go gc
前言
Visualizing memory management in Golang 有动图建议细读
字节跳动 Go 语言面试高频题 02:垃圾回收器 GC 示例讲的非常好。
推荐曹大的 聊聊Go 语言的 GC 实现,垃圾回收的理论,推荐阅读:《gc handbook》,可以解答你所有的疑问。
基本思想
最初的Go原型使用了一个基本的、停止世界(STW)的垃圾收集器,当然,它在网络服务器中引入了明显的尾部延时。今天,Go使用了一个完全并发的垃圾收集器,暂停时间不到一毫秒,通常只有几微秒,与堆的大小无关。最主要的延迟是操作系统向必须中断的线程传递信号所需的时间。
GC实例:Python和Go的内存管理机制是怎样的?Go 语言采用的垃圾回收算法是并发标记清理(Concurrent Mark Sweep,CMS)算法。相对于 CMS GC,基于压缩的 GC 算法和基于复制的 GC 算法最大的优势是,能够降低内存的碎片率。那为什么 Go 语言还是选择了 CMS 作为其 GC 算法呢?这里原因主要有两点:
- Go 的 GC 算法采用 TCMalloc 分配器的内存分配思路,虽然不能像基于 copy 的 GC 算法那样消除掉内存碎片化的问题,但也极大地降低了碎片率。另外,基于 Thread Cache 的分配机制可以使得 Go 在分配的大部分场景下避免加锁,这使得 Go 在高并发场景下能够发挥巨大的性能优势。
- Go 语言是有值类型数据的,即 struct 类型。有了值类型的介入,编译器只需要关注函数内部的逃逸分析(intraprocedural escape analysis),而不用关注函数间的逃逸分析(interprocedural analysis),由此可以将生命周期很短的对象安排在栈上分配。分代 GC 可以区分长生命周期和短生命周期对象,它的优势是能够快速回收生命周期短的对象。但由于逃逸分析的优势,Go 语言中的短生命周期对象并没有那么多,所以分代 GC 在 Go 语言中收益较低。另外,由于分代 GC 需要额外的 write barrier 来维护老年代对年轻代的引用关系,也加重了 GC 引入的开销。
三色标记、并发标记和清扫、非分代、非紧缩(在垃圾回收之后不会进行内存整理以清除内存碎片)、写屏障(处理标记遗漏的问题)。
不分代
垃圾回收的基本想法Go 实现的垃圾回收器是无分代(对象没有代际之分)、 不整理(回收过程中不对对象进行移动与整理)、并发(与用户代码并发执行)的三色标记清扫算法。分代 GC 依赖分代假设,即 GC 将主要的回收目标放在新创建的对象上(存活时间短,更倾向于被回收), 而非频繁检查所有对象。但 Go 的编译器会通过逃逸分析将大部分新生对象存储在栈上(栈直接被回收), 只有那些需要长期存在的对象才会被分配到需要进行垃圾回收的堆中。 也就是说,分代 GC 回收的那些存活时间短的对象在 Go 中是直接被分配到栈上, 当 goroutine 死亡后栈也会被直接回收,不需要 GC 的参与,进而分代假设并没有带来直接优势。 并且 Go 的垃圾回收器与用户代码并发执行,使得 STW 的时间与对象的代际、对象的 size 没有关系。 Go 团队更关注于如何更好地让 GC 与用户代码并发执行(使用适当的 CPU 来执行垃圾回收), 而非减少停顿时间这一单一目标上。
Visualizing memory management in Golang
