深入controller
简介
基于crd写一个controller的套路
crd:
spec:
status:
// 抽象版
func reconcile(){
// 1. 获取当前状态
// 2. 获取期望状态
// 3. 对比期望状态和当前状态
// 4. 更新状态
// 5. 返回
}
// 细节版
func reconcile(name){
crd := client.get(xx)
defer(){
// 保存对crd的变更
patch crd.status
}
if !crd.DeletionTimestamp.IsZero() {
// 检查是否可以删掉crd
// 如果不可以,状态1,doXX/reconcileXX
// 如果不可以,状态2,doXX/reconcileXX
// 如果可以
controllerutil.RemoveFinalizer(crd, xx)
return ctrl.Result{RequeueAfter: xx}, nil
}
if !controllerutil.ContainsFinalizer(crd, xx) {
controllerutil.AddFinalizer(crd, xx)
}
// 查找crd 可能依赖的其它crd
// 获取当前状态: status值、依赖的crd等
// 根据当前状态采取行动
// 如果状态1,doXX/reconcileXX(增删改其它crd,调用外部数据等,最后看是否状态流转,更改crd状态)
// 如果状态2,doXX/reconcileXX
return ctrl.Result{}, err
}
func register(){
// 监听哪些crd
// 监听哪些事件
}
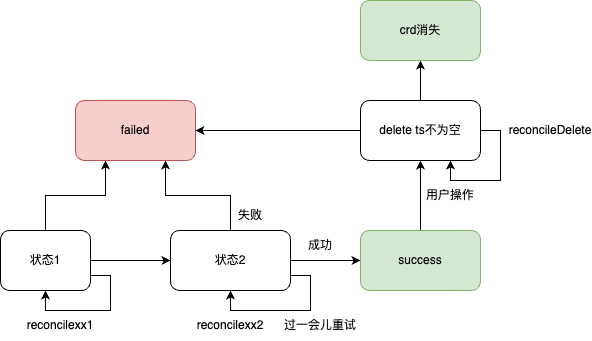
conroller 很适合处理“状态机”相关的逻辑。
- controller 核心是梳理状态、 状态处理函数(包含状态流转等)两部分。
- 最外围的controller.reconcile 只做一件事,判断状态并reconcile对应的状态函数reconcilexxx(除了状态定义外,没有具体业务逻辑的痕迹),具体的业务逻辑都收敛到 reconcilexxx里。 写代码有设计感的一个体现是:后来者如果要加一个逻辑,基本就只能在某个地方加。如果一段代码新增功能,既能在controller.reconcile写,又能在reconcilexxx加,代码慢慢就失控了。
- reconcilexxx 有3个结果:成功(流转到下一个状态)、失败、下次重试。 从这个视角讲,所有的controller.reconcile 都是一个套路。
- 因为reconcile 本质都是异步的,所以日志、event 要写仔细,每一条日志带上crd名字等,方便排查问题。event 上最好体现状态流转过程。
- 有的状态是“进行态”,处理完成后一般
return ctrl.Result{RequeueAfter: 10s}, nil以主动触发下次reconcile,有的状态是“终止态”,处理完return ctrl.Result{}, err,只有主要靠用户事件来触发reconcile。 - 正常状态流转 和
crd.DeletionTimestamp.IsZero()后的状态流转会有细微差别,比如后者执行时一些资源可能已经被销毁了。 - 一个crd spec 的定义很关键,它潜在的表示了你可以对这个crd 有哪些operation。 一种不太好的设计是 把所有信息都塞到annotation里,把逻辑都塞到reconcile 里,肯定也能干活儿,但这就好比一个类只有setter/getter方法一样,说明你对这个类的功能范围、调用者如何使用它没有充分的思考。
- 好的设计一定是清晰简单的,只有一个角色改动一个地方(一个地方只会被一个角色改动),否则就是设计不清晰、模块分工不明确的征兆。干啥都得讲点“师出有名”,一块代码叫啥名、放在啥地方会影响后续的思考方式。
condition
- conditions和status到底有什么区别?
