增强型LLM——Agent
简介
如果从最原始的词典里去查的话,Agent这个英文单词实际上是代理的意思。这里的代理,我个人理解的含义指的是让大模型“代理/模拟”「人」的行为,使用某些“工具/功能”来完成某些“任务”的能力。Agent比较经典的一个定义是OpenAI的研究主管Lilian Weng给出的定义是:Agent = 大模型(LLM)+ 规划(Planning)+ 记忆(Memory)+ 工具使用(Tool Use)。这个定义实际上是从技术实现的角度对Agent进行了定义。国内将Agent翻译为智能体,也是在表达,一个能规划、有记忆、能使用工具的东西,它又不是一个人,也不是一个动物,又不能直接将其描述为一个机器人(因为不一定是机器人形态,但有大脑),所以就给他起了个名字,叫“智能体”。AI Agent将使软件架构的范式从面向过程迁移到面向目标,,就像传统面向过程的工作流和K8S的声明式设计模式一样。PS:你只需要告诉我你要什么,不要告诉我怎么做(比如workflow)。
大模型技术在应用方面,主要有两大方向;
- 其一就是大模型的创作能力,简单来说就是内容生成方面,如生成图片,文字,视频等。
- 另一方向就是智能体,其目的是使大模型能够像人类一样,通过思考加使用外部工具的方式,能够自动化处理一些问题。比如说,让大模型遇到不懂的问题,可以自己上网搜索;需要使用一些第三方工具,比如说调用高德的地图接口或者调用美团的下单接口去自主规划旅行路线并订购门票,酒店等。PS:将Agent 提到llm应用方向的视角。
- 传统系统依赖刚性程序来规定每一个操作步骤,而 Agent 则利用 LLM 来驱动决策。它们可以推理、调用工具、访问记忆——且一切都能动态进行。这种灵活性使得工作流能够实时演变,让 Agent 远比基于固定逻辑的系统更加强大。
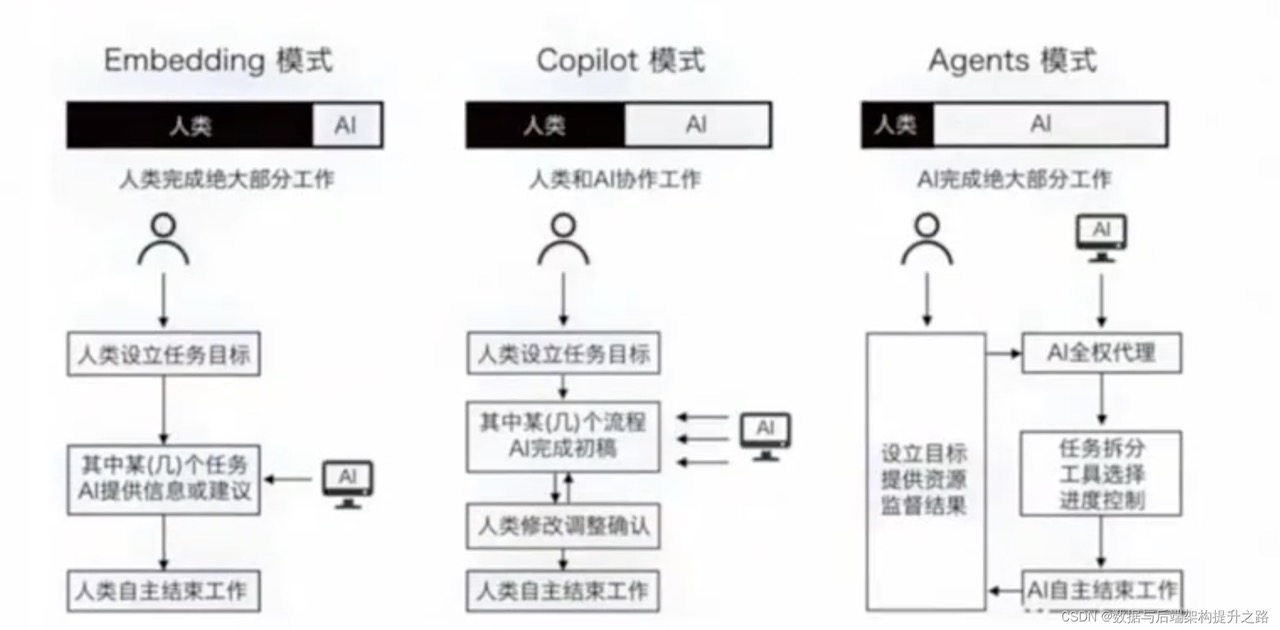
Agent 有两个关键特性
- 非确定性行为序列。利用LLM 作为推理引擎,通过LLM 来决定如何与外部世界进行交互,这意味着代理的行为不是预设的序列(硬编码是预置流程),而是根据用户输入和先前动作的结果动态决定的。这种灵活性使得代理能够应对多变的环境和复杂的任务。
- 工具的使用。人类和动物的最大区别是会制造和使用工具。Agent 不仅拥有大量工具,而且在不同环境和不同任务场景下,会自主选择和使用工具。会说话的只是ChatBot,会调工具做事的才叫Agent。Agent需要通过工具与你的业务上下文和外部世界交互。所有与外部世界的交互都会回到context window中。 PS:Agent就是在循环中(While Loop)运行工具来实现目标的系统。所以有一句:Agent 始于 tools。ce包含相对静态的部分(System Prompt、工具定义、领域知识)和动态增长的部分(对话历史、工具调用记录、检索到的知识)。静态部分的坑就是tool定义长,动态部分的坑就是tool observasion多。
Agent 核心要素
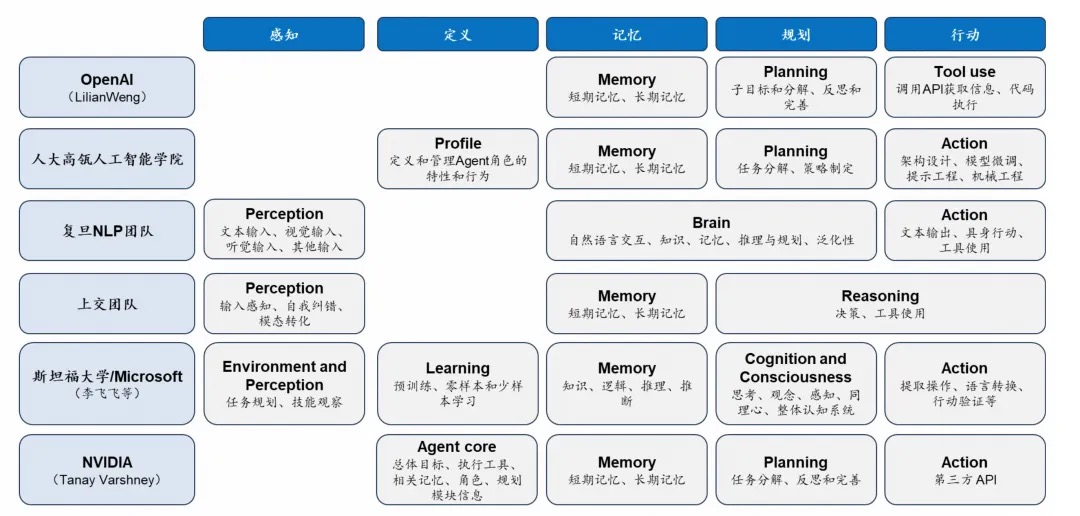
An LLM agent runs tools in a loop to achieve a goal. 1.0 时代是 Chatbot,每次与 AI 的对话都是一次 LLM 推理,2.0 时代是 Agent,是 Tool call,一次对话,通常要经过几轮到几十上百轮 LLM 的推理。
设计思想
