Linux2.1.13网络源代码学习
简介
以下来自linux1.2.13源码,算是参见Linux1.0的学习笔记。
源码目录
linux-1.2.13
|
|---net
|
|---protocols.c
|---socket.c
|---unix
| |
| |---proc.c
| |---sock.c
| |---unix.h
|---inet
|
|---af_inet.c
|---arp.h,arp.c
|---...
|---udp.c,utils.c
其中 unix 子文件夹中三个文件是有关 UNIX 域代码, UNIX 域是模拟网络传输方式在本机范围内用于进程间数据传输的一种机制。
系统调用通过 INT $0x80 进入内核执行函数,该函数根据 AX 寄存器中的系统调用号,进一步调用内核网络栈相应的实现函数。
网络分层
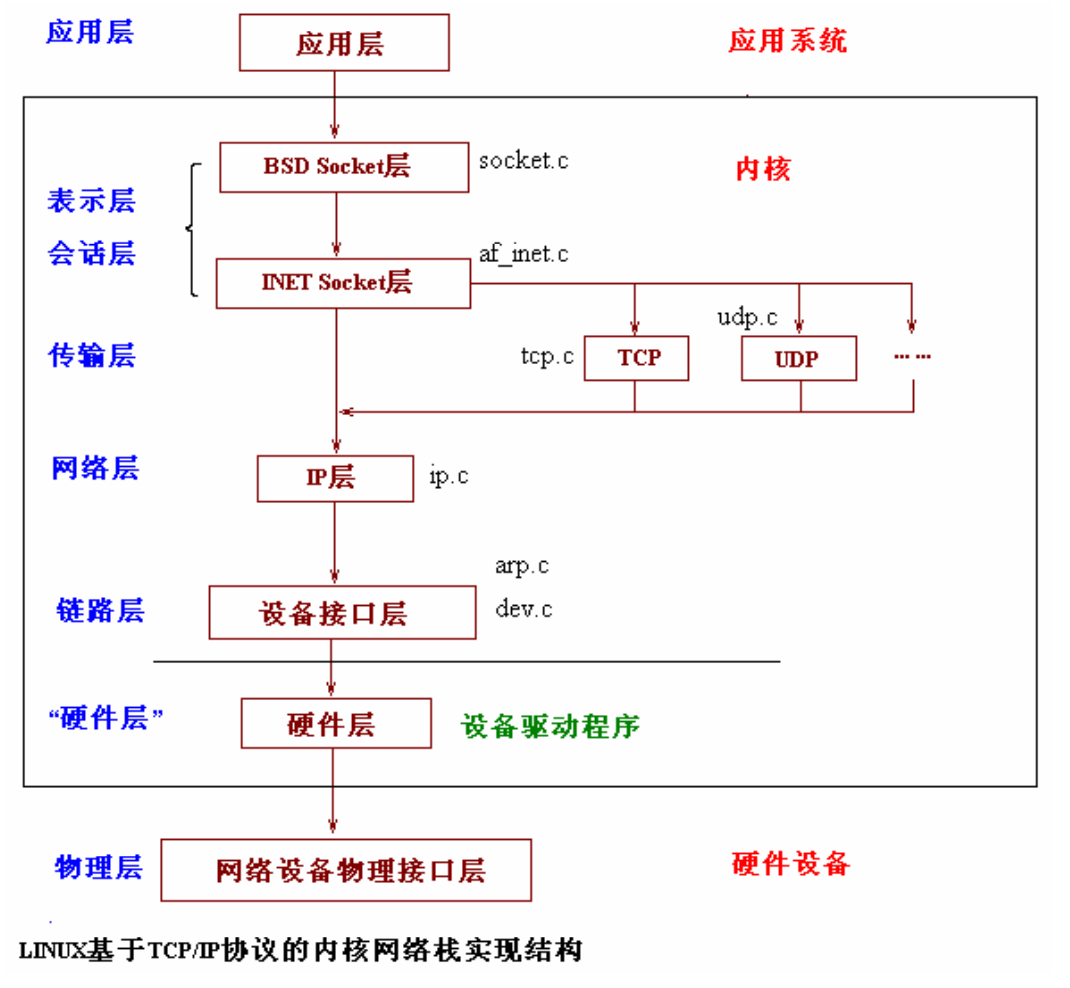
从这个图中,可以看到,到传输层时,横生枝节,代码不再针对任何数据包都通用。从下到上,收到的数据包由哪个传输层协议处理,根据从数据包传输层header中解析的数据确定。从上到下,数据包的发送使用什么传输层协议,由socket初始化时确定。
- vfs层
- socket 是用于负责对上给用户提供接口,并且和文件系统关联。应用程序通过读写收、发缓冲区(Receive/Send Buffer)来与 Socket 进行交互。
- sock,负责向下对接内核网络协议栈
