分层那些事儿
简介
笔者是一个java开发工程师,处于业务组,写了很多的crud代码。因此,对一些项目、架构保持很大的敬畏,一些开源项目的源码即便看的懂,也觉得很牛逼。十几个类,彼此之间,简单来看,是聚合、继承等关系,但又有一种说不清道不明的联系。不知怎么地,就可以弄出异步、监听等神奇的效果。
笔者这么多年的读书学习经验表明,如果你认为一个东西很厉害,理解起来有一些tricky的点,那就说明还没有深入理解它。
最近在看zookeeper client的源码,也曾看过我司的服务治理框架mainstay(可以实现rpc、服务发现、服务降级、异步调用等功能),它们涉及的东西很多:io、多线程、分层和异步等等。
A famous aphorism of David Wheeler goes: “All problems in computer science can be solved by another level of indirection” (the “fundamental theorem of software engineering”). This is often deliberately mis-quoted with “abstraction layer” substituted for “level of indirection”.
《软件架构设计》分层的典型特征:
- 越底层越简单、单一、固化。
- 严格遵守上层调用下层,控制同层调用。分层架构可以简单分为两种,即严格分层架构和松散分层架构。在严格分层架构中,某层只能与位于其直接下方的层发生耦合,而在松散分层架构中,则允许某层与它的任意下方层发生耦合。
分层
zookeeper、dubbo client端的基本套路
| 层 | 功能 | 交互数据 |
|---|---|---|
| 使用(可选) | 结合spring实现自动注入、自定义配置标签等 | |
| api层 | 提供crud监及异步操作接口 | 业务自定义model |
| 业务层(在不同的框架中可能继续分层) | 根据协议数据,以框架业务model的形式存储有状态信息,实现协议要求的机制,比如服务降级(dubbo)、监听(zookeeper)等功能 | 框架业务model |
| transport层 | 传输数据model,屏蔽netty、nio和bio使用差异 | 框架基本数据model,协议的对象化,负责序列化和反序列化 |
| socket | byte[] |
业务层的异步(线程加队列)和 通信层的异步(底层os机制),简单看,上层是否异步,依赖于底层,但分层是根据职责的,将异步封装为同步的代码,放在上层或下层均可。也就说,理论上,为了让代码符合直觉,每一层都可以做到同步。最上层是否提供异步操作,只看用户的需求。
分层在代码上的表现
不同的层次有不同的特性和符合这一层次的关键职责。在具体的工作中,有个习惯大家可以试试:我们总归有一层设计,是没有业务语义概念的。比如完整的一个insert操作。这个insert sql肯定没有业务语义,完全不理解这是一个什么场景需要insert。它只专注于实现insert功能。按照这种方法。我们就可以不断的抽象出不同的功能。
逻辑分层
- 上下分层
- 内外分层
- 洋葱分层架构
- 六边形分层架构
- DDD 分层架构
代码腾挪的艺术 如果一个逻辑,你用不同的语言实现,最后发现样子差别好大,就说明你没有做好抽象,任由语言特性干扰了代码结构。
系统设计的一些体会 要分得清楚访问代码、业务代码、存储代码、胶水代码各自应在哪些层级,它们应该是什么角色,而不是所有代码散乱的混在一起.
