《实现领域驱动设计》笔记
简介
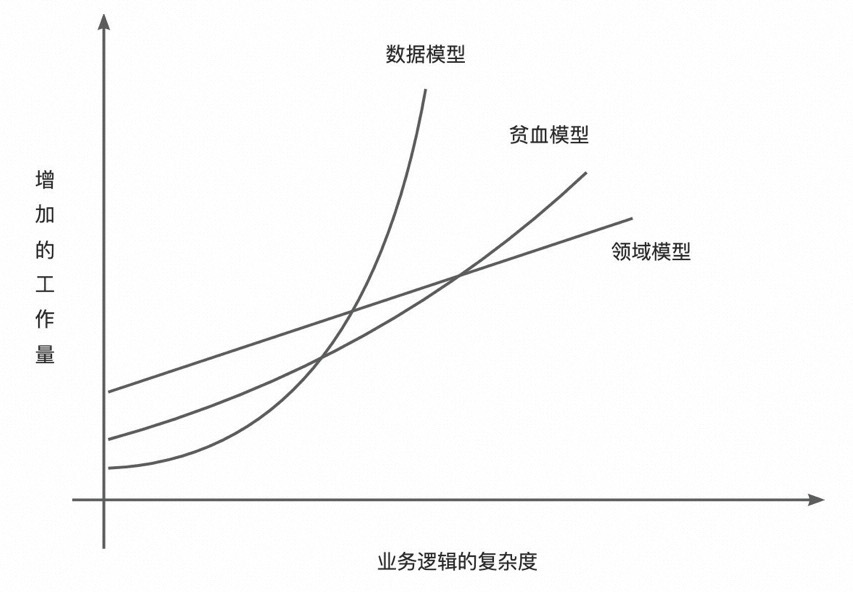
DDD绝非是什么标新立异之物,我更倾向于将其看成是软件发展的自然结果。就像20世纪六七十年代出现了软件危机之后,面向对象成为了人们的救赎;瀑布式开发过程遇到瓶颈时,敏捷被搬上了舞台;而DDD则是对传统的以数据为中心的建模方式的反思结果。
如果你的项目完全以数据为中心,所有的操作都通过对数据库的crud完成,那么你并不需要DDD。此时你的团队只需要一个漂亮的数据库表编辑器。如果做的是基础架构,比如开发一个RPC框架,也不需要用领域驱动。运用领域驱动的前提一定是业务足够复杂且多变,需要系统灵活支持。如果你的系统只有25到30个业务操作, 这应该是相当简单的,你没有感受到由复杂性和业务变化所带来的痛苦。 当你的系统有三四十个use case的时候,软件的复杂性便暴露出来了,如果软件功能在未来几年不断变化,ddd将有助于你管理复杂性和应对变化。
守住三个基本原则
- 必须通过领域建模来驱动设计。
- One principle behind DDD is to bridge the gap between domain experts and developers by using the same language to create the same understanding.
- Another principle is to reduce complexity by applying object oriented design and design patters to avoid reinventing the wheel.
Domain-Driven Design is a way of structuring and modeling the software after the Domain it belongs to. What this means is that a domain first has to be considered for the software that is written. The domain is the topic or problem that the software intends to work on. The software should be written to reflect the domain. The architecture in the code should also reflect on the domain.
书的基本思路:传统编码的问题 ==> DDD的基本概念 ==> DDD与架构的关系 DDD在某个架构下找到自己“位置”:领域模型只负责业务逻辑,此外还有应用层和基础设施层与领域层协作 ==> 领域模型内,领域对象的组成与彼此之间的关系
DDD入门
public void saveConsumer(String id,name,age,address,...){
Consumer consumer = new Consumer();
if(id != null){
...
}
...
consumerDao.save(consumer);
}
saveConsumer 至少存在三大问题
- saveConsumer 的业务意图不明确,代码无法反应业务意图,使用同一个方法来处理多个用例流
- 方法的实现本身增加了潜在的复杂性(比如复杂的参数校验)
- Consumer 只是一个data holder
一种优化:每一个应用层方法对应一个单一的用例流
interface Consumer{
public changePersonalName(String firstName,String lastName);
...
}
我们希望对对象行为的命名能够传达准确的业务含义,也即反映通用语言。要达到这样的目的,肯定不是先在类上定义属性,然后向客户端暴露getter和setter那么简单。那只是在创建纯数据模型。如果只提供setter 和getter 会怎么样?
