编程语言那些事儿
简介
编程语言本就是人类控制计算机的指令,语法规则等方面自然大同小异。
- 一般来说一门语言,它的本质就是提供一些 API 和运行时,让你可以在之上做一些事情,比如让你操作GPU。另外一个,它是给你提供一种抽象机制,它可以让你做模块化的编程。像最早的汇编,它没有 function,所以它基本上没有任何抽象机制,你很难做大规模的模块化编程。
- 如果你去学校学一个语言的话,可能你应该去学 Java ,为什么呢?因为 Java 它的设计非常 formal 、正规,非常的 canonical。 PHP 的很多的设计,有一些随意性,有一些 on the fly ,比如我今天在这写的时候,就这样定义,结果一下子就错了好多年。理解语言一定去理解和了解它的来龙去脉,Facebook 没有那么在意代码一定要写得非常的完美,为什么呢?是因为当时大家也不知道网站应该建成什么样子,也许第二天代码就被删掉重新写了,所以你去过度的 polish 打磨代码,有的时候反而还不如快速写完,叫所谓快速迭代的过程。所以 PHP 就跟 Facebook (当时的)研发的模式恰好很匹配,大家也没有那么强的抱怨。
- go是第一个主流语言把 structuraltyping 用在工业语言当中。 为什么 Google 要去做 Golang 呢?是因为我们在这个过去的五到十年里面,就发现了实际上绝大多数的公司在写什么呢?在写分布式计算。特别常见的情况是我调你、你调它,它调它。团队大了之后拆分 engineering task 拆分完了之后,我就要 RPC 调用对吧?很多的 application 就变成了所谓的 IO intensive 的这种形式,20 年前的话,很多的软件都是在做大量的计算对吧,没有太多的 RPC 因为都在一个机器上进行。 IO多了,问题就来了,你的线程模型是什么?一个io一个线程不行,最后就发现了一定要用比如说 epoll 这种模型,要搞 user thread ,让其他的人都能够很快的去跳到这个模型上,所以他才把 goroutine (协程)这个概念变成了 first classcitizen ,所以其实人家的本意是在这里。
- 程序语言就跟这个人生一样,只有选择没有对错。go没有 exception ,我写 C++ 的话,我觉得 exception 还是很有用的,让很多的那个代码变得很整洁,Go 的话就不行,一定要 return 一个 error 。这样选择的目的是因为 exception 是一个性能损耗点,那我要快,为了极致的性能,对不起你们所有写 Go 语言的人,你们自己累一点。你可以不同意这个取舍。但是没办法,这个语言是人家发明的,人家帮你做了一个决定
- 从 industrial(工业)的角度去思考编程语言,有两件事情,目前它做的不是特别的好,或者说还做不到,或者说不在语言的范畴之内
- 一个就是数据库,一个语言在访问数据库的时候,很多的有所谓的 data binding ,这个 problem 要解决。有 serialization(序列化)、deserialization(反序列化),有好多类似这样这方面的问题,它并没有把数据库、database 或者 data 的很多东西囊括在语言里面。为什么这两个 camp 的人不能在一起,为什么不把两个东西搞在一起?
- 分布式计算。目前还没有一个语言说它能够凌驾在众多的机器之上。我去写一个程序,这个程序咔嚓一下,在几千几万个机器上跑。那当然我们有类似的系统,比如说 map-reduce,但是它没有上升到语言这个层面。它没有说我今天字节只需要一个语言就好了,你们都不要去这写这个写那的什么 server 一个 client 一个,就一个语言,我写一个程序下来,然后一下 deploy 到所有不同的机器上跑。这个问题是有意义的。为什么呢?因为我们微服务实际上是一个很大的调用链。一个服务调其他的,其他服务又调更多的服务,它是一个树状的 call tree,它是有 dependency 的,但是还没有一个语言能够把完整的把整个的 call tree 给描述出来,如果真的可以描述出来的话,那 compiler (编译器)就可以去优化这棵树。我怎么样去优化让整个的调用是最 efficient 的,可是语言并没有回答这个问题,现在情况是,留给大家自己去做一些调度也好,或者自己去做一些优化也好,或者用 WebAssembly 让这个不同的微服务之间有一些 inter-operation。
几个问题
比如我们在学习一门新的语言的时候,可以考虑以下几个问题:
- 这门语言是强类型的吗?编译器是否会对语言类型进行严格检查, 或者说 是否只能同类型变量进行操作。
- 这门语言是动态类型吗?类型是编译期还是运行期检查的,变量的类型是否可以更改。
- 比如 Python 和 JavaScript,因为在编译期间缺少类型提示,编译器无法为对象安排合理的内存布局,所以它们的对象布局相比 Java/C++ 等静态类型语言会更加复杂,同时这也会带来性能的下降。
- 它支持多少种内建类型呢?
- 它支持结构体吗?
- 它支持字典 (Recorder) 吗?
