Go常用的一些库
一 前言
本文主要阐述一下golang中常用的库。
Go 大杀器之性能剖析 PProf 未读 Go 大杀器之跟踪剖析 trace 未读 用 GODEBUG 看调度跟踪 未读 用 GODEBUG 看GC 未读
golang 日志
日志接口
logr logr offers an(other) opinion on how Go programs and libraries can do logging without becoming coupled to a particular logging implementation. This is not an implementation of logging - it is an API.
- The Logger type is intended for application and library authors. It provides a relatively small API which can be used everywhere you want to emit logs. It defers the actual act of writing logs (to files, to stdout, or whatever) to the LogSink interface.
type appObject struct { // 使用时 直接使用 logr.Logger logger logr.Logger // ... other fields ... } func (app *appObject) Run() { app.logger.Info("starting up", "timestamp", time.Now()) ... } - The LogSink interface is intended for logging library implementers. It is a pure interface which can be implemented by logging frameworks to provide the actual logging functionality.
This decoupling allows application and library developers to write code in terms of logr.Logger (which has very low dependency fan-out) while the implementation of logging is managed “up stack” (e.g. in or near main().) Application developers can then switch out implementations as necessary.
// 启动时初始化一个 logr.Logger 实现(比如klog)赋给 全局logger 变量,然后就可以在项目中到处传递使用了。
func main() {
// ... other setup code ...
// Create the "root" logger. We have chosen the "logimpl" implementation, which takes some initial parameters and returns a logr.Logger.
logger := logimpl.New(param1, param2)
// ... other setup code ...
app := createTheAppObject(logger)
app.Run()
}
日志实现——以klog为例
klog是著名google开源C++日志库glog的golang版本
- 支持四种日志等级INFO < WARING < ERROR < FATAL,不支持DEBUG等级。
- 每个日志等级对应一个日志文件,低等级的日志文件中除了包含该等级的日志,还会包含高等级的日志。
- 日志文件可以根据大小切割,但是不能根据日期切割。
- 程序开始时必须调用
flag.Parse()解析命令行参数,退出时必须调用glog.Flush()确保将缓存区日志输出。 Info()与Infoln()没有区别,因为glog为了保证每行只有一条log记录,会主动check末尾是否有换行符,如果没有的话,会自动加上。
func main() {
klog.InitFlags(nil)
//Init the command-line flags.
flag.Parse()
...
// Flushes all pending log I/O.
defer klog.Flush()
}
通常而言,日志打印会按错误级别进行打印,如:【Fatal,Error,Warning,Info】等级别。但在实际项目开发过程中,还会涉及到一些内部状态切换、基础库以及框架的使用。这些信息显然不能按照错误级别进行打印。所以对 Info 级别日志进行二次分级是必要的。info 又可细化为多个级别:0~10,信息的重要性依次降低。
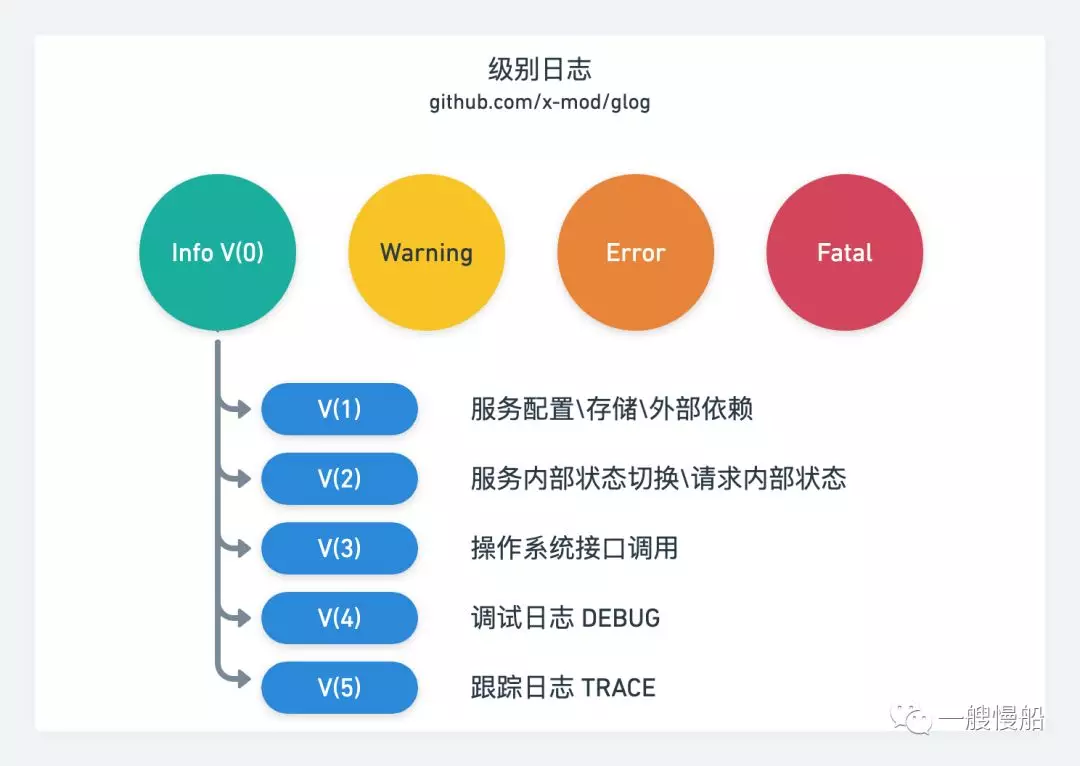
if glog.V(2) {
glog.Info("log this")
}
// Equals
glog.V(2).Info("log this")
如何在 Go 函数中获取调用者的函数名、文件名、行号…跟踪调用链的神器。
pc, file, lineNo, ok := runtime.Caller(1)
fmt.Println(pc)
fmt.Println(file)
fmt.Println(lineNo)
fmt.Println(ok)
unsafe
深度解密Go语言之unsafe相比于 C 语言中指针的灵活,Go 的指针多了一些限制。
- Go的指针不能进行数学运算。
- 不同类型的指针不能相互转换。
