gc分析
前言
基本概念
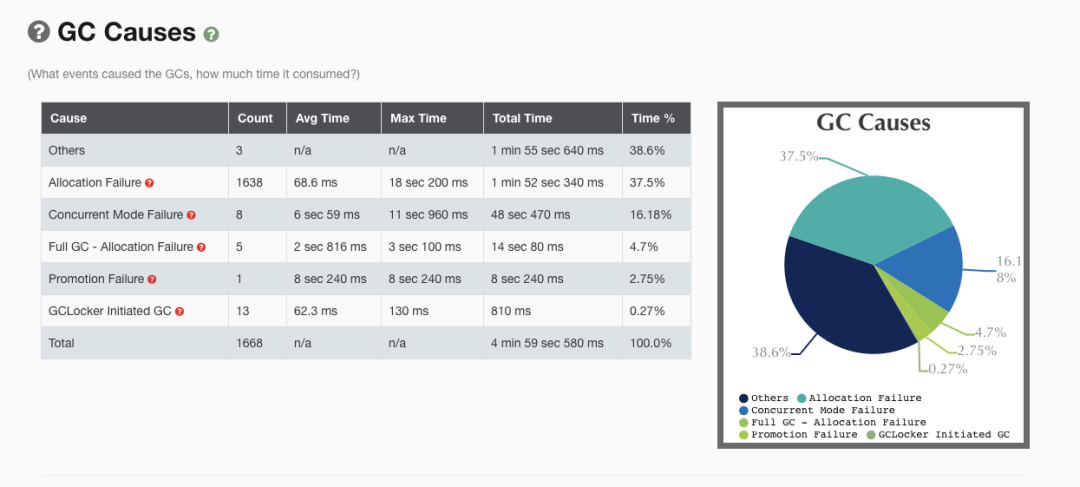
GC Cause
要分析 GC 的问题,先要读懂 GC Cause,即 JVM 什么样的条件下选择进行 GC 操作,具体 Cause 的分类可以看一下 Hotspot 源码:src/share/vm/gc/shared/gcCause.hpp 和 src/share/vm/gc/shared/gcCause.cpp 中。
const char* GCCause::to_string(GCCause::Cause cause) {
switch (cause) {
case _java_lang_system_gc:
return "System.gc()";
case _full_gc_alot:
return "FullGCAlot";
case _scavenge_alot:
return "ScavengeAlot";
case _allocation_profiler:
return "Allocation Profiler";
重点需要关注的几个GC Cause:
- System.gc():手动触发GC操作。
- CMS:CMS GC 在执行过程中的一些动作,重点关注 CMS Initial Mark 和 CMS Final Remark 两个 STW 阶段。
- Promotion Failure:Old 区没有足够的空间分配给 Young 区晋升的对象(即使总可用内存足够大)。
- Concurrent Mode Failure:CMS GC 运行期间,Old 区预留的空间不足以分配给新的对象,此时收集器会发生退化,严重影响 GC 性能
- GCLocker Initiated GC:如果线程执行在 JNI 临界区时,刚好需要进行 GC,此时 GC Locker 将会阻止 GC 的发生,同时阻止其他线程进入 JNI 临界区,直到最后一个线程退出临界区时触发一次 GC。
