java内存模型和jvm内存布局
前言
- 前言
- 为什么会有内存模型一说
- java memory model 与 harware memory Architecture
- java 内存模型与并发读写控制
- 进程内存布局
- JVM内存区域新画法
- 其它材料
Java Memory Model 它是一系列文章 Java Concurrency 中的一篇文章。
为什么会有内存模型一说
Java内存模型:Java中的volatile有什么用?在不同的架构上,缓存一致性问题是不同的,例如 x86 采用了 TSO 模型,它的写后写(StoreStore)和读后读(LoadLoad)完全不需要软件程序员操心,但是 Arm 的弱内存模型就要求我们自己在合适的位置添加 StoreStore barrier 和 LoadLoad barrier。一些代码在 x86 机器上运行是没有问题的,但是在 Arm 机器就有概率打印出 Error。为了解决这个问题,Java 语言在规范中做出了明确的规定,也就是在 JSR 133 文档中规定了 Java 内存模型。内存模型是用来描述编程语言在支持多线程编程中,对共享内存访问的顺序。在 JSR133 文档中,这个内存模型有一个专门的名字,叫 Happens-before,它规定了一些同步动作的先后顺序。JMM 是一种标准规定,它并不管实现者是如何实现它的。纯粹的 JMM 本身的实用性并不强。PS:线程间共享变量 就是 cpu多核共享缓存
Java内存模型深入分析曾经,计算机的世界远没有现在复杂,那时候的cpu只有单核,我们写的程序也只会在单核上按代码顺序依次执行,根本不用考虑太多。后来,随着技术的发展,cpu的执行速度和内存的读写速度差异越来越大,人们很快发现,如果还是按照代码顺序依次执行的话,cpu会花费大量时间来等待内存操作的完成,这造成了cpu的巨大浪费。为了弥补cpu和内存之间的速度差异,计算机世界的工程师们在cpu和内存之间引入了缓存,虽然该方法极大的缓解了这一问题,但追求极致的工程师们觉得这还不够,他们又想到了一个点子,就是通过合理调整内存的读写顺序来进一步缓解这个问题。
- 比如,在编译时,我们可以把不必要的内存读写去掉,把相关连的内存读写尽量放到一起,充分利用缓存。
- 比如,在运行时,我们可以对内存提前读,或延迟写,这样使cpu不用总等待内存操作的完成,充分利用cpu资源,避免计算能力的浪费。
这一想法的实施带来了性能的巨大提升,但同时,它也带来了一个问题,就是内存读写的乱序,比如原本代码中是先写后读,但在实际执行时却是先读后写,怎么办呢?为了避免内存乱序给上层开发带来困扰,这些工程师们又想到了可以通过分析代码中的语义,把有依赖关系,有顺序要求的代码保持原有顺序,把剩余的没有依赖关系的代码再进行性能优化,乱序执行,通过这样的方式,就可以屏蔽底层的乱序行为,使代码的执行看起来还是和其编写顺序一样,完美。
多核时代的到来虽然重启了计算机世界新一轮的发展,但也带来了一个非常严峻的问题,那就是多核时代如何承接单核时代的历史馈赠。单核运行不可见的乱序,在多核情况下都可见了,且此种乱序已经严重影响到了多核代码的正确编写。默认乱序执行,在关键节点保证有序,这种方式不仅使单核时代的各种乱序优化依然有效,也使多核情况下的乱序行为有了一定的规范。基于此,各种硬件平台提供了自己的方式给上层开发,约定好只要按我给出的方式编写代码,即使是在多核情况下,该保证有序的地方也一定会保证有序。这套在多核情况下,依然可以让开发者指定哪些代码保证有序执行的规则,就叫做内存模型。