Lilian Weng博文里Planning包含四个子模块,Reflection(反思)、Self-critics(自我批评)、Chain of thoughts(思维链)、Subgoal decomposition(子目标分解), Planning将任务分解为可执行的步骤,并根据反馈不断优化计划。PS: 也就是认为反思是规划的一部分。
行为范式:从COT到ReAct
“大模型视角”下的文本与我们“人类视角”并不一样。以Strawberry为例,其被拆分为【“str”, “aw”, “berry”】,自然也就不难理解为什么llm对于这个问题的回答是“两个r”了,毕竟对于它来说,这三者均是作为一个整体存在的,而不是从字母维度切分的。通过CoT方法编写Prompt后,可以引导大模型输出正确结果。
Strawberry里有几个r?请你先将单词拆分成一个个字母,再用0和1分别标记字母列表中非r和r的位置,数一下一共有几个r
为什么这么做可以提升大模型的表现呢?,大模型每一次生成是在“根据上文预测下一个Token”的话,那么CoT的作用便在于,它可以引导大模型先行生成有力的推理过程,比如引导其生成Strawberry拆解后的字母列表,或者数字的逐位比较,这样模型在生成最终结论的时候,会受到上文推理过程的影响,将下一个Token的概率分布限定在某个范围内,从而大大增加输出正确答案的概率。而若是不用CoT加以限制的的情况下,大模型倾向于先给出一个答案,再给出理由,那么很自然地变成了,先根据“问题”预测一个最有可能的“答案”,再为这个“答案”编造相应的“理由”,毕竟大模型的生成过程是逐步进行的,而不是全局性的,它在答案之后输出的理由永远只可能是为了圆“答案”这个谎而存在的。我们人类在思考的时候,通常也是会先有推理过程,再有结论,只不过在诉诸于语言时,可能会选择 先抛出结论表明立场,再给出解释 的表达方式,而思考过程对外界是不可见的,但是对于大模型而言,它的语言本身即是思考,并不存在诉诸于语言之前的思考过程,所以我们也需要引导它像人类一样先思考再判断,将思考过程以语言的方式表达出来。换句话说,“理由先行”的输出风格或许有助于大模型给出更加可靠的答案。
- 什么是“语言智能”?语言智能可以被理解为“使用基于自然语言的概念对经验事物进行‘理解’以及在概念之间进行‘推理’的能力”,随着参数量的飞升,以 Transformer 为基础架构的大规模语言模型以 “Chat” 的方式逐渐向人们展现出了它的概念理解与概念推理的能力。直观上,作为“语言模型”的大模型具备概念理解能力并不难理解,但是仅仅像 Word2vec 一样只能得到“国王”与“男人”的“距离”更近的结论对于语言智能而言必然远远不够。真正引发人们对大模型逼近“语言智能”无限遐想的,在于大模型展现出的概念推理能力。推理,一般指根据几个已知的前提推导得出新的结论的过程,区别于理解,推理一般是一个“多步骤”的过程,推理的过程可以形成非常必要的“中间概念”,这些中间概念将辅助复杂问题的求解。
- 2022 年,在 Google 发布的论文《Chain-of-Thought Prompting Elicits Reasoning in Large Language Models》中首次提出,通过让大模型逐步参与将一个复杂问题分解为一步一步的子问题并依次进行求解的过程可以显著提升大模型的性能。而这一系列推理的中间步骤就被称为思维链(Chain of Thought)。区别于传统的 Prompt 从输入直接到输出的映射