代码的跨层次调用
这块可以了解下 linux 网络协议栈
分层代码的配置传递问题
分层对接口设计的影响
拿业务层和transport层举例,笔者公司内部有一个rpc服务通信及治理框架,其项目maven接口如下
framework
framework-business
framework-business-api
framework-business-impl
framework-transport
framework-transport-api
framework-transport-netty
初看这段代码时,笔者曾觉得每一层弄一个xx-api不是很有必要,比如说,位于framework-transport-netty的NettyClient类
public class NettyClient{
void connect(ip,port){}
response transport(request){}
void close(){}
}
因为既然选定transport层使用netty,以后基于framework-transport-api不会有其它实现了,业务层直接使用NettyClient就好了嘛。可后来笔者发现,NettyClient.connect不仅业务层会调用,framework-transport-netty自身也会调用,比如心跳机制检测到连接断开时自动重连。如果一个方法有多个调用方,首先调用方传入的参数可能不同,这就需要方法由多个实现,这个好说。其次,调用方对方法的具体逻辑要求可能不同,这个就比较麻烦。同时,按照“单一职责原则”,向上的调用最好存在一个独立的接口,这或许是framework-transport-api存在的另一层重要原因。
分层与架构设计
比如操作系统的分层设计:kernel ==> memory management ==> input/output ==> file management ==> user interface
- 文件 读写要 内存缓冲区,因此要 事先弄好 内存管理
- 网络 访问,借用的 文件描述符,因此要实现 弄好 文件读写
在携程的持续交付实践中,它们没有直接让开发操作jenkins,而是自己实现了一个前置页面(及其系统),将用户的请求 根据jenkins 的负载负载分发到不同的jenkins上,亦或者执行容器化后的jenkins。
在众多大厂的内部私有云实现中,他们并没有将Kubernetes 直接暴露给开发, 而是实现了一个前置系统,规范、抽象一些基本动作。对于美团来说,开发无需感知底层是虚拟机还是容器。
2018.11.19 补充:笔者在公司内部进行docker实践时,一开始是使用jenkins 串联了代码 ==> 镜像 ==> 发布的各个步骤,用户直接操作jenkins。当时一个很头疼的问题是:一般项目内存设置为1g(此处是举例子)就可以了,但肯定有部分项目要特殊配置,此时个性化与模板化便有了矛盾。这类的问题可以使用前置系统来解决,1g 以下内存直接运行,1g以上内存则自动转入申请流程。解决普遍问题的开源系统 加上 个性化策略(比如权限、校验)的前置层,才是好用的内部系统。
为什么说,MapReduce,颠覆了互联网分层架构的本质?互联网分层架构的本质究竟是什么呢?如果我们仔细思考会发现,不管是跨进程的分层架构,还是进程内的MVC分层,都是一个“数据移动”,然后“被处理”和“被呈现”的过程。数据处理和呈现,需要CPU计算,而CPU是固定不动的。而数据是移动的,跨进程的:数据从数据库和缓存里,转移到service层,到web-server层,到client层;同进程的:数据从model层,转移到control层,转移到view层。归根结底一句话:互联网分层架构,是一个CPU固定,数据移动的架构。 假如MapReduce也使用类似的的分层架构模式,会有两层:map服务层:接收输入数据,产出“分”的数据,集群部署M=1W个实例;reduce服务层:接受“合”的数据,产出最终数据,集群部署R=1W个实例。当用户提交作业时:
- 把数据数据传输给map服务集群;
- map服务集群产出结果后,把数据传输给reduce服务集群;
- reduce服务集群把结果传输给用户; 存在什么问题?将有大量的时间浪费在大量数据的网络传输上。
为了减少数据量的传输
- 数据本身就是分散存储的。PS:任务是可以临时启动和销毁的。
- 输入数据,被分割为M(map实例的数量)块后,master会尽量将执行map函数的worker实例,启动在输入数据所在的服务器上;
