为什么netty比较难懂?
前言
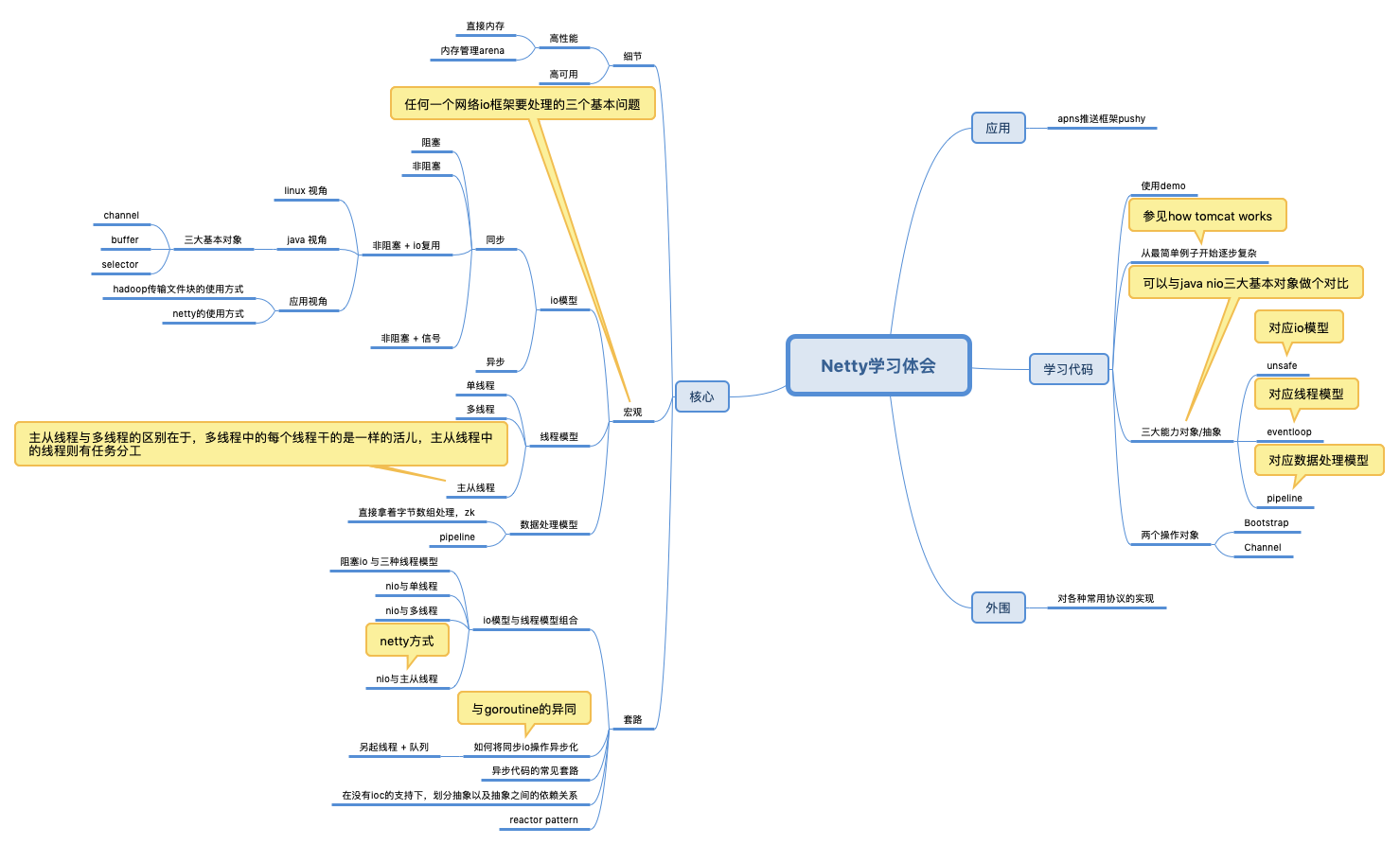
到目前为止,笔者关于netty写了十几篇博客,内容非常零碎,笔者一直想着有一个总纲的东西来作为主干,将这些零碎place it in context。所以梳理了一张图,从上往下“俯视”看,netty有哪些东西?
为什么很多人会觉得学习netty代码比较难(这也是笔者最初的感受)?因为对于大部分人来说,是先接触了netty,才第一次接触nio、同步操作异步化 等技术/套路,除了要理解netty代码本身的抽象之外,还需理解很多新概念。,此外,相比 C/C++ ,Java 的封装程度比较高。Java 语言本身的 JVM 中 NIO 对网络的封装就已经屏蔽了很多底层的概念了,再加上 Netty 又封装了一层,所以 Java 开发者常用的一些术语和概念和其它语言出入很大。
可以和go 版本的netty 对比着看 Go 语言网络库 getty 的那些事 未读完
剖析Netty内部网络实现原理 很经典
三个基本的技术点
一个稍微复杂的框架,必然伴随几个抽象以及抽象间的依赖关系,那么依赖的关系的管理,可以选择spring(像大多数j2ee项目那样),也可以硬编码。这就是我们看到的,每个抽象对象有一套自己的继承体系,然后抽象对象子类之间又彼此复杂的交织。比如Netty的eventloop、unsafe和pipeline,channel作为最外部操作对象,聚合这三者,根据聚合的子类的不同,Channel也有多个子类来体现。
同时,做一个粗略的对应
| 模型 | 代码抽象 |
|---|---|
| io模型 | unsafe |
| 线程模型 | eventloop |
| 数据处理模型 | pipeline |
通过聚合eventloop ,channel 有了提供异步接口的能力,参见netty中的线程池
Netty与reactor pattern
reactor pattern 理念 参见 Understanding Reactor Pattern: Thread-Based and Event-Driven,并且建议你读三遍。任何框架,一定都是先有了理念和思想,然后体现在代码上。看代码之前,找到那个理念和思想。
- 阻塞io 无论怎么玩,Unfortunately, there is always a one-to-one relationship between connections and threads
- Event-driven approach can separate threads from connections, which only uses threads for events on specific callbacks/handlers.