内存模型的英文是memory model,或者更精确的来说是memory consistency model,它其实就是一套方法或规则,用于描述如何在多核乱序的情况下,通过一定的方式,来保证指定代码的有序执行。它是介于硬件和软件之间,以一种协议的形式存在的。对硬件来说,它描述的是硬件对外的行为规范,对软件来说,它描述的是编写多线程代码的一套规则。这就衍生出了一个问题,就是不同硬件上的内存模型差异很大,完全不兼容。比如应用于桌面和服务器领域的x86平台用的是x86 tso内存模型。比如应用于手机和平板等移动设备领域的arm平台用的是weakly-ordered内存模型。比如最近几年大火的riscv平台用的是risc-v weak memory ordering内存模型。
深入理解并发编程艺术之内存模型处理器提供了一些特殊指令比如 LOCK,CMPXCHG,内存屏障等来保障多线程情况下的程序逻辑正常执行。但这依然存在几个问题:
- 处理器底层指令实现细节复杂难懂,开发人员需要付出巨大的学习成本。
- 不同的硬件和操作系统,对指令的支持和实现不一样,需要考虑跨平台的兼容性。
- 程序业务逻辑复杂多变,处理器和线程之间的数据操作依赖关系也相应更复杂。
因此高级语言会提供一种抽象的内存模型,用于描述多线程环境下的内存访问行为。无需关心底层硬件和操作系统的具体实现细节,就可以编写出高效、可移植的并发程序。对于 Java 语言,这种内存模型便是 Java 内存模型(Java Memory Model,简称 JMM)。Java 内存模型主要特性是提供了 volatile、synchronized、final 等同步原语,用于实现原子性、可见性和有序性。另一个重要的概念便是 happens-before 关系,用来描述并发编程中操作之间的偏序关系。除了 Java 语言,包括 golang,c++,rust 等高级语言也实现了自己的 happens-before 关系。Java 内存模型定义了主内存(main memory),本地内存(local memory),共享变量等抽象关系,来决定共享变量在多线程之间通信同步方式,即前面所说两个线程操作的内存可见性。其中本地内存,涵盖了缓存,写缓冲区,寄存器以及其他硬件和编译器优化等概念。
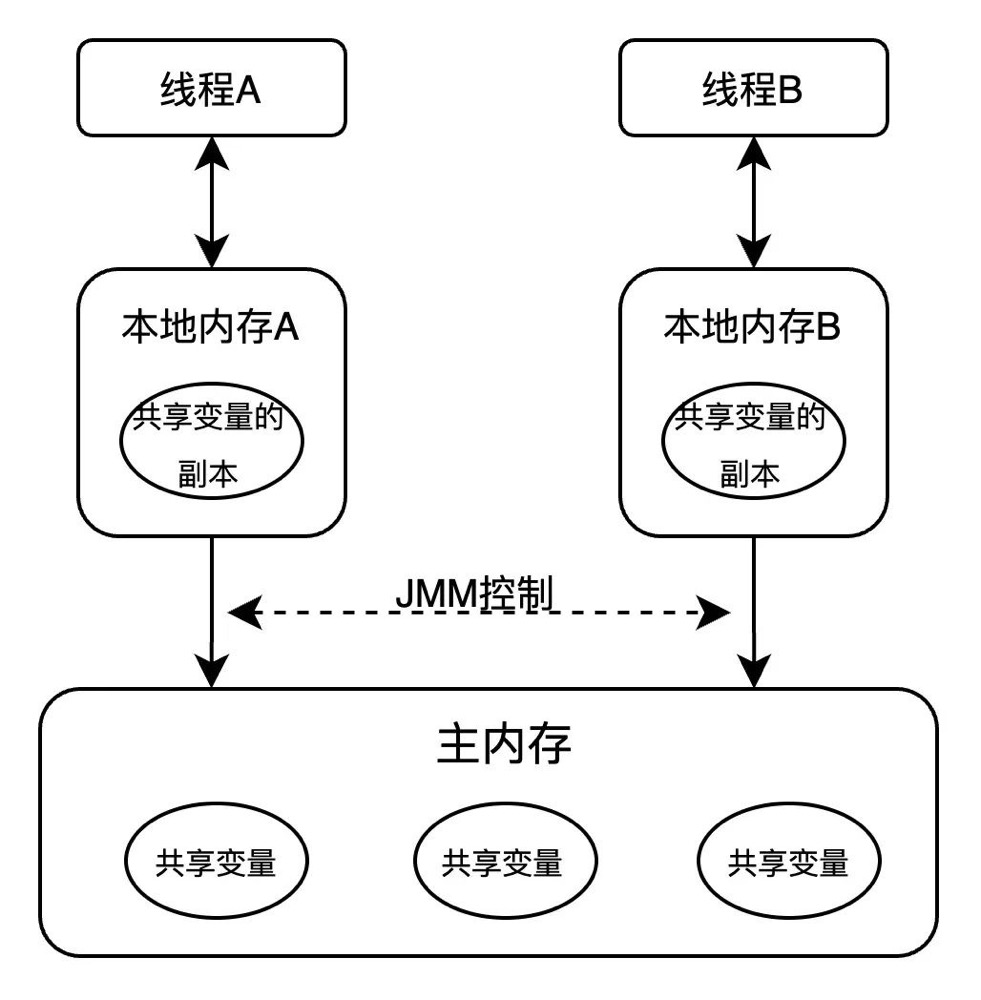
如图所示,如果线程 A 与线程 B 之间要通信的话,必须要经历下面 2 个步骤:
- 线程 A 把本地内存 A 中更新过的共享变量刷新到主内存中
- 线程 B 到主内存中去读取线程 A 之前已更新过的共享变量
硬件层面的内存模型
Memory Model:从SC到HRF Memory Model/存储模型并不是一个简单的硬件概念,往往是硬件/软件约定好的一套访问memroy的规则。Memory Model核心的一个词语是“Consistency”,区别于Cache的Coherence(一致性),可以用“连贯性”来翻译。二者是完全不同的两个概念。经典常见memory model
- SC(Sequential Consistency)
- 多个线程中的所有内存访问指令最终是以某种先后顺序(全局内存访问顺序,global memory order)访问集体共享的memory。然后具体到一个线程中的内存访问指令,这些指令在global memory order中的先后顺序跟它在程序中的先后顺序(program order)一致。线程1和2都可以访问二者共享的一个Memory,二者访存的指令序分别是ABC和123,在Memory端口上允许ABC123这样的顺序进入Memroy,也允许A12BC3、1AB23C……,但是不允许BAC123,因此SC模型要求线程自己的Program Order要体现在全局的Global Order中,B跑到A前面,不被允许。