- map函数的worker实例输出的的结果,会被分区函数划分成R(reduce实例的数量)块,写到worker实例所在的本地磁盘;map的输入输出不需要网络访问
- reduce函数,由于有M个输入数据源(M个map的输出都有一部分数据可能对应到一个reduce的输入数据),所以,master会尽量将执行reduce函数的worker实例,启动在离这些输入数据源尽可能“近”的服务器上;服务器之间的“近”,可以用内网IP地址的相似度衡量。reduce的输入就近,输出基本也不需要网络访问。
一个表格保存回显之路
2018.11.8 补充
假设要做一个后端系统,中间涉及到表格的保存和回显,表格如下图(实际上,表格跟具体的业务有关)
| header1 | header2 | header3 |
|---|---|---|
| cell1 | cell2 | cell3 |
| cell4 | cell5 | cell6 |
最开始的思路如下图左侧,根据表格中的业务数据直接保存。代码中大量的if else 以及for 循环。
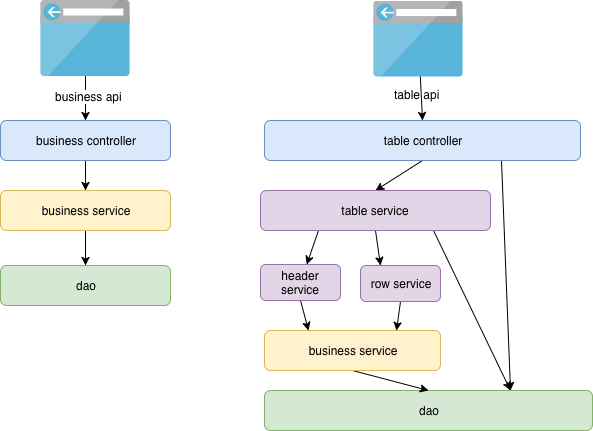
其实很明显我们可以想到,就界面交互来说,这首先是一个表格的保存与回显问题(前端无需知道业务,只知道保存与回显表格就行了),然后才是业务问题。于是笔者想,如果抛开具体业务,做一个普遍的表格保存与回显,应该如何做?所以采用了上图右侧的方式,抽象了一些类:Table、Header、Body,同时将service 分了一下层,代码清晰了一点,但是到这一步,仍只是理念上的分层,代码分散在一些类里,不那么“拥挤”了,但还有大量的if else 和 for循环。
大量的for 循环如何去掉?通过观察代码的特点,笔者考虑将for 循环抽出去,提取了如下接口
public interface HeaderHandler {
void handle(int index, String headerName);
}
public interface CellHandler {
void handle(int headerIndex,String headerName,int rowIndex,String rowValue);
}
public class TableUtils {
// 遍历table 特定列的 单元格,对每一个单元格执行 cellHandler
public static void iteratorCell(Table table, int columnStartIndex, int columnEndIndex, CellHandler cellHandler) {
...
for (int hi = columnStartIndex; hi < columnEndIndex; hi++) {
...
for (int ri = 0; ri < trs.size(); ri++) {
...
cellHandler.handle(hi, headerName, ri, cellValue);
}
}
}
}
于是在业务代码中便可以
public void saveBusiness(Table table){
...
TableUtils.iteratorCell(table, 0, 2, (headerIndex, headerName, rowIndex, rowValue) -> {
});
...
}
我们为了省去for 循环抽象的 ` public static void iteratorCell(Table table, int columnStartIndex, int columnEndIndex, CellHandler cellHandler)` 接口,正是一个表格 除数据抽象外,应该具备的 逻辑接口(另外还有一个表格的每一个单元格依次初始化)。至此,我们便可以借助TableUtils 干掉代码中大部分的for循环。
我们从各个角度回顾下上述过程
- 左耳朵耗子:控制与逻辑分离 《编程的本质》笔记
- 回调具有抽取代码的作用。将一整块代码 抽取为一个函数或工具类 比较容易,将流程的一部分抽取为接口则做的不多,很多生命周期接口(比如onSucces,onReceive,onFailure等)都是这样的例子代码腾挪的艺术
- 回调接口 也是分层接口设计的一部分 系统设计的一些体会
- 封层接口,有时候体现在工具类、业务类里,而不是模块间接口中
