认知的几点规律
简介
本文主要是对 公众号博主 张铁蕾(既爱写文字,也是一个程序猿) 几篇文章的重新梳理。
几篇文章体现了「学习」本身的知识,以及对认知过程本身的分析。学习和认知的方法本身也是一种技术。
马克思主义教导我们,人类创造历史只有两种基本活动:认识世界和改造世界。单就学知识而言, 尤其是技术知识,要回答“人(主体)如何去学习知识(客体)”?就得先回答:知识本身有什么特点?学习和认知本身有什么特点?
知识的归类和层次
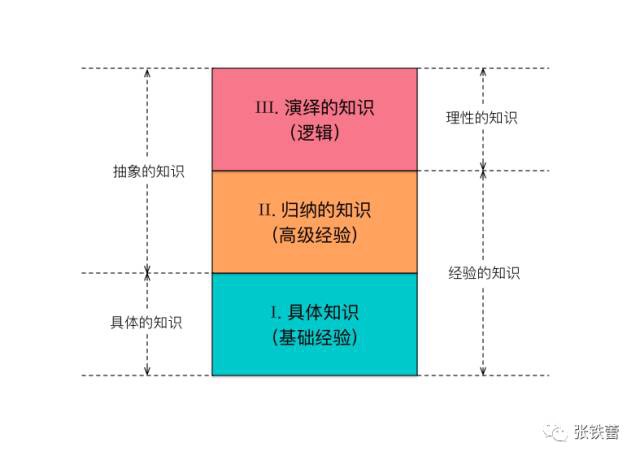
| 分类 | 例子 | 阐述 | 对应到程序猿的世界 | 获取难度 | 价值 |
|---|---|---|---|---|---|
| I类具体的知识 | “糖是甜的,盐是咸的”,“云是白的,天是蓝的” | 你知道就是知道,不知道就是不知道,你没法通过推理的方式获得它们。你只能从自己的实际动手过程中,或者从别人口中得到这些知识。 | 编程语言某个语法的具体用法 | “普通人”就可以快速积累 | 如果工作上用不到,就产生不了价值 |
| II类归纳的知识 | “朝霞不出门,晚霞行千里” | 相比具体的知识,抽象了一层。它们是从无数个具体经验中归纳总结出来的。 | 分布式系统有那些独特的问题需要考虑?如何使系统高可用? | 不管是“聪明人”还是“普通人”,都没法快速地积累。获取这一类知识,往往需要多年的工作经验和亲身实践的总结。因此这一类知识的传播比较困难,因为表达困难(尤其是系统的表达),一句“微言大义”未经历的人也没什么感觉 | 永远具有价值,与工作性质和工作内容无关 |
| III类演绎的知识 | 欧几里得的《几何原本》,从五条公设和五个公理出发,经过层层演绎推理,竟能推出整整一本书的内容。 | 它们几乎与经验无关,而是完全可以由推理得到。 | 对于程序员来说,除了解答数学题之外,我们平常用到此类知识的地方,主要在于算法设计、算法证明和算法复杂度分析上面。工作中涉及到的数学知识越多,对这类知识的需求就越多。 | “聪明人”可以快速积累 |
从具体到抽象,是人类智能的核心能力之一。这在哲学上的体现,初级的形式就是对于共相问题的探讨;而更高级的形式,则是对于归纳法、因果律的认识。
抽象的知识才是值得每个人着重关注的知识,也是最有价值的知识。
人工智能能从大量的数据中学习到内在的规律性,从而应用到它未见过的新的数据上去。这是它很重要的一个能力,称为generalization,其实就是归纳能力。可以说,AI技术已经开始触及到第II类知识,它要逐步替代人类来处理这部分知识。但是,与推理能力(reasoning)有关的第III类知识,目前的AI技术基本上还无能为力。所以说,在不远的未来,reasoning可能是人类智能最后的堡垒了。从这个意义上说,第III知识的价值理应为人的理性所高扬。
认知——用分层来学习分层的知识
我们的大脑好比内存。既然是内存,就装不下所有的知识,但应该能装下对于知识的索引。那么,这里就有一个选择性的问题:我们选择哪部分知识加载到“内存”里呢?
