数据集管理fluid
简介
Fluid 项目当前主要关注数据集编排和应用编排这两个重要场景。
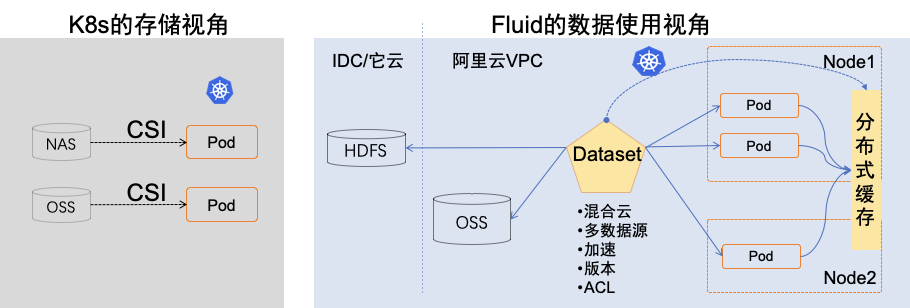
- 数据集编排可以将指定数据集的数据缓存到指定特性的 Kubernetes 节点。PS:任务编排 是把任务调度到哪个node 上,数据编排即把 数据调度到哪个node上。
- 移动数据,先不考虑 Alluxio 这类组件,可以认为 fluid 支持将xx 文件 从 远程磁盘/oss/hdfs 移动 k8s 某个node 的xx 目录下,不用的时候(比如删除dataset时)再把这个文件清理掉。
- 单论访问远端文件, 直接用 pvc 也可以,但性能不够,pvc 仅仅是把pod 跟远端存储搭个桥梁,访问接口统一了。所以,我们还是想 将文件挪到 k8s 集群本地来,在k8s 集群(一般即计算集群)和 存储集群异地的时候尤其需要,数据移到了本地就得做 生命周期管理,且本地文件仍以pvc 方式提供给pod 访问。
- 为了效率,通常不会直接移动文件,且对于AI 等任务来说,k8s node磁盘也放不下训练数据,所以引入了Alluxio等组件。Fluid 实现了 pvc 接口,让 pod 内可以像使用本地磁盘一样无感知 Fluid 提供元数据和数据分布式分层缓存,以及高效文件检索功能(因为缓存了元数据)。
- 应用编排将指定该应用调度到可以或已经存储了指定数据集的节点上。
pvc 将各种存储融入到k8s ,fluid实际做的是把alluixo类似的分布式缓存系统,以统一的方式做到可以被k8s感知和调度;
背景
如何基于 Kubernetes 构建云原生 AI 平台在云上通过云原生架构运行 AI、大数据等任务,可以享受计算资源弹性的优势,但同时也会遇到,计算和存储分离架构带来的数据访问延迟和远程拉取数据带宽开销大的挑战。尤其在 GPU 深度学习训练场景中,迭代式的远程读取大量训练数据方法会严重拖慢 GPU 计算效率。另一方面,Kubernetes 只提供了异构存储服务接入和管理标准接口(CSI,Container Storage Interface),对应用如何在容器集群中使用和管理数据并没有定义。在运行训练任务时,数据科学家需要能够管理数据集版本、控制访问权限、数据集预处理、加速异构数据读取等。但是在 Kubernetes 中还没有这样的标准方案,这是云原生容器社区缺失的重要能力之一。
Fluid 助力阿里云 Serverless 容器极致提速举例来说,如果我们想将 AI 推理服务应用部署在 Serverless 架构下,每个服务应用启动前必须将存放在外部存储系统的 AI 模型首先拉取到本地内存中。考虑到近年来 AI 大模型已经成为业界主流,让我们假设这个 AI 模型的大小为 30GB,并且存储于 OSS 对象存储服务中,如果需要同时启动 100 个这样的 AI 推理服务应用,那么总共的数据读取量就是 3000GB。OSS 存储默认的数据访问限速是 10Gbps,这就意味着 100 个应用都需要等待 2400 秒(3000GB * 8 / 10Gbps)才可以真正开始对外提供服务。
ACK 云原生 AI 套件对“计算任务使用数据的过程”进行抽象,提出了弹性数据集 Dataset 的概念,并作为“first class citizen”在 Kubernetes 中实现。围绕弹性数据集 Dataset,ACK 创建了数据编排与加速系统 Fluid,来实现 Dataset 管理(CRUD 操作)、权限控制和访问加速等能力。Fluid 可以为每个 Dataset 配置缓存服务,既能在训练过程中将数据自动缓存在计算任务本地,供下轮迭代计算,也能将新的训练任务调度到已存在 Dataset 缓存数据的计算节点上运行。再加上数据集预热、缓存容量监控和弹性伸缩,可以大大降低任务远程拉取数据的开销。Fluid 可以将多个不同类存储服务作为数据源(比如 OSS,HDFS)聚合到同一个 Dataset 中使用,还可以接入不同位置的存储服务实现混合云环境下的数据管理与访问加速。
