项目隔离——案例研究
简介
每个公司都有一个测试环境 供技术开发和调试。随着公司的壮大,会产生一个问题:一个测试环境够用么?不够用。只有一个测试环境的痛点:开发5分钟,联调1小时。为何呀?
假设你的服务依赖ABC,你联调的时候,极有可能ABC 中的某一个服务也在开发阶段,于是便可能:
- ABC 某一个服务直接不可用
- ABC 代码可能有bug,进而导致联调失败,耗费时间定位bug 在哪个服务上。
以上述问题为引子,可以看到:测试环境 应随着公司的壮大 而逐渐调整和规范,本文尝试梳理下 测试环境 管理 相关的几个问题,尤其关注的是环境隔离问题。
开发之痛:稳定的测试环境,怎么就那么难在测试环境中常用的实践主要有:双机部署、N+1部署、隔离环境等。
- 双机部署,一个应用至少部署两个Pod。资源占用高
- N+1部署
- 隔离环境,既然我们将环境隔离出来了,但隔离依赖的基础环境不稳定,这个时候假如我们有一个稳定的环境是否就能解决问题了呢?什么样的环境是稳定环境呢?就是能够发布到线上版本的环境,线上环境肯定是稳定环境,所以我们的稳定环境其实是由与线上版本一致的应用服务组成的,跟线上的服务是一致的。当有了稳定的基础环境,在应用部署到生产环境之后,也同样要把它部署到基础环境中去,提供一个给测试环境作为依赖的基础环境。
- 生产环境做基础环境,要解决两个重要的问题,第一个是流量隔离,流量隔离相对来说问题不太大,从以前面向资源到现在面向流量的隔离有很多现成的手段可以做。第二个是数据隔离。这个是挺大的挑战,数据形式有很多种,比如说消息队列和普通的数据库不一样,数仓又不一样,很多麻烦的问题在这里,但是具体到某一个点上都有办法解决。
毕玄:测试是个大问题,到现在也是,很多公司尤其服务化以后更严重。因为你原来就一个系统,测试还好,不存在互相干扰,服务化以后好了,有几百上千个系统,那完蛋了,一放到测试环境,你都不知道谁影响了你,所以各家公司就搞出了 N 套方案,来解决互相干扰的问题。比如阿里以前先搞了一套测试环境,所有人都在上面放新的代码,但慢慢的大家就发现这环境还是不要用了,没法用,全是异常,你查问题可能发现根本不是你代码的问题,都是别人的,但别人不理你,这就没法搞下去了。所以,我们又搞了一套日常环境,日常环境是比较稳定的,里面只允许放测试过的正常代码,但因为前面的测试环境不受大家认可,所以大家就时不时在日常环境里跑,然后就又尴尬了(笑),所以日常环境也慢慢变成测试环境了。后来希望从中间件的层面去解决,我们把这个叫二套环境,比如在这个环境里,你现在是测试,但别人调用的时候不会调用到你,会调用一个稳定版本。但是中间件要解决,很复杂,因为不光有服务调用,还有消息各种各样的问题。最后我觉得也解的不是很好。所以阿里后来都已经直接到预发环境去测了,预发其实就是线上生产环境,只不过用户访问不到,但我们内部能访问。因为用的是线上,可以确保如果出问题,应该就是我的问题。但是后来预发环境也乱套了(笑)。反正为了一个环境问题,尝试了不知道多少年,现在应该还有个团队尝试新的,专注怎么解决环境干扰问题。
vivo 全链路多版本开发测试环境落地实践 未细读。谈到了http、 rpc、mq 分别如何做流量隔离。
测试环境的特点
阿里测试环境运维及研发效率提升之道:生产环境最关注的就是稳定,测试环境更关注的是研发效率。
测试环境的特点
- 频繁的代码提交和部署
- 开发频繁修改自己的代码,但希望别人能够提供一个稳定的服务
- 资源配置低
线下环境为何不稳定?怎么破 建议细读 测试环境不稳定&复杂的必然性及其对策
一站式动态多环境建设案例 未读
资源配置低
- 服务器 配置比较低。比如磁盘容量比较低,一个服务打满磁盘,于是同主机的其它服务 直接就挂了。因此 需要进行资源监控,至少要做到支持报警以尽快发现问题。
- 服务器 运行环境不稳定,一般测试环境 都在公司的办公大楼内,比如笔者公司,每年断一次电是必然事件。
频繁的代码提交
带来的挑战
- 对于docker 环境来说,频繁部署会产生大量的镜像文件。因此要提供清理机制,尽可能压缩镜像文件大小,方法:直接压缩;尽可能共用layer。
- 尽可能缩短 代码提交 到开始在测试环境运行的 时间
环境隔离
为什么要隔离?为了避免相互干扰。可以回顾下开篇的案例。
环境包括什么?
