Kubernetes副本管理
简介
- 简介
- What is Kubernetes replication for?
- deployment
- What is a replication controller?(逐步弃用)
- Replication Controller Operations
本文主要来自对https://cloud.google.com/container-engine/docs的摘抄,有删减。
本文主要讲了replication controller(部分地方简称RC) 尤其要注意 replication controller 和 Kubernetes 控制器模型 不是一个范畴的事情。
2018.11.18 补充,内容来自极客时间 《深入剖析Kubernetes》
What is Kubernetes replication for?
Kubernetes Replication Controller, Replica Set and Deployments: Understanding replication options
Typically you would want to replicate your containers (and thereby your applications) for several reasons, including: Reliability、Load balancing、Scaling。也就是说,应用不是启动一个实例就是完事了。如果应用有多个实例,那么弄几个实例,如何更新所有实例。然后随着k8s的演化,先是Replication Controller、然后 ReplicaSets 最后Deployment
- The Replication Controller is the original form of replication in Kubernetes. It’s being replaced by Replica Sets.
- The major difference is that the rolling-update command works with Replication Controllers, but won’t work with a Replica Set.This is because Replica Sets are meant to be used as the backend for Deployments.
- Deployments are intended to replace Replication Controllers. They provide the same replication functions (through Replica Sets) and also the ability to rollout changes and roll them back if necessary.
deployment
《深入剖析Kubernetes》 经典PaaS的记忆:作业副本与水平扩展 小节 未完毕
有了Replication Controller 为什么还整一个 Deployment?因为后者是声明式的。
Replication Controller VS Deployment in Kubernetes
Deployments are a newer and higher level concept than Replication Controllers. They manage the deployment of Replica Sets (also a newer concept, but pretty much equivalent to Replication Controllers), and allow for easy updating of a Replica Set as well as the ability to roll back to a previous deployment.Previously this would have to be done with kubectl rolling-update which was not declarative and did not provide the rollback features.
Deployments A Deployment controller provides declarative updates for Pods and ReplicaSets.You describe a desired state in a Deployment object, and the Deployment controller changes the actual state to the desired state at a controlled rate.
