大模型推理
简介
影响因素
算法优化
每个周期的generate函数都必须处理逐渐增多的词元,因为每个周期我们都要在上下文中添加新词元。这意味着要从一个由10个词元组成的提示生成100个词元,你需要在模型上运行的不止109个词元,而是10 + 11 + 12 + 13 + … + 109 = 5950个词元!(初始提示可以并行处理,这也是为什么在推理API中提示词元通常更便宜的原因之一。)同时也意味着,随着生成的进行,模型会越来越慢,因为每个连续的词元生成都有一个越来越长的前缀。
系统工程优化
分类方式1
- 低比特量化,通过是否需要重新训练分为QAT和PTQ,围绕QAT和PTQ也衍生了很多经典算法
- 并行计算,大多数模型并行都是应用在分布式训练场景,不过像PaLM inference继承了TP的思想是应用在大规模Transformer推理场景的。
- 内存管理,随着KV Cache优化变成一个事实标准,对存储的使用需求越来越大。这里主要提三个系统优化,vLLM使用的pagedAttention优化、SpecInfer提出的tree attention优化和LightLLM采用的更精细的标记级内存管理机制。但这些优化在提高吞吐量的同时会牺牲一部分请求响应延时。
- 请求调度,早期的LLM 推理框架只支持request-level的调度,比如像fastertransformer这种,ORCA率先提出了iteration-level的调度系统,结合selective-batching输出了更高效的调度能力。后来continuous batching逐步应用到vLLM、TensorRT-LLM(flight batching)和RayLLM上,也成为了事实标准。
- 内核优化,即内核融合、定制attention、采样优化(采样算法的选择会极大地影响LLM的生成质量)、变长序列优化和自动编译优化。
整理一下最近学习进度分类方式2
- 单request单次推理中的算子级优化问题,如算子融合、算子加速、FlashAttention、FlashDecoder
- 多request多用户推理服务系统中的优化问题,目前来说比较有代表性的工作就是continuing batch等工作。
- 当模型大到一块卡甚至一台机器放不下的情况,包括模型放得下但是多请求服务系统中形成的规模放不下的情况,都会涉及到分布式系统和分布并行方法来帮忙解决其中的瓶颈。包括并行机制、分布调度、通信优化、容错优化等等方面。
- 改进推理算法类的工作:比如在推理时不再是一个词一个词蹦,可能一次多出来几个词作为候选的投机推理方法,比较有名如SpecInfer等工作;还有改变自回归机制的方法。不过这些方法大体上都需要训练配合。还有就是新的循环结构,如RWKV等。
- 模型小型化的工作:这里又会细分为小模型设计、模型稀疏化、模型剪枝、量化推理、蒸馏等方面。
- 专用硬件加速器:从我的感受看现在GPU上因为高速缓存的访存速度非常快,所以目前的优化瓶颈都在如何把计算算力利用好,同时相比Attention部分,MLP已经在生态中被优化了好多年了,Attention部分的优化,包括KVCache结合部分,才是真正的瓶颈。同时新的硬件研发也会结合这块的技术特点。
- 高效有效的解码算法和探索替代基础架构:现在主要的问题还是除了decoder这个结构之外其他的结构算法效果都不太好,但是其实不排除啥时候出现新的结构,怕就是突然的变化让现在基于decoder结构优化的方法存在一定的时效。
当前的生成式大模型的推理可以分为两个阶段:Context 阶段和 Generation 阶段。Context 阶段是批量计算输入的 Prompt,属于计算密集型。Generation 阶段是逐字生成下一个 Token,属于访存密集型,虽然每一轮 Generation 的计算量小于 Context 阶段,但是访存量相当。大模型推理主要面临三个挑战:输入输出变长、计算规模大、显存占用大,针对这些挑战当前有多种优化手段进行优化:
- 服务层面,打破之前的 Batch 只能同时返回结果的限制,允许部分请求结束后插入新的请求。
- 计算方面,也有一些算子融合,KV Cache 这样的无损加速方案,也有模型量化加速方案,比如 Smooth Quant 量化方案将激活和权重的分布进行平衡来降低模型精度损失。
- 显存方面,Generation 计算的访存密集型可以通过 Flash Attention 优化访存,也可以通过 Paged Attention 方法优化推理过程显存占用从而支持更大的吞吐。Paged Attention基本构建了一个类似于CPU内存管理的内存管理系统,以减少内存碎片并充分利用内存吞吐量
- 对于较短的文本输入 (词元数小于 1024),推理的内存需求很大程度上取决于模型权重的大小。
语言大模型推理性能工程:最佳实践 我们应该如何准确衡量模型的推理速度呢?首个词元生成时间(Time To First Token,简称TTFT);单个输出词元的生成时间;时延:模型为用户生成完整响应所需的总时间;吞吐量:推理服务器在所有用户和请求中每秒可生成的输出词元数。 以下通用技术可用于优化语言大模型的推理:
- 算子融合:将多个串行执行的算子合并为复合算子,通过减少中间数据传输和Kernel启动次数来提升性能。
- 合并后的算子无需将中间结果写入显存,(避免了反复从HBM中读写数据),算子之间的数据在 寄存器 / shared memory 里传递(数据留在寄存器/共享内存)。
- 降低Kernel调用次数:每个算子对应一次Kernel启动,合并后可显著减少启动开销。
- 提升计算密度:复合算子通过扩大并行粒度更充分地利用计算资源(让 warp、SM 更“忙碌”)。
- 量化。浮点数有不同的大小,这对性能很重要。对于常规软件(例如 JavaScript 数字和 Python 浮点数),我们大多使用64位(双精度)IEEE 754 浮点数。然而,大多数机器学习一直以来都使用的是32位(单精度)IEEE 754。一个70 亿参数的模型在fp64下需要占用56GB,而在fp32下只需28GB。在训练和推理期间,大量的时间都用来将数据从内存搬运到缓存和寄存器,所以搬运的数据越少越好。截至2023年,GPU不支持小于fp16的数据格式,除了int8(8 位整数)。如何准确且可解释地评估大模型量化效果?
- 对激活值和权重进行压缩,以使用更少的比特数。一般来说,所有量化技术的工作原理如下: $Y=XW$ 变成 $Y=X dequantize(W); quantize(W)$,当输入向量走过模型计算图时,所有权重矩阵都会依次执行反量化和重量化操作。因此,使用权重量化时,推理时间通常 不会 减少,反而会增加。
- 压缩:稀疏性或蒸馏。所谓“蒸馏”,就是说在预训练阶段小模型作为Student,大模型作为Teacher,Teacher告诉Student更多信息来提升小模型效果。原先小模型预训练目标是根据上文context信息正确预测Next Token,而蒸馏则改成Teacher把自己做相同上下文做Next Token预测的时候,把Token词典里每个Token的生成概率都输出来,形成Next Token的概率分布,这就是Teacher交给Student的额外附加信息,小模型从原先的预测Next Token改为预测Next Token的概率分布,要求和Teacher输出的分布尽量一致,这样就学到了Teacher的内部信息。PS:LLM预训练预测Next Token,其实是人类作为Teacher,LLM作为student。所以LLM本身就是对人类知识的蒸馏。
- 并行化:在多个设备间进行张量并行,或者针对较大的模型进行流水线并行。
在LLM中,计算主要由矩阵乘法计算主导;这些维度较小的计算在大多数硬件上通常受内存带宽的限制。在以自回归方式生成词元时,激活矩阵的维度之一(由批大小和序列中的词元数定义)在小型批大小上较小。因此,速度由我们将模型参数从GPU内存加载到本地缓存/寄存器中的速度决定,而不是由计算加载数据的速度决定。相比峰值计算性能,推理硬件中可用和可实现的内存带宽能够更好地预测词元的生成速度。
对于服务成本来说,推理硬件的利用率非常重要。由于GPU的价格十分高昂,因此我们需要尽可能地让它们完成更多工作。共享推理服务通过将多个用户的工作负载组合在一起,填补各自的差距,并将重叠的请求进行批处理,以降低成本。对于LLaMA2-70B等大型模型,只有在较大的批大小下才能实现更好的性价比。拥有能够以较大批大小运行的推理服务系统对于成本效率至关重要。然而,较大的批大小意味着较大的KV缓存,这反过来又增加了部署模型所需的GPU数量。我们需要在这两者之间博弈,进行取舍,共享服务运营商需要权衡成本,优化系统。
KV Cache/PagedAttention/FlashAttention 本质是基于GPU计算和内存架构,对注意力计算过程的优化
\(Attention(Q,K,V) = softmax(\frac{QK^T}{\sqrt{d_k}})V\) \(Q = W^Q * X\) \(K = W^K * X\) \(V = W^V * X\) 自注意力机制的时间和存储复杂度与序列的长度呈平方关系,因此占用了大量的计算设备内存并消耗的大量的计算资源,如果优化自注意力机制的时空复杂度、增强计算效率是大语言模型面临的重要问题。一些研究从近似注意力出发,旨在减少注意力计算和内存需求,提出了稀疏近似、低秩近似等方法。此外,有一些研究从计算加速设备本身的特性出发,研究如何更好的利用硬件特性对Transformer中的注意力层进行高效计算。
评估指标
技术变迁中的变与不变:如何更快地生成token?大多数时候我们使用吞吐量和响应时间来度量一个系统。大体上可以这样理解:
- 吞吐量关注系统整体性能,与系统的成本有关。
- 响应时间关注单个请求,跟用户的体验有关。