- tcp层 和 ip 层, linux 1.2.13相关方法都在 tcp_prot中。在高版本linux 中,sock 负责tcp 层, ip层另由struct inet_connection_sock 和 icsk_af_ops 负责。分层之后,诸如拥塞控制和滑动窗口的 字段和方法就只体现在struct sock和tcp_prot中,代码实现与tcp规范设计是一致的
- ip层 负责路由等逻辑,并执行nf_hook,也就是netfilter。netfilter是工作于内核空间当中的一系列网络(TCP/IP)协议栈的钩子(hook),为内核模块在网络协议栈中的不同位置注册回调函数(callback)。也就是说,在数据包经过网络协议栈的不同位置时做相应的由iptables配置好的处理逻辑。
- link 层,先寻找下一跳(ip ==> mac),有了 MAC 地址,就可以调用 dev_queue_xmit发送二层网络包了,它会调用 __dev_xmit_skb 会将请求放入块设备的队列。同时还会处理一些vlan 的逻辑
- 设备层:网卡是发送和接收网络包的基本设备。在系统启动过程中,网卡通过内核中的网卡驱动程序注册到系统中。而在网络收发过程中,内核通过中断跟网卡进行交互。网络包的发送会触发一个软中断 NET_TX_SOFTIRQ 来处理队列中的数据。这个软中断的处理函数是 net_tx_action。在软中断处理函数中,会将网络包从队列上拿下来,调用网络设备的传输函数 ixgb_xmit_frame,将网络包发的设备的队列上去。
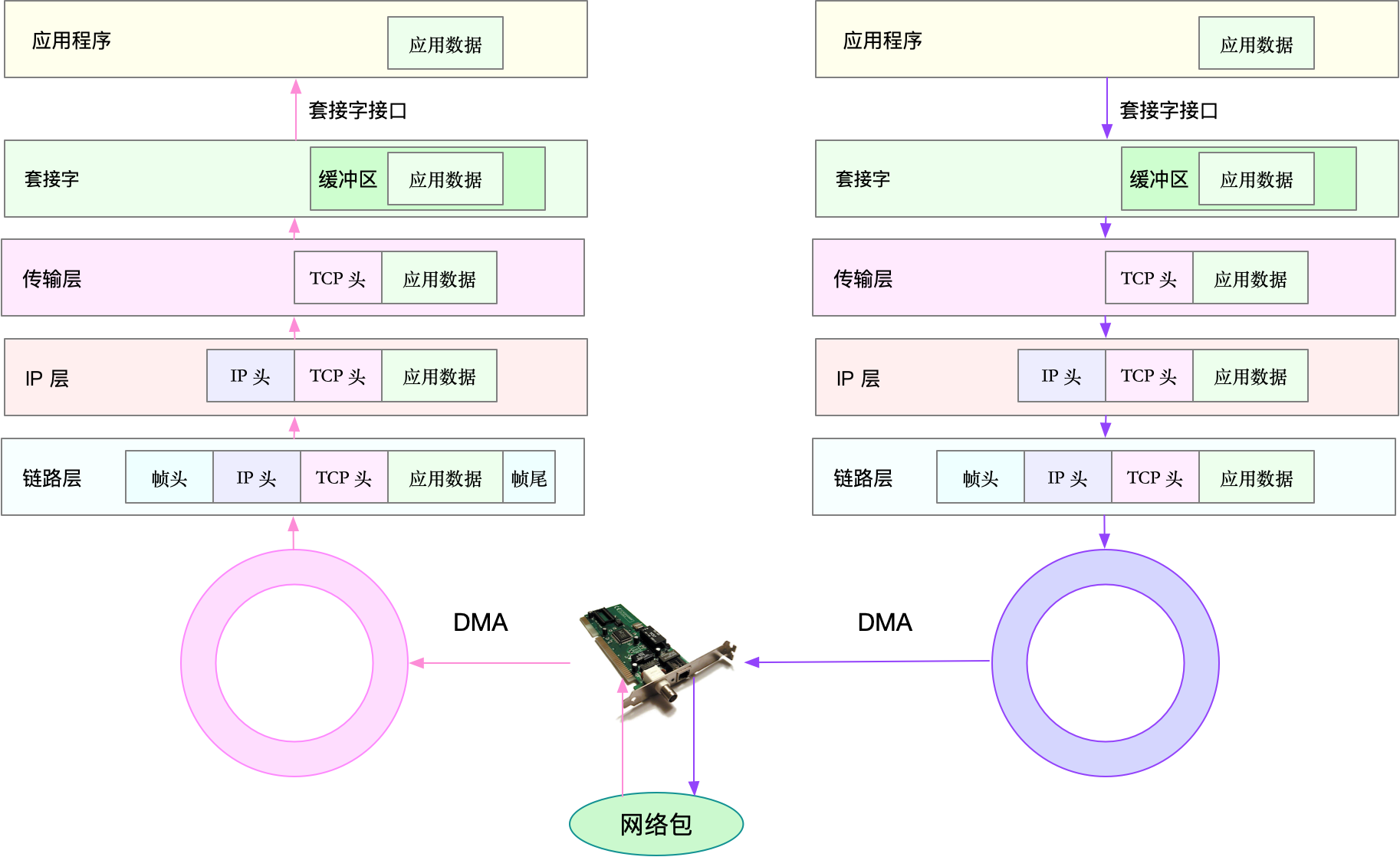
