Kubernetes类型系统
简介
k8s中Apimachinery、Api、Client-go库之间的关系k8s.io/client-go, k8s.io/api, k8s.io/apimachinery 是基于Golang的 Kubernetes 编程的核心,是 schema 的实现。kubernetes 中 schema 就是 GVK 的属性约束 与 GVR 之间的映射。
- apimachinery 是最基础的库,包括核心的数据结构,比如 Scheme、Group、Version、Kind、Resource,以及排列组合出来的 常用的GVK、GV、GK、GVR等等,再就是编码、解码等操作。类似于Java 中的Class/Method/Field 这些。
- api 库,这个库依赖 apimachinery,提供了k8s的内置资源,以及注册到 Scheme 的接口,这些资源比如:Pod、Service、Deployment、Namespace
- client-go 库,这个库依赖前两个库,提供了访问k8s 内置资源的sdk,最常用的就是 clientSet。底层通过 http 请求访问k8s 的 api-server,从etcd获取资源信息
从api 到 go struct
kubernetes-api-machineryhttp server 或者 rpc server 要解决的一个问题是:如何解析用户的请求数据,并把他反序列化为语言中的一个具体的类型。以一个 EchoService 为例,decode 程序需要从用户请求(如 post http://echo ) 文本或者二进制数据中创建出 EchoRequestV1,提供给上层处理,同时这个 decode 函数需要足够通用,他返回的是可能是一个 Message Interface(包含通用rpc 字段), 具体内容是 EchoRequestV1。decode 相关的细节要么通过代码生成的技术提供给 decoder,要么在 二进制或者文本请求数据(或者 header等元数据)中携带这部分信息。解决这个问题有两种方式Protobuf Unmarshal/Kubernetes Scheme
k8s api
Kubernetes API是一个HTTP形式的API,主要有三种形式
- core group API(在/api/v1路径下,由于某些历史原因而并没有在/apis/core/v1路径下)
- named groups API(在对应的/apis/$NAME/$VERSION路径下)
- system-wide API(比如/metrics,/healthz)。

出于可扩展性原因考虑,Kubernetes可支持多个API版本,通过不同的API路径的方式区分。
- Domain
- API group, 在逻辑上相关的一组 Kind 集合。如 Job 和 ScheduledJob 都在 batch API group 里。同一资源的不同版本的 API,会放到一个 group 里面。一开始 所有资源都在一条
/apis/$VERSION/路径下,用户很难使用不同版本的资源并保持控制器之间的兼容性。 - Version, 标示 API group 的版本更新, API group 会有多个版本 (version)。v1alpha1: 初次引入 ==> v1beta1: 升级改进 ==> v1: 开发完成毕业。 group + domain + version 在url 上经常体现为
$group_$domain/version比如batch.tutorial.kubebuilder.io/v1 - Kind, 每个 API 组-版本包含一个或多个 API 类型Kind,表示实体的类型。直接对应一个Golang的类型,定义在type.go,会持久化存储在etcd 中
