LLM预训练
简介
LLama3 405B 技术解读大模型之所以能力仍在快速提升,主要驱动力有三个:
- 首先就是不断扩大模型和数据规模(Scaling Law)。
- 一个是越来越强调数据质量的作用,各种数据筛选方法和工具越来越多,保证质量是第一位的
- 不断增加数学、逻辑、代码这种能够提升大模型理性能力的数据配比比例,包括在预训练阶段(增加预训练数据此类数据比例,且在预训练后面阶段来上采样此类数据,就是说同样数据多执行几遍,以增加其对模型参数影响的权重)和Post-Training阶段(增加此类数据占比,Llama3的经过instruct的模型比仅做预训练模型相比,各种尺寸的效果提升都很大)皆是如此。 目前看,在通用数据快被用完情况下,第三个因素会成为之后大模型进步的主导力量,包括使用数学、逻辑、代码合成数据在Post-Training阶段的应用,目前技术也越来越成熟,其质量和数量会是决定未来大模型效果差异的最关键因素。PS:合成数据其实是模型蒸馏的一种变体,合成数据是更大的模型输出数据作为Teacher,小点的模型作为Student从中学习知识,用A大模型合成的数据对A大模型本身没有提高效果,所以其实本质上是一种模型蒸馏
自研 pretrain 模型的意义又有哪些呢?
- 各公司仅仅是开源了模型参数,但并没有开源训练框架、训练数据等更核心的内容,其实本质上还是闭源。在这种情况下,每一个 qwen 模型的使用者都无法为下一版 qwen 模型的迭代做出贡献,qwen 团队也仅仅是收获了口碑,甚至因为自己的模型已经开源可以自行部署,买他们服务的客户可能都会变少。因此,在 llm 真正走向全面开源之前(大厂公开训练代码、配比数据,任何人都可以通过提 CR 来帮助大厂优化训练效率、炼丹技巧),掌握 pretrain 的技术能力依然是有意义的;
- 通用模型的变现能力远不如 domain 模型,continue-pretrain 的需求在日益增长,而 continue-pretrain 的技术栈和 pretrain 的技术栈并没有本质区别;
- 不是自己做的 pretrain,必然无法得知这个模型在 pretrain 阶段到底喂了什么数据。各种数据的精确配比、各种 knowledge 的掌握程度,并不是靠评估能准确衡量的。而如果不知道这些数据细节,那么 alignment 阶段就无法对症下药,就无法最大限度的开发模型潜力。举个简单的例子,你在 sft 阶段,让一个没训过唐诗宋词的通用模型学习作诗,它不出幻觉谁出幻觉?
- 使用开源模型的话,tokenizer 不可控,进而导致解码速度不可控。这里也举个例子,如果我们用 llama 模型来做意图识别任务,有个意图叫 ai.listen.music,会被映射成 5 个 token,但如果使用自己训练的大模型,便会在一开始就设置成 1 个 token,极大节省了生成速度。虽然扩词表已经是一个比较成熟的技术了,但不仅需要花费算力来恢复效果,而且不管训多少新语料,也很难做到模型效果完全不掉点。
从零手搓中文大模型 比较通俗易懂,推荐看下。
目前比较成熟,一般采用 gpt架构,Llama/Llama2,在模型结构不改变的情况下,模型的优化主要在于 分词、参数选择、训练数据,同时也包括对attention方法的选择。
计算量
面试时被问到“Scaling Law”,怎么答?在大模型的研发中,通常会有下面一些需求:
- 计划训练一个 10B 的模型,想知道至少需要多大的数据?
- 收集到了 1T 的数据,想知道能训练一个多大的模型?
- 老板准备 1 个月后开发布会,给的资源是 100 张 A100,应该用多少数据训多大的模型效果最好?
- 老板对现在 10B 的模型不满意,想知道扩大到 100B 模型的效果能提升到多少? 大模型的 Scaling Law(一般称为pretrain-time scaling law) 是 OpenAI 在 2020 年提出的概念,具体如下:
- 对于 Decoder-only 的模型,计算量 C(Flops), 模型参数量 N,数据大小 D(token 数),三者满足:$C \approx 6ND$
- 模型的最终性能主要与计算量 C,模型参数量 N 和数据大小 D 三者相关,而与模型的具体结构(层数/深度/宽度)基本无关。固定模型的总参数量,调整层数/深度/宽度,不同模型的性能差距很小,大部分在 2% 以内。
- 对于计算量 𝐶,模型参数量 𝑁 和数据大小 𝐷,当不受其他两个因素制约时,模型性能与每个因素都呈现幂律关系。根据幂律定律,模型的参数固定,无限堆数据并不能无限提升模型的性能,模型最终性能会慢慢趋向一个固定的值。
- 为了提升模型性能,模型参数量 N 和数据大小 D 需要同步放大,但模型和数据分别放大的比例还存在争议。
- Scaling Law 不仅适用于语言模型,还适用于其他模态以及跨模态的任务:
对于 Decoder-only 的模型,计算量C(Flops),模型参数量 N(除去 Embedding 部分),数据大小 D(token 数),三者的关系为: C≈6ND。推导如下,记模型的结构为:decoder 层数l,attention隐层维度d,attention feedforward层维度 $d_{ff}$,一般来说 $d_{ff} = 4 * d$。 模型的参数量N(忽略emebedding、norm和bias) 计算如下,transformer 每层包含 self-attention 和mlp 两个部分
- self-attention 的参数为$W_q$、$W_k$、$W_v$、$W_o$,每个矩阵的维度为$R^{d*d}$,整体参数量:$4 * d^2$
- mlp 的参数为 $W_1$(维度为$R^{dd_{ff}}$)和$W_2$(维度为$R^{d_{ff}d}$),整体参数量:$2 * d * d_ff = 2 * d * 4d = 8d^2$