- 暴露了 对象的内部结构
- 贫血对象/setter 和getter 并没有业务价值,方法的名字没有业务含义。如果Consumer 只修改了地址 而没修改邮政编码会发生什么呢?显然是一种领域逻辑的泄漏。这要求开发对对象很熟悉(随着迭代并不总能办到);如果软件留下太多的地方让用户自己去理解,用户往往需要培训才能做出操作决定。《程序员修炼之道》不应该根据对象的内部状态做决策,然后更新对象,这样做完全破坏了封装的优势,这样做时,完全把相关的知识扩散到整个代码中,只管命令不要询问。
领域建模/对需求建模
万事开头难,需求是项目最开始的输入,肯定是非常重要的,但现实情况往往是当我们接到需求后第一个想到的问题确是我该如何实现,而没有在业务思考这一块过多的停留。如果最开始理解的输入是错误的,后面的过程再优秀可想而知也只能是垃圾。为了解决这一问题,很多优秀的大佬发明了很多对需求进行功能建模的工具,主要目的就是让我们更好的理解需求并认识其背后的本质。
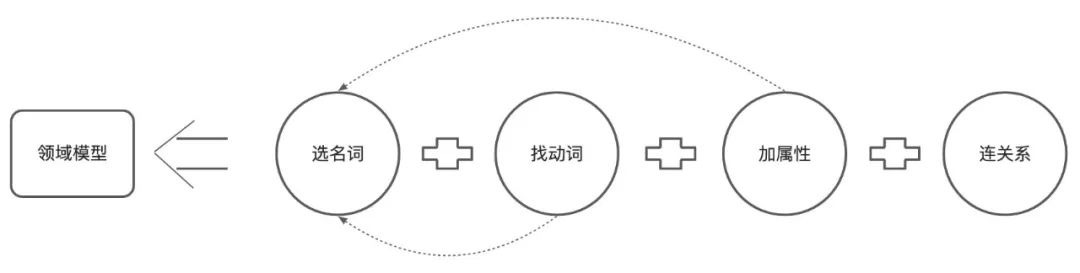
在我们日常工作的项目中,大多数场景都可以通过在需求用例中通过找名称的方式来最终刻画出领域模型,当然找到的名词后并不是所有的都符合要求,这时可以通过一条原则”一个名词或实体必有其属性和行为,一属性或行为也必归属于一个实体”来进行提炼,不符合这条原则的名词就是需求剔除的。总体来说建模一共分为四步
- 选名词:从用例中选出所有名词,在去伪存真选出符合要求的;
- 找动词:找出所有动词,在判断这些动词属不属于上一步选出的名词所具有的行为;
- 加属性:找出所有属性,在判断这些属性属不属于上一步选出的名词所具有的特征;
- 连关系:确定实体和实体之间的协作关系;
限界上下文/Bounded Context
领域上下文是一个显式的边界,领域模型便存在于这个边界之内。创建边界的原因在于:每个模型概念,包括它的属性和操作,在边界之内都具有特殊的含义。在很多情况下, 在不同模型中存在名字相同或相近的对象,但是它们的意思却不同。 当模型被一个显式的边界所包围时,其实每个概念的含义便是确定的了。任何两个事物,如果不加约束的话,我们总是可以从很多角度进行抽象。比如我在《程序员的底层思维》中讲过一个笑话,问:金鱼和激光笔有什么共同之处?答:它们都不会吹口哨。类似这样天马行空的“抽象”,可以说是无穷无尽。但真正有用的抽象是在领域上下文下,对我们解决问题有帮助的抽象。