网卡中断处理程序为网络帧分配的,内核数据结构 sk_buff 缓冲区;是一个维护网络帧结构的双向链表,链表中的每一个元素都是一个网络帧(Packet)。虽然 TCP/IP 协议栈分了好几层,但上下不同层之间的传递,实际上只需要操作这个数据结构中的指针,而无需进行数据复制。
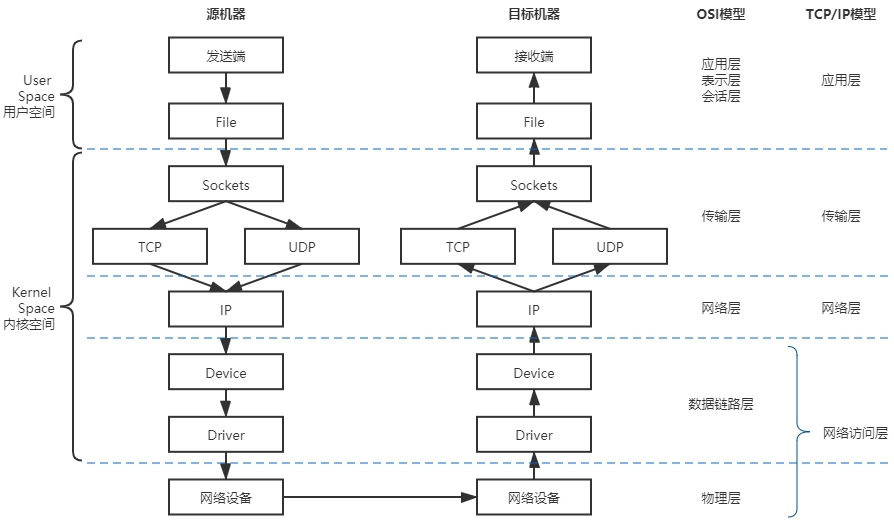
数据结构
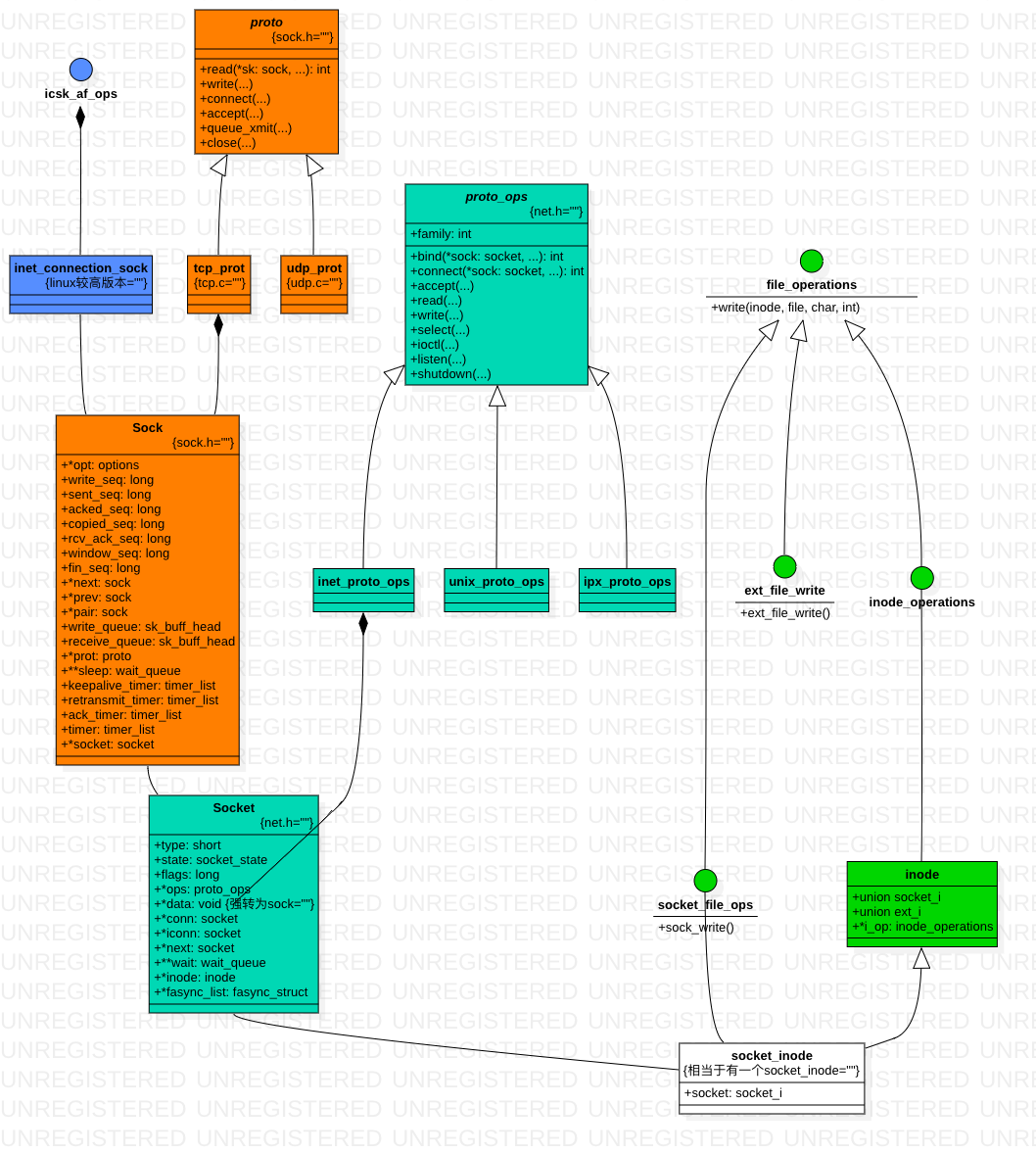
套接字
每个程序使用的套接字都有一个 struct socket 数据结构与 struct sock 数据结构的实例,socket 与sock 一一对应。
struct socket {
socket_state state; // 套接字的状态
unsigned long flags; // 套接字的设置标志。存放套接字等待缓冲区的状态信息,其值的形式如SOCK_ASYNC_NOSPACE等
struct fasync_struct *fasync_list; // 等待被唤醒的套接字列表,该链表用于异步文件调用
struct file *file; // 套接字所属的文件描述符
struct sock *sk; // 指向存放套接字属性的结构指针
wait_queue_head_t wait; //套接字的等待队列
short type; // 套接字的类型。其取值为SOCK_XXXX形式
const struct proto_ops *ops; // 套接字层的操作函数块
}
struct sock {
...
struct sk_buff_head write_queue, receive_queue;
...
