Kubernetes 控制器模型
简介
《阿里巴巴云原生实践15讲》 K8S 的关键词就是最终一致性,所有的 Controller 都会朝着最终一致 性不断 sync。PS:文章里经常出现一个词:面向终态。
control system
Kubernetes: Controllers, Informers, Reflectors and Stores
kube-controller-manager In applications of robotics and automation, a control loop is a non-terminating loop that regulates the state of the system(在自动化行业是常见方式). We really like the Kubernetes ideology of seeing the entire system as a control system. That is, the system constantly tries to move its current state to a desired state.The worker units that guarantee the desired state are called controllers. 控制器就是保证系统按 desired state运行。
声明式API对象与控制器模型相辅相成,声明式API对象定义出期望的资源状态,实际状态往往来自于 Kubernetes 集群本身,比如kubelet 通过心跳汇报的容器状态和节点状态,或者监控系统中保存的应用监控数据,或者控制器主动收集的它自己感兴趣的信息。控制器模型则通过控制循环(Control Loop)将Kubernetes内部的资源调整为声明式API对象期望的样子。因此可以认为声明式API对象和控制器模型,才是Kubernetes项目编排能力“赖以生存”的核心所在。
for {
actualState := GetResourceActualState(rsvc)
expectState := GetResourceExpectState(rsvc) // 来自yaml 文件
if actualState == expectState {
// do nothing
} else {
Reconcile(rsvc) // 编排逻辑,调谐的最终结果一般是对被控制对象的某种写操作,比如增/删/改 Pod
}
}

Reconcile 的是什么?在Kubernetes中,Pod是调度的基本单元,也是所有内置Workload管理的基本单元,无论是Deployment还是StatefulSet,它们在对管理的应用进行更新时,都是以Pod为单位。所谓编排,最终落地就是 更新pod 的spec ,condition,container status 等数据(原地更新或重建符合这些配置的pod)。非基本单位的 Deployment/StatefulSet 的变更更多是 数据的持久化。
整体架构
