推理服务
简介
预测就是对样本执行前向传播的过程
- 在线预测。但一般也是批量请求,在推荐场景下,input 一般是
<uid,itemId>,根据uid/itemId 查询各种特征,组成input tensor查询推理服务,output 是uid和itemId 评分,itemId 一般有多个。 - 批量预测
入门
模型保存与加载
模型保存需要把计算图的结构、节点的类型以及变量节点的值从内存写到磁盘文件中,前两者一般保存为xml或json 格式,方便阅读、编辑和可视化,变量节点的值就是矩阵,没有阅读和编辑的需求,使用内存序列化的方式将其保存到一个二进制文件中。
《用python实现深度学习框架》 保存graph 示例
"graph" :[
{
"node_type": "Variable",
"name": "Variable:0",
"parents" : [],
"children": ["MatMul:4"],
"dim": [3,1],
"kargs": {}
},
{
"node_type": "MatMul",
"name": "MatMul:4",
"parents" : ["Variable:0","Variable:2"],
"children": [],
"kargs": {}
}
]
保存变量节点的值,因为计算图中有多个变量节点,因此需要维护节点名称与其序列化值之间的关系。
模型加载: 首先读取xx.json,根据node_type 字段记录的类型,利用Python 的反射机制来实例化相应类型的节点,再利用parents和children 列表中的信息递归构建所有的节点并还原节点间的连接关系,接着读取二进制文件把Variable 的值还原为训练完成时的状态。
模型预测:先找到输入/输出节点,把待预测的样本赋给输入节点,然后调用输出节点的forward 方法执行前向传播,计算出输出节点的值。
serving 服务一个示例c 接口如下
// model_entry: 默认置空
// model_config:从配置文件中读取的json内容,包括模型文件路径、cpu、线程数等配置
// state返回给框架的状态
void* initialize(const char* model_entry, const char* model_config, int* state)
// model_buf:initialize的返回值
// input_data/input_size:输入request的指针以及大小,格式见pb文件, input_size是序列化之后的长度
// output_data/output_size:输出response的指针以及大小,格式见pb文件,output_data是processor分配内存,返回给用户的,output_size指示output_data长度
int process(void* model_buf, const void* input_data, int input_size, void** output_data, int* output_size);
input_data 是 tensor 的 proto 格式表述,假设存在一个tensor[0,0,1,0,1,0],用struct 可以表示为
dtype = int
shape = [6]
intVal = [0,0,1,0,1,0]
以tensorflow 为例
模型文件目录
/tmp/mnist
