是类似的需求,但并非是“同样需求”的,可以预见到在未来的某个时刻,这两个业务的需求和需要提供的接口会越走越远,所以需要将这两个接口类拆分开。
一个Interface层的类应该是“小而美”的,应该是面向“一个单一的业务”或“一类同样需求的业务”,需要尽量避免用同一个类承接不同类型业务的需求。也许会有人问,如果按照这种做法,会不会产生大量的接口类,导致代码逻辑重复?答案是不会,因为在DDD分层架构里,接口类的核心作用仅仅是协议层,每类业务的协议可以是不同的,而真实的业务逻辑会沉淀到应用层。也就是说Interface和Application的关系是多对多的。因为业务需求是快速变化的,所以接口层也要跟着快速变化,通过独立的接口层可以避免业务间相互影响,但我们希望相对稳定的是Application层的逻辑。
应用层——为什么要用CQE对象?
ApplicationService负责了业务流程的编排,是将原有业务流水账代码剥离了校验逻辑、领域计算、持久化等逻辑之后剩余的流程,是“胶水层”代码。
Command/Query/Event
通常在很多代码里,能看到接口上有多个参数
Result<OrderDO> checkout(Long itemId, Integer quantity);
如果需要在接口上增加参数,考虑到向前兼容,则需要增加一个方法:
Result<OrderDO> checkout(Long itemId, Integer quantity);
Result<OrderDO> checkout(Long itemId, Integer quantity, Integer channel);
传统的接口写法有几个问题:
- 接口膨胀:一个查询条件一个方法
- 难以扩展:每新增一个参数都有可能需要调用方升级
- 难以测试:接口一多,职责随之变得繁杂,业务场景各异,测试用例难以维护
- 这种类型的参数罗列,本身没有任何业务上的”语意“,只是一堆参数而已,无法明确的表达出来意图。
CQE和DTO有什么区别呢?