- go 没有对内存 分代管理, The main reason for this is the TCMalloc(Thread-Caching Malloc), which is what Go’s own memory allocator was modeled upon. Many programming languages that employ Garbage collection uses a generational memory structure to make collection efficient along with compaction to reduce fragmentation. Go takes a different approach here, as we saw earlier, Go structures memory quite differently. Go employs a thread-local cache to speed up small object allocations and maintains scan/noscan spans to speed up GC. This structure along with the process avoids fragmentation to a great extent making compact unnecessary during GC.
- One major difference Go has compared to many garbage collected languages is that many objects are allocated directly on the program stack. The Go compiler uses a process called escape analysis to find objects whose lifetime is known at compile-time and allocates them on the stack rather than in garbage-collected heap memory. During compilation Go does the escape analysis to determine what can go into Stack(static data) and what needs to go into Heap(dynamic data). Go的对象(即struct类型)是可以分配在栈上的。Go会在编译时做静态逃逸分析(Escape Analysis), 如果发现某个对象并没有逃出当前作用域,则会将对象分配在栈上而不是堆上,从而减轻了GC压力。其实JVM也有逃逸分析,但与Go不同的是Java无法在编译时做这项工作,分析是在运行时完成的,这样做一是会占用更多的CPU时间,二是不可能会把所有未逃逸的对象都优化到栈中。
串行标记清扫
回收器开始执行时, 将并发执行的赋值器挂起。这种情况下,对用户态代码而言,回收器是一个原子操作。
// 标记追踪:从根集合(寄存器、执行栈、全局变量)开始遍历对象图,标记遇到的每个对象;
func mark() {
worklist.Init() // 初始化标记 work 列表
for root := range roots { // 从根开始扫描
ref := *root
if ref != nil && !isMarked(ref) { // 标记每个遇到的对象
setMarked(ref)
worklist.Add(ref)
for !worklist.Empty() {
ref := worklist.Remove() // ref 已经标记过
for fld := range Pointers(ref) {
child := *fld
if child != nil && !isMarked(child) {
