模型服务化(未完成)
简介
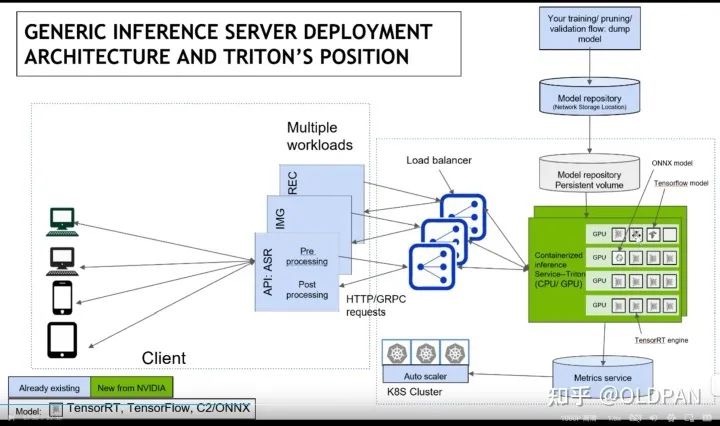
模型推理服务化框架Triton保姆式教程(一):快速入门Triton 是 Nvidia 发布的一个高性能推理服务框架,可以帮助开发人员高效轻松地在云端、数据中心或者边缘设备部署高性能推理服务。其中主要特征包括:
- 支持多种深度学习框架(Triton 称之为backend,tf、pytorch、FasterTransformer都有对应backend),Triton Server 可以提供 HTTP/gRPC 等多种服务协议。同时支持多种推理引擎后端,如:TensorFlow, TensorRT, PyTorch, ONNXRuntime 等。Server 采用 C++ 实现,并采用 C++ API调用推理计算引擎,保障了请求处理的性能表现。
- 模型并发执行
- 动态批处理(Dynamic batching)
- 有状态模型的序列批处理(Sequence batching)和隐式状态管理(implicit state management)
- 提供允许添加自定义后端和前/后置处理操作的后端 API
- 支持使用 Ensembling 或业务逻辑脚本 (BLS)进行模型流水线
- HTTP/REST和GRPC推理协议是基于社区开发的KServe协议
- 支持使用 C API 和 Java API 允许 Triton 直接链接到您的应用程序,用于边缘端场景
- 支持查看 GPU 利用率、服务器吞吐量、服务器延迟等指标 PS:基本上对一个推理服务框架的需求都在这里了。
深度学习部署神器——triton-inference-server入门教程指北 未细读。
PyTorch/TensorFlow 等框架相对已经解决了模型的训练/推理统一的问题,因此模型计算本身不存在训推一体的问题了。完整的服务通常还存在大量的预处理/后处理等业务逻辑,这类逻辑通常是把各种输入经过加工处理转变为 Tensor,再输入到模型,之后模型的输出 Tensor 再加工成目标格式。核心要解决的问题就是:预处理和后处理需要提供高性能训推一体的方案。
2023年10月19日,NVIDIA正式宣布TensorRT-LLM开放使用,TensorRT-LLM的主要特性有:
- 支持多GPU多节点推理
- 包含常见大模型的转换、部署示例(LLaMA系列、ChatGLM系列、GPT系列、Baichuan、BLOOM、OPT、Falcon等)
- 提供Python API支持新模型的构建和转换
- 支持Triton推理服务框架
- 支持多种NVIDIA架构:Volta, Turing, Ampere, Hopper 和Ada Lovelace
- 除了FastTransformer中针对transformer结构的优化项,新增了多种针对大模型的优化项,如In-flight Batching、Paged KV Cache for the Attention、INT4/INT8 Weight-Only Quantization、SmoothQuant、Multi-head Attention(MHA)、Multi-query Attention (MQA)、Group-query Attention(GQA)、RoPE等。 大模型推理实践-1:基于TensorRT-LLM和Triton部署ChatGLM2-6B模型推理服务
TensorRT-LLM
在生产环境通过 TensorRT-LLM 部署 LLM 未读。
Triton Inference Server 主要负责整个模型的部署,而TensorRT-LLM 主要负责模型推理的加速,使模型推理能够更加高效。 TensorRT-LLM 实际上是基于 TensorRT 的,它对 LLM(语言模型)相关的一些操作进行了一些优化,但是很多 CUDA kernel 仍然来自于 TensorRT。
TensorRT-LLM 增加的优化部分包括:
- KV Caching,每次计算中,KV Caching 始终是一个较大的部分,因为这部分有很多无需进行重复计算的内容,需要将之前的计算结果保存在 Caching 中,这是一个非常重要的优化。
- 对于 MHA(Multi-Head Attention)kernels,也就是多头注意力的 CUDA kernel,TensorRT-LLM 也做了增强。
- Inflight Batching。语言模型接收的每句话长度都不同,对于比较短的话,很快就结束了,是否可以在运行时插入后面一句话进行推理呢?
- 拥有 Multi-GPU、Multi-Node 等功能。
留下评论