/1 # 表示模型版本号为1
/saved_model.pb
/variables
/variables.data-00000-of-00001
/variables.index
发布模型
tensoflow_model_server --port=9000 --model_name=mnist --model_base_path=/tmp/mnist
更新线上的模型服务,对于新旧版本的文件处于同一个目录的情况,ModelServer 默认会自动加载新版本的模型
python tensorflow_serving/example/mnist_saved_model.py --training_iteration=10000 --model_version=2 /tmp/mnist
Exporting trained model to /tmp/mnist/2
预估 url http://localhost:9000/v1/tmp/mnist:predict
模型同步
TensorFlow 模型准实时更新上线的设计与实现TensorFlow 原有的模型参数上线流程,需要在训练中将参数保存到文件,再将文件传输到预测服务器,由预测服务器进行加载使用。这个过程流程长,文件传输慢,更新不及时。如果将模型训练时保存的参数和预测服务共用一套,就可几乎完全节省掉参数同步过程的时间消耗。尤其是对于大规模参数的数据传输,节省同步时间带来的效率提升就更大。当然出于数据隔离的考虑,这种方式还需要模型参数的版本管理等辅助支持。
部署实践
AI 模型在线推理服务的弹性,以及服务化运维,与微服务和 Web 应用是比较类似。很多云原生已有技术都可以直接用在在线推理服务上。但是 AI 模型推理依然有很多特殊之处,模型优化方法、流水线服务化、精细化的调度编排、异构运行环境适配等等方面都有专门诉求和处理手段。
在实践中还要考虑 模型的大小(有的模型几百G),是否动态加载(很多公司没做镜像层面的管理,而是serving 服务直接可以按版本动态加载模型)
基于镜像的模型管理-KubeDL实践
KubeDL 0.4.0 - Kubernetes AI 模型版本管理与追踪
- 从训练到模型。训练完成后将模型文件输出到本地节点的
/models/model-example-v1路径,当顺利运行结束后即触发模型镜像的构建,并自动创建出一个 ModelVersion 对象apiVersion: "training.kubedl.io/v1alpha1" kind: "TFJob" metadata: name: "tf-mnist-estimator" spec: cleanPodPolicy: None # modelVersion defines the location where the model is stored. modelVersion: modelName: mnist-model-demo # The dockerhub repo to push the generated image imageRepo: simoncqk/models storage: localStorage: path: /models/model-example-v1 mountPath: /kubedl-model nodeName: kind-control-plane tfReplicaSpecs: Worker: replicas: 3 -