<input——>output>的方式,CoT 完成了从输入到思维链再到输出的映射,即<input——>reasoning chain——>output>。如果将使用 CoT 的 Prompt 进行分解,可以更加详细的观察到 CoT 的工作流程。- 虽然与传统的直进直出的Prompt相比,COT能让模型带来更多的思考(其实只是更多tokens自回归带来的准确性提升)。但是它无法与外部世界互动,很多时候的结果产出与我们人类的预期还是会有偏差,抽奖不可避免。
- 在许多 Agent 需要处理的任务中,Agent 的“先天知识”并不包含解决任务的直接答案,因此 Agent 需要在一系列与外部环境的交互循环中,制定计划,做出决策,执行行动,收到反馈……在一整个计划、决策与控制的循环中,大模型需要具备“感知”,“记忆”与“推理”的能力。无论是环境的反馈,还是人类的指令,Agent 都需要完成一个对接收到的信息进行“理解”,并依据得到的理解进行意图识别,转化为下一步任务的过程。而使用 CoT 可以大大帮助模型对现有输入进行“感知”,譬如,通过使用“Answer: Let’s think step by step. I see $$, I need to …”的 Prompt,可以让模型逐步关注接收到的信息,对信息进行更好的理解。
从ReAct出发
ReAct模式(Thought -> Action -> Observation 的循环)最早出现的Agent设计模式,目前也是应用最广泛的。从ReAct出发,有两条发展路线:
- 一条更偏重Agent的规划能力,包括REWOO(Planner + Worker + Solver)、Plan & Execute、LLM Compiler。在重规划的模式下,ReAct模式加上规划器就成为REWOO,再加上重规划器就成为Plan & Execute,再叠加计划并行执行能力就成为LLM Compiler。
- 一条更偏重反思能力,包括Basic Reflection、Reflexion、Self Discover、LATS。在重反思模式下,ReAct模式加上左右互搏框架就成为Basic Reflecion,边推理边执行则演变为Self-Discover,加入强化学习则演变为Reflexion,最后的LATS是推理和规划的集大成者,LATS = Tree search + ReAct + Plan&Execute + Reflexion。
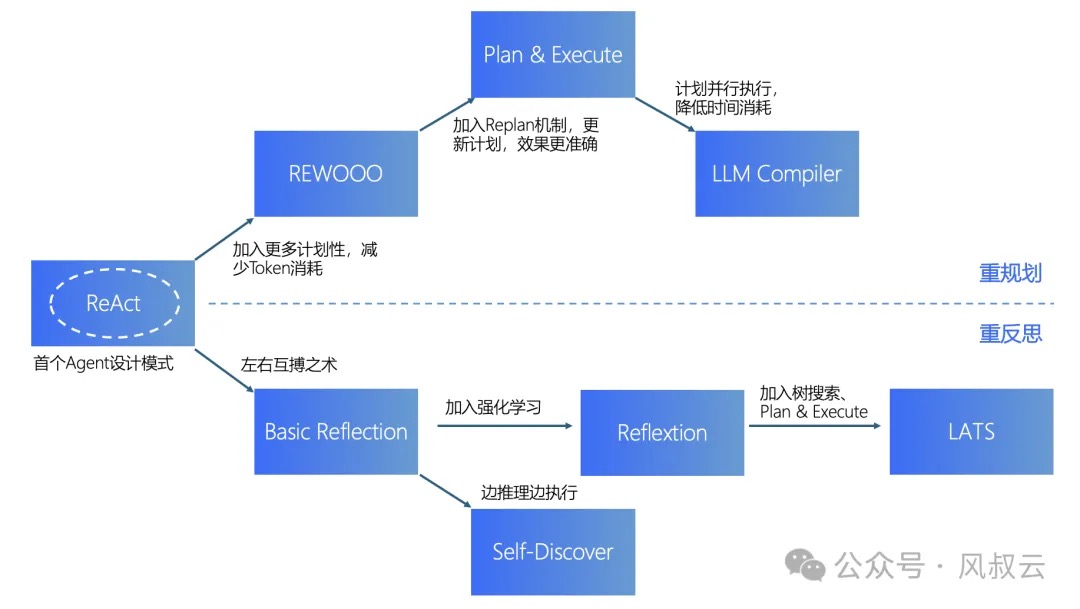
从最初的ReAct模式出发,加入规划能力即演变成REWOO;再加上Replan能力即演变成Plan-and-Execute;最后再加上DAG和并行处理能力,即演变成LLM Compiler。
- ReAct模式是最早出现、也是目前使用最广泛的模式。核心思想就是模拟人思考和行动的过程,通过Thought、Action、Observation的循环,一步步解决目标问题。ReAct模式也存在很多的不足:对于一个步骤清晰、逻辑严密的工程任务,当前 LLM 的自主规划和纠错能力还不够成熟。
- 首先是LLM大模型的通病,即产出内容不稳定,不仅仅是输出内容存在波动,也体现在对复杂问题的分析,解决上存在一定的波动
- 然后是成本,在任务提交给LLM后,LLM对任务的拆解、循环次数是不可控的。因此存在一种可能性,过于复杂的任务导致Token过量消耗。
- 最后是响应时间,LLM响应时间是秒级以上。因为无法确定需要拆分多少步骤,需要访问多少次LLM模型。