}
服务器端只有一个端口,收发请求不会乱吗?内核在接收到网络包的时候,在协议栈处理的时候会解析包头,根据这个包头中完整的四元组和内核中 hashtable 中管理的 socket 进行匹配,只有四元组信息完全一致,才能把接收到的数据放到该 socket 的接收队列中。
套接字与vfs
套接字的连接建立起来后,用户进程就可以使用常规文件操作访问套接字了。每个套接字都分配了一个该类型的 inode,inode 和 socket 的链接是通过直接分配一个辅助数据结构来socket_slloc实现的
struct socket_slloc {
struct socket socket;
struct inode vfs_inode;
}
VFS为文件系统抽象了一套API,实现了该系列API就可以把对应的资源当作文件使用,当调用socket函数的时候,我们拿到的不是socket本身,而是一个文件描述符fd。
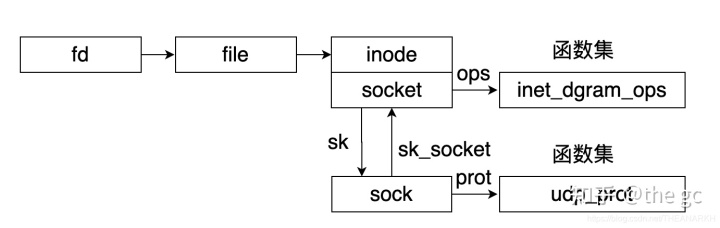
从linux5.9看网络层的设计整个网络层的实际中,主要分为socket层、af_inet层和具体协议层(TCP、UDP等)。当使用网络编程的时候,首先会创建一个socket结构体(socket层),socket结构体是最上层的抽象,然后通过协议簇类型创建一个对应的sock结构体,sock是协议簇抽象(af_inet层),同一个协议簇下又分为不同的协议类型,比如TCP、UDP(具体协议层),然后根据socket的类型(流式、数据包)找到对应的操作函数集并赋值到socket和sock结构体中,后续的操作就调用对应的函数就行,调用某个网络函数的时候,会从socket层到af_inet层,af_inet做了一些封装,必要的时候调用底层协议(TCP、UDP)对应的函数。而不同的协议只需要实现自己的逻辑就能加入到网络协议中。
file_operations 结构定义了普通文件操作函数集。系统中每个文件对应一个 file 结构, file 结构中有一个 file_operations 变量,当使用 write,read 函数对某个文件描述符进行读写操作时,系统首先根据文件描述符索引到其对应的 file 结构,然后调用其成员变量 file_operations 中对应函数完成请求。
// 参见socket.c
static struct file_operations socket_file_ops = {
sock_lseek, // δʵÏÖ
sock_read,
sock_write,
sock_readdir, // δʵÏÖ
sock_select,
sock_ioctl,
NULL, /* mmap */
NULL, /* no special open code... */
sock_close,
NULL, /* no fsync */
sock_fasync
};
以上 socket_file_ops 变量中声明的函数即是网络协议对应的普通文件操作函数集合。从而使得read, write, ioctl 等这些常见普通文件操作函数也可以被使用在网络接口的处理上。kernel维护一个struct file list,通过fd ==> struct file ==> file->ops ==> socket_file_ops,便可以以文件接口的方式进行网络操作。同时,每个 file 结构都需要有一个 inode 结构对应。用于存储struct file的元信息
struct inode{
...
union {
...
struct ext_inode_info ext_i;
struct nfs_inode_info nfs_i;
struct socket socket_i;
}u
}
也就是说,对linux系统,一切皆文件,由struct file描述,通过file->ops指向具体操作,由file->inode 存储一些元信息。对于ext文件系统,是载入内存的超级块、磁盘块等数据。对于网络通信,则是待发送和接收的数据块、网络设备等信息。从这个角度看,struct socket和struct ext_inode_info 等是类似的。
sk_buff结构
当在内核中对数据包进行时,内核还需要一些其他的数据来管理数据包和操作数据包(就像加入jvm堆的数据必须有mark word一样),例如协议之间的交换信息,数据的状态,时间等。在发送数据时,在套接字层创建了 Socket Buffer 缓冲区与管理数据结构,存放来自应用程序的数据。在接收数据包时,Socket Buffer 则在网络设备的驱动程序中创建,存放来自网络的数据。在发送和接受数据的过程中,各层协议的头信息会不断从数据包中插入和去掉,sk_buff 结构中描述协议头信息的地址指针也会被不断地赋值和复位。
sk_buff部分字段如下,
struct sk_buff {
/* These two members must be first. */
struct sk_buff *next;
struct sk_buff *prev;
struct sk_buff_head *list;
struct sock *sk;
struct timeval stamp;
struct net_device *dev;
struct net_device *real_dev;
union {
struct tcphdr *th;
struct udphdr *uh;
struct icmphdr *icmph;
struct igmphdr *igmph;
struct iphdr *ipiph;
unsigned char *raw;
} h; // Transport layer header
union {
struct iphdr *iph;
struct ipv6hdr *ipv6h;
struct arphdr *arph;
unsigned char *raw;
} nh; // Network layer header
union {
struct ethhdr *ethernet;
unsigned char *raw;
} mac; // Link layer header
struct dst_entry *dst;
struct sec_path *sp;
void (*destructor)(struct sk_buff *skb);
/* These elements must be at the end, see alloc_skb() for details. */
unsigned int truesize;
atomic_t users;
unsigned char *head,
*data,
*tail,
*end;
};
head和end字段指向了buf的起始位置和终止位置。然后使用header指针指像各种协议填值。然后data就是实际数据。tail记录了数据的偏移值。