我们的认知是建立在「概念」的基础上的,在此基础上「概念」之间形成「关系」,就构成了一个知识体系——一个知识的大网。而对于「概念」和它们之间的「关系」的把握,我们靠的是什么呢?没错,靠的是「逻辑」。
如果我们从认知的角度出发,重点来关注概念之间的「依赖」关系,那么可以看到概念之间会呈现出清晰的分层结构。为了理解一个系统或者新的知识领域,我们必须要找到这样一个概念的层次,然后把我们所有的认知构建在这个层次之上。
在认知的过程中,我们要把概念清晰地分层呢?
- 必要性。有些时候,当我们接触一个新的知识领域时,有大量的概念需要理解。如果我们想理解上层的概念,那么必须先理解下层的概念,一层层推下去,直到我们到达了一层我们已经熟知的概念为止。这时候,我们才能理解整个体系。
- 更深刻的理解。几乎所有情况下,理解了下层的概念,上层的概念也变得更加清晰。试想一下,分别站在四个不同的层面来看系统:JDK,JVM,POSIX规范,Kernel,看到的东西自然相差甚远。很多情况下,受限于时间和精力,我们没有机会去一窥各个层次的究竟,但我们也不应该忘了在研究方法中这种层层深入的可能性。
- 更清晰的知识结构。如果我们头脑中对于某个知识领域的认识,只有一系列杂乱的概念,且它们来自各个不同的层次,那么我们的知识就是支离破碎的。在这样一个支离破碎的基础上,我们是没法进行正常的逻辑思考的。PS: 所以我们要有意识的学,其中一个重要目标是提高高层次知识的占比。
笔者最近在读书时,也一直在试图寻找一种感觉:找到几个要紧处,然后就可以放心大胆地忘掉细节。从作者的文章可以看到, “要紧处” 指的是归纳的知识,一是减少记忆成本,二是可以推导出细节。此外,也要求实现搞过足够复杂的事情,这样在碰到另一个复杂的事情时,可以进行类比借鉴,也可以减少思维负载。当你发现两个东西是一个东西时,就不觉得那么神秘了。
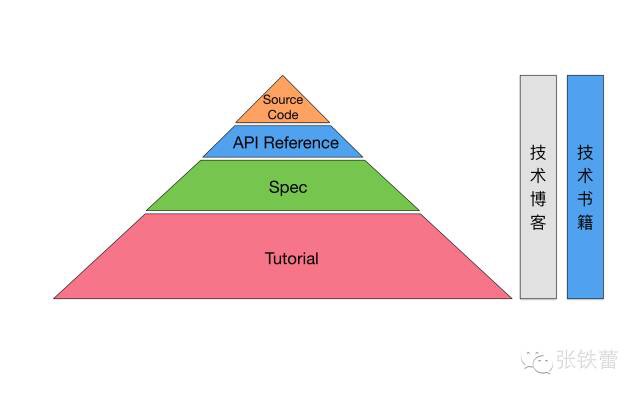
Spec是对于某项技术或知识的某个层次的一份完备的、系统性的描述。
像计算机科学中的很多问题一样,认知的过程也可以分为自底向上(bottom-up)或自顶向下(top-down)的
- 自底向上(学校里传统的教学过程),知识的根基会打得更深。但缺点是费时费力,目的性不明确。
- 自顶向下,优点是目的性强。缺点是获得的知识可能不够系统。
在实际中,两种方法应该互为补充。当时间相对紧迫,而所面临的新领域又相对庞大的时候,这时候可以选用自顶向下的方法,来迅速地自上而下地穿透各个概念层次,把遭遇到的陌生的概念变成可以理解的概念。而当时间充裕之后,对于重要的知识领域,就可以采用自底向上的方式,重新把各个概念层次自下而上地梳理一遍,以达到一个更系统性的理解。
每当我们接触一项新的技术的时候,我们都要把手头的资料按照类似的这样一个金字塔结构进行分类。如果我们阅读了一些技术博客和技术书籍,那么也要清楚地知道它们涉及到的是金字塔中的哪些部分。如果一篇技术文章,仅仅是对于所涉及技术的官方文档(Tutorial或Spec)的复述,甚至只是个翻译,那么就价值不高。那什么样的技术文章才有价值呢?大概可以说(未必那么准确),那些包涵了实践经验的,能将各个技术点综合起来产生思考,从而给人以启迪的。简单来说,就是有深度的。技术牛人学东西都比较快,而且在很短的时间内就能对某项新技术达到很深的理解。为什么呢?他们知道阅读正确的资料,从而很快能达到知识金字塔更高的一层。他们通常会确保它的每一部分都能安放在知识金字塔的某一部分,他们不容许那种不属于任何体系的知识孤岛的出现。