- REWOO的全称是Reason without Observation,是相对ReAct中的Observation 来说的。通过生成一次性使用的完整工具链来减少token消耗和执行时间。简化微调过程。由于规划数据不依赖于工具的输出(没有重新规划步骤,蓝图固定),因此可以在不实际调用工具的情况下对模型进行微调。包括三个部分:Planner;Worker;Solver。缺陷在于,非常依赖于Planner的规划能力,如果规划有误,则后续所有的执行都会出现错误。尤其是对于复杂任务,很难在初始阶段就制定合理且完备的计划清单。AI大模型实战篇:AI Agent设计模式 - REWOO,此外不限制工具使用并行化。
- Plan-and-Execute。先计划再执行,即先把用户的问题分解成一个个的子任务,然后再执行各个子任务,并根据执行情况调整计划。相比ReWOO,最大的不同就是加入了Replan机制,其架构上包含规划器、执行器和重规划器。Plan-and-Execute和ReAct也有一定的相似度,但是Plan-and-Execute的优点是具备明确的长期规划。局限性在于,每个任务是按顺序执行的,下一个任务都必须等上一个任务完成之后才能执行,这可能会导致总执行时间的增加。AI大模型实战篇:AI Agent设计模式 - Plan & Execute
- LLM Compiler,训练大语言模型生成一个有向无环图,DAG可以明确各步骤任务之间的依赖关系,从而并行执行任务,实现类似处理器“乱序执行”的效果,可以大幅加速AI Agent完成任务的速度。主要有以下组件:Planner(输出流式传输任务的DAG)Task Fetching Unit(调度并执行任务)Joiner(由LLM根据整个历史记录(包括任务执行结果),决定是否响应最终答案或是否将进度重新传递回Planner) AI大模型实战篇:AI Agent设计模式 - LLM Compiler,Agent的并行处理器
ReAct + 规划
ReACT框架的一个关键特点是其任务拆解模块,能够将复杂的任务拆解成一系列更小、更明确的子任务,这些子任务更容易被模型理解和执行,让模型不再“消化不良”。一篇大模型Agent工具使用全面研究综述任务规划的方法:
- 无需调整的方法(Tuning-free Methods):利用LLMs的内在能力,通过少量示例或零示例提示来实现任务规划。例如,使用CoT(Chain of Thought)或ReACT等框架来引导LLMs逐步思考和规划。
- 基于调整的方法(Tuning-based Methods):通过在特定任务上微调LLMs来提高任务规划能力。例如,Toolformer等方法通过微调来增强LLMs对工具使用的意识和能力。
工具选择的分类:
- 基于检索器的工具选择(Retriever-based Tool Selection):当工具库庞大时,使用检索器(如TF-IDF、BM25等)来从大量工具中检索出与子问题最相关的前K个工具。这种方法侧重于通过关键词匹配和语义相似性来快速缩小工具选择范围。
- 基于LLM的工具选择(LLM-based Tool Selection):当工具数量有限或者在检索阶段已经缩小了工具范围时,可以直接将工具描述和参数列表与用户查询一起提供给LLM。
工具学习范式:
- 没有反馈的计划制定。一步任务解决,这种范式涉及到在收到用户问题后,LLMs立即分析用户请求,理解用户意图,并规划出所有需要的子任务来解决问题。在这个过程中,LLMs会直接生成一个基于选定工具返回结果的响应,而不会考虑过程中可能出现的错误或根据工具的反馈调整计划。
- 单路推理,仅一次大语言模型调用就输出完整的推理步骤;
- 多路推理,借鉴众包思想,让大语言模型生成多个推理路径,进而确定最佳路径;
- 借用外部的规划器。Agent Planning大揭秘:外部规划器怎么玩?
