Tomcat源码分析
简介
使用golang 语言 实现一个http server,只需几行代码即可,为何用java 实现如何“沉重”呢?这背后tomcat 是一个什么角色呢?
package main
import (
"io"
"net/http"
)
func helloHandler(w http.ResponseWriter, req *http.Request) {
io.WriteString(w, "hello, world!\n")
}
func main() {
http.HandleFunc("/", helloHandler)
http.ListenAndServe(":12345", nil)
}
本文整体结构受周瑜《Tomcat底层源码解析与性能调优》培训视频的启发。
从各个视角看tomct
我们为什么能通过web服务器映射的url的访问资源?主要3个过程:接收请求;处理请求;响应请求。接收和响应请求是共性功能,于是将这两个功能抽取成web服务器。处理请求的逻辑是不同的,抽取成Servlet(容器),交给程序员来编写。随着后期互联网的发展,出现了三层架构,一些逻辑就从Servlet 抽取出来,分担到Service和Dao。等Spring家族出现后,Servlet 开始退居幕后,SpringMVC的核心DispatcherServlet 本质就是一个Servlet。
tomcat是一个Servlet 容器?
单纯的思考一下这句话,我们可以抽象出来这么一段代码:
class Tomcat {
List<Servlet> sers;
}
如果Tomcat就长这样,那么它肯定是不能工作的,所以,Tomcat其实是这样:
class Tomcat {
Connector connector; // 连接处理器
List<Servlet> sers;
}
Servlet规范与tomcat实现

绿色的类定义 在servlet-api 包中,其它类除自定义外在tomcat 包中
整体架构
Tomcat 要实现 2 个核心功能:
- 处理 Socket 连接,负责网络字节流与 Request 和 Response 对象的转化。
- 加载和管理 Servlet,以及具体处理 Request 请求。