- 所以每层参数是$4d^2 + 8d^2 = 12d^2$,全部l 层的参数量为 $12ld^2$,即$N=12ld^2$
计算量的单位是FLOPS,float point operations 对于矩阵A (mn)和B(np) AB 相乘的计算量为2mnp,一次加法一次乘法。假设decoder 层的输入X(bsd),b为batch size,s为序列长度,d为模型维度。
- 前向推理的计算量:
- self-attention 部分的计算:
- 输入线性层,$XW_q$、$XW_k$、$XW_v$,计算量为 $3 * b * s * d * d * 2 = 6bsd^2$
- attention 计算 $QK^T$,计算量为 $2 * b * s* s * d = 2bs^2d$
- score 与V 的计算,$S_{attention}V$,计算量为 $b*2 * s * s * d = 2bs^2d$
- 输出线性层 $X^{\prime} W_O$,计算量为 $b * 2 * s * d * d = 2bsd^2$
- MLP 部分的计算:
- 升维 $XW_1$,计算量为 $b * 2 * s * d * 4d = 8bsd^2$
- 降维 $XW_2$,计算量为 $b * 2 * s * 4d * d = 8bsd^2$
- 所以整个decoder层的计算量为 $24bsd^2 + 4bs^2d$,全部l层为 $C_{forward}=24bsd^2 + 4bs^2d$。
- self-attention 部分的计算:
- 反向传播计算量是正向的2倍,所以全部计算量为 $C=3*C_{forward} = 72bsd^2 + 12bs^2d$。
- 平均每个token的计算量为 $C_{token}=\frac{C}{b s} = 72ld^2 + 12lsd = 6N (1+\frac{s}{6 d}) \approx 6N(s \le 6d)$
- 所以对于包含全部D个token的数据集 $C = C_{token}D \approx 6ND$
PS:mlp参数量和计算量都不输attention。 $C_{token} \approx 6N$ 可以认为是正反向3倍*加法乘法2倍=6倍。再拿到GPU的算力 * GPU 个数,就可以根据 $C \approx 6ND$ 计算训练的耗时了。
数据准备
| 训练阶段 | 说明 | 常见数据集 |
|---|---|---|
| pre-train(continual-train) | 收集、整理清洗,分类筛选,多语言无需特别加工,主要是数据分布合理,质量保障 | C4(T5),RedPajama,Pile,Wudao,ROOTS(BLOOM) |
| sft | 指令微调,数据需要人工加工,已经有一些公开数据集了主要目的是让机器学会一些思考、回答问题的方法 | |
| RLHF | 需要单独组织,人工整理数据主要目的是在回答的helpful、safety等方面符合人类标准 | https://github.com/anthropics/hh-rlhf/blob/master/README.md |
关于大模型语料的迷思 未读。 聊一聊做Pretrain的经验pretrain 大模型的第一件事:先找个 10T 左右的训练数据吧。至于怎么获取数据,爬网页、逛淘宝、联系数据贩子,等等等等。算法同学往往搞不定这个事情,你敢爬他就敢封你 IP,你爬得起劲他甚至还可以起诉你,所以这个工作最好还是让专业的数据团队同学来做。好在,世上还是好人多!今年再做 pretrain 工作,网上的开源数据集已经很多了。FineWeb、pile、Skypile、RedPajama,凑合着差不多能当启动资金来用。但从另一个角度讲,世界上没有免费的午餐,所有开源出来的中文大模型数据集,我不认为是他们最干净的数据,质量多少都有点问题。准备数据还要懂得一个基础概念:数据的知识密度是有差异的。“唐诗三百首”的知识量要远远大于“中国新闻网的三百篇新闻”。而这种高知识密度的训练数据,往往都是需要花钱的。最近,一种新的数据趋势是“合成高知识密度数据”,把几千字的新闻概括成几百字喂给模型,四舍五入也等于训练速度提高了十倍。

- 数据清洗。
- 目前,利用模型对 pretrain 数据的质量进行打分,已经成了数据清洗工作的标配,llama3、qwen2 的技术报告都有提及。需要注意的是,基本上大家都认同:同等 size 下,BERT 结构的模型的表征能力是强于 transformer-decoder 模型的,因此打分模型最好还是从 BERT 家族中选一个来训,效果好、速度还快。训打分器这个工作的难点是要学会放低心态,别那么执拗,不要执着于打分器 100% 的准确率,凑合能用就行了,有打分器总比没打分器强,但你要花一个月来训打分器,那就还不如没打分器。打分器结果只是众多数据特征中的一个特征,并不一定要完全依赖它来洗数据,可以和其他特征结合使用。
- 这也引出了数据清洗的另一个大杀器:规则。不要瞧不起规则!数据长度是否少于某个值,数据中某个 token 的比例超过某个阈值,数据的 zh 占比、en 占比、数字占比,数据是否有“http”字段,数据是否包含了“新冠”、“疫情”等低质量关键词,数据是否包含某些反动词汇,数据是否包含某些黄色字眼,等等等等。用启发式的规则过滤数据并不丢人,洗不干净数据才丢人。但同时,必须注意到,用规则清洗或者过滤数据的时候,一定不要把数据搞成分布有偏的数据。比如、你觉着:“包含网址的数据质量低,而网址的英文占比高”,所以你把英文占比高的数据都去掉了。整挺好,模型成了单语模型。因此,用规则的时候,一定要多 check 下被滤出去的数据长什么样子,勤 vim 一下!