如下图就是使用 gceasy 绘制的图表:
heap dump
Heap Dump中主要包含当生成快照时堆中的java对象和类的信息,主要分为如下几类:
- 对象信息:类名、属性、基础类型和引用类型
- 类信息:类加载器、类名称、超类、静态属性
- gc roots:JVM中的一个定义,进行垃圾收集时,要遍历可达对象的起点节点的集合
- 线程栈和局部变量:快照生成时候的线程调用栈,和每个栈上的局部变量 Heap Dump中没有包含对象的分配信息,因此它不能用来分析这种问题:一个对象什么时候被创建、一个对象时被谁创建的。
Shallow vs. Retained Heap
Shallow heap是一个对象本身占用的堆内存大小。一个对象中,每个引用占用8或64位,Integer占用4字节,Long占用8字节等等。
Retained set,对于某个对象X来说,它的Retained set指的是——如果X被垃圾收集器回收了,那么这个集合中的对象都会被回收,同理,如果X没有被垃圾收集器回收,那么这个集合中的对象都不会被回收。
Retained heap,对象X的Retained heap指的时候它的Retained set中的所有对象的Shallow si的和,换句话说,Retained heap指的是对象X的保留内存大小,即由于它的存活导致多大的内存也没有被回收。因为对于某个类的所有实例计算总的retained heap非常慢,因此mat中使用者需要手动触发计算。
leading set,对象X可能不止有一个,这些对象统一构成了leading set。如果leading set中的对象都不可达,那么这个leading set对应的retained set中的对象就会被回收。一般有以下几种情况:
- 某个类的所有实例对象,这个类对象就是leading object