- TSO(Total Store Ordering)。
- 处理器发展过程中,为了提升性能,store Memory时,引入了硬件Write buffer。让store操作是先进入write buffer,再进入memory。但是这一方法会导致:后续的load跳到了同线程store之前进入共享memory。在SC中这是违法的,禁掉write buffer是一种方法,但是会影响性能。遂提出TSO模型,认为load-> store序可以违背。但是一个很显然的问题在于如果是同地址的写后读,读一旦跑到写后面,结果可就错了。为了保证不出错,在TSO下,如果想人为要求一些保序行为,必须由使用者显式地进行保序操作。FENCE指令就是保序显式指令,或者叫内存barrier。可以简单理解为一堵墙,在FENCE之前的指令不能越过这堵墙跑到后面,反之,在其后的指令也不能跑到前面执行。(此处的前后是Program Order)
- TSO引入后,load->store序不再强制要求,借助write buffer甚至可以将同地址的load->store进行优化,即:store的data直接forwarding给后续的load,避免了load再去访问Memory。
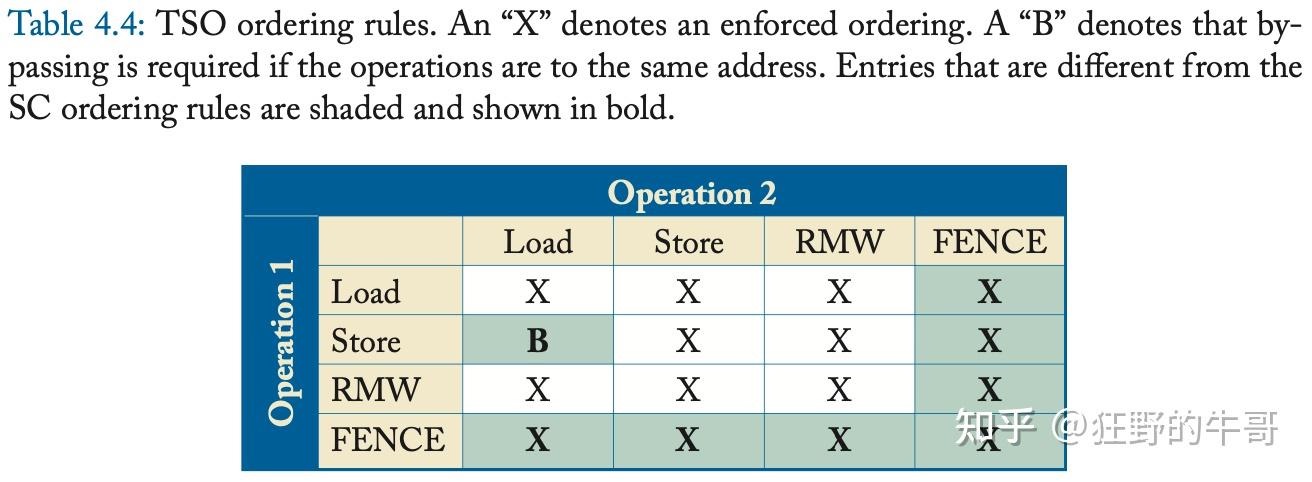 图中的RMW是read-modify-write,常常是atomic操作,在不可打断的过程中,完成一次完整的的先读,再改,改完结果再写入Memory的操作。
图中的RMW是read-modify-write,常常是atomic操作,在不可打断的过程中,完成一次完整的的先读,再改,改完结果再写入Memory的操作。
- XC/RC(Relax/Release Consistency) 在TSO的基础上,完全可以更进一步放松保序限制,因为从功能正确性来看,除了前后存在依赖的访存顺序一定要保证以外,绝大部分的访存操作顺序并不影响最终结果。这些访存顺序被允许乱序,是可以提升性能的,所以weak model在现当代的处理器中经常见到(PowerPC、ARM、RISCV)
- 变种概念之SC for DRF(Data_race_free)
- DRF: 认定程序没有data race 发生,即对于任何内存位置的读写操作,如果它们没有被适当的同步机制(如互斥锁、原子操作等)所保护,那么它们就不会同时发生。
- SC for DRF:用同步机制保护的访存序是SC的,而不被同步机制保护的可以完全乱序,认为它们不会产生竞争。
随着顺序性从strong→weak递减,访存程序的可优化性递增,但程序员为了功能正确要额外注意的点就会递增。但是芯片硬件设计复杂度不一定递增,因为有的时候无脑强制保序在硬件设计上反而简单,显式指定的同步/保序反而代价高一些。weak模型引入的顺序操作指令,比如FENCE(XC)、比如acquire/release(RC)。区别在于:
FENCE是更加严格的,保前也要保后,可以理解为一道墙隔开前后的访存指令段,不能逾越;
acquire/release则是将FENCE功能拆分,acquire保后,release保前。
acquire(x)
y = 1
z = 2
release(x)
//acuqire之后的访存指令,不允许跑到acquire之前去执行;
//release之前的访存指令,不允许跑到release之后去执行;
//允许单独出现,只保半边。