重新定义容器化 Serverless 应用的数据访问Fluid is an open source Kubernetes-native Distributed Dataset Orchestrator and Accelerator for data-intensive applications, such as big data and AI applications.云原生环境与更早的大数据处理框架在设计理念和机制上存在天然分歧。深受Google三篇论文GFS、MapReduce、BigTable影响的Hadoop大数据生态,从诞生之初即信奉和实践“移动计算而不是数据”的理念。因此以Spark,Hive,MapReduce为代表的数据密集型计算框架及其应用为减少数据传输,其设计更多地考虑数据本地化架构。但随着时代的变迁,为兼顾资源扩展的灵活性与使用成本,计算和存储分离的架构在更新兴的云原生环境中大行其道。因此云原生环境里需要类似Fluid这样的一款组件来补充大数据框架拥抱云原生以后的数据本地性的缺失。
计算和存储分离的模式使得以往我们认为非常特殊的服务可以被无状态化,可以像正常服务一样被纳入 devops 体系中,而基于 Fluid 的数据编排和加速系统,则是实践计算和存储分离的一个切口。
思路
Fluid 把数据集的准备工作从整个流程里单独抽取了出来,利用底层的 K8s 分配需要的资源,例如缓存系统需要的内存和磁盘资源。资源分配出来后,可以选择性的发起元数据和数据的预热工作。等预热工作完成之后,再由 K8s 调度计算资源运行训练任务。训练任务可以选择是否亲和,所谓亲和是让缓存的节点和计算的节点是同一批节点,这个能带来什么样的好处待会儿会讲到。训练完成后,用户可以视情况而定决定何时回收 Fluid 占用的资源,这个过程和计算也是独立的。
Fluid 的实质是利用计算集群的空闲资源(CPU,Memory,Disk)和特定场景的抽象假设简化问题
- 通过数据分流(Data Offloading)降低中心存储的压力;就近缓存(Tiered Locality Cache)和亲和性调度(Cache Locality Scheduling)提升数据访问性能;Fluid 会把需要访问的数据缓存到与应用 Pod 更近的分布式缓存系统(例如:JindoFS、JuiceFS、Alluxio 等)中,于是,与缓存系统位于同一 VPC 网络的应用 Pod,就能够以远比直接访问中心存储带宽更高的 VPC 内网带宽进行数据访问。
- 在计算资源高并发访问数据的时候,通过自动化扩容缓存集群提供弹性 IO 吞吐能力。由于对接的是分布式缓存系统,所以当单个缓存系统 Worker 节点提供带宽不足时,可将分布式缓存系统扩容,从而实现数据访问带宽的弹性伸缩,匹配 Serverless 场景下的计算资源弹性。 将底层存储系统的有限带宽,扩展到了可以弹性扩容的 Kubernetes 集群内。这个集群内的可用带宽取决于分布式缓存的节点数量,从而可以根据业务需求,及时进行伸缩,提供灵活而高效的 I/O 处理。
Dataset 和 Runtime,它们分别代表需要访问的数据源和对应的缓存系统。
- Dataset,它代表需要访问的数据源,比如OSS 存储桶中的一个子目录
- Runtime,代表对应的缓存系统,比如Alluxio 当用户创建了 Dataset 和对应的 Runtime 后,Fluid 会接管后续的所有工作。首先,Fluid 会自动完成对应的缓存系统的配置,然后,它会自动拉起缓存系统的组件。接着,Fluid 会自动创建一个 PVC(Persistent Volume Claim)。当这些准备工作完成后,希望访问模型数据的推理应用只需要挂载这个 PVC,就可以从缓存中读取模型数据。
实现
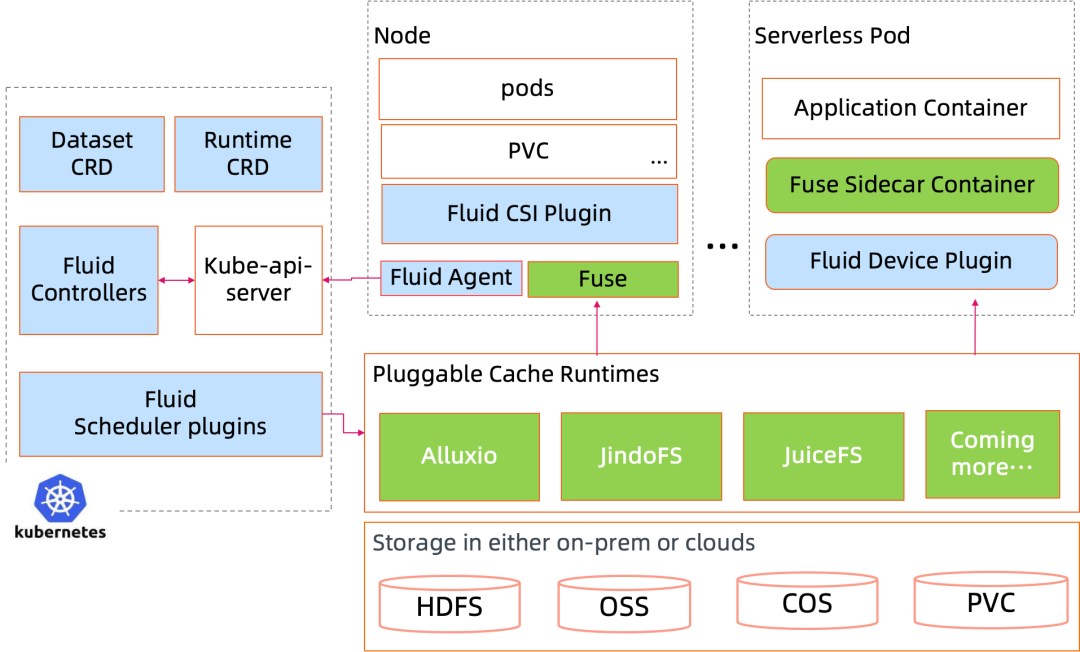
Fluid 工作原理解析Fluid 的整个架构主要分为两个部分。
- Controller,包括 RuntimeController 及 DatasetController,分别管理 Runtime 和 Dataset 的生命周期,二者共同作用,以 helm chart 为基础,快速搭建出一套完整的分布式缓存系统,通常是 master + worker + fuse 的形式,向上提供服务。master 是缓存系统的核心组件,通常是一个 pod;worker 是组成缓存集群的组件,可以是多个 pod,可以设置个数;fuse 是提供 POSIX 接口服务的组件;
