OS Agent
简介(未完成)
Browser Use
以前很多浏览器能力,是给人点的,是给开发者调试的。现在越来越多的能力,开始直接为AI准备,或者至少在快速变得更适合AI使用。
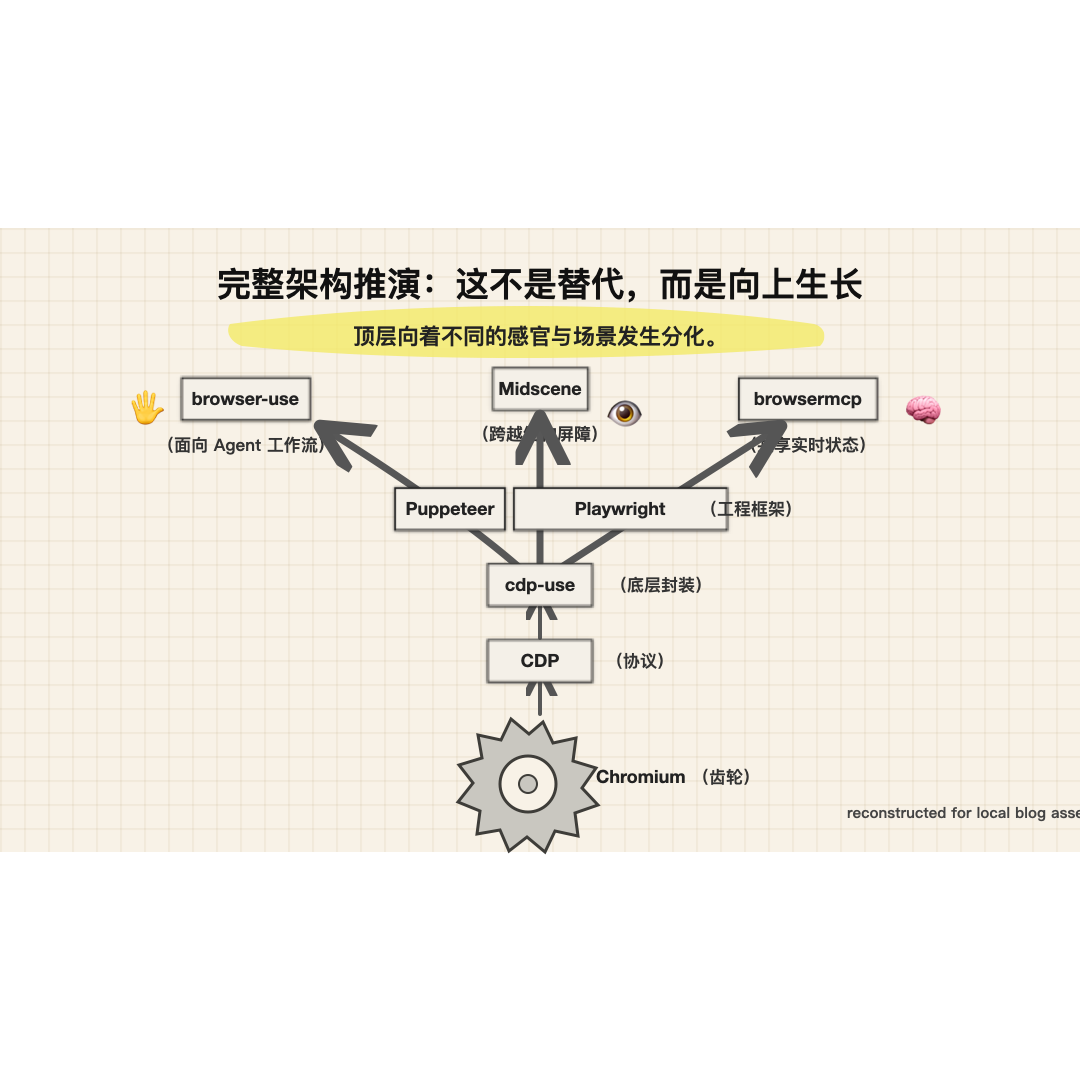
- 最底层依赖的是Chromium。你可以把Chromium理解成一个浏览器底座,Google Chrome是基于它做出来的,Edge、Brave这些浏览器,本质上也都在这个体系里。所以当我们说浏览器自动化的时候,很多时候我们真正操作的,并不是某个网页本身,而是这个Chromium系浏览器对外暴露出来的一套能力。
- 这套能力里最核心的一个东西,就是cdp。cdp的全称叫Chrome DevTools Protocol,你可以把它理解成浏览器对外开放的一套远程控制协议。通过这套协议,外部程序可以让浏览器做很多事情,比如打开页面、执行JavaScript、读取DOM、监听网络请求、获取控制台日志、截图、输入文本、点击元素,甚至接管tab和target的生命周期。
- 那有了接口之后,下一步自然就是,得有人把它更方便地用起来。于是就有了像cdp-use这种东西。你可以把cdp-use理解成一个更贴近cdp协议本身的客户端封装,它负责建立连接、发送命令、接收事件、管理target和session。这个层级已经比直接手写协议好了很多,但它还是偏底层,真要拿它去写完整的业务流程,细节会很多,心智负担也会比较重。
- 再往上,才是Puppeteer和Playwright这种更高层的浏览器自动化框架。等待机制、多上下文、多标签这些能力也更系统。
- browser-use不是要替代Playwright,也不是要替代cdp,它更像是在更上面再包了一层,专门为了AI和Agent这种使用方式,设计出了一套更自然的CLI工作流。它想解决的问题不是浏览器能不能点,而是AI该怎么更顺手地操作浏览器。你会看到它强调的就是open、state、click、input、upload、screenshot这些动作,本质上是在把复杂的浏览器能力,整理成一组更适合智能体逐步调用的命令。
- 不管是browser-use,还是Playwright、Midscene,本质上大多都还是重新拉起一个浏览器,或者重新跑一个自动化进程。那如果我现在正在用一个浏览器,我就想让AI直接看到我当前这个浏览器里正在发生什么,并且顺着这个上下文继续操作,有没有办法?其实也有,就是官方出的browsermcp。它可以基于你当前正在使用的浏览器,把页面内容、DOM结构和可操作能力,更自然地暴露给AI。
https://github.com/browser-use/browser-use
如何让AI“看懂”网页?拆解 Browser-Use 的三大核心技术模块 Browser Use 是什么
- Browser Use 是一种基于 AI 模型的浏览器自动化工具,基于 Playwright(浏览器自动化框架)
- Browser Use 是是一个开源的Python库,基于 LangChain 生态构建
Playwright 是一个底层浏览器自动化驱动层,负责:
- 启动、控制浏览器进程;
- 执行 DOM 操作、点击、输入、截图;
- 模拟网络请求、地理位置、时间;
- 拦截 / 注入脚本;
- 提供 API 接口给上层应用调用。 它相当于“浏览器的远程控制器”,用来跑测试、爬取数据、或者做自动化交互。
# 初始化AI模型
llm = ChatOpenAI(model="gpt-4o")
# 定义任务
task = "打开google,搜索'AI编程助手',告诉我第一条结果的标题"
# 创建AI代理
agent = Agent(task=task, llm=llm)
# 运行任务
await agent.run()
现代Python项目最佳实践:以 agentic tool browser-use为例
class Agent(Generic[Context, AgentStructuredOutput]):
async def run(self, max_steps: int = 100) -> AgentHistoryList:
for step in range(max_steps):
await self.step(step_info)
async def step(self, step_info: Optional[AgentStepInfo] = None) -> None:
try:
# Phase 1: Prepare context and timing
browser_state_summary = await self._prepare_context(step_info)
# Phase 2: Get model output and execute actions
await self._get_next_action(browser_state_summary)
await self._execute_actions()
# Phase 3: Post-processing
await self._post_process()
except Exception as e:
# Handle ALL exceptions in one place
await self._handle_step_error(e)
finally:
await self._finalize(browser_state_summary)
Chromium
Chromium 是 Google 开源的浏览器项目,Chrome 就是在它之上加了私有组件(Google 账号、自动更新、编解码器等)打包出来的商业版。对自动化场景来说两者能力基本等价,所以服务器/容器里几乎都用 chromium。它可以完全无界面运行(headless 模式),这就是沙盒里跑浏览器不需要显示器的原因。
Chromium 是多进程架构:browser 主进程(可信,管协调)+ 一堆renderer 进程(每个站点/标签页一个,负责解析 HTML、跑 JS、解码图片——全是在处理不可信的互联网内容)
- hromium 默认自带沙箱就是给 renderer 进程上枷锁:通过 user namespaces(或 setuid helper)+ seccomp-bpf,把 renderer 锁到”没有文件系统、没有网络、只剩最小 syscall 集”的状态,所有资源访问都要经 browser 进程代理。恶意网页打穿 renderer 只能拿到一个”什么都摸不着”的进程,还需要第二个沙箱逃逸漏洞才能干坏事
- 沙箱的两条实现路径(unprivileged userns、setuid helper)在”容器 + 非 root + 默认 seccomp”下经常都不可用, 于是 –no-sandbox 成了容器部署的肌肉记忆
Chromium --no-sandbox一个 renderer 漏洞 = 直接以浏览器进程的 uid 在 pod 里执行代码
遥控靠什么:CDP
Chrome DevTools Protocol(CDP)是 Chromium 浏览器调试工具的核心通信协议:它基于 JSON 格式,可以通过 WebSocket 实现客户端与浏览器内核之间的双向实时交互。基于 CDP 的开源产品有许多,其中最有名的应该是 Chrome Devtools Frontend,Puppeteer 和 Playwright 了。
首先 CDP 协议是一个典型的 CS 架构,这里我们拿 Chrome Devtools 为例:
- Chrome Devtools:就是 Client,用来做调试数据的 UI 展示,方便用户阅读
- CDP:就是连接 Client-Server 的 Protocol,定义 API 的各种格式和细节
- Chromium/Chrome:就是 Server,用来产生各种数据
CDP 协议的格式基于 JSON-RPC 2.0做了一些轻量的定制。首先是去掉了 JSON 结构体中的 “jsonrpc”: “2.0” 这种每次都要发送的冗余信息。CDP 其实可以分为两大类,然后下面有不同的 Domain 分类:
- Browser Protocol:浏览器相关的协议,之下的 Domain 都是平台相关的,比如说 Page,DOM,CSS,Network,都是和浏览器功能相关
- JavaScript Protocol:JS 引擎相关的协议,主要围绕 JS 引擎功能本身,比如说 Runtime,Debugger,HeapProfiler 等,都是比较纯粹的 JS 语言调试功能
playwright
chromium 带上--remote-debugging-port=9222就会开一个端口,任何程序都能连上来发指令:”导航到这个 URL”“把当前页面截图”“执行这段 JS”。chromium 是浏览器本体,playwright 是遥控器(对cdp的高级封装)。写 page.goto(url)、page.screenshot(),它翻译成 CDP 消息发给 chromium 进程。
playwright 本质是一个浏览器遥控库,npm 上是一个包家族:
- playwright-core:遥控核心库,不带浏览器;
- playwright:core + 浏览器下载管理 + 完整 CLI(install、screenshot、open……);
- @playwright/test:测试框架;
- @playwright/cli:2025 年出的面向 agent 的会话式 CLI。
playwright 自带chromium。CDP 协议本身随 chromium 版本演进,playwright 还给 chromium 打了一些自动化相关的补丁。所以 playwright 团队的做法是:每个 playwright 版本钉死一个自己编译、自己测过的 chromium build(比如 1.54.2 对应某个 build 号),playwright install 下载的就是这个 build,放进 PLAYWRIGHT_BROWSERS_PATH,按 build 号建目录。版本对不上它就拒绝用、要求重新下载。有一个例外通道叫 channel:channel: ‘chrome’ 可以让 playwright 放弃自带 build,去固定路径(如 /opt/google/chrome/chrome)找一个现成浏览器,兼容性不如 pinned build 有保证。
playwright 的对象模型三层:Browser(浏览器进程,比如chromium)→ BrowserContext(一份独立的 cookie/登录态,相当于一个隐身窗口)→ Page(一个标签页)。进程模型有两种
@playwright/playwright CLI 是一次性的 比如playwright screenshot <url> <file>CLI 命令的生命周期是:起一个新浏览器 → 开页面 → 干活 → 杀掉浏览器 → 进程退出。所以两次 CLI 调用 = 两个先后存在、互不相识的浏览器。@playwright/cli/playwright-cli。2025 年新出的独立包- agent 的工作方式是一条一条 shell 命令地试探,比如“导航→看快照→点按钮→再看”,playwright一次性模型完全不匹配。
- 进程模型:daemon 常驻。首次调用拉起后台 daemon,daemon 持有浏览器连接不放;每条命令是打向 daemon 的短请求。跨命令的页面状态、登录态、多 session(-s=name)都由 daemon 维护。
computer use
https://github.com/e2b-dev/open-computer-use
GUI Agent
GUI Agent类模型的训练关键是否应该算在RL post-train里是个模糊的问题
- GUI Agent的数据收集困难,多样性的仿真环境构建困难。
- 虽然主流应用数量不多,手机端App是频繁在更新的。
- 用户在GUI上进行的任务也相对匮乏,,除了少数很复杂的网站和PC专业应用之外,大部分用户在大部分软件上只是在完成少数任务。虽然输入的信息是个性化的,但任务流程很固定,也并不多样。当然在国内各种臃肿的App上,我们可以探索它们的各种功能,产出很多task,但这些task对于用户主要场景上的成功率和泛化性很难说有多大提升。