从模型到推理。Inference Controller 在创建 predictor 时会注入一个 Model Loader,它会拉取承载了模型文件的镜像到本地,并通过容器间共享 Volume 的方式把模型文件挂载到主容器中,实现模型的加载。
apiVersion: serving.kubedl.io/v1alpha1 kind: Inference metadata: name: hello-inference spec: framework: TFServing predictors: - name: model-predictor # model built in previous stage. modelVersion: mnist-model-demo-abcde replicas: 3 template: spec: containers: - name: tensorflow image: tensorflow/serving:1.11.1 command: - /usr/bin/tensorflow_model_server args: - --port=9000 - --rest_api_port=8500 - --model_name=mnist - --model_base_path=/kubedl-model/
seldon
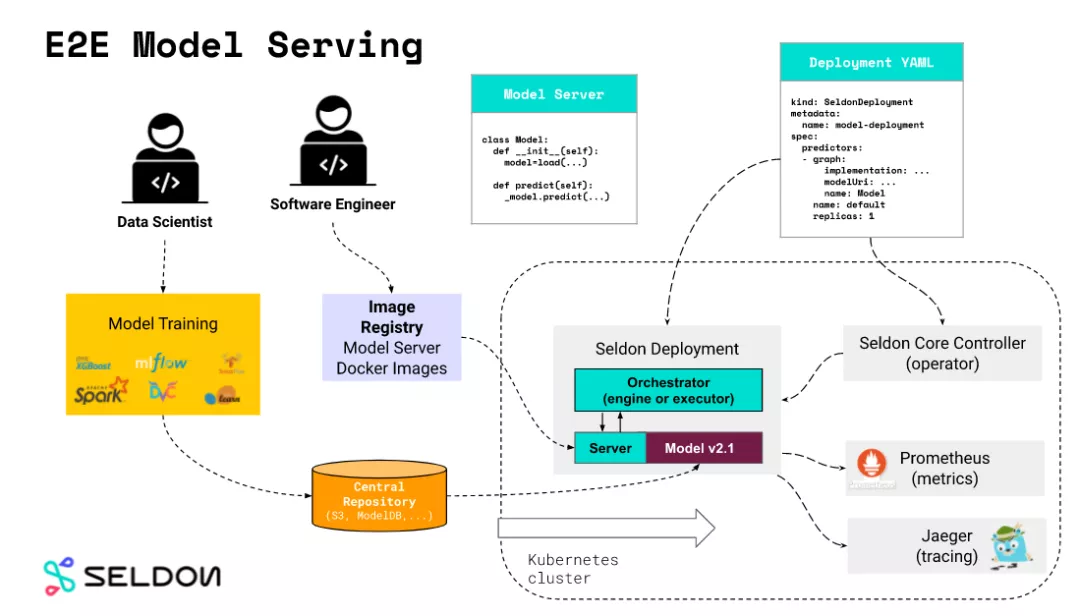
核心概念是 Model Server,Model Servers 通过配置的模型地址,从外部的模型仓库下载模型, seldon 模型预置了较多的开源模型推理服务器, 包含 tfserving , triton 都属于 Reusable Model Servers。
apiVersion: machinelearning.seldon.io/v1alpha2
kind: SeldonDeployment
metadata:
name: tfserving
spec:
name: mnist
predictors:
- graph:
implementation: TENSORFLOW_SERVER
modelUri: gs://seldon-models/tfserving/mnist-model
name: mnist-model
parameters:
- name: signature_name
type: STRING
value: predict_images
- name: model_name
type: STRING
value: mnist-model
name: default
replicas: 1
推理框架——提高性能,降低单个请求的耗时
GPU推理服务性能优化之路传统推理服务的常用架构,优势是代码写起来比较通俗易懂。但是在性能上有很大的弊端
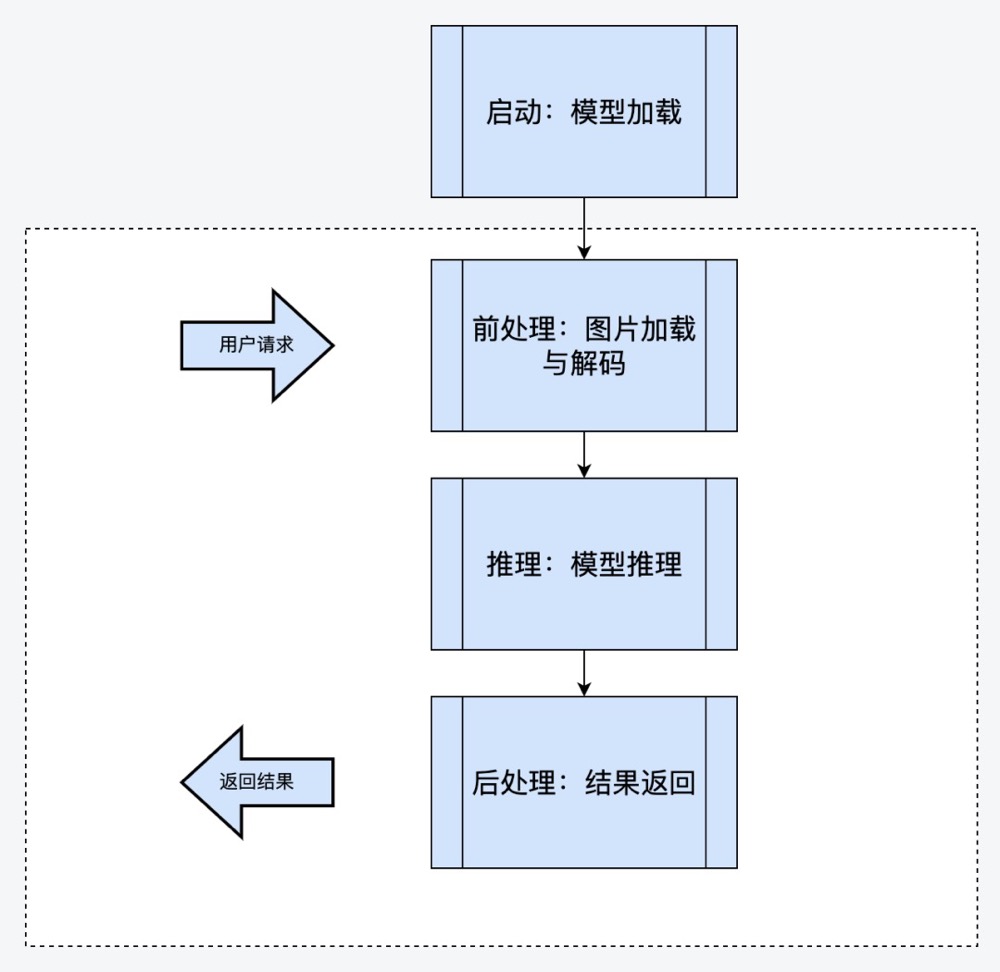
- CPU逻辑(图片的前处理,后处理)与GPU逻辑(模型推理)在同一个线程内
- 如果是单线程的模式,CPU逻辑与GPU逻辑相互等待,GPU Kernel函数调度不足,导致GPU使用率不高。无法充分提升QPS。这种情况下只能开启更多进程来提升QPS,但是更多进程会带来更多显存的开销。
- 如果开启多线程模式,由于Python GIL锁的存在,Python的多线程实际上是伪的多线程,并不是真正的并发执行,而是多个线程通过争抢GIL锁来执行,这种情况下GPU Kernel launch线程不能得到充分的调度,也无法充分利用GPU使用率。
