LLM外挂知识库
简介
RAG(Retrieval-Augmented Generation),LLM相比传统算法最重要的就是zero shot能力,最重要的是从海量的文档中找到和问题相关的片段。找到后使用LLM生成回答其实很鸡肋,尤其是针对技术问题的回答,不需要LLM 去造答案,LLM 就帮我找到相关文档就行了。RAG 的主要目标是通过利用检索的优势来增强生成过程,使 NLG 模型能够生成更合理且适合上下文的响应。通过将检索中的相关信息纳入生成过程,RAG 旨在提高生成内容的准确性、连贯性和信息量。With RAG, we augment the knowledge base of an LLM by inserting relevant context into the prompt and relying upon the in context learning abilities of LLMs to produce better output by using this context.
引入外部知识 的几个示例
大语言模型的原理,就是利用训练样本里面出现的文本的前后关系,通过前面的文本对接下来出现的文本进行概率预测。如果类似的前后文本出现得越多,那么这个概率在训练过程里会收敛到少数正确答案上,回答就准确。如果这样的文本很少,那么训练过程里就会有一定的随机性,对应的答案就容易似是而非。
LLM 擅长于一般的语言理解与推理,而不是某个具体的知识点。如何为ChatGPT/LLM大语言模型添加额外知识?
- 通过fine-tuning来和新知识及私有数据进行对话,OpenAI 模型微调的过程,并不复杂。你只需要把数据提供给 OpenAI 就好了,对应的整个微调的过程是在云端的“黑盒子”里进行的。需要提供的数据格式是一个文本文件,每一行都是一个 Prompt,以及对应这个 Prompt 的 Completion 接口会生成的内容。
{"prompt": "<prompt text>", "completion": "<ideal generated text>"} {"prompt": "<prompt text>", "completion": "<ideal generated text>"} {"prompt": "<prompt text>", "completion": "<ideal generated text>"} ...有了准备好的数据,我们只要再通过 subprocess 调用 OpenAI 的命令行工具,来提交微调的指令就可以了。
subprocess.run('openai api fine_tunes.create --training_file data/prepared_data_prepared.jsonl --model curie --suffix "ultraman"'.split())微调模型还有一个能力,不断收集新的数据,不断在前一个微调模型的基础之上继续微调我们的模型。
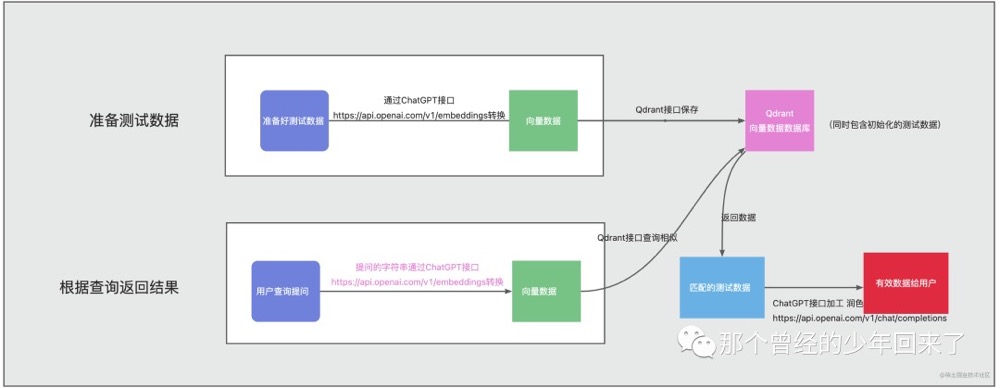
- 通过word embeddings + pinecone数据库来搭建自己私有知识库。 chatgpt预训练完成后,会生成一个embeddings向量字典,比如我们可以将我们的私有知识库各个章节通过openai的相关api获取到对应的embeddings,然后将这些embeddings保存到向量数据库(比如 Facebook 开源的 Faiss库、Pinecone 和 Weaviate),当用户要对某个领域后者问题进行语义查询时,则将用户的输入同样通过openai的相关api来获取相应的embeddings向量,然后再和向量数据库pinecone中的我们的私有知识库类型做语义相似度查询,然后返回给用户。PS: 内容向量化
- 数据向量化的目的是将文本数据映射到一个低维的向量空间中,使得语义相似的文本在向量空间中的距离较近,而语义不相似的文本在向量空间中的距离较远。比如判断某一段文本 是积极还是消极,向chatgpt 查询目标文本的向量,然后计算其与“积极” “消极” 两个词 embedding 向量的“距离”,谁更近,说明这段文本更偏向于积极或消极。
- 向量是基于大模型生成的,因此对两段文本向量相似度计算必须基于同一个模型,不同的模型算出来的向量之间是没有任何关系的,甚至连维数都不一样。不过你可以把基于A 模型来算向量相似度进行检索把文本找出来,然后把找到的文本喂给B模型来回答问题。
- chatgpt 插件,比如有一个提供酒旅租车信息的插件
比如针对问题:鲁迅先生去日本学习医学的老师是谁。因为 LLM(大语言模型)对上下文长度的限制,你不能将《藤野先生》整体作为提示语然后问“鲁迅在日本的医学老师是谁?”。 先通过搜索的方式,找到和询问的问题最相关的语料。可以用传统的基于关键词搜索的技术。也可以先分块存到向量数据库中(向量和文本块之间的关系),使用 Embedding 的相似度进行语义搜索的技术。然后,我们将和问题语义最接近的前几条内容,作为提示语的一部分给到 AI(使用检索结果作为 LLM 的 Prompt)。然后请 AI 参考这些内容,再来回答这个问题。

这也是利用大语言模型的一个常见模式(这个模式实在太过常用了,所以有人为它写了一个开源 Python 包,叫做 llama-index)。因为大语言模型其实内含了两种能力。PS:有点像推荐的粗排和精排,纯向量化的召回在一些Benchmark上表现还不如关键字搜索。
- 海量的语料中,本身已经包含了的知识信息。比如,我们前面问 AI 鱼香肉丝的做法,它能回答上来就是因为语料里已经有了充足的相关知识。我们一般称之为“世界知识”。
- 根据你输入的内容,理解和推理的能力。这个能力,不需要训练语料里有一样的内容。而是大语言模型本身有“思维能力”,能够进行阅读理解。这个过程里,“知识”不是模型本身提供的,而是我们找出来,临时提供给模型的。如果不提供这个上下文,再问一次模型相同的问题,它还是答不上来的。
多文档问答难点
上下文注入,即不修改LLM,专注于提示本身,并将相关上下文注入到提示中,让模型参考这个提示进行作答,但是其问题在于如何为提示提供正确的信息。目前我们所能看到的就是相关性召回,其有个假设,即问题的答案在召回的最相似的文档里。
单文档问答,即类似ChatPDF的需求,ChatPDF的目标是尽可能全面地总结出整篇文档的信息。这个需求以目前ChatGPT可接受的16K上下文而言,不少文档可以直接丢进去问答,不需要使用召回工具先做知识检索。PS:慢慢随着技术进步不成问题。
如果我们看一下RAG系统中的流程链:
- 将文本分块(chunking)并生成块(chunk)的Embedding
- 通过语义相似度搜索检索数据块
- 根据top-k块的文本生成响应 我们会看到所有的过程都是有信息损失的,这意味着不能保证所有的信息都能保存在结果中。如果我们把所有的限制放在一起,重新考虑一些公司即将推出的基于RAG的企业搜索,我真的很好奇它们能比传统的全文搜索引擎好多少。
RAG探索之路的血泪史及曙光 值得细读。
深入剖析开源大模型+Langchain框架智能问答系统性能下降原因常规方案中对智能问答系统准确率影响最大的几个因素如下:
- embedding 在 Retrieval 任务中 TopK 的准确率 (受 embedding 模型自身能力、Retrieval 算法、K等三个因素影响)
- K 的大小,K 原则越大越好,但是 LLM 的 tokens 限制导致 K 由不能太大。(上述 1、2 的都是为了从数据库海量 chunks 中选择出包含正确答案的 chunks)
- LLM 自身阅读理解与总结推理能力。
问题分级
如何让LLM简要、准确回答细粒度知识?如何让LLM回答出全面的粗粒度(跨段落)知识?QA 的难度主要在于回答这个问题所依赖的信息在长文档中的分布情况,具体可以大致分为下面三种情况:
- 相关信息可以出现在不超过一个固定上下文长度(512)限制的 block 以内
- 相关信息出现在多个 block 里,出现的总数不超过 5-10 个,最好是能在大模型支持的有效长度内。
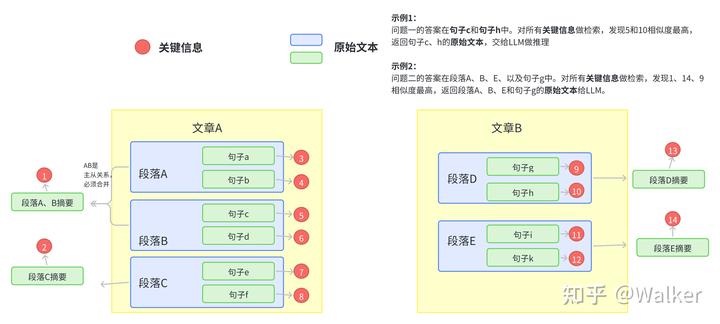
- 需要考虑多个片段,并综合结合上下文信息甚至全部内容才能得到结果。通过多次提问,不断诱导模型生成解决问题的路径,对于一个问题的解决可能需要重复调用很多次才能完成。比如段正淳这一生有几个相好? PS: 可能要知识图谱帮一点忙。
受限于数据集的大小和规模以及问题的难度,目前主要研究偏向于 L1 和 L2,也就是局部检索能力。能比较好的整合和回答 L1 类问题,L2 类问题也有比较不错的结果,但对于 L3 类问题,如果所涉及到的片段长度过长,还是无法做到有效的回答。了解RAG能做什么和不能做什么,可以让我们为RAG寻找最适合的领域,避免强行进入错误的地方。大模型应用落地那些事工程上,除 langchain 外,任何复杂的 L3 级别的构建都不推荐使用langflow/coze这类工具,因为 L3 架构需要大量定制化调优,而这类工具通常是有自己的一套逻辑。
RAG一周出Demo,半年上不了线,怎么破?任何用户检索问题都可以分成四类
- 显性事实查询,指外部数据中直接存在的事实信息或数据,不需要进行额外的推理。比如“2016年奥运会在哪里举办的?”
- 隐性事实查询,隐性事实并不会直接在原始数据中显现,需要少量的推理和逻辑判断。而且推导隐性事实的信息可能分散在多个段落或数据表中,因此需要跨文档检索或跨表查询。比如,“查询过去一个月营收增长率最高的门店”
- 隐性事实查询的主要挑战是,不同问题依赖的数据源和推理逻辑都各不相同,如何保障大模型在推理过程中的泛化性。
- 可解释性推理。是指无法从显性事实和隐性事实中获取,需要综合多方数据进行较为复杂的推理、归纳和总结的问题,并且推理过程具备业务可解释性。比如”过去一个月,华南区域营收下滑5%的原因是什么?。这个问题无法直接获取,但可以通过一定方式进行推理,“总营收 = 新客 * 转化率 * 客单价 + 老客 * 复购率 * 客单价”。经过分析,新客数量、转化率和客单价并未发生明显变化,而老客复购率下滑约10%,因此可以推断出可能是”服务质量、竞品竞争“等原因,引起了老客复购率的下滑,从而导致了总营收的下降。可解释性推理问题主要有两个挑战,多样化的提示词(不同的查询问题,需要特定的业务知识和决策依据,需要行业专家进行梳理和规则沉淀)和有限的可解释性(提示词对于大模型的影响是不透明的)。有以下解题思路:
- 提示词优化和微调,有效地将业务推理逻辑,整合到大语言模型中,比较考验提示词设计人员的行业know-how。
- 决策树:将决策流程转换为状态机、决策树或伪代码,让大模型执行。比如在设备运维领域,构建故障树就是一种非常有效的故障检测方案。
- 利用智能体工作流。通过workflow构建大模型思考和行动的具体步骤,从而约束大模型的思考方向。这种方法的优点是能够提供相对稳定的输出,但缺点是灵活性不足,同样需要针对每类问题设计工作流。
- 隐性推理查询。隐性推理查询,是指难以通过事先约定的业务规则或决策逻辑进行判断,而必须从外部数据中进行观察和分析,最终推理出结论。比如IT智能运维,并不存在先验的完整文档,详细记录每种问题的处理方法和规则,只有运维团队过去处理的各种故障事件和解决方案。大模型需要从这些数据中挖掘出针对不同故障的最佳处理方案,这就是隐性推理查询。主要挑战是逻辑提炼困难、数据分散和不足,是最为复杂和苦难的问题。有以下解题思路:
- 机器学习:通过传统的机器学习方法,从历史数据和案例中总结出潜在的规则。
- 上下文学习:在提示中涵盖相关的示例,给模型进行参考。但是这种方法的缺陷在于,如何让大模型掌握其训练领域之外的推理能力。
- 模型微调:通过大量业务数据和案例数据,对模型进行微调,将领域知识进行内化。但是这种方法的资源耗费比较大,中小企业谨慎使用。
- 强化学习:通过奖励机制,鼓励模型产生最符合业务实际的推理逻辑和答案。
问题分级也是牵引下面各个技术点的抓手,技术点非常多,但是它们主要是为了解决某一级的问题而出现的。
OOD/Out-of-Domain
- 预检索阶段
- 给提问贴意图标签。将用户查询映射到预定义的业务意图空间,不在空间内的直接拒答。
- 动态查询重写
- 检索阶段
- 过滤低置信度匹配。传统做法设定固定余弦相似度阈值(如0.75),但存在致命缺陷:不同Embedding模型的向量分布差异极大,高维空间的聚类效应也会让无关文档获得虚假高分。自适应阈值的核心逻辑:分析Top-K结果的分数分布,而非绝对数值:
- 如果Top-1分数显著高于Top-2(陡峭落差)→ 大概率是精准匹配,保留结果;
- 如果Top-10分数平缓(彼此差异小)→ 系统在硬凑相关文档,判定为OOD,剔除结果。
- 用双重验证避免单一检索的盲区
- 过滤低置信度匹配。传统做法设定固定余弦相似度阈值(如0.75),但存在致命缺陷:不同Embedding模型的向量分布差异极大,高维空间的聚类效应也会让无关文档获得虚假高分。自适应阈值的核心逻辑:分析Top-K结果的分数分布,而非绝对数值:
- 后检索阶段—— 引入相关性裁判
文档处理/非结构化数据结构化
文档解析
经常遇到一些复杂文档的情况,这些文档中可能有表格,有图片,有单双栏等情况。尤其是对于一些扫描版本的文档时候,则需要将文档转换成可以编辑的文档,这就变成了版面还原的问题。具体的,可以利用ppstructrue进行文档版面分析,在具体实现路线上,图像首先经过版面分析模型,将图像划分为文本、表格、图像等不同区域,随后对这些区域分别进行识别。
- pdf pdf解析关键问题
- 将pdf 转为markdown
- 还有一些pdf 内容花样很多、布局复杂、图片占比高,比如xx用户手册等,此时转为markdown 就不是一个很好的方式。PS:手工转也很难。
- ppt
- 复杂之处在于:没有固定的格式与布局;典型的图、文、表混排;相对于文本,更倾向用图表来表示信息
- 不过PPT文档也有一个优势:有天然的知识块分割,每一页即为一个Chunk。 办法
- 索引阶段:对每一页截图,并生成尽可能丰富的文本表示做嵌入(使用vlm)
- 生成阶段:将检索到的文本与关联的截图一起输入大模型用于生成(因为vlm 不完全准,所以不能完全靠vlm识别后的文本)
- 企业AI知识库的文件解析痛点-Word格式解析优化 未读。
- 表格 Langchain下利用MutiVector Retriever更好支持RAG架构下表格文字混合内容问答 完全指南——使用python提取PDF中的文本信息(包括表格和图片OCR)
文档增强:可能用到一些参数提取工具,https://github.com/google/langextract
文档切分
如何将文档拆分为文本片段。主要有两种,一种就是基于策略规则,另外一种是基于算法模型。
- 如何保证文档切片不会造成相关内容的丢失?一般而言,文本分割如果按照字符长度进行分割,这是最简单的方式,但会带来很多问题。例如,如果文本是一段代码,一个函数被分割到两段之后就成了没有意义的字符。因此,我们也通常会使用特定的分隔符进行切分,如句号,换行符,问号等。可以使用专门的模型去切分文本,尽量保证一个chunk的语义是完整的,且长度不会超过限制。
- 文档切片的大小如何控制? 太小则 容易造成信息丢失,太大则不利于向量检索命中。此外还要考虑LLM context 长度的限制,GPT-3.5-turbo 支持的上下文窗口为 4096 个令牌,这意味着输入令牌和生成的输出令牌的总和不能超过 4096,否则会出错。为了保证不超过这个限制,我们可以预留约 2000 个令牌作为输入提示,留下约 2000 个令牌作为返回的消息。这样,如果你提取出了五个相关信息块,那么每个片的大小不应超过 400 个令牌。最详细的文本分块(Chunking)方法——可以直接影响基于LLM应用效果 Unstructured专家分享RAG应用中文档分块(chunking)的最佳实践 建议切的小一点。