- 它支持泛型吗? 现代编程语言需要泛型
类型系统
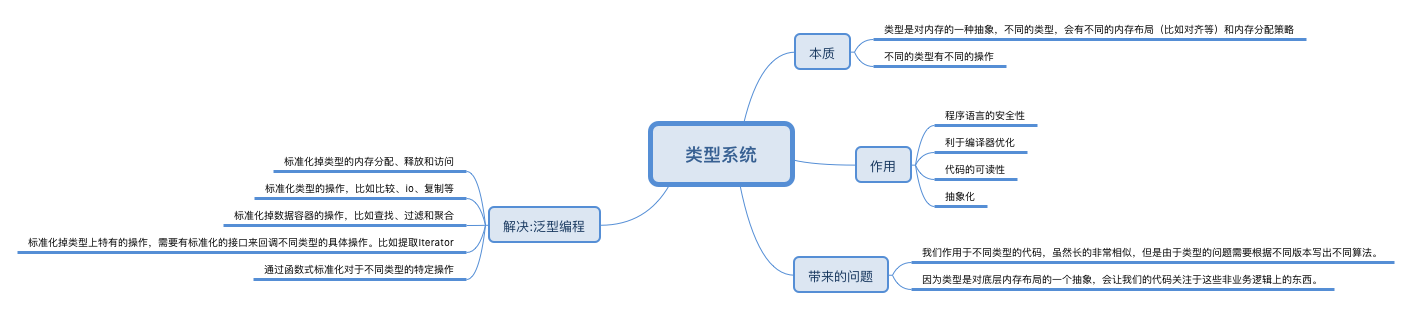
类型是天然的,把类型以及对类型的操作封装在一起也是合理的。数据结构加上操作这些数据结构的函数,本来就是程序运行的客观规律。
为什么要有类型系统
类型是对数据做的一种分类,定义了能够对数据执行的操作、数据的意义,以及允许数据接受的值的集合。编译器和运行时会检查类型,以确保数据的完整性,实施访问限制,以及按照开发人员的意图来解释数据。类型系统是一组规则,为编程语言的元素分配和实施类型。这些元素可以是变量、函数和其他高级结构。类型系统通过两种方式分配类型:程序员在代码中指定类型,或者类型系统根据上下文,隐式推断出某个元素的类型。类型系统允许在类型之间进行某些转换,而阻止其他类型的转换。
- “系统”一词由来已久,在古希腊是指复杂事物的总体。到近代,一些科学家和哲学家常用系统一词来表示复杂的具有一定结构的整体。在宏观世界和微观世界,从基本粒子到宇宙,从细胞到人类社会,从动植物到社会组织,无一不是系统的存在方式。
- 控制论告诉我们,负反馈就是系统稳定的机制,一个组织系统之所以能够受到干扰后能迅速排除偏差恢复恒定的能力,关键在于存在着“负反馈调节”机制:系统必须有一种装置,来测量受干扰的变量和维持有机体生存所必需的恒值之间的差别。例如,一个实时系统复杂性任务的约束,包括时间约束、资源约束、执行顺序约束和性能约束。
- 类型系统,就是复杂软件系统的“负反馈调节器”。通过一套类型规范,加上编译监控和测试机制,来实现软件系统的数据抽象和运行时数据处理的安全。
在低层的硬件和机器代码级别,程序逻辑(代码)及其操作的数据是用位来表示的。在这个级别,代码和数据没有区别,所以当系统误将代码当成数据,或者将数据当成代码时,就很容易发生错误。这些错误可能导致系统崩溃,也可能导致严重的安全漏洞,攻击者利用这些漏洞,让系统把他们的输入数据作为代码执行。类型为数据赋予了意义。类型还限制了一个变量可以接受的有效值的集合。
类型系统层面上的动态性
根据类型检查发生的时间,我们可以把计算机语言分为两类:
- 静态类型语言,全部或者几乎全部的类型检查是在编译期进行的。因为编译期做了类型检查,运行期不用再检查类型,性能更高。像 C、Java 和 Go 语言,在编译时就对类型做很多处理,包括检查类型是否匹配,以及进行缺省的类型转换
- 动态类型语言,类型绑定到值,类型的检查是在运行期进行的。动态类型不会在编译时施加任何类型约束。日常交流中有时会将动态类型叫作“鸭子类型”(duck typing),代码可按照需要自由使用一个变量,运行时将对变量应用类型。
泛型编程
对于List[int],其中List就是泛型(Generic Type)。List[int]合一块儿叫具体类型(Concrete Type)。用List这个泛型,生成List[int]这个具体类型的过程叫做参数化 (Parameterization)
来自陈皓《左耳听风》笔记
编程语言的本质是帮助程序猿屏蔽底层机器代码,使得我们可以更为关注业务逻辑代码。
programming paradigm,范即模范之意,是一类典型的编程风格,不同的风格解决的都是同一个问题:如何写出更为通用、更具可重用性的代码或模块。
作者提供了一个视角,从“程序=算法 + 数据结构”出发,从语言对泛型的支持来看待语言的演化:泛型编程的支持。逻辑重用 ==> 算法复用性高 ==> 数据结构标准化 ==> 类型泛型。简单说就是让数据结构 迁就算法。
- 对于程序=算法 + 数据结构,C语言有以下问题:一个通用的算法,需要对所处理的数据的数据类型进行适配。
- C语言的伟大之处在于 程序猿可以在高级语言的特性之上还能简单的做任何底层上的微观控制。但在编程这个世界中,更多的编程工作是解决业务上的问题,而不是计算机的问题。
- C++的作者有一本书《C++语言的设计和演化》这本书系统介绍了C++诞生的背景和初衷: 早先很多是对C的强化和净化 ==> 用引用解决指针问题;用class来解决对象的创建、赋值、销毁等问题(C指针干这些都要手动)。泛型编程是C++的重点
-
理想情况下,算法应是和数据结构以及类型无关的,各种特殊的数据类型理应做好自己分内的工作。算法只关心一个标准的实现。而对于泛型的抽象,我们需要回答的问题是:如果我们的数据类型符合通用算法,那么对数据类型的最小需求是什么?