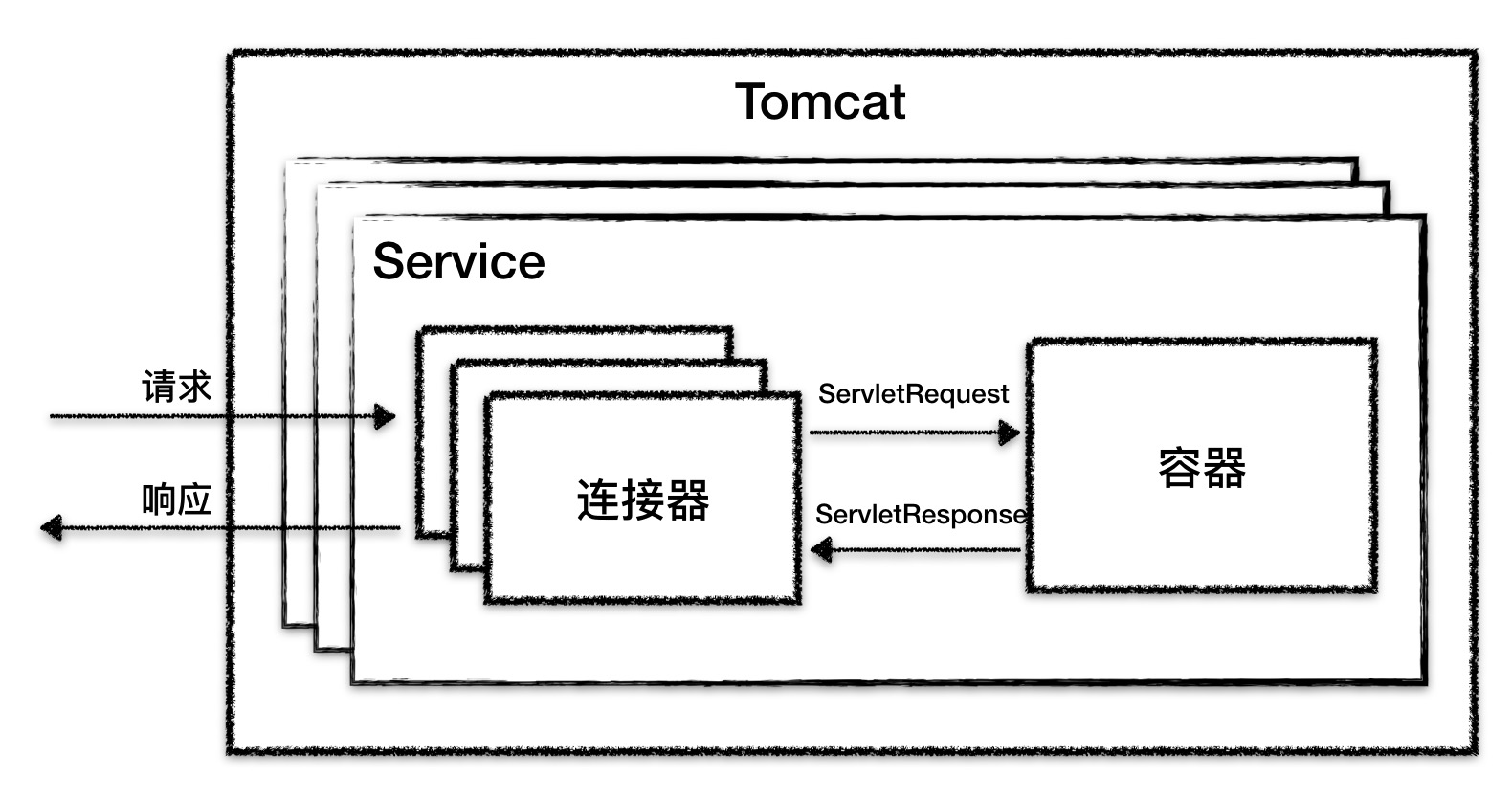
从图上可以看到,最顶层是 Server,这里的 Server 指的就是一个 Tomcat 实例。一个 Server 中有一个或者多个 Service,一个 Service 中有多个连接器和一个容器。
下图红线即为请求处理路径PS:画流程架构图时又学到一招
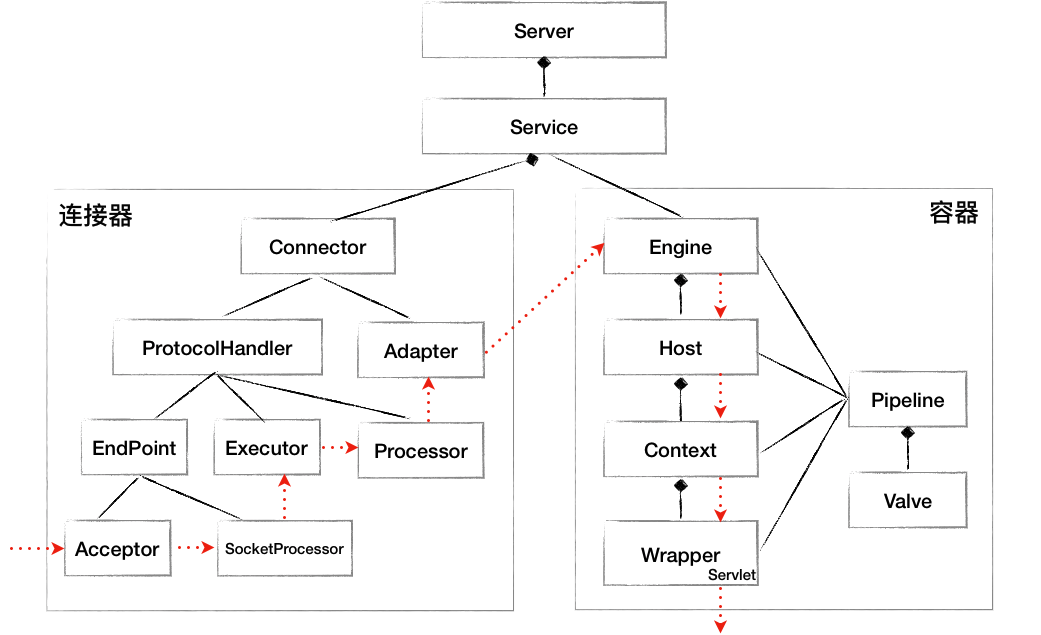
2021.1.5补充:如果代码中出现较多阻塞逻辑(比如获取db/redis/rpc连接池慢)、业务处理逻辑慢,则会很快耗尽上图的Executor,导致 Acceptor 还在收连接,但是Executor 处理不了,tomcat 像“假死”一样。
启动过程
Tomcat 独立部署的模式下,我们通过 startup 脚本来启动 Tomcat,Tomcat 中的 Bootstrap 和 Catalina 会负责初始化类加载器,并解析server.xml和启动这些组件。
/usr/java/jdk1.8.0_191/bin/java -Dxx -Xxx org.apache.catalina.startup.Bootstrap start

分别启动连接管理部分和业务处理部分
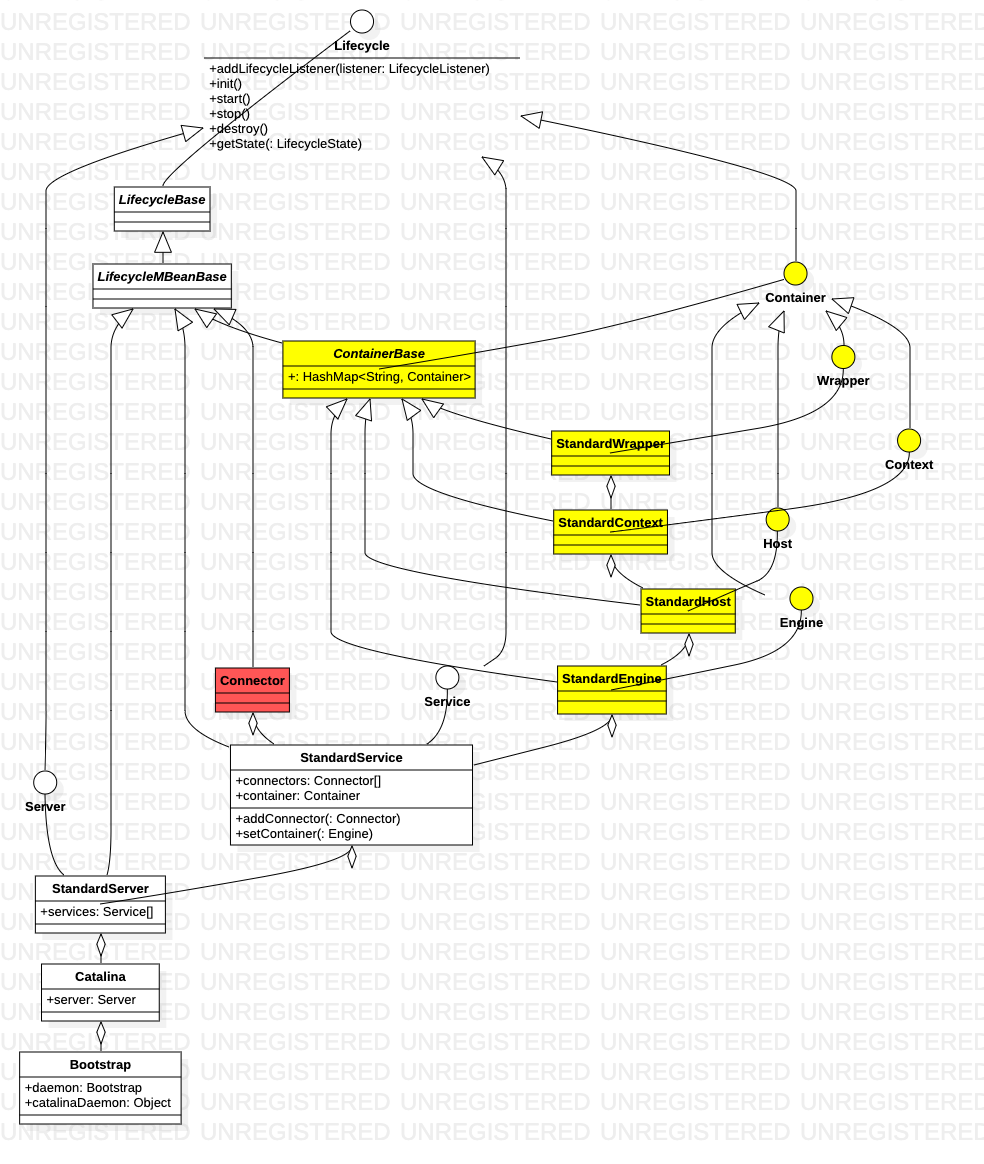
业务处理部分中,各个类的关系 在tomcat server.xml 中体现的也非常直观
<Server port="8005" shutdown="SHUTDOWN">
<Listener className="org.apache.catalina.core.ThreadLocalLeakPreventionListener" />
<Service name="Catalina">
<Connector port="8080" protocol="HTTP/1.1"
connectionTimeout="20000"
redirectPort="8443" />
<Connector port="8009" protocol="AJP/1.3" redirectPort="8443" />