- 互通服务器/容器,提供计算资源
- 中间件,比如mq、zk等
- 前端接入,比如nginx;后端存储,比如db、hdfs等
解决方案
- 强隔离,一个环境一套业务服务、中间件、数据库等。听起来 服务器成本 很贵的样子,多环境的维护也需要耗费人力。
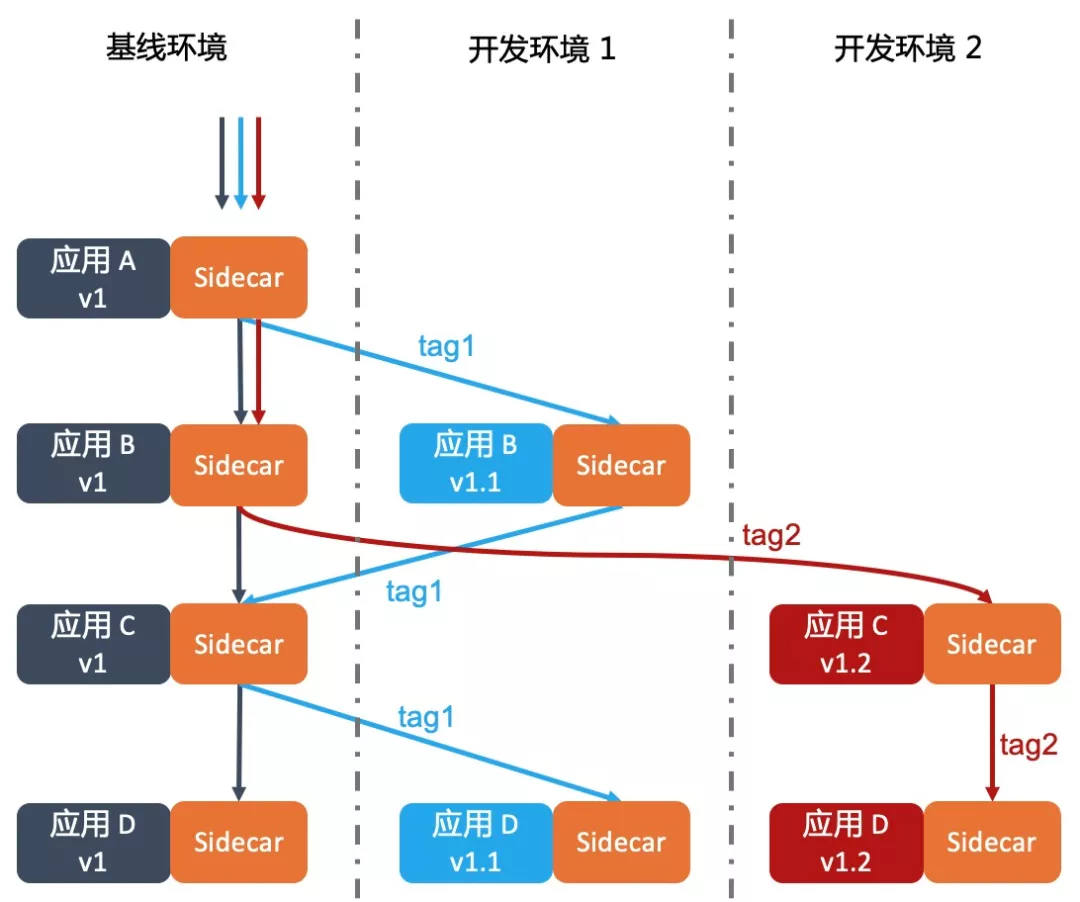
- 弱隔离,能共用共用,按需隔离。对于服务A,存在开发版本A1及稳定版本A0,服务B类似。则A 服务调用 B 服务时。A0 会调用B0 服务,A1 服务则若存在B1 服务便调用B1 服务,否则A1 调用B0 服务。
弱隔离 实现方案
实现原理
-
根据源头的IP所在隔离组进行路由。(阿里文章中的方案)
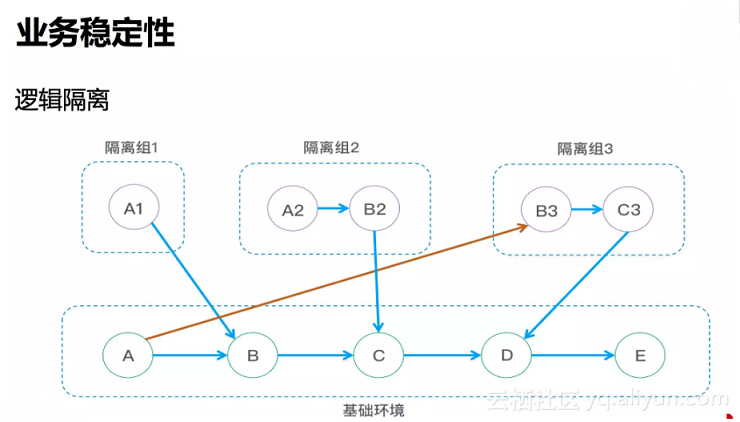
暂时忽略上图中的红线
把源头的请求IP放在ID(阿里有一个中间件叫做鹰眼,每个用户请求会生成一个ID,这个ID会随着每一次调用一个一个传下去)里面,当你服务调用的时候,服务路由会把ID取出来,看看你的IP有没有跟隔离组做关联,如果有的话就到那个隔离组里面去调用。
特别的,把一个服务单独放在一个隔离组里,可以实现“服务在运行,但不会被任何人调用到”的效果
-
请求链路 中携带 环境标识。(有赞文章中的方案)
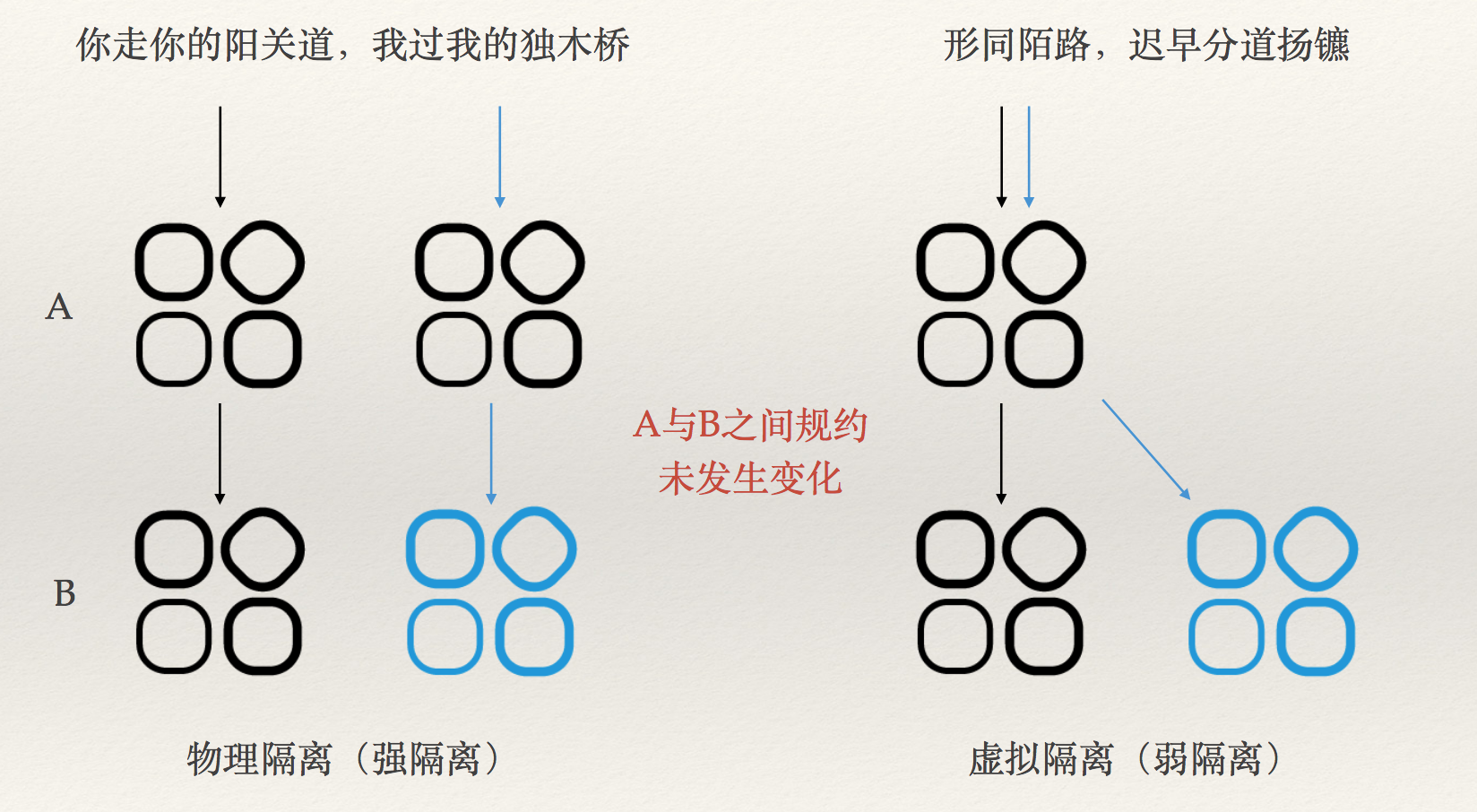