- 分开不仅要支持设置上限,还是要支持设置下限(不能太短)。
- 基于算法模型,主要是使用类似 BERT 结构的语义段落分割模型,能够较好的对段落进行切割,并获取尽量完整的上下文语义。需要微调,上手难度高,而且切分出的段落有可能大于向量模型所支持的长度,这样就还需要进行切分。
分块方法。PS: 后续出了一个开源项目 Chonkie
- 按字符/标记分块
- 按段落分块。
- 语义分块/semantic chunking,它根据含义而不是结构元素对文本进行分组,通过检测句子之间的语义变化来进行分割,对于需要理解数据上下文的任务至关重要。
- 语义分块的主要思想是根据块的含义相似程度来分割给定的文本。这种相似性是通过将给定的文本分成句子,然后将所有这些基于文本的块转换为向量嵌入并计算这些块之间的余弦相似度来计算的。
- 这种方法虽然比递归字符分割更智能,但它也有局限性。比如,当文档中的话题来回切换时,语义分割可能会将相关内容分割到不同的块中,导致信息不连贯。比如遇到下面这种场景时,它们就会集体失灵:
"小明介绍了Transformer架构...(中间插入5段其他内容)...最后他强调,Transformer的核心是自注意力机制。"传统方法要么把这两句话拆到不同区块,要么被中间内容干扰导致语义断裂。而人工分块时,我们自然会将它们归为“模型原理”组。PS:跨越文本距离的关联性无法捕捉。
- 然而,其效果高度依赖于嵌入模型的质量和阈值的选择,且对于多主题交织的复杂段落,仍可能面临挑战。它无法“理解”内容的内在逻辑和未来可能被查询的方式。
- Agentic Chunking。核心思想是让大语言模型(LLM)主动评估每一句话,LLM会将这些句子进行propositioning(可以看做是对文档进行“句子级整容”,确保每个句子独立完整)处理,即将每个句子独立化,确保每个句子都有自己的主语。之后将其分配到最合适的文本块中。PS:问题就是慢、贵。
- latechunking,用 “先嵌入再分割” 思路,先对整个长文本标记化并经嵌入模型 Transformer 部分处理(需要一个很长的emb model),生成含全文上下文信息的标记嵌入,之后在均值池化前分块,并对各块做池化得嵌入表示。PS: 譬如1w 个token 经过transformer 后得到1w个 token vector输出,再根据chunk size将chunk 个token vector转为输出emb。优点是,一些代词能考虑到整个上下文。
- 正则表达式。你的RAG也许真的不需要语义切分
- 根据不同的文档类型(如法律合同、技术手册、财务报告)选择最合适的Chunking方法。
一个不好的分块,会带来很多的问题,比如说以下几点:
- 代称,他/她等表示响应的主题,刚好被切分在单独的块中,影响召回
- 单个块可能不包含完整的答案块,答案可能包含在连续的几个块中
- 块可能仅在某种特定上下文中才有意义 解决方案有2种:
- 在每个块添加上下文头,将更高级别的信息补充在文档块开头(例如将文档标题,摘要放在每个块的开头)这些上下文头会随着块一级被向量模型编码。
- 从块到段 chunk -> segments。 PS: 要么别切碎,要么切碎了再找补(给chunk 加元信息,用图勾连起来,raptor等), Doc Tree
LangChain+LLM大模型问答能力搭建与思考一般通用分段方式,是在固定max_length的基础上,对出现。/;/?/....../\n等等地方进行切割。但这种方式显然比较武断,面对特殊情况需要进一步优化。比如1.xxx, 2.xxx, ..., 10.xxx超长内容的情况,直接按这种方法切割就会导致潜在的内容遗漏。对于这种候选语料”内聚性“很强的情况,容易想到,我们要么在切割语料时动手脚(不把连续数字符号所引领的多段文本切开);要么在切割时照常切割、但在召回时动手脚(若命中了带连续数字符号的这种长文本的开头,那么就一并把后面连续数字符号引领的多段文本一起召回)。笔者目前只想到了这两种方法且还没具体做实验,只是凭空想来,前者方案有较明显瑕疵,因为这样会
- 相对于更短文段而言,长文段的语义更丰富,每个单独的语义点更容易被淹没,所以在有明确语义query的召回下这种长文段可能会吃亏;
- 长文段一旦被召回,只要不是针对整段文本的提问,那么也是引入了更多的噪声(不过鉴于LLM的能力,这可能也无伤大雅,就是费点显存or接口费用了) 但后者就显得更灵活些,不过确实也不够聪明。暂时没想到其他办法,有好想法的人可以来交流一下~此外,有研究表明,长文本作为输入LLM输入时,LLM倾向于更关注长文本的开头、结尾处,然而中间部分的语义可能会被忽略。
对于大模型RAG技术的一些思考针对各种类型的文档,分别进行了很多定制化的措施,用于完整的提取文档内容。
- Doc类文档还是比较好处理的,直接解析其实就能得到文本到底是什么元素,比如标题、表格、段落等等。这部分直接将文本段及其对应的属性存储下来,用于后续切分的依据。
- PDF类文档的难点在于,如何完整恢复图片、表格、标题、段落等内容,形成一个文字版的文档。这里使用了多个开源模型进行协同分析,例如版面分析使用了百度的PP-StructureV2,能够对Text、Title、Figure、Figure caption、Table、Table caption、Header、Footer、Reference、Equation10类区域进行检测,统一了OCR和文本属性分类两个任务。
- PPT的难点在于,如何对PPT中大量的流程图,架构图进行提取。因为这些图多以形状元素在PPT中呈现,如果光提取文字,大量潜藏的信息就完全丢失了。于是这里只能先将PPT转换成PDF形式,然后用上述处理PDF的方式来进行解析。
- 当然,这里还没有解决出图片信息如何还原的问题。大量的文档使用了图文混排的形式,例如上述的PPT文件,转换成PDF后,仅仅是能够识别出这一块是一幅图片,对于图片,直接转换成向量,不利于后续的检索。所以我们只能通过一个较为昂贵的方案,即部署了一个多模态模型,通过prompt来对文档中的图片进行关键信息提取,形成一段摘要描述,作为文档图片的索引。
对于每个文档,实际上元素的组织形式是树状形式。例如一个文档包含多个标题,每个标题又包括多个小标题,每个小标题包括一段文本等等。我们只需要根据元素之间的关系,通过遍历这颗文档树,就能取到各个较为完整的语义段落,以及其对应的标题。有些完整语义段落可能较长,于是我们对每一个语义段落,再通过大模型进行摘要。这样文档就形成了一个结构化的表达形式: |id| text| summary| source| type| image_source| |–|–|–|–|–|–| |1| 文本原始段落| 文本摘要| 来源文件| 文本元素类别(主要用于区分图片和文本)| 图片存储位置(在回答中返回这个位置,前端进行渲染)|
切片增强:利用 LLM 对知识语料进行增强和扩充。
- 将chunk和该chunk所在的文档内容(这里是整片论文)传给LLM,让LLM结合整个文档对这段chunk作个概述,然后把这个概述的信息append到chunk的内容中,从而增强在后续进行语义检索时的精确性。
- 对一篇文档/chunk生成知识点、问题、短摘要(有地方称为反向HyDE),当根据query 进行匹配时,可能先匹配到知识点、问题、短摘要,再找到原始chunk。MultiVectorRetriever/ParentDocumentRetriever 。
文档召回/大海捞阵
查询本身可能并未提供足够的信息来指导模型找到最相关的文本块,而是需要更多的信息和逻辑推理,于是修改用户输入以改善检索。文档召回过程中如何保证召回内容跟问题是相关的? 或者说,如何尽可能减少无关信息? 召回数据相关性的影响方面很多,既包括文档的切分,也包括文档query输入的清晰度,因此现在也出现了从多query、多召回策略以及排序修正等多个方案。