现在,我们就来看看现代的LLM推理系统,情况有没有变化。当然,有些东西没有变。我们仍然应该关注吞吐量和响应时间,它们对于系统性能的描述能力,跟什么类型的系统无关,跟技术的新旧也无关。但是,毕竟LLM推理系统也有一些不一样的地方。最大的一个不同在于,LLM生成的是一个长的sequence,一个token一个token的流式输出。这是由Decoder-Only的语言模型架构所决定的,它自回归式的 (auto-regressive) 生成方式正是如此。这也意味着,LLM推理系统对于请求的响应,存在一个显著的持续时间(若干秒、十几秒,甚至几十秒)。一个请求本身包含很多token,同时也会生成很多token。我们仍然可以以 requests/s 来表示吞吐量,但业界通常换算到更细的粒度,也就是token的粒度,就得到了大家常说的 tokens/s。我们需要使用至少三个性能指标来对它进行度量:
- 每秒生成的token数 (tokens/s),作为吞吐量的度量。
- 首token的生成延迟,作为响应时间的一个度量。
- Normalized Latency,作为响应时间的另一个度量。每个请求的端到端的延迟(也就是系统从收到一个请求直到最后一个token生成完毕的持续时间)除以生成的token数,再对于所有请求计算平均值。它的度量单位是s/token
在大语言模型推理中常会用到四个指标:Throughput(吞吐量)、First Token Latency(首字延迟)、Latency(延迟)和QPS(每秒请求数)。这四个性能指标会从四个不同的方面来衡量一个系统的服务提供能力。
- Throughput/吞吐量是指当系统的负载达到最大的时候,在单位时间内,能够执行多少个 decoding,即生成多少个字符。
- First Token Latency/TTFT(首字延迟 Time To First Token)。指的是当一批用户进入到推理系统之后,用户完成 Prefill 阶段的过程需要花多长时间。这也是系统生成第一个字符所需的响应时间。很多需求关注这一指标,希望用户在系统上输入问题后得到回答的时间小于 2~3 秒。
- Latency/TBT(延迟 Time between tokens)。指的是每一个 decoding 所需要的时长。它反映的是大语言模型系统在线上处理的过程中,每生成一个字符的间隔是多长时间,也就是生成的过程有多么流畅。大部分情况下,我们希望生成的延迟小于 50 毫秒,也就是一秒钟生成 20 个字符。
- QPS(每秒请求数)。反映了在线上系统的服务当中,一秒钟能够处理多少个用户的请求。 First Token Latency 和 Latency 这两个指标会因为用户输入的长度不同、batch size 的不同而发生非常大的变化。用户输入的长度越长,首字延迟也会越高。decoding 延迟,只要不是千亿级别的模型,decoding 的延迟都会控制在 50 毫秒以内,主要受到 batch size 的影响,batch size 越大,推理延迟也会越大,但基本上增加的幅度不会很高。吞吐量其实也会受到这两个因素的影响。如果用户输入的长度和生成的长度很长,那么系统吞吐量也不会很高。如果用户输入长度和生成长度都不是很长,那么系统吞吐量可能会达到一个非常离谱的程度。 除了首token时延,LLM在线服务也可能会把尾token时延(即完成response的时延)作为优化目标,例如,当LLM推理服务作为中间环节时,就会希望response的尾token时延越小越好。
耗时分布
高性能 LLM 推理框架的设计与实现与传统的 CNN 模型推理不同,大语言模型的推理通常会分成 prefill 和 decoding 两个阶段。每一个请求发起后产生的推理过程都会先经历一个 Prefill 过程,prefill 过程会计算用户所有的输入,并生成对应的 KV 缓存(虽然计算量很大,因为要一次性完成用户输入的所有词的计算,但它只是一次性的过程,所以在整个推理中只占不到 10% 的时间。),再经历若干个 decoding 过程,每一个 decoding 过程,服务器都会生成一个字符,并将其放入到 KV 缓存当中,之后依次迭代。由于 decoding 过程是逐个字符生成的,每一段答案的生成都需要很长时间,会生成很多字符,所以 decoding 阶段的数量非常多,占到整个推理过程的 90% 以上。
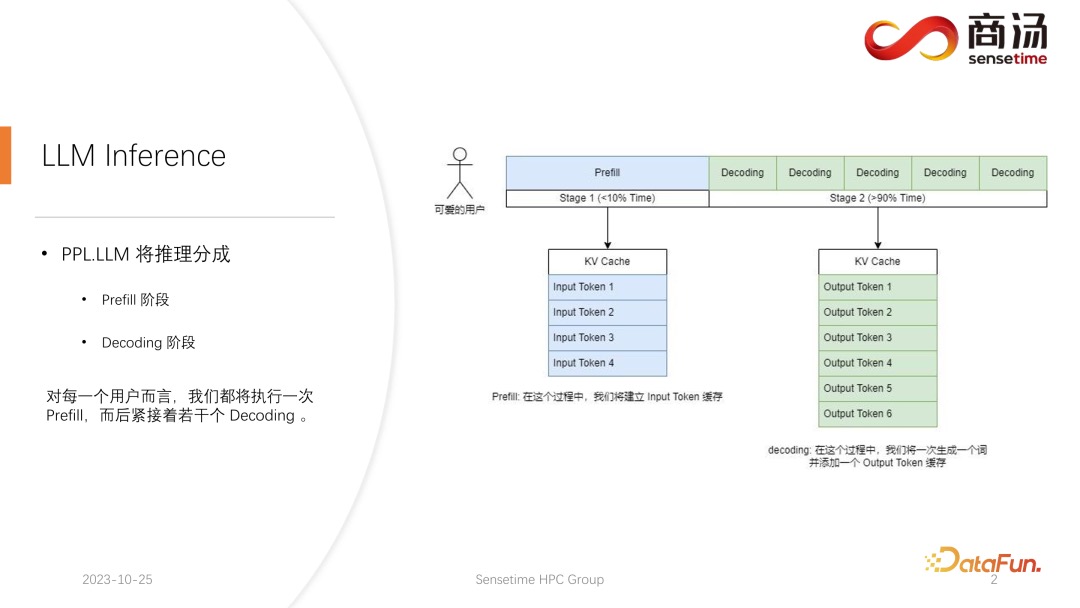
在 prefill 阶段,至少要做四件事情:第一件事情是把用户的输入进行向量化,tokenize 的过程指的是将用户输入的文本转换为向量,相对于 prefill 整个阶段来说,大概要占掉 10% 的时间,这是有代价的。之后就会进行真正的 prefill 计算,这一过程会占掉大概 80% 的时间。计算之后会进行 sampling,这个过程在 Pytorch 里面一般会用sample、top p。在大语言模型推理当中会用 argmax。总而言之,是根据模型的结果,生成最后词的一个过程。这个过程会占掉 10% 的时间。最后将 refill 的结果返回给客户,这需要的时间会比较短,大概占 2% 到 5% 的时间。

Decoding 阶段不需要 tokenize,每一次做 decoding 都会直接从计算开始,整个decoding 过程会占掉 80% 的时间,而后面的 sampling,也就是采样生成词的过程,也要占掉 10% 的时间。但它会有一个 detokenize 的时间,detokenize 是指生成了一个词之后,这个生成的词是个向量,需要把它解码回文本,这一操作大概会占掉 5% 的时间,最后将这个生成的词返回给用户。
新的请求进来,在进行完 prefill 之后,会不断迭代进行 decoding,每一个 decoding 阶段结束之后,都会将结果当场返回给客户。这样的生成过程在大语言模型里面是很常见的,我们称这样的方式为流式传输。
技术栈
大模型推理加速技术概要目前大模型推理加速技术栈大体可以分成三层(从低到高):
- 线性代数计算库,cuBLAS、Eigen、Intel MKL、ARM Compute Library等,其中定义了矩阵乘法、矩阵和向量乘法等数十个标准函数。线性代数层的加速主要依赖以下优化:
- GPU多核计算能力:通过调用CUDA、OpenCL等API,来利用GPU的并行能力。
- CPU SIMD和多核 :单指令多数据SIMD在x86上有SSEx和AVX等指令,在ARM上有NEON和SVE,都广泛被使用,也有的库通过OpenMP再叠加多核能力。
- Tiling分块:矩阵乘法GEMM作为机器学习关键操作(矩阵乘还经常用作张量形状的变换),Tiling(平铺)是一种优化技术,它涉及将大的矩阵分解成更小的块或“瓦片”(tiles),这些小块的大小通常与CPU或GPU的缓存大小相匹配,以便可以完全加载到缓存中
- Autotuning自动调优:通过参数空间搜索,可以在多个分块办法和操作核之间自动优选适合本机的优化方案。
- 模型推理引擎,TensorRT、TensorFlowServing、TVM等。 和线性代数层的优化不同,执行引擎能够看到整个神经网络的架构,也能够同时处理多个来自客户端的请求,所以可以使用涉及多个算子、整个模型,以及多个请求间的优化来提高执行效率。执行引擎一般有这些办法将模型推理进一步加速:
- Operator Fusion 算子融合:因为内存带宽往往是一大瓶颈,所以简单将多个相邻的算子找准机会合并起来计算,就可以减少对数据的扫描而大幅提升性能,所以Fusion是算子间优化的重要步骤,可以手工进行,也可以由执行引擎自动进行。
- Quantization 量化:随着GPU对数据结构支持的多元化,当前推理的基线数据类型已经是FP16,比几年前的FP32提高了不少速度。即便如此,将模型量化为INT8进行推理,依然可以提高较多速度,而在手机平台上,量化推理能进一步降低能耗。
- Distribution 分布式:使用多卡推理,以及通信加速,来提升能推理的模型规模和速度。
- Batching 批量化:将多个请求合并处理,是提高性能的另外一个关键办法,这个能大幅提高性能的原因主要有两个:1. 合并请求可以增大代数运算的矩阵规模,而下层代数库处理越大的矩阵规模,相对性能越高。2. 合并请求可以减少对静态的模型参数矩阵的扫描次数,减少内存带宽消耗。
- 大模型调度引擎,vLLM、TensorRT-LLM(原FasterTransformer)、llama.cpp等。大模型调度引擎是2022年开始新出现的一层抽象。为什么有了执行引擎还需要大模型调度引擎?主要是因为大家希望进一步优化推理性能,而大模型架构相对固定(Transformer架构及变形),通过专门针对大模型而不是更通用的神经网络进行推理优化,就可以利用大模型架构的特点和算法特性,来进一步提高性能。
- KV Cache:这是fairseq等系统很早就开始有的基础方法,就是将transformer attention计算中的Key和Value张量集合缓存下来,避免每输出一个token都重复计算。
- Iteration-level scheduling 迭代层调度:这是2022年Orca引入的方法,推理引擎默认都是按请求批量化,而LLM推理需要多次迭代进行自回归计算,所以按“迭代”为单位进行批量化,可以提高并行度和性能。
- PagedAttention 分页注意力: 这是今年vLLM引入的方法(参考文献2),背后洞察是上面提到的KV cache占用大量GPU内存,一个13B模型每个输出token对应的KV张量,需要800KB,而最长输出长度2048个token的话,一个请求就需要1.6GB显存。因此vLLM引入类似操作系统中的分页机制,大幅减少了KV cache的碎片化,提高性能。
- 低比特量化。传统的量化方法分为Quantization-Aware Training (QAT) 和 Post-Training Quantization (PTQ)。PTQ主要是对模型权重值和激活值进行INT8/INT4量化,QAT一般效果是更好的,但是它需要重训模型所以成本会大一些,相关的研究成果相较PTQ也少一些,在fintune阶段会用的比较多一些,例如 QLoRA。GPTQ量化。有一批研究专注于寻找更优的量化方法,llama.cpp支持近期发表的GPTQ(参考文献3),默认将模型量化到4比特,大幅提升性能且准确率下降很小。
