《程序员的自我修养》小结
前言
近日,有幸研读了俞甲子的《程序员的自我修养》,人家在读研的时候就出书了,真是让也是研究生的我自惭形秽。
本书主要讲述装载、链接和库,强烈推荐学校开设相关的过程,因为这样才能将大学所学的编程语言、操作系统和组成原理等课程联系起来。否则,从语言直接蹦到了操作系统和组成原理,相关知识联系不到一起,无法相互印证。
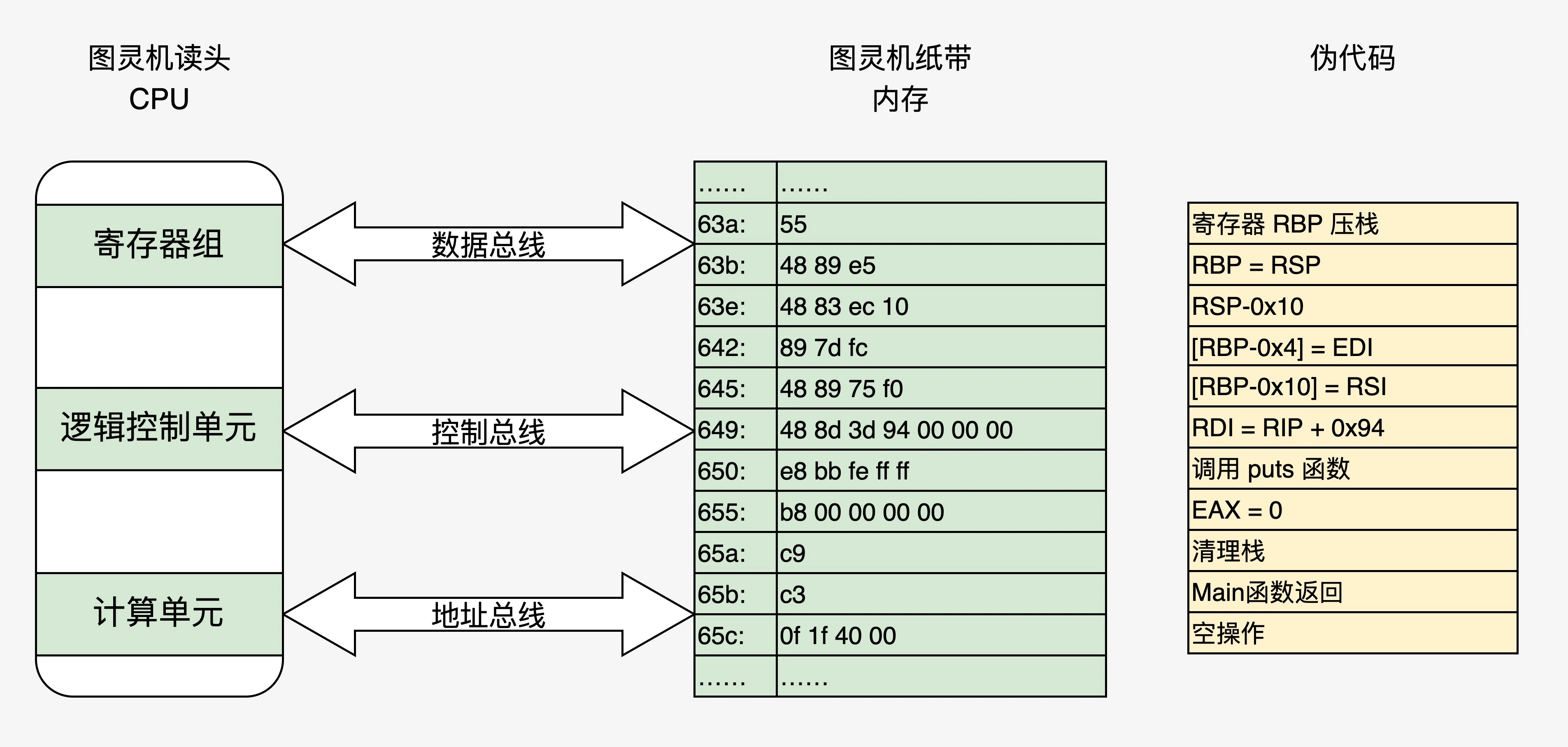
从源代码到内存的通路
可执行文件的组成
在链接前,需要将源文件编译(其实我觉得翻译更贴切)为目标文件,目标文件链接为可执行文件。与源代码文件和汇编代码文件等纯文本文件相比,可执行文件(动态链接与运行时加载)由多个段组成:
- 文件头。文件基本信息
- 段表。描述各段的基本信息,比如各段的位置。
- 基本的代码段和数据段。
- 链接相关的。一个可执行文件可能有多个目标文件组成,目标文件之间相互引用,便涉及到符号的解析和重定位。
- 装载相关。比如
.dynamic(描述依赖的共享对象)
可执行文件的加载
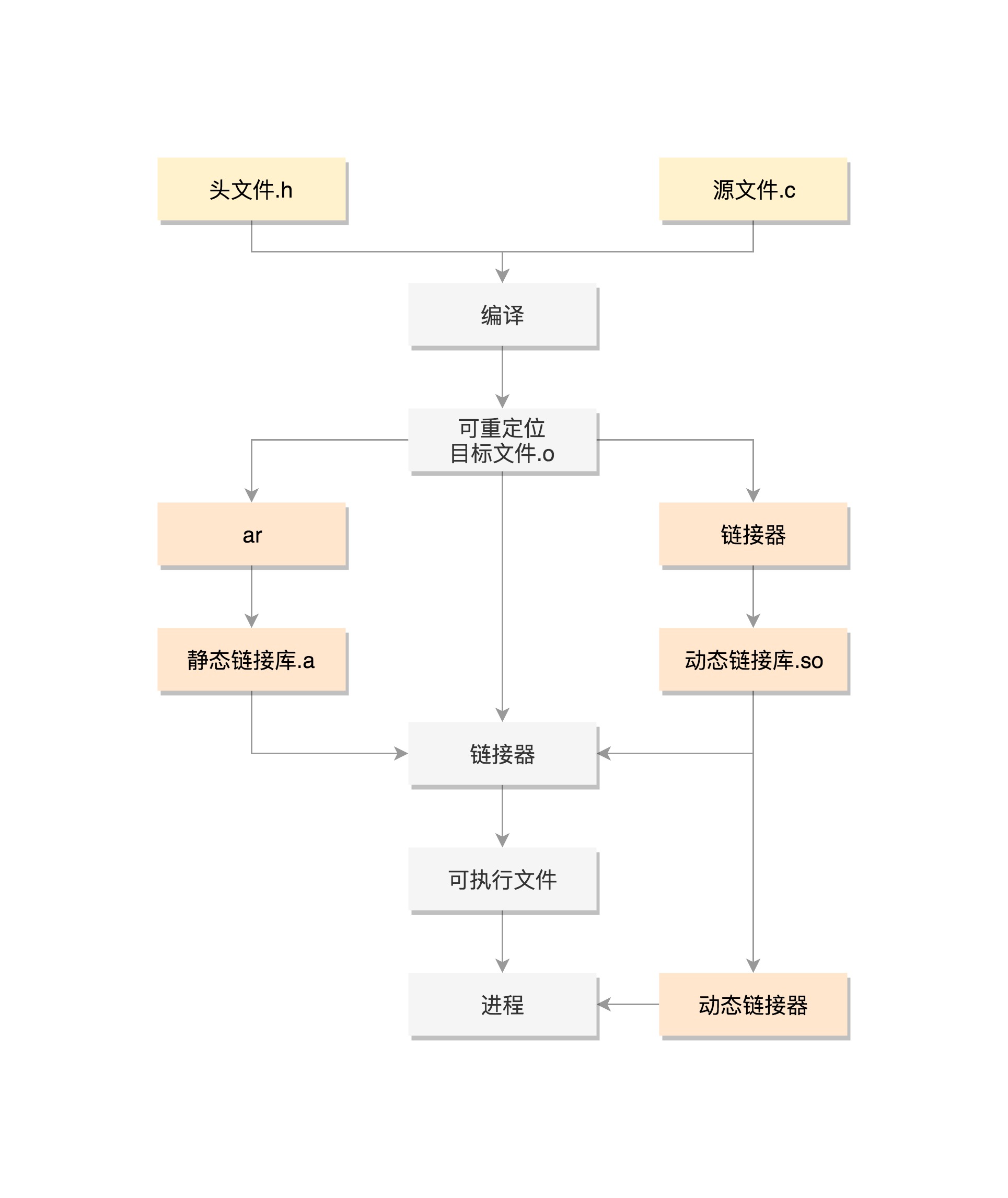
源代码编译而成的目标文件一般依赖系统的运行库及其它共享对象,将它们链接成可执行的程序并载入内存,有以下几种方式:
- 将所有相关文件静态链接成一个完整的可执行文件,然后进入内存。
- 将目标文件作为可执行文件,载入内存时由动态链接器加载其依赖的其它文件。动态链接的魔法:Linux下动态链接库机制探讨 未细读。
- 将目标文件作为可执行文件,载入内存,由程序调用“依赖”函数 ==> 发现不在 ==> 执行代理代码(ld-linux.so) ==> 加载或找到已加载到内存的函数地址,继续执行。有点像 java中本来该编译在一起,但代码中使用Class.forName(“xxx”) 的感觉。
fork ==> 内核态 sys_execve ==> do_execve ==> load_elf_binary。
前奏:内核启动的初期会自动注册elf程序处理函数