召回的输入(不一定是用户原输入)?召回的输出(不一定是Vectordb原输出)?召回的方式(不一定直接查vectordb,微调embedding)?
优化召回的输入/如何使检索对用户输入的变异性稳健/优化发送给检索器的搜索查询?
- 查询转换
- 将用户问题采用多个不同的视角去提问,借助子问题检索,然后 LLM 会得出最终结果。大多数人在问问题的过程中,如果不懂 prompt 工程,往往不专业,要么问题过于简单化,要么有歧义,意图不明显。那么向量搜索也是不准确的,导致LLM回答的效果不好。所以需要 LLM 进行问题的修正和多方位解读。MultiQueryRetriever 。使用RAG-Fusion和RRF让RAG在意图搜索方面更进一步
- Decomposition(问题分解)在最终回答子问题的时候有两种方式。第一种是递归回答,即先接收一个子问题,先回答这个子问题并接受这个答案,并用它来帮助提出第二个子问题。第二种方式是独立回答,然后再把所有的这些答案串联起来,得出最终答案。这更适合于一组有几个独立的问题,问题之间的答案不互相依赖的情况。
from langchain.prompts import ChatPromptTemplate # Decomposition template = """You are a helpful assistant that generates multiple sub-questions related to an input question. \n The goal is to break down the input into a set of sub-problems / sub-questions that can be answers in isolation. \n Generate multiple search queries related to: {question} \n Output (3 queries):""" prompt_decomposition = ChatPromptTemplate.from_template(template) - BPO 通过优化提问和提供思路使得大模型更好的理解问题和回答问题。
- 天猫超市供应商如何入驻? ==> 通过对话增强优化后的提问:你是物流部的机器人,针对天猫超市供应商入驻物流及供应链产品的流程,进行详细且有条理的解答,包括但不限于入驻申请、签署协议、品牌授权、创建二级供应商、签署商务合同和确定入仓方案等步骤。请确保你的回答准确、有深度且连贯,能够帮助用户理解和使用产品。
- 下班后帮我推荐个附近好吃的店?==> 通过对话增强优化后的提问:今天是周五,路上比较拥挤。想吃点辣的,给我推荐下周围车程不超过10分钟有什么好吃的店?
- 结合历史对话的重新表述,在进行多轮对话时,用户的提问中的某个词可能会指代上文中的部分信息,因此可以将历史信息和用户提问一并交给LLM重新表述。
- 假设文档嵌入(HyDE),核心思想是接收用户提问后,先让LLM在没有外部知识的情况下生成一个假设性的回复。然后,将这个假设性回复和原始查询一起用于向量检索。假设回复可能包含虚假信息,但蕴含着LLM认为相关的信息和文档模式,有助于在知识库中寻找类似的文档。
- 退后提示(Step Back Prompting):如果原始查询太复杂或返回的信息太广泛,我们可以选择生成一个抽象层次更高的“退后”问题,与原始问题一起用于检索,以增加返回结果的数量。例如,原问题是“桌子君在特定时期去了哪所学校”,而退后问题可能是关于他的“教育历史”。这种更高层次的问题可能更容易找到答案。
- 关键信息抽取:关键信息抽取是通过自然语言处理技术从用户提问中提取关键词或短语,以便更准确地检索信息。基于LLM的关键词抽取 再看RAG在真实金融文档问答场景的实践方案:SMP2023 金融大模型挑战赛的两种代表实现思路
- 采用In-Context Learning的关键词抽取方案。通过构造history,模拟多轮对话的方式进行,让模型能稳定输出json,对于异常json通过调整temperature=1加上retry多次,使其更稳定输出。PS:有点意思,带有历史记录的 icl

- 有监督方案

- 采用In-Context Learning的关键词抽取方案。通过构造history,模拟多轮对话的方式进行,让模型能稳定输出json,对于异常json通过调整temperature=1加上retry多次,使其更稳定输出。PS:有点意思,带有历史记录的 icl
- 术语字典。查询扩展的一种,用户输入术语字典,查询时先根据query查询术语字典,若有匹配的则将query中的术语替换/增强一下(比如带上缩写词的全称),再去检索知识库。
- 把知识图谱的查询结果作为向量查询的输入信息,通过向量查询获取相关文档后,由LLM最终生成更加完整的问答结果。
- Finetune 向量模型。在专业数据领域上,嵌入模型的表现不如 BM25,但是微调可以大大提升效果。embedding 模型 可能从未见过你文档的内容,也许你的文档的相似词也没有经过训练。在一些专业领域,通用的向量模型可能无法很好的理解一些专有词汇,所以不能保证召回的内容就非常准确,不准确则导致LLM回答容易产生幻觉(简而言之就是胡说八道)。可以通过 Prompt 暗示 LLM 可能没有相关信息,则会大大减少 LLM 幻觉的问题,实现更好的拒答。
- 许多vdb支持了对元数据的操作。LangChain 的 Document 对象中有个 2 个属性,分别是page_content和metadata,metadata就是元数据,我们可以使用metadata属性来过滤掉不符合条件的Document。元数据过滤的方法虽然有用,但需要我们手动来指定过滤条件,我们更希望让 LLM 帮我们自动过滤掉不符合条件的文档。SelfQueryRetriever
-
增加追问机制。这里是通过Prompt就可以实现的功能,只要在Prompt中加入“如果无法从背景知识回答用户的问题,则根据背景知识内容,对用户进行追问,问题限制在3个以内”。这个机制并没有什么技术含量,主要依靠大模型的能力。不过大大改善了用户体验,用户在多轮引导中逐步明确了自己的问题,从而能够得到合适的答案。
def ask_questions(model, context, query, max_follow_ups=3): follow_ups = 0 while follow_ups < max_follow_ups: if model.can_answer(query, context): return model.answer(query, context) else: follow_up_query = generate_follow_up_query(query, context) query = follow_up_query follow_ups += 1 return "I'm sorry, I couldn't find an answer to your question." def generate_follow_up_query(current_query, context): # 这里可以根据上下文和当前查询生成一个追问 # 例如,询问用户是否需要更具体的信息 return "Can you please provide more details or clarify your question?" # 示例 context = "The capital of France is Paris." query = "What is the capital?" answer = ask_questions(model, context, query) print(answer)