- Fused kernels等各类手工优化:很多时候,手打优化都是少不了的办法,llama.cpp短时间积累大量用户,就是因为项目作者不怕麻烦,快速积累了大量手工小优化,集腋成裘,形成领先的综合性能。
访存量
LLM推理到底需要什么样的芯片?LLM的访存特征并不复杂,大模型的内存消耗主要来源于模型权重本身的加载和 Transformer Block 中的 Key/Value 这 2 个矩阵。权重是所有请求所有Token都共享的,也是固定大小的内存占用量,一般是1GB~100GB量级,取决于模型规模(Cache的大小只有几十M,因此权重在每次运行间不会保留在Cache中)。KV的内存占用量则是和模型相关,也和上下文长度成正比,并且每个请求独立的,并发的请求越多,KV需要占用的存储越大。今天在100GB~1TB区间上极限也就是做到100K量级的上下文长度,此时并发度往往是个位数甚至1。这个是很恐怖的,因为并发度提升一个数量级,或者上下文长度提升一个数量级,需要的KV存储也直接提升一个数量级,奔着1TB~10TB去了。而今天对于上下文长度的提升需求一定程度就是这样指数级的。每个请求实际上对应了一连串的Token生成,并且这一串Token是串行生成的。每个Token生成的过程都需要权重和这个请求对应的KV一起参与计算,这个访存量和硬件架构无关,只和模型以及上下文长度有关。而硬件能以多快的速度完成这个访存量,就决定了Token生成的时间下限。复用是一切花里胡哨的前提。一个系统同时并发处理大量这样的请求。权重部分的访存量所有Token都可以复用,而KV部分只有同一个请求的Token才共享,但这些Token的生成又是串行的,也没法共享。最终硬件拼的就是能够全量放下所有权重和并发请求对于KV的那个内存介质的带宽成本。PS: 提到了一个概念:每生成一个Token的访存量
Token生成的质量其实抛开纯算法层面的因素,主要是取决于参与计算的权重和参与计算的KV,分别对应模型对世界的静态认知以及对当前请求上下文的感受野。提高Token质量的方式就是更精细地利用访存量,让参与到Token计算的模型权重和KV更重要,除了量化压缩这些在质量和访存量上取平坦斜率的玄学外,这里面最显著的花里胡哨也就是稀疏化。
- MOE算是稀疏化了权重,每个Token只访问了可能和这个请求更相关的权重,这样用更少的访存量就可以获得接近的权重质量,因为Token感受野里的世界理解以及上下文相关度更高。深度解读混合专家模型(MoE):算法、演变与原理 未读
- KV的稀疏化未来大概率也会爆发,当上下文长度飙升到M甚至G量级的时候,只访问其中相关度更高的子集来减少访问量 LLM推理需要的芯片形态,最重要的是内存带宽和互联带宽,无比粗暴的100GB~1TB级别的scan模式访问(拒绝一切花里胡哨的复用),内存系统的噩梦。
不同场景的访存量
- prefill(用户输入)和decode(模型输出)的token量在不同场景下也是不一样的。LLM的prefill和decode分别用来处理用户输入的token和产生模型输出的token。prefill阶段是一次性输入全部token进行一次模型推理即可,期间生成用户输入对应的KV补充到整个KV-cache中供decode阶段使用,同时也生成输出的第一个token供decode启动自回归。这是个计算密集的阶段,且计算量随着用户输入token长度增加成正比增加。而decode阶段因为每个token都需要对模型进行一次inference,并对权重和KV进行一次访问,总的访存量和用户输入token数成正比,计算量也是一样成正比。所以相同token长度下,prefill和decode计算量一致,decode阶段访存量远远大于prefill阶段的,正比于token长度。一次用户请求实际上是既包含prefill,也包含decode。一个是计算密集型,一个是访存密集型,对硬件的要求更夸张了。如果是简单对话场景,通常模型的decode输出会更多一些,而如果是超长上下文场景,用户先上传一本几十万字的书再进行问答,这本书的prefill会直接起飞。在Agent场景下,大量预设的prompt也会占据非常多的prefill,不过prompt的prefill有不少机会可以提前算好KV而无需每个用户请求单独重复计算。
- 同一个batch的prefill和decode长度也不一样。考虑到我们搭建这样一个庞大的大模型推理系统需要服务大量用户,每个用户的prefill和decode长度很难保持一致。考虑到prefill和decode截然相反的计算访存特性,再考虑到芯片系统里面的内存资源异常宝贵,其实此时对Infra层面的调度设计已经开始爆炸了,而芯片设计同样需要考虑给Infra层面提供什么样的设计空间。用户请求之间相互等待prefill和decode阶段的同步完成会产生很强的QoS问题,但如果同时进行prefill和decode硬件算力资源、内存资源、带宽资源的分配以及每一阶段的性能优化策略产生很强的扰动和不确定性,甚至产生内存不足等一系列问题。此外,面对不等长输入输出的更加复杂和精细的资源调度,也进一步产生大量更精细的算子编写和优化的工作量,对于芯片的可编程性进一步提出了变态要求。
海量用户的KV-cache需要频繁从高速内存中切入切出。当整个推理系统服务几千万用户时,一个batch的几十个用户请求支持开胃菜。每个用户会不间断地和大模型进行交互,发出大量请求,但这些请求的间隔时间短则几秒,长则几分钟几小时。因此我们上一章讲的占用内存空间巨大的KV-cache实际上只考虑了当前系统正在处理的用户请求总量,还有大量用户正在阅读大模型返还的文字,正在打字输入更多的请求。考虑人机交互的频率,一个用户请求结束后,对应的KV-cache继续常驻在高速内存中实际意义不大,需要赶紧把宝贵的高速内存资源释放出来。而其他已经发送到系统的新用户请求也需要把对应的KV-cache赶紧加载到高速内存中来开启对该用户请求的处理。每个用户聊天的KV-cache都是100MB~100GB量级的IO量(取决于模型和上下文长度,跨度比较大)。这个IO带宽要求也不小,因为要匹配系统内部的吞吐率,每个请求要进行一次完整的KV导入和导出,而系统内部的内存带宽需要读取的次数正比于token数,所以两者带宽差距取决于请求输出的文本长度,通常在100~1000左右,注意这里的带宽是芯片系统的总内存带宽,例如groq的是80TB/s * 500+ = 40PB/s,那么这个IO的总带宽需要飙升到40TB/s~400TB/s才能满足sram的吞吐要求。当然也可以考虑重计算,但这个重计算的代价一定是超过prefill的,因为聊天历史记录一定比当前这一次的输入长度要长的多,尤其对于超长上下文,用户上传一个文件后进行多轮对话,对文件的prefill进行一次即可,后续的交互中仅仅对用户提问进行prefill而无需对文件重复prefill,但需要将前面prefill的结果从外部IO倒腾进来,并在回答后将增量部分及时倒腾出去。虽然倒腾到高速内存系统外部了,但面对几千万用户时,每个用户的每个聊天对应的KV-cache量也是天文数字一样的存储,实际上也不需要都存,但确实需要综合考虑效率的问题。一个用户在看到大模型回复之后,可能在几秒钟内回复,也可能几分钟后回复,也有可能就离开电脑永远不回复了。此时已经是一个大规模集群层面的调度和存储资源、计算资源、带宽资源的综合管理了。多模态进一步加剧复杂程度。不同模态的流量潮汐、计算特点以及计算、内存、带宽资源占用情况,都会进一步加剧整个系统对于弹性的需求。
当然,软件问题也不能抛开不谈。实际上LLM推理系统远不是transformer模型怎么硬件实现最高效,软件就可以丢到一边不管或者丢给编译器就能了事的。我们也可以看到实际上LLM的推理对Infra层面的调度设计的复杂性压根不在transformer本身,而是在“大”模型产生的各自带宽流量问题,精细化利用高速内存和带宽资源催生的潜在的算子需求也已经开始爆炸,甚至复杂度是远高于原先的朴素算子的。这些算子和调度分别是在微观层面和宏观层面对硬件资源的极致利用,在今天这种对算力、带宽、容量、互联需求全都拉爆的应用上,这种极致利用会变得更加重要。今天在Infra的调度设计层面实际上在标准体系上还没有事实标准。这是无数Infra从业者又一次巨大的机会。同时,Infra对事实标准的竞争之下还有一条暗线,就是LLM芯片和系统形态的竞争。实际上NVidia就是借着深度学习框架的竞争,成功用CPU+GPU的异构形态干掉了CPU集群的形态。通过CPU+GPU的异构形态为所有深度学习框架的竞争者创造了一种更高的上限和更极致的设计空间,从而使得所有深度学习框架事实上都在CPU+GPU的异构形态下竞争。
LLM推理的极限速度生成第一个Token通常是计算受限的,而随后的解码是内存受限操作。速度依赖于我们能多快从GPU内存加载模型参数到本地缓存/寄存器,而不是我们能多快地在加载的数据上进行计算。在推理硬件中可用和实际达到的内存带宽是预测token生成速度的更好指标,而不是它们的峰值计算性能。对于Mistral 7B,如果模型在矩阵元素上使用FP16,那么我们需要为每个词元读取约14.2GB的数据。在NVidia RTX 4090(1008 GB/s)上,读取14.2 GB需要约14.1毫秒,因此我们可以预期低位置编号的每个词元需要约14.1毫秒(KV缓存的影响可以忽略不计)。上述数字都是下限值,代表每个词元理论上的最短时间。要实际达到这一最短时间,你需要高质量的软件实现,以及能够达到理论峰值带宽的硬件。对于共享在线服务,连续批处理是不可或缺的,我们只有在大批量大小时才能实现良好的成本/性能比(小batch都对不起为了算它们搬的这么多参数),然而,大批量意味着更大的KV缓存大小,这反过来又增加了服务模型所需的GPU数量,这里有一个拉锯战。
具体技术
流水线优化