考虑一个图书出版机构,它需要处理图书生命周期的不同阶段
- 概念设计,计划出书。此时,连书名都没有。
- 联系作者,签订合同
- 图书编辑、设计布局、插图。此时,图书是一些列稿件、注释、校正
- 出版纸质书
- 市场营销。此时,营销人员只关心书的简介
- 将图书卖给销售商或读者。此时,重点是书的价格、重量、物流目的地。
如果整个系统只有一个Book对象,概念混淆、意见分歧和争论是不可避免的。如果我们将系统划分为3个上下文,每个上下文都有Book
- 创作上下文,Book 是一个“作品”
- 出版上下文,Book 可以视为一个印刷品(可能不准确)、出版物
- 销售上下文,Book 可以视为一个 商品
如果你在不同的界限上下文中看到了完全相同的对象,通常意味着你的模型是错误的。有些相似的对象拥有不同的属性和行为(一个对象在不同上下文的“分身”),此时通常可以认为上下文边界的划分是合理的。 PS:从下往上看,每个上下文内部都有统一且明确的业务术语定义,包含自己完整的领域模型(实体/值对象/聚合等)。
名词解释
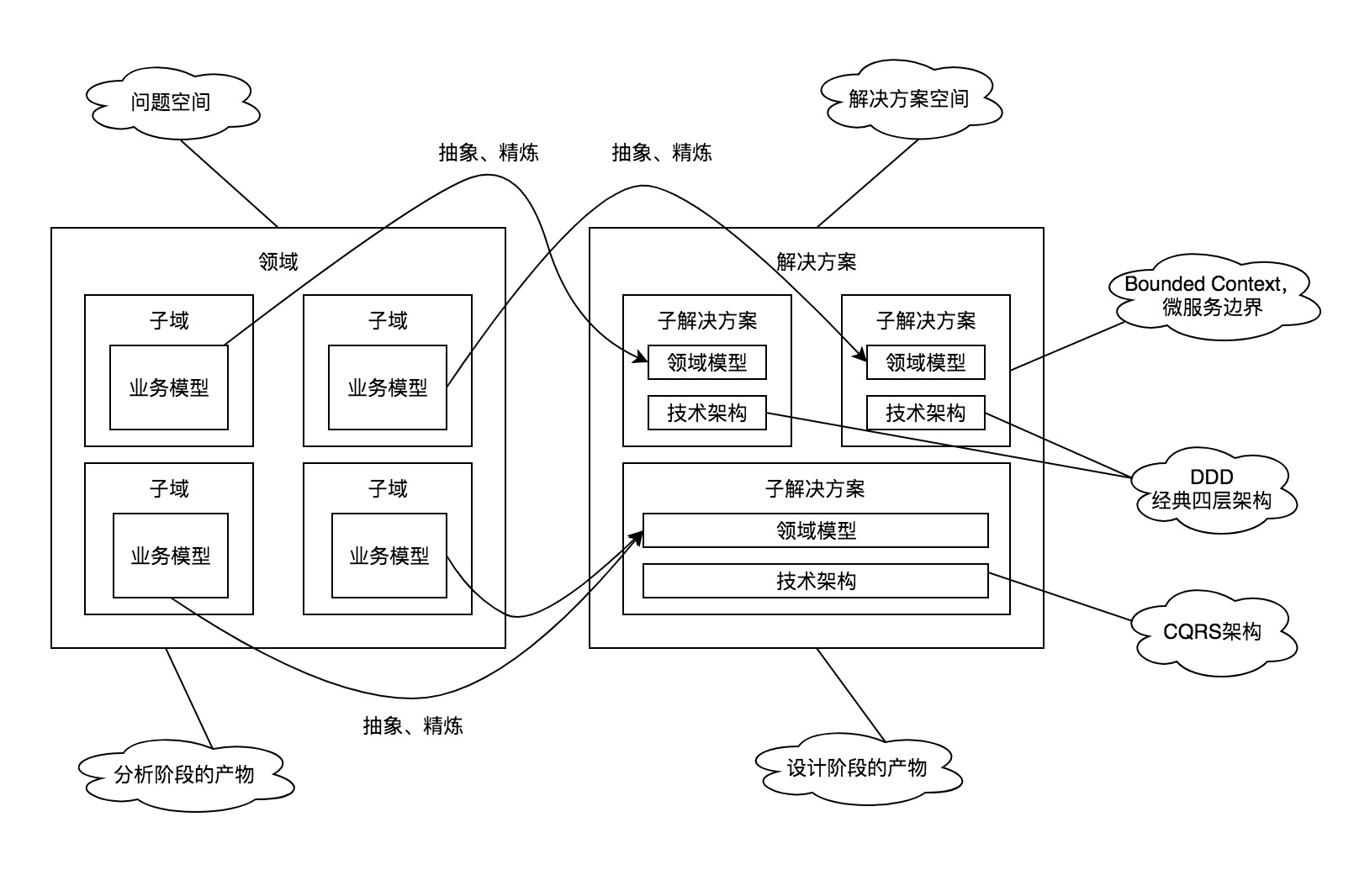
- 领域是一个边界,所以可以划分领域的大小,即领域划分,划分出来的子领域简称子域,每个子域对应一个小的问题域和和小的业务;
- BC和子域的关系?没有关系。因为它们是不同的东西被划分后的产物,对解决方案空间进行划分产生了BC,对领域划分后产生了子域。
- 领域模型和业务模型是不同的
叫什么不重要,我们真正要学会的是划分的原则、依据、经验
需要特别注意的是,领域模型设计只是整个软件设计中的很小一部分。除了领域模型设计之外,要落地一个系统,我们还有非常多的其他设计要做,比如:容量规划;架构设计;数据库设计;缓存设计;框架选型;发布方案;数据迁移、同步方案;分库分表方案;回滚方案;高并发解决方案;一致性选型;性能压测方案。
DDD——事件风暴 ==> 归类划分的分析方法
《DDD实战》DDD 战略设计会建立领域模型,事件风暴是建立领域模型的主要方法,它是一个从发散到收敛的过程
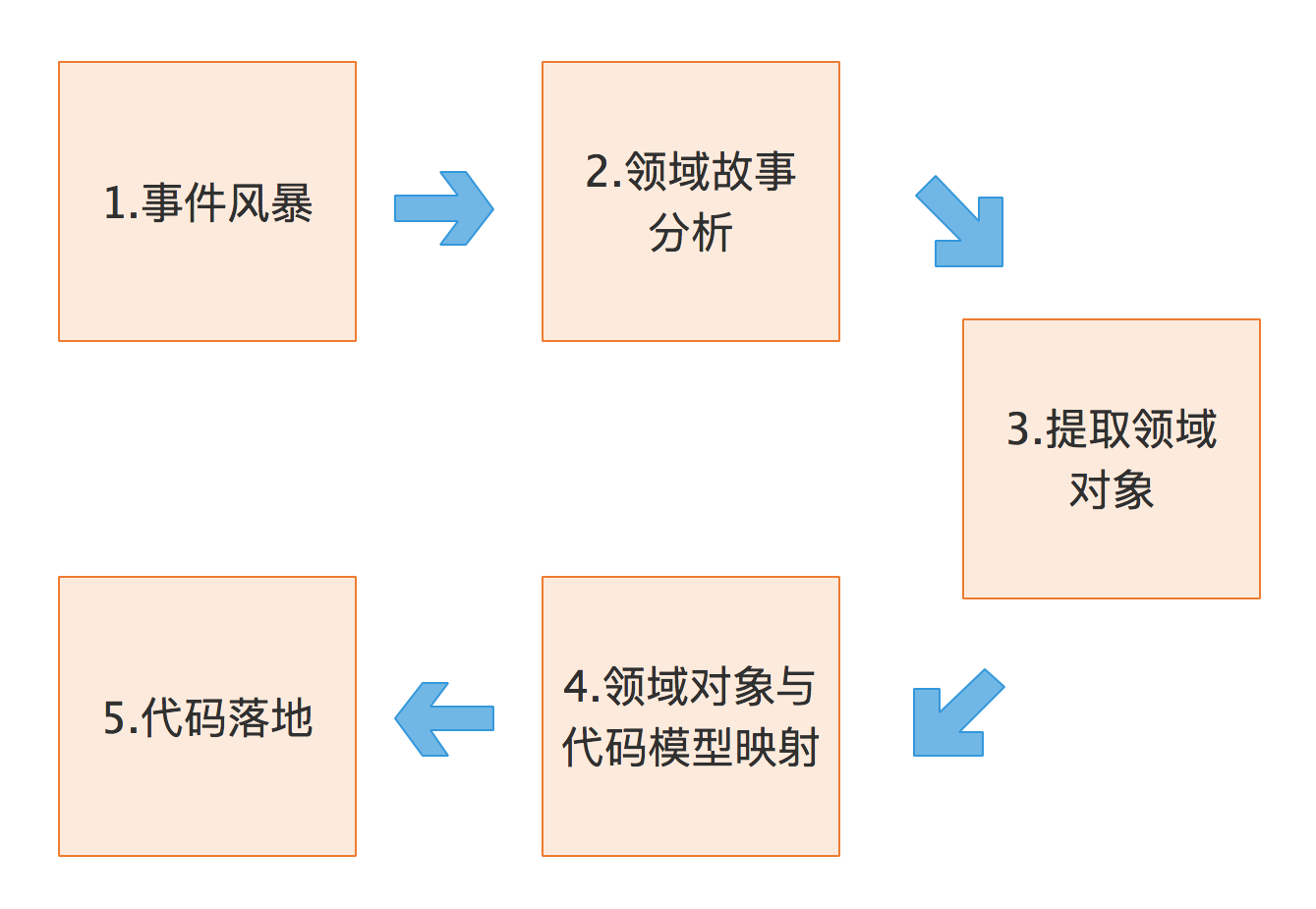