PS: 一开始认为要全部保序 ==> load/store 两类操作要保序(不管是不是针对同一变量) ==> 没有明说都不保序(atomic指令转向保证,提供fence/barrier等指令)
Java内存模型(Java Memory Model,JMM)JMM和Java运行时数据区没有直接对应关系
- 基于高速缓存的存储交互很好的解决了CPU和内存的速度的矛盾,但也引入了一个新的问题,缓存一致性,为了解决这个问题
- 总线锁机制,总线锁就是使用CPU提供的一个LOCK#信号,当一个处理器在总线上输出此信号,其他处理器的请求将被阻塞,那么该处理器就可以独占共享锁。
- 缓存锁机制,总线锁定开销太大,我们需要控制锁的力度,所以又有了缓存锁,核心就是缓存一致性协议,不同的CPU硬件厂商实现方式稍有不同,有MSI、MESI、MOSI等。
- JSR-133规范,即Java内存模型与线程规范。JSR133倾诉的对象有两个,一个是使用者(程序员),另外一个是JMM的实现方(JVM)。面向程序员,JSR133通过happens-before规则给使用者提供了同步语义的保证。面向实现者,JSR133限制了编译器和处理器的优化(禁止处理器重排序,要求Java编译器在生成指令序列时,插入特定类型的内存屏障指令,通过内存屏障指令来禁止特定类型的处理器重排序)。
- JMM对特性提供的支持如下: ||volatile关键字|synchronized关键字|Lock接口|Atomic变量| |—|—|—|—|—| |原子性|无法保障|可以保障|可以保障|可以保障| |可见性|可以保障|可以保障|可以保障|可以保障| |有序性|一定程度|可以保障|可以保障|无法保障|
语言层面的内存模型
图解JVM内存模型及JAVA程序运行原理通常,我们编写的Java源代码在编译后会生成一个Class文件,称为字节码文件。Java虚拟机负责将字节码文件翻译成特定平台下的机器代码,然后类加载器把字节码加载到虚拟机的内存中,通过解释器将字节码翻译成CPU能识别的机器码行。简言之,java的跨平台就是因为不同版本的 JVM。JVM与实际机器一样,他有自己的指令集(类似CPU通过指令操作程序运行),并在运行时操作不同的内存区域(JVM内存体系)。JVM位于操作系统之上,与硬件没有直接交互。每一条Java指令,Java虚拟机规范中都有详细定义,如怎么取操作数,怎么处理操作数,处理结果放在哪里。
由于Java的目标是write once, run anywhere,所以它不仅创造性的提出了字节码中间层,让字节码运行在虚拟机上,而不是直接运行在物理硬件上,它还在语言层面内置了对多线程的跨平台支持,也为此提出了Java语言的内存模型,这样,当我们用Java写多线程项目时,只要按照Java的内存模型规范来编写代码,Java虚拟机就能保证我们的代码在所有平台上都是正确执行的。在语言层面支持多线程在现在看来不算什么,但在那个年代,这也算是一项大胆的创举了,它也成为了首个主流编程语言中,内置支持多线程编码的语言。
JMM属于语言级的内存模型,它确保在不同的编译器和不同的处理器平台之上,通过禁止特定类型的编译器重排序和处理器重排序,为程序员提供一致的内存可见性保证。
Java内存模型FAQ(二) 其他语言,像C++,也有内存模型吗?大部分其他的语言,像C和C++,都没有被设计成直接支持多线程。这些语言对于发生在编译器和处理器平台架构的重排序行为的保护机制会严重的依赖于程序中所使用的线程库(例如pthreads),编译器,以及代码所运行的平台所提供的保障。也就是,语言上没有final、volatile 关键字这些,可以对编译器和处理器重排序 施加影响。