- 有反馈的计划制定。这种范式允许LLMs与工具进行迭代交互,不预先承诺一个完整的任务计划。相反,它允许基于工具的反馈逐步调整子任务,使LLMs能够一步步地解决问题,并根据工具返回的结果不断完善计划。这种方法增强了LLMs的问题解决能力,因为它允许模型在响应工具反馈时进行适应和学习。反馈的提供者来自三个方面:环境反馈、人类反馈和模型反馈。
ReAct + 反思
- Basic Reflection,类比于左右互博。左手是Generator,负责根据用户指令生成结果;右手是Reflector,来审查Generator的生成结果并给出建议。在左右互搏的情况下,Generator生成的结果越来越好,Reflector的检查越来越严格,输出的结果也越来越有效。非常适合于进行相对比较发散的内容生成类工作,比如文章写作、图片生成、代码生成等等。也面临着一些缺陷:对于一些比较复杂的问题,显然需要Generator具备更强大的推理能力;Generator生成的结果可能会过于发散,和我们要求的结果相去甚远;在一些复杂场景下,Generator和Reflector之间的循环次数不太好定义,如果次数太少,生成效果不够理想;如果次数太多,对token的消耗会很大。AI大模型实战篇:Basic Reflection,AI Agent的左右互搏之术
- Self-Discover框架包含两个主要阶段,自发现特定任务的推理结构、应用推理结构解决问题。AI大模型实战篇:Self Discover框架,万万想不到Agent还能这样推理
- 阶段一:自发现特定任务的推理结构,主要包含三个主要动作:选择(SELECT)、适应(ADAPT)和实施(IMPLEMENT)。在这个阶段,模型从一组原子推理模块(例如“批判性思维”和“逐步思考”)中选择对于解决特定任务有用的模块。模型通过一个元提示来引导选择过程,这个元提示结合了任务示例和原子模块描述。选择过程的目标是确定哪些推理模块对于解决任务是有助的。一旦选定了相关的推理模块,下一步是调整这些模块的描述使其更适合当前任务。这个过程将一般性的推理模块描述,转化为更具体的任务相关描述。例如对于算术问题,“分解问题”的模块可能被调整为“按顺序计算每个算术操作”。同样,这个过程使用元提示和模型来生成适应任务的推理模块描述。在适应了推理模块之后,Self-Discover框架将这些适应后的推理模块描述转化为一个结构化的可执行计划。这个计划以键值对的形式呈现,类似于JSON,以便于模型理解和执行。这个过程不仅包括元提示,还包括一个人类编写的推理结构示例,帮助模型更好地将自然语言转化为结构化的推理计划。
- 阶段二:应用推理结构,完成阶段一之后,模型将拥有一个专门为当前任务定制的推理结构。在解决问题的实例时,模型只需遵循这个结构,逐步填充JSON中的值,直到得出最终答案。
- Reflexion本质上是强化学习,可以理解为是Basic reflection 的升级版。Reflexion的三大组件:参与者(Actor):基于ReAct或CoT生成行动轨迹。评估者(Evaluator):对轨迹打分,判断成功或失败。自我反思(Self-Reflection):核心组件,生成语言反馈并存入长期记忆,指导下次行动。AI大模型实战篇:Reflexion,通过强化学习提升模型推理能力 PS:用时间换质量
- LATS,全称是Language Agent Tree Search,LATS = Tree search + ReAct + Plan&Execute + Reflexion。融合了Tree Search、ReAct、Plan & Execute、Reflexion的能力于一身之后,LATS成为AI Agent设计模式中,集反思模式和规划模式的大成者。
工具调用的步骤:
- 参数提取:LLMs必须能够从用户查询中提取出符合工具描述中指定格式的参数。
- 调用工具:使用提取的参数向工具服务器发送请求,并接收响应。
现有方案如CoT和基于分解的提示,都有擅长的任务类型,适合作为独立的原子模块,不具有普适性;大模型自动推理?谷歌等发布SELF-DISCOVER!