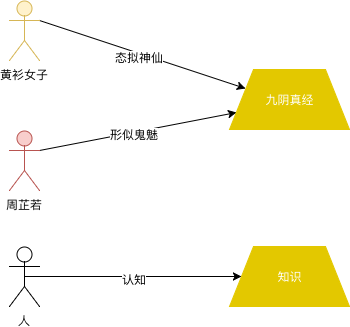
技术的正宗与野路子 技术的“野路子”,其实是知识结构的不完整和不系统造成的一种状态。只有当你冲破知识金字塔层层的障碍,迈向更高层次的时候,才可以“态似神仙”。
要把知识梳理成系统的结构,要让头脑中的知识层次清楚,为此,我们需要阅读恰当的东西,需要不断地练习,需要克服种种困难。
心态建设
马拉松式学习与技术人员的成长性 意大利「文艺复兴之父」彼特拉克曾经说过:「肉体和心智的能力必须大到足以满足文学活动和妻子两方面的需要。」如果换做程序员的角度,这句话应该修正一下:肉体和心智的能力必须大到足以满足熬夜写代码和女朋友两方面的需要。当然啦,这个说法也还远没有表达出生活真实的复杂性和严峻性。
不同技术人员之间的区别到底在哪。是在于工作经验,还是在于他们的聪明程度,或者是在于他们是否有名校的教育背景?为什么本来基础差不多的人,多年之后会产生巨大的差异?与此相关的一个很实际的问题是,我们在招聘新员工时,到底应该看重他们的哪些特点?我最后想到的答案是,决定不同技术人员之间的真正分野,在于「成长性」,也就是持续学习和提高自身的能力,在于他们身上有没有自我超越的基因。换句话说,「后劲」足不足。一个人的成长过程,什么都可能随时变化,但成长性本身不应该有丝毫减弱。
人脑其实也是一个智能模型,只不过这个模型更庞大,参数更多,容量更大;训练它需要的数据更多,时间也更长。如果你想成为某方面的专家,就需要花费很多年的精力来进行专业训练。一个人,要想在某方面获得睿智,唯一的办法就是持续地学习、调整、提高、成长。这个过程需要耐力和坚持,而最终你会收获成功和乐趣。
分层涉及的思维方式与方法论,不仅可以用在学习技术上,也可以用在人员管理、感情、生活等各个方面。
如何学习
- 俗话说“活到老,学到老”,这是真的。不论人在哪个年龄,都不应该放弃学习新知识。这是普通人的理解。但我觉得,更重要的是,无论多大年纪,在学习的过程中,都不应该放弃对“学习”本身的思考和理解,不断提升学习的效率。这样,学习的速度,才不会因为年龄的增长而急剧下降。
- 对真正的学习来说,预习-上课-复习,其实是前后连贯的三个环节。
- 如果不预习,上课就只能两眼一抹黑,仓促上阵的效果当然大打折扣。预习是提前摸一遍石头,知道哪些部分对自己很容易,哪些部分对自己很难,哪些部分自己还有什么疑问。之前的教育过于注重“普惠”性质,所以授课强度不够高,信息密度不够大。换句话说,即便你毫无准备也不要紧,老师会把东西“嚼烂了喂到你嘴里”。既然课堂的时间不够宝贵,提前多做准备的价值也就大打折扣了。
- 如果不上课,就不知道自己之前的猜测和理解对不对,没有机会产证和比对;