sk_buff 是各层通用的,在应用层数据包叫 data,在 TCP 层我们称为 segment,在 IP 层我们叫 packet,在数据链路层称为 frame。下层协议将上层协议数据作为data部分,并加上自己的header。这也是为什么代码注释中说,哪些字段必须在最前,哪些必须在最后, 这个其中的妙处可以自己体会。
sk_buff由sk_buff_head组织
struct sk_buff_head {
struct sk_buff * volatile next;
struct sk_buff * volatile prev;
#if CONFIG_SKB_CHECK
int magic_debug_cookie;
#endif
};
TCP/IP 协议栈处理完输入数据包后,将数据包交给套接字层,放在套接字的接收缓冲区队列(sk_rcv_queue)。然后数据包从套接字层离开内核,送给应用层等待数据包的用户程序。用户程序向外发送的数据包缓存在套接字的传送缓冲区队列(sk_write_queue),从套接字层进入内核地址空间。
网络协议栈实现——数据struct 和 协议struct
socket分为多种,除了inet还有unix。反应在代码结构上,就是net包下只有net/unix,net/inet两个文件夹。之所以叫unix域,可能跟描述其地址时,使用unix://xxx有关
The difference is that an INET socket is bound to an IP address-port tuple, while a UNIX socket is “bound” to a special file on your filesystem. Generally, only processes running on the same machine can communicate through the latter.
本文重点是inet,net/inet下有以下几个比较重要的文件,这跟网络书上的知识就对上了。
arp.c
eth.c
ip.c
route.c
tcp.c
udp.c
datalink.h // 应该是数据链路层
| 数据struct | 数据struct 例子 | 协议struct | 协议struct例子 | ||
|---|---|---|---|---|---|
| 应用层 | struct file | struct file_operations | struct socket_file_ops | ||
| bsd socket 层 | struct socket,struct sk_buff | struct proto_ops,struct net_proto(for init) | inet,unix,ipx等 | ||
| inet socket 层 | struct sock | struct prot | tcp_prot,udp_prot,raw_prot | ||
| 传输层 | struct inet_protocol | tcp_protocol,udp_protocol ,icmp_protocol,igmp_protocol | |||
| 网络层 | struct packet_type | ip_packet_type,arp_packet_type | |||
| 链路层 | device | loopback_dev | |||
| 硬件层 |
怎么理解整个表格呢?协议struct和数据struct有何异同?
- struct一般由一个数组或链表组织,数组用index,链表用header(比如packet_type_base、inet_protocol_base)指针查找数据。
- 协议struct是怎么回事呢?通常是一个函数操作集,类似于controller-server-dao之间的interface定义,类似于本文开头的file_operations,有open、close、read等方法,但对ext是一回事,对socket操作是另一回事。
- 数据struct实例可以有很多,比如一个主机有多少个连接就有多少个struct sock,而协议struct个数由协议类型个数决定,具体的协议struct比如tcp_prot就只有一个。比较特别的是,通过tcp_prot就可以找到所有的struct sock实例。
- socket、sock、device等数据struct经常被作为分析的重点,其实各种协议struct 才是流程的关键,并且契合了网络协议分层的理念。
以ip.c为例,在该文件中定义了ip_rcv(读数据)、ip_queue_xmit(用于写数据),链路层收到数据后,通过ptype_base找到ip_packet_type,进而执行ip_rcv。tcp发送数据时,通过tcp_proto找到ip_queue_xmit并执行。
tcp_protocol是为了从下到上的数据接收,其函数集主要是handler、frag_handler和err_handler,对应数据接收后的处理。tcp_prot是为了从上到下的数据发送(所以struct proto没有icmp对应的结构),其函数集connect、read等主要对应上层接口方法。
到bsd socket层,相关的结构在/include/linux下定义,而不是在net包下。这就对上了,bsd socket是一层接口规范,而net包下的相关struct则是linux自己的抽象了。
主要要搞清楚三个问题,具体可以参见相关的书籍,此处不详述。参见Linux1.0中的Linux1.2.13内核网络栈源码分析的第四章节。
- 这些结构如何初始化。有的结构直接就是定义好的,比如tcp_protocol等
- 如何接收数据。由中断程序触发。接收数据的时候,可以得到device,从数据中可以取得协议数据,进而从ptype_base及inet_protocol_base执行相应的rcv
- 如何发送数据。通常不直接发送,先发到queue里。可以从socket初始化时拿到protocol类型(比如tcp)、目的ip,通过route等决定device,于是一路向下执行xx_write方法
linux1.2.13
首先,我们从device struct开始。struct反映了很多东西,比如看一下linux的进程struct,就很容易理解进程为什么能干那么多事情。
linux会维护一个device struct list,通过它能找到所有的网络设备。device struct 和设备不是一对一关系。
include/linux/netdevice.h
struct device{
/*
* This is the first field of the "visible" part of this structure
* (i.e. as seen by users in the "Space.c" file). It is the name
* the interface.