java memory model 与 harware memory Architecture
JVM在执行 Java 程序的过程中会把它管理的内存划分为若干个不同的数据区域。每个区域都有各自的作用。
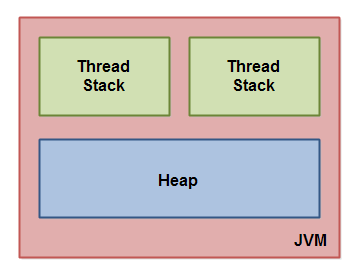
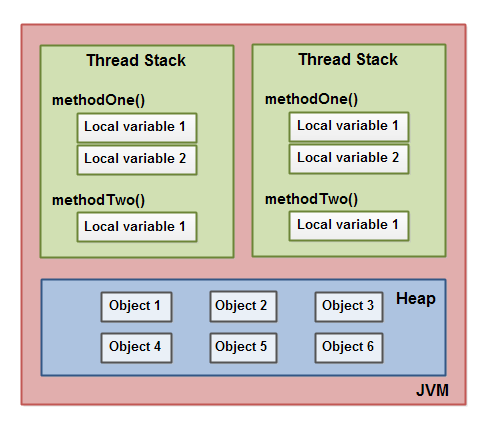
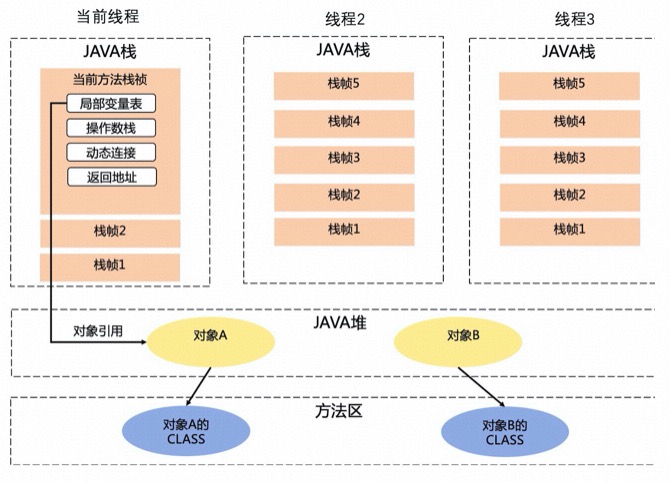
这几张图从粗到细,逐步引出了jvm 内存组成,栈的组成,堆的组成,栈和堆内数据的关系。逐步介绍了 thread stack、call stack(方法栈、栈帧)等概念
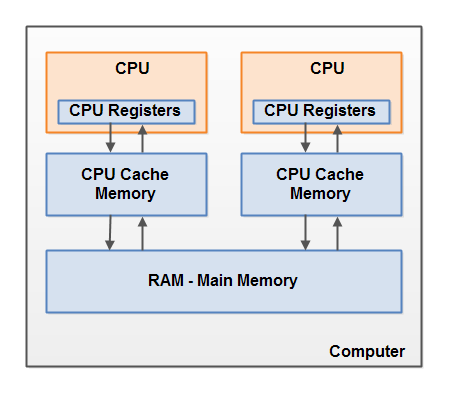
cpu ==> 寄存器 ==> cpu cache ==> main memory,cpu cache 由cache line 组成,cache line 是 与 main memory 沟通的基本单位,就像mysql innodb 读取 一行数据时 实际上不是 只读取一行,而是直接读取一页到内存一样。
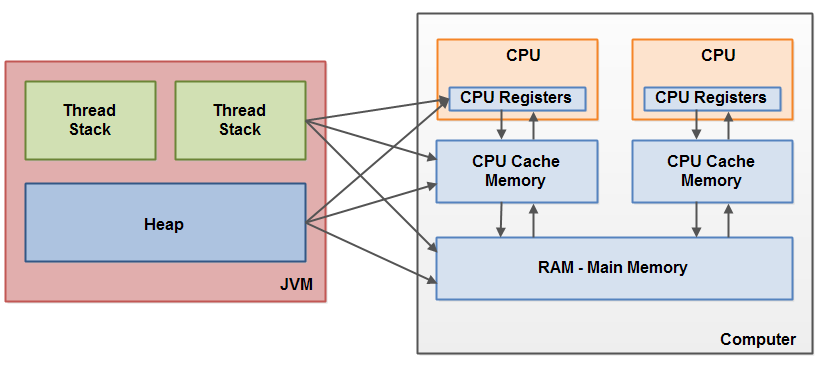
The hardware memory architecture does not distinguish between thread stacks and heap. On the hardware, both the thread stack and the heap are located in main memory. Parts of the thread stacks and heap may sometimes be present in CPU caches and in internal CPU registers. jvm 和 物理机 对“内存/存储” 有不同的划分,jvm 中没有cpu、cpu core 等抽象存在,也没有寄存器、cpu cache、main memory 的区分,因此 stack、heap 数据 可能分布在 寄存器、cpu cache、main memory 等位置。
When objects and variables can be stored in various different memory areas in the computer, certain problems may occur. The two main problems are:
- Visibility of thread updates (writes) to shared variables. 可以用volatile 关键字解决
- Race conditions when reading, checking and writing shared variables. 让两个线程 不要同时执行同一段代码,可以用synchronized block 解决,本质就是将竞争转移(从竞争同一个变量 到去竞争 同一个锁)。或者使用cas 保证竞争是原子的。
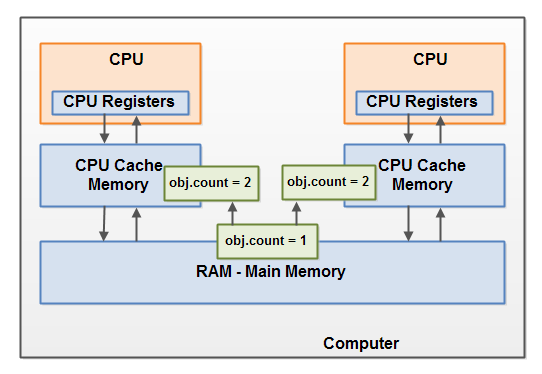
就着上图 去理解《java并发编程实战》中的有序性、原子性及可见性 ,会有感觉很多。基于JVM的内存结构,看一下程序在JVM内部是怎么运行的:
- JAVA源代码编译成字节码;
- 字节码校验并把JAVA程序通过类加载器加载到JVM内存中;
- 在加载到内存后针对每个类创建Class对象并放到方法区;
- 字节码指令和数据初始化到内存中;