Ralph Loop
从 ReAct 到 Ralph Loop:AI Agent 的持续迭代范式 未细读
猴版实现
while not done:
response = model.invoke(messages, tools)
handle_response(response)
再复杂一点
# Claude Code 的核心逻辑(简化版)
system_prompt = """你是一个软件工程助手...
[长达 5000+ 字的详细操作手册]
"""
while not task_completed:
response = claude_3_7.invoke(
system=system_prompt,
messages=conversation_history,
tools=available_tools
)
if response.tool_calls:
results = execute_tools(response.tool_calls)
conversation_history.append(results)
if response.says_completed:
task_completed = True
ReAct/交互循环
class LLMSingleActionAgent {
llm: AzureLLM
tools: StructuredTool[]
stop: string[]
private _prompt: string = '{input}'
constructor({ llm, tools = [], stop = [] }: LLMSingleActionAgentParams) {
this.llm = llm
this.tools = tools
if (stop.length > 4)
throw new Error('up to 4 stop sequences')
this.stop = stop
}
}
class AgentExecutor {
agent: LLMSingleActionAgent
tools: StructuredTool[] = []
maxIterations: number = 15
constructor(agent: LLMSingleActionAgent) {
this.agent = agent
}
addTool(tools: StructuredTool | StructuredTool[]) {
const _tools = Array.isArray(tools) ? tools : [tools]
this.tools.push(..._tools)
}
async call(input: promptInputs): Promise<AgentFinish> {
...
}
}
无反馈的planner和solver
planner的prompt模版
You are an AI agent who makes step-by-step plans to solve a problem under the help of external tools.
For each step, make one plan followed by one tool-call, which will be executed later to retrieve evidence for that step.
You should store each evidence into a distinct variable #E1, #E2, #E3 ... that can be referred to in later tool-call inputs.
##Available Tools##
{tool_description}
##Output Format (Replace '<...>')##
#Plan1: <describe your plan here>
#E1: <toolname>[<input here>] (eg. Search[What is Python])
#Plan2: <describe next plan>
#E2: <toolname>[<input here, you can use #E1 to represent its expected output>]
And so on...
##Your Task##
{task}
##Now Begin##
"""
solver的prompt模版
You are an AI agent who solves a problem with my assistance. I will provide step-by-step plans(#Plan) and evidences(#E) that could be helpful.
Your task is to briefly summarize each step, then make a short final conclusion for your task. Give answer in {lang}.
##My Plans and Evidences##
{plan_evidence}
##Example Output##
First, I <did something> , and I think <...>; Second, I <...>, and I think <...>; ....
So, <your conclusion>.
##Your Task##
{task}
##Now Begin##
Basic Reflection
构建Generator
from langchain_core.messages import AIMessage, BaseMessage, HumanMessage
from langchain_core.prompts import ChatPromptTemplate, MessagesPlaceholder
from langchain_fireworks import ChatFireworks
prompt = ChatPromptTemplate.from_messages(
[
(
"system",
"You are an essay assistant tasked with writing excellent 5-paragraph essays."
" Generate the best essay possible for the user's request."
" If the user provides critique, respond with a revised version of your previous attempts.",
),
MessagesPlaceholder(variable_name="messages"),
]
)
llm = xx
generate = prompt | llm
essay = ""
request = HumanMessage(
content="Write an essay on why the little prince is relevant in modern childhood"
)
构建Reflector
reflection_prompt = ChatPromptTemplate.from_messages(
[
(
"system",
"You are a teacher grading an essay submission. Generate critique and recommendations for the user's submission."