- 数据脱敏也是数据清洗环节必须要做的一个工作。我们要尽可能的把训练数据中涉及到的人名、电话号码、邮箱等剔除出去,一旦被模型说出来,就构成了隐私侵犯,公司被罚的钱足够雇人把数据脱敏 N 遍了。更广义的,把数据的“转载自……”删掉,黄色信息、反动信息,references 等剔除出去,都可以视作数据脱敏工作的一部分。这个工作好像没任何奇淫巧技,老老实实的写正则匹配吧。

- 数据去重。数据环节最考研工程能力的环节到了:对 T 级别的数据进行去重。
- 不要心存任何幻想:能不能不做数据去重。答案肯定是不行的!网上基本所有的开源数据,都是来自 common crawl,你不去重如何混合使用呢。就算你只使用单一数据源或者自己爬取数据,也应该注意到:网页 A 引用了 网页 B,网页 B 引用了 网页 C……,网页 Z 又引用了网页 A。这种 url 循环调用的现象,在互联网屡见不鲜,你的训练数据集大概率会把一个网页翻来覆去的使用。即使能确保是不同的网页,一篇文章也会被知乎、CSDN、博客、微信公众号、小红书等不同软件反复转载。
- 去重工作唯一可以让步的地方是:是做 sentence 去重还是做 document 去重,这个我也不好断定,我的建议是量力而为。能做 sentence 去重,谁不愿意呢?可是数据量和工作难度也会陡增。
- 那么如何去重呢?首先,你一定要有一个大数据处理集群,hadoop 也好、spark 也罢,只要是一个 map / reduce 的框架就都可以。这个属于汽车的轮子,想要靠 python 写 for 循环完成这个工作,确实是勇气可嘉。然后,就去实现一个简单的 minhash 代码,没啥难度,ChatGPT 一定会写。
- 数据去重工作有一个比较重要的意识:要先确定需要多少训练数据,再确定去重的粒度。去重工作是没有尽头的,任何时候你都能把数据继续洗下去,所以必须明确自己需要多少训练数据。需要 10T 训练数据,就卡相似度在 80% 的阈值进行去重;需要 5T 的训练数据,就卡相似度在 90% 的阈值进行去重;以此类推。目前没有任工作能证明,一条数据在 pretrain 阶段训多少遍对模型是最友好的。因此,大胆的按需去重,即使去重粒度小,导致一篇文档出现多次,也可以通过让两篇相似文档之间隔尽量多的 token 来降低影响。去重的时候,“新闻”类可能 70% 的重复度就不要,“知识”类则可以 85% 的相似度才丢弃,在丢去重复文档的时候,优先保留数据打分器比较高的数据。
- 数据配比。大模型可能在训练过程中过度专注于垂类数据,导致loss的收敛不再依赖全局而是从部分数据进行考虑。
- 每一个 document 进行类别判断,不用特别精准,把数据划分成新闻、百科、代码、markdown、等类目即可,分类器模型依然可以选择使用 BERT 家族。
- 大部分的技术报告里,应该都提及了自己的数据是如何配比的,基本上都是“知识 + 代码 + 逻辑”三个大类目,其中知识数据分文中文知识和英文知识,逻辑数据则可以认为是 math 数据和 cot 数据的混合体。整体上,大部分中文模型的配比都在这个区间左右:中:英:code = 4:4:2(逻辑数据的比例我没有写进去,加入多少取决于你能收集多少,其他三类数据应该是要多少有多少的存在)。我们可以根据自己的实际情况调整配比,但英文的比例一定不能太低。目前中文数据的质量不如英文数据质量基本已经成功共识,导致这个现象可能有两个原因:中文确实比英文难学,语言空间的复杂度更高;中文语料无论是干净程度还是数量级,都无法与英文语料相比较。
- 数据顺序,pretrain 的本质是一个教模型学知识的过程,既然是学习,那么知识的顺序就显得很重要,总不能先学微积分,再学数字加减法吧。这也就是“课程学习”的核心思想。课程学习的内容很宽泛,无论是先学难知识、再学脏知识,还是先学好数据、再学脏数据,都可以视为是课程学习。其本质就是在阐述一件事情:“同样 1个T的训练数据,通过调整训练顺序得到的不同模型,能力是不同的。”这个观点基本已经被很多团队论证多次了,因此课程学习目前也可以认为是 pretrain 的标配。虽然 next_token 的训练方法,基本不存在模型学不会某条数据的情况。但从另外一个角度来分析,灾难性遗忘可能始终在发生,A + B 的学习顺序可能导致 A 知识遗忘了 30%,B + A 的学习顺序可能导致 B 知识遗忘了 20%,那后者忘得少自然能力更强啊。而且,如果 B 是一个简单的知识,那就代表 B 在训练语料中会出现非常多的次数,即使遗忘了后续也会被重新捡起来,困难知识在全部训练数据中出现的次数自然也会小很多。(全局训练语料中,蜀道难全文出现的次数一定比静夜思全文出现的次数少)。
数据流水线:首先要明确一个概念,pretrain 模型一定是动态加载数据的,读 1B 、训 1B、再读 1B 、再训 1B…… 原因很简单,你不知道你要训多少数据,即使知道你也没那么大的内存空间一下子读取好几 T 的数据。再明确一个概念,pretrain 阶段模型获取的是 token_id,而不是 token 本身,我们的 tokenization、concatenation 操作肯定是要提前做好的。当机器读取了一个新数据块之后,如果不能直接去训练,而是还要花时间去转 token,去 concat、去 pad,这简直是对 GPU 的一种侮辱。明确这两个概念之后,我们就应该知道,pretrain 的两个进程是独立的:“数据处理进程”和“模型训练进程”。前者要保证后者始终有最新的数据可用,除了 save_checkpoint 的时候,GPU 的空闲是一种极大的浪费。pretrain 阶段的数据是可以复用的,高质量数据训多遍对模型并没有坏处。因此,数据处理进程在生产 part-00000.jsonl 的同时,它也应该标记清楚每一条原始的 document 数据被使用了多少次,被标记次数多的数据,后续要降低它再被选中的概率。每个数据块不要太大,因为我们训练的时候,经常有烧卡、loss 炸、数据配错了,等不可控的天灾人祸,所以回退到上个数据块进行续训是一个很频繁的操作。较大的数据块自然会导致模型版本回退时损失的算力也较多。这里,我推荐每个数据块都以 B 为单位,正好是 1B、2B、4B 等。
二次预训练
- 主要数据格式:文本段