</Service>
<Engine name="Catalina" defaultHost="localhost">
<Realm className="org.apache.catalina.realm.UserDatabaseRealm"
resourceName="UserDatabase"/>
<!--可以另外创建一个host,使用不同的appBase-->
<Host name="localhost" appBase="webapps"
unpackWARs="true" autoDeploy="true">
<!--可以配置 Context-->
</Host>
</Engine>
</Server>
io处理
connector 架构
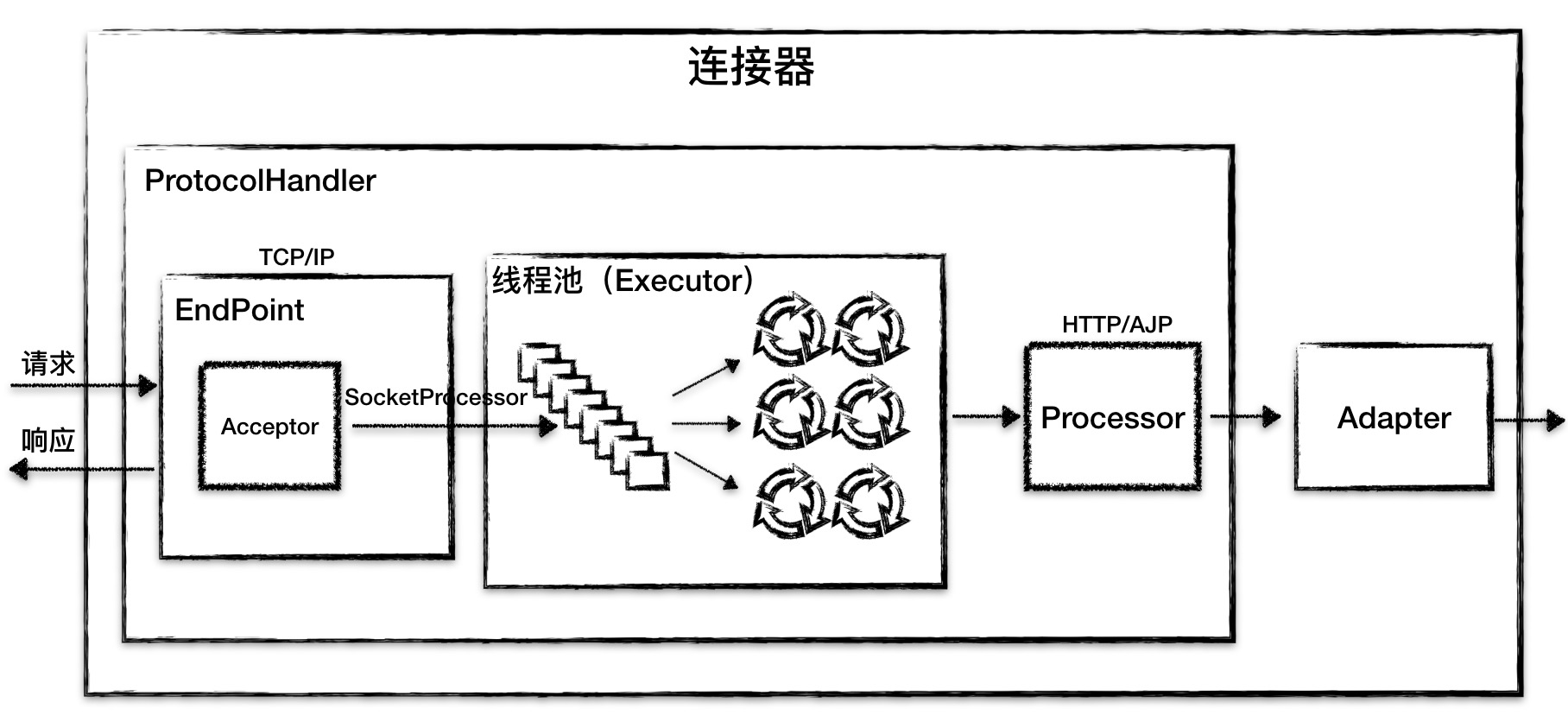
我们可以把连接器的功能需求进一步细化,比如:
- 监听网络端口。
- 接受网络连接请求。
- 读取网络请求字节流。
- 根据具体应用层协议(HTTP/AJP)解析字节流,生成统一的 Tomcat Request 对象。
- 将 Tomcat Request 对象转成标准的 ServletRequest。
- 调用 Servlet 容器,得到 ServletResponse。
- 将 ServletResponse 转成 Tomcat Response 对象。
- 将 Tomcat Response 转成网络字节流。将响应字节流写回给浏览器。
优秀的模块化设计应该考虑高内聚、低耦合。通过分析连接器的详细功能列表,我们发现连接器需要完成 3 个高内聚的功能:
- 网络通信。
- 应用层协议解析。
- Tomcat Request/Response 与 ServletRequest/ServletResponse 的转化。
Tomcat 的设计者设计了 3 个组件来实现这 3 个功能,分别是 Endpoint、Processor 和 Adapter。组件之间通过抽象接口交互,这样做一个好处是封装变化。这是面向对象设计的精髓,将系统中经常变化的部分和稳定的部分隔离,有助于增加复用性,并降低系统耦合度。网络通信的 I/O 模型是变化的,可能是非阻塞 I/O、异步 I/O 或者 APR。