kubernetes yaml配置Every Kubernetes object includes two nested object fields that govern the object’s configuration: the object spec and the object status. 每个kubernetes object 都包括两个部分object spec 和 object status. Deployment 只是在 ReplicaSet 的基础上,添加了 UP-TO-DATE 这个跟版本有关的状态字段(也就是说 spec 部分没改?)。
我们对多个实例的应用(而不是单个实例)有以下操作:
| Deployment controller逻辑 | 备注 | |
|---|---|---|
| 水平扩展/收缩 | 修改所控制的 ReplicaSet 的 Pod 副本个数 | 只更改数量,镜像不变 |
| 滚动更新/回滚 | 见下图,逐步减少v1 ReplicaSet 副本数,增加v2 ReplicaSet 的副本数 | 镜像改变,每次改变算一个“版本” |
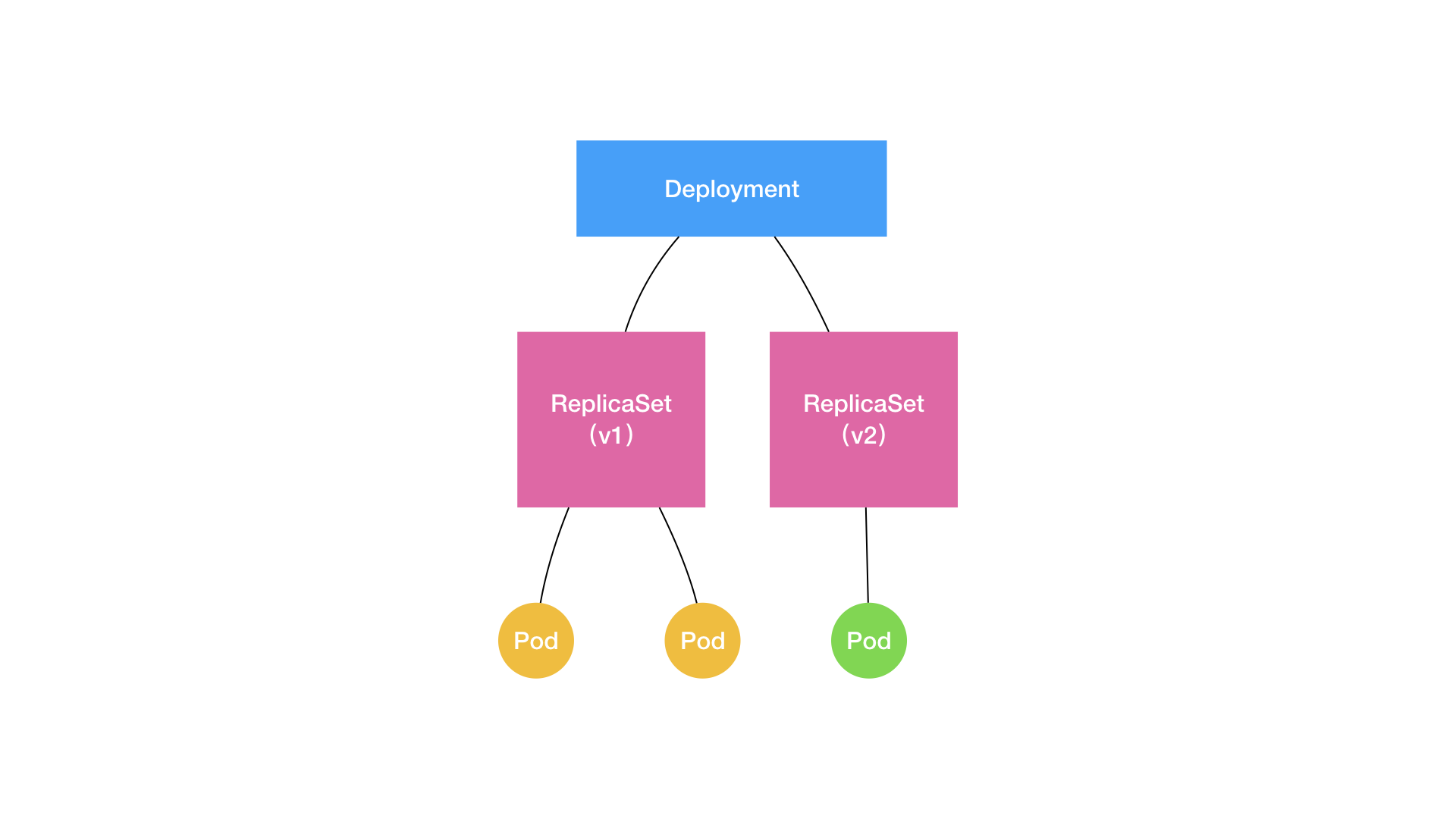
| Kubernetes object | 控制器逻辑 | 备注 |
|---|---|---|
| Deployment | 控制 ReplicaSet 的数目,以及每个 ReplicaSet 的属性 | Deployment 实际上是一个两层控制器 |
| ReplicaSet | 保证系统中 Pod 的个数永远等于指定的个数(比如,3 个) | 一个应用的版本,对应的正是一个 ReplicaSet |
OpenKruise 如何实现应用的可用性防护?Deployment 的 MaxUnavailable 是在应用滚动发布的过程中保证最小的 Pod 数量,而 RS Controller 控制器则是尽快让应用实际的福本数等于预期的副本数,并不能保证应用每时每刻的最小可用副本数。
What is a replication controller?(逐步弃用)
A replication controller ensures that a specified number of pod “replicas” are running at any one time. If there are too many, the replication controller kills some pods. If there are too few, it starts more. As opposed to just creating singleton pods or even creating pods in bulk, a replication controller replaces pods that are deleted or terminated for any reason, such as in the case of node failure. For this reason, we recommend that you use a replication controller even if your application requires only a single pod.(将Pod维持在一个确定的数量)
A replicationController is only appropriate for pods with RestartPolicy = Always.
How does a replication controller work?
replication controller中的几个概念(与replication controller config file中都有对应),RC与pod之间的关系。
Pod template
A replication controller creates new pods from a template.
Rather than specifying the current desired state of all replicas, pod templates are like cookie cutters(饼干模型切割刀). Once a cookie(饼干) has been cut, the cookie has no relationship to the cutter. Subsequent changes to the template or even a switch to a new template has no direct effect on the pods already created.