- 发散:采用用例分析、场景分析和用户旅程分析,尽可能全面不遗漏地分解,业务领域,并梳理领域对象之间的关系,事件风暴过程会产生很多的实体、命令、事件等领域对象,这是一个发散的过程。
- 收敛:我们将这些领域对象从不同的维度进行聚类,形成如聚合、限界上下文等边界,建立领域模型
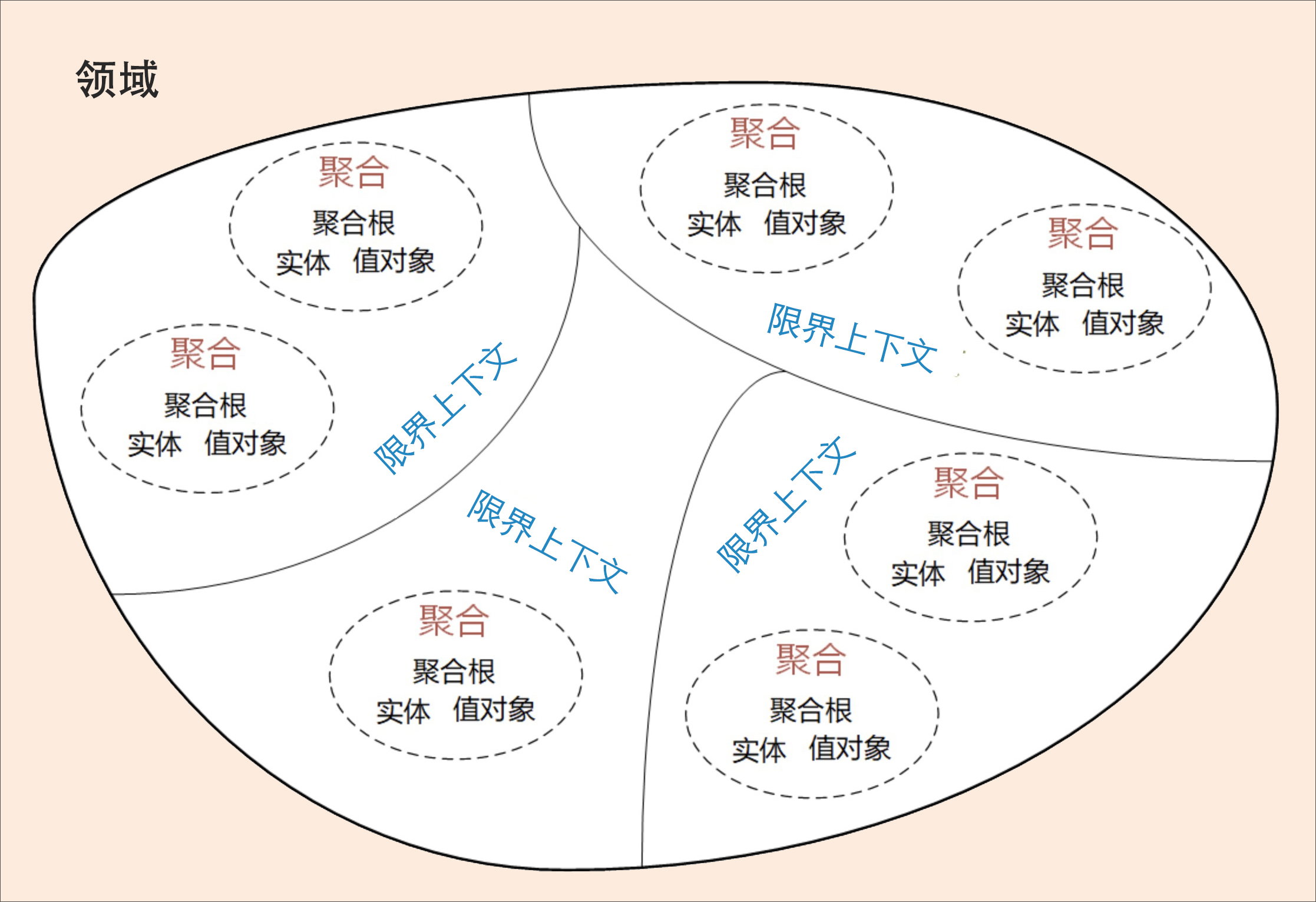
ddd与微服务的结合
- 在事件风暴中梳理业务过程中的用户操作、事件以及外部依赖关系等,根据这些要素梳理出领域实体等领域对象。
- 根据领域实体之间的业务关联性,将业务紧密相关的实体进行组合形成聚合,同时确定聚合中的聚合根、值对象和实体。在这个图里,聚合之间的边界是第一层边界,它们在同一个微服务实例中运行,这个边界是逻辑边界,所以用虚线表示。
- 根据业务及语义边界等因素,将一个或者多个聚合划定在一个限界上下文内,形成领域模型。在这个图里,限界上下文之间的边界是第二层边界,这一层边界可能就是未来微服务的边界,不同限界上下文内的领域逻辑被隔离在不同的微服务实例中运行,物理上相互隔离,所以是物理边界,边界之间用实线来表示。
DDD 主要关注:从业务领域视角划分领域边界,构建通用语言进行高效沟通,通过业务抽象,建立领域模型,维持业务和代码的逻辑一致性。PS:就像一个大牛讲ddd的文章中提到的,你在实现一个购物车业务的时候,代码看起来就要像是一个购物车。
微服务主要关注:运行时的进程间通信、容错和故障隔离,实现去中心化数据管理和去中心化服务治理,关注微服务的独立开发、测试、构建和部署。
DDD 不仅可以用于微服务设计,还可以很好地应用于企业中台的设计。PS:从《DDD实战》中嗅出来的味道是,ddd可以认为是一种从事件风暴到分类划分,进而指导组织划分(中台)、系统划分(微服务)、代码划分的思想方法。
DDD 与架构整合
架构描述了如何划分系统的各个部分以及各个部分的关系(说的直观点,就是会影响项目中package的命名)。包括分层、六边形、CQRS等架构
DDD 与分层架构
DDD 与分层架构整合有多种方式,这是比较传统的一种
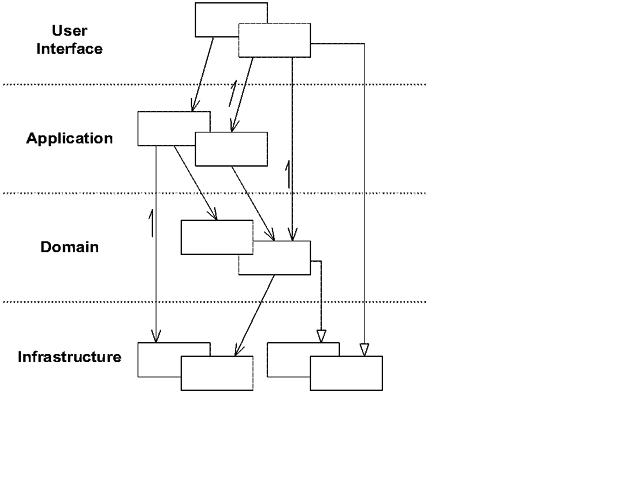