- 某个类记载器加载的所有类,以及这些类的实例对象,这个类加载器对象就是leading object
- 一组对象,要达到其他对象的必经路径上的对象,就是leading object
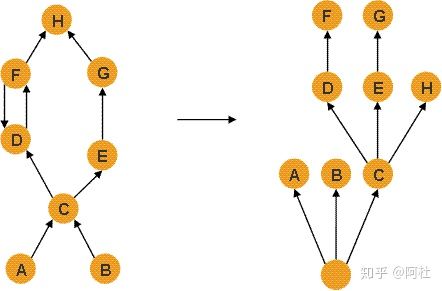
在下面这张图中,A和B是gc roots中的节点(方法参数、局部变量,或者调用了wait()、notify()或synchronized()的对象)等等。可以看出,E的存在,会导致G无法被回收,因此E的Retained set是E和G;C的存在,会导致E、D、F、G、H都无法被回收,因此C的Retined set是C、E、D、F、G、H;A和B的存在,会导致C、E、D、F、G、H都无法被回收,因此A和B的Retained set是A、B、C、E、D、F、G、H。

Dominator Tree
MAT根据堆上的对象引用关系构建了支配树(Dominator Tree),通过支配树可以很方便得识别出哪些对象占用了大量的内存,并可以看到它们之间的依赖关系。
如果在对象图中,从gc root或者x上游的一个节点开始遍历,x是y的必经节点,那么就可以说x支配了y(dominate)。
如果在对象图中,x支配的所有对象中,y的距离最近,那么就可以说x直接支配(immediate dominate)y。
支配树是基于对象的引用关系图建立的,在支配树中每个节点都是它的子节点的直接支配节点。基于支配树可以很清楚得看到对象之间的依赖关系。
现在看个例子,在下面这张图中
- x节点的子树就是所有被x支配的节点集合,也正式x的retained set;
- 如果x是y的直接支配节点,那么x的支配节点也可以支配y
- 支配树中的边跟对象引用图中的引用关系并不是一一对应的。
生成dump 文件
java程序性能分析之thread dump和heap dump