注意箭头的颜色
有赞与阿里方案类似,将服务实例信息与env 绑定。不同的是
-
隔离组的概念 是从 服务粒度来说的,即假设一次开发只涉及到 AB 两个服务,则希望实现:AB 存在开发和稳定两种状态,开发状态 可以访问别人的稳定状态,但开发状态对外不可见,除非AB 本身就是一起开发的,B 的开发状态 对A 可见。
-
有赞 的方案则是从 隔离角度 来说的,只是说 硬隔离成本太高,通过env 参数化的方式 实现弱隔离。
隔离组的概念 更加通用,你可以一个服务 占用一个隔离组,而一个服务占用env 则一个语义上不太顺。
信息关联
因为阿里 和 有赞的文章 分别提到 环境 和隔离组 等类似概念,以下统一 使用隔离组。
服务的提供方,如何告知 自己提供的是哪个隔离组的服务? 调用方 如何感知 自己所在的隔离组,以便调用 对应隔离组的服务。
对于rpc 服务,可以提供 第三方配置界面人为关联,将服务实例信息(比如ip)与隔离组 的关联情况 写入到 etcd/zk 等。
对于rpc 服务,服务治理框架 在发起 rpc 调用时
- 根据本机信息/ip 查询zk,感知自己所在的隔离组
- 查询目标 服务 在该隔离组 中是否有 实例
- 若有,则直接调用
- 若无,则调用默认 隔离组 对应的服务