- 减少自定义数据类型 与 内建数据类型的差异。比如漏出构建、析构、克隆等函数 的hook交由语言自动执行,类似int自动帮你初始化为0.
- 减少自定义数据类型之间的差异。List、Set 抽象为Iterator,而调用Iterator.next 可以按照实际的数据类型反应。从泛型的角度理解Iterator 的价值
- 使用动态类型语言写sum(x,y)貌似没有泛型的问题,但在你要明确类型时又很难受,比如将一个不知道什么类型的x转为一个数字。
一个良好的泛型编程需要解决 几个问题
- 算法的泛型,将sum 和max、min等都抽象为 reduce(把数组聚合为一个值),也就是将for 循环之内的 逻辑/算法 作为参数传入。
- 类型的泛型,比如sum int 改为sum T。
- 数据结构的泛型,比如找到一种公共的方式来描述List、Set、Map 等 ==> Iterator
泛型编程于1985年在论文 generic programming 中被这样定义:Generic programming centers around the idea of abstracting from concrete, efficient algorithms to obtain generic algorithms that can be combined with different data representations to produce a wide variety of useful software. 屏蔽掉数据和操作数据的细节,让算法更为通用,让编程者更多的关注算法的结构,而不是在算法那中处理不同的数据类型。
泛型会让你的 Go 代码运行变慢 提到了泛型的两类基本实现。
编程语言层面上的动态性
动态语言之三:语言的动态性 要点如下
-
不同的语言具有不同程度的动态特性,现代大多数语言都是介于二者之间的折中。下面是两个极端:
- Fortran语言不支持堆栈,所有的变量和子程序都是在编译时分配好内存的,不能进行动态内存分配,因而不能进行函数递归调用。
- Perl、Python和Ruby语言可以在运行时修改类的结构或定义,变量的类型可以按需改变,Lisp语言甚至可以在运行时动态地改变自身的代码。
- 动态语言有多种定义,本文采用:动态语言是指能够在运行时改变程序结构和变量类型的语言。
- 动态语言的特征是可以在运行时,为对象甚至是类添加新的属性和方法,而静态语言不能在运行期间做这样的修改。
- 动态语言的代表是 Python 和 JavaScript,静态语言的代表是 C++。Java 本质上是一门静态语言,但它又提供了反射(reflection)的能力为动态性开了一个小口子。
- 从实现的层面讲,静态语言往往在编译时就能确定各个属性的偏移值,所以编译器能确定某一种类型的对象,它的大小是多少。这就方便了在分配和运行时快速定位对象属性。而动态语言往往会将对象组织成一个字典结构。
- 程序中定义的操作一般需要特定类型的参数作为操作的输入,操作只有在接收到类型正确的参数时才能正确无误的执行(包括操作内存)。所以无论哪种语言,都逃避不了一个特定的类型系统
- 动态类型语言在每个数据对象中保存一个类型标签表明该数据对象的类型,在运行时进行动态类型检查。比如在表达式C=A+B中,A和B的类型在程序运行时确定,也可以在运行时改变,所以每次执行 + 操作时都要根据类型标签对A和B的类型进行检查
-
动态类型检查的主要优点在于程序设计的灵活性,不需要声明语句,一个变量名绑定的数据对象的类型可以在程序执行时按需改变,使程序员从数据类型摆脱出来。运行时进行的类型检查也存在几点重大不足:
- 程序难以调试。只在程序运行到某一条操作时才对其进行类型检查,软件测试时是不能遍历程序中所有的执行路径,这样没有被执行的路径仍有可能存在bugs
- 保存大量的类型信息。运行时需要相当大的额外存储空间
- 执行效率低,动态类型检查要靠软件模拟实现,主要是在运行时完成的
50 万行代码没有类型系统是不可维护的。
留下评论