" Provide detailed recommendations, including requests for length, depth, style, etc.",
),
MessagesPlaceholder(variable_name="messages"),
]
)
reflect = reflection_prompt | llm
第三步 循环执行
for chunk in generate.stream(
{"messages": [request, AIMessage(content=essay), HumanMessage(content=reflection)]}
):
print(chunk.content, end="")
第四步 构建流程图(用langgraph)
应用
大佬:这一波Agent热潮爆发,其实是LLM热情的余波,大家太希望挖掘LLM潜力,为此希望LLM担任各方面的判断。但实际上有一些简单模块是不需要LLM的,不经济也不高效。例如我们要抽取每轮对话的情绪,可以用LLM,其实也可以用情绪识别模型。例如我们希望将长对话压缩后作为事件记忆存储,可以用LLM,也可以用传统摘要模型,一切只看是否取得ROI的最佳平衡,而不全然指望LLM。
- 创作与生成类助手,简单的借助Prompt工程即可实现
- 企业知识助手,本质上也是一种提示工程:借助于在大模型输入时携带相关的私有知识上下文,让大模型理解、总结、整理并回答用户问题。只是这里的私有知识上下文需要借助嵌入模型(Embedding Model)、向量数据库(Vector Store)、文档加载分割(Document Loader&Splitter)等相关技术来获得。
- 数据分析助手,基本以三种方式为主:自然语言转API、转SQL、以及代码解释器(转代码)。DB-GPT、OpenAgents、OpenInterpreter
- 应用/工具助手,能够把自然语言转换成对企业应用或者互联网开放API调用的一种基础Agent形式。比如:如果你需要AI帮你在协同办公系统中提交一个付款申请,那么你需要调用办公系统的接口;当然,在复杂任务场景下的这种调用往往不是单一的,复杂性主要体现在大模型对自然语言转API的能力:能否根据上下文理解,精确匹配到需要使用的API(一个或者多个);能否准确地提取或生成每个API的调用参数。LangChain、Assistants API、OpenAgents。
- Web操作助手,主要能力是自动化Web网络浏览、操作与探索的动作与过程,以简化web浏览访问与操作。对于个人来说,可以作为个人数字助理,简单对话即可让AI帮你完成Web浏览与操作,比如在线订票。而对于企业来说,则可以作为企业的数字员工,来简化企业日常工作中重复性较高、流程与规则固定、大批量的前端操作性事务。比如批量订单处理、批量客户联络、批量网站抓取等,提高效率,降低错误率。传统的RPA机器人也是用来完成此类工作的AI形式,由于这种AI机器人工作在软件的最上层即操作层面,好处是流程直观、简单、也可以配置化,且对应用无侵入性;但其缺点是与前端应用耦合性大,每个任务需要根据前端应用界面做精心配置与调试,自适应能力较差。在大模型出现以后,给这一类RPA智能也带来了新的优化空间。
- 自定义流程助手,严格来说是上面的几种基础Agent能力的组合,理想中的AI Agent是在丢给他一个工具包与一些知识以后,借助于大模型的理解、推理能力,完全自主的规划与分解任务,设计任务步骤,并智能的使用各种工具,检索知识,输出内容,完成任务。但是在企业应用中,由于企业知识、应用、业务需求的千差万别,以及大模型自身的不确定性,如果这么做,那么结果很可能是“开盲盒”一样的不可控。所以这也是越来越多的Agents项目要强调可控性的原因,即能够对AI智能体的执行过程与细节进行更多的控制,来让AI按照人类确认过的工作流程来完成任务。 PS: 人规定流程 + 单个步骤代码化(有些场景代码无法实现 或 个性化成本太高) ==> 人规定流程 + 单个步骤智能化 ==> 自动分析流程 + 单个步骤智能化
从需求满足的角度来聊一聊:我们首先以“用户去某地旅游”为需求来解释LLM、RAG、Agent三者的能力边界以及需求满足度。
- LLM:能够生成“无法考证可能正确”以及“不一定及时”的相关行程攻略,景点等信息。
- RAG:能够检索一些时效性高、内容可靠的信息源的内容,并生成相关的行程信息。PS:看能召回什么内容了
- Agent:能够基于用户的需求目标完成,通过使用各种工具和系统交互完成攻略制定,订票,制定行程日历等过程任务。PS:先去搜一些攻略,再去订酒店 ==> 从景色、经济、时间等各个角度做一些对比。
阿里云服务领域Agent智能体:从概念到落地的思考、设计与实践
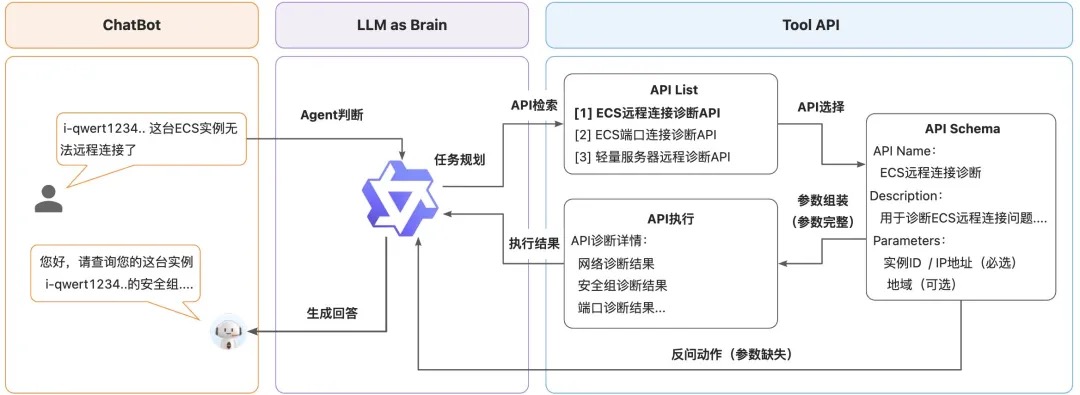