《programming kubernetes》 Kubernetes 控制平面大量使用事件和松散耦合的组件。其它分布式系统使用rpc 来触发行为,但Kubernetes 并没有这么做(纯粹依赖事件来进行多组件协同,许多独立的控制循环只通过 api server 上对象的变化进行通信,有点事件驱动架构的意思,根据对象变动采取动作,所谓采取动作也是cud对象)。Kubernetes controller 监听api server 中的Kubernetes 对象操作:添加、删除、更新。当发生此类事件时,controller 将执行其业务逻辑。监听事件 是通过api server 和controller 之间的http 长连接发送,从而驱动informer
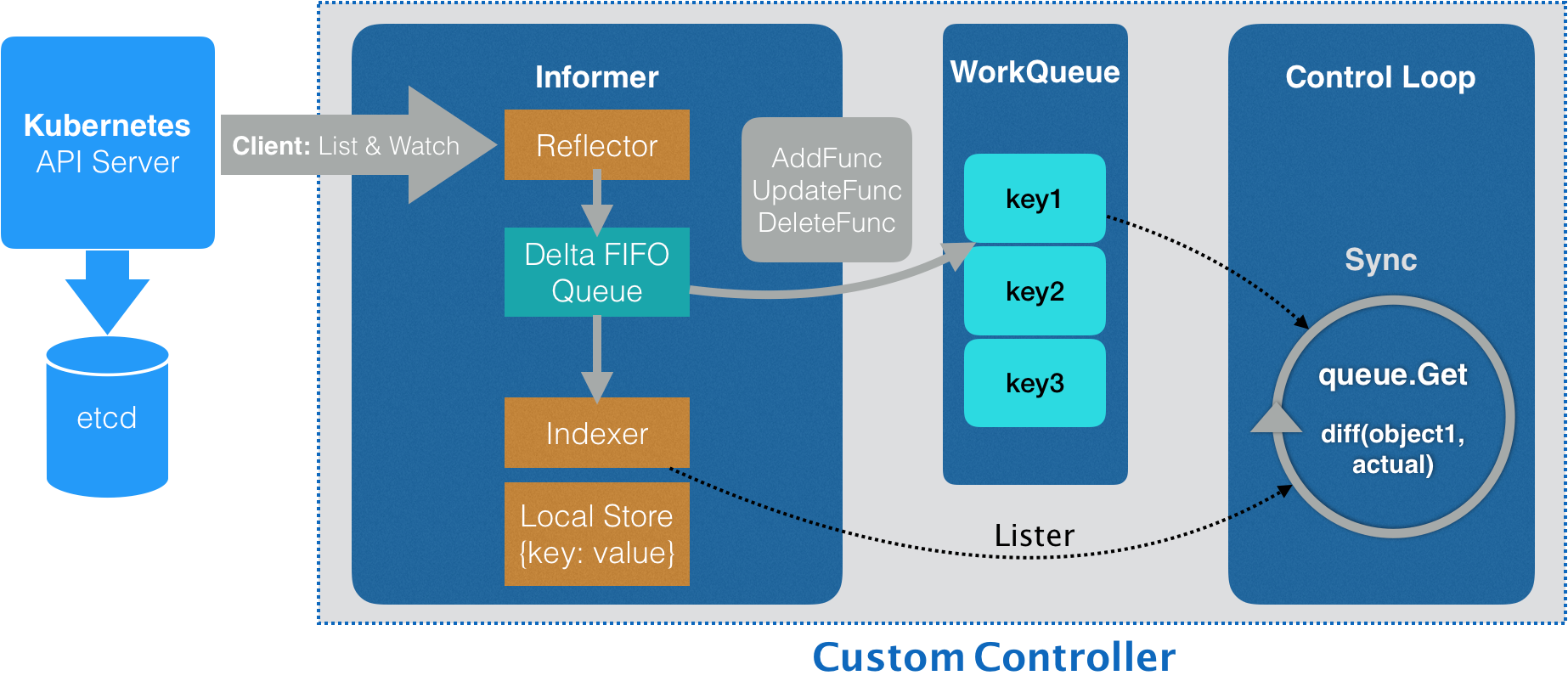
控制器与Informer——如何高效监听一个http server
控制器与api server的关系——从拉取到监听:In order to retrieve an object’s information, the controller sends a request to Kubernetes API server.However, repeatedly retrieving information from the API server can become expensive. Thus, in order to get and list objects multiple times in code, Kubernetes developers end up using cache which has already been provided by the client-go library. Additionally, the controller doesn’t really want to send requests continuously. It only cares about events when the object has been created, modified or deleted.
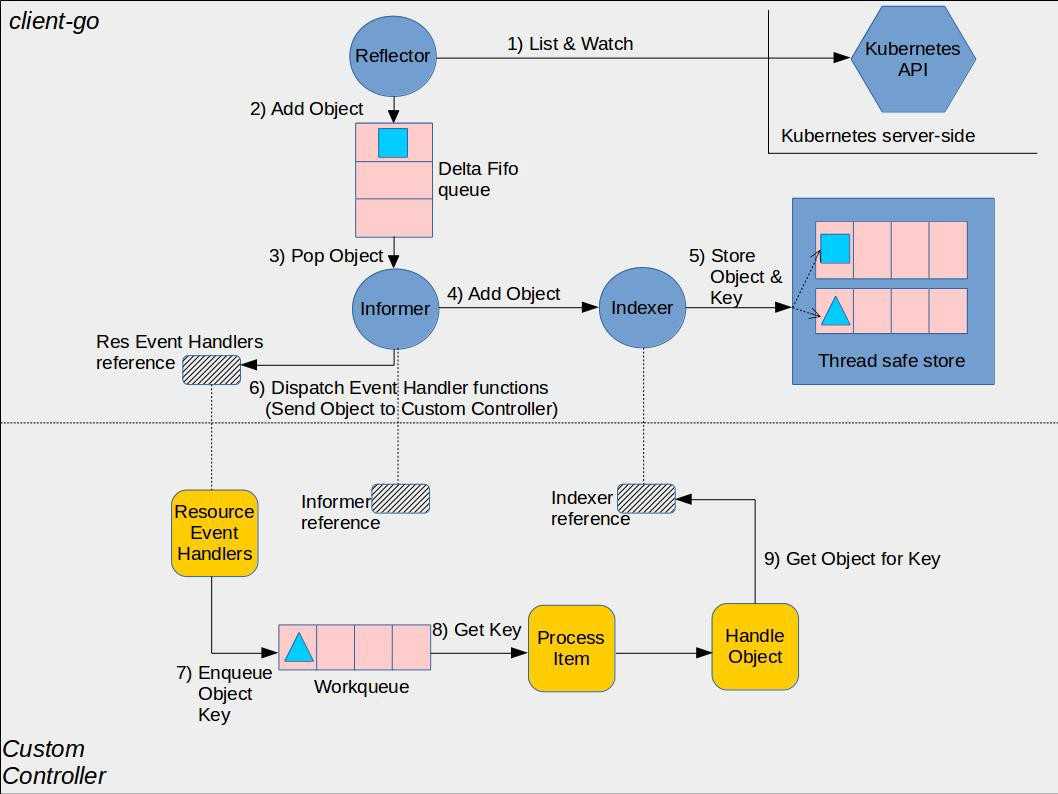
上图上半部分为client-go 原理,下半部分是informer 与controller 的交互。Informer 间接通过工作队列(Workqueue)与controller 通信
- Informer 可以添加自定义回调函数,但controller 并不直接 注册业务 逻辑到 informer 回调上。一旦有资源被添加、修改或删除,就会将相应的事件加入到工作队列中。
- 工作队列用于状态更新事件的有序处理并协助实现重试。所有的控制器排队进行读取,一旦某个控制器发现这个事件与自己相关,就执行相应的操作。如果操作失败,就将该事件放回队列,等下次排到自己再试一次。如果操作成功,就将该事件从队列中删除。
事件驱动