- 笔记不是机械记录老师的板书,而是根据自己的理解,对授课的内容进行剪裁和补充。简单说,笔记可以包括:这部分内容比较好理解,记录几个关键词即可;这部分内容比较容易和哪里混淆,应当如何辨析;这部分内容似乎还没讲明白,需要引入外部资料印证;这部分内容之前理解错了,上课才被老师纠正,需要重点记忆……要注意的是,所有这些“好理解”、“容易混淆”、“没讲明白”、“之前理解错了”等等的评价,都是根据个人的情况做出的,因为每个人的知识储备、思维习惯不同,笔记当然也就是千人千面的。如果预习和上课之中的任何一个环节有缺失,没有总结出自己的知识脉络,复习就成了无源之水、无本之木,只剩下机械重复。复习的过程,就是循着这脉络逐步展开,复现全貌,既能加深印象,也有机会跳出当时的局限,换个角度看问题。甚至,更有可能把不同的问题关联起来,拓展知识脉络,造就新的认知结构——所谓“认知升级”,大致就是如此。
- 授课的本质,是“裁剪”和“共建”。我曾经问过德语老师,为什么课本上每节课的篇幅都差不多,有的课你要讲三四天,有的课却一天就结束?她回答说:因为讲课没有机械规律,一定是根据学生和课堂的实际情况来安排的。有的班亚洲的学生多一点,那么相对亚洲文化比较好理解的课程,就不必花那么多时间。有时候课程内容正赶上当下的新闻热点,值得多花一点的时间讨论。还有的课,我没有想到那么多同学觉得困难,所以也需要多花时间聆听大家的问题……总的来说,同样的课本,不同的学生,每一次授课,都是根据实际情况,重新编排的过程。讲课不是照着课本从前往后阅读,而是老师和同学以合适的方式营造共同的体验和经历,在这个过程中让学生学到知识。虽然那天老师只花了十来分钟解答我的问题,却解开了我长久以来的疑惑:如果年复一年,针对不同的学生,讲的却是同样的内容,那么讲课是不是一种机械的重复,老师是不是一个令人厌烦的工作?答案就是“不是”。因为每一次讲课都是全新的创造,都需要辛勤的思考,它既是对课本内容的裁剪和编排,也是老师与学生的“体验共建”。PS:日常的沟通也不单是表达想法的过程、我觉得对就一股脑说出来,也是一个体验共建的过程,针对不同的人,你表达了,他也舒服了。
其它的一些关于学习的tips
学习这个东西,没有什么捷径。而且往往是需要先明白更多抽象的相对比较难的东西之后,学习简单的东西就只是一个查文档的过程。所谓的学习,知识只是一部分,理解知识是如何被抽象和提炼的过程,才是更重要的。很不幸没什么人愿意做。PS: 学习高维信息有时候是一种不得已,单纯的低维信息很多时候是一种负担。笔者看之前写的博客有一个体会:从高维向低维写的博客容易看懂,否则就是一堆过时的技术细节的堆砌。
读书在当今的时代真的是一项能力,一本书看完,作者想表达的观点到底是什么,如何与你的生活与实际进行结合,书中的知识怎么和你的存量知识进行连接,这是一个需要长期锻炼的能力。
学习过程需要我们不断将新知识与旧知识进行关联,形成自己的知识体系,而非一个个知识孤岛。
自己的体会:
- 发掘知识点之间的联系,消灭细节孤岛,把知识点 串起来,找到“一切都是相通”的感觉
- 要有意识的学,去提炼,其中一个重要目标是提高高层次知识的占比
原作者微信订阅号

笔者个人微信订阅号

留下评论