- CQE:CQE对象是ApplicationService的输入,是有明确的”意图“的,所以这个对象必须保证其”正确性“。
- 当入参改为了CQE之后,我们可以利用java标准JSR303或JSR380的Bean Validation来前置这个校验逻辑。
- 因为CQE是有“意图”和“语意”的,我们需要尽量避免CQE对象的复用,哪怕所有的参数都一样,只要他们的语意不同,尽量还是要用不同的对象。
- DTO:DTO对象只是数据容器,只是为了和外部交互,所以本身不包含任何逻辑,只是贫血对象。 因为CQE是”意图“,所以CQE对象在理论上可以有”无限“个,每个代表不同的意图;但是DTO作为模型数据容器,和模型一一对应,所以是有限的。
DDD设计实例
Domain-driven Design Example译文领域驱动设计示例 未读
源码实例:Domain-Driven Design领域驱动设计落地节选自《领域驱动设计第7章》假设我们正在为一家货运公司开发新的软件,最初的需求包括三项基本功能:
- 事先预约货物
- 跟踪客户货物的主要处理流程
- 当货物到达其处理过程中的某个位置时,自动向客户寄送发票
对应的博客 领域驱动设计DDD和CQRS落地 未读
cqrs
cqrs 全称command and Query Responsibility Segregation(隔离),也就是命令(增删改)与查询(查)职责分离。如果把Command 操作变成Event Sourcing,那么只需要记录不可修改的事件,并通过回溯事件得到数据的状态。
mvc 到ddd的过渡形态
万字长文!Go 后台项目架构思考与重构 PS: 从实践上,很多项目直接上ddd吃不消
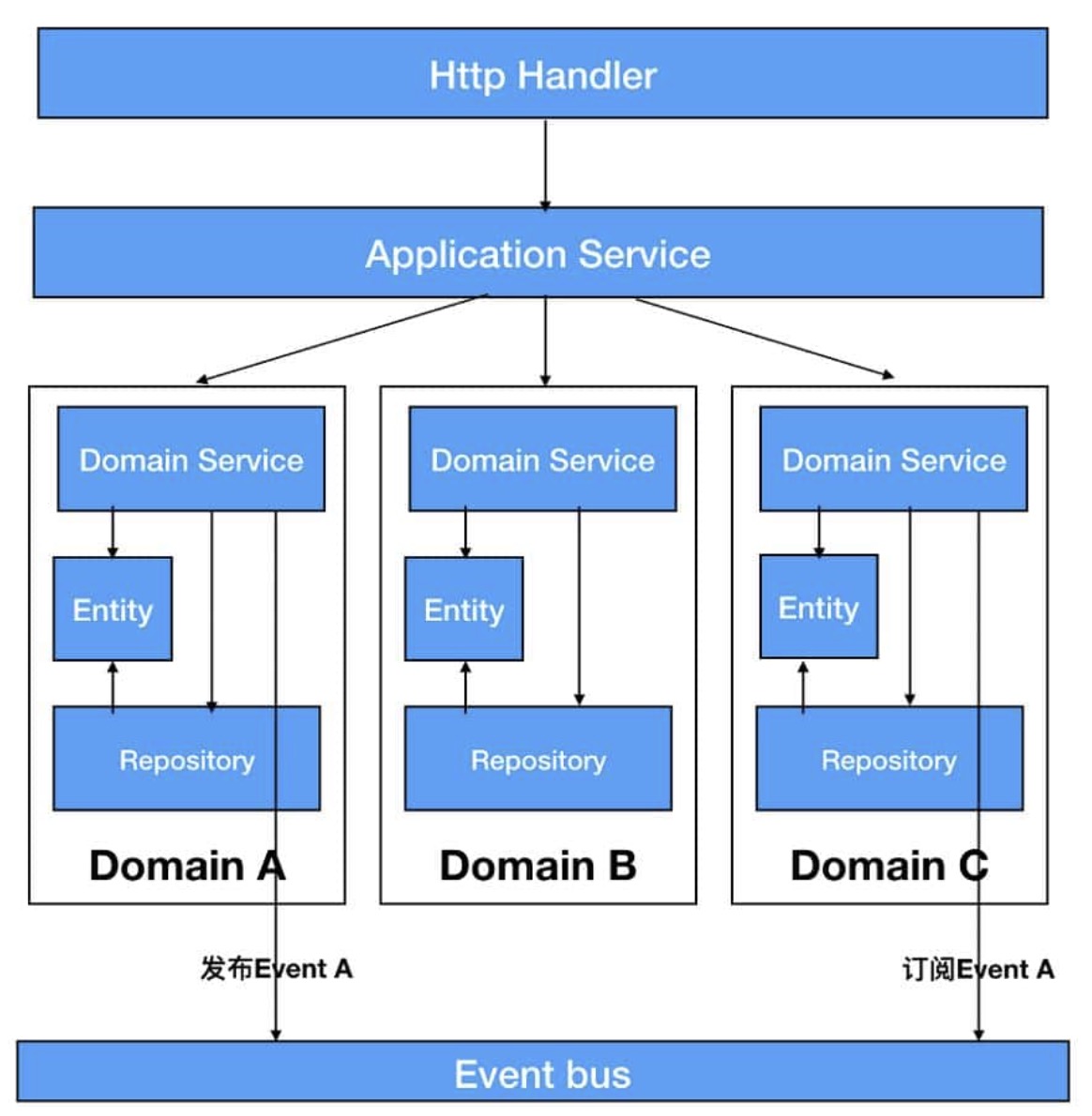
- 严格遵守水平分层,比如只能上层调下层
- 进行垂直切片,将应用层以下划分成了不同领域(Domain),每个领域责任明确且高度内聚。领域的划分应该满足单一职责原则,每个领域应当只对同一类行为者负责,每次系统的修改都应该分析属于哪个领域,如果某些领域总是同时被修改,他们应当被合并为一个领域。一旦领域划分后,不同领域之间需要制定严格的边界,领域暴露的接口,事件,领域之间的依赖关系都该被严格把控。PS: 没有ddd形式化的约束,领域概念缺失是mvc 在演进中很大的问题