在Kubernetes 控制平面中,许多组件会更改apiserver 上的对象,每次更改都会导致事件的发生。另一方面,很多组件对这些事件有兴趣。如果组件消费事件时 出现错误,就很容易丢失事件。k8s 由事件驱动,但总是基于最新状态执行逻辑,以replicaset controller 为例,假设其收到 pod 更新事件,它不会管当前pod 如何,而是将pod.spec.repliacas 与正在运行的pod做比较。当它丢失事件时,下次收到pod 更新事件 会再次执行。
更改集群内或集群外对象
controller 消费事件,处理结果是更改其管理资源、对象的状态,具体逻辑特定于领域或任务。此外,资源本身不一定必须是Kubernetes 集群的一部分,即controller 可以更改位于Kubernetes外部的资源(例如云存储服务) 的状态。
并发写入可能因为写冲突而失败:为了进行无锁的并发操作,Kubernetes api server 使用乐观锁 进行并发控制。言而言之,如果api server 检测到有并发写,它将拒绝两个写操作中的后者,然后由客户端(controller、scheduler、kubectl)来处理写冲突并充实写操作。
从client.Get 调用返回的对象 foo 包含一个资源版本号(ObjectMeta struct的一部分),实际上是 etcd 键值对的版本号,etcd 维护着一个计数器,每次修改键的值时,计数器都会增加。
理解 K8s 资源更新机制,从一个 OpenKruise 用户疑问开始
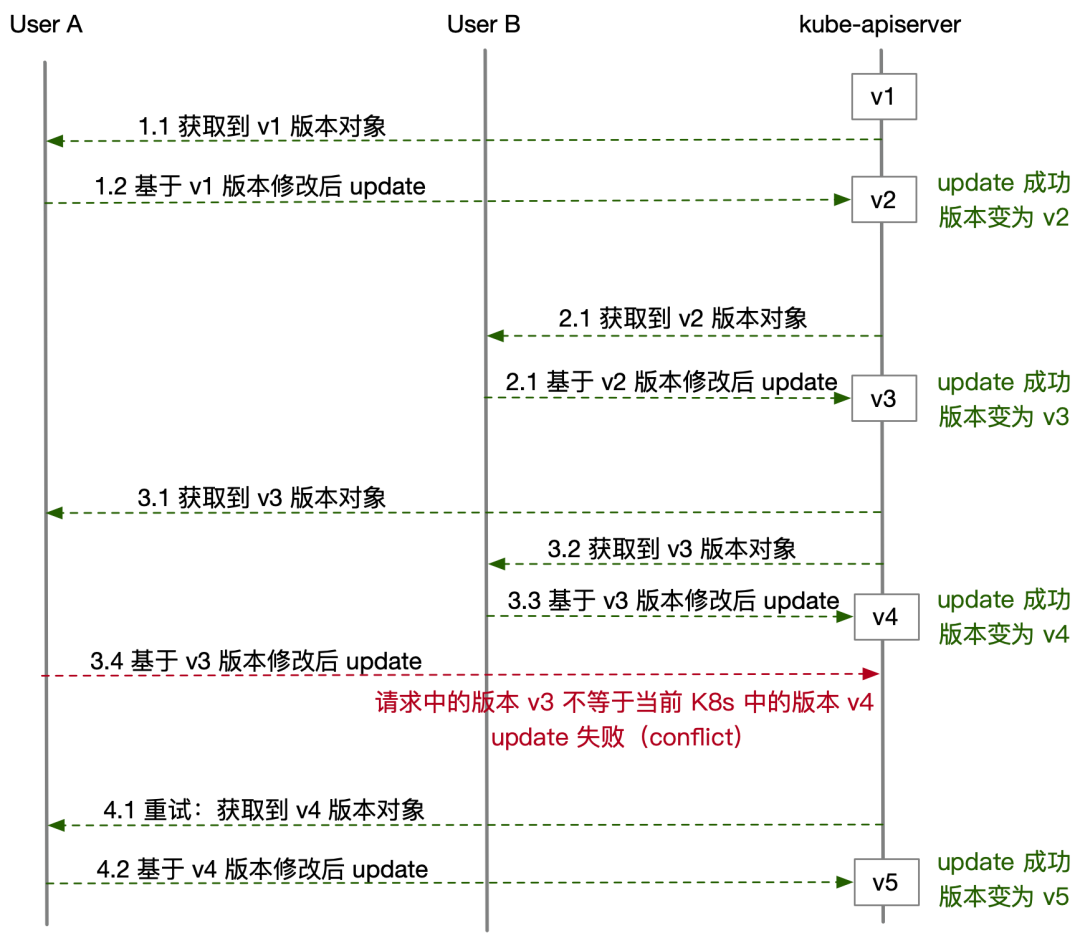
单个Controller的工作原理
从DeploymentController 及 ReplicaSetController 观察到的共同点
- struct 中都包含获取 决策所以依赖 资源的lister,对于DeploymentController 是DeploymentLister/ReplicaSetLister/PodLister ,对于ReplicaSetController 是ReplicaSetLister和 PodLister
- struct 中都包含 workqueue, workqueue 数据生产者是 Controller 注册到所以依赖的 Informer 的AddFunc/updateFunc/DeleteFunc,workqueue 数据消费者是 control loop ,每次循环都是 从workqueue.Get 数据开始的。
- struct 都包含 kubeClient 类型为 clientset.Interface,controller 比对新老数据 将决策 具体为“指令”使用kubeClient写入 apiserver ,然后 scheduler 和 kubelet 负责干活儿。
-
相同的执行链条:
Run ==> go worker ==> for processNextWorkItem ==> syncHandler。Run 方法作为 Controller 逻辑的统一入口,启动指定数量个协程,协程的逻辑为:wait.Until(dc.worker, time.Second, stopCh),control loop 具体为Controller 的worker 方法,for 循环具体为for processNextWorkItem(){},两个Controller 的processNextWorkItem 逻辑相似度 90%: 从queue 中get一个key,使用syncHandler 处理,处理成功就标记成功,处理失败就看情况将key 重新放入queue。func processNextWorkItem() bool { key, quit := queue.Get() if quit { return false} defer queue.Done(key) err := syncHandler(key.(string)) handleErr(err, key) return true }
数据结构
Controller Mananger 的主要逻辑便是 先初始化 资源(重点就是Informer) 并启动Controller。kubectl 创建 Pod 背后到底发生了什么?将 Deployment 记录存储到 etcd 并初始化后,就可以通过 kube-apiserver 使其可见,DeploymentController工作就是负责监听 Deployment 记录的更改——控制器通过 Informer 注册cud事件的回调函数。
外围——循环及数据获取
// Run begins watching and syncing.
func (dc *DeploymentController) Run(workers int, stopCh <-chan struct{}) {
defer utilruntime.HandleCrash()
defer dc.queue.ShutDown()
if !controller.WaitForCacheSync("deployment", stopCh, dc.dListerSynced, dc.rsListerSynced, dc.podListerSynced) {
return
}
for i := 0; i < workers; i++ {
go wait.Until(dc.worker, time.Second, stopCh)
}
<-stopCh
}
重点就是 go wait.Until(dc.worker, time.Second, stopCh)。for 循环隐藏在 k8s.io/apimachinery/pkg/util/wait/wait.go 工具方法中,func Until(f func(), period time.Duration, stopCh <-chan struct{}) {...} 方法的作用是 Until loops until stop channel is closed, running f every period. 即在stopCh 标记停止之前,每隔 period 执行 一个func,对应到DeploymentController 就是 worker 方法
// worker runs a worker thread that just dequeues items, processes them, and marks them done.