20250923:当执行一个动态链接的 ELF 可执行文件(如 ls命令)时,shell首先在PATH遍历查找第一个符合我们可以执行程序名一样的程序(如果是绝对路径(如/bin/ls)则不需查找,找到存在的可执行程序后bash程序会调用execve 系统调用,整个流程的就从内核(execve syscall)开始了:
- 内核读取可执行文件的 ELF 头,找到 PT_INTERP 程序头(该头指定了动态链接器的路径,如 /lib64/ld-linux-x86-64.so.2)。
- 如果 ELF 有 动态段 (.dynamic),说明它需要动态链接。内核发现 PT_INTERP 段,会把控制权交给 动态链接器 ld.so
- 动态链接器启动后,首先完成自身初始化(如设置堆、栈、线程局部存储等),随后开始处理目标程序的依赖加载。
- 然后将控制权交给动态链接器(而非直接执行程序的 _start 入口)。
- 解析共享库依赖。动态链接器的核心工作之一是解析目标程序的 .dynamic 段(动态段),该段存储了动态链接所需的全部元数据(如依赖库、符号表位置、重定位信息等)。
- 符号重定位。将程序中对外部符号(如共享库中的函数、变量)的 “占位引用” 替换为这些符号在内存中的实际地址,确保程序执行时能正确访问依赖的代码和数据。动态链接的程序(或共享库)在编译时无法知道依赖的共享库最终会被加载到内存的哪个地址(共享库采用位置无关代码 PIC,可加载到任意地址)。因此,程序中对外部符号(如 printf)的引用只能暂时用 “符号名” 或 “偏移量占位符” 表示,需要在运行时由动态链接器根据实际加载地址修正 —— 这一修正过程就是符号重定位。动态链接器的重定位过程依赖于 ELF 文件中的重定位表(Relocation Table)、符号表(Symbol Table) 和已加载共享库的地址信息。
- 初始化共享库。目的是确保共享库在被程序使用前完成必要的准备工作(如全局变量初始化、资源分配等)。其初始化流程严格遵循依赖顺序,通过解析共享库的 ELF 结构(如 .init 段、动态段条目)触发初始化逻辑。