在domain层中,将各领域内的业务模型定义成entity和vo(value object),并且基于面向对象的思想,将相关的业务逻辑封装到类的成员方法中,以形成所谓的“充血模型”。对于需要访问到的业务数据存储模型,子域中会定义出仓储接口repository,并由infrastructure提供具体实现版本。在domain层,还有一个重要概念——聚合(aggregate):aggregate用于将多个具有关联性的entity和value object组织在一起,确保聚合内的对象在业务处理流程中保持数据的一致性。对于application层而言,访问domain层时使用聚合后的aggregate,也能降低因为entity数量更多而导致的业务理解成本。PS:domain层的概念与aggregate/entity/vo/充血模型的概念串在一起了。
- 领域层实现业务逻辑,领域层映射到领域模型,是问题域的领域模型在软件中的反映。包含实体、值对象和领域服务等领域对象,在实体、值对象和领域服务等领域对象的方法中封装实现业务规则和保证完整性约束。领域对象在实现业务逻辑上具备坚不可摧的完整性,意味着不管外界代码如何操作,都不可能创建不合法的领域对象(例如没有账户号码或余额为负数的借记卡对象),亦不可能打破任何业务规则(例如在多次转账之后,钱凭空丢失或凭空产生)。领域对象的功能是高度内聚的,具有单一的职责,任何不涉及业务逻辑的复杂的组合操作都不在领域层而在应用层中实现。领域层中的全部领域对象的总和在功能上是完备的,意味着系统的所有行为都可以由领域层中的领域对象组合实现。
- 领域层不依赖基础层的实现:在领域层定义好repo接口,由基础层依赖领域层实现这个接口。
- 模型与数据分离:
- 改变模型:domain.bizFunc。
- 改变数据:repo.save(domain)
- 应用层映射到系统用例模型,是系统用例模型在软件中的反映。它的职责可表示为“编排和转发”,即将它要实现的功能委托给一个或多个领域对象来实现,它本身只负责安排工作顺序和拼装操作结果。
- 基础设施层为其余各层提供技术支持。注意基础设施层不只负责数据库访问,它实现了系统的全部技术性需求,比如持久化、消息通知等
- 用户接口层为外部用户访问底层系统提供交互界面和数据表示。用户接口层有两个任务:(1)从用户处接收命令操作,改变底层系统状态;(2)从用户处接收查询操作,将底层系统状态以合适的形式呈现给用户。PS:相当于输入输出设备
