如何看待大牛的经验文
简介
网络上经常会有各种大牛(cto、阿里架构师等)的分享,诸如:
- 技术人员2年、3年、5年如何提高自己
- 程序猿自我修炼之路
- 工作八年、十年总结
会列出各种路线图,分为几类
- 过程式,即不同阶段要做什么
-
目标式,即不管干什么,到一定要阶段要掌握xx。比如:
- 分析源码,主要指常用设计模式、spring3/4/5、mybatis
- 分布式架构,包括原理、中间件以及 应用层框架(计算、微服务、存储等)
- 并发编程、性能调优
- 开发工具工程化,包括maven、jenkins、sonar、git等
- 项目实战,比如一个b2c项目包括:用户认证、店铺商品、订单支付、数据统计分析、通知推送等
技术人员在面对这些攻略,要认识到以下几点,否则这样的文章看的越多就越焦虑和困惑:
-
有自己的侧重,比如笔者就觉得spring 代码组织的不太好,在买过一本书对其原理有大致体会后便没有深究,springmvc 源码笔者到现在都没有深入看过。
- 有的东西不理解到细节难受,你知道底层原理,然后可以推知上层所有因果
- 有的东西不耽误用就行,可以通过博客等把别人二手结论拿来用。比如要实现一个自定义注解,博客说spring xx组件可以实现,你demo 做出来就可以用在项目中。
- 你对项目的定位(自己学到何种程度)要有自己的判断,当然,这个判断要根据实际情况调整。
- 有自己的路线图,靠兴趣、“事到临头”来推动。别人是1=>2=>3开始学,你2==>3==>1学也没什么问题,甚或是2.1 ==>1.6 ==>3.2==>2.5。比如jvm调优很有意义,但一则很多人用不上,二则过早接触也看不懂。你先看点,关键时刻知道有这么个事儿就行。一般来说,只要你追求去做更大和复杂的项目,123终究会体验全的。
- 看文章 要为我所用,前提是你自己有一套取舍观、方法论和路线图。看文章的目的不是刷新自己,而是吸取自己之前没注意到的知识、观点和方法论,添长处去短板。
为何要想这些东西,因为如果这些东西想不清楚,他们会一次次来占用你的精力、带来困惑和烦扰。以后看到这类“经验文” 应该不会再引起难受了。有一句话:很多人为了不思考愿意做任何事情。但其实,很多人没认识到该思考这个问题,也没认识到一直拒绝思考导致自己付出了多大的代价。
思考是对复杂事务、信息降维处理, 以便于主动规划,而不总是被动应对。你应该先有一套知识图谱、方法论,然后碰到新东西,去充实它们。而不是左支右绌,忙于应对。
知识模型