- 最开始只抽象出Table、Header、Body 时候,连带上分层,代码并没有明确的精简,想到HeaderHandler、CellHandler才豁然开朗。也可以看到,分层不仅要提供抽象,还要抽象行为。或者换个角度看,iteratorCell 方法也可以直接 放在Table 对象中,这也说明,贫血对象的抽象意义有限,充血对象才是有价值的(不仅有数据,还有行为)。ddd(一)——领域驱动理念入门
- 计算中没有什么问题是加一层解决不了的
如何识别需要分层
隐藏细节
以一个zk 数据的保存为例:笔者曾经有一个业务,涉及到project 的保存、删除、开启和关闭(存储为zk)。有一个zk工具类
class ZKUtils {
public static void create(String path,String value){...}
public static void remove(String path){...}
public static void update(String path,String value){...}
public static String get(String path){...}
}
然后在业务中 就直接使用了zk 工具类,从常规来看,这样写并没有什么问题。但ZKUtils.update 的操作语义可以很宽泛,可能是改了个名字、更新状态等。也就是说,上层只需要4个数据操作,而ZKUtils 直接提供了几乎无限的操作可能,若是将ZKUtils 直接暴露在业务操作中,会有一些问题
- 代码复用不够,比如 将project 转换为path 和 value 的代码会到处都是
- 新手过来不了解情况,用
ZKUtils.update关闭了一个project,但不知道关闭后还要 执行关联代码,造成数据不一致。 - 需求的更改不能控制在有限的边界内
这时,一定可以有一个抽象层
interface ZK{
void addProject(Project porject);
void remove(Project project/String projectName);
void close(Project project);
void open(Project project);
}
对上承接业务需求,对下屏蔽zk处理,以后数据存储不用zk了,存储变动对上层业务代码也没有影响。平时的controller-service-dao代码 在这块最为明显。
所以笔者当下的业务经验是:如果数据提供方和需求方接口数量差异很大时,要使用分层。另一个跟分层无关的经验是:不要向上层直接暴露update 方法,而是暴露意义的更新操作名来明确变动。
增加把控
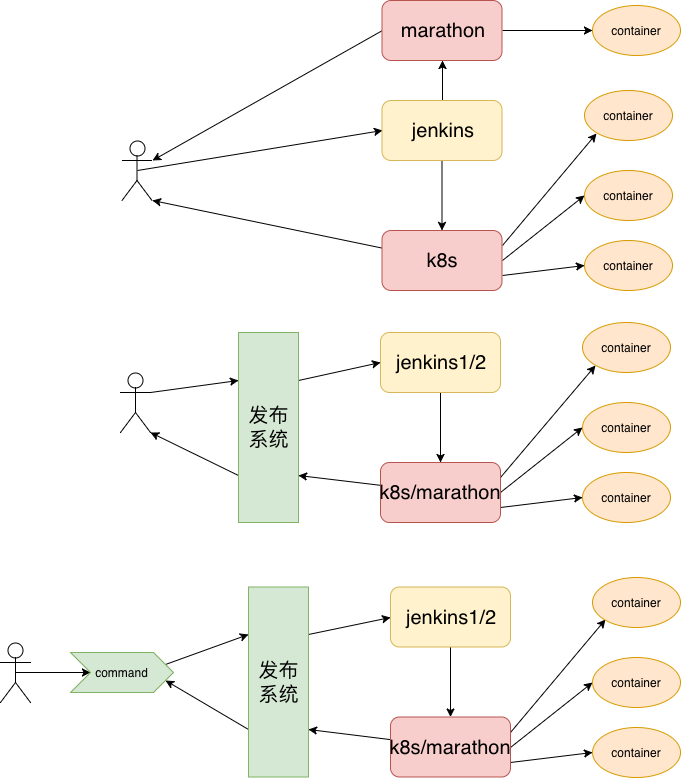
笔者曾负责过一段时间的发布系统,常规流程是:用户操作 jenkins ==> build ==> 触发k8s 调度业务系统 ==> 业务系统在docker 环境上运行。
在维护时发现几个问题
- 用户经常输入错误(少输、输错)jenkins 配置,而因为无法介入jinkins的工作过程,输错了也无法正确提示
- 用户jenkins 操作完毕后,无法直观的看到业务容器状态,需要另外进入k8s界面查看。
- 有部分老业务跑在marathon 上,前两点的复杂性翻倍
- 开发人员发布时有明显的高峰低谷,每到下午五六点,开发忙了一天,也开发布下代码看看效果了,此时jenkins 便会很忙。采用jenkins 本身的集群机制,负载均衡效果比较差。
因此我们自己实现了一个发布系统,加了这一层,便可以做到
- 对用户的输入进行校验
- 根据jenkins 负载动态将任务调度到不同的jenkins上
- 用户只需感知一个发布系统,对jenkins、marathon和k8s无需关注
- 做的更狠一点,为用户提供一个二进制工具来操作发布系统,这样用户在开发时甚至都无需离开IDE窗口。
分层和线程
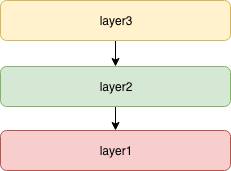
假设layer1是阻塞的,那么为layer2加上线程池后,在layer3看来,layer2接口就变成非阻塞的了(调用变成了任务,存在了layer2 executor的队列中)。
假设layer1是阻塞的,那么layer2经过多线程及其它技巧,在layer3看来,layer2接口可以变成异步的,例如netty就做到了喔。参见异步编程
其它
如果你看神经网络,很明显无论宏观微观,是一个分层的结构。
知识和人类的认知本身,也是一个分层的结构, 认知的几点规律
留下评论