// It enforces that the syncHandler is never invoked concurrently with the same key.
func (dc *DeploymentController) worker() {
for dc.processNextWorkItem() {
}
}
func (dc *DeploymentController) processNextWorkItem() bool {
// 取元素
key, quit := dc.queue.Get()
if quit {
return false
}
// 结束前标记元素被处理过
defer dc.queue.Done(key)
// 处理元素
err := dc.syncHandler(key.(string))
dc.handleErr(err, key)
return true
}
dc.syncHandler 实际为 DeploymentController 的syncDeployment方法
一次调协(Reconcile)
syncDeployment 包含 扩容、rollback、rolloutRecreate、rolloutRolling 我们裁剪部分代码,以最简单的 扩容为例
// syncDeployment will sync the deployment with the given key.
func (dc *DeploymentController) syncDeployment(key string) error {
namespace, name, err := cache.SplitMetaNamespaceKey(key)
deployment, err := dc.dLister.Deployments(namespace).Get(name)
// List ReplicaSets owned by this Deployment, while reconciling ControllerRef through adoption/orphaning.
rsList, err := dc.getReplicaSetsForDeployment(d)
scalingEvent, err := dc.isScalingEvent(d, rsList)
if scalingEvent {
return dc.sync(d, rsList)
}
...
}
// sync is responsible for reconciling deployments on scaling events or when they are paused.
func (dc *DeploymentController) sync(d *apps.Deployment, rsList []*apps.ReplicaSet) error {
newRS, oldRSs, err := dc.getAllReplicaSetsAndSyncRevision(d, rsList, false)
...
dc.scale(d, newRS, oldRSs);
...
allRSs := append(oldRSs, newRS)
return dc.syncDeploymentStatus(allRSs, newRS, d)
}
scale要处理 扩容或 RollingUpdate 各种情况,此处只保留扩容逻辑。
func (dc *DeploymentController) scale(deployment *apps.Deployment, newRS *apps.ReplicaSet, oldRSs []*apps.ReplicaSet) error {
// If there is only one active replica set then we should scale that up to the full count of the
// deployment. If there is no active replica set, then we should scale up the newest replica set.
if activeOrLatest := deploymentutil.FindActiveOrLatest(newRS, oldRSs); activeOrLatest != nil {
if *(activeOrLatest.Spec.Replicas) == *(deployment.Spec.Replicas) {
return nil
}
_, _, err := dc.scaleReplicaSetAndRecordEvent(activeOrLatest, *(deployment.Spec.Replicas), deployment)
return err
}
...
}
func (dc *DeploymentController) scaleReplicaSetAndRecordEvent(rs *apps.ReplicaSet, newScale int32, deployment *apps.Deployment) (bool, *apps.ReplicaSet, error) {
// No need to scale
if *(rs.Spec.Replicas) == newScale {
return false, rs, nil
}
var scalingOperation string
if *(rs.Spec.Replicas) < newScale {
scalingOperation = "up"
} else {
scalingOperation = "down"
}
scaled, newRS, err := dc.scaleReplicaSet(rs, newScale, deployment, scalingOperation)
return scaled, newRS, err
}
func (dc *DeploymentController) scaleReplicaSet(rs *apps.ReplicaSet, newScale int32, deployment *apps.Deployment, scalingOperation string) (bool, *apps.ReplicaSet, error) {
sizeNeedsUpdate := *(rs.Spec.Replicas) != newScale
annotationsNeedUpdate := ...
scaled := false
var err error
if sizeNeedsUpdate || annotationsNeedUpdate {
rsCopy := rs.DeepCopy()
*(rsCopy.Spec.Replicas) = newScale
deploymentutil.SetReplicasAnnotations...
// 调用api 接口更新 对应ReplicaSet 的数据
rs, err = dc.client.AppsV1().ReplicaSets(rsCopy.Namespace).Update(rsCopy)
...
}
return scaled, rs, err
}
调用api 接口更新Deployment 对象本身的数据
// syncDeploymentStatus checks if the status is up-to-date and sync it if necessary
func (dc *DeploymentController) syncDeploymentStatus(allRSs []*apps.ReplicaSet, newRS *apps.ReplicaSet, d *apps.Deployment) error {
newStatus := calculateStatus(allRSs, newRS, d)
if reflect.DeepEqual(d.Status, newStatus) {
return nil
}
newDeployment := d
newDeployment.Status = newStatus
_, err := dc.client.AppsV1().Deployments(newDeployment.Namespace).UpdateStatus(newDeployment)
return err
}
留下评论