Labels
The population of pods that a replication controller monitors is defined with a label selector(A key:value pair), which creates a loosely coupled relationship between the controller and the pods controlled.(replication controller有一个label,一个replication controller监控的所有pod(controller’s target set)也都包含同一个label,两者以此建立联系)
So that only one replication controller controls any given pod, ensure that the label selectors of replication controllers do not target overlapping(重叠) sets.
To remove a pod from a replication controller’s target set, change the pod’s label(改变一个pod的label,可以将该pod从controller’s target set中移除). Use this technique to remove pods from service for debugging, data recovery, etc. Pods that are removed in this way will be replaced automatically (assuming that the number of replicas is not also changed).
Similarly, deleting a replication controller does not affect the pods it created. To delete the pods in a replication controller’s target set, set the replication controller’s replicas field to 0. (一旦为pod创建replication controller,再想删除这个pod就要修改replication controller的replicas字段了)
Common usage patterns(应用场景)
Rescheduling
Whether you have 1 pod you want to keep running, or 1,000, a replication controller will ensure that the specified number of pods exists, even in the event of node failure or pod termination (e.g., due to an action by another control agent).
Scaling
Replication controllers make it easy to scale the number of replicas up or down, either manually or by an auto-scaling control agent. Scaling is accomplished by updating the replicas field of the replication controller’s configuration file. (很轻松的改变pod的个数)
Rolling updates
Kubernetes deployment strategies
Replication controllers are designed to facilitate(促进,帮助,使容易) rolling updates to a service by replacing pods one by one.
The recommended approach is:
- Create a new replication controller with 1 replica.
- Resize the new (+1) and old (-1) controllers one by one.
- Delete the old controller after it reaches 0 replicas.
This predictably updates the set of pods regardless of unexpected failures.
The two replication controllers need to create pods with at least one differentiating label.
(逐步更新pod(现成的命令喔):建立两个Replication controllers,老的replicas减一个,新的replicas加一个,直到老的replicas为0,然后将老的Replication controllers删除)
Multiple release tracks
In addition to running multiple releases of an application while a rolling update is in progress, it’s common to run multiple releases for an extended period of time, or even continuously, using multiple release tracks. The tracks in this case would be differentiated by labels.
For instance, a service might target all pods with tier in (frontend), environment in (prod). Now say you have 10 replicated pods that make up this tier. But you want to be able to ‘canary’ a new version of this component. You could set up a replicationController with replicas set to 9 for the bulk of the replicas, with labels tier=frontend, environment=prod, track=stable, and another replicationController with replicas set to 1 for the canary, with labels tier=frontend, environment=prod, track=canary. Now the service is covering both the canary and non-canary pods. But you can update the replicationControllers separately to test things out, monitor the results, etc.
(多版本长期共存:多个replicationController,不同的track字段值)
Replication Controller Operations
Creating a replication controller
$ kubectl create -f xxx
A successful create request returns the name of the replication controller.
Replication controller configuration file
When creating a replication controller, you must point to a configuration file as the value of the -f flag. The configuration file can be formatted as YAML or as JSON, and supports the following fields:
{
"id": string,
"kind": "ReplicationController",
"apiVersion": "v1beta1",
"desiredState": {
"replicas": int,
"replicaSelector": {string: string},
"podTemplate": {
"desiredState": {
"manifest": {
manifest object
}
},
"labels": {string: string}
}},
"labels": {string: string}
}
Required fields are:
- id: The name of this replication controller. It must be an RFC1035 compatible value and be unique on this container cluster.
- kind: Always ReplicationController.
- apiVersion: Currently v1beta1.
-
desiredState: The configuration for this replication controller. It must contain:
- replicas: The number of pods to create and maintain.
- replicaSelector: A key:value pair assigned to the set of pods that this replication controller is responsible for managing. This must match the key:value pair in the podTemplate’s labels field.
- podTemplate contains the container manifest that defines the container configuration. The manifest is itself contained within a desiredState object.