setMarked(child)
worlist.Add(child)
}
}
}
}
}
}
// 清扫回收:检查堆中每一个对象,将所有未标记的对象当做垃圾进行回收。
func sweep() {
// 检查堆区间内所有的对象
for scan := worklist.Start(); scan < worklist.End(); scan = scan.Next {
if isMarked(scan) {
unsetMarked(scan)
} else {
free(scan) // 将未标记的对象释放
}
}
}
采取 STW 这样凶残的策略,主要还是防止 mutator 在 GC 的时候捣乱——这跟你用扫地机器人的时候先把狗(Mutator/Application)先锁起来,等房子全部打扫完再把狗放开 的道理是一样的(Stop The Dog)。
三色(并发)标记法/三色抽象
三色抽象只是一种描述追踪式回收器的方法,在实践中并没有实际含义,三色标记法可以帮助我们搞清楚在可达性分析的第二阶段(也就是遍历对象图),如果用户线程和垃圾收集线程同时进行,会出现什么问题。它的重要作用在于从逻辑上严密推导标记清理这种垃圾回收方法的正确性。 之前 gc 和 应用线程没有 沟通机制,所以gc 干活儿的时候,应用线程就得 “歇着”。涂色本质上是提供了一种沟通渠道(存储了对象的中间状态)。PS: 涂色只是表达手段,比如红黑树,一些算法题真的会将 颜色引入到树的遍历中,不知道谁先抄谁的。
func isWhite(ref interface{}) bool {
return !isMarked(ref)
}
func isGrey(ref interface{}) bool {
return worklist.Find(ref)
}
func isBlack(ref interface{}) bool {
return isMarked(ref) && !isGrey(ref)
}
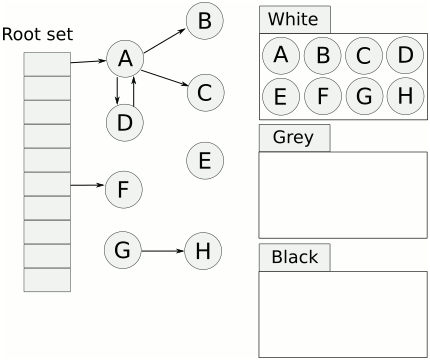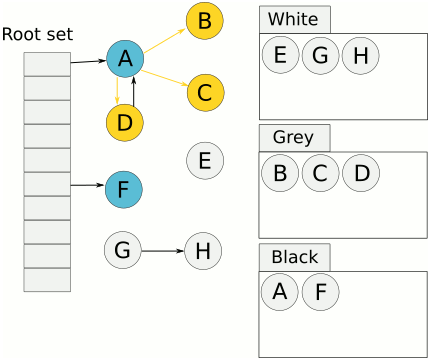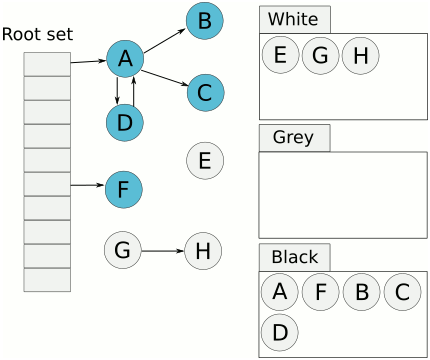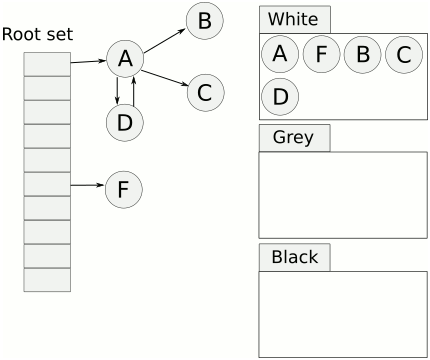
当垃圾回收开始时,只有白色对象。随着标记过程开始进行时,灰色对象开始出现(着色),这时候波面便开始扩大。当一个对象的所有子节点均完成扫描时,会被着色为黑色。当整个堆遍历完成时,只剩下黑色和白色对象,这时的黑色对象为可达对象,即存活;而白色对象为不可达对象,即死亡。这个过程可以视为以灰色对象为波面,将黑色对象和白色对象分离,使波面不断向前推进,直到所有可达的灰色对象都变为黑色对象为止的过程。
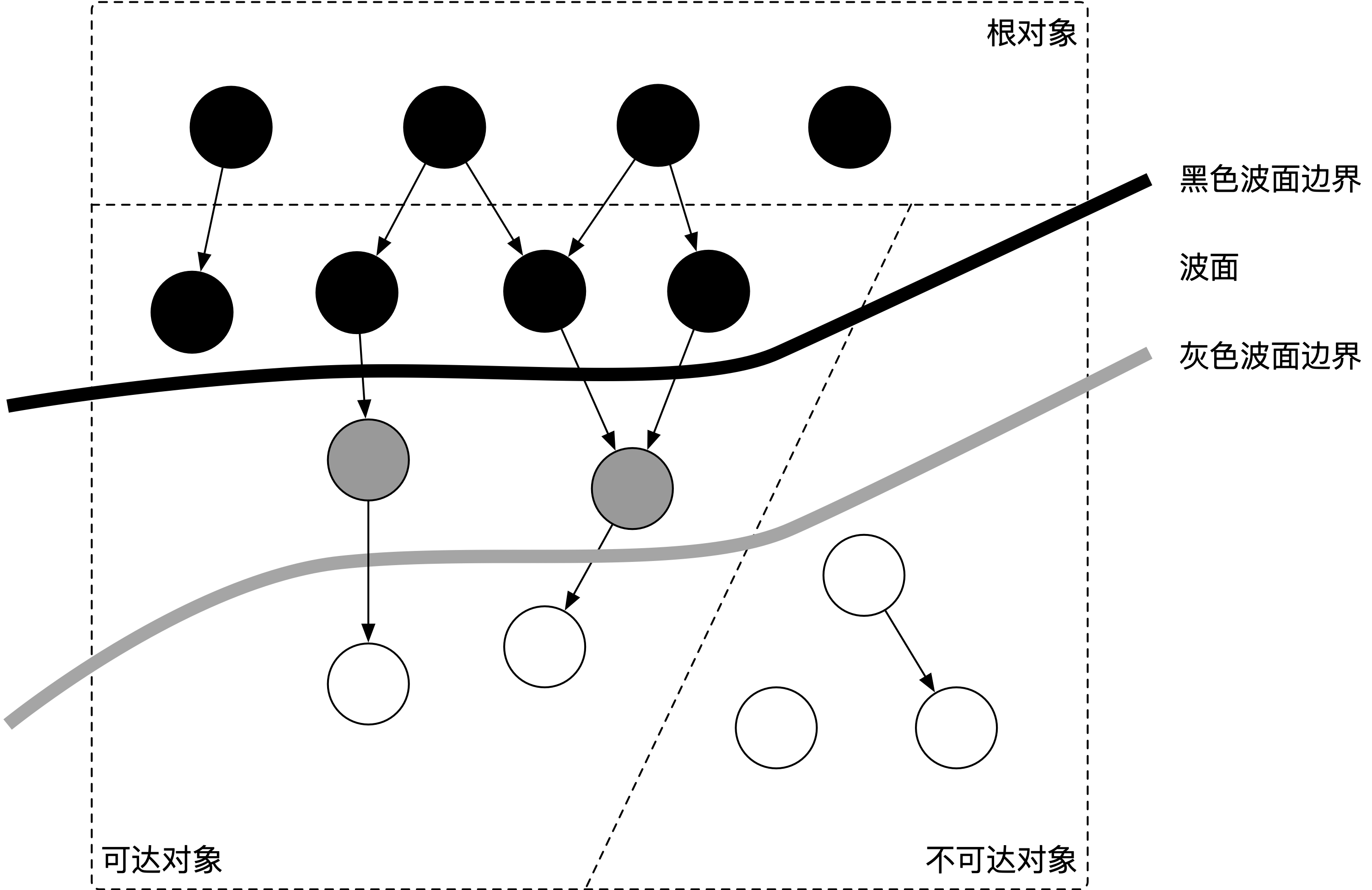 扩大波面:将白色对象作色成灰色;推进波面:扫描对象并将其着色为黑色;后退波面:将黑色对象回退到灰色
扩大波面:将白色对象作色成灰色;推进波面:扫描对象并将其着色为黑色;后退波面:将黑色对象回退到灰色
并发标记清扫
// 并发标记
func markSome() bool {
if worklist.empty() { // 初始化回收过程
scan(Roots) // 赋值器不持有任何白色对象的引用
if worklist.empty() { // 此时灰色对象已经全部处理完毕
sweep() // 标记结束,立即清扫
return false
}
}
// 回收过程尚未完成,后续过程仍需标记
ref = worklist.remove()
scan(ref)
return true