应用层协议也是变化的,可能是 HTTP、HTTPS、AJP。浏览器端发送的请求信息也是变化的。但是整体的处理逻辑是不变的,Endpoint 负责提供字节流给 Processor,Processor 负责提供 Tomcat Request 对象给 Adapter,Adapter 负责提供 ServletRequest 对象给容器。其中 Endpoint 和 Processor 放在一起抽象成了 ProtocolHandler 组件。
io 和线程模型
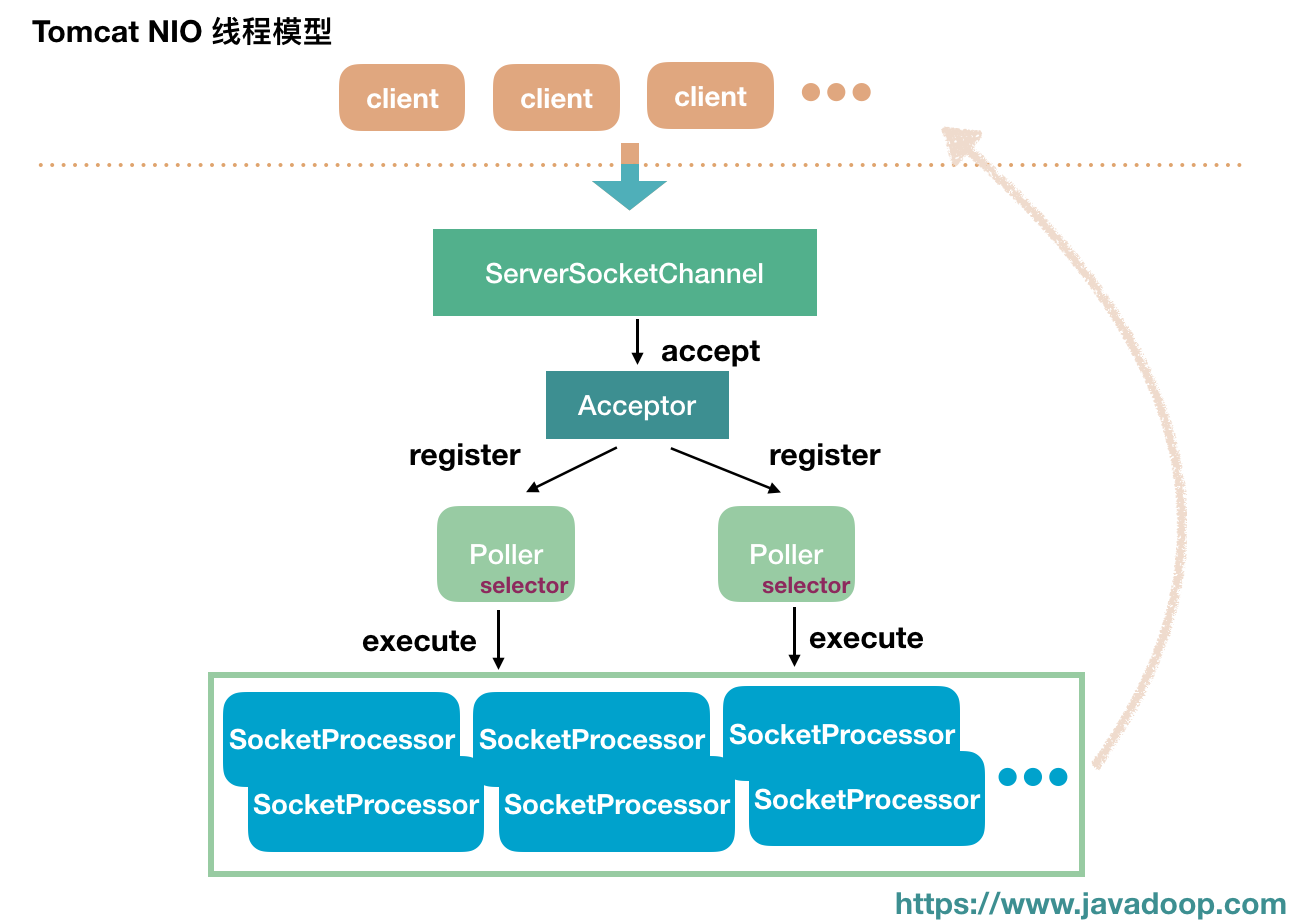
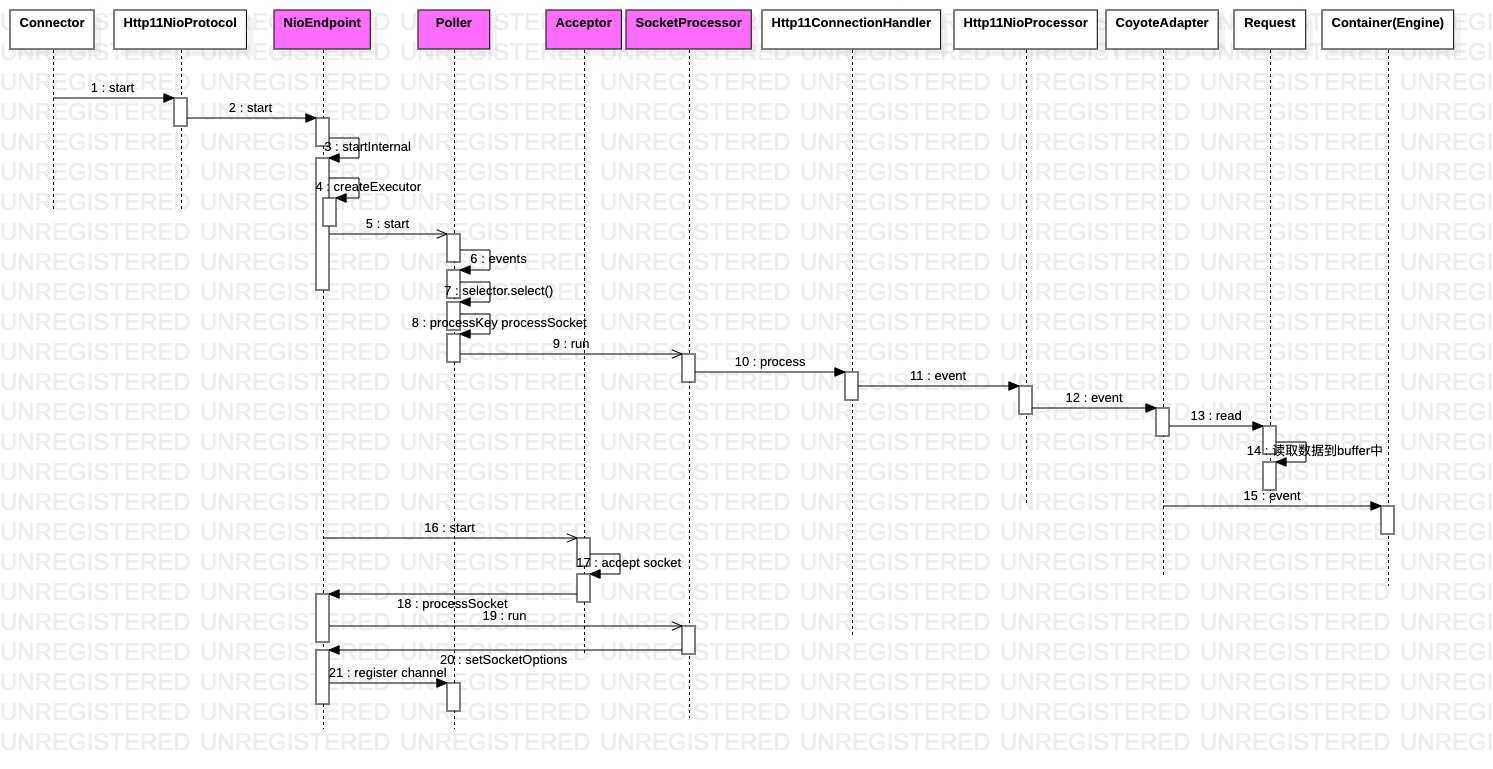
- Http11NioProtocol start 时会分别启动poller 和 acceptor 线程
- acceptor (一个Runnable)持有ServerSocket/ServerSocketChannel, 负责监听新的连接,并将得到的Socket 注册到Poller 上
- Poller (一个Runnable)持有Selector, 负责
selector.select()监听读写事件,将新的socket 注册到selector上,以及其它通过addEvent 加入到Poller中的event - Http11NioProcessor 封装了 http 1.1 的协议处理部分,比如parseRequestLine,连接出问题时response设置状态码为503 或400 等。以读事件为例, 最终会将数据读取到 Request 对象的inputBuffer 中
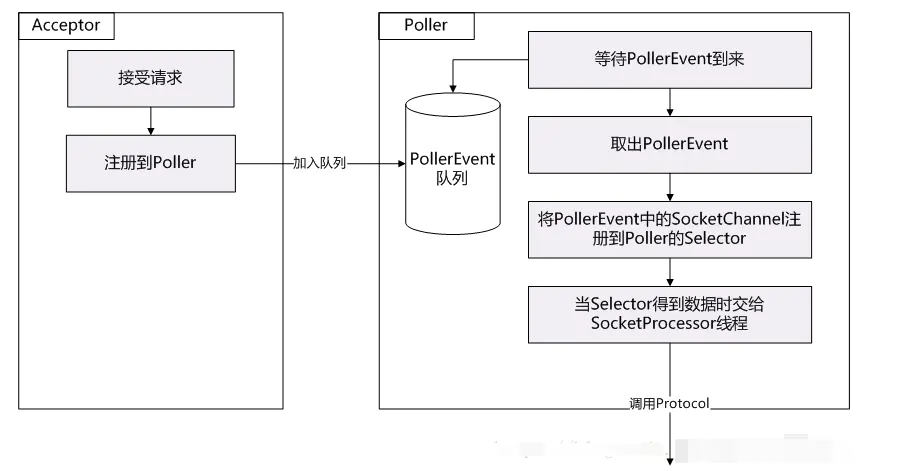
// NioEndpoint.Poller.run ==> 循环 selector.selectedKeys;processKey ==> processSocket ==> 异步执行 SocketProcessor.run ==>
// AbstractConnectionHandler.process ==> AbstractHttp11Processor.process
public class NioEndpoint extends AbstractEndpoint<NioChannel> {
private Executor executor = new ThreadPoolExecutor(getMinSpareThreads(), getMaxThreads(), 60, TimeUnit.SECONDS,taskqueue, tf);
private int pollerThreadCount = Math.min(2,Runtime.getRuntime().availableProcessors()); // new Thread().start() 的方式
protected int acceptorThreadCount = 0;
public class Acceptor implements Runnable{
// acceptor 就是简单的 accept 一个socket 并将其 加入到poller 的event 队列中( 以将socket 注册到selector)所以没有用到executor
}
public class Poller implements Runnable {
private Selector selector;
public void run() {
while (true) {
keyCount = selector.selectNow();
Iterator<SelectionKey> iterator =
keyCount > 0 ? selector.selectedKeys().iterator() : null;
// poller 内部除了 selector.select() 逻辑外,一般通过executor 异步执行
while (iterator != null && iterator.hasNext()) {
processKey(sk, attachment);
}
}
}
}
protected boolean processSocket(KeyAttachment attachment, SocketStatus status, boolean dispatch) {
...