- 解决方案是把CPU逻辑与GPU逻辑分离在两个不同的进程中。CPU进程主要负责图片的前处理与后处理,GPU逻辑则主要负责执行cuda kernel 函数,即模型推理。
- TensorRT是由英伟达公司推出的一款用于高性能深度学习模型推理的软件开发工具包,可以把经过优化后的深度学习模型构建成推理引擎部署在实际的生产环境中。TensorRT提供基于硬件级别的推理引擎性能优化。业界最常用的TensorRT优化流程,也是当前模型优化的最佳实践,即pytorch或tensorflow等模型转成onnx格式,然后onnx格式转成TensorRT进行优化。其中TensorRT所做的工作主要在两个时期,一个是网络构建期,另外一个是模型运行期。
- 网络构建期:模型解析与建立,加载onnx网络模型;计算图优化,包括横向算子融合,或纵向算子融合等;节点消除,去除无用的节点;多精度支持,支持FP32/FP16/int8等精度;基于特定硬件的相关优化。
- 模型运行期:序列化,加载RensorRT模型文件;提供运行时的环境,包括对象生命周期管理,内存显存管理等。
AI推理加速原理解析与工程实践分享优化方案分为三类:
- 第一类优化是模型精简类,即在模型真正执行之前就对模型的计算量进行精简,从而提升推理速度。这部分业界常见的优化方向包括量化、减枝、蒸馏和 NAS 等;
- 量化就是将模型中的计算类型进行压缩,从而降低计算量。常见的手段包括离线量化和量化训练两类。离线量化是指在模型训练完成后,离线的对计算算子进行量化,这种方案通常易用性较好,对算法开发人员几乎透明,但对模型精度会有一定损失;量化训练则是在模型训练过程中就显示插入量化相关的操作,这样通常会有更好的精度,但需要算法开发同学准备相关数据。
- 减枝则是通过将模型中对结果影响较小的一些计算进行移除,从而降低计算量。
- 蒸馏则通常是将一个复杂的大模型通过降维的知识传递层,将大模型中的复杂计算,减少为效果相当的更小规模的计算,从而实现降低计算量,提升推理效率的效果。
- 第二类和第三类则是当模型已经交由推理引擎在 GPU 上执行时,如何更好的提升 GPU 的利用效率。尽可能让 GPU 上有计算任务和单个计算任务在 GPU 上执行效率更高。这两类优化方案常见的手段分别是算子融合和单算子优化。
- 算子融合顾名思义是指将多个计算算子合并成一个大算子的过程。例如对于 BERT Base 这个模型,经过 PyTorch 原生 jit 编译生成的 TorchScript 图中有 800 多个小算子,这些小算子会带来 2 类问题:一是这些算子通常执行过程较短,因此会造成大量的 GPU 空闲时间;二是由于不同的任务之间还有数据的依赖,因此也会带来额外的访存开销。BERT Base 在经过 FasterTransformer 的算子融合优化后,数量可以降到 100 个左右。
- 单算子优化是根据单个算子,结合计算模式和硬件架构特点,调整 GPU 核函数的实现方法,从而提升具体算子的执行效率。单算子优化中,最经典的例子就是对通用矩阵乘(GEMM)的优化。
淘宝逛逛ODL模型优化总结 模型加速核心离不开裁枝、增加并行度、提升计算效率和缓存的使用。