}
func scan(ref interface{}) {
for fld := range Pointers(ref) {
child := *fld
if child != nil {
shade(child)
}
}
}
func shade(ref interface{}) {
if !isMarked(ref) {
setMarked(ref)
worklist.add(ref)
}
}
堆上对象本质上是图,标记过程是一个广度优先的遍历过程。从根节点开始,将节点的子节点推到任务队列中,然后递归扫描子节点的子节点,直到所有工作队列都被排空为止。标记过程会将白色对象标记,并推进队列中变成灰色对象。
// 并发清扫
func New() (interface{}, error) {
collectEnough()
ref := allocate()
if ref == nil {
return nil, errors.New("Out of memory")
}
return ref, nil
}
func collectEnough() {
stopTheWorld()
defer startTheWorld()
for behind() { // behind() 控制回收工作每次的执行量
if !markSome() {
return
}
}
}
对象丢失问题
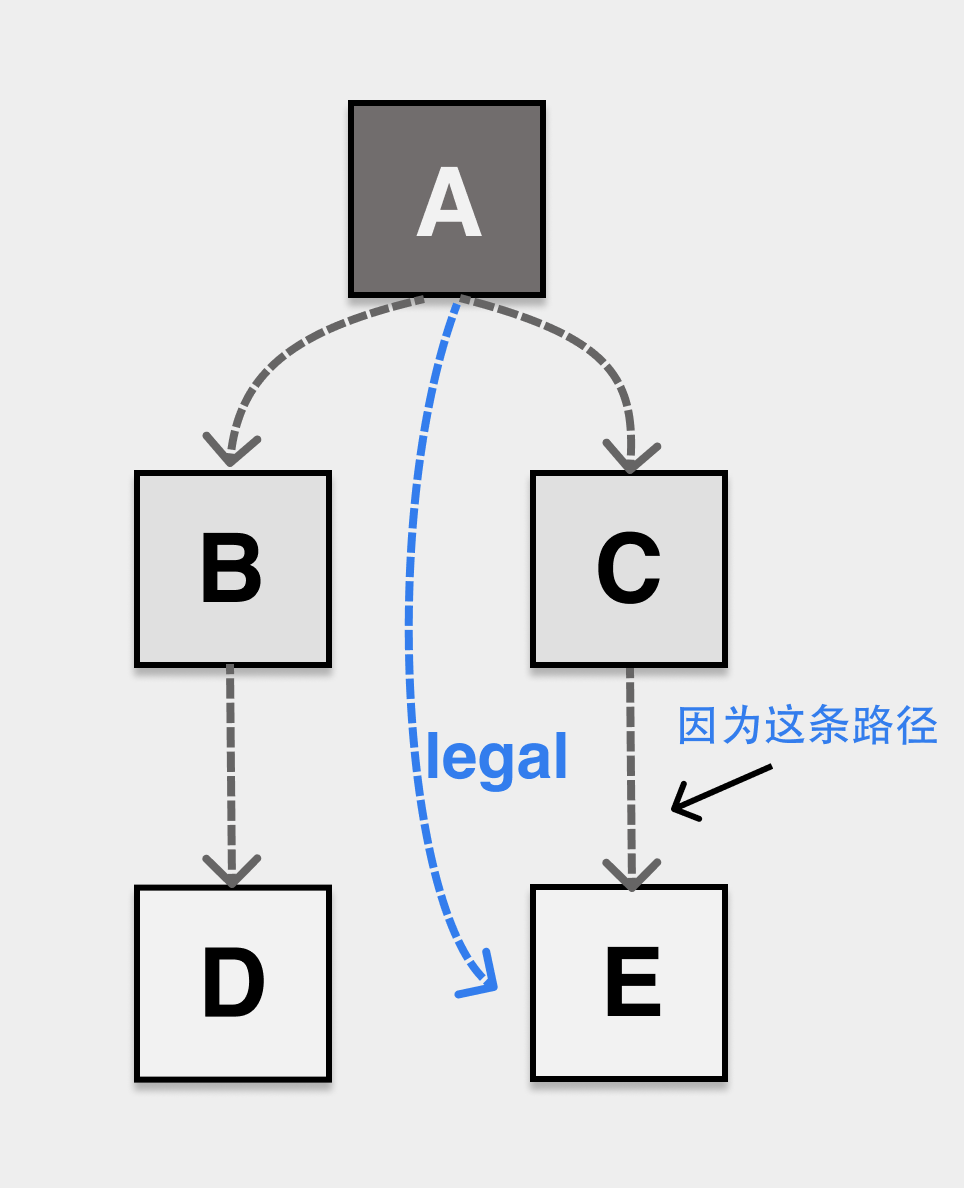
GC 线程 / 协程与应用线程 / 协程是并发执行的,在 GC 标记 worker 工作期间,应用还会不断地修改堆上对象的引用关系(PS:引用关系的并发修改),这就可能导致对象丢失问题。为了解决漏标,错标的问题,我们先需要定义“三色不变性”,如果我们的堆上对象的引用关系不管怎么修改,都能满足三色不变性,那么也不会发生对象丢失问题。
- 强三色不变性,禁止黑色对象指向白色对象
- 弱三色不变性,黑色对象可以指向白色对象,但指向的白色对象,必须有能从灰色对象可达的路径
write barrier
目的:在标记过程中,write barrier 会把所有被覆盖的指针以及新指针都标记为灰色(所以要概念上区分下三色),而新分配的对象指针则直接标记为黑色。
实现强 / 弱三色不变性均需要引入屏障技术。在 Go 语言中,使用写屏障,也就是 write barrier 来解决上述问题。这里 barrier 的本质是 : snippet of code insert before pointer modify。不过,在并发编程领域也有 memory barrier,但这个含义与 GC 领域的 barrier 是完全不同的,不要混淆这两个概念。Go 语言的 GC 只有 write barrier,没有 read barrier。
在应用进入 GC 标记阶段前的 stw 阶段,会将全局变量 runtime.writeBarrier.enabled 修改为 true,这时所有的堆上指针修改操作在修改之前便会额外调用 runtime.gcWriteBarrier
- Write barrier is a special code inserted by the compiler, inserted during compilation, the code function name is called gcWriteBarrier;
- The barrier code does not run directly, but also requires conditional judgment. Therefore, there is one more write operation for the assignment of the memory on the heap in normal times; 伪代码 PS: 也就是 堆上所有指针修改