SocketProcessor sc = processorCache.pop();
if ( sc == null ) sc = new SocketProcessor(attachment, status);
Executor executor = getExecutor();
executor.execute(sc);
...
}
}
public abstract class AbstractHttp11Processor<S> extends AbstractProcessor<S> {
Adapter adapter; // AbstractProcessor
public SocketState process(SocketWrapper<S> socketWrapper){
...
getAdapter().service(request, response);
...
}
}
一个不太成熟的理解:在io 层面上,io 组件与业务组件约定了request/response 对象 (具体的说是inputBuffer 和 outputBuffer 作为中介)。io 组件监听socket,将socket 数据读入request.inputBuffer(并触发上层协议解析及业务处理),将response.outputBuffer 写回到socket(伴随向selector注册SelectionKey.OP_WRITE)。对于同步Servlet 来说,Servlet.service 处理完毕后,request和response 可以释放(request.recycle();response.recycle();)。而对于异步Servlet来说,Servlet.service结束后request/response 只能先释放一部分资源,并等待AsyncContext.complete() 收尾。
业务处理
container 架构
Tomcat 设计了 4 种容器,分别是 Engine、Host、Context 和 Wrapper。这 4 种容器是父子关系,形成一个树形结构。Tomcat 是用组合模式来管理这些容器的,具体实现方法是,所有容器组件都实现了 Container 接口。
public interface Container extends Lifecycle {
public void setName(String name);
public Container getParent();
public void setParent(Container container);
public void addChild(Container child);
public void removeChild(Container child);
public Container findChild(String name);
}
假如有用户访问一个 URL:http://user.shopping.com:8080/order/buy,Tomcat 如何将这个 URL 定位到一个 Servlet 呢?Tomcat 是用 Mapper 组件。
- 根据协议和端口号选定 Service 和 Engine。
- 根据域名选定 Host。
- 根据 URL 路径找到 Context 组件。
- 根据 URL 路径找到 Wrapper(Servlet)。
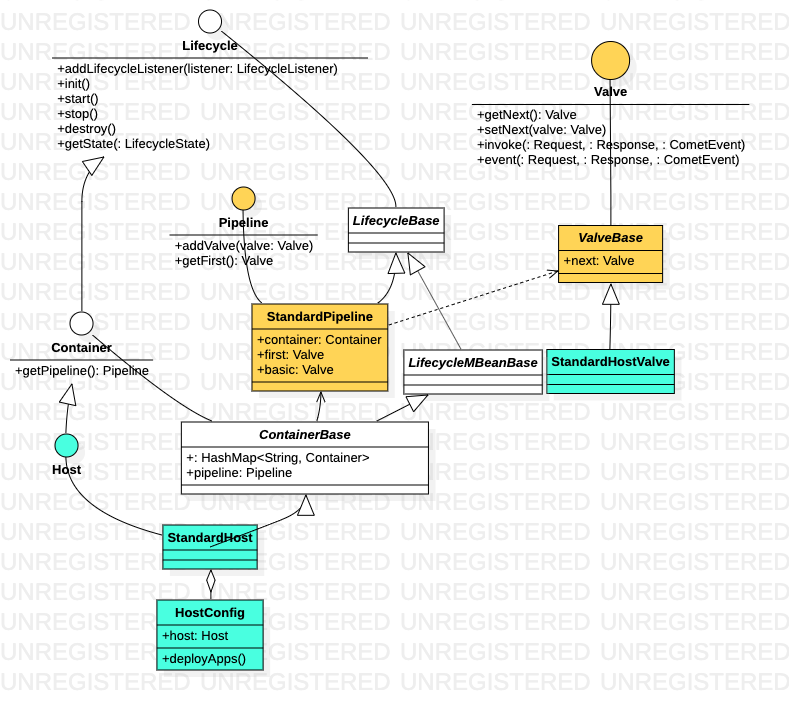
为了更清晰一点,上图只画出了Host 类族,Engine、Context、Wrapter 与Host 类似。黄色部分组成了一个pipeline,可以看到Engine、Context、Wrapter 和Host 作为容器,并不亲自“干活”,而是交给对应的pipeline。
public class CoyoteAdapter implements Adapter {
// 有读事件时会触发该操作
public boolean event(org.apache.coyote.Request req,
org.apache.coyote.Response res, SocketStatus status) {
...
// 将读取的数据写入到 request inputbuffer
request.read();
...
// 触发filter、servlet的执行
connector.getService().getContainer().getPipeline().getFirst().event(request, response, request.getEvent());
...