- 适用类型:通用支持或无法有效整理成QA知识的
# txt格式 Machine learning (ML) is a field devoted to understanding and building methods that let machines "learn" – that is, methods that leverage data to improve computer performance on some set of tasks. # json格式 { "completion": "下埔,是台湾宜兰县头城镇的一个传统地域名称,位于该镇南部。相较于今日行政区,其范围大致为包括顶埔里、下埔里。\n历史\n台湾清治末期,下埔地区为一街庄,称为「下埔庄」,隶属于头围堡。该庄东与三抱竹庄为邻,南与大塭庄为邻,西南边一小段与二围庄为邻,西边为中仑庄,北边为金面庄、新兴庄。\n1901年(日治明治三十四年)11月,废县厅改设二十厅,该庄隶属于宜兰厅,编入第四区。1905年(明治三十八年)7月,第四区改名「二围区」。1909年(明治四十二年)10月,合并二十厅为十二厅,该庄仍隶属于宜兰厅。1920年(大正九年),废十二厅改设五州二厅,该庄改制为「下埔」大字,隶属于台北州宜兰郡头围庄,大字下有「下埔」、「顶埔」小字名。\n战后头围庄改制为头围乡,隶属于台北县,大字亦改制为村。1946年9月,头围乡更名为头城乡。1948年再改制为头城镇,村改制为里。1950年10月,北、基、宜分治,头城镇改隶属于宜兰县。\n聚落\n本地区发展较早的聚落有顶埔、下埔等,在日治期初期的官方地图上已有记载。\n交通\n台铁宜兰线是台湾东北部铁路干线,大致以东北—西南走向经过下埔地区西北部。境内设有顶埔车站,属招呼站,只停靠区间车。由此可前往台铁沿线各地。\n省道台2线(头滨路三段)是台湾滨海公路系统之一,其中基隆至苏澳路段又称为「北部滨海公路」,大致以纵向转西北—东南走向经过本地区东北端。由该道路向北可前往头城市区、贡寮、瑞芳、基隆等地,向东南转南可前往壮围、五结、苏澳等地。\n省道台2庚线(青云路二段)是头城至二城的干线,大致以东北—西南走向经过本地区西北部边界地带。由该道路向东北可前往头城市区南侧并止于省道台2线路口,向西南可前往中仑北部、二城并止于省道台9线路口,亦可于该处连接国道5号头城交流道。\n县道191号是顶埔至宜兰的道路,其北侧端点位于本地区西北部边界上的省道台2庚线路口。由此向南南西出境后,可前往中仑、大塭、五股、茅埔、踏踏、抵美、五间、壮七并止于宜兰市区东侧的省道台7线路口。\n学校\n* 二城国小(大部分)", "source": "wikipedia.zh2307" }
阿里的data-juicer工具将每个数据处理步骤抽象为一个算子,用户可以方便的配置yaml文件实现自定义的数据处理流程。
继续预训练
继续预训练是在已经预训练的模型基础上,进一步在特定领域的数据上进行训练,以提高模型对该领域的理解和适应能力。数据集通常是未标注的,并且规模较大。
- 混合数据,如果想要领域的模型还具备一定的通用能力,即通用的能力不会退化(或者灾难性遗忘)这就需要在语言模型训练的时候混杂通用的数据。
- 要不要从零训。回顾人对知识的理解:小学中学都在学习通用领域的知识,然后大学阶段继续进一步学习特定领域的知识。所以在通用模型的基础上继续二次预训练注入领域知识是合理的。但是如果想通过二次预训练进行语言层面的迁移就会比较难,没有从零开始训练好。回顾人对语言的学习,如果刚“出生”时候就在学习一门语言,进行听说读写的训练,这就是母语了。会比长大以后再去学习一门外语要容易的多,效果也要好很多。所以基于llama做的中文适配 不如 纯中文训练的baichuan 在中文任务上效果好。
浅谈-领域模型训练 提到了很多pre-training 和post-training 的why/trick。 pretrain 最重要的几个东西:数据,学习率,优化器!
- 数据就不多说了,质量为王,记得去重!
- 学习率:模型的更新幅度,size越大的模型,特征空间越大、表达能力和学习能力越强,因此学习率也应该小一点(做个假设,模型 size 无限大,有无数的神经元,那么它完全可以启用没用到的神经元来学习新知识,这样就避免了遗忘旧知识这个现象的发生)。
- 优化器:Adam 的基础知识我就不谈了,这里只强调一点,模型的优化方向是“历史动量”和“当前数据 grad”共同决定的。也就是说,不管当前数据多 bad,优化器都会限制你做出太大幅度的更新,梯度裁剪/梯度正则类似。因此,基本可以认为我们的模型具有一定的抗噪能力。
目前,大家基本都默认使用如下三个步骤进行 pretrain:
- warmup:在训练过程中,将学习率慢慢提高。(可以这么理解,你的模型还没有积攒足够的动量去抗噪,太大的学习率容易造成不可逆的影响)
- linear / constant / cosine decay:维持稳定的学习率,或者缓慢衰减的学习率。
- Anneal:用小学习率去学高精数据,IFT数据,逻辑数据,去提高通用逻辑能力能力和打榜能力。
之前看见有种说法说洗数据是脏简历的工作,恕我不能认同。如果 infra 团队已经帮忙调通了 megatron 的训练代码,那么训练才是真的最没技术含量的工作,改几个参数,然后 bash train.sh,训练挂了就重启,这些工作谁做不来呢?反倒是洗数据时的灵光一现,往往能大大提升模型的效果。
大模型预训练中,退火通常指的是一种学习率调度策略。初始阶段使用较大的学习率以快速探索参数空间,随后逐渐减小,以细化模型的参数调整。
数据实验:同源小模型是大模型的实验场
大模型 VS 小模型scaling law 告诉我们:小模型的性能表现能用来预测大模型的性能表现。这也就是说,大部分情况下,我们是可以通过在同源小模型上做实验,去预测大模型的效果的。
在 pretrain / post_pretrain 阶段有很多需要做实验才能知道答案的问题。怎么样的数据配比最合理,课程学习中哪种学习顺序效果最好,数据的质量是否过关,数据的去重程度是否过关,先训4k、再扩到 32k 和直接训 32k 的效果差异,post_pretrain 的时候怎样调整学习率和数据分布来防止模型断崖式的能力遗忘?