- GUI Agent模型的跨应用泛化能力较差,海外的模型对于国内应用来说几乎不可用,因为这些模型没有针对于国内的网站和应用进行训练。国内的网站和应用的交互范式也与海外有差异。
code sandbox
起初OpenAI Code Interpreter 的出现, 需要一个安全的 Sandbox 来执行它生成的 Python 代码,仅仅为了弥补数学计算和逻辑执行的短板。随后, 随着 Context Engineering 的深入,Manus 和 Anthropic 的实践告诉我们,Sandbox 里的 File System 不再只是存临时文件的地方,它是 Agent 的memory,于是Sandbox 变成了 Agent Skills 和Memory 的载体。
根据业界领先的context Engineering的经验:
- Cursor 的 “File-based Tools”: Cursor 采取了一种文档化方案,将工具的“说明书”全部文件化。当 Agent 需要使用某个能力时,它会先通过Retrieval找到对应的文档,阅读后生成代码
- Manus 的 “Context Offloading”: 在 Manus 的设计中,采用了层级化的工具架构。为了应对复杂的长流程任务,Agent 不再试图把所有中间状态都记在 Context Window 里,而是利用文件系统进行 Context Offloading(上下文卸载)。文件系统成为了 Agent 的外挂memory(不同于compact的有损压缩,Offloading是无损的)
- Anthropic 的 “Programming tool-using” 和skills:由agent自身编写代码实现tool-call相比于直接的tool-call能够节约大量context;同时agent skills本质上也是利用了file-system,对宝贵的context 进行节约的设计 显而易见,代码执行环境 (Code Execution) 和 可读写的文件系统 (File System) 已经超越了辅助工具的范畴,成为 Agent 组件中必要且不可或缺的部分。赋予 Agent “写代码”和“改文件”的能力,等同于赋予了它巨大的破坏力。因此,通过为 Agent 划定严格的 安全边界(Sandbox)——如网络隔离、文件系统隔离、进程隔离,便显得尤为重要。
https://github.com/vndee/llm-sandbox
https://mp.weixin.qq.com/s/JiRAuWAQ0RqNKlgtShaOvw
从技术实现角度,现阶段的Sandbox有以下几种实现方式
- Local Sandbox-runtime。其原理利用 Linux 的 namespaces 和 cgroups 或 macOS 的 sandbox-exec 等操作系统原语直接限制进程权限, 如限制对配置路径的读/写访问,通过内置代理路由网络流量。如 Claude Code 中 执行 /sandbox 可在 中配置对应的权限:
{ "sandbox": { "enabled": true, "autoAllowBashIfSandboxed": true, "excludedCommands": ["git", "docker"], "network": { "allowUnixSockets": ["/var/run/docker.sock"], "allowLocalBinding": true } }本质上,Claude Code 的 sandbox runtime 是一个 OS 级别的“受限 Bash 运行环境”。
- Docker。默认的 Docker 是不安全的,在标准 Docker 中,容器只是宿主机上的一个进程。存在容器逃逸的问题: Linux 内核由数千万行代码组成,不可避免地存在 Bug(漏洞)。如果 Agent 发送了一个精心构造的“恶意系统调用”触发了内核漏洞(Kernel Panic 或 提权漏洞),它就能瞬间逃出容器,直接控制整台宿主机。因此必须进行安全加固。关键配置包括移除 Linux capabilities、只读文件系统、禁用网络接口等。