CPU 推理优化 直接使用 TensorFlow 提供的 C++ 接口调用 Session::Run,无法实现多 Session 并发处理 Request,导致单 Session 无法实现 CPU 的有效利用。如果通过多 Instance 方式(多进程),无法共享底层的 Variable,导致大量使用内存,并且每个 Instance 各自加载一遍模型,严重影响资源的使用率和模型加载效率。为了提高 CPU 使用率,也尝试多组 Session Intra/Inter,均会导致 latency升高,服务可用性降低。
小红书推搜场景下如何优化机器学习异构硬件推理突破算力瓶颈! 罗列的比较详细。
调优
算法工程师视角
- 训练完的模型直接推理性能差
- 复杂模型推理性能差 基础架构工程师视角
- GPU成本高
- GPU利用率,资源浪费严重
在深度学习算法开发中,开发者通常使用 Python 进行快速迭代和实验,同时使用 C++ 开发高性能的线上服务,其中正确性校验和服务开发都会成为较重负担!MatxScript(https://github.com/bytedance/matxscript) 是一个 Python 子语言的 AOT 编译器,可以自动化将 Python 翻译成 C++,并提供一键打包发布功能。基于 MATXScript,我们可以训练和推理使用同一套代码,大大降低了模型部署的成本。同时,架构和算法得到了解耦,算法同学完全使用 Python 工作即可,架构同学专注于编译器开发及 Runtime 优化。PS:推广搜一般不需要算法写代码,由平台提供DAG,预处理和后处理 定义了一套dsl(主要用于数据转换),由java引擎执行,训练时 交给spark 执行,推理时由java库执行。
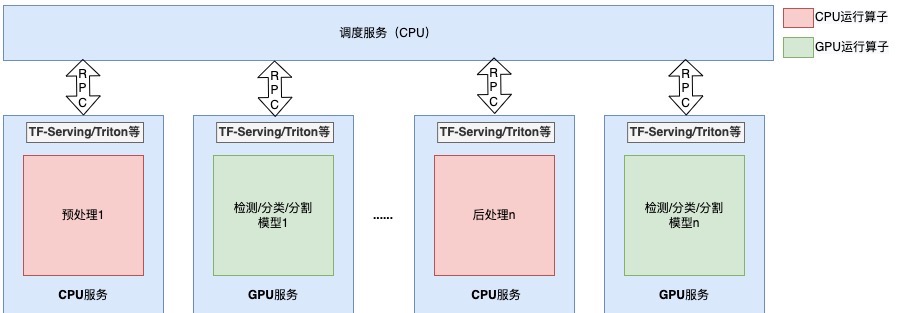
- 视觉服务经常存在组合串接多个模型实现功能的情况。例如在文字识别服务中,先通过检测模型定位文字位置,然后裁切文字所在位置的局部图片,最后送入识别模型得到文字识别结果。服务中多个模型可能采用不同训练框架,TF-Serving或Troch Serve推理框架只支持单一模型格式,无法满足部署需求。Triton支持多种模型格式,模型之间的组合逻辑可以通过自定义模块(Backend)和集成调度(Ensemble)方式搭建,但实现起来较为复杂,并且整体性能可能存在问题。
- 通用部署框架重点关注的是“通信方式、批处理、多实例”等服务托管方面的性能问题,但如果模型本身中间某个部分(如图像预处理或后处理)存在瓶颈,优化工具也无法优化,就会出现“木桶效应”,导致整个推理过程性能变差。
- 通过NVIDIA Nsight System(nsys)工具查看模型运行时的CPU/GPU执行情况,可以发现GPU运行有明显间隔,需要等待CPU数据准备完成并拷贝到GPU上,才能执行主干网络推理运算,CPU处理速度慢导致GPU处于饥饿状态。优化方法:
- 增加CPU:增加机器CPU数量是最简单的做法,但是受限于服务器硬件配置,1个GPU通常只配置8个CPU。所以增加CPU的方法只能用于性能测试数据对比,无法实际应用部署。
- 前置预处理:大尺寸图片的解码、缩放操作CPU消耗较高,相较而言小尺寸图片的处理速度会快很多。因此考虑对输入图片提前进行预处理,将预处理后的小图再送入服务。
- 分离预处理:另外一种思路是将模型预处理部分和主干网络拆分,预处理部分单独部署到CPU机器上,主干网络部署到GPU机器上。这种做法让CPU预处理服务可以水平无限扩容,满足GPU处理数据供给,充分利用GPU性能。更重要的是将CPU和GPU运算进行解耦,减少了CPU-GPU数据交换等待时间,理论上比增加CPU数量效率更高。在时延方面,拆分微服务的部署方式增加了RPC通信和数据拷贝时间开销,但从实践来看这部分时间占比很小,对端到端的延迟没有显著影响。