*/
char *name;
/* I/O specific fields - FIXME: Merge these and struct ifmap into one */
unsigned long rmem_end; /* shmem "recv" end */
unsigned long rmem_start; /* shmem "recv" start */
unsigned long mem_end; /* shared mem end */
unsigned long mem_start; /* shared mem start */
// device 只是一个struct,可能几个struct共用一个物理网卡
unsigned long base_addr; /* device I/O address */
// 赋给中断号
unsigned char irq; /* device IRQ number */
/* Low-level status flags. */
volatile unsigned char start, /* start an operation */
tbusy, /* transmitter busy */
interrupt; /* interrupt arrived */
struct device *next;
/* The device initialization function. Called only once. */
// 初始化函数
int (*init)(struct device *dev);
/* Some hardware also needs these fields, but they are not part of the
usual set specified in Space.c. */
unsigned char if_port; /* Selectable AUI, TP,..*/
unsigned char dma; /* DMA channel */
struct enet_statistics* (*get_stats)(struct device *dev);
/*
* This marks the end of the "visible" part of the structure. All
* fields hereafter are internal to the system, and may change at
* will (read: may be cleaned up at will).
*/
/* These may be needed for future network-power-down code. */
unsigned long trans_start; /* Time (in jiffies) of last Tx */
unsigned long last_rx; /* Time of last Rx */
unsigned short flags; /* interface flags (a la BSD) */
unsigned short family; /* address family ID (AF_INET) */
unsigned short metric; /* routing metric (not used) */
unsigned short mtu; /* interface MTU value */
unsigned short type; /* interface hardware type */
unsigned short hard_header_len; /* hardware hdr length */
void *priv; /* pointer to private data */
/* Interface address info. */
unsigned char broadcast[MAX_ADDR_LEN]; /* hw bcast add */
unsigned char dev_addr[MAX_ADDR_LEN]; /* hw address */
unsigned char addr_len; /* hardware address length */
unsigned long pa_addr; /* protocol address */
unsigned long pa_brdaddr; /* protocol broadcast addr */
unsigned long pa_dstaddr; /* protocol P-P other side addr */
unsigned long pa_mask; /* protocol netmask */