多种召回方式
- 同时使用了es 和向量召回。 EnsembleRetriever。 |倒排召回|向量召回|知识图谱召回| |—|—|—| |检索速度更快||| |精确匹配能力强,比如一些专有名词、人名、产品名、缩写、id、低频词等|考虑语义相似性,更加智能|实体-关系检索| |没有语义信息,对”一词多义”现象解决的不好|不理解专有词汇,容易出现语义相似但主题不相似的情况|
- 对于两个不同检索方式(关键词检索、矢量检索)得到的召回数据,分数范围不一致,一个比较直接的想法就是对分数做归一化,然后把归一化后的数据做权重加和,得到最终分数。
- RRF,比单独的lexical search和单独的semantic search的效果要好,RRF存在两个问题:
- RRF只是对召回的topk数据的顺序进行近似排序计算,并有真正的对数据顺序计算。
- RRF只关注topk数据的位置,忽略了真实分数以及分布信息。你的RAG混合搜索效果不好?别着急上Reranking,先把RRF算法的K=60改了试试。
- 用rerank 对query + chunk 相关性进行打分。 embedding精度较低的根本原因在于,它必须将文档的所有潜在含义压缩成一个向量——这无疑导致了信息的丢失。此外,由于查询是在收到后才知道的,双编码器对查询的上下文一无所知(我们是在用户提出查询之前就已经创建了嵌入)。而reranker能够在大型Transformer中直接处理原始信息,这大大减少了信息丢失。由于reranker是在用户提出查询时才运行,这让我们能够针对具体查询分析文档的含义,而非仅生成一个泛化的、平均化的含义。但它也有代价,那就是时间。PS:rerank 既可以基于专门模型也可以基于llm,参考开源项目rerankers
- RRF,比单独的lexical search和单独的semantic search的效果要好,RRF存在两个问题:
- 合并检索时首先需要将文档按特定的层次结构进行切割,比如按两层结构进行切割即首先将文档按块大小(chunk_size)为1024进行切割,切割成若干个大文档块,然后每个大文档块(chunk_size=1024)再被切分成4个块大小为512的子文档块,那么这些子文档块就是所谓的叶子节点,而子文档块所属的大文档块就是所谓的父节点,而在检索时只拿叶子节点和问题进行匹配,当某个父节点下的多数叶子节点都与问题匹配上则将该父节点作为context返回给LLM。PS:dify 同时支持父子块暴漏给用户编辑。
- 在知识问答系统中,检索成本是一个不容忽视的问题。随着知识库的增长,可能需要遍历大量文档,导致检索速度缓慢,在检索大量信息时,如何确保检索结果的相关性和准确性也是一个挑战。层次检索是一种优化策略,它通过构建知识库的层次结构来减少检索范围,从而提高检索效率。实践方法:分析知识库的结构,建立层次索引;从顶层开始检索,逐步向下深入到具体的文档或信息片段;在每个层次上应用剪枝策略,只保留最相关的部分进行进一步检索。
- 文档切片为chunk,切得时候可以保留段落章节信息。对md 先按切到最小单元(比如最小三级标题),再对最小单元按长度切,chunk保留章节信息。emb召回时按chunk召回,rerank时按最小单元rerank, 生成时前后扩充更大的单位参与生成(反正llm context也不小了)“无”中生有:基于知识增强的RAG优化实践
- 多向量检索同样会给一个知识文档转化成多个向量存入数据库,不同的是,这些向量不仅包括文档在不同大小下的分块,还可以包括该文档的摘要,用户可能提出的问题等等有助于检索的信息。在使用多向量查询的情况下,每个向量可能代表了文档的不同方面,使得系统能够更全面地考虑文档内容,并在回答复杂或多方面的查询时提供更精确的结果。例如,如果查询与文档的某个具体部分或摘要更相关,那么相应的向量就可以帮助提高这部分内容的检索排名。
- 多向量检索也适用于包含文本和表格混合的半结构化文档。在这些情况下,可以提取每个表,生成适合检索的表摘要,但将原始表返回到LLM进行答案合成。
优化召回输出/Post-Processing,如何合并我检索到的文件?因为Content Windows的大小有限。
- 如果一篇文档与查询非常相关,但与已经呈现给用户的文档非常相似,那么这篇文档的边际收益可能就不大。MMR 是一种广泛应用于信息检索和自然语言处理领域的算法。MMR 的主要目标是在文档排序和摘要生成等任务中平衡相关性和新颖性。换句话说,MMR 旨在为用户提供既相关又包含新信息的结果。
- 在传统的RAG模型中,文本数据通常被分割成固定长度的块,然后再进行嵌入。这种方式虽然简单,但却忽略了文档级别的上下文信息,导致嵌入的上下文不够准确和完整。而 AutoContext 技术则巧妙地解决了这一问题。AutoContext 的核心思想是在嵌入各个文本块之前,先自动将文档级别的上下文信息注入到每个块中。具体来说,它会生成一个包含1-2个句子的文档摘要,并将其与文件名一起添加到每个块的开头。这样一来,每个块就不再是孤立的,而是携带了整个文档的上下文信息。通过 AutoContext,嵌入的文本块变得更加准确和完整,能够更好地捕捉文本的内容和含义。在实际测试中,AutoContext 显著提高了检索质量,不仅加快了检索正确信息的速度,还大大降低了搜索结果中出现不相关结果的概率。这对于下游的聊天和生成应用来说,意义重大,因为它减少了语言模型误解文本的可能性。
- 使用title 段落标题作为上下文
- 再进一步,使用整个文档的上下文为每个块提供简洁的、块特定的上下文,通过prompt 为每一个chunk 生成上下文
<document> </document> Here is the chunk we want to situate within the whole document <chunk> </chunk> Please give a short succinct context to situate this chunk within the overall document for the purposes of improving search retrieval of the chunk. Answer only with the succinct context and nothing else. 原始块 = "公司的收入比上个季度增长了3%。" 上下文化块 = "这个块来自关于ACME公司2023年第二季度表现的SEC文件;上个季度的收入为3.14亿美元。公司的收入比上个季度增长了3%。"
- 训练一个排序模型的方式对Topk 进行进一步相关性打分。建议以上游打分 Topk 作为训练数据,特别是结合真实的用户反馈数据。
- 文档重排:LLM 对位置是相对比较敏感的,得分好的放在首或尾,LLM会重点关注。LongContextReorder 。Rerank——RAG中百尺竿头更进一步的神器,从原理到解决方案
- Relevant Segment Extraction(RSE)RSE 是一个后置处理步骤,它的目标是智能地识别和组合能够提供最相关信息的文本部分,形成更长的文本段(segment)。这些文本段为语言模型提供了比任何单个块更好的上下文,使其能够更准确地理解和回答复杂的问题。RSE的工作原理如下:首先,它会对检索到的相关文本块进行聚类,将内容相似或语义相关的块归为一组。然后,它会根据查询的需求,智能地选择和组合这些块,形成长度适当、信息相关的文本段。这个过程不受固定长度块的限制,能够灵活地适应不同查询的需求。举个例子,如果我们问”苹果公司最近一个财年的主要财务业绩是什么?”,RSE就会将最相关的部分确定为整个”综合运营报表”部分,这可能包含5-10个块的内容。而如果问”苹果公司的首席执行官是谁?”,RSE则会识别出包含”蒂姆·库克,首席执行官”的单个块作为最相关的部分。PS:无关的候选分片剔除?时效性剔除?业务属性不满足剔除?