jmap -dump:live,format=b,file=heap.dmp <pid>
dump文件分析工具
jhat
jhat -port 5000 dump文件在浏览器中,通过http://localhost:5000/进行访问 页面底部点击 Show heap histogram
使用 VisualVM 进行性能分析及调优
可以将jvm日志导出来,有专门的线下、线上工具帮你分析日志,生成图表。也可以配置tomcat等打开jmx端口,jvisualvm 连接远程 ip 和 jmx 端口也可进行分析。
mat
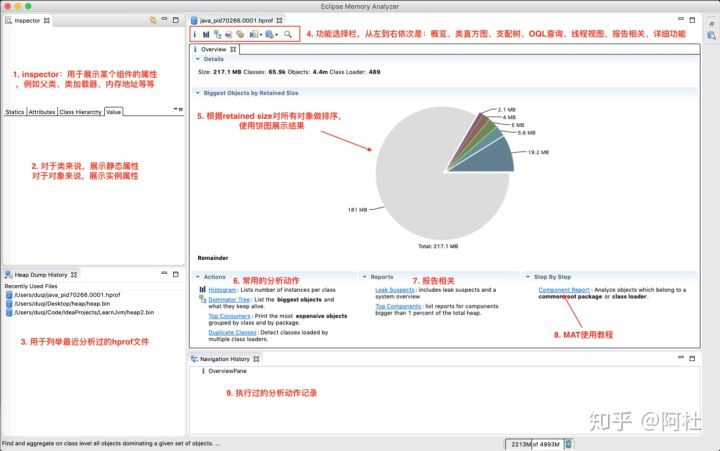
- overview中的饼图:该饼图用于展示retained size最大的对象
- 常用的分析动作:类直方图、支配树、按照类和包路径获取消耗资源最多的对象、重名类。
- 报告相关:Leak Suspects用于查找内存泄漏问题,以及系统概览
- Components Report:这个功能是一组功能的集合,用于分析某一类性的类的实例的问题,例如分析java.util.*开头的类的实例对象的一些使用情况,例如:重复字符串、空集合、集合的使用率、软引用的统计、finalizer的统计、Map集合的碰撞率等等。
- inspector窗口的下半部分是展示类的静态属性和值、对象的实例属性和值、对象所属的类的继承结构。
fullgc 排查实战
当小白遇到FullGC 很经典的一个例子。
某个对象数量太多
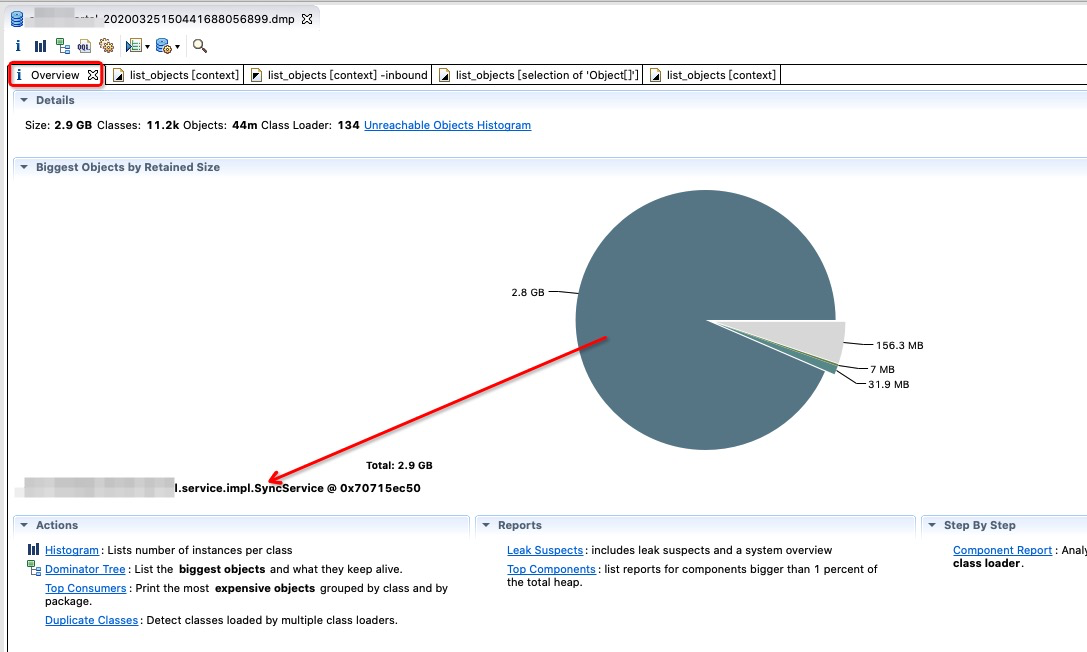
概览中的饼图:该饼图用于展示retained size最大的对象。可以看到最大的就是 SyncService 对象
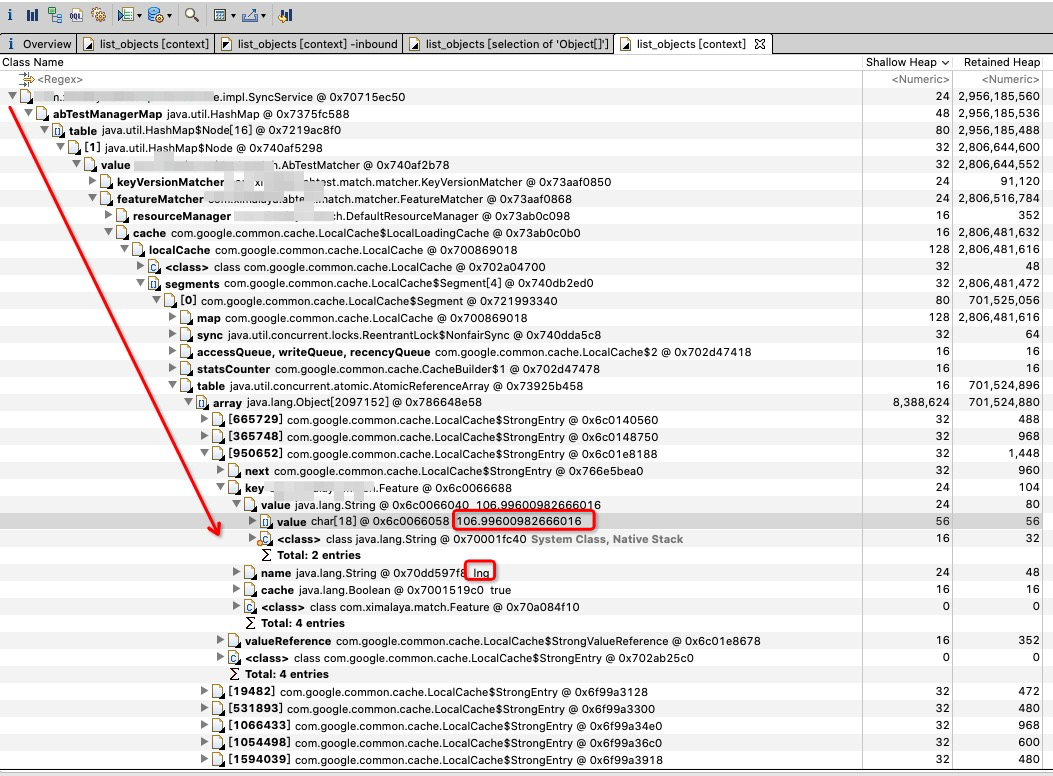
SyncService
abtestManagerMap