直接启动大模型的成本实在是在太高昂了,可能训练两三周,loss 曲线才会表现出一点点差异。但我们完全可以在小模型上大胆的训,每天训 100B token,两天就能出一版实验结果。观察 tensorbord 的 loss 曲线,刷 benchmark 打榜,或是做 sft 看效果,总之小模型可以帮助我们快速地敲定 pretrain 阶段使用的数据配置。
在 alignment 阶段,我们也可以去借助小模型和 scaling law 来指导工作。我要强化模型的某个能力,准备了 N 条训练数据,能让模型达到多大的提升呢?可以看看这份数据在小模型上能有大提升,绘制一条曲线,去预估大模型的性能表现。说的再通俗一点,100B token 能让 0.5B 模型下降 0.2 loss,能让 72B 模型下降 0.1 loss, alignment 数据能让 0.5B 模型提高 x% 的 task 能力,那么大概率这份数据也只能让 72B 模型提升 0.5x % 的 task 能力。
具体的实验内容,可以根据自己的时间、人力来三个阶段走:
- 粗糙一点的工作:在小模型上起多个数据配比、数据顺序,训练 500B 左右的数据量,然后选择 loss 曲线最完美,或者 loss 下降最低的那个模型(这个阶段刷 benchmark 意义不大,模型小,训得少,大概率都是瞎蒙);
- 专业一点的工作:额外起多个 size 的小模型,跑出 loss 结果,结合 scaling_law 公式,去推算大模型最适合的数据配比、学习率、训练 token 量等参数;
- 创新一点的工作:像 llama 和 deepseek 技术报告里提到的一样,去绘制出 loss 到 benchmark 的 scaling_law,提前预知模型训多少 token 量能在某个 benchmark 达到什么样的能力。 这个地方展开说的话,能说巨多的东西,但不方便细说,感兴趣的同学还是多读读各公司的技术报告吧。scaling_law 只是放缓了,不是死了,在没有新的技术指引的情况下,scaling_law 你不信也得信,它毕竟是用某种规则在做训练,按照自己的直觉来做训练基本等于“random”。
大模型背后的无数小模型
一个优秀的大模型,无论是在训练阶段,还是线上部署阶段,其背后默默付出的小模型都数不胜数。
- 数据质量分类器:llama3 和 qwen2 都提到了,他们的 pretrain 训练数据是有得分的,然后通过阈值来找出最高质量的训练数据,开源 pretrain 数据集 fineweb 也提到了他们给数据打分的工作。Good data makes good model performance!李沐大佬在他的视频里说到,llama3 的数据打分器是 RoBERTa,这很合理,效果又好、推理又快的分类模型确实还要看 BERT 家族。
- 数据 domain 分类器:垂直领域模型的 post_pretrain 工作,往往需要非常精准的数据配比,domain 数据的数据质量也需要非常优质。这也就是说,我们需要一个分类器,去提取海量数据中的 domain 数据,这个分类器最好还能把低质量的 domain 数据也视为非 domain 数据,通常承担这个工作的模型也是 BERT 家族。
Tokenizer
大模型无法直接处理文本,需要转换为数字。转换过程可以简化为以下几步:输入文本序列,对序列进行切分成为Token序列,再构建词典将每个Token映射为整数型的index。通常情况下,Tokenizer有三种粒度:word/char/subword。llm使用的 Tokenizer 一般为subword。
扩词表容易把词表扩错,这和字典树的逻辑有关。简单来说,就是你加入“中华人民”这个新 token,并且引入相对应的 merge token 的逻辑,就可能导致“中华人民共和国”这个旧 token 永远不会被 encode 出来,那“中华人民共和国”这个 token 对应的知识也就丢失了。因此,提前准备好自己的 tokenizer 真的非常重要,这就是一个打地基的工作。你如果想着后期可以扩词表解决,那和房子歪了你再加一根柱子撑着有啥区别呢?llama + 扩中文词表 + conitnue pretrain 训出来过效果惊艳的中文模型吗?至于怎么训 tokenizer:找一个内存空间很大的 cpu 机器,再找一份很大的 common 数据集,然后利用 BPE / BBPE 算法去跑(ChatGPT会写),这里只提醒一些细节。
- 数字切分(虽然不知道 OpenAI 为什么不做了,但我们还是做吧,避免 9.9 > 9.11 的问题回答不正确);
- 控制压缩率,1 个 token 对应多少个汉字:压缩率太低,那就是字太多、词太少,很影响解码效率;压缩率太大,也就是词太多,又会影响模型的知识能力。通常,压缩率越低的模型,loss 也会低,大部份中文大模型的1 个 token 会映射成 1.5 个汉字左右;
- 手动移除脏 token,之前 GPT4o 的 token 词表泄漏, 就被发现有很多中文的色情、赌博 token; 如果提前知道自己的业务场景,那就应该补充业务场景对应的 token,增加业务场景文本的压缩率,比如医疗场景,就提前把阿莫西林、青霉素等作为一个 token;
- 词表的中、英覆盖率要足够大,至于其他小语种是否要加,则看业务需求;
- tokenizer 的 vocab_len 和模型的 embdding_size 之间,要有一千个左右的 buffer,后续的 alignment 环节,需要大量在 pretrain 阶段没见过的全新 token 来做训练。
“大模型视角”下的文本与我们“人类视角”并不一样。以Strawberry为例,其被拆分为【“str”, “aw”, “berry”】,自然也就不难理解为什么llm对于这个问题的回答是“两个r”了,毕竟对于它来说,这三者均是作为一个整体存在的,而不是从字母维度切分的。
模型结构
一个原则:能抄 llama 的结构就不要随便创新,就 rope + gqa + rms_norm + swiglu,少创新 = 少踩坑,创新的前提是大量鲁棒的实验。如果是 1B 左右很小的模型,那么 embedding 和 lm_head 还需要共享参数,目的是让 layer 的参数占全局参数的比例大一些,大一点的模型则没有这个必要。
pretrain 是个成本极高的工作,一切都要以稳健为主。假设你是 pretrain 负责人,你为了写论文,为了强行宣传自己的模型比 llama 更先进,做了一两周实验,在 0.5B 这种 size 发现新结构的 loss 下降更快。你大喜,也没去找两个数学系博士做做理论证明或推导,就去草草的去更改 llama 结构。等训练一个多月之后发现这个新结构有某个致命缺陷,几千万的算力资金已经投进去了。老板问你什么情况,你说当初在小模型上改结构没出问题啊!老板给你打了低绩效,自己心里又一百个不服气。
我觉着,国内 99% 的大模型技术岗,并不鼓励创新和试错,老板们只鼓励用最快的速度、最少的钱去追赶 OpenAI。除非你的老板真的支持你积极创新,否则不考虑试错成本盲目追求创新的人真的有点大病。