- 工具API尽可能的将场景端到端的进行了封装,做到每个场景的API都能“开箱即用”,比如“退款”的API可以支持实例ID、订单号等多种入参,“ECS无法连接”的API也支持实例ID、IP地址等多种入参,尽量避免出现客户提供一种入参的情况下还需调用另一种API去转换的情况,这样算法侧就可以减少多步调用的场景,从而优化耗时。
- 根据用户Query的分布特点,在阿里云客服场景下,大部分客户的问题中缺失具体信息的较多,很多问题都是“ECS连不上”、“备案进度查询”这类简明的意图名称,因此很难一次性直接提取出必填的参数信息,所以绝大多数的场景都需要参数“反问”的能力,那么涉及到反问澄清,就需要具备多轮的Agent对话能力,也就在客户提供了相应信息的情况下,Agent还能够接得上之前的意图,并且继续完成调用的链路,除此之外,还需要增加不需要调用API的情况,以及无参数提取等情况,让大模型能够知道在什么场景下要调用什么API、调用的动作、参数的提取、API的执行情况等等。
- 在训练完成后,我们也构建了一个服务领域的Agent benchmark评测集,用于对比不同模型的Agent能力情况,这个benchmark中有多个维度的评估,包括API选择准确率、动作执行(反问、直接调用、拒识等)准确率、入参抽取准确率、端到端成功率、生成文案的BLEU和Rouge-L等指标,最终需要经过各维度的权衡决策哪版本模型作为线上模型。
框架
agent 翻来覆去就是llm/tool/memory 那几个概念,langchain/llamaindex 都会提供对应抽象,自己手撸的话,每个工具业界也有对应的抽象。
||langchain/llamaindex|自建|
|—|—|—|
|model|BaseModel|litellm
Trustcall|
|memory|momory|LangMem/Mem0|
|tool|BaseTool|mcp|
|Agent|xxAgent|一般手撸|
Agently
Agently AI应用开发框架由浅入深的应用开发指导 - 应用开发者入门篇 在Agently框架的演进过程中,Agent实例是模型能力的放大器这个关键认知深切地影响了框架的设计思想。应该如何理解这个认知?回想一下,当你最初开始使用ChatGPT或者与其类似的聊天机器人(Chat Bot)产品的时候,你对于在聊天框中输入信息并获得返回结果的期待是什么?是不是除了获得对当前一次输入问题的直接回答之外,还期望这次返回结果能够结合之前的几句对话记录,甚至是更远的几天、几周前的对话记录进行回答?是不是还期望聊天机器人能够具备更加生动的形象,并且更了解你的喜好和个人情况,给出更具有针对性的回复?是不是还期望它的回复内容中,除了从模型自身的预训练知识储备中抽取和组织信息,也希望它能够更多地结合外界的信息进行回答?是不是甚至期待它除了给出一条回复之外,还能够真切地帮你写下一段笔记、记录一个提醒、定上一个闹钟?当然了,如果你已经看到了这个章节,你也一定明白,这些期待并不能够通过直接对模型发起一次请求而得到实现,在模型之上,似乎需要有一个结构体,通过一定的结构设计和运行逻辑,来完成这些期待,对于使用者而言,他们仍然可以将这个结构体视作一个加强版的模型,通过简单的输入交互向它发起请求(例如我们在第二部分提供的方法)。在Agently框架中,这样的结构体就是Agent实例。PS: 非常深刻的一个认知
在理解了Agently框架对Agent实例这个结构体的基础设计思想之后,接下来我们来进一步说明在代码编写和运行过程中,Agent实例到底进行了哪些工作?
demo_agent = agent_factory.create_agent()
result = (
demo_agent
# Agent Component 能力插件提供的交互指令
.set_role("角色", "你是一个幼儿教师")
.set_role(
"回复规则",
"你需要将晦涩难懂的专业知识理解之后转化成小孩子能听懂的故事讲给用户听," +
"注意,虽然是讲故事,但是要保证专业知识的准确真实"
)
.on_delta(lambda data: print(data, end=""))
# 基础请求指令
.instruct("如果搜索结果中包含较多内容,请尽可能将这些内容有条理系统地转化成多段故事")
.input("天空为什么是蓝色的")
# 请求启动指令
.start()
)
print("\n[最终回复]: ", result)
smolagents
HuggingFace smolagents:仅1000行代码的轻量级Agent框架 未细读。
其它
别指望 AI 一次生成,其实不论是文本生成,还是代码生成,都涉及到生成式 AI 的能力问题:
- 用户无法提供所有上下文给模型。既然能提供,提供的成本往往过高(大于 AI 生成的时间)
- 模型无法理解你提供的所有上下文。
留下评论