table
[1]
value
featureMatcher
cache // guava cache
从SyncService 看下去,占空间最大的是 abTestMangerMap,然后不停的向下,直到一个guava cache 对象,由几个segments 组成(就像ConcurrentHashMap是分段一样),每个segment 有table ,table 有array 可以观察其数量非常大。
yonnggc 太多进而导致 fullgc太多
-
使用VisualVM 可以确认字符串是最多的。发现一个奇怪的现象:“计算保留大小”之后,这些String的保留大小都是0。使用VisualVM 显示最近的垃圾回收根节点,发现都找不到。
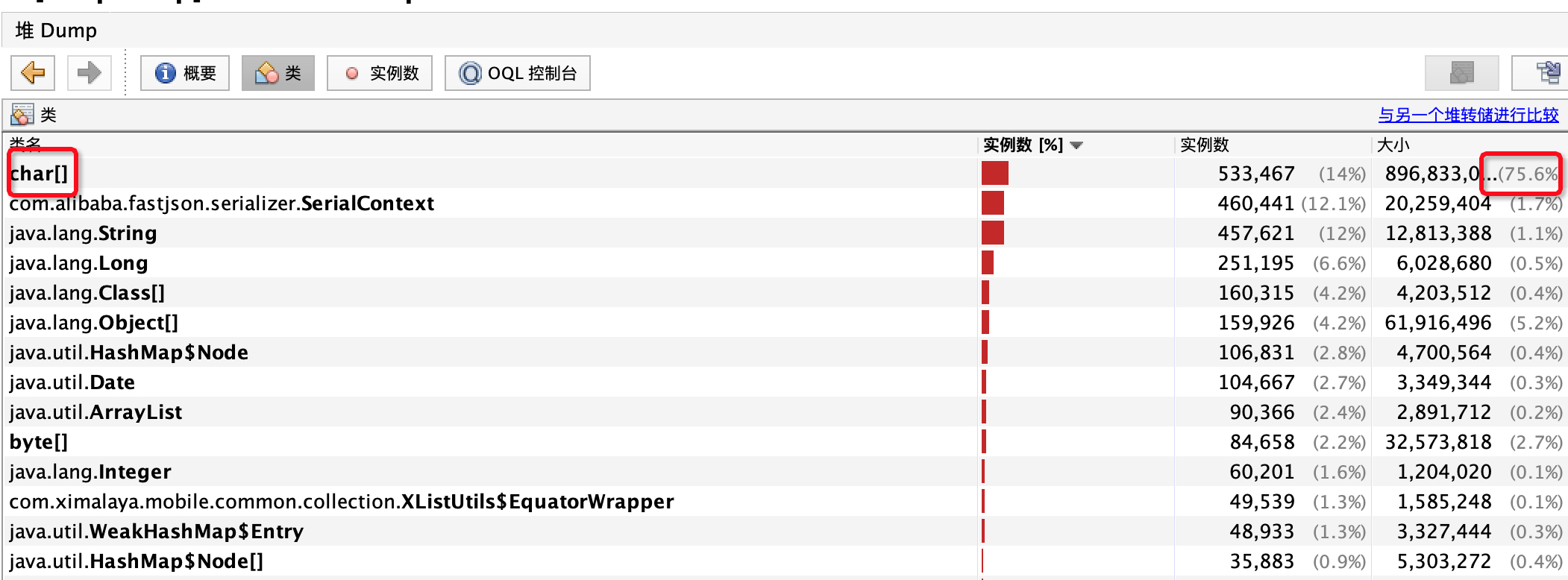
- 使用MAT 寻找内存较大的对象。但意外发现size 只有4xxM。
- MAT的主要目标是排查内存占用量,所以默认大小是不计算不可达对象的。在”Preferences=>Memory Analyzer”中勾选”Keep Unreachable Objects”,关闭mat,删除索引文件Dump同路径下的所有”.index”文件,启动mat,即可看到所有的对象。
- overview 发现size 有1GB
- 保留大小是什么呢?它是分析工具从GC roots开始查找,找到的所有不会回收的对象,然后按照引用关系,计算出这个“对象以及它引用的对象”的内存大小。结合以上现象:这些大String是临时对象,没有什么对象持有它——通过分析这些String的依赖关系也说明了这一点。这些对象是可以被回收的,换句话说,并不是有明显的内存泄露。只是对象大 + 写入太快 导致了频繁的younggc,younggc 忙不过来年轻代满了 新的String 就进入老年代,然后引发fullgc。
- 这些字符串是什么呢?