- MicroVM。AWS 在 2018 年开源了 Firecracker,专为 Serverless 和多租户容器设计: 砍掉了传统虚拟机(如 QEMU)中 90% 对 Agent 无用的功能,只保留了 CPU、内存、网络和最基础的块设备, 因而带来了惊人的性能,约 125 毫秒的冷启动时间,内存开销不到 5 MiB。
从工程落地角度
- 自托管 (Self-hosting) vs 云服务 (Managed Provider)
- Long running vs High-frequency (Lifecycle, persistence)。现阶段的sandbox的最主要用途,还是 code Interpreter,如执行agent生成的代码、数据分析等。对于大多数情况下,用完即焚,每次请求启动一个全新环境,任务结束立即销毁。同时通过预装环境的sandbox(常用数据分析库)也可节约响应时间。在如Agent skills所需要file-system的场景下,持久化则显得很重要。
agent与sandbox
越来越多的 Agent(智能体)需要一个工作空间:即一台可以运行代码、安装包和访问文件的计算机。沙箱提供了这一功能。将 Agent 与沙箱集成主要有两种架构模式:
- Agent 在沙箱内部运行,你通过网络与其通信。优点:镜像本地开发体验,Agent 与环境紧密耦合。
- 更新需要重新构建容器镜像并重新部署
- 安全风险。假设你想要一个拥有 bash 工具和一个可以进行网页搜索或网页抓取工具的 Agent,那么所有 LLM 生成的代码都可以进行无限制的网页抓取(这是一个巨大的安全风险)。
- 沙箱作为工具。Agent 在本地/你的服务器上运行,远程调用沙箱进行执行。优点:易于更新 Agent 逻辑,API 密钥保留在沙箱之外,关注点分离更清晰。
- 网络延迟是主要的缺点。每次执行调用都要跨越网络边界。对于包含许多小型执行操作的工作负载,这可能会累积起来。
exec 输出太多怎么办? https://github.com/mksglu/claude-context-mode
Sandlock:最轻量级的 AI Agent 沙箱Sandlock 的做法是每次工具调用单独开设沙箱。每个工具声明自己所需的能力:读哪些路径、写哪些路径、访问哪些主机。调用时 Sandlock 启动一个新进程,仅按该工具自身的声明施加约束。浏览工具的沙箱有网络但无法写盘,文件工具的沙箱能写目录但无法联网。一个工具被攻破,攻击者无法获得其他工具的权限。
其它
一句指令帮你操作手机,最新多模态手机助手Mobile-Agent来了!为了便于将文本描述的操作转化为屏幕上的操作,Mobile-Agent生成的操作必须在一个定义好的操作空间内。这个空间共有8个操作,分别是:打开App(App名字);点击文本(文本内容);点击图标(图标描述);打字(文本内容);上翻、下翻;返回上一页;退出App;停止。点击文本和点击图标设计了输入参数。
- 在迭代开始之前,用户需要输入一个指令。我们根据指令生成整个流程的系统提示。在每次迭代开始时,Mobile-Agent会获取手机屏幕的截图,通过观察系统提示、操作历史和当前屏幕截图,输出下一步操作。如果Mobile-Agent输出的是结束,则停止迭代;否则,继续新的迭代。Mobile-Agent利用操作历史记录了解当前任务的进度,并根据系统提示对当前屏幕截图进行操作,从而实现迭代式自我规划流程。
- 在迭代过程中,Mobile-Agent可能会遇到错误,导致无法完成指令。为了提高指令的成功率,我们引入了一种自我反思方法。这种方法将在两种情况下生效。第一种情况是生成了错误或无效的操作,导致进程卡住。当Mobile-Agent注意到某个操作后截图没有变化,或者截图显示了错误的页面时,它会尝试其他操作或修改当前操作的参数。第二种情况是忽略某些复杂指令的要求。当通过自我规划完成所有操作后,Mobile-Agent会分析操作、历史记录、当前截图和用户指令,以确定指令是否已完成。如果没有,它需要继续通过自我规划生成操作。
留下评论