流水线优化目的是尽可能让显卡利用率占满。在大语言模型推理过程中,tokenize、fast sample 和 detokenize 这些过程都与模型的计算无关。我们可以把整个大语言模型的推理想象成这样一个过程,在执行 prefill 的过程中,当我拿到了 fast sample 的词向量之后,就可以立刻开始下一个阶段 decoding,不用等到结果返回,因为结果已经在 GPU 上了。而当完成了一次 decoding 后,不用等待 detokenize 的完成,可以立刻开始下一次的 decoding。因为 detokenize 是个 CPU 过程,后面这两个过程,只涉及到用户的结果返回,不涉及任何 GPU 的运算。并且在执行完采样过程之后,就已经知道下一个生成的词是什么了,我们已经拿到了所需的所有数据,可以立刻开始下一次运算,不需要再等待后面两个过程的完成。在 PPL.LLM 的实现当中使用了三个线程池:
- 第一个线程池负责执行 tokenize 过程;
- 第三个线程池负责执行后面的 fast sample 以及返回结果的过程和 detokenize;
- 中间的线程池用来执行 computing 的过程。 这三个线程池互相异步地把这三部分的延迟相互隔离,从而尽可能地将这三部分的延迟掩蔽掉。这将给系统带来 10% 到 20% 的 QPS 提升
KV Cache/attention cache
有许多针对Transformer的重要优化技术,如KV(键-值)缓存,每个Transformer层有一个KV缓存(在许多Transformer的实现中,KV缓存位于注意力类的内部)。 KVCache 顾名思义缓存一部分K矩阵和V矩阵(省的是$inputW_k$和$inputW_v$的计算),主要用于加速生成 token 时的 attention 计算。PS:llm 计算就是 input矩阵 ==attention==> O矩阵 ==ffn==> last token logits
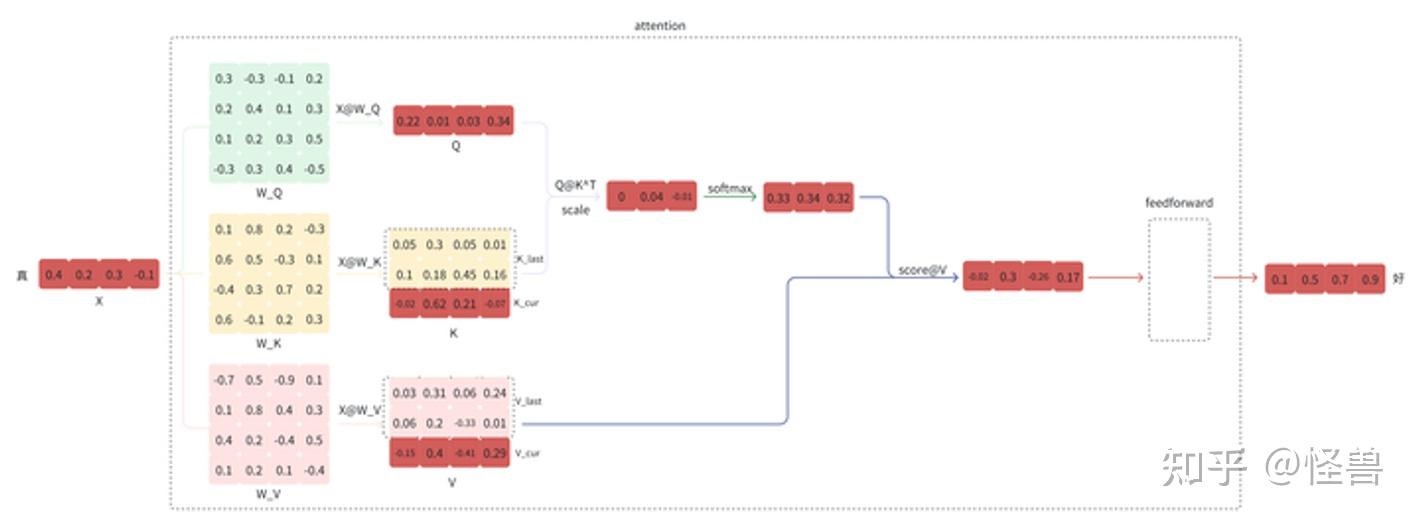
比如,当预测 今天天气真 ==> 好 时,使用kv cache后流程如下:
- 输入“真”的向量
- 计算“真”向量 乘以$W_q$,$W_k$,$W_v$ 得到 $Q_i$,$K_i$,$V_i$。
- 拼接历史K、V的值,得到完整的K、V。PS:注意,每一步step迭代中,K矩阵列数加1,V矩阵行数加1,“今天天气”4个token的key矩阵列和value矩阵行就不用再算了,K矩阵前面n-1列都是保存在cache中,只有k矩阵的最后一列是通过新增加的输入input token和$W_k$进行矩阵相乘得到的(后续也会加入到kvcache中),之后进行拼接即可。
- 然后经过Attention计算,获得 $O_i$ 输出。 \(\text{Attention}(Q_t, K_{1:t}, V_{1:t}) = \text{softmax}\Big(\frac{Q_t K_{1:t}^\top}{\sqrt{d}})V_{1:t}\)
- 根据$O_i$ 计算得到“好”。
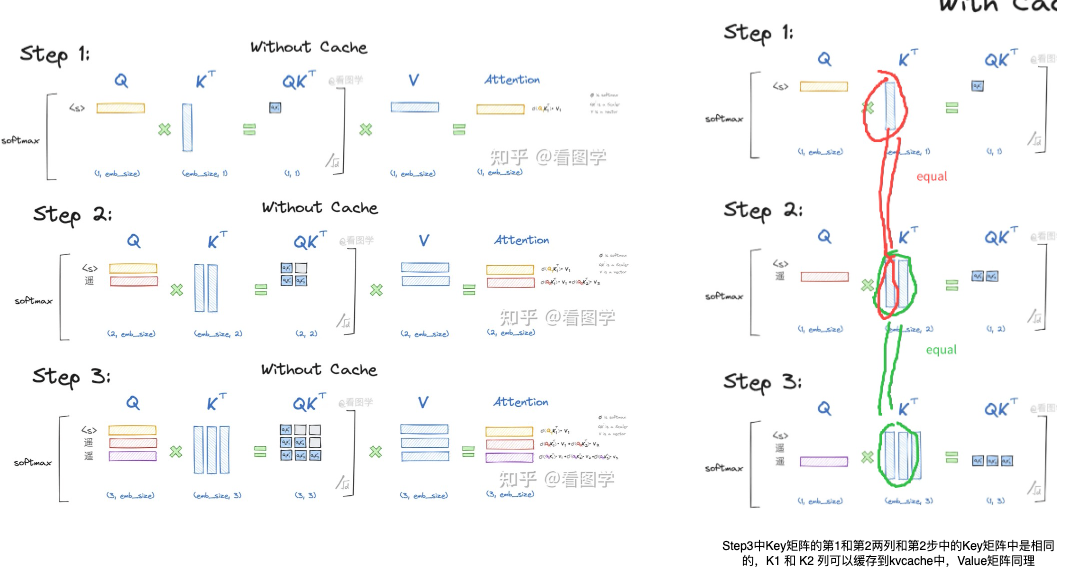
在推理的时候transformer本质上只需要计算出$O_{i+1}$ ,即一个字一个字地蹦。
- Attention的第i+1个输出只和第 i+1 个query有关,和其他query无关,所以query完全没有必要缓存,每次预测 $O_{i+1}$时只要计算最新的$O_{i+1}$,不用计算 $O_1$到 $O_i$。依赖前面所有 token 的 K 向量,前面所有 token 的 V 向量,以及仅仅依赖当前 token 的 Q 向量。
- 和casual mask 的关系:用了 causal mask 之后, 加入$Q_{i+1}$ , $O_1$到 $O_i$ 也不会变。但没有 causal mask,在“自回归逐步推理”场景下,也仍然不需要缓存 Q。
- Attention的输出$O_{i+1}$的计算和完整的K和V有关,而K、V的历史值只和历史的O有关,和当前的O无关。那么就可以通过缓存历史的K、V,而避免重复计算历史K、V。
K = X * W_k
V = X * W_v
Q = X * W_q
Attention(Q, K, V) = softmax(Q * K^T / sqrt(d)) * V
# 初始化缓存
K_cache = []
V_cache = []
for x in X: # 对每一个新的输入x
# 计算新的K和V
K_new = x * W_k
V_new = x * W_v
# 将新的K和V添加到缓存中
K_cache.append(K_new) # kvcache 也在膨胀,KCache_i ==> KCache_i+1
V_cache.append(V_new)
# 使用缓存中的K和V计算Attention
output = Attention(Q, K_cache, V_cache)
但是有一个问题就是KV Cache非常的大,比如说拿LLaMA-13B举例子,假设每个token在一层的大小有20KB,LLaMA-13B有40层,这样这个token大小就会达到800KB,而一个sequence一般来说会有几千的token,也就是说一个sequence就会达到几个G。对于 256K 上下文的模型来说,这部分显存可以轻松超过模型权重本身。Transformers KV Caching Explained 动图实在太贴切了。PS:KV-Cache的总空间大小为max_seqlen×layer_num×dim×sizeof(float)。因此,在第token_pos步时,我们可以通过索引位置(token_pos, layer_idx)来获取第layer_idx层的KV-Cache。 KV缓存技术详解与PyTorch实现 forward 是要多维护k_cache/v_cache/cache_index成员。
Memory waste in KV Cache
- 内部碎片:推理过程具有非常大的动态性,输出的长度不能预先知道,传统的serving system为了保险起见,就会预留非常大的空间,比如模型支持的最大输出2048个token,它就会预留这么大的空间,那么如果我产生的输出仅有10个token,剩下的2038的slots就会作为内部碎片被浪费。
- 外部碎片:因为每个request长度不等,就像os中的malloc,长度不等,不停的malloc就会产生外部碎片。
KV Cache的优化方法
- MQA、MHA减少KV Cache。KV cache的存在,本来是为了避免在推理阶段对前置序列的重复计算的。但是,随着前置序列的长度变长(我们记为kv_len),需要读取的KV cache也将越来越大,数据的传输成本增加,这就使得attn计算逐渐变成memory bound。我们采取了一些策略来缓解KV cache过大的问题,其中2种就是大家熟知的MQA和GQA。
- 在MQA的情况下,一个token所有的heads都共享同一个k和v。这样在降低param weights大小的同时,还让原本需要保存num_heads份的kv cache降低为只需保存1份。
- 但是,MQA可能造成模型效果上的损失,毕竟原来对于1个token,它的每个head都有各自的k、v信息的,现在却被压缩为一份。所以GQA作为一种折衷的方案出现了,即将1个token的head分成num_group组,每个group内共享同一个k,v信息,使得信息压缩不像GQA那样严重。
- 但是,不管是MQA还是GQA,对于1个token来说,总是存在heads上k、v信息被压缩的情况。那么是否有一种办法,能在尽量不压缩head上k,v信息的情况下,节省kv cache,提高整体推理速度呢?MLA 再读MLA,还有多少细节是你不知道的
- 窗口约束减少KV Cache
- 量化和稀疏。量化原本的意思是把原来不是“数量的”变化成“数量的”。这个术语起的名字很不好(在降低精度这个场景)。
- PageAttention
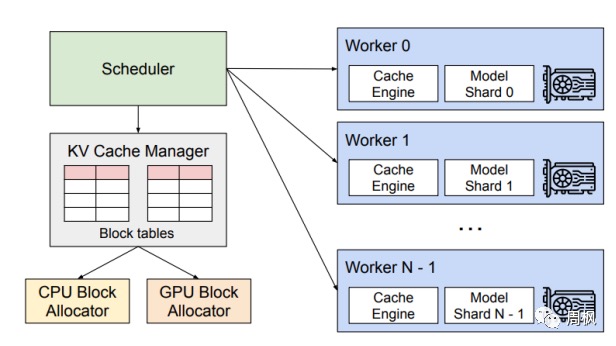
如何解决LLM大语言模型的并发问题?vLLM:Efficient memory management for LLM inference 受到操作系统中的分页和虚拟内存的启发,通过额外的元数据即page table管理KV cache。将KV Block当做页,将Request当做进程,每个 “KV Block” 可以存储指定数目的 tokens 对应的 Key 向量及 Value 向量,允许在非连续的内存空间中存储连续的KV。PagedAttention机制:传统要求将keys和values存到连续的内存空间,因为我们知道传统大家都是用TensorFlow、pytorch之类的,它是一个个tensor,所以很自然的就假设给它们一段连续的内存空间,但是对于LLM来说,这个假设就不是一个好的假设,因此PagedAttention允许在非连续内存空间中存储连续的keys和values,vLLM维护一个Block table,存放逻辑空间到物理空间的映射。现在有一个Prompt:Alan Turing is a computer scientist,当产生一个新的token时,会查看Block table中的Physical block no.,然后找到对应物理内存的地方存储进去,并更新Block table中的Filled slots内容。当产生“renowned”的时候,是新开了一个Block,所以也要更新Block table,新开一个物理内存(每个kv block中有固定的token数目)。
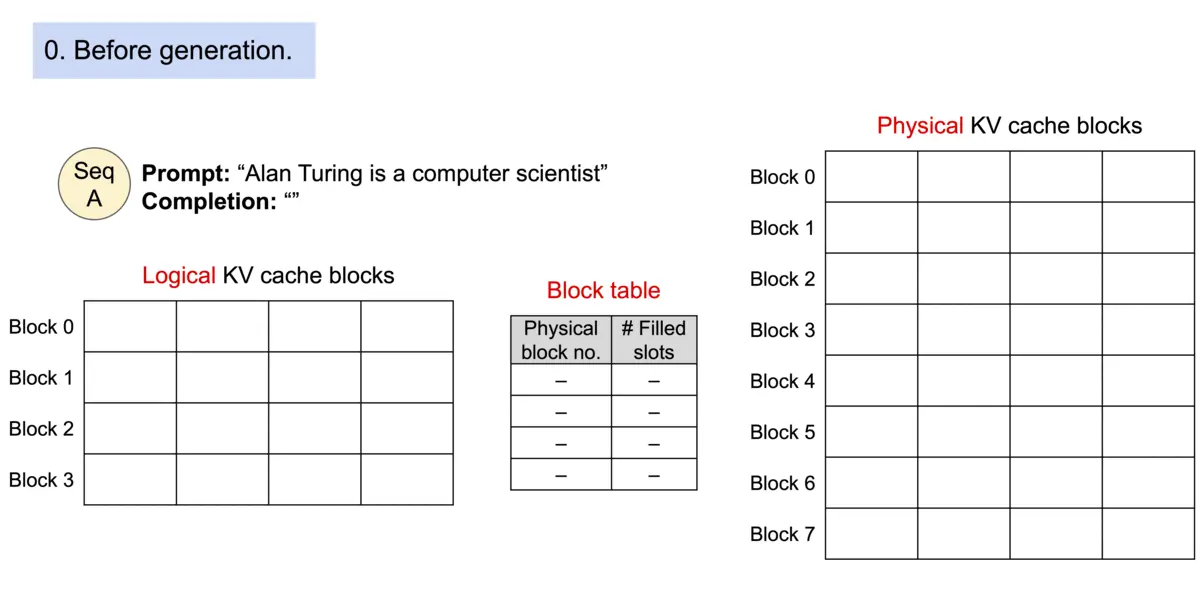
PS:Transformer (和Attention) layer 已经支持了缓存机制 (use_cache=true),kvcache 在代码上如何体现可以理解。pageattention 是不是可以理解为:pageattention 初始化了cache,只要把这个cache 引用传给 Transformer (和Attention) forward 函数参数,Transformer 就可以用这个cache 到计算过程中了?