模型参数
- 模型的 size。我建议不要根据自己的场景需求来敲定模型 size(除非是 Math 等复杂任务必须是接近千亿参数的模型),小模型的极限在哪里目前仍然是个未知数,qwen2.5 也贴了一张图,在 benchmark 上能达到某个分数的模型 size,在持续变小。因为模型的 size 选小了,导致后续应用的时候业务场景扛不住,这种现象其实并不常见,alignment 基本都能救回来,无非就是 sft 的时候在业务能力上过拟合一些罢了。因此,选模型 size 主要看两个因素,训练算力和推理算力:
- 训练算力:手头有多少机器,能做多久 pretrain,有多少训练数据,使用的训练框架一天能吃多少 token,这些事情都是提前能确定的。假设要在 2 个月后训完模型,目标训 2T 数据,那么便可以计算出自己该训什么 size 的模型。尽量和大厂的模型 size 保持一致,不瞎创新就不会踩奇奇怪怪的坑,而且模型效果对比的时候也有说服力;
- 推理算力:实操过模型的同学都知道,用 AutoModelForCausalLM 加载 33B 模型基本是卡着一张 80G 显存的极限在推理,加载 72B 模型基本上是卡着两张 80G 显存的极限在推理,稍微多一点 seq_len,立刻 OOM(暂不讨论量化等因素)。换句话也就是说,假设你有个 40B 的模型,他和 72B 模型效果一样,那又怎样呢?他还是得用两张卡推理,在部署成本上和 72B 模型还是一个量级的。所以,敲定模型 size 的时候,我们需要知道自己的推理机器是什么,不要出现 1 张推理卡刚好装不下模型的尴尬现象。适当给模型增大 1B、减小 1B 参数是可以的,这也能解释了为什么不是所有公司都用 70B,而是 65B、70B、72B、75B 等 size 都有的现象。
- 模型的超参数 size。目前学界都有一个共识:一个好模型是“身材匀称”的。也就是说标准的 llama 结构应该是横向和纵向呈某种比例的,所以在增大模型 size 的时候,layer_num 和 hidden_size 要一起递增。具体如何递增,llama 论文和李牧老师视频里都有介绍,这里不在赘述了。我的观点依然是普通人没必要研究这个,超参数 size 的量级就和 llama 保持一致即可,少创新就等于少犯错。但具体到该使用什么值的参数,还是有说法的:尽量能被 2 / 4 / 8 / 64 / 128 等数整除。不是有什么理论证明,而是训练框架要求你这样。
- layer_num:有尽量多的质因数,它与 pipeline_parallel 有关。pipeline_parallel 的要求是:assert layer_num % pipeline_size == 0。如果你的 layer_num = 30,那它就不能支持 pipeline_size = 4。当然,你可以修改训练代码,让 pipeline_parallel 的时候,不同的卡放置不同数量的 layer,但这不就又增加开发成本了;
- num_head:8 的整数倍,它与 tensor_parallel 有关。tensor_parallel 的极限一般是 8,因为大于 8 就引入了机间通讯,训练效率就低了。tensor_parallel 的效率很高,能开大就尽量开大一点;
- hidden_states:128 的整数倍,目前没有理由,保不齐以后有;
- vocab_size:128 的整数倍,目前没有理由,保不齐以后有。
- 另外一个比较重要的超参数是 seq_len 的选取:无论你的业务场景需不需要长文本,都不要一开始就使用 32K / 200K 这种夸张的数据 seq_len,算力根本承受不起,attention 的 seq_len^2 的计算量实在可怕。rope 的 NTK 外推方法已经是各大厂标配的方案:4K/8K + rope 小 base + 90% 数据量 –> 32K/64K + rope 大 base + 10% 数据量。
GPT-2养成记
Training and Fine-Tuning GPT-2 and GPT-3 Models Using Hugging Face Transformers and OpenAI API 非常经典,入门必读。
- it does not implement neural networks from scratch(从头开始) but relies on lower-level frameworks PyTorch, TensorFlow, and FLAX.
- it heavily uses Hugging Face Hub, another Hugging Face project, a hub for downloadable neural networks for various frameworks.
- Model is a valid PyTorch model with some additional restrictions and naming conventions introduced by the transformers framework.
- Neural networks are not able to work with raw text; they only understand numbers. We need a tokenizer to convert a text string into a list of numbers. But first, it breaks the string up into individual tokens, which most often means “words”, although some models can use word parts or even individual characters. Tokenization is a classical natural language processing task. Once the text is broken into tokens, each token is replaced by an integer number called encoding from a fixed dictionary. Note that a tokenizer, and especially its dictionary, is model-dependent: you cannot use Bert tokenizer with GPT-2, at least not unless you train the model from scratch. Some models, especially of the Bert family, like to use special tokens, such as
[PAD],[CLS],[SEP], etc. GPT-2, in contrast, uses them very sparingly.