timeline 分析
有哪些相见恨晚的 TensorFlow 小技巧? - zhile yu的回答 - 知乎在利用tensorflow写程序时,常常会碰到GPU利用率始终不高的情况,这时我们需要详细了解程序节点的消耗时间,tensorboard提供了一个窗口,但仍不详细,这里介绍timeline的使用,他可以更详细的给出各部分op的时间消耗,让你了解程序的瓶颈。
横坐标为时间,从左到右依次为模型一次完整的forward and backward过程中,每个操作分别在cpu,gpu 0, gpu 1上消耗的时间,这些操作可以放大,非常方便观察具体每个操作在哪一个设备上消耗多少时间。
- 模型有一个PyFunc在cpu上运行,如红框所示,此时gpu在等这个结果,没有任何操作运行,这个操作应该要优化的。
- gpu上执行的时候有很大空隙,如黑框所示,这个导致gpu上的性能没有很好的利用起来。最后分析发现是我bn在多卡环境下没有使用正确,bn有一个参数updates_collections我设置为None 这时bn的参数mean,var是立即更新的,也是计算完当前layer的mean,var就更新,然后进行下一个layer的操作,这在单卡下没有问题的, 但是多卡情况下就会写等读的冲突,因为可能存在gpu0更新(写)mean但此时gpu1还没有计算到该层,所以gpu0就要等gpu1读完mean才能写,这样导致了 如黑框所示的空隙。
特点
Morphling:云原生部署 AI , 如何把降本做到极致? 专门整了一个论文,推理业务相对于传统服务部署的配置有以下特性:
- 使用昂贵的显卡资源,但显存用量低:GPU 虚拟化与分时复用技术的发展和成熟,让我们有机会在一块 GPU 上同时运行多个推理服务,显著降低成本。与训练任务不同,推理任务是使用训练完善的神经网络模型,将用户输入信息,通过神经网络处理,得到输出,过程中只涉及神经网络的前向传输(Forward Propagation),对显存资源的使用需求较低。相比之下,模型的训练过程,涉及神经网络的反向传输(Backward Propagation),需要存储大量中间结果,对显存的压力要大很多。我们大量的集群数据显示,分配给单个推理任务整张显卡,会造成相当程度的资源浪费。然而如何为推理服务选择合适的 GPU 资源规格,尤其是不可压缩的显存资源,成为一个关键难题。
- 性能的资源瓶颈多样:除了 GPU 资源,推理任务也涉及复杂的数据前处理(将用户输入 处理成符合模型输入的参数),和结果后处理(生成符合用户认知的数据格式)。这些操作通常使用 CPU 进行,模型推理通常使用 GPU 进行。对于不同的服务业务,GPU、CPU 以及其他硬件资源,都可能成为影响服务响应时间的主导因素,从而成为资源瓶颈。
- 容器运行参数的配置,也成为业务部署人员需要调优的一个维度:除了计算资源外,容器运行时参数也会直接影响服务 RT、QPS 等性能,例如容器内服务运行的并发线程数、推理服务的批处理大小(batch processing size)等。
双引擎 GPU 容器虚拟化,用户态和内核态的技术解析和实践分享我们从复杂多变的在线生产环境中抽象出这几种利用率模式。如何抽象业务场景,定制混布方案,是生产环境落地的关键。PS:意味着没有通用的?