}
}
pipeline 逐步传递请求直到Servlet

Pipeline-Valve 是责任链模式,责任链模式是指在一个请求处理的过程中有很多处理者依次对请求进行处理,每个处理者负责做自己相应的处理,处理完之后将再调用下一个处理者继续处理。Valve 表示一个处理点,比如权限认证和记录日志。
每一个容器都有一个 Pipeline 对象,只要触发这个 Pipeline 的第一个 Valve,这个容器里 Pipeline 中的 Valve 就都会被调用到。不同容器的 Pipeline 是怎么链式触发的呢?Pipeline 中还有个 getBasic 方法。这个 BasicValve 处于 Valve 链表的末端,它是 Pipeline 中必不可少的一个 Valve,负责调用下层容器的 Pipeline 里的第一个 Valve。
Wrapper 容器的最后一个 Valve 会创建一个 Filter 链,并调用 doFilter 方法,最终会调到 Servlet 的 service 方法。
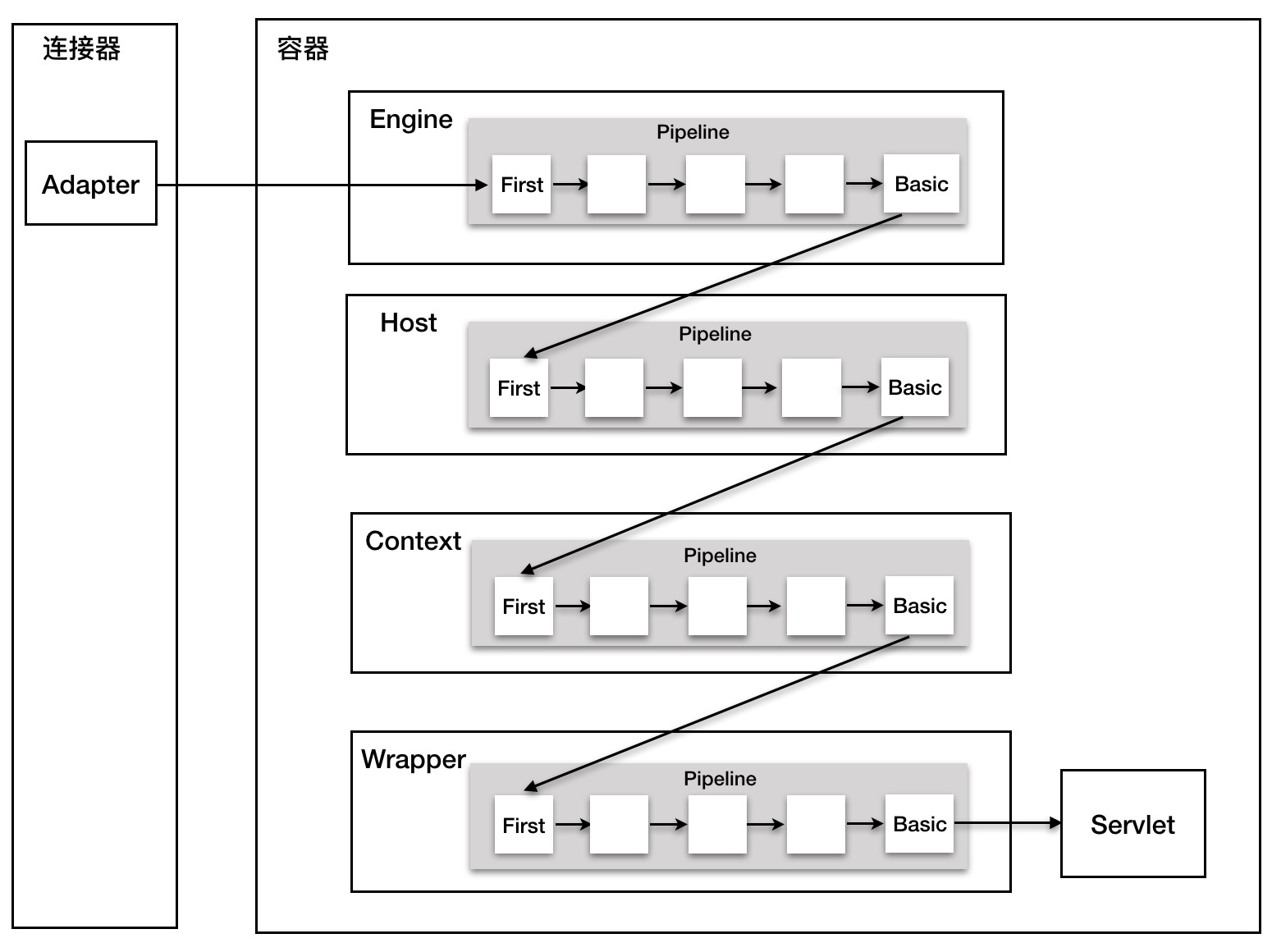
那 Valve 和 Filter 有什么区别吗?Valve 是 Tomcat 的私有机制,与 Tomcat 的基础架构 /API 是紧耦合的。Servlet API 是公有的标准,所有的 Web 容器包括 Jetty 都支持 Filter 机制。
Tomcat如何支持异步Servlet?
异步Servlet 的初衷就是解耦Servlet 线程与业务逻辑线程的。从上文类图可知,NioEndpoint中有一个Executor,selector.select 之后,Executor 异步处理 Socket.read + 协议解析 + Servlet.service,如果Servlet中的处理逻辑耗时越长就会导致长期地占用Executor,影响Tomcat的整体处理能力。 为此一个解决办法是
public class AsyncServlet extends HttpServlet {
Executor executor = xx
public void doGet(HttpServletRequest req, HttpServletResponse res) {
AsyncContext asyncContext = req.startAsync(req, res);
executor.execute(new AsyncHandler(asyncContext));
}
}
public class AsyncHandler implements Runnable {
private AsyncContext ctx;
public AsyncHandler(AsyncContext ctx) {
this.ctx = ctx;
}
@Override
public void run() {
//耗时操作
PrintWriter pw;
try {
pw = ctx.getResponse().getWriter();
pw.print("done!");
pw.flush();
pw.close();
} catch (IOException e) {
e.printStackTrace();
}
ctx.complete();
}
}
startAsync方法其实就是创建了一个异步上下文AsyncContext对象,该对象封装了请求和响应对象。然后创建一个任务用于处理耗时逻辑,后面通过AsyncContext对象获得响应对象并对客户端响应,输出“done!”。完成后要通过complete方法告诉Tomcat已经处理完,Tomcat就会请求对象和响应对象进行回收处理或关闭连接。

public class Request
implements HttpServletRequest {
public AsyncContext startAsync(ServletRequest request,
ServletResponse response) {
...
asyncContext = new AsyncContextImpl(this);
...
asyncContext.setStarted(getContext(), request, response,
request==getRequest() && response==getResponse().getResponse());
asyncContext.setTimeout(getConnector().getAsyncTimeout());
return asyncContext;
}
}
写回数据由Response 完成,从代码看,AsyncContextImpl.complete 方法表示 tomcat 可以重新开始关注该socket read事件了(之前一直在等socket 写回客户端数据)。

Sprint Boot如何利用Tomcat加载Servlet?