- Resource, 只是 API 中Kind的一个使用方式,通常是小写的复数词,Kind 的小写形式(例如,pods),用于标识一组 HTTP 端点(路径),来对外暴露 CURD 操作。
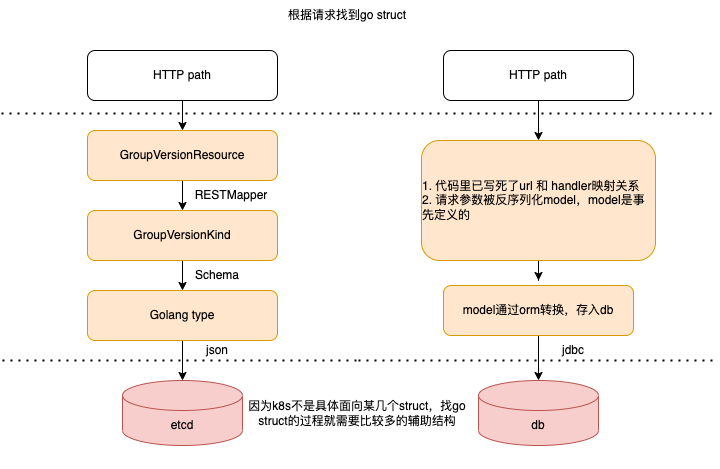
每个 Kind 和 Resource 都存在于一个APIGroupVersion 下,分别通过 GroupVersionKind 和 GroupVersionResource 标识。关联GVK 到GVR (资源存储与http path)的映射过程称作 REST mapping。

通常情况下,Kind 和 resources 之间有一个一对一的映射。 例如,pods 资源对应于 Pod 种类。但是有时,同一类型可能由多个资源返回。例如,Scale Kind 是由所有 scale 子资源返回的,如 deployments/scale 或 replicasets/scale。这就是允许 Kubernetes HorizontalPodAutoscaler(HPA) 与不同资源交互的原因。然而,使用 CRD,每个 Kind 都将对应一个 resources。
Kubernetes 基础类型系统
api machinery 代码库实现了 Kubernetes 基础类型系统(实际指的是kinds)。kinds被分为 group 和verison,因此api machinery 代码中的核心术语是 GroupVersionKind,简称GVK。 与kinds 同级概念的是 resource,也按group 和version 划分,因此有术语GroupVersionResource 简称GVR,每个GVR 对应一个http 路径,用于标识 Kubernetes API的REST 接口,比如 ` /api/v1/namespaces/{namespace}/pods,使用kubectl api-resources`命令可查看支持的Resource。
// k8s.io/apimachinery/pkg/runtime/schema/group_version.go
// 对应一个 http 路径
type GroupVersionResource struct {
Group string
Version string
Resource string
}
// 对应一个golang struct
type GroupVersionKind struct {
Group string
Version string
Kind string
}
一个GVK 到一个GVR 的映射被称为 REST mapping, RESTMapper interface/ RESTMapping struct 来完成转换。
// k8s.io/apimachinery/pkg/api/meta/interface.go
type RESTMapper interface {
// gvr ==> gvk
KindFor(resource schema.GroupVersionResource) (schema.GroupVersionKind, error)
ResourceFor(input schema.GroupVersionResource) (schema.GroupVersionResource, error)
...
}
每个 GVK 对应 Golang 代码中的到对应生成代码中的 Go type。Scheme提供了 Kinds 和相应的 Go 类型之间的映射。schema struct 将golang object 映射为可能的GVK。
Kubernetes Scheme
GVK 是一个 Object 概念,而 GVR 代表一个 Http Path。PS: rest path ==> gvr ==> gvk ==> empty go struct ==> decoder.decode(empty go struct) ==> go struct.