- 找到main方法,并创建栈帧;
- 初始化程序计数器内部的值为main方法的内存地址;
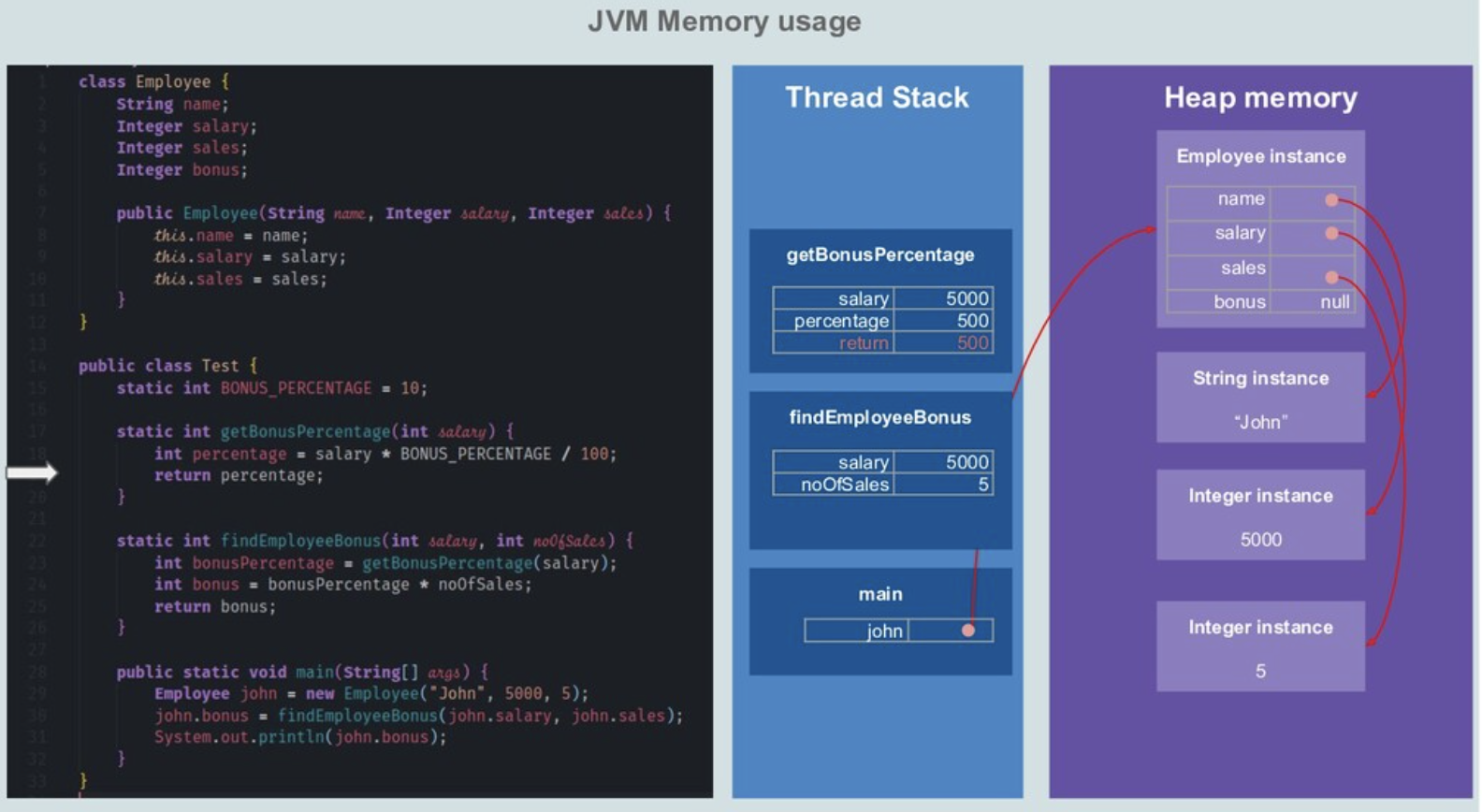
- 程序计数器不断递增,逐条执行JAVA字节码指令,把指令执行过程的数据存放到操作数栈中(入栈),执行完成后从操作数栈取出后放到局部变量表中,遇到创建对象,则在堆内存中分配一段连续的空间存储对象,栈内存中的局部变量表存放指向堆内存的引用;遇到方法调用则再创建一个栈帧,压到当前栈帧的上面。
可以脑补一下 基于jvm 内存模型,多线程执行 访问 对象的局部变量 的图,直接的观感是jvm 是从内存(heap)中直接拿数据的,会有原子性问题,但没有可见性问题。但实际上,你根本搞不清楚,从heap 中拿到的对象变量的值 是从寄存器、cpu cache、main memory 哪里拿到的,写入问题类似。jvm 提供volatile 等微操工具,介入两种内存模型的映射过程,来确保预期与实际一致,从这个角度看,jvm 并没有完全屏蔽硬件架构的特性(当然,也是为了提高性能考虑),不过确实做到了屏蔽硬件架构的差异性。
汇编代码中访问 Java 堆、栈和方法区中的数据,都是直接访问某个内存地址或者寄存器,之间并没有看见有什么隔阂。HotSpot 虚拟机本身是一个运行在物理机器上的程序,Java 堆、栈、方法区都在 Java 虚拟机进程的内存中分配(这意思是有一个变量指向堆、栈、方法区?)。在 JIT 编译之后,Native Code 面向的是 HotSpot 这个进程的内存,说变量 a 还在 Java Heap 中,应当理解为 a 的位置还在原来的那个内存位置上,但是 Native Code 是不理会 Java Heap 之类的概念的,因为那并不是同一个层次的概念。
java 内存模型与并发读写控制
Java内存模型深入分析如果程序中存在对同一变量的多个访问操作,且至少有一个是写操作,则这些访问操作被称为是conflicting操作,如果这些conflicting操作没有被happens-before规则约束,则这些操作被称为data race,有data race的程序就不是correctly synchronized,运行时也就无法保证sequentially consistent特性,没有data race的程序就是correctly synchronized,运行时可保证sequentially consistent特性。
happens-before规则由两部分组成,一部分是program order,即单线程中代码的编写顺序,另一部分是synchronizes-with,即多线程中的各种同步原语。也就是说,在单线程中,代码编写的前后顺序之间有happens-before关系,在多线程中,有synchronizes-with关联的代码之间也有happens-before关系。
- program order,即单线程中代码的字面顺序
- synchronizes-with,即各种同步操作,比如synchronized关键字,volatile关键字,线程的启动关闭操作等。定义多线程之间操作的顺序
极客时间《深入拆解Java虚拟机》
- happens-before 关系是用来描述两个操作的内存可见性的。如果操作 X happens-before 操作 Y,那么 X 的结果对于 Y 可见。
- 规定的happens-before 关系:Java 内存模型定义了六七种线程间的 happens-before 关系。比如 线程的启动操作(即 Thread.starts()) happens-before 该线程的第一个操作。