-
点击Histogram,即可看到类的占用。在类上选择”List Objects”,即可看到所有对象。
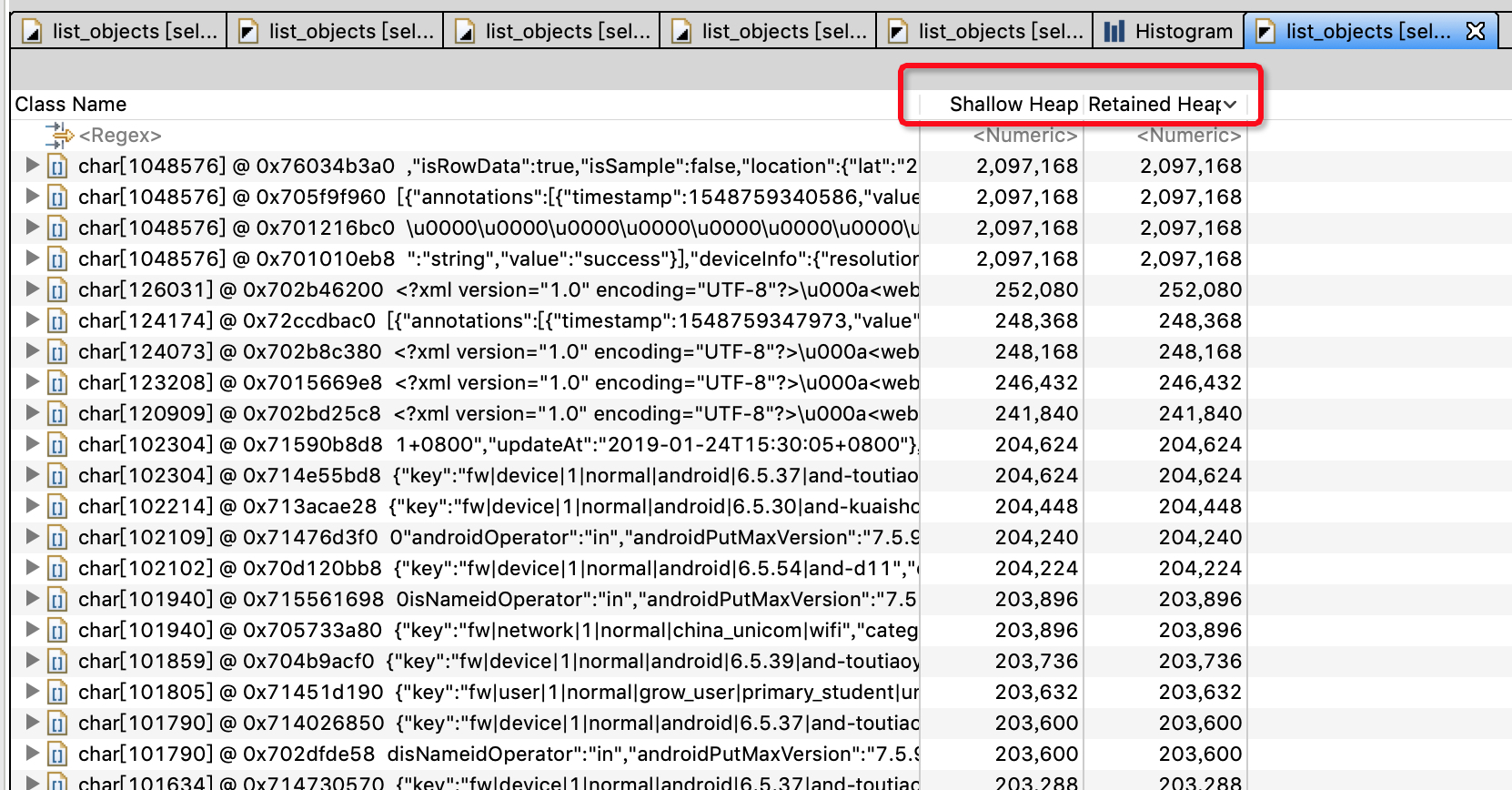
retained heap 从高到低排列
- 在对象上选择”Copy=>Value to File”,即可保存到文件。查看文件内容 是一个对象json 后的内容
- 在代码中有大量的
log.debug(JSON.toJSONString(obj));,obj 在一些场景下会很大。而虽然日志级别是info,debug 日志不会打印。但按照log.debug的实现,是先执行JSON.toJSONString(obj),然后判断debug 日志无需输出,因此还是会频繁的执行JSON.toJSONString(obj) - 解决这个问题参见 log4j学习
mat 线程视图
heap dump和MAT不仅仅用于排查内存相关的问题,也有助于排查线程相关的问题。
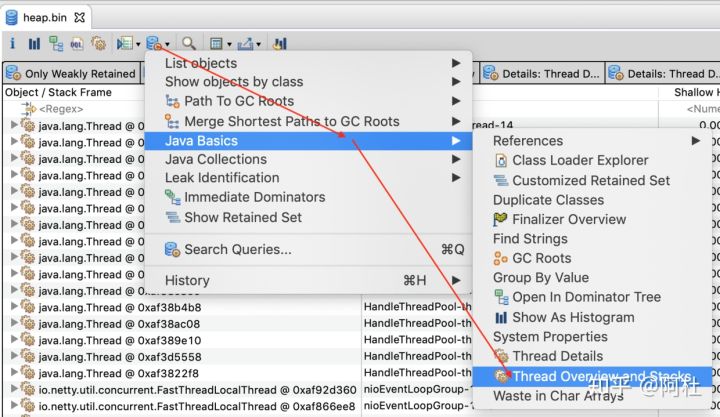
通过上图中的那个按钮,可以查看线程视图,线程视图首先给出了在生成快照那个时刻,JVM中的Java线程对象列表。
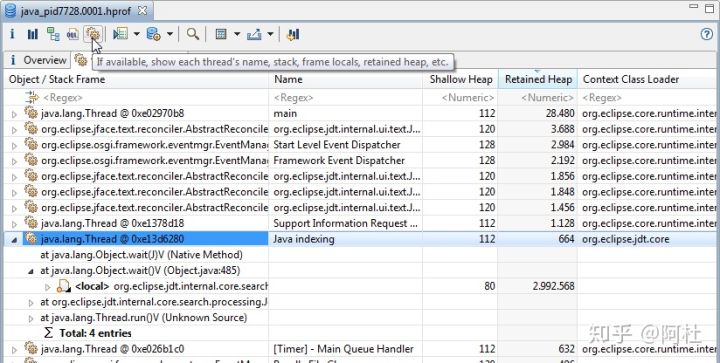
在线程视图这个表中,可以看到以下几个信息:线程对象的名字、线程名、线程对象占用的堆内存大小、线程对象的保留堆内存大小、线程的上下文加载器、是否为守护线程。
选中某个线程对象展开,可以看到线程的调用栈和每个栈的局部变量,通过查看线程的调用栈和局部变量的内存大小,可以找到在哪个调用栈里分配了大量的内存。
jstack thread dump
java程序性能分析之thread dump和heap dump