- 均值偏低型,由于模型特点和服务 SLA 的限制,GPU 的峰值利用率只有 10%,平均利用率会更低。
- 峰谷波动型:服务在白天会达到高峰,在深夜至第二天早上是利用率的低谷,全天平均利用率只有 20% 左右,低谷利用率只有 10% 不到。
- 短时激增型:在夜间黄金时段会有两个明显的利用率高峰,高峰阶段的利用率高达 80%,为了满足高峰阶段的服务质量,该服务在部署过程中会预留不小的 buffer,资源平均利用率也刚刚超过 30%。
- 周期触发型:在线训练任务介于离线训练和在线推理之间,这是一种周期性批处理的任务。例如每 15 分钟会有一批数据到达,但这批数据的训练只需要 2-3 分钟,大量的时间 GPU 处于闲置状态。 几种混部方式
- 共享混布。无论在开发、训练、还是推理场景,在多个低利用率任务之间,我们都可以采用共享混布。
- 抢占混布。在峰值较高且延迟敏感的高优业务上混布一个延迟不敏感的低优任务。利用虚拟化功能中的高优抢占机制,高优任务时刻掌握占用资源的主动权。当流量处于波谷时,整卡的负载不高,低优任务可以正常运行,一旦流量处于波峰或者出现短时激增,高优抢占机制可以实时感知并且在 kernel 粒度上进行算力的抢占,此时低优任务会被限流甚至完全 pending,保障高优任务的服务质量。这种混布模式下可能会出现显存不足的情况,此时算力可能还有很大冗余。针对这类场景,我们提供了隐式的显存超发机制。用户可以通过环境变量对低优任务进行显存超发,混布更多的实例,确保随时有算力填充利用率的波谷,实现整体利用效率最大化。
- 分时混布。针对显存常驻、算力间歇性触发场景。典型的代表业务是开发任务和在线训练。类似于时间片轮转的共享混布,但此时显存也会随着计算的上下文一同被换入换出。由于底层的虚拟化层无法感知业务何时需要计算,我们针对每张 GPU 卡,维护了一个全局的资源锁。并封装了相应的 C++ 和 Python 接口供用户调用。用户只需要在需要计算的时候申请这把锁,显存就会从其它空间自动换入到显存空间;在计算完成后释放这把锁,对应的显存会被换出到内存或者磁盘空间。利用这个简单的接口,用户可以实现多个任务分时独占 GPU。在线训练场景中,使用分时混布,可以在拉升整体利用率的基础上实现最高 4/5 的资源节省。
AI 推理任务的优化部署相关主题包括:AI 模型的动态选择、部署实例的动态扩缩容、用户访问的流量调度、GPU 资源的充分利用(例如模型动态加载、批处理大小优化)等。
深度学习推理阶段对算力和时延具有很高的要求,如果将训练好的神经网络直接部署到推理端,很有可能出现算力不足无法运行或者推理时间较长等问题。
- 让模型更快(推理优化),比如聚合运算、分散运算、内存占用优化、针对具体硬件编写高性能核等。
- 指令集优化,比如使用AVX2、AVX512指令集;
- 使用加速库(TVM、OpenVINO)。
- GPU加速
- 推理引擎的选择:业界常用推理加速引擎有TensorRT、TVM、XLA、ONNXRuntime等,由于TensorRT在算子优化相比其他引擎更加深入,同时可以通过自定义plugin的方式实现任意算子,具有很强的扩展性。而且TensorRT支持常见学习平台(Caffe、PyTorch、TensorFlow等)的模型,其周边越来越完善(模型转换工具onnx-tensorrt、性能分析工具nsys等),因此在GPU侧的加速引擎使用TensorRT。