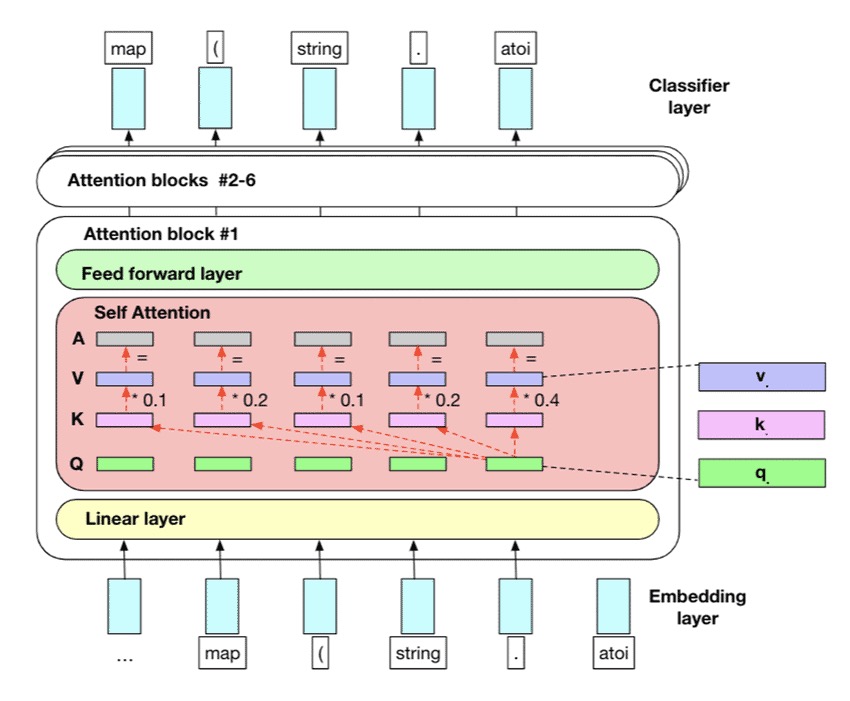
different GPT versions differ pretty much only in size, minor details, and the dataset+training regime. If you understand how GPT-2 or even GPT-1 works, you can, to a large extent, understand GPT-4 also. PS: 不同的gpt从模型结构上差别不大。
以GPT-2 为例
- The transformer itself works with a D-dimensional vector at every position, for GPT-2 D=768.
- V=50257 is the GPT-2 dictionary size.
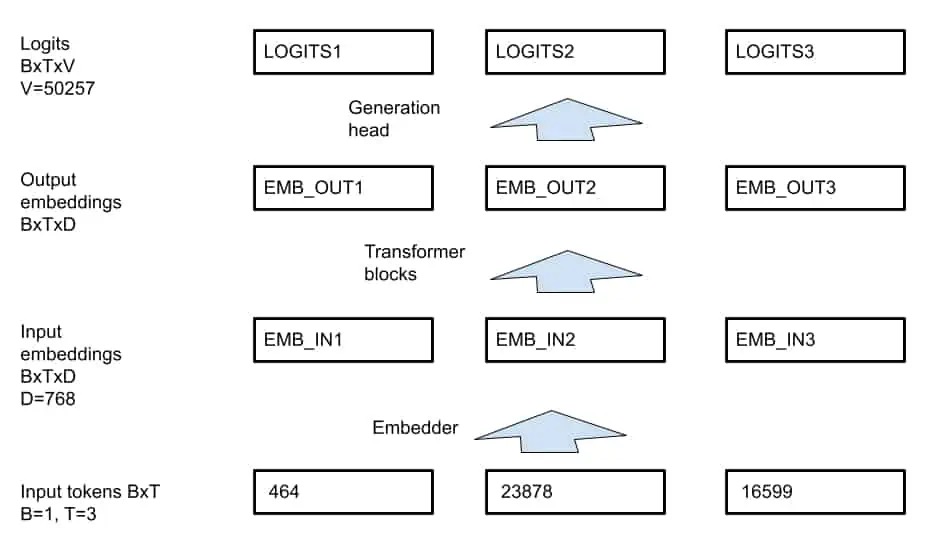
GPT-2 model使用
config = transformers.GPT2Config.from_pretrained(MODEL_NAME)
config.do_sample = config.task_specific_params['text-generation']['do_sample']
config.max_length = config.task_specific_params['text-generation']['max_length']
# print(config)
model = transformers.GPT2LMHeadModel.from_pretrained(MODEL_NAME, config=config)
# Tokenizer
tokenizer = transformers.AutoTokenizer.from_pretrained(MODEL_NAME)
# Tokenize the input
enc = tokenizer(['The elf queen'], return_tensors='pt')
print('enc =', enc)
print(tokenizer.batch_decode(enc['input_ids']))
input_ids = enc['input_ids']
attention_mask = torch.ones(input_ids.shape, dtype=torch.int64) # 训练时不是自递归的,所以用到了mask
# predicts the next token at each position. 也就是 input_ids = [v1,v2,v3] 输出为 [v20,v30,v4]]。 v20 是根据v1 生成的下一个token,大概率跟v2 不一样,v4 是根据v1,v2,v3 生成的。
out = model(input_ids=input_ids, attention_mask=attention_mask)
logits = out['logits']
# -1 在python list 里表示最后一个元素。
new_id = logits[:, -1, :].argmax(dim=1)
print(new_id)
print(tokenizer.batch_decode(new_id))
GPT2 源码解析 建议细读
input_ids = enc['input_ids']
for i in range(20):
attention_mask = torch.ones(input_ids.shape, dtype=torch.int64)
logits = model(input_ids=input_ids,attention_mask=attention_mask)['logits']
new_id = logits[:, -1, :].argmax(dim=1) # Generate new ID
input_ids = torch.cat([input_ids, new_id.unsqueeze(0)], dim=1) # input_ids 加入新生成的字符
| i | input_ids | decoded text | next token |
|---|---|---|---|
| 0 | [464,23878,16599] | the elf queen | 11 |
| 1 | [464,23878,16599,11] | the elf queen, | 508 |
| 2 | [464,23878,16599,11,508] | the elf queen,who | 550 |
为什么可以一次性构建:
- Transformer的并行架构:可以同时处理序列的所有位置
- 因果掩码(Causal Mask):确保每个位置只看到前面的信息,保持因果性
- 高效训练:一次前向传播完成所有时间步的学习
- 数学等价:一次性训练与传统逐位训练数学上等价
在实际应用中,我们通常面对的是很长的文本,比如一篇文章、一本书。这时候就不能用”向右位移”的方法处理整个文本了,为此,我们引入了滑动窗口技术。滑动窗口包含两个关键参数:
- 窗口长度:每次能看到多少个词
- 窗口位移:每次滑动多少个词
损失函数:衡量“猜对”的程度。在训练过程中,我们需要一个标准来衡量AI“猜词”的水平。这就是损失函数的作用。 计算原理:
- 在每个位置,AI会给出对下一个词的“猜测”(一个概率分布)
- 我们将这个猜测与真实的词比较
- 计算它们之间的差异(使用交叉熵损失)
比如“机器, 学习, 是, 人工, 智能, 的, 重要, 分支”,当AI看到“机器学习是”时:
- 它可能认为下一个是“人工智能”的概率是0.7
- 是“深度学习”的概率是0.2
- 是“一个”的概率是0.1
如果真实的下一个词是“人工智能”,那么损失就是:
- 理想情况:AI应该100%确定是“人工智能”
- 实际情况:AI只有70%确定
- 损失值 $ = -\log(0.7) \approx 0.36 $
在自回归模型中,最核心的要求是:生成第t个词时,只能看到前面t-1个词,不能看到未来的词。这就是后续掩码(Causal Mask,也叫因果掩码)要确保的事情。后续掩码是一个下三角矩阵,掩码位置不参与梯度计算。在正向传播中,这些值被设为常数-1e9,经过softmax后,这些位置的权重约等为0,对输出没有任何贡献。在反向传播中,这些常数位置的梯度为0,位置2的梯度只能流向位置0、1、2的参数。
微调GPT-2 model
GPT models are trained in an unsupervised way on a large amount of text (or text corpus). The corpus is broken into sequences, usually of uniform size (e.g., 1024 tokens each). PS: 预训练素材通常被切成特定长度的句子。The model is trained to predict the next token (word) at each step of the sequence. For example (here, we write words instead of integer encodings for clarity) :
| position | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 |
|---|---|---|---|---|---|---|---|---|---|
| input_ids | The | elf | queen | was | wearing | a | cloak | . | [END] |
| labels | elf | queen | was | wearing | a | cloak | . | [END] | [-1] |