- conditions的设计原则是什么?在设计API扩展时,该如何定义conditions?
What the heck are Conditions in Kubernetes controllers? the difference between the ‘phase’ and ‘conditions:
- The top-level phase is an aggregated state that answers some user-facing questions such as is my pod in a terminal state? but has gaps since the actual state is contained in the conditions.
- The conditions array is a set of types (Ready, PodScheduled…) with a status (True, False or Unknown) that make up the ‘computed state’ of a Pod at any time. As we will see later, the state is almost always ‘partial’ (open-ended conditions).
从sync loop 说起
Kubernetes itself is made of multiple binaries (kubelet on each node, one apiserver, one kube-controller-manager and one kube-scheduler). And each of these binaries have multiple components (i.e., sync loops):
| binary | sync loop = component | reads | creates | updates |
|---|---|---|---|---|
| kube-controller-manager | syncDeployment | Pod | ReplicaSet | Deployment |
| kube-controller-manager | syncReplicaSet | Pod | ||
| kubelet | syncPod | Pod | ||
| kube-scheduler | scheduleOne | Pod | ||
| kubelet | syncNodeStatus | Node |
We can see that one single object (Pod) can be read, edited and updated by different components. When I say ‘edited’, I mean the sync loop edits the status (which contains the conditions), not the rest. The status is a way of communicating between components/sync loops.
The status of a Pod is not updated by a single Sync loop: it is updated by multiple components: the kubelet, and the kube-scheduler. Here is a list of the condition types per component:
| Possible condition types for a Pod | Component that updates this condition type |
|---|---|
| PodScheduled | scheduleOne (kube-scheduler) |
| Unschedulable | scheduleOne (kube-scheduler) |
| Initialized | syncPod (kubelet) |
| ContainersReady | syncPod (kubelet) |
| Ready | syncPod (kubelet) |
the status of a Pod is partly constructed by the kube-scheduler, partly by the kubelet.
Although conditions are a good way to convey information to the user, they also serve as a way of communicating between components (e.g., between kube-scheduler and apiserver) but also to external components (e.g. a custom controller that wants to trigger something as soon as a pod becomes ‘Unschedulable’, and maybe order more VMs to the cloud provider and add it as a node.
Finalizer
Finalizers 是 Kubernetes 资源删除流程中的一种拦截机制。
Kubernetes模型设计与控制器模式精要如果只看社区实现,那么该属性毫无存在感,因为在社区代码中,很少有对Finalizer的操作。但在企业化落地过程中,它是一个十分重要,值得重点强调的属性。因为Kubernetes不是一个独立存在的系统,它最终会跟企业资源和系统整合,这意味着Kubernetes会操作这些集群外部资源或系统。试想一个场景,用户创建了一个Kubernetes对象,假设对应的控制器需要从外部系统获取资源,当用户删除该对象时,控制器接收到删除事件后,会尝试释放该资源。可是如果此时外部系统无法连通,并且同时控制器发生重启了会有何后果?该对象永远泄露了。
Finalizer本质上是一个资源锁,Kubernetes在接收到某对象的删除请求,会检查Finalizer是否为空,如果不为空则只对其做逻辑删除,即只会更新对象中metadata.deletionTimestamp字段。具有Finalizer的对象,不会立刻删除,需等到Finalizer列表中所有字段被删除后,也就是该对象相关的所有外部资源已被删除,这个对象才会被最终被删除。PS:本质是可以干预 资源的删除逻辑。
Using Finalizers to Control DeletionFinalizers are keys on resources that signal pre-delete operations. They control the garbage collection on resources, and are designed to alert controllers what cleanup operations to perform prior to removing a resource. However, they don’t necessarily name code that should be executed; finalizers on resources are basically just lists of keys much like annotations. Like annotations, they can be manipulated.