thread dump文件主要保存的是java应用中各线程在某一时刻的运行的位置,即执行到哪一个类的哪一个方法哪一个行上。thread dump是一个文本文件,打开后可以看到每一个线程的执行栈,以stacktrace的方式显示。通过对thread dump的分析可以得到应用是否“卡”在某一点上,即在某一点运行的时间太长,如数据库查询,长期得不到响应,最终导致系统崩溃。单个的thread dump文件一般来说是没有什么用处的,因为它只是记录了某一个绝对时间点的情况。比较有用的是,线程在一个时间段内的执行情况。
两个thread dump文件在分析时特别有效,困为它可以看出在先后两个时间点上,线程执行的位置,如果发现先后两组数据中同一线程都执行在同一位置,则说明此处可能有问题,因为程序运行是极快的,如果两次均在某一点上,说明这一点的耗时是很大的。通过对这两个文件进行分析,查出原因,进而解决问题。
jstack 2576 > thread.txt
Java内存泄漏分析系列之四:jstack生成的Thread Dump日志线程状态 是一个系列,建议结合java线程的状态转换图 一起看。一个thread dump文件部分示例如下:
"resin-22129" daemon prio=10 tid=0x00007fbe5c34e000 nid=0x4cb1 waiting on condition [0x00007fbe4ff7c000]
java.lang.Thread.State: WAITING (parking)
at sun.misc.Unsafe.park(Native Method)
at java.util.concurrent.locks.LockSupport.park(LockSupport.java:315)
at com.caucho.env.thread2.ResinThread2.park(ResinThread2.java:196)
at com.caucho.env.thread2.ResinThread2.runTasks(ResinThread2.java:147)
at com.caucho.env.thread2.ResinThread2.run(ResinThread2.java:118)
留下评论