图解大模型推理优化:KV Cache LLM推理入门指南②:深入解析KV缓存 未读
System Prompt Caching,也称为 Prefix Sharing,其基本思想是对System Prompt部分进行一次计算,并缓存其对应的Key和Value值(例如,存放在GPU显存中),当LLM推理再次遇到相同的(甚至部分相同的)System Prompt时,则可以直接利用已经缓存的System Prompt对应的Key和Value值,这样就避免了对于System Prompt的重复计算。
Mooncake: A KVCache-centric Disaggregated Architecture for LLM ServingMooncake的核心是其以KVCache为中心的调度器,将预填充/prefill服务器与解码/decoding服务器分开,因为LLM服务的这两个阶段具有非常不同的计算特性,Prefill是计算密集,受限算力带宽用不满,Decode是访存密集性,受限带宽算力用不满。所以用同一种硬件部署两阶段往往顾此失彼,不是最有性价比。拆分Prefill/Decode之后,LLM推理系统就更像一个分布式内存系统+流处理系统,其中KVCache随着请求从预填充移动到解码服务器而转移,将KVCache和计算分离开,它将GPU集群的CPU、DRAM、SSD和RDMA资源分组组成Distributed KVCache Pool,KVCache也是分块以Paged方式管理,KVCache Blocks如何在Pool中调度,请求和复用KVCache乃精髓。这就是传统计算机系统研究者最擅长的领域,sys三板斧,batch, cache,调度都可以招呼上,比如
- Prefill阶段可以利用request间存在共同前缀的机会,尽可能复用KVCache。PS:比如agent 循环调用 多次请求的prompt prefix是一样的。
- Decode可以进一步拆成Attention和非Attention算子分离调度。
LLM推理加速:decode阶段的Attention在GPU上的优化 结合Attention计算、kvcache与gpu硬件架构如何加快Attention 的计算。建议细读。一直以来缺一个 llm 架构与gpu 架构结合怎么优化计算的问题,各个概念怎么映射。
Flash Attention
其核心思想是通过分块(Tiling)和重计算(Recomputation),将Attention计算限制在GPU的高速片上缓存(SRAM)中进行,从而避免了将庞大的中间矩阵(如N*N的Attention Score矩阵)写回HBM。这一策略大幅减少了HBM的访问次数,使得Attention计算从显存带宽受限转变为计算受限。
模型在训练时候,除了gpu的计算时间外,从显存把数据搬运到缓存也占用了很多时间。举个例子,算一个最简单的标准化(x-mean)/var,需要涉及到如下步骤:
- 读x+读mean
- 写x-mean
- 读x-mean,读var
- 写(x-mean)/var 如果想让gpu端到端的计算结果(只读一次写一次),就需要做算子融合了,用cuda编程或者triton编程都行。在LLM中,RMSNorm、RoPE、self-attention、交叉熵损失函数都是频繁读取数据的大户,因此能把这些操作融合掉能提高不少的训练时间。对self-attention进行算子融合的实现就是大名鼎鼎的flash attention。
Flash Attention 的数学原理Flash Attention 并没有减少 Attention 的计算量,也不影响精度,但是却比标准的Attention运算快 2~4 倍的运行速度,减少了 5~20 倍的内存使用量。究竟是怎么实现的呢?简单来说,Flash Attention 让 Attention 的所有计算都符合结合律,这样就可以充分利用 GPU 的并行优势。从Attention 计算公式可以看出,Attention 的并行计算主要解决两个问题:
- 矩阵的并行计算。$X=QK^T$
- Softmax 的并行计算。$A=softmax(\frac{X}{\sqrt{d}})$。 矩阵的并行算法已经比较成熟,GPU 上也有 TensorCore 来加速计算。 Softmax 操作让并行计算有些棘手。Softmax 的并行无法将计算放到一个 Kernel 中。后面的建议细读文章。
传统attention流程如下:从显存中取QK计算->将结果S写回显存->从显存读S计算softmax->将结果P写回显存->从显存读取P和V进行计算->将结果O写回显存。因此想办法进行分块计算,拆到足够小,就能全塞到L1缓存上(比如说A100的L1只有192KB)进行计算了,不需要将这些参数从显存反复的读入读出,只需要读L1缓存,就实现了加速。但是softmax是需要需要知道全局信息的,所以分块计算后,需要一些技巧对结果进行融合。
- FlashAttention是一种IO-aware算法,它通过tiling来减少对HBM的访存量,从而提高性能。本质上是利用IO Aware、重计算提升计算强度;
- FlashAttention避免了从HBM读写一些中间结果,比如QK得到的相似度矩阵,以及基于相似度矩阵计算softmax得到的概率矩阵 Flash Attention 的目标是尽可能使用 SRAM来加快计算速度,避免从全局内存中读取或写入注意力矩阵(H100 全局内存80G,访问速度3.35TB/s,但当全部线程同时访问全局内存时,其平均带宽仍然很低)。达成该目标需要做到在不访问整个输入的情况下计算softmax函数,并且后向传播中不能存储中间注意力矩阵(存部分信息,反向传播时重新计算)。PS:通过数学变换,换个算法,减少内存占用,pytorch2.0 已支持Flash Attention。PS:FA的本质是融合算子的一种新的实现方式。
图解大模型计算加速系列:Flash Attention V1,从硬件到计算逻辑在矩阵分块的时候设计好一个能够充分利用高速访存HBM的分块方法,让一次搬运进HBM中的参数可以全部和该做乘加操作的算子都计算完再丢弃,达到数量单次访存利用率最大化。
- Fast(with IO-Awareness),计算快。它发现:计算慢的卡点不在运算能力,而是在读写速度上。所以它通过降低对显存(HBM)的访问次数来加快整体运算速度(通过分块计算(tiling)和核函数融合(kernel fusion)来降低对显存的访问),这种方法又被称为IO-Awareness。
- Memory Efficicent,节省显存。在标准attention场景中,forward时我们会计算并保存N*N大小的注意力矩阵;在backward时我们又会读取它做梯度计算,这就给硬件造成了的存储压力。在Flash Attention中,则巧妙避开了这点,使得存储压力降至。在后文中我们会详细看这个trick。
- Exact Attention,精准注意力。
我们知道显存的带宽相比SRAM要小的多,读一次数据是很费时的,但是SRAM存储又太小,装不下太多数据。所以我们就以SRAM的存储为上限,尽量保证每次加载数据都把SRAM给打满,能合并的计算我们尽量合并在一起,节省数据读取时间。举例来说,我现在要做计算A和计算B。在老方法里,我做完A后得到一个中间结果,写回显存,然后再从显存中把这个结果加载到SRAM,做计算B。但是现在我发现SRAM完全有能力存下我的中间结果,那我就可以把A和B放在一起做了,这样就能节省很多读取时间,我们管这样的操作叫kernel融合。kernel包含对线程结构(grid-block-thread)的定义,以及结构中具体计算逻辑的定义。flash attention将矩阵乘法、mask、softmax、dropout操作合并成一个kernel,做到了只读一次和只写回一次,节省了数据读取时间。