apiVersion: v1
kind: ConfigMap
metadata:
name: mymap
finalizers:
- kubernetes
kubectl delete configmap/mymap 只是给 mymap.deletionTimestamp 赋了一个值,当手动移除 finalizers (比如kubectl patch) 之后,才会真正删除mymap。通过脚本清理带有finalizers 的资源
#!/bin/bash
NAMESPACE="ns-xx"
# 获取 resource 资源列表
resources=$(kubectl get resource -n $NAMESPACE --no-headers -o custom-columns=":metadata.name")
# 遍历每个 resource 资源并执行 kubectl patch 命令
for resource in $resources; do
echo "Processing resource: $resource"
kubectl patch resources/$resource -n $NAMESPACE --type json --patch='[ { "op": "remove", "path": "/metadata/finalizers" } ]'
kubectl delete resource -n $NAMESPACE $resource
done
日志
golang中,一般以 logr.Logger 定义了日志接口,各个日志库比如klog提供底层实现(LogSink)
func main(){
// controller-runtime 维护了一个全局的 Log,可以通过 SetLogger/LoggerFrom 等方法去设置和获取它。
// ctrl.SetLogger(klogr.New()) 表示底层使用的是klog
ctrl.SetLogger(klogr.New())
mgr, err := ctrl.NewManager(restConf, ctrl.Options{
Scheme: Scheme,
...
})
r := &xxReconciler{
client: mgr.GetClient(),
log: ctrl.LoggerFrom(context.Background()).WithName(name),
recorder: mgr.GetEventRecorderFor(name),
}
ctrl.NewControllerManagedBy(mgr).
WithOptions(...).
For(&v1alpha1.xx{}).
Build(r)
}
Garbage Collection
在 Kubernetes 引入垃圾收集器之前,所有的级联删除逻辑都是在客户端完成的,kubectl 会先删除 ReplicaSet 持有的 Pod 再删除 ReplicaSet,但是垃圾收集器的引入就让级联删除的实现移到了服务端。
Garbage CollectionSome Kubernetes objects are owners of other objects. For example, a ReplicaSet is the owner of a set of Pods. The owned objects are called dependents of the owner object. Every dependent object has a metadata.ownerReferences field that points to the owning object.Kubernetes objects 之间有父子关系,那么当删除owners 节点时,如何处理其dependents呢?
- cascading deletion
- Foreground模式,先删除dependents再删除owners. In foreground cascading deletion, the root object first enters a “deletion in progress” state(
metadata.finalizers = foregroundDeletion). Once the “deletion in progress” state is set, the garbage collector deletes the object’s dependents. Once the garbage collector has deleted all “blocking” dependents (objects withownerReference.blockOwnerDeletion=true), it deletes the owner object. - background模式(默认),先删owners 后台再慢慢删dependents. Kubernetes deletes the owner object immediately and the garbage collector then deletes the dependents in the background.
- Foreground模式,先删除dependents再删除owners. In foreground cascading deletion, the root object first enters a “deletion in progress” state(
- 非级联删除,Orphan 策略:此时the dependents are said to be orphaned.
如何控制Garbage Collection?设置propagationPolicy
kubectl proxy --port=8080
curl -X DELETE localhost:8080/apis/apps/v1/namespaces/default/replicasets/my-repset \
-d '{"kind":"DeleteOptions","apiVersion":"v1","propagationPolicy":"Background"}' \
-H "Content-Type: application/json"
## cascade 默认值是true
kubectl delete replicaset my-repset --cascade=false
kubelet Garbage Collection
回收物理机上不用的 容器或镜像。
Configuring kubelet Garbage Collection(未读)
- Image Collection, Disk usage above the HighThresholdPercent will trigger garbage collection. The garbage collection will delete least recently used images until the LowThresholdPercent has been met.
[LowThresholdPercent,HighThresholdPercent]大于HighThresholdPercent 开始回收直到 磁盘占用小于LowThresholdPercent -
Container Collection 核心就是什么时候开始删除容器,什么样的容器可以被删掉
- minimum-container-ttl-duration, 容器dead 之后多久可以被删除
- maximum-dead-containers-per-container, 每个pod 最多允许的dead 容器数量,超过的容器会被删掉
- maximum-dead-containers, 主机上最多允许的dead 容器数量,超过的容器会被删掉
留下评论