对于restful 等服务,服务方可以 约定 url 规范,提供服务的url 中包含 隔离组信息,并强制通过域名 访问(这样就用到了 nginx)。请求方 则在请求中 加入 带有隔离组信息的cookie(此时一般一个隔离组一个请求方,可以在请求方启动时配置好 隔离组参数,也可以单独做一个代理系统,在代理系统中关联 请求方ip 和隔离组,然后由代理系统转发rest请求),由nginx 根据 cookie 信息 自动 路由到 对应的 隔离组服务。
后续 全链路 压测时,也可以使用 弱隔离的逻辑。
20年11月1日补充:信也科技是如何用Kubernetes搞定1000个应用测试环境的? 也是弱隔离的方案,细节实现上有独树一帜的地方。
对调度系统的要求
在单一环境下,除了业务上有shard 逻辑的需求 导致项目需要多个实例外,一般一个项目一个实例即可。此时,用户发起一次项目的部署,则调度系统会干掉 老的实例,创建新的实例。
多隔离组环境下会带来以下不同:
- 项目通常会具备两个状态: 开发和稳定。此时,用户发起一个项目的部署,可以将隔离组 配置 纳入部署参数,调度系统 在隔离组维度上 确保一个 隔离组 只有特定数量(一般是一个)的实例
- 项目稳定后,通常会删除 开发 版本的隔离组 实例,删除 操作 也应确保 在隔离组 维度下。
弱隔离有多弱
- 比如mq 是否要做弱隔离?发的消息 带上 隔离组标识,只有对应 隔离组 标识的消费者才可以接收 该隔离组标识的消息。