- 让模型更小(模型压缩),起初,这类技术是为了让模型适用于边缘设备,让模型更小通常能使其运行速度更快。业界神经网络模型优化的一般思路,可以从模型压缩、不同网络层合并、稀疏化、采用低精度数据类型等不同方面进行优化,甚至还需要根据硬件特性进行针对性优化。最常见的模型压缩技术是量化(quantization),比如在表示模型的权重时,使用 16 位浮点数(半精度)或 8 位整型数(定点数),而不是使用 32 位浮点数(全精度)。另一种常用的技术是知识蒸馏,即训练一个小模型(学生模型)来模仿更大模型或集成模型(教师模型)。即使学生模型通常使用教师模型训练得到,但它们也可能同时训练。其它技术还包括剪枝(寻找对预测最无用的参数并将它们设为 0)、低秩分解(用紧凑型模块替代过度参数化的卷积滤波器,从而减少参数数量、提升速度)。
- 让硬件更快。大公司和相关创业公司正竞相开发新型硬件,以使大型机器学习模型能在云端和设备端(尤其是设备)更快地推理乃至训练。
推理服务规格调优
推理因为没有反向计算,所以资源的利用率大大降低了。
- 人为经验,倾向于配置较多的资源冗余
- 基于资源历史水位画像,在更通用的超参调优方面,Kubernetes 社区有一些自动化参数推荐的研究和产品,但业界缺少一款直接面向机器学习推理服务的云原生参数配置系统。 Tensorflow 等机器学习框架倾向于占满所有空闲的显存,站在集群管理者的角度,根据显存的历史用量来估计推理业务的资源需求也非常不准确。KubeDL 加入 CNCF Sandbox,加速 AI 产业云原生化 分布式训练尚能大力出奇迹,但推理服务的规格配置却是一个精细活。显存量、 CPU 核数、BatchSize、线程数等变量都可能影响推理服务的质量。纯粹基于资源水位的容量预估无法反映业务的真实资源需求,因为某些引擎如 TensorFlow 会对显存进行预占。理论上存在一个服务质量与资源效能的最优平衡点,但它就像黑暗中的幽灵,明知道它的存在却难以琢磨。
对于 AI 推理任务,我们在 CPU 核数、GPU 显存大小、批处理 batch size、GPU 型号这四个维度(配置项)进行“组合优化”式的超参调优,每个配置项有 5~8 个可选参数。这样,组合情况下的参数搜索空间就高达 700 个以上。基于我们在生产集群的测试经验积累,对于一个 AI 推理容器,每测试一组参数,从拉起服务、压力测试、到数据呈报,需要耗时几分钟。
KubeDL-Morphling 组件实现了推理服务的自动规格调优,通过主动压测的方式,对服务在不同资源配置下进行性能画像,最终给出最合适的容器规格推荐。画像过程高度智能化:为了避免穷举方式的规格点采样,我们采用贝叶斯优化作为画像采样算法的内部核心驱动,通过不断细化拟合函数,以低采样率(<20%)的压测开销,给出接近最优的容器规格推荐结果。
其它
推理服务不仅可以运行在服务端,还可以运行在客户端、浏览器端(比如Tensorflow 提供tensorflow.js)
留下评论