领域驱动设计分层架构——六边形架构
依赖倒置原则:六边形架构进一步提升了抽象内核的地位,把领域建设作为架构的核心目标,不为任何模块影响。以领域为中心,其实是一个比较重要的转变:
- 原来以分层架构为主:讲究按层次去看,尽量将能力下沉,进行更多工具复用,积累的是通用组件。
- 现在以领域为中心:讲究按抽象层次去看,尽量将理解融入到领域核心,进行更多“理解”复用,积累的是业务知识。
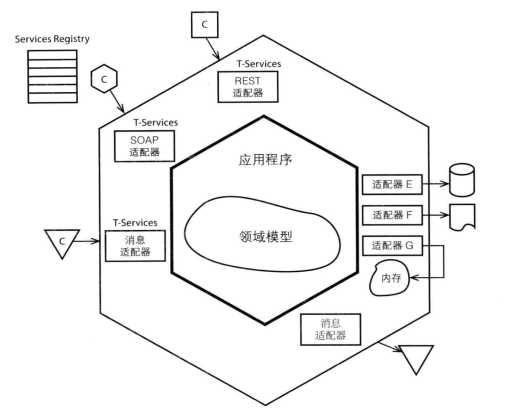
我们通常将客户与系统交互的地方称为“前端”;同样,我们将系统中获取、存储持久化数据和发送输出数据的地方称为“后端”。六边形架构提倡用一种新的视角来看待系统, 该架构中存在两个区域:外部和内部。 外部客户和内部系统的交互都会通过端口和适配器完成转换,这些外部客户之间是平等的。 web界面和持久化统称在一起,没有前端和数据库后端之分。
六边形每条不同的边代表了不同类型的端口,端口要么处理输入,要么处理输出。 以输入端口为例, 当客户请求到达时, 会有相应的适配器对输入进行转化,然后端口将调用应用程序的某个操作或者向应用程序发送一个事件,控制权由此交给内部区域。
| 端口 | 适配器 |
|---|---|
| HTTP | java的Servlet,也可以是SpringMVC的注解和Controller |
| 消息机制 | Rabbitmq消息监听器 |
| 资源库接口 | 资源库的实现便是持久化适配器 |
为了保证领域内核的抽象,需要定义好领域内核的边界,领域内核有两类接口:
- 对上游提供的能力:通过接口声明,说明能承担的职责,在领域内部进行实现支撑。
- 对下游的能力依赖:外部服务、业务扩展定制、存储服务都可以作为下游服务看待,通过接口声明服务依赖。 可以看到,领域内核与外部之间通过接口进行解耦。对于更基础的服务(比如存储服务),会被视为和业务入口一样的外部端口。
DDD 与 CQRS
- 代码层面:一个方法要么是执行某种动作的命令,要么是返回数据的查询,而不是两者皆是。
- 对象设计层面:如果一个方法修改了对象的状态,该方法便是一个命令,它不应该返回数据。在java和C#中, 这样的方法应该声明为void。如果一个方法返回了数据,该方法便是一个查询,此时它不应该通过直接的或间接的手段去修改对象的状态。