在内嵌式的模式下,Bootstrap 和 Catalina 的工作就由 Spring Boot 来做了,Spring Boot 调用了 Tomcat 的 API 来启动这些组件。
tomcat 源码中直接提供Tomcat类,其java doc中有如下表述:Tomcat supports multiple styles of configuration and startup - the most common and stable is server.xml-based,implemented in org.apache.catalina.startup.Bootstrap. Tomcat is for use in apps that embed tomcat. 从Tomcat类的属性可以看到,该有的属性都有了,内部也符合Server ==> Service ==> connector + Engine ==> Host ==> Context ==> Wrapper 的管理关系,下图绿色部分是通用的。

所以 Minimal 情况下 new 一个tomcat 即可启动一个tomcat。
Tomcat tomcat = new Tomcat();
tomcat.setXXX;
tomcat.start();
所以spring-boot-starter-web 主要体现在 创建 并配置Tomcat 实例,具体参见SpringBoot 中内嵌 Tomcat 的实现原理解析
其它
tomcat为什么运行war 而不是jar
tomcat 的功能简单说 就是让 一堆class文件+web.xml 可以对外支持http
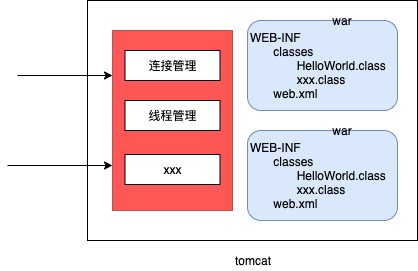
如果一个项目打成jar包,那么tomcat 在启动时 就要去分析下 这个jar 是一个web项目还是一个 普通二方库。
tomcat的类加载
Tomcat热部署与热加载 值得细读
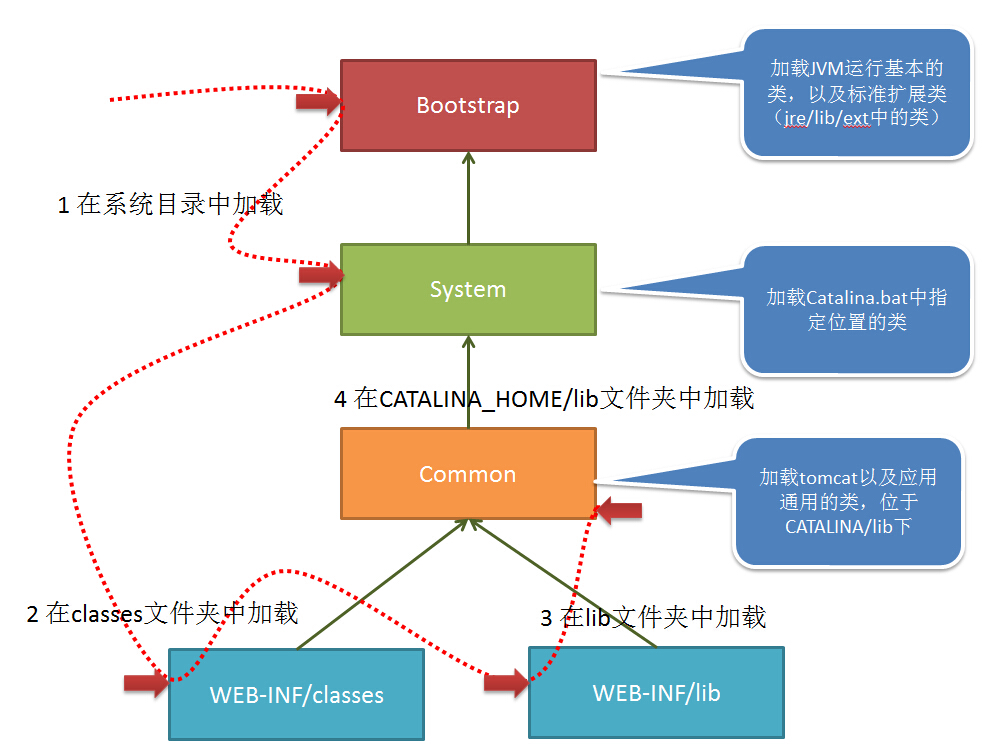
tomcat并没有完全遵循类加载的双亲委派机制,考虑几个问题:
- 如果在一个Tomcat内部署多个应用,多个应用内使用了某个类似的几个不同版本,如何互不影响?org.apache.catalina.loader.WebappClassLoader
- 如果多个应用都用到了某类似的相同版本,是否可以统一提供,不在各个应用内分别提供,占用内存呢?common ClassLoader 其实质是一个指定了classpath(classpath由catalina.properties中的common.loader 指定
common.loader="${catalina.base}/lib","${catalina.base}/lib/*.jar","${catalina.home}/lib","${catalina.home}/lib/*.jar")的URLClassLoader
public final class Bootstrap {
ClassLoader commonLoader = null;
ClassLoader catalinaLoader = null;
public void init() throws Exception {
initClassLoaders();
Thread.currentThread().setContextClassLoader(catalinaLoader);
SecurityClassLoad.securityClassLoad(catalinaLoader);
...
}
private void initClassLoaders() {
...
commonLoader = createClassLoader("common", null);
...
catalinaLoader = createClassLoader("server", commonLoader);
}
}

热部署和热加载是类似的,都是在不重启Tomcat的情况下,使得应用的最新代码生效。热部署表示重新部署应用,它的执行主体是Host,表示主机。热加载表示重新加载class,它的执行主体是Context,表示应用。
安全
如果你在Servlet代码中直接 加入System.exit(1) 你会发现,仅仅是作为一个tomcat 上层的一个“业务方”,却有能力干掉java进程,即tomcat的运行。
public class XXServlet extends HttpServlet {
protected void doGet(HttpServletRequest req, HttpServletResponse resp)
throws ServletException, IOException{
System.exit(1);
xxx
}
}
类图补充

同样一个颜色的是内部类的关系
留下评论