Kubernetes 资源对象序列化实现序列化和反序列化在很多项目中都有应用,Kubernetes也不例外。Kubernetes中定义了大量的API对象,为此还单独设计了一个包(https://github.com/kubernetes/api),方便多个模块引用。API对象在不同的模块之间传输(尤其是跨进程)可能会用到序列化与反序列化,不同的场景对于序列化个格式又不同,比如grpc协议用protobuf,用户交互用yaml(因为yaml可读性强),etcd存储用json。Kubernetes反序列化API对象不同于我们常用的json.Unmarshal()函数(需要传入对象指针),Kubernetes需要解析对象的类型(Group/Version/Kind),根据API对象的类型构造API对象,然后再反序列化。
gvk := schema.GroupVersionKind{Group: "batch", Version: "v2alpha1", Kind: "Job"}
obj := api.Scheme.New(gvk) // 根据API对象的类型构造API对象
codec := api.Codecs.LegacyCodec(gvk.GroupVersion())
codec.Decode(reqBody, gvk, obj) // 假设reqBody 是一段json,则需要 通过reflect 获取个字段的类型并为字段赋值的
go struct
kubernetes object 在go 中是struct(k8s.io/api/core/v1/types.go),struct 的filed 当然不同, 但也共用一些结构 runtime.Object。用来约定:可以set/get GroupVersionKind 和 deepCopy,即k8s object 存储其类型并允许克隆。
// k8s.io/apimachinery/pkg/runtime/interface.go
type Object interface{
GetObjectKind() schema.ObjectKind
DeepCopyObject() Object
}
type ObjectKind interface{
SetGroupVersionKind(kind GroupVersionKind)
GroupVersionKind() GroupVersionKind
}
// k8s.io/apimachinery/pkg/apis/meta/v1/types.go
// 实现 ObjectKind
type TypeMeta struct{
Kind string `json:"kind"`
APIVersion string `json:"apiVersion"`
}
type ObjectMeta struct{
Name string
Namespace string
UID types.UID
ResourceVersion string
CreationTimestamp Time
DeletionTimestamp Time
Labels map[string]string
Annotations map[string]string
}
go 中的pod 声明 如下所示
// k8s.io/api/core/v1/types.go
type Pod struct{
metav1.TypeMeta
metav1.ObjectMeta `json:"metadata"`
Spec PodSpec `json:"spec"`
Status PodStatus `json:"status"`
}
每一个对象都包含两个嵌套对象来描述规格(Spec)和状态(Status),对象的规格其实就是我们期望的目标状态。而Status描述了对象的当前状态(或者说愿望的结果),是我们观察集群本身的一个接口。
type Deployment struct {
metav1.TypeMeta `json:",inline"`
metav1.ObjectMeta `json:"metadata,omitempty" protobuf:"bytes,1,opt,name=metadata"`
Spec DeploymentSpec `json:"spec,omitempty" protobuf:"bytes,2,opt,name=spec"`
Status DeploymentStatus `json:"status,omitempty" protobuf:"bytes,3,opt,name=status"`
}
注册go struct 到schema
为了使 scheme正常工作,必须将golang struct 注册到 scheme 中。对于Kubernetes 核心类型,在k8s.io/client-go/kubernetes/scheme 包中 均已预先注册
// k8s.io/client-go/kubernetes/scheme/register.go
var Scheme = runtime.NewScheme()
var AddToScheme = localSchemeBuilder.AddToScheme
func init(){
v1.AddToGroupVersion(Scheme, schema.GroupVersion{Version: "v1"})
utilruntime.Must(AddToScheme(Scheme))
}
var localSchemeBuilder = runtime.SchemeBuilder{
corev1.AddToScheme,
appsv1.AddToScheme,
}
// k8s.io/api/core/v1/register.go
var (
SchemeBuilder = runtime.NewSchemeBuilder(addKnownTypes)
AddToScheme = SchemeBuilder.AddToScheme
)
func addKnownTypes(scheme *runtime.Scheme) error {
scheme.AddKnownTypes(SchemeGroupVersion,
&Pod{},
&PodList{},
&Service{},
)
...
}
使用schema 进行序列化和序列化
Scheme defines methods for serializing and deserializing API objects, a type registry for converting group, version, and kind information to and from Go schemas, and mappings between Go schemas of different versions. A scheme is the foundation for a versioned API and versioned configuration over time.
// k8s.io/apimachinery/pkg/runtime/scheme.go
type Scheme struct {
// a Type is a particular Go struct,比如k8s.io/api/apps/v1.StatefulSet
gvkToType map[schema.GroupVersionKind]reflect.Type
typeToGVK map[reflect.Type][]schema.GroupVersionKind
...