obj = xx会自动被编译为 下列代码,多了一个判断,gc未执行期间,效率肯定比没gc的语言低一点if runtime.writeBarrier.enabled { runtime.gcWriteBarrier(ptr, val) } else { *ptr = val }
在 GC 领域中,常见的 write barrier 有两种:
- Yuasa Deletion Barrier,指针修改时,修改前指向的对象要标灰
func YuasaWB(slot *unsafe.Pointer, ptr unsafe.Pointer){ shade(*slot) *slot = ptr } -
Dijistra Insertion Barrier,指针修改时,指向的新对象要标灰:
// ptr 赋值给 slot ,在编译器层面改为 DijkstraWritePointer 调用(如果开启写屏障) // 灰色赋值器 Dijkstra 插入屏障 func DijkstraWritePointer(slot *unsafe.Pointer, ptr unsafe.Pointer) { shade(ptr) // shade(ptr) 会将尚未变成灰色或黑色的指针 ptr 标记为灰色。通过保守的假设 *slot 可能会变为黑色, 并确保 ptr 不会在将赋值为 *slot 前变为白色,进而确保了强三色不变性。 *slot = ptr }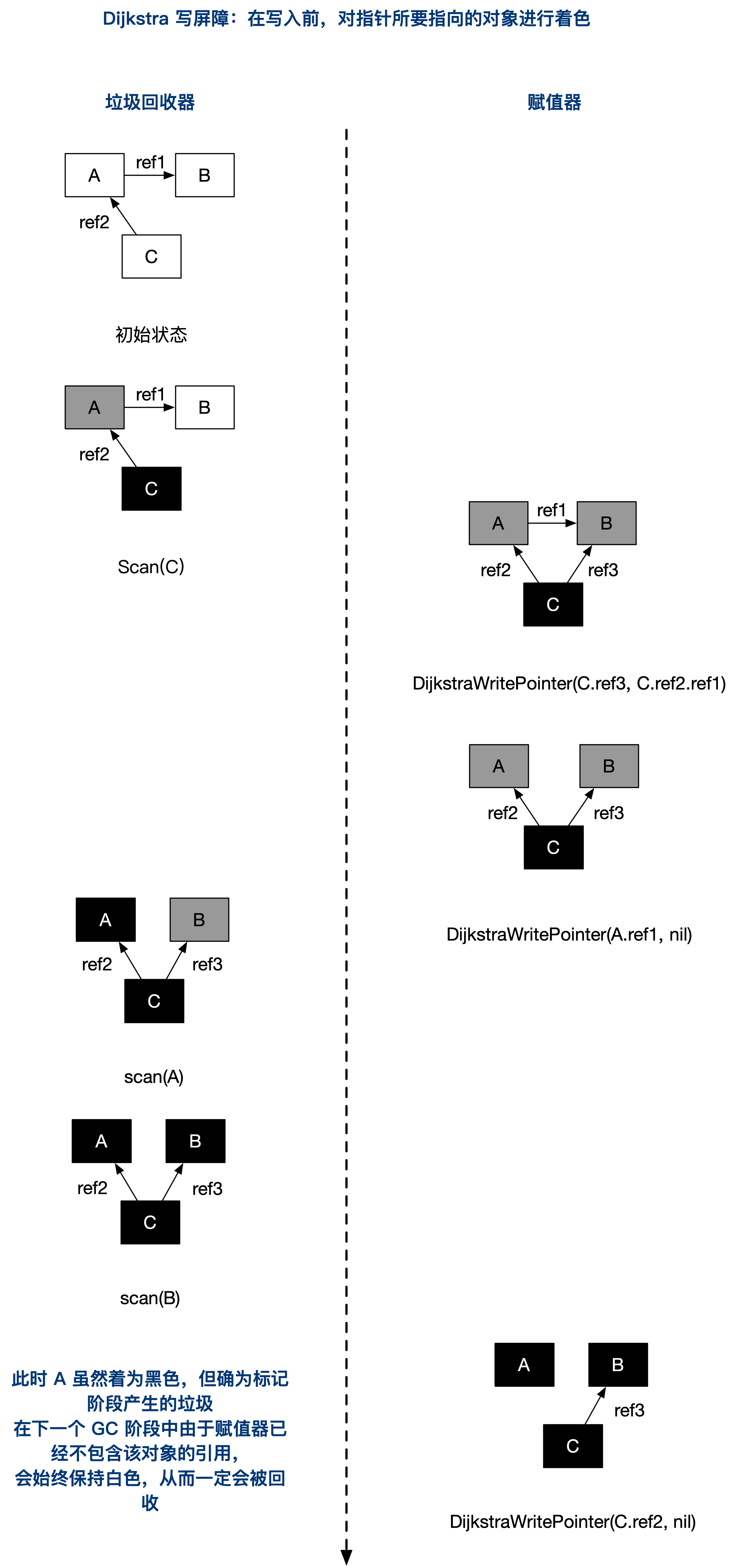
使用上述两种屏障其中的任意一种,都需要在 stw 阶段对栈进行重扫。所以经过多个版本的迭代,现在 Go 的写屏障混合了上述两种屏障,实现是这样的:
func RealityWB(slot *unsafe.Pointer, ptr unsafe.Pointer){
shade(*slot)
shade(ptr)
*slot = ptr
}
三色标记法是一种可以并发执行的算法。Collector可以做了一段标记工作后,就让mutator再运行一段。如果在mutator运行期间,一个黑色对象被修改了,比如往一个黑色对象 a 里新存储了一个指针 b,那么把 a 涂成灰色,或者把 b 涂成灰色,就可以了。增量标记的过程中,需要编译器做配合往生成的目标代码中插入写屏障(Write Barrier)的代码。Write Barrier 主要做这样一件事情,修改原先的写逻辑,当白色节点交由黑色节点引用时, 立刻对被引用节点进行着色,并且着色为”灰色“,并加入到work pool。因此打开了 Write Barrier 可以保证了三色标记法在并发下安全正确地运行。 另一种表述:since the garbage collector can run concurrently with our Go program, it needs a way to detect potential changes in the memory while scanning. To tackle that potential issue, an algorithm of write barrier is implemented and will allow Go to track any pointer changes. The garbage finally stops the world, flushes the changes made on each write barrier to the work pool and performs the remaining marking. PS: Write Barrier 可以追踪标记期间变化的 对象并将它们加入到work pool