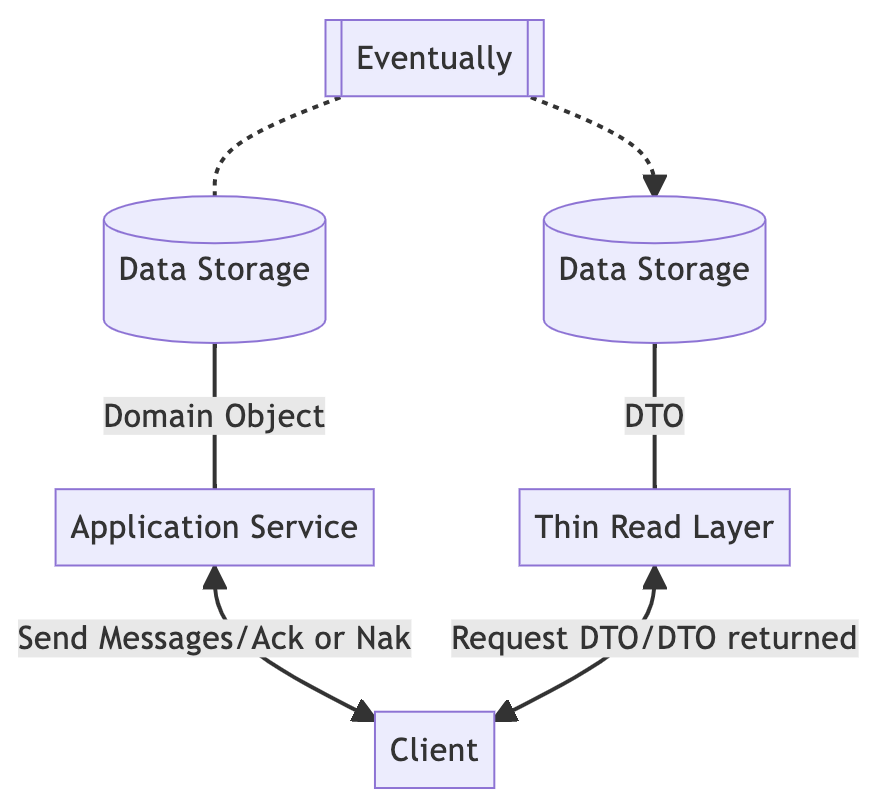
- 对于同一个(领域)模型,考虑将那些纯粹的查询功能从命令功能中分离出来。聚合将不再有查询方法,而只有命令方法。 资源库也将变成只有add或save方法(分别支持创建和更新操作),同时只有一个查询方法,比如fromId()。这个唯一的查询方法将聚合的身份标识作为参数, 然后返回该聚合实例。在将所有的查询方法移除之后,我们将此时的模型称为命令模型。但我们仍需要向用户显示数据,为此我们创建第二个模型——查询模型,专门用于优化查询。领域模型被一分为二。
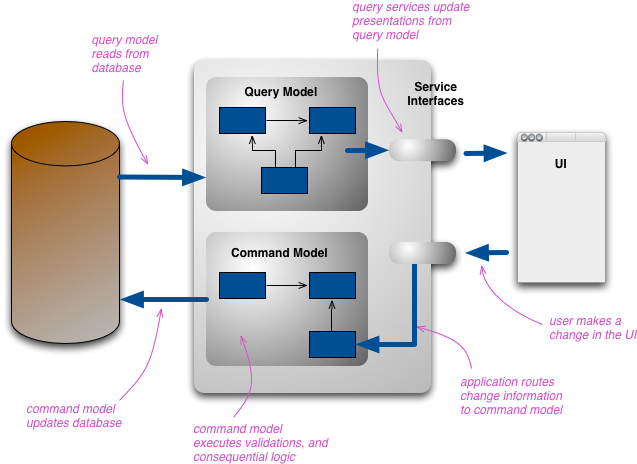
这张图读写只是逻辑分离,物理层面还是使用了一个数据库,我们可以将数据库改成读库和写库做到物理分离
- 在客户端,DTO 通常包含要在屏幕上呈现的所有数据。客户端事先与后端协商好传输格式。读和写都是通过 DTO,即数据传输对象完成的。然而,后端在处理业务逻辑时需要将 DTO 转换为具有领域知识的领域对象,并使用领域对象作为数据库的存储单元(这里没有区分PO和BO)。为什么我们要强调读 / 写分离?我们不能在读 / 写路径上使用同一个程序吗?因为我们想在将来更好地优化我们的系统。写路径有特定的优化方法,读路径也是如此。因此,读 / 写分离是必不可少的,写路径专注于数据的持久化;而读路径则专注于数据的查询。然而,这个系统设计模型有两个主要问题:贫血模型,也被称为 CRUD 模型。后端专注于数据转换而不处理业务逻辑,这将导致业务逻辑散落在各处,领域知识也会消失。例如,对于一个电子商务网站,我们会说“购买”,而不是“插入一条订单记录”。可扩展性不足。
- 为了解决上述传统单体架构中存在的问题,这里我们尝试引入域的概念,在写路径上用消息代替了 DTO。消息包含动作和数据,而不是像 DTO 那样只包含数据本身。因此,我们可以在消息中携带特定域的动作,使后端更容易识别每个动作,并有一个相应的域实现。在这个阶段,CQRS 中的 C 出现了,消息就是一种命令。但在读路径上我们仍然需要 DTO,但需要各种不同的读视图,以社交媒体为例,它有一个个人资料的展示,但可能有另一个按照时间线的展示,谁该准备那些读视图?