- labels: Arbitrary(任意的) key:value pairs used to target or group this replication controller. These labels are not associated with the replicaSelector field or the podTemplate’s labels field. (label标签是为Replication controller分组用的,跟pod没关系)
Manifest
Manifest部分的内容不再赘述(所包含字段,是否必须,以及其意义),可以参见文档
Sample file
{
"id": "frontend-controller",
"kind": "ReplicationController",
"apiVersion": "v1beta1",
"desiredState": {
"replicas": 2,
"replicaSelector": {"name": "frontend"},
"podTemplate": {
"desiredState": {
"manifest": {
"version": "v1beta1",
"id": "frontendController",
"containers": [{
"name": "php-redis",
"image": "dockerfile/redis",
"ports": [{"containerPort": 80, "hostPort": 8000}]
}]
}
},
"labels": {"name": "frontend"}
}},
"labels": {"name": "serving"}
}
Updating replication controller pods
Google Container Engine provides a rolling update mechanism for replication controllers. The rolling update works as follows:
-
A new replication controller is created, according to the specifications in the configuration file.
-
The replica count on the new and old controllers is increased/decreased by one respectively until the desired number of replicas is reached.
If the number of replicas in the new controller is greater than the original, the old controller is first resized to 0 (by increasing/decreasing replicas one at a time), then the new controller is resized to the final desired size.
If the number of replicas in the new controller is less than the original, the controllers are resized until the new one has reached its final desired replica count. Then, the original controller is resized to 0 to delete the remaining pods.
$ kubectl rollingupdate NAME -f FILE \
[--poll-interval DURATION] \
[--timeout DURATION] \
[--update-period DURATION]
Required fields are:
- NAME: The name of the replication controller to update.
- -f FILE: A replication controller configuration file, in either JSON or YAML format. The configuration file must specify a new top-level id value and include at least one of the existing replicaSelector key:value pairs.
Optional fields are:
- –poll-interval DURATION: The time between polling the controller status after update. Valid units are ns (nanoseconds), us or µs (microseconds), ms (milliseconds), s (seconds), m (minutes), or h (hours). Units can be combined (e.g. 1m30s). The default is 3s.
- –timeout DURATION: The maximum time to wait for the controller to update a pod before exiting. Default is 5m0s. Valid units are as described for –poll-interval above.
- –update-period DURATION: The time to wait between updating pods. Default is 1m0s. Valid units are as described for –poll-interval above.
If the timeout duration is reached during a rolling update, the operation will fail with some pods belonging to the new replication controller, and some to the original controller. In this case, you should retry using the same command, and rollingupdate will pick up where it left off.
(更新过程有很多时间限制,如果更新失败,下一次更新命令将继续完成上一次遗留的工作)
Resizing a replication controller
$ kubectl --replicas COUNT resize rc NAME \
[--current-replicas COUNT] \
[--resource-version VERSION]
Required fields are:
- NAME: The name of the replication controller to update.
- –replicas COUNT: The desired number of replicas.
Optional fields are:
- –current-replicas COUNT: A precondition for current size. If specified, the resize will only take place if the current number of replicas matches this value.
-
–resource-version VERSION: A precondition for resource version. If specified, the resize will only take place if the current resource version matches this value. Resource versions are specified in a resource’s labels field, as a key:value pair with a key of version. For example:
"labels": { "version": "canary" }
Viewing replication controllers
$ kubectl get rc
A successful get command returns all replication controllers on the specified cluster in the specified zone (cluster names may be re-used in different zones). For example:
CONTROLLER CONTAINER(S) IMAGE(S) SELECTOR REPLICAS
frontend-controller php-redis dockerfile/redis name=frontend 2
You can also use kubectl get rc NAME to return information about a specific replication controller.
To view detailed information about a specific replication controller, use the container kubectl describe sub-command:
$ kubectl describe rc NAME A successful describe request returns details about the replication controller:
Name: frontend-controller
Image(s): dockerfile/redis
Selector: name=frontend
Labels: name=serving
Replicas: 2 current / 2 desired
Pods Status: 2 Running / 0 Waiting / 0 Succeeded / 0 Failed
No events.
Deleting replication controllers
To delete a replication controller as well as the pods that it controls, use the container kubectl stop command:
$ kubectl stop rc NAME
The kubectl stop resizes the controller to zero before deleting it. To delete a replication controller without deleting its pods, use container kubectl delete:
$ kubectl delete rc NAME
A successful delete request returns the name of the deleted resource.
留下评论