unsigned short pa_alen; /* protocol address length */
struct dev_mc_list *mc_list; /* Multicast mac addresses */
int mc_count; /* Number of installed mcasts*/
struct ip_mc_list *ip_mc_list; /* IP multicast filter chain */
/* For load balancing driver pair support */
unsigned long pkt_queue; /* Packets queued */
struct device *slave; /* Slave device */
// device的数据缓冲区
/* Pointer to the interface buffers. */
struct sk_buff_head buffs[DEV_NUMBUFFS];
/* Pointers to interface service routines. */
// 打开设备
int (*open)(struct device *dev);
// 关闭设备
int (*stop)(struct device *dev);
// 调用具体的硬件将数据发到物理介质上,网络栈最终调用它发数据
int (*hard_start_xmit) (struct sk_buff *skb, struct device *dev);
int (*hard_header) (unsigned char *buff,struct device *dev,unsigned short type,void *daddr,void *saddr,unsigned len,struct sk_buff *skb);
int (*rebuild_header)(void *eth, struct device *dev,unsigned long raddr, struct sk_buff *skb);
unsigned short (*type_trans) (struct sk_buff *skb, struct device *dev);
#define HAVE_MULTICAST
void (*set_multicast_list)(struct device *dev, int num_addrs, void *addrs);
#define HAVE_SET_MAC_ADDR
int (*set_mac_address)(struct device *dev, void *addr);
#define HAVE_PRIVATE_IOCTL
int (*do_ioctl)(struct device *dev, struct ifreq *ifr, int cmd);
#define HAVE_SET_CONFIG
int (*set_config)(struct device *dev, struct ifmap *map);
};
耐心的看完这个结构体,网络部分的初始化就是围绕device struct的创建及其中字段(和函数)的初始化.
linux内核与网络驱动程序的边界:linux内核准备好device struct和dev_base指针(这句不准确,或许是ethdev_index[]),kernel启动时,执行驱动程序事先挂好的init函数,init函数初始化device struct并挂到dev_base上(或ethdev_index上)。
ei开头的都是驱动程序自己的函数。
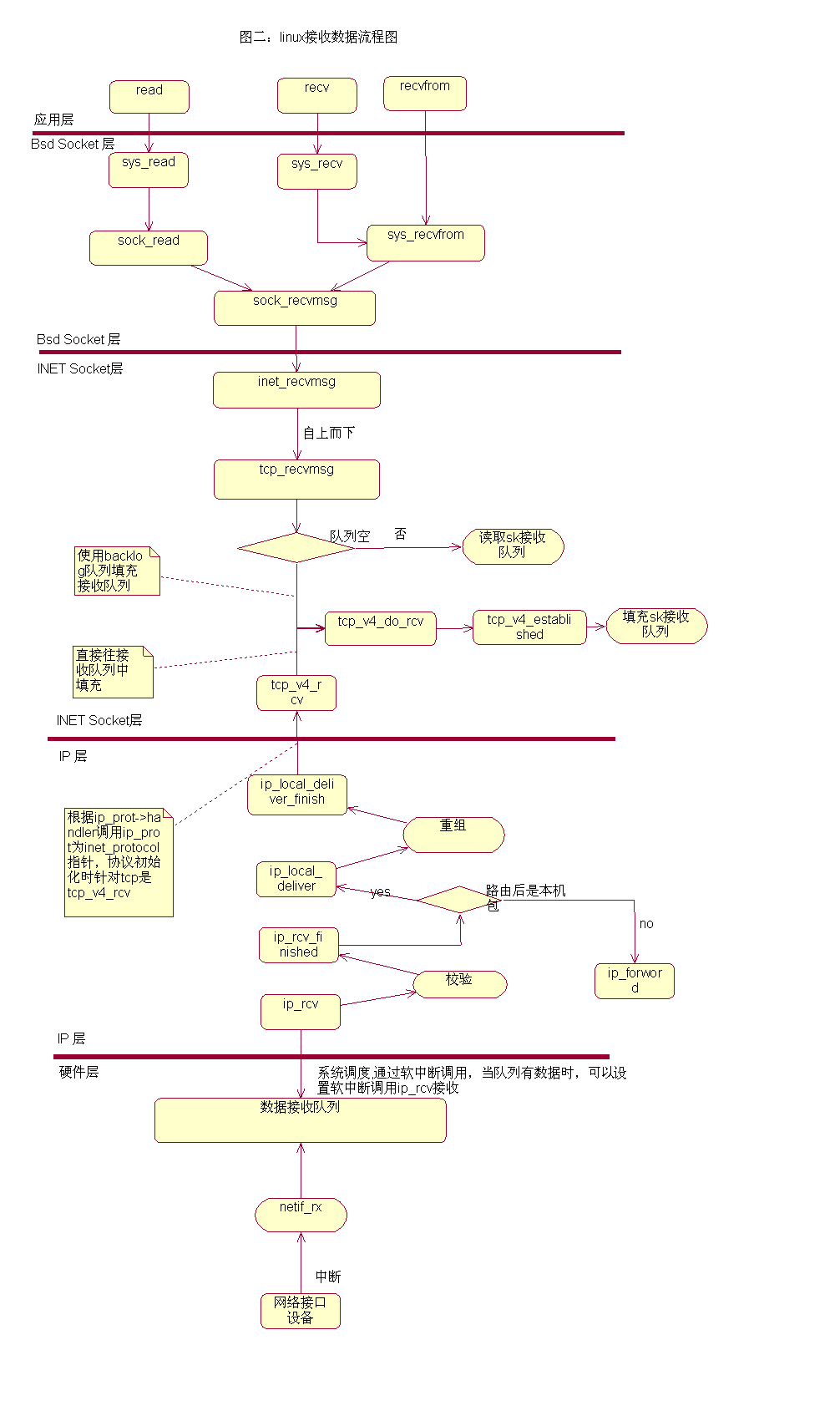
接收数据
device struct 初始化时,会为这个设备生成一个irq(中断号),为irq其绑定ei_interrutp(网卡的中断处理函数),同时会建立一个irq与device的映射。接收到数据后,触发ei_interrutp, ei_interrutp根据中断号得到device,执行ei_receive(device), ei_receive 将数据拷贝到 数据接收队列(元素为 sk_buff,具有prev和next指针,struct device 维护了 sk_buff_head),执行内核的netif_rx,netif_rx 触发软中断 执行net_bh,net_bh 遍历 packet_type list 查看数据 符合哪个协议(不是每次都遍历),执行packet_type.func将数据包传递给网络层协议接收函数,packet_type.func 的可选值 arp_rcv,ip_rcv. ip_rcv中带有device 参数,用于校验数据包的mac 地址是否在 device.mc_list 之内,及检查是否开启IP_FORWARD等。