图解大模型计算加速系列:Flash Attention V2,从原理到并行计算 未读。
不会 CUDA 也能轻松看懂的 FlashAttention 教程(算法原理篇) 未细读。
调度优化/动态批处理
大模型推理服务调度优化技术-Continuous batching
- 单处理,也就是单个提示(Prompt)传过来直接送入到LLM进行推理。因为每次只能处理一条数据,对GPU资源的利用率较低。
- 静态批处理(static batching),将请求凑成固定Batch再执行,不同的request组成batch后,要等最长的一个request执行完毕,才能整体退出,批处理的大小在推理完成之前保持不变。因此,GPU 未得到充分利用。
- 动态批处理(Dynamic batching),动态批处理是指允许将一个或多个推理请求组合成单个批次(必须动态创建)以最大化吞吐量的功能。
- 静态批处理是基于固定的请求个数来触发的,比如每4个请求一批进行处理;动态批处理是在静态批处理之上,增加一个时间窗口的维度,比如也是4个请求,但同时还有一个时间窗口100ms的约束,那么在100ms以内,如果积累了4个请求,那么就会触发后置处理,或者是在100ms的窗口时间内,没有达到4个请求,那么也会触发后置处理,动态相比静态处理来说,对用户侧会更友好,但是从资源利用率上来说没有静态批处理好,使用哪种方式可以结合场景进行权衡选择。
- 连续批处理(Continuous Batching),在Token粒度动态插入/移除请求。无论是动态批处理还是静态批处理,通常在相同形状的输入和输出请求的场景,提高GPU的利用率。但对于自回归大模型推理场景而言,都不太适用(同一批次中的数据输入和输出长度都不一样)。Continuing Batching(有的地方也叫做 Inflight batching 或者 Iteration batching)指请求在到达时一起批量处理,但它不是等待批次中所有序列都完成,而是当一个输入提示生成结束之后,就会在其位置将新的输入Prompt插入进来,从而比静态批处理具备更高的 GPU 利用率。由于每次迭代的批处理大小是动态的,因此,有些地方也叫动态Batching。PS:当一个request执行完毕之后,可以继续插入新的request,从request视角是立即开始立即结束。
提升模型服务吞吐最重要的手段是 Batching 策略,Batching主要包含以下三个步骤:
- 模型服务调度层将多个不同的请求组成一个 batch 的模型输入;
- 将batch 化的模型输入放入推理后端进行推理,得到一个 batch 结果;
- 再将推理的 batch 结果拆分,并封装成不同的 Response 返回到对应的请求中。
一般来说,合并越多的请求作为单次推理的输入,服务吞吐越高。所以从请求 Batching 的角度去提升模型服务吞吐的本质是提升单次推理的最大合并请求数,即 batch size。对于模型服务来说,单次推理最大合并请求数主要受显存制约。合并越多的请求,batch size 越大,KVCache 的显存占用则越大。KVCache 的显存占用上限可简单的通过显卡的最大显存减去模型权重显存计算得到。
Batching就是将一段时间内到达的用户请求合并到一起,提交到GPU中执行,从而提高系统的吞吐量。然而,与传统的 DNN Model 在推理时只要正向执行一遍不同,基于 Transformer 的 Generative Model 在推理时是迭代式的(Iterative),每个请求都需要迭代式执行多次,每次生成部分结果(一个 Token),且每个请求的迭代次数可能是不同的(例如迭代直到模型生成一个 End-Of-Sequence Token)。因此将现有的 Batching 方式应用在 Generative Model 时,可能导致有的请求已经迭代结束了,但是还需要和同Batch中没有迭代结束的请求继续一起执行。这个问题的核心在于,传统的 Batching 技术是以 Request 为粒度的(Request-Level),将多个 Request 绑定在一起提交给执行引擎,多个 Request 同时开始同时结束。因此需要一个新的 Batching 的方式,这也是本项工作核心的 Insight:使用更细粒度的,Iteration-level Batching,在每个 Iteration 中将不同的 Request 合并到一起。对于新到达的请求,有机会在当前的迭代执行后进行处理,从而减少等待时间。通过迭代级调度,调度器可以完全控制每次迭代处理的请求数量和哪些请求。PS: batch的粒度不同。
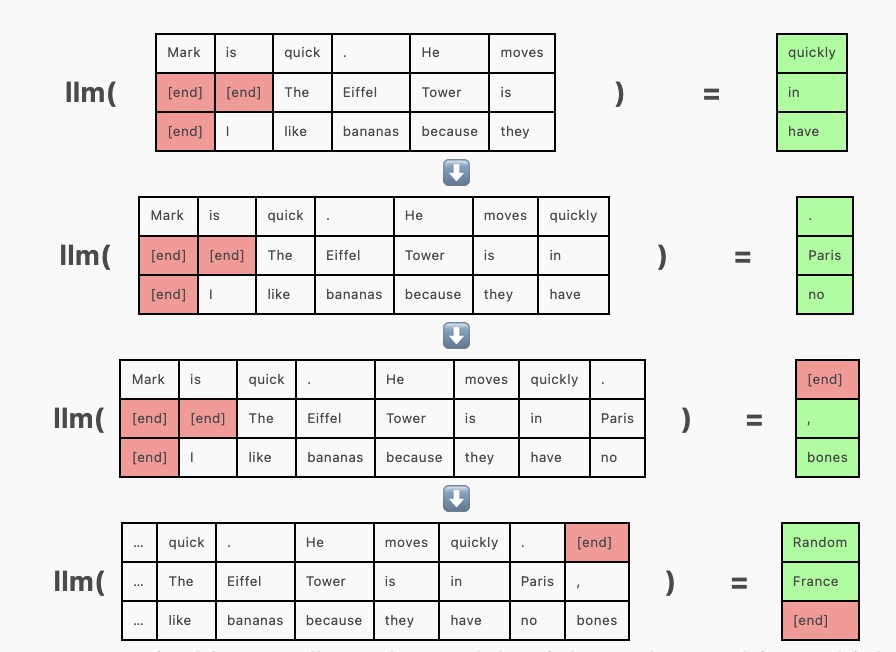
为了进行批次生成,我们改为一次向模型传递多个序列,在同一前向传递中为每个序列生成一个补全(completion),这需要在左侧或右侧使用填充词元对序列进行填充,使它们达到相同的长度。填充词元(可以是任何词元,我这里使用 [end])在注意力掩码中被屏蔽,以确保它们不会影响生成。
但在上面的例子中,请注意 “Mark is quick. He moves quickly.” 在其他序列之前完成,但由于整个批次尚未完成,我们被迫继续为其生成词元(“Random”)。这并不影响准确度,我们只需简单地将生成的序列截断到 [end] 词元即可,但这样很浪费资源,因为GPU资源正在用于生成我们即将丢弃的词元。连续批处理通过将新序列插入批次来解决这一问题,插入位置是 [end] 词元之后。在 [end] 词元之后生成随机词元的代替方案是,在批次的相应行中插入新序列,并使用注意力掩码机制来防止该序列受到上一序列中词元的影响。(实际上,先前的序列充当了额外的填充内容。)
vLLM(二)架构概览vllm Scheduler 使用 iterative-level 策略对请求进行调度(选择要被处理的请求),被调度的请求在生成一个 token 后会被重新调度。得益于 itertive-level 策略,vLLM 能够在每一轮新的迭代时选择不固定数量的请求进行处理(即 batch size 每次都不一定相同),因此它能够尽可能多地处理请求。
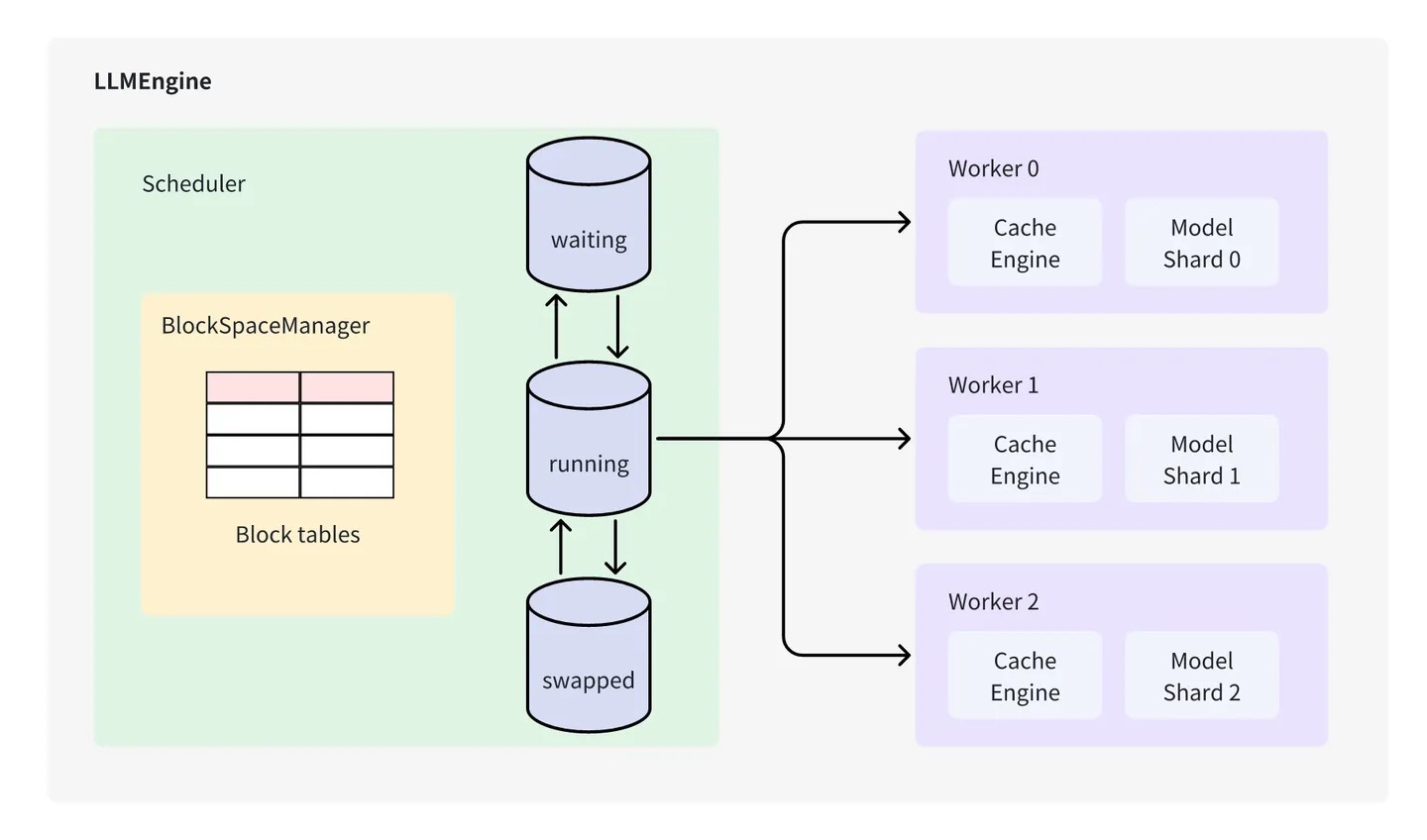
请求的处理通常分为两个阶段,第一个阶段对 prompt 进行处理(也被称为填充阶段,后文使用填充阶段表示这一个阶段),生成 prompt KV cache 的同时生成第一个 token,第二个阶段是生成阶段,不断预测下一个 token。目前对 iterative-level 的实现有两种方式,一种是区分填充阶段和生成阶段,另一种是不区分这两个阶段。vLLM 采用的 iterative-level 策略是区分两个阶段的(https://github.com/vllm-project/vllm/pull/658),即同一批被调度的请求要么都处于填充阶段,要么都处于生成阶段,Scheduler 中有 3 个队列,waiting(接受到的新请求会先放入 waiting 队列)、running(被调度的请求)和 swapped 队列(swapped 队列用于存放被抢占的请求,即当请求处于生成阶段时,但由于空间的不足,需暂时将 running 队列中优先级低的请求移到 swapped 队列)。在调度时,Scheduler 会按照先到先处理(first come first served)的原则从 waiting 队列中选择请求放入 running 队列,此外,Scheduler 的另一个核心组件是 BlockSpaceManager,它主要负责块表的维护。