触发时机
什么时候应该触发下一次 GC? Go 触发 GC 的时机
- 监控线程 runtime.sysmon 定时调用;
- 手动调用 runtime.GC 函数进行垃圾收集;
- 申请内存时 runtime.mallocgc 会根据堆大小判断是否调用; 上面这三个触发 GC 的地方最终都会调用 gcStart 执行 GC,但是在执行 GC 之前一定会先判断这次调用是否应该被执行,并不是每次调用都一定会执行 GC,runtime.gcTrigger中的 test 函数负责校验本次 GC 是否应该被执行。
目前触发 GC 的条件使用的是从 Go 1.5 时提出的调步(Pacing)算法,调步算法包含四个部分:
- GC 周期所需的扫描估计器
- 为用户代码根据堆分配到目标堆大小的时间估计扫描工作量的机制
- 用户代码为未充分利用 CPU 预算时进行后台扫描的调度程序
- GC 触发比率的控制器
两万字长文带你深入Go语言GC源码我们在测试的时候可以调用 runtime.GC来手动的触发 GC。但实际上,触发 GC 的入口一般不会手动调用。正常触发 GC 应该是在申请内存时会调用 runtime.mallocgc或者是 Go 后台的监控线程 sysmon 定时检查调用 runtime.forcegchelper。
整体实现
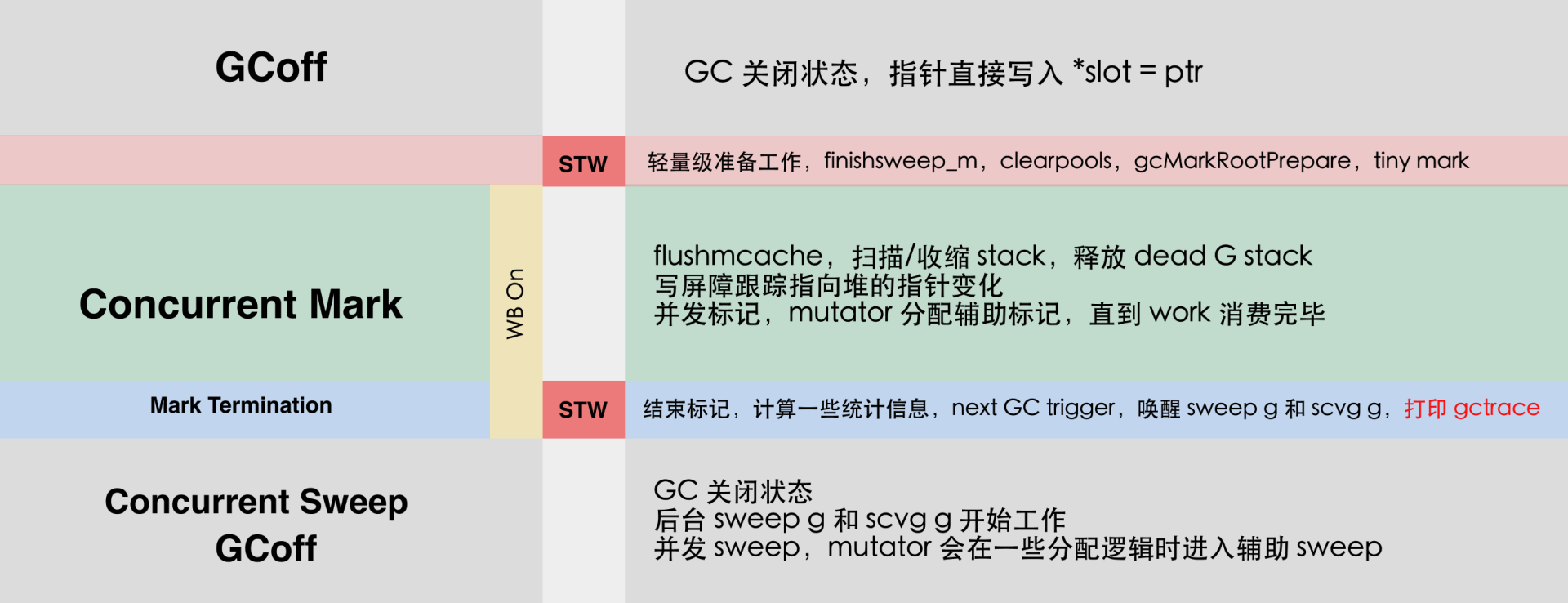
GC在离开(off)、标记和扫描这三种状态之间不断循环,这就是所谓的GC循环。
| gc阶段 | 说明 | mutator状态 |
|---|---|---|
| 清扫终止 | 为下一个阶段的并发标记做准备工作,启动写屏障 | STW |
| 标记 | 与mutator并发执行,写屏障处于开启状态 | 并发 |
| 标记终止 | 保证一个周期内标记任务完成,停止写屏障 | STW |
| 内存清扫 | 将需要回收的内存归还到堆中,写屏障处于关闭状态 | 并发 |
| 内存归还 | 将过多的内存归还给操作系统,写屏障处于关闭状态 | 并发 |
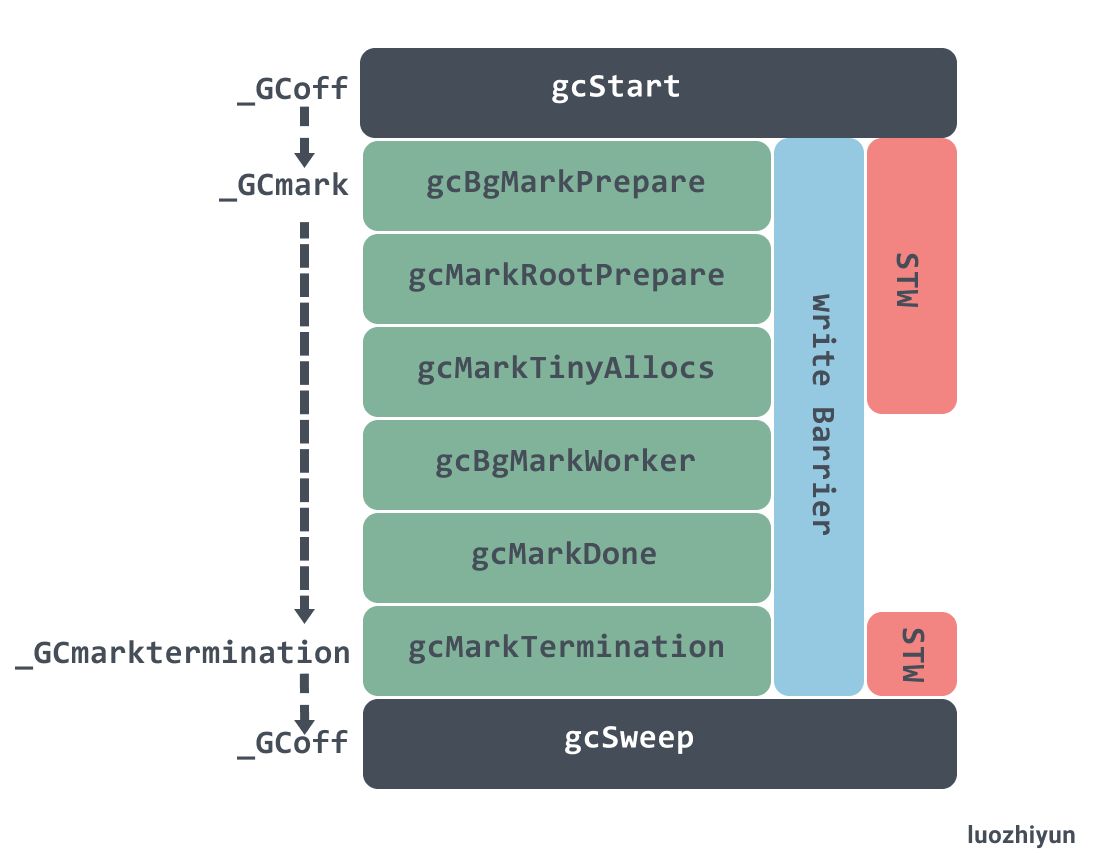
为什么 Go 垃圾收集器需要 STW?PS:难道就为了开关写屏障?
- 1st Stop The World(标记阶段之前):设置状态并打开写屏障。写屏障确保在 GC 运行时正确跟踪新的写入(这样它们就不会被意外释放或保留)。
- 2nd Stop The World(标记阶段之后):清理标记状态并关闭写屏障。
Go: How Does the Garbage Collector Mark the Memory?GC 从栈开始,递归地顺着指针找指针指向的对象,遍历内存。每个指针被加入到一个 work pool(type gcWork/workbuf struct) 中的队列。后台运行的标记 worker 从这个 work pool 中拿到前面出列的 指针,扫描这个对象然后把在这个对象里找到的指针加入到队列。归功于每一个 span 中的名为 gcmarkBits 的 bitmap 属性,三色被原生地实现了,bitmap 对 scan 中相应的 bit 设为 1 来追踪 对象。灰色和黑色在 gcmarkBits 中皆为 1,A grey object is one that is marked and on a work queue. A black object is marked and not on a work queue.