- 调度器,在有缓存的情况下,调度器会根据 worker 的节点信息,使得上层应用 pod 尽可能调度到有缓存的节点。
整个过程如下,Dataset Controller 监听 Dataset,Runtime Controller 监听对应的 Runtime,当二者一致时,RuntimeController 会启动 Engine,Engine 创建出对应的 Chart(Runtime Controller 启动 JuiceFS 的环境的方法是启动一个 helm chart,其渲染的 values.yaml 以 ConfigMap 的形式保存在集群中),里面包含 Master、Worker、FUSE 组件。同时,Runtime Controller 会定期同步数据(如总数据量、当前使用数据量等)状态更新 Dataset 和 Runtime 的状态信息。
下面以 JuiceFS 为例,搭建一套 Fluid 环境,搭建好后组件如下:
$ kubectl -n fluid-system get po
NAME READY STATUS RESTARTS AGE
csi-nodeplugin-fluid-fczdj 2/2 Running 0 116s
csi-nodeplugin-fluid-g6gm8 2/2 Running 0 117s
csi-nodeplugin-fluid-twr4m 2/2 Running 0 116s
dataset-controller-5bc4bcb77d-844rz 1/1 Running 0 116s
fluid-webhook-7b4f48f647-s8c9w 1/1 Running 0 116s
juicefsruntime-controller-5d95878575-hj785 1/1 Running 0 116s
# JuiceFS 相对其他 Runtime 的特殊之处在于其没有 master 组件
jfsdemo-worker-0 1/1 Running 0 58m
jfsdemo-worker-1 1/1 Running 0 58m
# FUSE 组件
jfsdemo-fuse-pd9zq 1/1 Running 0 25s
各个组件的作用:
- dataset-controller:管理 Dataset 的生命周期
- juicefsruntime-controller:管理 JuiceFSRuntime 生命周期,并快速搭建 JuiceFS 环境;
- fluid-webhook:实现 Fluid 应用的缓存调度工作;
- csi-nodeplugin:实现各引擎的挂载路径与应用之间的连接工作;
在 Fluid 中,数据加速对应的是 DataLoad,也是一个 CRD,DatasetController 负责监听该资源,根据对应的 DataSet 启动 Job,执行数据预热操作。同时 Runtime Controller 向 Worker 同步缓存的数据信息,并更新 Dataset 的状态。
大致理解:Dataset 表述了要访问哪些数据源文件,对pod 提供了pv和pvc ,对下封装了缓存、数据集调度等能力。
- fluid 开发了对应的csi ,Dataset 和 Runtime Bound 之后,fluid 会自动创建与 Dataset 同名的pvc 和 pvc
- pod 调度到一个node 上之后,因为pod 声明了和dataset 同名的pvc,fluid csi 在node 上准备一个目录(pv),走csi 流程挂到pod 里。
- 此外 在node上启动一个fuse pod(或者说,fuse pod 将挂载点暴露在宿主机上,然后 csi 将挂载点 bind 到应用 pod 里)。pod 里程序对这个目录的读写请求 都转给了fuse pod,fuse 将文件io 转为网络io 访问真实的runtime。PS:
其它
Fluid 助力阿里云 Serverless 容器极致提速 展示了创建Dataset 访问oss 以及进行数据预热等操作。
留下评论