- 把跨多领域的业务逻辑上拉至 application 层中。
- 原来全局公用的存储层,现在分散到各个领域自行维护,不同领域可以采用不同的存储;
材料3
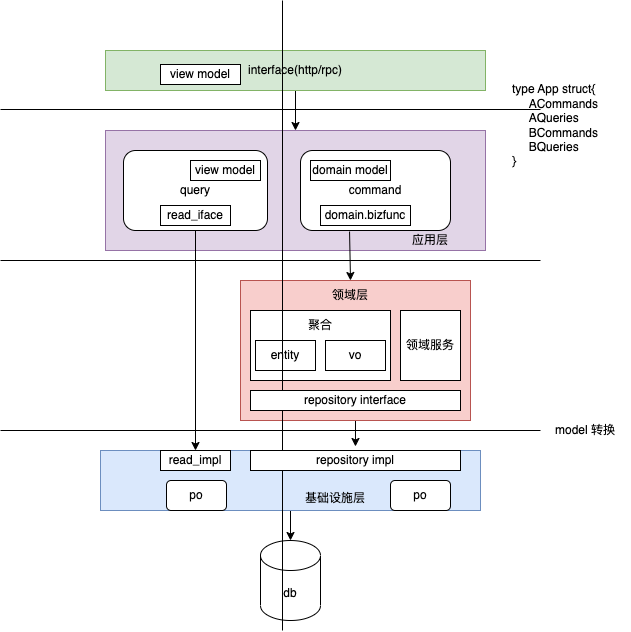
和公司内大佬关于支付系统为何用ddd,以及ddd与微服务的关系(项目拆分角度)问题的讨论。
- 在做支付系统的时候,DDD提供了一个切分系统的思路,防止系统变成一个大煤球。这个切分思想的好处是让工作经验比较浅的人做也不会出太大问题。PS:过程式代码 改起来,一个是不好改,另一个是改哪里都可以。cqrs+ddd对过程式代码进行横切、竖切(明确分工),为此不惜增加了很多胶水代码和 model 转化,好处是,当代码变更时,改哪里显而易见一些。
- DDD是逻辑上的切分。微服务是实现上的切分。按DDD做模块切分,最终实现如果还是在一个应用里面,那就是单一应用程序。如果把DDD的模块分散成多个app,通过发布事件的方式建立联系协调工作,那就是微服务的实现。
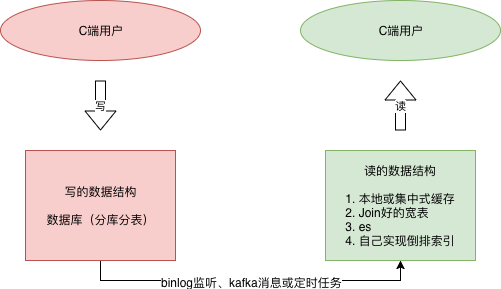
材料1
《软件架构设计》读写分离模型的典型特征:分别为读和写设计不同的数据结构。
材料2
阿里高级技术专家方法论:如何写复杂业务代码?一般来说实践DDD有两个过程:
- 套概念阶段:了解了一些DDD的概念,然后在代码中“使用”Aggregation Root,Bounded Context,Repository等等这些概念。更进一步,也会使用一定的分层策略。然而这种做法一般对复杂度的治理并没有多大作用。
- 融会贯通阶段:术语已经不再重要,理解DDD的本质是统一语言、边界划分和面向对象分析的方法。