- CRAG使用一个轻量级的检索评估器对检索到的每个文档进行质量评估,计算出一个量化的置信度分数。触发知识检索动作:根据置信度分数,CRAG将触发以下三种动作之一:
- 正确:如果评估器认为文档与查询高度相关,将采用该文档进行知识精炼。
- 错误:如果文档被评估为不相关或误导性,CRAG将利用网络搜索寻找更多知识来源。
- 模糊:对于相关性不确定的文档,CRAG会结合正确和错误的处理策略,以提高检索的鲁棒性。 分解-重组:CRAG采用一种分解-重组算法,将检索到的文档解构为关键信息块,筛选重要信息,并重新组织成结构化知识。最后,利用经过优化和校正的知识,提高了生成文本的准确性和鲁棒性。
- small to big。比如一个query 召回10个分块。
- 将每个分块前后xx个分块召回(有的地方称之为膨胀系数),10个chunk ==> xx个分块塞给llm
- 将每个分块 所属的段落召回,10个chunk ==> 10个段落塞给llm
- 如果10个分块里,部分分块同属于一个文章,比如有3个分块在文章里的顺序是124,则将1234一起返回。
- 通过关联度扩展。索引阶段:对chunk 抽取实体和概念,再对所有chunk通过图谱建立关联,chunk 与chunk 之间计算关联度。查询阶段:根据已查询chunk 通过关联度扩展同一个文档内的chunk。WeKnora 上述一些方法是以时间换效果,并且query改写成多个,多个容易漂移,而且选项太多对于排序也有影响,这个提分不明显,是优化阶段要做的事,重点要放在文本切割上。因此,如何增强大模型自身的知识,或许才是正道?但这明显十分漫长。
知识冲突 “无”中生有:基于知识增强的RAG优化实践在知识库非常大的智能体下面,会发现有这样一种bad case:对同一个query,在不同的文档里确实是都能找到回答,但这两个文档的质量又确实有差异。一方面是在面对这类问题时往往大模型是无法直接判断错对优先,另一方面是本身模糊不清的知识更易让大模型产生幻觉。因此,我们在构建知识库时,可以考虑运用一些天然的知识标签和低成本构建的知识标签来增强知识库以化解知识冲突问题。
- 为了前置去解决给大模型的知识文档冲突的问题,我们需要在给大模型前事先判断出文档之间的重要性次序,可以利用文档的一些内容以外的信息作为文档标签来进行文档之间的相对优先级比较。 ||天然标签|人工标签| |—|—|—| |标签信息|文档创建时间、文档阅读次数、文档最近阅读时间、文档最近编辑时间|AI关键字、文档优先级| 从天然标签上来说,文档的时间信息及阅读量信息均可作为参考;从人工标签上来说,配合的业务方能从专业的角度进行简单的标记,将一些高保障知识库优先级打高、非常用知识库优先级打低。标签的用法上,一方面是可以前置做一些规则上的定制化过滤;另一方面,当我们需要的只是在大模型思考时候减少知识冲突带来的混乱时,则是可以将其综合对文档做相对的优先级分数区分。
- 从文档标签中获取优先级后,到底如何使用?对于都可能有用的文档来说,检索召回阶段的目标是召回相关文档,那这个阶段优先级加权怎么都不合理,因为必然会影响本身文本的相关性。我们不在检索中直接按优先级排序,而是将原有的通过相关性检索出来的文档和文档之间的相对优先级均通过prompt的方式告诉大模型,启发大模型先去选出要参考的文档再从中进行作答。
对LLM的要求
对于 RAG 来说,LLM 最基础也是最重要的能力其实包含:
- 摘要能力;
- 可控性:既 LLM 是否听话,是否会不按照提示要求的内容自由发挥产生幻觉;
- 翻译能力,这对于跨语言 RAG 是必备的。
优化
- 缓存
- LangChain 提供了 CacheBackedEmbeddings , 可以提高 embedings 的二次加载和解析的效率,首次正常速度,后续有一个 3倍效率的提升。
- 多模态。如何从非文本内容中提取有用的信息,并将其转化为可检索的格式?如何将提取的多模态信息与文本信息融合,以便进行统一的检索和回答?如何构建一个能够索引多模态内容的知识库。
- RAG与Long-Context之争—没必要争
- RAG 当前最大的问题是什么?笔者觉得是R 和 G 的割离。如果我们能在检索之前对知识点进行学习理解,去指导检索器应该从哪方面去查找,是不是能解决当下的很多问题?比如:花里胡哨的各路检索策略?、花里胡哨的各路query扩展和排序策略?、lost middle(因为查询到的都是相关的)?比如:法律场景笔者瞎编一个案例,张三走在路上,突然大叫一声,把旁边的老大爷吓的晕倒在地,请问这种情况张三犯法嘛,犯了什么法?当前的检索逻辑能召回什么法条?那如果要改进,该怎么办?笔者思考的是,在检索前让模型先分析案例,提出可能的法条方向,然后告诉检索器进行检索,是不是比瞎蒙的情况要更好?那么这个检索前的模型(暂且称之为检索指导模型)应该做到哪些点?应该对知识点有充分的理解能力。
模型也能“知其然知其所以然”——看SimRAG如何通过提问提升自己虽然现在的ChatGPT、Claude这些大模型很厉害,但在专业领域它们的表现还是不够好,比如说,当我们问它一个关于”支气管扩张”的专业问题时,它可能就答不太准确了。这是为什么呢?主要原因是这样的 - 这些专业领域有很多特殊的知识和术语,普通模型可能理解得不够深入。就像我们普通人看医学论文一样,没有专业背景的话,很多术语都看不懂。RAG先检索相关文档,再基于这些文档来回答问题。但是呢,这里又出现了一个新的问题。就算用了RAG技术,在专业领域的表现还是不够理想。这是为什么呢?因为模型可能不太懂得如何正确使用检索到的专业文献。就像一个医学院新生,即使给他一堆医学文献,他也不一定能准确理解和应用这些知识,那现在已经有哪些解决方案呢?主要有这么几种:
- 在专业文献上继续预训练,就像让模型多读点专业书籍。成本很高,就像要付很多学费一样
- 用专业领域的指令来微调模型。需要大量标注数据,这个在专业领域特别难获取
- 用GPT-4这样的强大模型来生成训练数据。不但贵,而且在一些涉及隐私的领域(比如医疗)可能还有安全隐患
近期有很多研究者在改进RAG,比如说:
- 有的在研究如何找到更相关的文档,就像图书馆员帮我们找最合适的参考资料一样
- 有的在研究如何过滤掉无关的内容,就像我们写论文时要去掉不相关的引用一样。自训练,它就像是“教学相长”的过程 - 模型一边学习,一边用学到的知识来教自己。具体怎么做呢?