- 作为开发人员,更加关注知识的深度,以便有足够的知识储备满足工作需要(正确地做事)。开发人员在职业生涯的早期,应该关注于自身知识储备的增长,并保持技术深度。PS:学习了,深度=你知道自己知道。广度=你知道自己知道+你知道自己不知道。
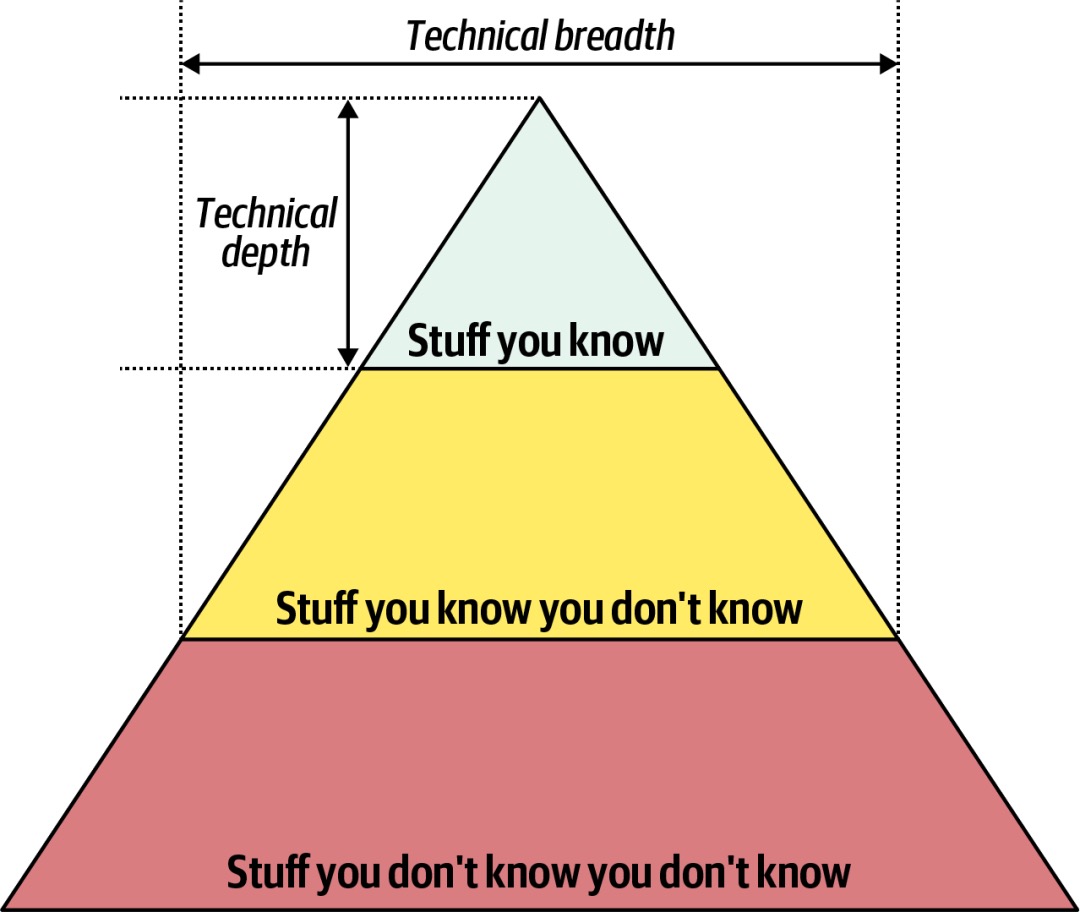
-
作为架构师,之所以技术的广度比深度更重要,是因为架构师的重要职责之一是进行架构决策(做正确的事)。系统架构设计是关于权衡的艺术,在特定的问题域上下文下,架构师需要在诸多可行的解决方案间进行权衡和决策,这也对其技术广度提出了要求。开发人员成长为架构师,应该更加关注知识的广度,并在几个特定领域深耕,以便有足够的知识支撑架构决策。对于架构师来说,要想设计优秀的系统,关键在于“洞察力”:是否准确抓住系统设计的关键点和复杂点,是否能够预判业务未来发展给系统带来的挑战。可以把架构师类比成乐团“指挥家”,不亲自演奏每个音符,却要决定用哪些乐器、以什么节奏、在何种结构下协同发声,才能奏出一曲稳健而富有张力的交响乐。架构师的核心思维则是“取舍”(Trade-off)——在资源有限、目标冲突、信息不全的现实约束下,做出全局最优的权衡。他必须不断问自己:是要强一致性,还是高可用性?是快速上线抢占市场,还是花时间夯实基础?是自研以掌握控制权,还是采用成熟方案降低风险?是追求极致性能,还是优先保障开发效率?架构师必须认识到:没有完美的架构,只有“在特定上下文中最合适的选择”,架构师需要在不确定性的环境下做出判断和选择,需要容忍模糊性,接受“局部不完美”,甚至主动放弃某些技术亮点,只为守住系统的核心目标。这种思维不是非黑即白的逻辑推导,而是多维度、动态、平衡、取舍的选择艺术。
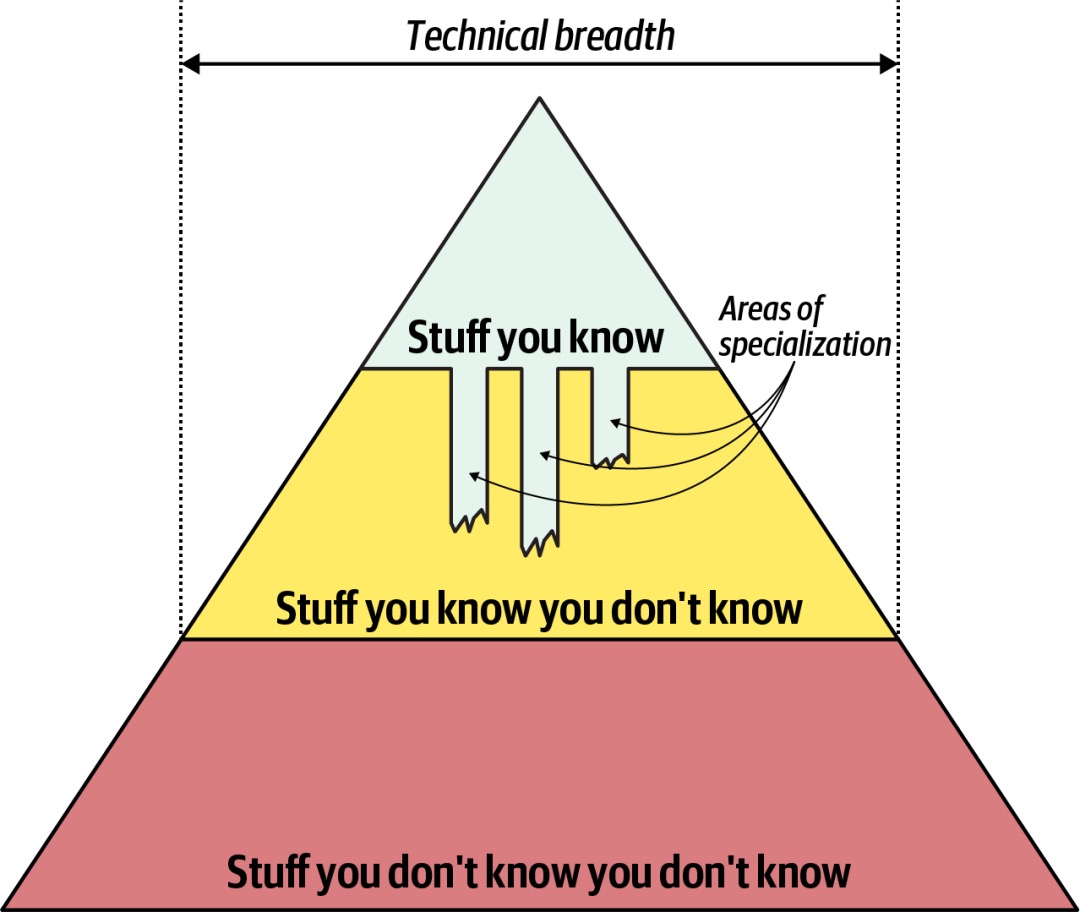
虽然开发人员和架构师在知识域的关注点上存在差异,但在认知层面都可以统一到Bloom认知层次模型。该模型将认知层次划分为逐步递进的六个层次:

不论是架构师还是开发人员,Bloom认知层次模型都适用。通过不断的学习扩展自身的知识体系,在识记、理解和应用的同时,要持续的培养分析、评估和创造的能力,逐步向高层次的认知水平提升。但需要注意的是:知识不等于认知,避免陷入知识学习的陷阱。知识是无限的,没有人能够以有限的精力去学习无限的知识。不论是开发人员还是架构师,又或者其他角色,不应该只将精力投入在知识边界的扩充,而应该注重从知识到认知提升的转变。格物以致知,对表象不断的归纳、演绎直至事物的本象,探寻事物背后的规律,建立更高层的认知。这种认知层次由下及上的跃升有两种方式:
- 悟:由内向外,通过不断积累、持续思考,由量变到质变,直至 “开悟”
- 破:自外向内,高层次或不同的思想输入碰撞,加速认知层次的突破
如何学习
费曼学习法的要点:
- 追溯这个新知识的前世今生。对于文中提出的技术,我们需要按符合常人逻辑思考顺序的方式想一遍,也即【之前的人是怎么解决这个问题的?】【之前的解决方法优缺点是什么?】【新技术的作者是基于什么提出目前的解决方法?】【为什么新技术要被设计成这样,换成另一种思路行不行】。在这个过程中,始终有一条主线牢牢贯穿你的整个逻辑思维过程,比起怎么做,多问问自己为什么。当然,这些“追溯”的内容在原始论文中基本不会有(related work是粗糙的),所以需要我们做大量的额外调查阅读。
- 用老师的口吻来写笔记。
- 不要害怕有一天会忘记这些知识。我们时常会有一种想法“很多技术不经常用,就会忘记了,因此即便我此刻学得如此认真,我也不能永久记住,那有什么用呢?”我个人觉得,“忘记”才是常态,而我们写笔记的目的就是,有一天当我们需要用起这些被忘记的技术时,我们能通过自己的这份笔记,在10分钟内迅速回忆起所有的细节,而不需要再四处查找资料。PS:感同身受。另一个是,有一个笔记,你就有一个知识体系,下次碰到一个新东西,就可以place it in context. 和论文有一条逻辑主线一样,代码也有其主线。找到代码主线的好方法就是绘制架构图。使用【主体架构图 + 细节】的方式来把控整个代码的阅读。
- 优先用官方提供的架构图。比如vllm这种,官方就给过几版很清晰的架构图,方便我们快速理解设计思想,然后在读代码的过程中不断完善架构图细节。
- 没有官方架构图时,自己最好在阅读源码后绘制一张。 代码也是文字,它也能串成一个故事。如果你能在阅读源码后,把源码转变成一张张图,能做到对着图,从架构到关键细节复述一遍整个源码的设计思路,那么这份代码就算被完全理解了(不要只看架构,不看细节,有很多trick就藏在细节里)。如果对于一些经典的、常用的代码我们能按这个方式走一遍,总有一天我们会发现,这一类架构的代码,我们基本都能做到扫一遍就能清楚知道它在做什么事。
这里想给大家一点信心,请不要因为担心自己努力钻研和做过的事情没有回报,而失去探索的热情。因为【用心做过的事情有回报】本来就是偶发事件,但【用心做过的事情会留下痕迹】却是必然事件,收获若不在此时,必然在未来没有想到的某一刻。所以不管是付出的过程,还是等待收获的过程,都多一些耐心就可以。就和我们学习新技术和代码一样,最终能够达到一个令自己满意的、自洽的逻辑就行了,没有标准答案,否则就不会有后继无数次的迭代。

留下评论