- 不同类型的指针不能使用==或!=比较。
- 不同类型的指针变量不能相互赋值。
为什么有 unsafe?Go 语言类型系统是为了安全和效率设计的,有时,安全会导致效率低下。有了 unsafe 包,高阶的程序员就可以利用它绕过类型系统的低效。Package unsafe contains operations that step around the type safety of Go programs.
$GOROOT/src/unsafe/unsafe.go 里只有一个文件,内容只有几行
package unsafe
type ArbitraryType int
type Pointer *ArbitraryType
func Sizeof(x ArbitraryType) uintptr
func Offsetof(x ArbitraryType) uintptr
func Alignof(x ArbitraryType) uintptr
以上三个函数返回的结果都是 uintptr 类型,这和 unsafe.Pointer 可以相互转换。三个函数都是在编译期间执行,它们的结果可以直接赋给 const型变量。另外,因为三个函数执行的结果和操作系统、编译器相关,所以是不可移植的。Packages that import unsafe may be non-portable and are not protected by the Go 1 compatibility guidelines.
unsafe 包提供了 2 点重要的能力:
- 任何类型的指针和 unsafe.Pointer 可以相互转换。
- uintptr 类型和 unsafe.Pointer 可以相互转换。
unsafe.Pointer |
pointer | |
|---|---|---|
| 数学运算 | 不能 | 可以 |
| 指针的语义 | 有 | 无 uintptr 所指向的对象会被 gc 无情地回收 |
func testPtr() {
s := &Student{
name: "xiaoming",
age: 10,
}
pName := (*string)(unsafe.Pointer(s))
*pName = "lihua"
pAge := (*int)(unsafe.Pointer(uintptr(unsafe.Pointer(s)) + unsafe.Offsetof(s.age)))
*pAge = 20
fmt.Printf("student(name=%v, age=%v)\n", s.name, s.age)
}
//OUTPUT: student(name=lihua, age=20)
在java 中经常有一种场景
class Business{
private validate Object data;
// sync 会被定时执行
void sync()(
Object newData = 从db 拉到新数据 构造data
synchronized(this){
this.data = newData
}
)
}
对应到go 中可以 atomic.StorePointer($data,unsafe.Pointer(&newData))
sync.pool
sync.Pool 是 sync 包下的一个组件,可以作为保存临时取还对象的一个“池子”。它的名字有一定的误导性,与java 里的pool 不同,sync.Pool 里装的对象可以被无通知地被回收(GC 发生时清理未使用的对象,Pool 不可以指定⼤⼩,⼤⼩只受制于 GC 临界值),可能 sync.Cache 是一个更合适的名字。
var pool *sync.Pool
type Person struct {
Name string
}
func main() {
pool = &sync.Pool {
// 用于在 Pool 里没有缓存的对象时,创建一个。这点就很像guava cache
New: func()interface{} {
fmt.Println("Creating a new Person")
return new(Person)
},
}
// 当调用 Get 方法时,如果池子里缓存了对象,就直接返回缓存的对象。如果没有存货,则调用 New 函数创建一个新的对象。
p := pool.Get().(*Person)
p.Name = "first"
// 处理p
// 将对象放回池中
p.Name = "" // 将对象清空
pool.Put(p)
}
- Go 语言内置的 fmt 包,encoding/json 包都可以看到 sync.Pool 的身影;gin,Echo 等框架也都使用了 sync.Pool。
- Pool 里对象的生命周期受 GC 影响,不适合于做连接池,因为连接池需要自己管理对象的生命周期。
- 不要对 Get 得到的对象有任何假设,更好的做法是归还对象时,将对象“清空”。
type Pool struct {
noCopy noCopy
// 本地池,本地池数量与P 相等,一个P同时只能执行一个G,因此操作本地池时没有并发问题
local unsafe.Pointer // local fixed-size per-P pool, actual type is [P]poolLocal
localSize uintptr // size of the local array
victim unsafe.Pointer // local from previous cycle
victimSize uintptr // size of victims array
// New optionally specifies a function to generate a value when Get would otherwise return nil.It may not be changed concurrently with calls to Get.