- 如果需要在没有happen before关系的时候可见,就要用到内存屏障了。Java 内存模型是通过内存屏障来禁止重排序的。语义上,内存屏障之前的所有写操作都要写入内存;内存屏障之后的读操作都可以获得同步屏障之前的写操作的结果。
- 应用程序开发者能够轻易地干预/表达不同线程的操作之间的内存可见性,包括锁、volatile 字段、final 字段与安全发布,所有的解决可见性的手段,最终都基于CPU指令lock。
了解Java可见性的本质 非常经典。volatile关键字的本质
- 禁止编译重排序;
- 插入运行时内存屏障(x86 lock)。
- 在每个volatile写操作的前面插入一个StoreStore屏障;
- 在每个volatile写操作的后面插入一个StoreLoad屏障;
- 在每个volatile读操作的前面插入一个LoadLoad屏障;
- 在每个volatile读操作的后面插入一个LoadStore屏障。
L1\2\3 cache解决CPU读写内存效率的问题,但引出了缓存一致性问题;MESI协议解决缓存一致性问题,但加剧了总线占用和资源竞争;store buffer进一步解决CPU效率的问题,但引出了可见性问题;最终可见性问题抛给了开发者,硬件只提供了lock指令。

进程内存布局
JVM 的内存布局和 Linux 进程的内存布局有什么关系?它们是一样的吗? 推荐细读。
Linux内核基础知识进程内存布局
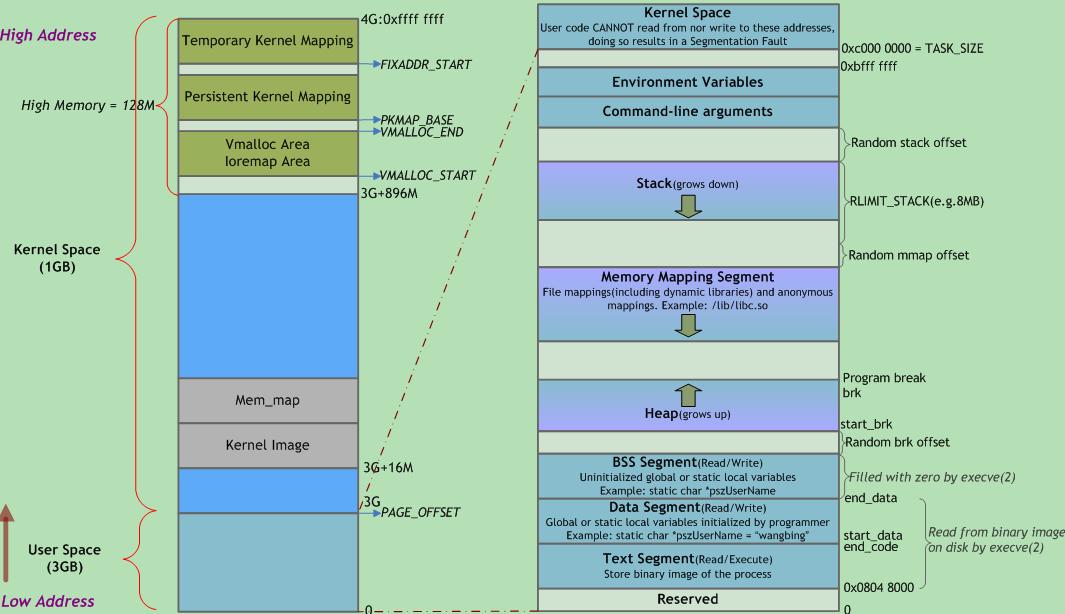
左右两侧均表示虚拟地址空间,左侧以描述内核空间为主,右侧以描述用户空间为主。右侧底部有一块区域“read from binary image on disk by execve(2)”,即来自可执行文件加载,jvm的方法区来自class文件加载,那么 方法区、堆、栈 便可以一一对上号了。
jvm 作为 a model of a whole computer,便与os 有许多相似的地方,包括并不限于:
- 针对os 编程的可执行文件,主要指其背后代表的文件格式、编译、链接、加载 等机制
- 可执行文件 的如何被执行,主要指 指令系统及之上的 方法调用等
- 指令执行依存 的内存模型
这三者是三个不同的部分,又相互关联,比如jvm基于栈的解释器与jvm 内存模型 相互依存。
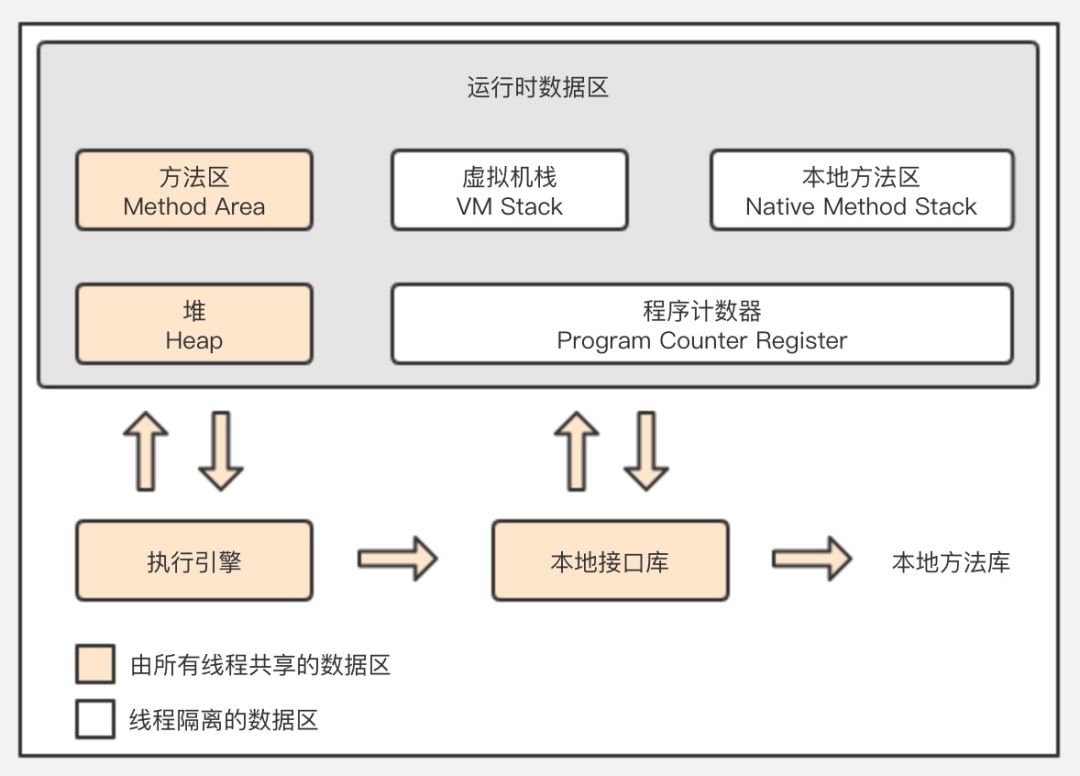
JVM内存区域新画法
- 程序计数器:字节码行号指示器,每个线程需要一个程序计数器
- 虚拟机栈:方法执行时创建栈帧(存储局部变量,操作栈,动态链接,方法出口)编译时期就能确定占用空间大小,线程请求的栈深度超过jvm运行深度时抛StackOverflowError,当jvm栈无法申请到空闲内存时抛OutOfMemoryError,通过-Xss,-Xsx来配置初始内存
- 本地方法栈:执行本地方法,如操作系统native接口。
- 堆:存放对象的空间,通过-Xmx,-Xms配置堆大小,当堆无法申请到内存时抛OutOfMemoryError
- 方法区:存储类数据,常量,常量池,静态变量,通过MaxPermSize参数配置
- 对象访问:初始化一个对象,其引用存放于栈帧,对象存放于堆内存,对象包含属性信息和该对象父类、接口等类型数据(该类型数据存储在方法区空间,对象拥有类型数据的地址)
一个cpu对应一个线程,一个线程一个栈,或者反过来说,一个栈对应一个线程,所有栈组成栈区。我们从cpu的根据pc指向的指令的一次执行开始:
- cpu执行pc指向方法区的指令