- 移交控制权。当前面所有的动作都执行完成之后ld程序将控制权交还给程序真正的入口,也就是ELF程序的entrypoint。这个地址实际的符号是_start函数,再由_start函数调用__libc_start_main(glibc里的),__libc_start_main 是 GNU C 库(glibc)中程序启动阶段的核心函数,它是连接操作系统内核启动逻辑与用户代码(main 函数)的关键桥梁。其主要作用是在 main 函数执行前完成一系列初始化工作,并在 main 执行后处理程序退出流程,确保程序能在正确的环境中运行。
- 最终程序进入到main函数执行,至此控制权真正交给了我们的代码。
PS:JVM 里 Class 加载,.class 文件本身只包含 类的定义(字段、方法、常量池等)。 类依赖加载 是在运行时 解析常量池符号引用 时触发的:比如某个方法第一次被调用,需要解析到实际的类;VM 的 ClassLoader 会根据命名空间去找到对应的 .class 文件并加载(懒加载)。Linux 内核加载 ELF:程序启动时由动态链接器一次性解析并加载所需共享库(除非库里用了 dlopen 这种手动按需加载)(预先加载)。
文件的映射
程序不是一下子就全部装载到内存中的,而是在执行时访问数据发生“缺页”,再由操作系统将该页加载到内存中。中间有两个关键的映射关系:
- 可执行文件各段与虚拟地址空间的映射。(由一个叫VMA的数据结构维护,进程的task_struct中有该结构的指针)
- 虚拟地址空间与物理地址空间的映射。该映射关系由操作系统维护(比如页表)
进程虚拟地址空间的分布
进程的虚拟地址空间,主要包含用户地址空间和内核地址空间(即,进程其实没有利用虚拟地址空间中的所有地址)。用户地址空间包含堆、栈以及可执行文件的相关数据(由VMA结构负责维护)。
elf可执行文件中虽然有好多段,但以权限划分主要有三种(进程虚拟地址空间中,来自于可执行文件的也主要是这三种):
- 以代码段为代表的可读可执行段
- 以数据段和bss段为代表的可读可写段
- 以只读段为代表的只读段
加载时,同一类型的文件将被放在一个VMA(Virtual Memory Area).