-
2019.4.10补充:当某个隔离组的服务挂掉时,比如下图的C1,那么是走A0->B0->C0->D1呢?还是直接告诉用户C1挂了。
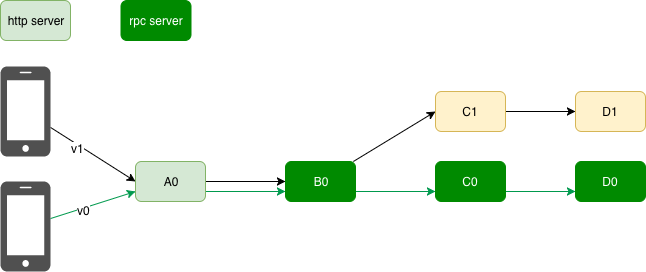
请求时除了携带隔离组标识外,还应携带一个白名单:描绘哪些服务挂掉就立即报错。否则就有则调用,无则调用stable(稳定组,对应上图中的v0),再无则报错。
针对第二点有一个背景,笔者最初实现的版本就是:对于A1,有B1则调用,无B1则调用B0。而新的业务需求是,没有B1就要立即报错。然后开始互撕,从中可以发现几个问题
- 一开始受限于强弱隔离的概念,对”弱隔离有多弱“没有认识。技术概念是人为创造出来的,但创造出来是解决问题的。后来者削足适履,为了满足概念而做事儿,超出概念的却认为提出问题的人有问题。不执念于概念,尤其是权威概念,专注于解决问题。
- 知道、理解、应用,每一个层次之间都差的挺远的。
- 技术沟通极易转换为人身攻击,尤其是事先存在偏见的时候
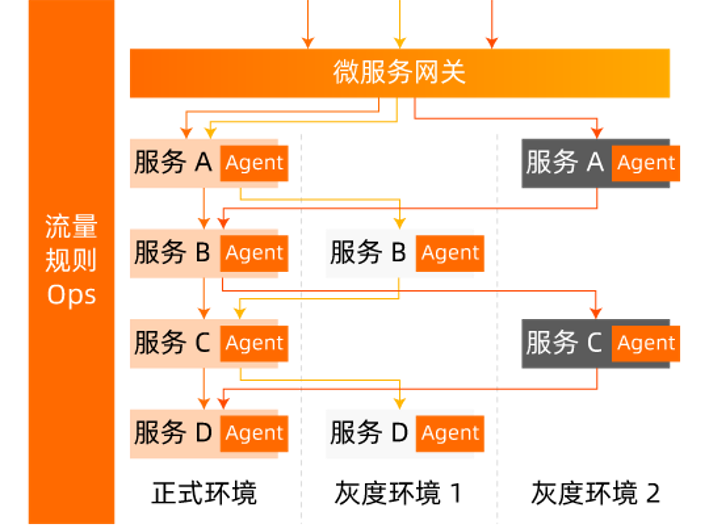
全链路灰度
浅析微服务全链路灰度解决方案 非常好的文章,建议细读。感触就是,没有这么复杂的业务,你很容易觉得istio 很多余,这种体感蛮重要的。
那么全链路灰度具体是如何实现呢?