- 先让模型学习一些基础知识
- 然后让它自己生成一些训练数据
- 再用这些数据来提升自己 但这个过程也有个问题,就像我们自学时可能会学到一些错误的知识一样,模型生成的训练数据也可能有错误。所以研究者们想了很多办法来解决这个问题:
- 有的会仔细筛选生成的数据,只用质量好的
- 有的会给不同的数据分配不同的重要性
- 还有的在研究如何让模型更好地理解和使用这些资料。领域特定的大语言模型。比如医疗领域的、法律领域的。他们是怎么训练这些模型的呢?主要有两种方式:
- 一种是让模型不断地读专业文献,就像医学生要不断学习专业知识一样
- 另一种是用特定领域的问题来训练模型,就像针对性地做习题 但这些方法都有什么问题呢?
- 成本太高了,就像请个一对一家教一样贵
- 效率不够高,投入了很多资源可能效果却不理想
- 有些方法还依赖GPT-4这样的大模型来生成训练数据,这就更贵了
Self-RAG
Self-RAG 框架:更精准的信息检索与生成 未读 也看引入自我反思的大模型RAG检索增强生成框架:SELF-RAG的数据构造及基本实现思路 未读
Self-RAG 及其实现 Self-RAG 主要步骤概括如下:
- 判断是否需要额外检索事实性信息(retrieve on demand),仅当有需要时才召回
- 平行处理每个片段:生产prompt+一个片段的生成结果。PS: query + chunk ==> 带有反思标记(relevant/supported/partital/inrelevant)的chunk
- 使用反思字段,检查输出是否相关,选择最符合需要的片段;
- 再重复检索
- 生成结果会引用相关片段,以及输出结果是否符合该片段,便于查证事实。
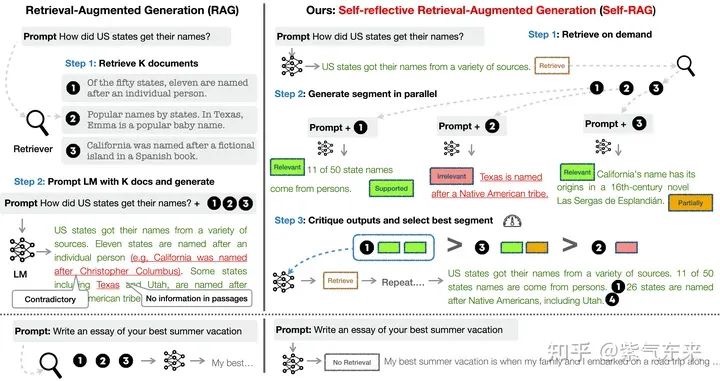
Self-RAG 的一个重要创新是 Reflection tokens (反思字符):通过生成反思字符这一特殊标记来检查输出。这些字符会分为 Retrieve 和 Critique 两种类型,会标示:检查是否有检索的必要,完成检索后检查输出的相关性、完整性、检索片段是否支持输出的观点。模型会基于原有词库和反思字段来生成下一个 token。PS: 需要进行模型微调以生成 Reflection tokens
一文彻底搞懂Self-RAG【上】:自省式RAG的原理与应用 建议细读。 一文彻底搞懂Self-RAG【下】:构建自省式的RAG应用与模型微调
另一种自我进化手段,给系统加了”错题本”机制:
- 每次问答结束后自动评估:
- 用户是否追问?
- 答案是否被采纳?
- 人工评分如何?
- 问题案例库分类存储
- 每周自动微调模型
要不要微调
如何权衡对需求prompt、continue pretrain 、sft?实时性强的知识以外挂知识库为主,专业的较为稳定的领域知识去微调模型:continue pretain 更多微调领域知识(比如知道感冒是什么),sft 更多是微调领域指令(比如能听懂“给我开个药方”,“下游任务”)。 具体到rag流程
- 微调提高rewrite 用户问题
- 微调提高emebedding 检索能力
- 微调提高agent调用tool的能力
- 微调提高llm 生成能力(有点次要)
效果评价
如何评估 RAG 应用的质量?最典型的方法论和评估工具都在这里了
- 评估指标。标准的 RAG 流程就是用户提出 Query 问题,RAG 应用去召回 Context,然后 LLM 将 Context 组装,生成满足 Query 的 Response 回答。那么在这里出现的三元组:—— Query、Context 和 Response 就是 RAG 整个过程中最重要的三元组,它们之间两两相互牵制。我们可以通过检测三元组之间两两元素的相关度,来评估这个 RAG 应用的效果
无需 ground-truth 也能做评估 1. Context Relevance: 衡量召回的 Context 能够支持 Query 的程度。如果该得分低,反应出了召回了太多与Query 问题无关的内容,这些错误的召回知识会对 LLM 的最终回答造成一定影响。三元指标其中的某个可能还有具体的一些细分,比如 Ragas中就将 Context Relevance 这一步又分为Context Precision、Context Relevancy、Context Recall。 2. Groundedness: 衡量 LLM 的 Response 遵从召回的 Context 的程度。如果该得分低,反应出了 LLM 的回答不遵从召回的知识,那么回答出现幻觉的可能就越大。 3. Answer Relevance: 衡量最终的 Response 回答对 Query 提问的相关度。如果该得分低,反应出了可能答不对题。
- 基于 Ground-truth 的指标,当一个数据集已经标注好了ground-truth 回答,那就可以直接比较 RAG 应用的回答和 ground-truth 之间的相关性,来端到端地进行衡量。