- 指令=操作码+操作数,jvm的指令执行是基于栈的,所以需要从栈帧中的“栈”区域获取操作数,栈的操作数从栈帧中的“局部变量表”和堆中的对象实例数据得到。
- 当在一个方法中调用新的方法时,根据栈帧中的对象引用找到对象在堆中的实例数据,进而根据对象实例数据中的方法表部分找到方法在方法区中的地址。根据方法区中的数据在当前线程私有区域创建新的栈帧,切换PC,开始新的执行。
虚拟机栈、本地栈和程序计数器在编译完毕后已经可以确定所需内存空间,程序执行完毕后也会自动释放所有内存空间,所以不需要进行动态回收优化。JVM内存调优主要针对堆和方法区两大区域的内存。
PermGen ==> Metaspace
Permgen vs Metaspace in JavaPermGen (Permanent Generation) is a special heap space separated from the main memory heap.
- The JVM keeps track of loaded class metadata in the PermGen.
- all the static content: static methods,primitive variables,references to the static objects
- bytecode,names,JIT information
- before java7,the String Pool
With its limited memory size, PermGen is involved in generating the famous OutOfMemoryError. What is a PermGen leak?
Metaspace is a new memory space – starting from the Java 8 version; it has replaced the older PermGen memory space. The garbage collector now automatically triggers cleaning of the dead classes once the class metadata usage reaches its maximum metaspace size.with this improvement, JVM reduces the chance to get the OutOfMemory error.
其它材料
JSR 133 (Java Memory Model) FAQ及其译文Java内存模型FAQ(一) 什么是内存模型,深入理解Java内存模型(一)——基础系列文章
Java includes several language constructs, including volatile, final, and synchronized, which are intended to help the programmer describe a program’s concurrency requirements to the compiler. The Java Memory Model defines the behavior of volatile and synchronized, and, more importantly, ensures that a correctly synchronized Java program runs correctly on all processor architectures.
留下评论