假设 vLLM 接收到 3 个请求(记为 s0, s1, s2)并放入 waiting 队列中,它们的 prompt 分别为 “Hello, my name is”、”The future of AI is” 和 “The life is”。接下来开始 vLLM 的调度和处理。
- vLLM 的第一轮处理,假设 vLLM 在这一轮只能调度两个请求进行处理,那么根据先到先处理的原则,会从 waiting 队列中选择 s0 (“Hello, my name is”) 和 s1 (“The future of AI is”) 放入到 running 队列。对于 s0,Worker 生成的 token 为 Dustin,对于 s1,Worker 生成的 token 为 bright。同时,Worker 会将计算过程产生的 KV 值存储在 KV cache 中
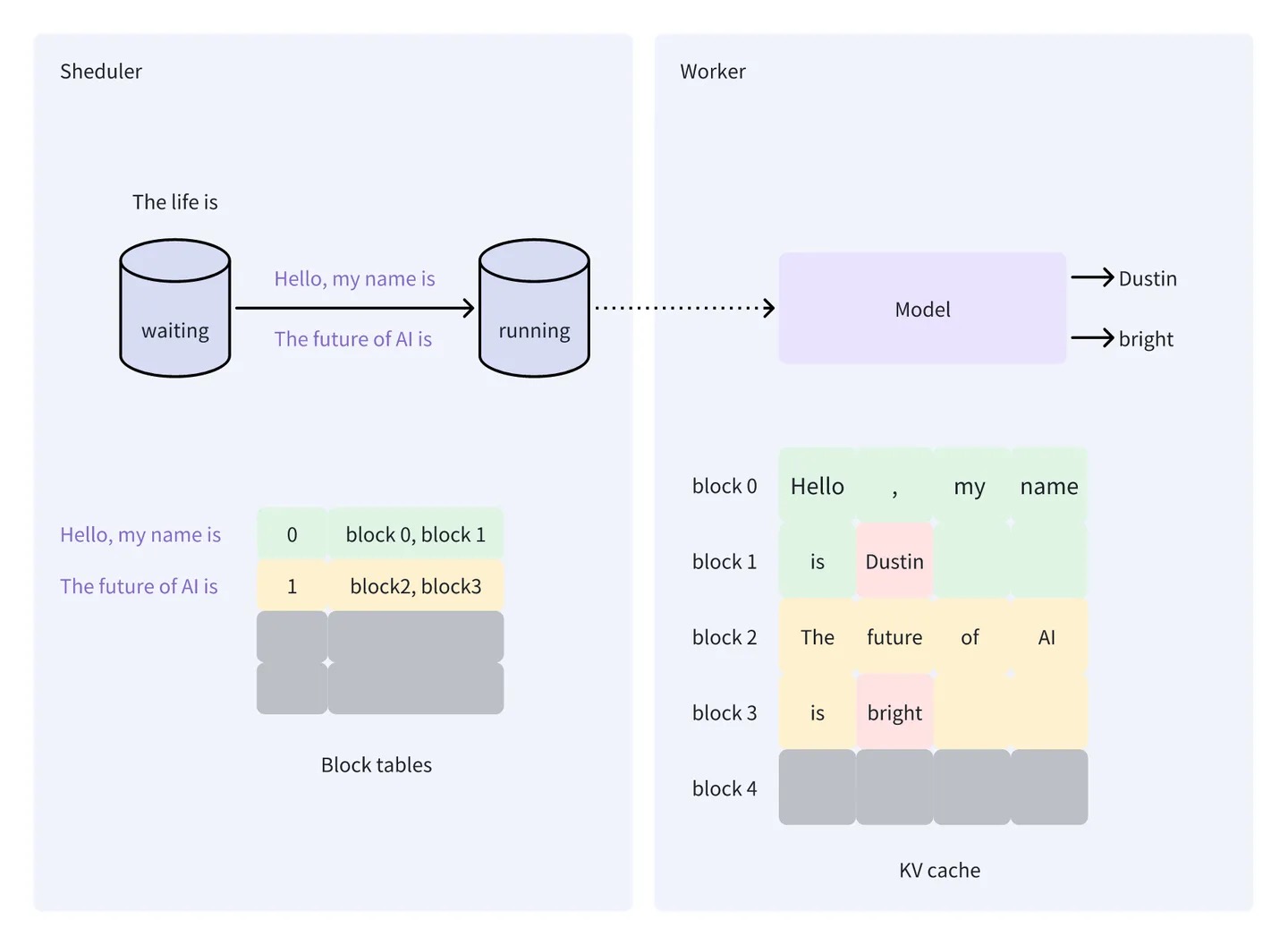
- vLLM 的第二轮处理,由于 waiting 队列中还有一个请求 s2(The life is),因此,vLLM 在第二轮只会处理这一个请求,因为前面提到,vLLM 只会处理要么都是填充阶段的请求,要么都是生成阶段的请求。
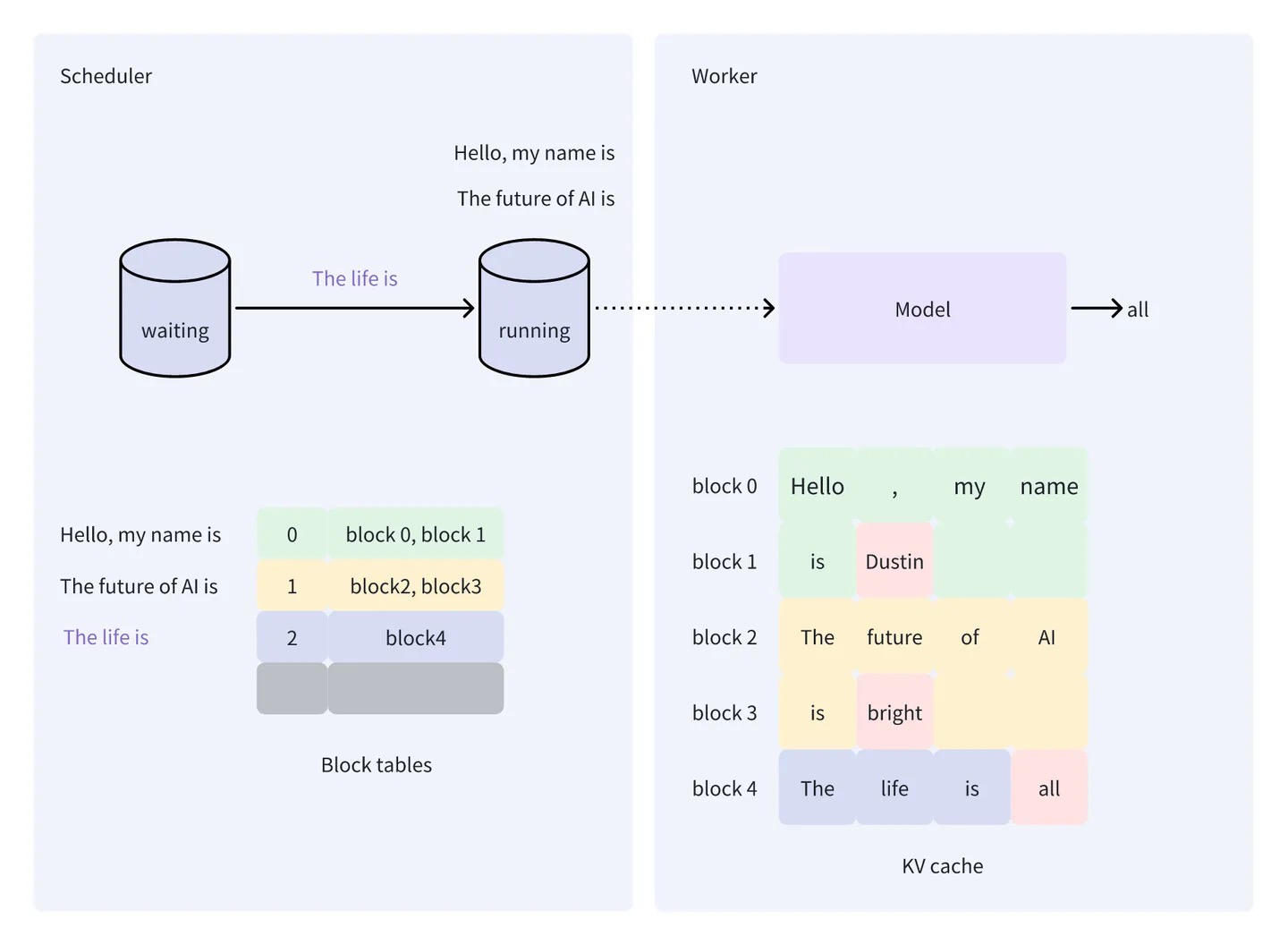
- vLLM 的第三轮处理,waiting 队列中没有要处理的新请求,所以会从 running 队列中选择此轮要处理的请求(这些请求均处于生成阶段)。但由于没有多余的空间,vLLM 只会选择 s0 和 s1 进行处理。经过多轮调度和推理,最终完成 3 个请求的处理,以上就是 vLLM 的工作流。
让LLM推理加速的batching是什么技术(in-flight batching)
借着triton inference server聊一下各种batching方法 未读
一些材料
推理加速,标准的推理优化技术对于LLM很重要(例如,算子融合、权重量化),但探索更深层次的系统优化也很重要,特别是那些能改善内存利用率的优化。
- 模型优化技术(重点Kernel 优化)。MHA(Multi-Head Attention) ==> MQA/GQA;FlashAttention;PagedAttention
- 模型压缩技术。量化的粒度从per tensor,per channel到per group,涉及到weight、activation以及kv cache的量化。
- prompt压缩,在prompt进入到LLM推理之前,压缩掉一些不必要的prompt信息,prompt长度变短之后,整体计算量减少,推理性能提升。
- Offload技术。大模型低显存推理优化-Offload技术对于推理场景下,Offload的对象有以下两种:权重、KV Cache。PS:由于涉及使用速度较慢的存储介质,卸载操作会带来严重的时延,因此不适用于对时延比较敏感的用例。卸载系统通常用于面向吞吐量的用例(因为batch 可以很大),如离线批处理。
- 硬件加速
- GPU加速
- 模型并行化和分布式计算技术。在Memory-Bound场景里,为了提升GPU利用率,一般会采用张量并行(Tensor Parallelism, TP),将LLM模型参数进行切分,从而减少从显存中读取模型参数的耗时。举例而言,对于13B的模型,如果使用FP16精度进行模型推理,那么模型参数所占的显存空间约为24.21 GB
(13*2/(1.024**3) ~= 24.21)如果是使用单张L20卡进行推理,那么从显存中读取模型参数的耗时约为28.02毫秒(24.21/864 ~= 0.02802)如果是使用两张L20卡进行推理,并选择TP=2,那么从显存中读取模型参数的耗时约为14.01毫秒,当然TP策略会带领额外通信开销,所以也不是越多卡越好。进一步的,当单机8个GPU卡总的显存都放不下模型参数时,就需要使用流水线并行技术以便将模型参数切分到不同的服务器上,或者是采用ZeRO-Inference大模型推理技术,将模型参数切分以及将模型参数(后续扩展到KV Cache)offload到CPU内存。 - 李谋:不同复杂度的任务使用了不同数量,不同配比的硬件。举个例子,对于同一个模型 Yi-34B,我们部署了 2 套硬件集群 (低配版 / 高配版,算力和成本不同),针对用户在线请求的具体输入长度来决定使用哪个集群服务,这样能兼顾用户体验,服务压力和服务成本。
迈向100倍加速:全栈Transformer推理优化本文回顾了从GPU架构到MLsys方法,从模型架构到解码算法的全栈Transformer推理优化方法。可以看出,大部分性能提升都来自于一个原则的利用:Transformer推理受内存限制,因此我们可以释放额外的计算能力/flops。其次,优化要么来自于优化内存访问,比如Flash Attention和Paged Attention,要么来自于释放计算能力,比如Medusa和前向解码。我们相信MLSys和建模仍有许多改进空间。在即将到来的2024年,随着模型变得更大、上下文变得更长以及随着更多开源MoE(混合专家模型)、更高内存带宽和更大内存容量的硬件,以及具有更大DRAM和专用计算引擎的移动设备的亮相,将出现更强大且人人可操作、可访问的AI。一个新时代即将到来。
GPU编程基础:在执行model.generate(prompt)时,我们进行以下操作:
- 内存访问:
- 从高带宽内存(HBM)加载模型权重到L2缓存,然后传输到SM(流处理器单元)
- 计算:
- 在SM中执行矩阵乘法,SM请求张量核心执行计算
- A100:
- 108个SM,DRAM容量为80G,40M L2缓存
- bf16张量核心:每秒312万亿浮点运算(TFLOPS)
- DRAM内存带宽为2039GB/秒 = 2.039T/秒
- 如果模型很大,我们将其分割到多个GPU上,比如两个由NVLink连接的GPU
- NVLink 300GB/秒 = 0.3T/秒
- 我们大致观察了速度层次结构。尽管不能直接比较,但它们的数量级差异是我们需要优化的主要方面:
- 312T(SM计算) > 2.03T(DRAM内存访问) > 0.3T=300G(NVLink跨设备通信) > 60G(PCIe跨设备通信)
这意味着,如果我们希望速度更快,我们应该尽力:
- 充分利用SM
- 减少单个GPU的内存访问(因为它比计算慢得多),
- 减少GPU之间的通信(因为它甚至比内存访问还要慢)。
调用model.generate(prompt)时有两个步骤:
- 预填充:
- 为提示计算键值(kv)缓存。
- 这一步骤受计算限制,因为我们并行计算了一系列词元。
- 解码:
- 自回归采样下一个词元。
- 这一步骤受内存限制,因为我们仅计算一个词元,未充分利用SM。
函数计算推出 GPU 闲置计费功能,在保障性能的前提下,可以帮助您大幅降低 GPU 的成本开销。以往部署大型语言模型(LLM)可能需要昂贵的 GPU 支持,尤其在需要大量计算资源时。但请求处理并不是每时每刻都处于活跃状态,势必存在流量的潮汐现象,后端的计算资源会出现空载导致成本的浪费。借助函数计算 GPU 闲置计费功能,用户的开销将会根据实际计算负载动态调整。
在线推理框架
揭秘大语言模型实践:分布式推理的工程化落地才是关键!与以往的模型不同,单张 GPU 卡的显存可能不足以支撑大语言模型。因此,需要使用模型并行技术,将大语言模型进行切分后,在多张 GPU 卡上进行推理。我们使用 DeepSpeed Inference 来部署大语言模型分布式推理服务。DeepSpeed Inference 是 Microsoft 提供的分布式推理解决方案,能够很好的支持 transformer 类型的大语言模型。。DeepSpeed Inference 提供了模型并行能力,在多 GPU 上对大模型并行推理。通过张量并行技术同时利用多个 GPU,提高推理性能。DeepSpeed 还提供了优化过的推理定制内核来提高 GPU 资源利用率,降低推理延迟。