- 数据从客户端开始,以命令格式进入后端。根据业务逻辑,它被转换为域对象并存储在数据库中。这些域对象被转换为各种读视图,并根据要求存储在不同的专用读数据库中。最后,客户端以 DTO 的形式获取这些读视图。
DDD面向对象设计——对面向对象的进一步约束
开发者趋向于将关注点放在数据上,而不是领域上。在软件开发中,数据库依然占据着主导地位。我们应首先考虑的是数据的属性(对应数据库的列)和关联关系(外键关联),而是富有行为的领域概念。这样做的结果是将数据模型直接反映在对象模型上,导致那些表示领域模型的实体包含了大量getter和setter方法。
唯一身份标识和可变性特征将实体对象和值对象区分开来。
- 类的公有方法表示类的隐式接口,只有当我们不必使用多个setter方法来完成单个请求时, 才有道理使用setter方法。多个setter方法使意图充满了歧义, 同时也使发布领域事件变得更加复杂,因为一个领域事件应该对应于逻辑上的单个命令。
- 值对象的不变性。通常来说,值对象一般有两个构造函数
- 第一个构造函数接受用于构建对象状态的所有属性参数。只有主构造函数才能使用setter方法来设置属性值,其它属性都不能使用setter方法。由于值对象中的所有setter方法都是私有的,消费方是没有机会直接调用setter方法的,这是保持值对象不变性的两个重要因素。
- 第二个构造方法用于将一个值对象复制到另一个新的值对象。
何为高内聚低耦合?我解释不出来,我也没有找到明确的定义什么样子的代码是高内聚低耦合。但是在众多解释高内聚低耦合的一个关键词是『模块』,模块内高内聚,模块外低耦合。那问题来了,我们有什么方法能更方便的划归模块吗?一味的靠着经验积累将会大大这种效率太低了,甚至在没有正确实践的情况下,经验都没有办法积累。有没有办法比较简单的来划分所谓的模块这个概念呢?其实是有的这里可以引入ddd 的概念限界上下文。那这个限界上下文应该如何划分呢?有一些极端的观点是这样的:一个限界上下文下只有一个聚合根。所有的东西都要通过这个聚合根来完成。换到我们的组织架构下就是所有的事情都要通过leader来给我们安排任务,假设我们的一个 tl 只需要管理 3-4 人的团队,那么确实是什么事情都可以经过这个 tl。但是如果这个团队的大小已经到30-40人,那么明显什么事情都经过这一个人来分配任务就不是那么合理了。能产生依赖的才有可能是一个限界上下文中。注意这里是依赖,而非关联(PS:有关系未必要划到一起)。 结合之前说的一个聚合根的管理能力有限,我们可以得出一个比较直接的结论
- 根据天然的业务或者职能划分边界
- 一个限界上下文中的聚合根不能太多(拍个脑袋 5个以内)
- 一个聚合根依赖的实体不能太多(拍个脑袋 15个以内)
- 关联不等于依赖 如何高内聚低耦合呢?
- 同一限界上下文中,尽量使用函数依赖或者实体依赖,这样方便梳理逻辑和追踪代码,也更容易拿到聚合根这个上下文
- 不同限界上下文中,尽量只依赖数据或者消息,消灭实体依赖,防止改动的蔓延和放大
领域服务表示一个无状态的操作,它用于实现特定于某个领域的任务。当且仅当某个操作不适合放在实体和值对象上时(当然也不会在不负责业务逻辑的应用服务中),可以将其放在领域服务中。主要有以下场景
- 执行一个显著地业务操作过程
- 对领域对象进行转换
- 以多个领域对象作为输入进行计算,结果产生一个值对象。比如在订单最终的金额还要和用户的VIP身份挂钩,这时就需要调用用户聚合了,所以领域服务负责对聚合根进行调度和封装,同时可以对外提供各种形式的服务。
过度的使用领域服务将导致贫血领域模型,即所有业务逻辑都位于领域服务中,而不是实体和值对象中,陷入将领域服务作为银弹的陷阱。
在java世界中, 常见的命名实现类的方法便是给接口加上Impl后缀。此外, 实现类和接口通常被放在相同的包下。如果是这种情况,往往意味着你根本就不需要一个独立接口,因为我们知道不会再有另外的实现类。
对于系统中发生的每一件事情,我们都用事件的形式予以捕获, 然后将事件发布给订阅方处理, 这能达到简化系统的目的么?答案是肯定的。原本集中处理的过程可以分散成许多粒度较小的处理单元,业务需求也由此得到更快的满足。
将实体和值对象在一致性边界之内组成聚合(Aggregate)乍看起来是一件轻松地任务。一方面,我们可能为了对象组合上的方便而将聚合设计的很大(一个用例对应一个聚合上的命令方法)。另一方面,我们设计的聚合有可能因为过于贫瘠而丧失了保护真正不变条件的目的(某个用例需要修改多个聚合实例,这是需要保持多个聚合实例间的一致性,这时要考虑是否将聚合组合成一个新的聚合,慎重)。推荐
- 设计小聚合。聚合只包含最小数量的属性或值类型属性,且为相互之间必须保持一致的属性
- 优先考虑通过全局唯一标识来引用外部聚合,而不是直接的对象引用
留下评论