}
// go struct ==> gvk
func (s *Scheme) ObjectKinds(obj Object) ([]schema.GroupVersionKind, bool, error) {...}
// gvk ==> go struct
func (s *Scheme) New(kind schema.GroupVersionKind) (Object, error) {
if t, exists := s.gvkToType[kind]; exists {
return reflect.New(t).Interface().(Object), nil
}
...
return nil, NewNotRegisteredErrForKind(s.schemeName, kind)
}
Protobuf Unmarshal
根据 生成的 golang 结构体的 Field tag来做 Unmarshal
// 生成的 golang 结构体
type EchoRequest struct {
A string `protobuf:"bytes,1,opt,name=A,proto3" json:"A,omitempty"`
}
// 收到请求,在 Unmarshal 过程中会调用这个函数
func (m *EchoRequest) XXX_Unmarshal(b []byte) error {
return xxx_messageInfo_EchoRequest.Unmarshal(m, b)
}
var xxx_messageInfo_EchoRequest proto.InternalMessageInfo
// InternalMessageInfo 是 Unmarshal 相关信息的存储位置
// b 是 protocol buffer raw 数据,而a 是要 unmarshal 到的结构
// 基础库不关心具体 unmarshal 类型,始终 unmarshal 到一个 interface Message
// 实际上面到结构调用到时候 会是 EchoRequest 类型
func (a *InternalMessageInfo) Unmarshal(msg Message, b []byte) error {
// ... 略
err := u.unmarshal(toPointer(&msg), b)
return err
}
func (u *unmarshalInfo) unmarshal(m pointer, b []byte) error{
if atomic.LoadInt32(&u.initialized) == 0 {
// 保存 unmarshal 这个类型的函数、信息到一个结构里面,加速重复的 unmarshal
u.computeUnmarshalInfo()
}
// .... 略
if fn := f.unmarshal; fn != nil {
var err error
// unmarshal 这个 field 这里的关键是 unmarshal 到原始 bytes 设置到对应字段的
// offset上面去,里面比较关键的是用了 golang reflect的 StructField
// StructField 的 Offset 是固定的,根据 一个结构的指针的 pointer 以及 Field的
// offset 就可以直接用指针设置 结构的某个字段内容了