至此,源代码,目标文件,链接成可执行文件,(部分)加载到内存就算是通了。
2018.10.17补充:从另一个角度来划分内存区域
- 代码区
-
数据区
- 静态数据区
-
动态数据区,必须要解决分配与回收的问题
- 堆区
- 栈区
运行库
操作系统通过系统调用提供自己的服务,但是因为种种原因,程序无法直接使用调用(具体原因?)程序与系统调用之间隔着一层运行库(比如glibc等)。
linux内核的功能,glibc大都进行了封装,但也会因为封装的不太好,或没有提供封装,出现了许多库,不然libcontainer、libvirt
问题
为什么会有数据段
我们知道冯诺依曼体系将指令和数据存在一起,那为什么非得有数据段呢(或者说代码段和数据段分开呢)?
汇编指令,调用数据就那么几种方式:立即数,寄存器,和直接寻址,间址寻址。
除了立即数,就必须是数据存在在一个地方,由指令根据地址去访问,这就是为什么要有数据段。可见,所谓指令和数据存在一起,直观上大部分更像是指令和地址存在一起。同时,代码段和数据段分开还有一个额外的好处,比如根据一个可执行文件运行多个进程,内存中可以只存储一份代码段,每个进程只读写属于自己的数据段即可。
2019.4.23补充:《趣谈Linux操作系统》笔记 程序是代码写的,所以一定要有”代码段“。代码的执行过程 会产生临时数据,所以要有”数据段“
函数调用和栈
为什么需要栈?
(从书中推想)c程序中一般都包含函数的调用,函数调用涉及到参数及返回值的传递、函数执行完毕后返回等问题(即调用惯例)。因为这种操作形式较为固定,所以为其单独分配一段空间存储相关数据。并且因为空间的分配与回收非常符合栈的特性,所以为每个进程安排一个栈空间就确定下来。
- 栈段: 用户感知不到, 由编译器(根据方法调用)自动分配释放 ,存放函数的参数值,局部变量的值等。
- 堆段: 一般是用户手动分配的,也就是通过malloc函数来手动分配内存的。
cpu 栈寄存器 + 出入栈指令 这类硬件支持,加上栈操作形式的相对固定,使得编译器层面便可以屏蔽这些细节。甚至反过来说,是硬件特性 + 编译器 造就了“方法/函数”这一抽象,而不是方法利用了栈的特性。jvm 虽说堆内存垃圾回收很高端,但这类复杂的事儿就只能语言的虚拟机层 解决了。
从这里也可以看到,一段代码到机器指令 中间经过很多转换
- 加减乘除类(也就是运算类)代码 的直接转换
- 方法调用 转换为 指令跳转,入栈,出栈。在汇编里没有方法一说。
- 变量声明转换为 内存分配
这些直接的、模式固定的,光靠编译器就行了。复杂点的,比如说自动内存回收、注解等,就得另整一个虚拟机层。cpu + 编译器 + 虚拟机合力,屏蔽细节,提供更符合人类直觉的语言抽象。
为什么是值传递?
函数调用时,会先将相关参数压入栈中,“被调用函数”在执行代码时,对参数的操作访问的就是属于该函数栈帧中的参数值(而不是“调用函数”栈帧中对应的参数值),函数执行完毕后,“被调用函数”栈帧被释放(或者说抛弃),其对参数的更改就会丢失。
其实任何参数传递都是值传递,当然,参数是指针类型时,我们对指针指向数据的更改可以保留下来,但对指针本身的更改是无效的。
函数局部变量为什么被限制声明周期?
函数局部变量保存在函数栈帧中,函数执行完毕后,栈帧被释放,局部变量当然就无效了。
为什么可以有构造函数和析构函数
可执行文件除了代码段(.text或.code)外,构造函数和析构函数代码一般存放在.init和.finit段中。
运行库一般包含入口函数,这才是进程执行的入口(而不是main函数),它会在main执行前执行.init中的代码(还有其他很重要的工作),main执行完毕后执行.finit。
这样,go语言里的defer关键字就很好解释了。
留下评论