- LLM 回答本身的指标,比如评估回答本身是否友好,是否有害,是否简洁等,它们参考来源的是 LLM 本身的一些评估指标。
具体怎么衡量这三个得分,也有不同的方式。最常见的就是基于目前最好的 LLM(如 GPT-4)做为一个裁判,给输入的这一对元组打分,判断它们的相似度。根据我们目前的观察,GPT-4 这在方面做得已经很好了。人类都有可能打错分,GPT-4 的表现和人类类似,误判的比例保持在很低就可以保证这种方法的有效性。因此,如何设计 prompt 同样重要,这就要用到一些高级的 prompt 工程技巧,比如 multi-shot,或 CoT(Chain-of-Thought)思维链技巧。在设计这些 prompt 时,有时还要考虑 LLM 的一些偏见,比如 LLM 常见的位置偏见:当 prompt 比较长时,LLM 容易注意到 prompt 里前面的一些内容,而忽略一些中间位置的内容。好在这些 prompt 的设计已经被设计和集成在 RAG 应用的评估工具中。
关于ToB垂直领域大模型的一点探索和尝试我们沉淀了几万条标注过的物流垂类场景测评数据。这些测评数据是让我们选定基座模型、微调方法 和 后续一直迭代模型的一个重要指引。在这些测评数据的基础上,我们测评了市面上几乎所有的开源基座模型,以及能看到的几乎全部微调方法,并利用embedding similarity、人工打分、chatgpt4打分这3个维度分别测试 “基座模型” 和 “基座模型+微调” 在物流场景下的表现情况,从而挑选适合我们场景的基座模型和微调方法。在实际sft时候,我们还夹杂了部分公开数据集为了解决垂类大模型通用能力退化,适用性限制这一问题。公开数据集主要参考了有COIG-CQIA、alpaca-gpt4-data-cn等。最近,我们也参考ORPO尝试将SFT + DPO的模式变成单纯在SFT中增加一个惩罚项来让大模型做更好的偏好对齐。通过实验对比,ORPO相较于之前的链路,整体回答效果提升了约5.2%。
工程架构
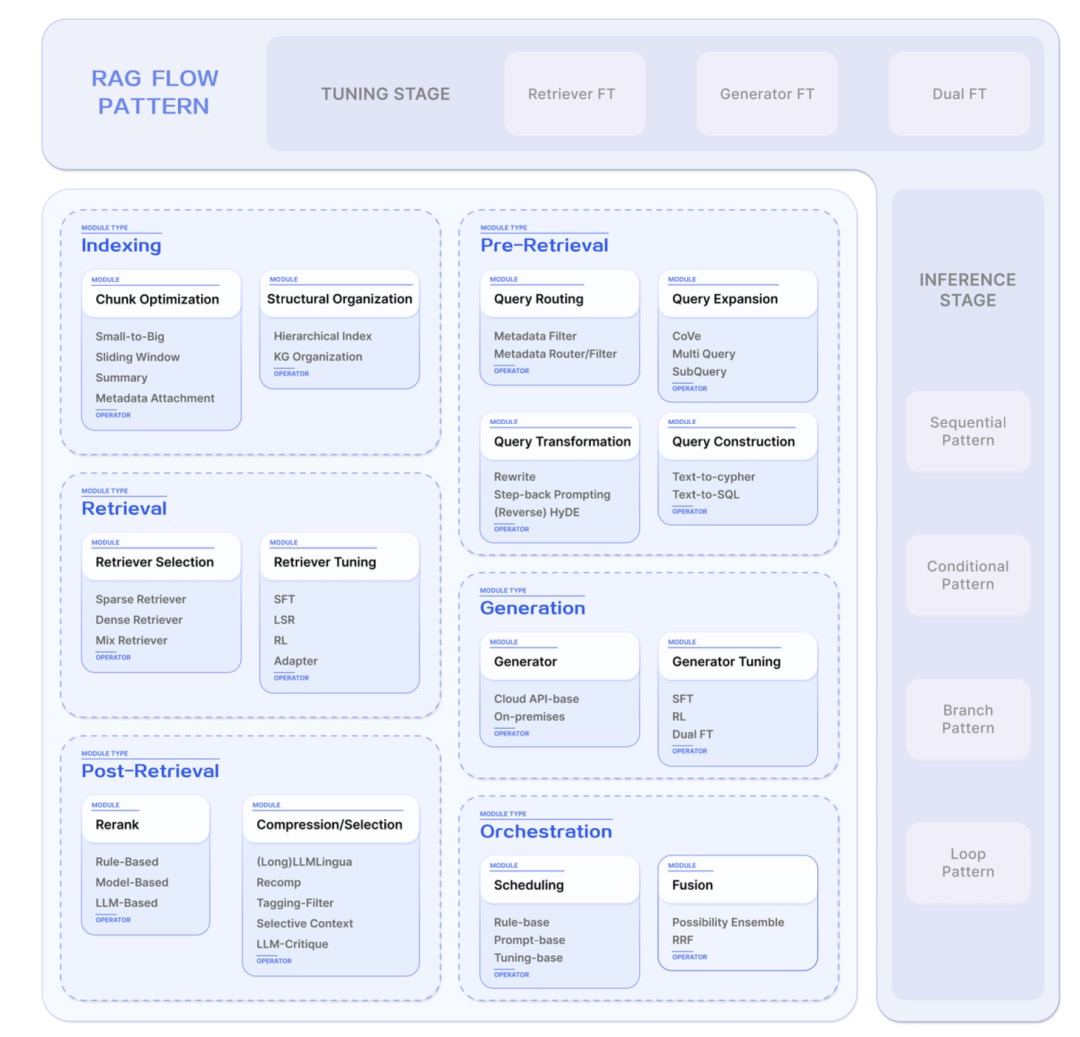
值得一看的大模型RAG问答总括性梳理:模块化(Modular)RAG范式的定义、构成及机遇RAG的快速发展早已经突破传统的链式RAG范式,展示出了模块化的特点。
文档处理工作流 PS:datashaper/ray
- 首先文档处理包含多个步骤,所以是一个典型的workflow/step,workflow 对应一个文档处理流程,step对应一个class/func,按配置拼为workflow。再丰富一点,workflow 和step 的状态支持持久化(对应db表),持久化之后 bind 一些字段/数据就可以支持重试/缓存,也具备一定的容错能力。至此,创建一个workflow 即可触发step 依次执行直到workflow 完成。
- 接着是workflow/文档 创建和消费,比如server 负责创建workflow,worker 负责消费workflow,并执行step。server 可以通过mq 将workflow id发给worker来驱动worker 执行workflow,也可以worker 监听workflow 表自己轮询来消费workflow。考虑到文档隶属于不同的知识库,要考虑不要让某个知识库的workflow独占了所有worker,这需要mq 分topic消费,从这个视角来说,worker 主动扫db消费workflow 更有利于各个知识库文档获取同等的处理机会。
问答工作流这块,llm的推理能力仍然不够,国内的llm更不够,llm的能力甚至影响了问答代码的实现方案。理想状态下,如果llm能力足够的话,基于llm的agentic chat (由llm决定是否拆分子问题,以及用户问题是否已充分回答,未充分回答则提取新问题)即可满足大部分需求。这里的一个大的难点是,各种技术论文每周都有新的方法出来,但每个方法都有特定的场景,无法直接纳入到现有的问答流程里。 比如hyde,也不可能一个问题进来都执行一次hyde再去检索。如果没有通用的处理工作流,则RAG平台型、专用型产品的鸿沟就一直在。想进一步,有时候觉得有必要微调下llm,但又不知道从哪里搞数据集,尤其是诱导llm拆解L2 L3 类问题。团队里缺个算法工程师的话,下个决心就比较难,是不是微调好llm + agentic chat 就一统天下了?尤其是开源llm一般一个季度发一版(内厂快的一个月发一版),刚微调完base llm能力提升了不白忙活了。
企业AI落地不顺,问题可能出在你没搞懂知识库 PS:知识库的内涵
- 解析、切分、入库
- 理论:数据 ==> 信息 ==> 经验 ==> 知识。工程:知识构建(抽取 ==> 处理算子 ==> 清洗算子 ==> 丰富算子)、知识应用(帮我找、帮我写、帮我做)、知识运营(冲突文档检测,知识刷新)
其它
ChromaFs 把向量数据库伪装成文件系统
一篇大模型NL2SQL全栈技术最新综述 未细读。
留下评论