- An event-driven architecture consists of event creators and event consumers. The creator, which is the source of the event, only knows that the event has occurred. Consumers are entities that need to know the event has occurred. They may be involved in processing the event or they may simply be affected by the event.
- The reactor pattern is one implementation technique of the event-driven architecture. In simple words, it uses a single threaded event loop blocking on resources emitting events and dispatches them to corresponding handlers/callbacks.
- There is no need to block on I/O, as long as handlers/callbacks for events are registered to take care of them. Events are like incoming a new connection, ready for read, ready for write, etc.
- This pattern decouples modular application-level code from reusable reactor implementation.
- The purpose of the Reactor design pattern is to avoid the common problem of creating a thread for each message/request/connection.Avoid this problem is to avoid the famous and known problem C10K.
《反应式设计模式》 基于事件的系统通常建立在一个事件循环上。任何时刻只要发生了事情, 对应的事件就会被追加到一个队列中。事件循环持续的从队列中拉取事件,并执行绑定在事件上的回调函数。每一个回调函数通常都是一段微小的、匿名的、响应特定事件(例如鼠标点击)的过程。回调函数也可能产生新事件,这些事件随后也会被追加到队列里面等待处理。
netty 代码是如何驱动的
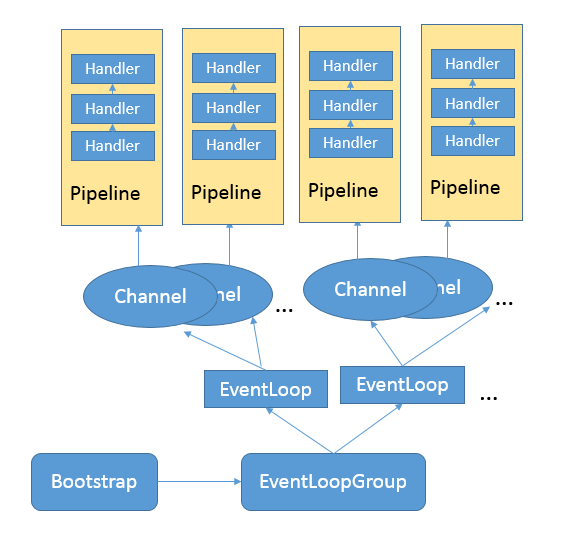
netty 首先是由线程池驱动的,其次,与我们熟悉的“并发执行体”之间只有竞争关系不同,“执行体”之前可以移交数据(也就是合作),一个线程除了处理io 还可以处理task
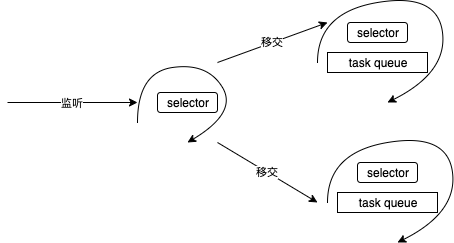
io编程的理想姿势
Go语言TCP Socket编程从tcp socket诞生后,网络编程架构模型也几经演化,大致是:“每进程一个连接” –> “每线程一个连接” –> “Non-Block + I/O多路复用(linux epoll/windows iocp/freebsd darwin kqueue/solaris Event Port)”。伴随着模型的演化,服务程序愈加强大,可以支持更多的连接,获得更好的处理性能。
不过I/O多路复用也给使用者带来了不小的复杂度,以至于后续出现了许多高性能的I/O多路复用框架, 比如libevent、libev、libuv等,以帮助开发者简化开发复杂性,降低心智负担。不过Go的设计者似乎认为I/O多路复用的这种通过回调机制割裂控制流的方式依旧复杂,且有悖于“一般逻辑”设计,为此Go语言将该“复杂性”隐藏在Runtime中了:Go开发者无需关注socket是否是 non-block的,也无需亲自注册文件描述符的回调,只需在每个连接对应的goroutine中以“block I/O”的方式对待socket处理即可。PS:netty 在屏蔽java nio底层细节方面做得不错, 但因为java/jvm的限制,“回调机制割裂控制流”的问题依然无法避免。
一个典型的Go server端程序大致如下:
func handleConn(c net.Conn) {
defer c.Close()
for {
// read from the connection
// ... ...
// write to the connection
//... ...
}
}
func main() {
l, err := net.Listen("tcp", ":8888")
if err != nil {
fmt.Println("listen error:", err)
return
}
for {
c, err := l.Accept()
if err != nil {
fmt.Println("accept error:", err)
break
}
// start a new goroutine to handle
// the new connection.
go handleConn(c)
}
}
留下评论