b, err = fn(b, m.offset(f.field), wire)
// ....
}
}
kubernetes 对象
Kubernetes 对象是系统中的持久实体,描述集群的期望状态
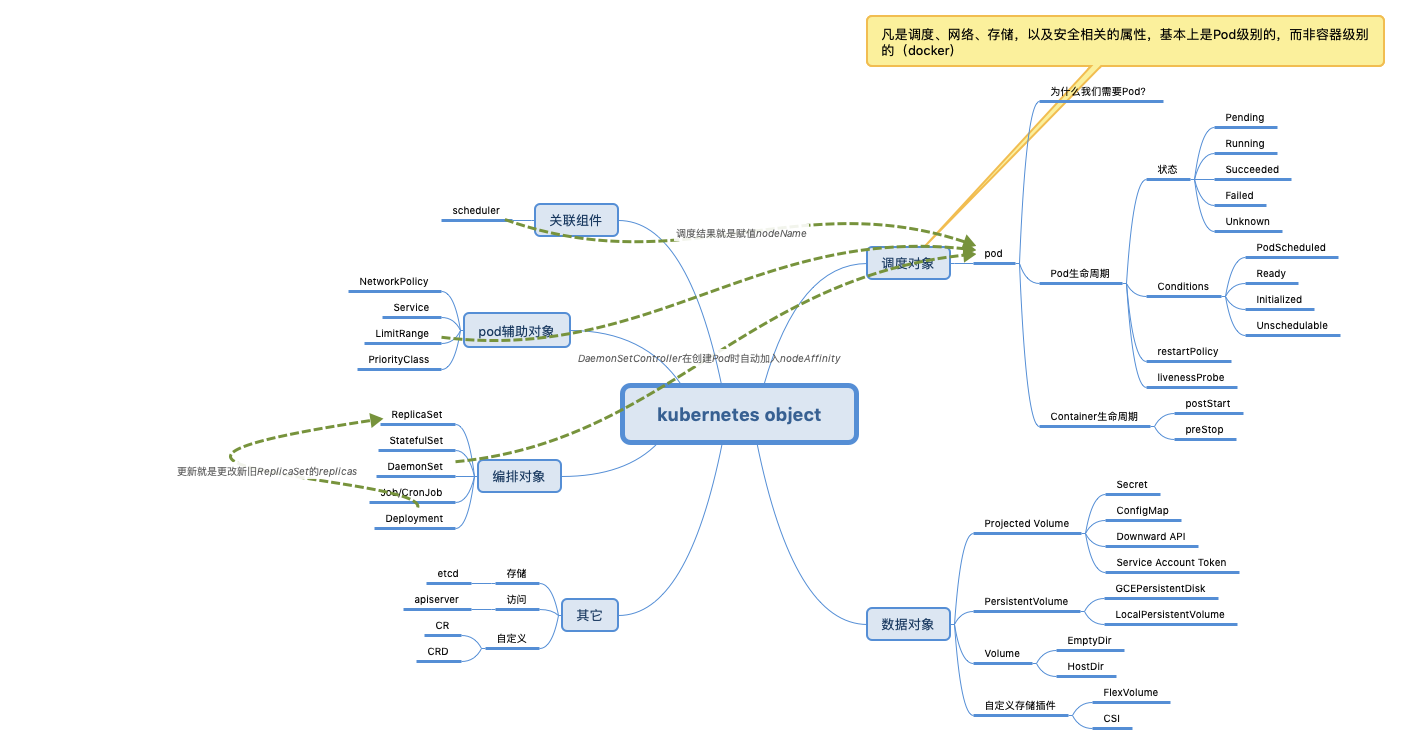
你一定有方法在不使用 Kubernetes、甚至不使用容器的情况下,自己 DIY 一个类似的方案出来。但是,一旦涉及到升级、版本管理等更工程化的能力,Kubernetes 的好处,才会更加凸现。
Kubernetes 的各种object,就是常规的各个项目组件在 kubernetes 上的表示 深入理解StatefulSet(三):有状态应用实践 充分体现了在我们把服务 迁移到Kubernetes 的过程中,要做多少概念上的映射。
百度混部实践:如何提高 Kubernetes 集群资源利用率?百度为支持混部在每个node 除了kubelet 之外还部署了一个agent(负责数据上报和下发动作执行),定义了很多策略,通过给这些策略设计了一个这个 CRD ,单机引擎通过对 APIServer 发起 List-watch,实时的 Watch CR 的变更,实时调整参数和相关策略。
CustomResourceDefinition 的版本
Versions in CustomResourceDefinitionsCustomResourceDefinition API 的 versions 字段可用于支持你所开发的 定制资源的多个版本。
apiVersion: apiextensions.k8s.io/v1
kind: CustomResourceDefinition
metadata:
name: mpijobs.kubeflow.org
spec:
group: kubeflow.org
names:
kind: MPIJob
plural: mpijobs
shortNames:
- mj
- mpij
singular: mpijob
scope: Namespaced
versions:
- name: v1alpha2
schema: ...
served: true
storage: false
- name: v1
schema: ...
served: true
storage: false
- name: v2beta1
schema: ...
served: true
storage: true
- 对apiserver,crd版本可以具有不同的schema,默认存储storage=true的版本,版本之间如果字段相同 默认直接转化,如果字段不同 可以自定义Webhook conversion。 如果storage version发生变化, 已有对象不会被自动转换。
- 当读取对象时,作为路径的一部分,你需要指定版本。 如果所指定的版本与对象的持久版本不同,Kubernetes 会按所请求的版本将对象返回,你可以以当前提供的任何版本 来请求对象,自然也可以通过client-go 监听到变化。如果你更新一个现有对象,它将以当前的存储版本被重写。
-
对kubectl,kubectl 使用 具有最高优先级的版本作为访问对象的默认版本,顺序示例
- v10 - v2 - v1 - v11beta2 - v10beta3 - v3beta1 - v12alpha1 - v11alpha2 - foo1 - foo10
留下评论