你写的代码是别人的噩梦吗?从领域建模的必要性谈起软件的世界里没有银弹,是用事务脚本还是领域模型没有对错之分,关键看是否合适。就像自营和平台哪个模式更好?答案是都很好,所以亚马逊可以有三方入住,阿里也可以有自建仓嘛。实际上,CQRS就是对事务脚本和领域模型两种模式的综合,因为对于Query和报表的场景,使用领域模型往往会把简单的事情弄复杂,此时完全可以用奥卡姆剃刀把领域层剃掉,直接访问Infrastructure。
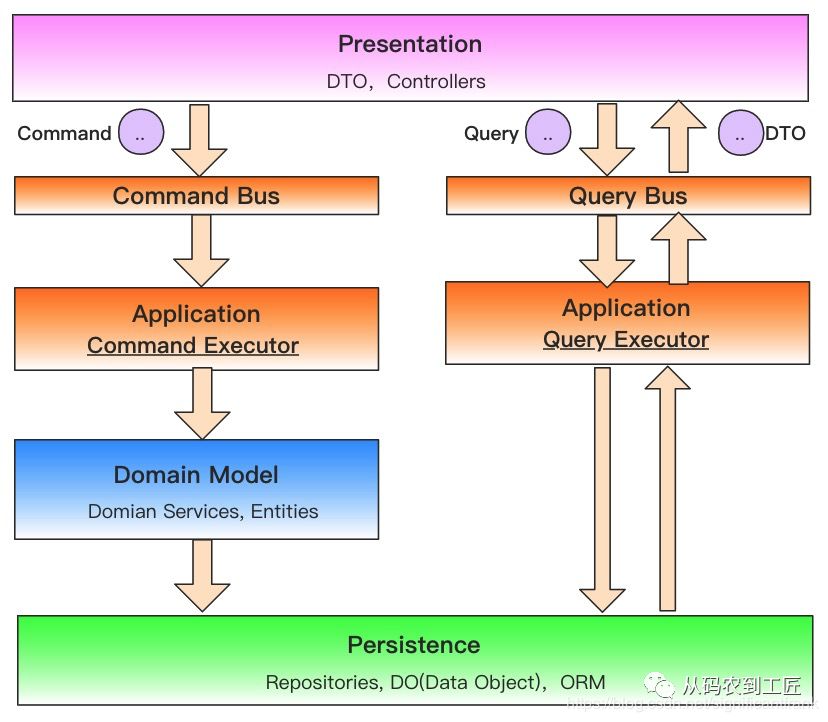
材料3
详解 CQRS 架构模式在拥有大量数据和复杂实体模型的大型应用程序中,一些实现细节随着时间推移变成了“核心”部分。有时候,这些东西是工程师在很明确的情况下完成的,但更多的是以一种隐式甚至是无意的方式发生。于是,新需求可能与现有的实现不一致,以至于根本无法很好地容纳它们。
对于一部分场景,CQRS 是一种非常有用的架构模式。在基于 CQRS 的系统中,命令 (写操作) 和查询 (读操作) 所使用的数据模型是有区别的。命令模型用于有效地执行写 / 更新操作,而查询模型用于有效地支持各种读模式。通过领域事件或其他各种机制将命令模型中的变更传播到查询模型中(PS:领域事件的一种用法?),让两个模型之间的数据保持同步。只用于读取的数据模式看起来就像是一个缓存。事实上,查询模型可以使用 Redis 这样的缓存技术来实现。但是,CQRS 不只是为了分离数据的写入和读取,它的根本目的是为了实现数据的多重表示,每一种表示都能够满足某些用户的需求。CQRS 可能会有多种查询模式,每个模式可能使用不同的物理实现。有些可能使用数据库,有些可能使用 Redis,等等。
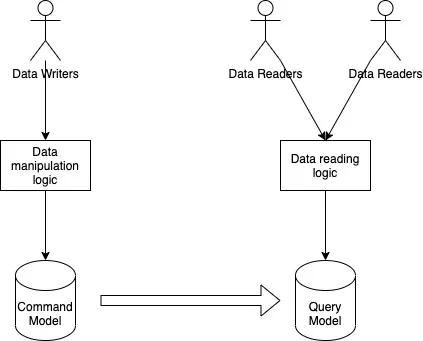
什么时候不该使用 CQRS?在系统中使用 CQRS 会带来显著的认知负担和复杂性。开发人员必须面对至少两个数据模型和多种技术选择,所有这些都是不可忽略的负担。第二个问题是如何保持命令模型和查询模型的数据同步。如果选择了异步方式,那么整个系统就要承担最终一致性所带来的后果。这可能非常麻烦,特别是当用户希望系统能够立即反映出他们的操作时,即使是单个一致性要求也会危及整个系统的设计。
留下评论