有了大模型分布式推理方案,然而想要在 Kubernetes 集群中高效部署大模型推理服务,还存在很多工程化挑战,比如大规模的 GPU 等异构资源如何高效地管理运维和自动调度?如何快速部署推理服务,服务上线后如何保证资源能够应对波动的访问量?以及没有适合的工具进行推理服务时延、吞吐、GPU 利用率、显存占用等关键指标监控,没有合理的模型切分方案,模型版本管理等。
大模型的好伙伴,浅析推理加速引擎FasterTransformer 未细读 FasterTransformer 是真对于 Transofrmer 类型模型(也包括 encoder-only、decoder-only)的推理加速方案,其提供了 Kernel Fuse、Memory reuse、kv cache、量化等多种优化方案,同时也提供了 Tensor Parallel 和 Pipeline Parallel 两种分布式推理方案。
大模型推理优化实践:KV cache复用与投机采样RTP-LLM 是阿里巴巴大模型预测团队开发的大模型推理加速引擎,该引擎与当前广泛使用的多种主流模型兼容,并通过采用高性能的 CUDA 算子来实现了如 PagedAttention 和 Continuous Batching 等多项优化措施。RTP-LLM 还支持包括多模态、LoRA、P-Tuning、以及 WeightOnly 动态量化等先进功能。
高性能 LLM 推理框架的设计与实现PPL.LLM,商汤,开源。
分布式推理
- 在提升模型显存使用效率方面,Flash Attention 和 Paged Attention 是两种常用的方法。在输入序列中,模型会根据每个词的重要性来分配显存。对于重要性较高的词,模型会分配更多的显存空间来存储其信息;而对于重要性较低的词,模型则会分配较少的显存空间。
- 量化。从感知上来讲模型的参数量越大,其中的信息冗余程度也就越高,低精度量化在传统的小模型推理中已经是一个常见的优化手段了,对于更大参数量的语言模型更是如此。量化过程主要涉及两个方面:参数环节的小型化和降低数据类型。通过这一步骤,我们能够使得模型加载的参数更小,从原本的 FP32 降低到 FP16,从而提高推理性能。在量化过程中,我们还会采用混合精度量化技术。这种技术能够在保证模型准确性的前提下,将异常值保留精度,并在混合精度分块矩阵最后再加回去。
- BF16拥有与FP32相同的8位指数部分,因而能够表示与FP32几乎一样广泛的数值范围,这对于避免上溢和下溢非常重要。尽管BF16在尾数精度上不如HF16,但在深度学习应用中,这种较宽的数值范围通常比尾数的额外几位精度更为重要。这是因为深度学习模型通常对权重的尾数精度不是非常敏感,而更依赖于能够处理范围广泛的梯度和权重值。
- 量化对于文本生成特别有效,因为我们关心的是选择 最可能的下一个词元的分布 ,而不真正关心下一个词元的确切 logit 值。所以,只要下一个词元 logit 大小顺序保持相同, argmax 或 topk 操作的结果就会相同。
- 常用量化方法:GPTQ、AWQ和GGUF
- 模型稀疏化。模型稀疏化是一种重要的优化方法。它的主要目的是减少模型参数的数量,从而降低模型的复杂度,提高模型的泛化能力和计算效率。模型稀疏化的主要方法有剪枝、量化、低秩近似等。剪枝是一种直接删除模型中部分参数的方法,它可以有效地减少模型的规模,但需要注意不能过度剪枝,以免影响模型的性能。低秩近似则是通过将模型转换为低秩矩阵,来减少模型的参数数量。
- 并行。在Attention层中采用TP、SP,也可以开始CP;FFN层如果是dense结构用TP+SP,如果是sparse结构(MoE)常用EP;DP是所有层都适用。ZeRO策略(参数分片/shard)、PP层间的流水线并行相对而言当前的使用频率较低,在一些特定场景中可考虑开启。分布式推理并行策略
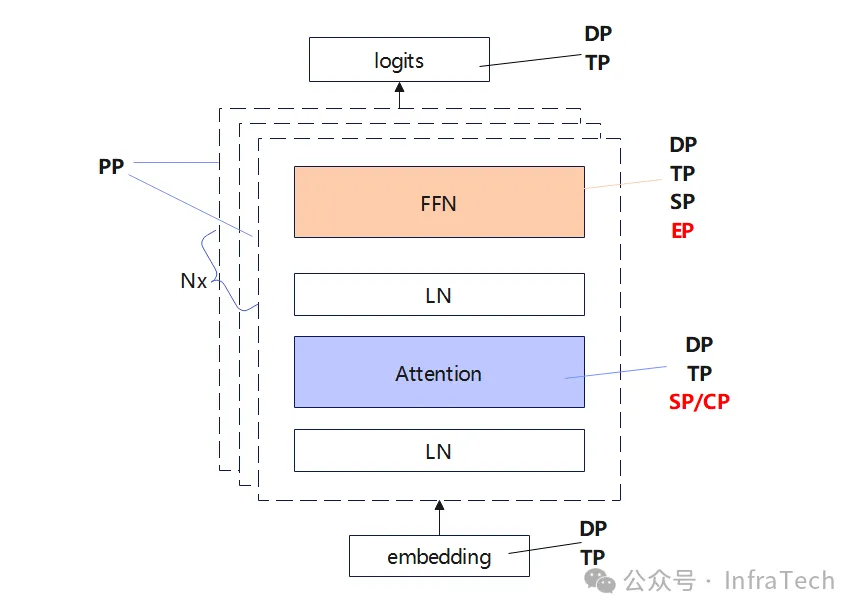
- 推理引擎都是做成多卡TP而不是PP,主要是因为从服务器视角看PP的吞吐上限更高,但是从单个请求视角看TP的延迟会更低,在线服务往往不需要那么高的吞吐,延迟更加重要。后来vLLM还增加了流水线并行(Pipeline Parallelism)的支持,从vLLM版本 0.5.1 开始支持跨多节点的流水线并行,对于那些跨多个节点的超大模型和低带宽连接,流水线并行是一种更优的选择。
随着 DeepSeek V3/R1 与 Kimi K2 等 MoE 架构的模型的横空出世,更大参数量与上下文的模型以及更复杂的使用场景使得单机的 GPU 部署方式无法再适用,因为节点内卡间的通信以及跨节点的通信(根据网络拓扑的不同)在不同的并行方式下都会引入难以忽略的延迟,对多个关键指标都会造成显著的降级,从而影响推理服务的质量。
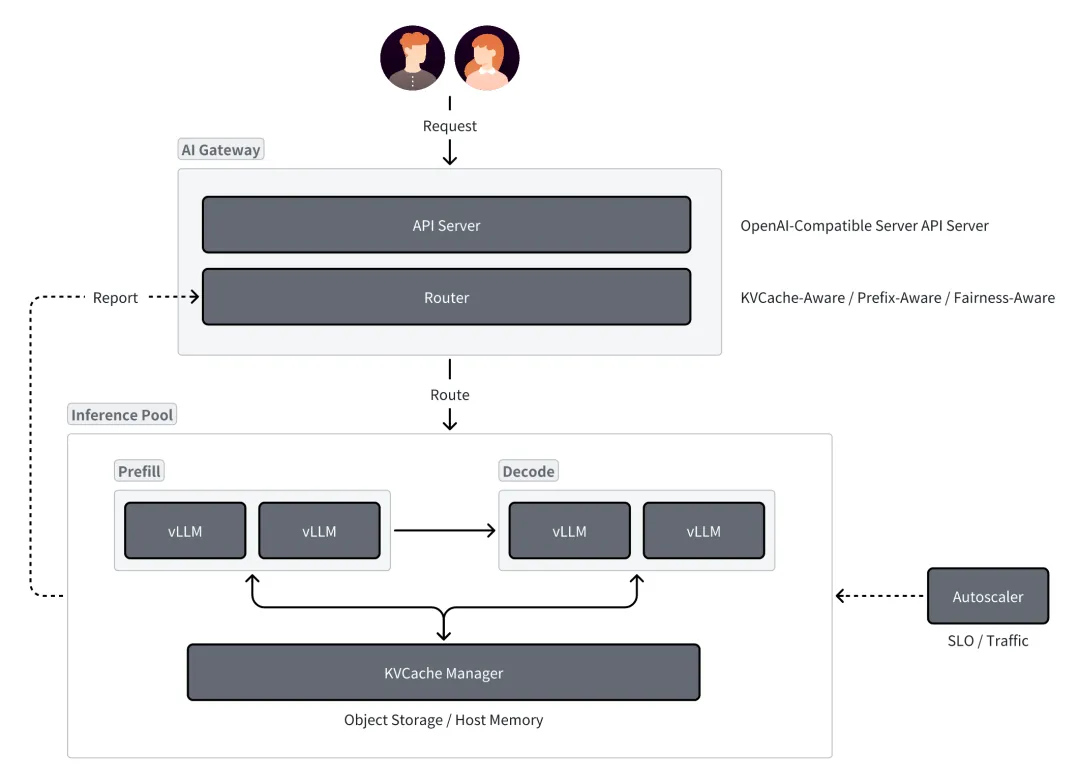
硬件
训练卡和推理卡的需求有什么区别?
- 训练是包括了前向传播,反向传播,和梯度更新三个过程。然而推理实际上是这三个过程中的一个过程,是前向传播,原则上讲这是训练里面的一部分。技术上,从软件的框架和整个软件站的调用,还有一些要用的库上面都是有很大区别的。
- 训练实际上对内存和内存搬运的效率和显存的要求是更高的,因为训练的整个过程中会有很多中间结果要保存,比如说Step One的中间结果要留给Step Two或Step Three去做新的计算,所以这就会导致需要的显存实际上比模型的大小还要大。所以一般的训练卡都需要更好的计算的能力和更大的显存带宽。然后卡的设计从最小的计算单元来看,它是要支持多种精度的,因为训练是要求精度比较高的,这样才能够去做更好的拟合,模型才有更好的表达能力。所以训练的话,就要更好的计算架构设计,要更多的不同精度的计算单元,和更好的显存。推理就不一样,它实际上是在已经训练好的模型里做一个前向传播。现在大模型对推理的显存要求也比较高。它主要占内存的地方,第一个是模型本身,另一个是推理用到的加速技术KV Cache,这个大概是50%-60%的模型大小。这个可以理解为推理的时候保存中间结果就不用再次重新计算,以达到计算更快。
- 推理卡的精度一般以FP16和INT8为主。现在我们看到大模型的参数越来越大,意味着它的功耗和稀疏性越来越强。所谓稀疏性,就是参数越大,当去掉一些参数,整个网络没有什么影响。现在可以在通过推理的时候,用一些结构化或者非结构化稀疏,对大模型做稀疏化,模型就会急速压缩,然后对精度的丢失实际上又比较小。另一个就是做量化,比如本来一个FP32浮点的模型,可以把它量化成FP16的半精度浮点。然而在业务场景其实用的最多的是INT8,所以在推理卡的设计上面,实际上是以INT8为主,半精度为辅。所以这么低精度的这种推理计算,对卡的功耗要求会更低一些。
- 从芯片设计的角度上来说,它的面积也会小很多。比如浮点64位,就是我们说的双精度的计算,同样的算力,它的硅面积是FP32的4倍多,所以在做推理卡的时候,芯片面积实际上是可以控制的,但做训练卡的时候,芯片面积一定会明显大。
提升推理吞吐量(输出第一个 token 后,单个请求每秒输出的 token 数量)有什么用?现在大多数模型输出 token 的速度已经超过用户的阅读速度,那么输出再快一些有多少商业价值。在需要复杂推理的应用中,输出的 token 并不是直接给用户看的,而是思考过程的一部分,这样输出 token 越快,整个推理请求的延迟就越低。
留下评论