The labels are identical to input_ids, but shifted to one position to the left. Note that for GPT-2 in Hugging Face transformers this shift happens automatically when the loss is calculated, so from the user perspective, the tensor labels should be identical to input_ids. PS:常规深度模型的训练输入是 feature1,feature2,...,label,LLM也是,不过label 有时是由input_id得到的。
There are two ways to train Hugging Face transformers models: with the Trainer class or with a standard PyTorch training loop. We start with Trainer. PS: 下面代码基于GPT-2 已有的参数微调GPT-2,感觉模型微调 跟model = load_checkpoint(xx) 断点重训没啥区别,侧重点在于讲Transformers库原理。
class MyDset(torch.utils.data.Dataset):
"""A custom dataset that serves 1024-token blocks as input_ids == labels"""
def __init__(self, data: list[list[int]]):
self.data = []
for d in data:
input_ids = torch.tensor(d, dtype=torch.int64)
attention_mask = torch.ones(len(d), dtype=torch.int64)
self.data.append({'input_ids': input_ids, 'attention_mask': attention_mask, 'labels': input_ids})
def __len__(self):
return len(self.data)
def __getitem__(self, idx: int):
return self.data[idx]
def break_text_to_pieces(text_path: str, tokenizer: transformers.PreTrainedTokenizer, block_len: int = 512) -> list[str]:
"""Read a file and convert it to tokenized blocks, edding <|endoftext|> to each block"""
with open(text_path) as f:
text = f.read()
chunk_len0 = block_len - 1 # Leave space for a TOKEN_ENDOFTEXT
tokens = tokenizer.encode(text) # 原文本直接弄,够粗暴
blocks = []
pos = 0
while pos < len(tokens):
chunk = tokens[pos: pos + chunk_len0]
chunk.append(TOKEN_ENDOFTEXT)
blocks.append(chunk)
pos += chunk_len0
if len(blocks[-1]) < block_len:
del blocks[-1]
return blocks
def train_val_split(data: list[str], ratio: float):
n = len(data)
assert n >= 2
n_val = max(1, int(n * ratio))
return data[n_val:], data[:n_val]
def prepare_dsets(text_path: str, tokenizer: transformers.PreTrainedTokenizer, block_len: int):
"""Read the text, prepare the datasets """
data = break_text_to_pieces(text_path, tokenizer, block_len)
data_train, data_val = train_val_split(data, 0.2)
return MyDset(data_train), MyDset(data_val)
# Load model and tokenizer
model = transformers.GPT2LMHeadModel.from_pretrained(MODEL_NAME)
tokenizer = transformers.AutoTokenizer.from_pretrained(MODEL_NAME)
training_args = transformers.TrainingArguments(output_dir="idiot_save/", learning_rate=1e-3,...)
# 传给trainer 的必须是预处理好的dataset(包含input_ids 等column)
trainer = transformers.Trainer(model=model,args=training_args,train_dataset=dset_train,eval_dataset=dset_val)
trainer.train()
# Save the model if needed
model.save_pretrained('./trained_model/')
tokenizer.save_pretrained('./trained_model/')
# Now our model is trained, try the generation
text = 'Natural language understanding comprises a wide range of diverse tasks'
batch = tokenizer([text], return_tensors='pt')
for k, v in batch.items():
batch[k] = v.to(DEVICE)
out = model.generate(input_ids=batch['input_ids'], attention_mask=batch['attention_mask'], max_length=20)
print('GENERATION=', tokenizer.batch_decode(out.cpu()))
一把情况下 you are not allowed to train a model from scratch. Neither are you allowed to fine-tune on a text corpus or fine-tune with additional heads. The only type of fine-tuning allowed is fine-tuning on prompt+completion pairs, represented in JSONL format, for example:
{"prompt":"banana is ","completion":"yellow"}
{"prompt":"orange is ","completion":"orange"}
{"prompt":"sky is ","completion":"blue"}
How exactly is GPT-3 trained on such examples? We are not exactly sure (OpenAI is very secretive), but perhaps the two sequences of tokens are concatenated together, then GPT-3 is trained on such examples, but the loss is only calculated in the “completion” part. PS: 终于知道为何要分成两段,而不是喂一个文本就算了。labels 中prompt部分的位置都置为-100,-100表示在计算loss的时候会被忽略,这个由任务性质决定。
留下评论