New func() interface{}
}
command line application
go 可执行文件没有复杂的依赖(java依赖jvm、python 依赖python库),特别适合做一些命令行工具
大概的套路都是
- 定义一个Command对象
- Command 对象一般有一个 name,多个flag(全写和简写) 以及一个处理函数
urfave/cli
cli is a simple, fast, and fun package for building command line apps in Go. The goal is to enable developers to write fast and distributable command line applications in an expressive way.
Things like generating help text and parsing command flags/options should not hinder productivity when writing a command line app.This is where cli comes into play. cli makes command line programming fun, organized, and expressive!
spf13/cobra
这个库牛就牛在k8s 用的也是它
The best applications will read like sentences when used(命令执行起来应该像句子一样). Users will know how to use the application because they will natively understand how to use it.
The pattern to follow is APPNAME VERB NOUN --ADJECTIVE. or APPNAME COMMAND ARG --FLAG
A flag is a way to modify the behavior of a command 这句说的很有感觉
其它
组合一个struct 以方便我们给它加方法。比如 net.IP 是go 库的struct,想对ip 做一些扩充。就可以提供两个ip 的转换方法,以及扩充方法。
// Sub class net.IPNet so that we can add JSON marshalling and unmarshalling.
type IPNet struct {
net.IPNet
}
// MarshalJSON interface for an IPNet
func (i IPNet) MarshalJSON() ([]byte, error) {
return json.Marshal(i.String())
}
func (i *IPNet) UnmarshalJSON(b []byte) error {...}
// Version returns the IP version for an IPNet, or 0 if not a valid IP net.
func (i *IPNet) Version() int {
if i.IP.To4() != nil {
return 4
} else if len(i.IP) == net.IPv6len {
return 6
}
return 0
}
func ParseCIDR(c string) (*IP, *IPNet, error) {...}
优雅退出
Go 程序如何实现优雅退出?如果要停止正在运行的程序,通常可以这样做:
- 在正在运行程序的终端执行 Ctrl + C。发送的是 SIGINT 信号,这个信号表示中断,默认行为就是终止程序。
- 在正在运行程序的终端执行 Ctrl + \。发送的是 SIGQUIT 信号,这个信号其实跟 SIGINT 信号差不多,不过它会生成 core 文件,并在终端会打印很多日志内容,不如 Ctrl + C 常用。
- 在终端执行 kill 命令,如 kill pid 或 kill -9 pid。 发送的是 SIGTERM 信号,而 kill -9 pid 则发送 SIGKILL 信号。 这几种操作本身没什么问题,不过它们的默认行为都比较“暴力”。它们会直接强制关闭进程,这就有可能导致出现数据不一致的问题。比如,一个 HTTP Server 程序正在处理用户下单请求,用户付款操作已经完成,但订单状态还没来得及从「待支付」变更为「已支付」,进程就被杀死退出了。这种情况肯定是要避免的,于是就有了优雅退出的概念。所谓的优雅退出,其实就是在关闭进程的时候,不能“暴力”关闭,而是要等待进程中的逻辑(比如一次完整的 HTTP 请求)处理完成后,才关闭进程。
以上几种方式中我们见到了 4 种终止进程的信号:SIGINT、SIGQUIT、SIGTERM 和 SIGKILL。这其中,前 3 种信号是可以被 Go 进程内部捕获并处理的,而 SIGKILL 信号则无法捕获,它会强制杀死进程,没有回旋余地。在写 Go 代码时,默认情况下,我们没有关注任何信号,Go 程序会自行处理接收到的信号。对于 SIGINT、SIGTERM、SIGQUIT 这几个信号,Go 的处理方式是直接强制终止进程。如果我们在 Go 代码中自行处理收到的 Ctrl + C 传来的信号 SIGINT,我们就能够控制程序的退出行为,这也是实现优雅退出的机会所在。Go 为我们提供了 os/singal 内置包用来处理信号,os/singal 包提供了如下 6 个函数 供我们使用:
// 忽略一个或多个指定的信号
func Ignore(sig ...os.Signal)
// 判断指定的信号是否被忽略了
func Ignored(sig os.Signal) bool
// 注册需要关注的某些信号,信号会被传递给函数的第一个参数(channel 类型的参数 c)
func Notify(c chan<- os.Signal, sig ...os.Signal)
// 带有 Context 版本的 Notify
func NotifyContext(parent context.Context, signals ...os.Signal) (ctx context.Context, stop context.CancelFunc)
// 取消关注指定的信号(之前通过调用 Notify 所关注的信号)
func Reset(sig ...os.Signal)
// 停止向 channel 发送所有关注的信号
func Stop(c chan<- os.Signal)
留下评论