- 需要对服务下的所有节点进⾏分组,能够区分版本。即节点打标,对应k8s 的pod.label 或者 nacos label。
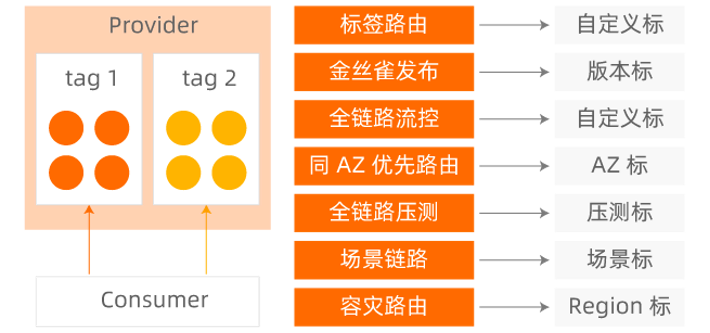
- 需要对流量进⾏灰度标识、版本标识、传递。即流量染色。在请求的源头/前端或网关根据⽤户信息或者平台信息的不同对流量进⾏打标。
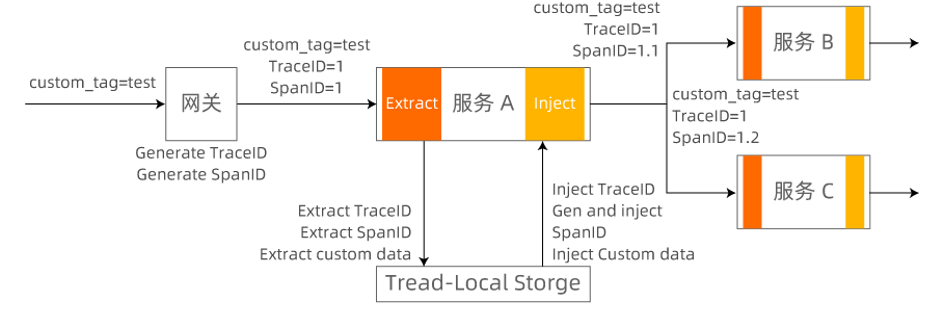
- 需要识别出不同版本的灰度流量。
- 链路上各个组件和服务能够根据请求流量特征进⾏动态路由。此外,需要引⼊⼀个中⼼化的流量治理平台,⽅便各个业务线的开发者定义⾃⼰的全链路灰度规则。
流量染色,如果不走灰度标识的全链路透传(需要链路上的所有 服务都支持,包括mq 等),实现方式是不是可以理解为:每个pod打了anno,<podIp,流量标识>会被记录下来。一个pod 在收到请求时,根据请求来源podip 即可获取请求的流量标识,这样省得在框架里去透传流量标识了。PS:还不清晰,有没有可能实现,在实例外部做流量染色
service mesh
留下评论