收到数据包的几种情况
- 来的网络包正是服务端期待的下一个网络包 seq = rcv_nxt
- end_seq < rcv_nxt 服务端期待 5,但来了一个3,说明3和4的ack 客户端没有收到,服务端应重新发送
- seq 不小于 rcv_nxt + tcp_receive_window,说明客户端发送得太猛了。本来 seq 肯定应该在接收窗口里面的,这样服务端才来得及处理,结果现在超出了接收窗口,说明客户端一下子把服务端给塞满了。这种情况下,服务端不能再接收数据包了,只能发送 ACK了,在 ACK 中会将接收窗口为 0 的情况告知客户端,客户就知道不能再发送了。这个时候双方只能交互窗口探测数据包,直到服务端因为用户进程把数据读走了,空出接收窗口,才能在 ACK里面再次告诉客户端,又有窗口了,又能发送数据包了。
- seq < rcv_nxt 但 end_seq > rcv_nxt,说明从 seq 到 rcv_nxt 这部分网络包原来的 ACK 客户端没有收到,所以客户端重新发送了一次,从 rcv_nxt到 end_seq 时新发送的
- 乱序包。正常情况下,发送端的报文是按照先后顺序发送的,如果到了接收端发生了乱序,那么很可能是中间设备出现了问题,比如中间的交换机路由器(以及这节课的主角防火墙)做了一些处理,引发了报文乱序。乱序给接收端重组报文带来了困难,因为接收端必须等这些报文全部都收到并组装成连续数据后,才能通知用户空间程序来读取。那么自然地,乱序也容易引发应用层异常。
Socket 读取
- VFS 层:read 系统调用找到 struct file,根据里面的 file_operations 的定义,调用 sock_read_iter 函数。sock_read_iter 函数调用 sock_recvmsg 函数
- Socket 层:从 struct file 里面的 private_data 得到 struct socket,根据里面 ops 的定义,调用 inet_recvmsg 函数
- Sock 层:从 struct socket 里面的 sk 得到 struct sock,根据里面 sk_prot 的定义,调用 tcp_recvmsg 函数。
- TCP 层:tcp_recvmsg 函数会依次读取 receive_queue 队列、prequeue 队列和 backlog 队列。
socket.read 的本质就是去内核读取 receive_queue 队列、prequeue 队列和 backlog 队列 中的数据。如果实在没有数据包,则调用 sk_wait_data,等待在那里
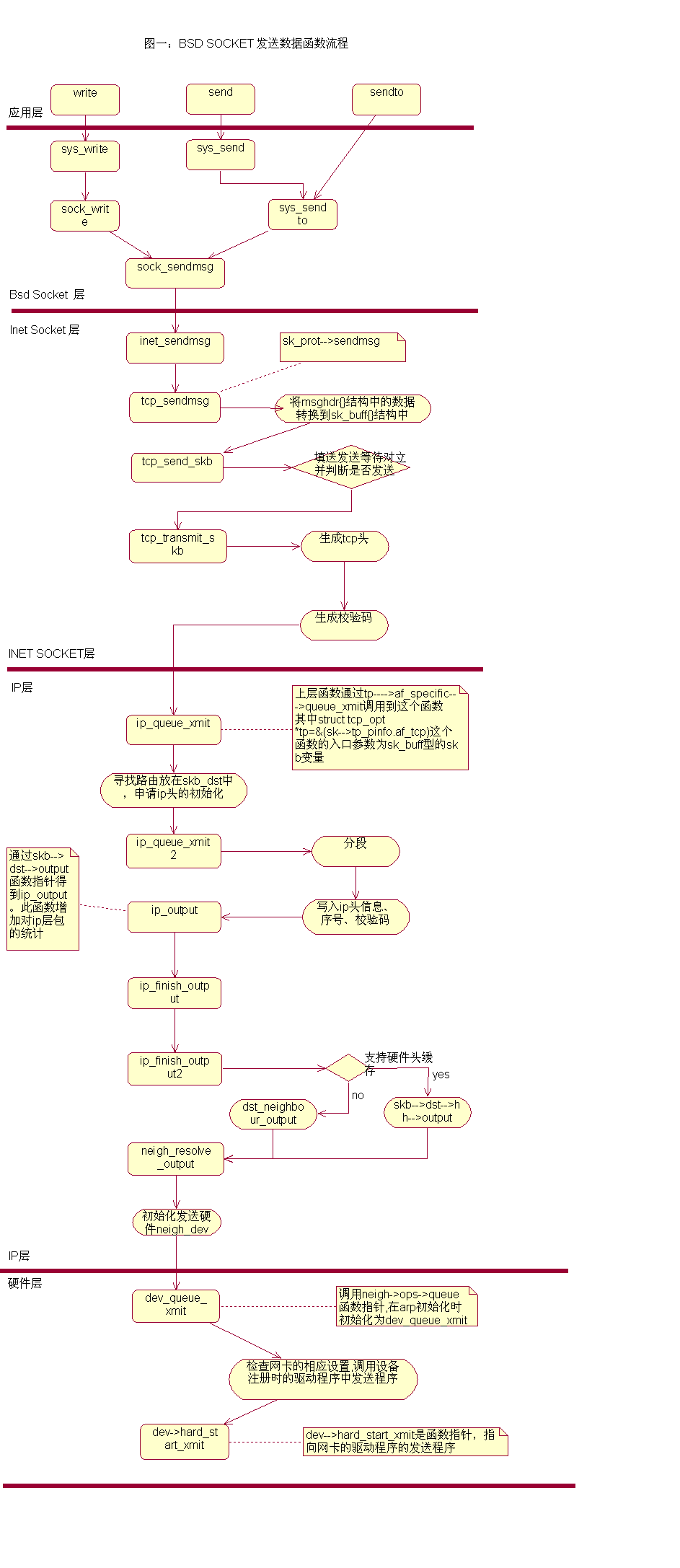
发送数据
由网络协议栈调用hard_start_xmit(初始化时,驱动程序将ei_start_xmit函数挂到其上)
总的来说,kernel有几个extern的struct、pointer和func,驱动程序初始化完毕后,为linux内核准备了一个device struct list(驱动程序自己有一些功能函数,挂到device struct的函数成员上)。收到数据时,kernel的extern func(比如netif_rx)在中断环境下被驱动程序调用。发送数据时,则由内核网络协议栈调用device.hard_start_xmit,进而执行驱动程序函数。
面向过程/对象/ioc

重要的不是细节,这个过程让我想到了web编程中的controller,service,dao。都是分层,区别是web请求要立即返回,网络通信则不用。
- mac ==> device ==> ip_rcv ==> tcp_rcv ==> 上层
- url ==> controller ==> service ==> dao ==> 数据库
想一想,整个网络协议栈,其实就是一群loopbackController、eth0Controller、ipService、TcpDao组成,该是一件多么有意思的事。
| 类别 | 依赖关系的存储或表示 | 如何找依赖 | 依赖关系建立的时机是集中的 |
|---|---|---|---|
| web | 由spring管理,springmvc建立<url,beanid>,ioc建立<beanId,bean> |
根据request信息及自身逻辑决定一步步如何往下走。 | 依赖关系建立的代码是集中的 |
| linux | 所谓的“依赖关系”是通过一个个struct及其数组(或链表)header,下层持有上层的struct header以完成接收,发送时则直接指定下层函数 | 接收时根据packet的一些字段,发送时根据socket参数及路由 | 依赖关系建立的代码是分散的,就好比有个全局的map,所有service(或者dao)自己向map注入自己的信息 |
留下评论