对象的标记与回收最终都落实到 mspan的 mark与sweep,也对上了一句话;Go 的内存管理基本单元是 mspan。
type mspan struct {
next *mspan // next span in list, or nil if none
prev *mspan // previous span in list, or nil if none
startAddr uintptr // address of first byte of span aka s.base()
npages uintptr // number of pages in span
spanclass spanClass // size class and noscan (uint8)
...
allocBits *gcBits
gcmarkBits *gcBits // 实现 span 的颜色标记
}
func (s *mspan) sweep(preserve bool) bool {
...
}
// markBits.setMarked 就算是标记了
func (s *mspan) markBitsForIndex(objIndex uintptr) markBits {
...
}
垃圾标记
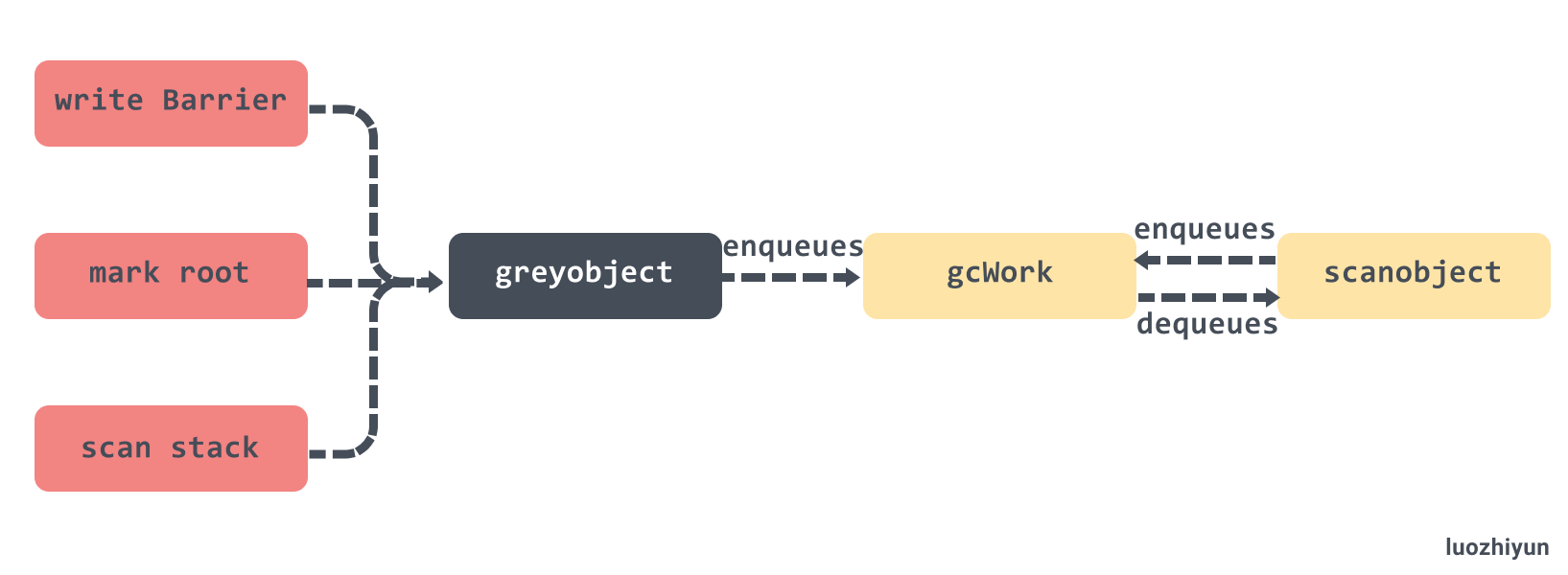
Write barriers, root discovery, stack scanning, and object scanning produce pointers to grey objects. Scanning consumes pointers to grey objects, thus blackening them, and then scans them,potentially producing new pointers to grey objects. call gcw.put() to produce and gcw.tryGet() to consume. gc标记本质是一个灰色对象的生产与消费过程。scanObject 最终 mspan.markBitsForIndex(objIndex)
数据结构
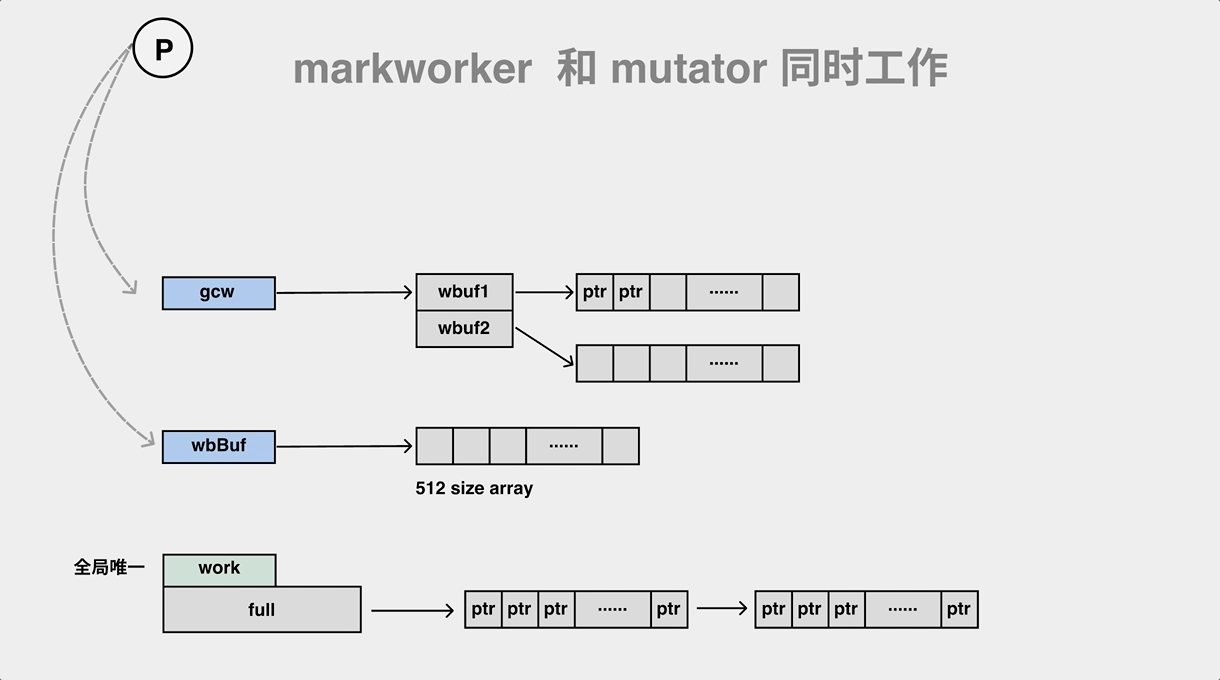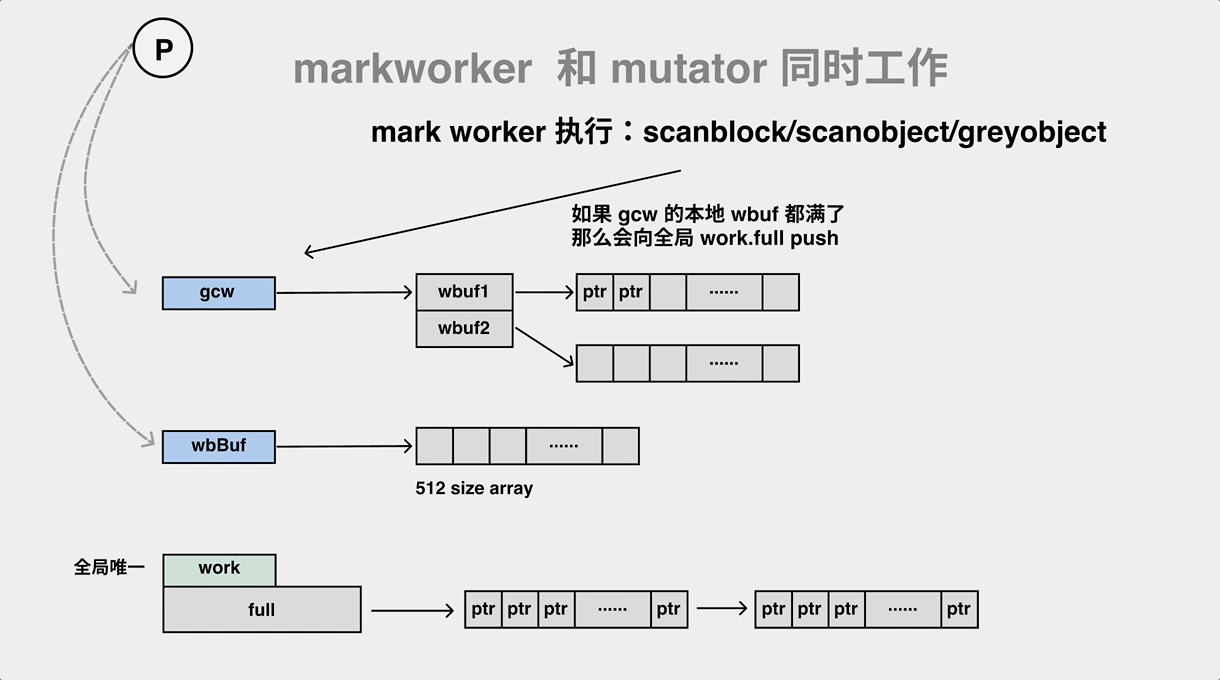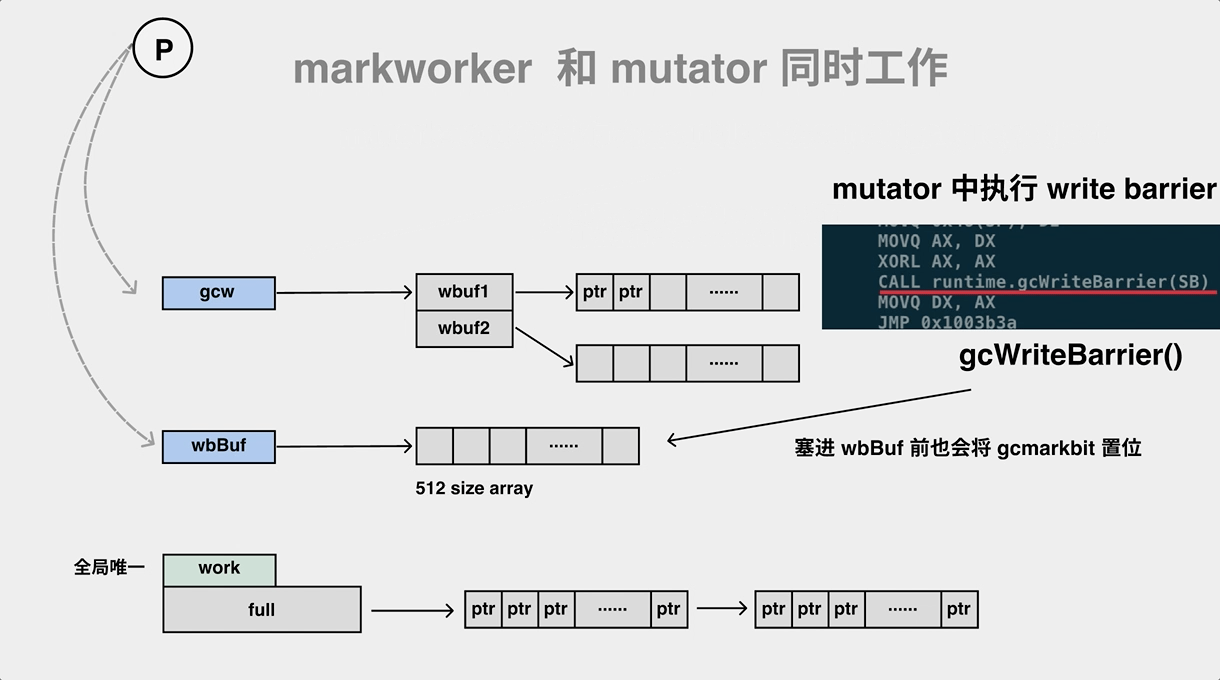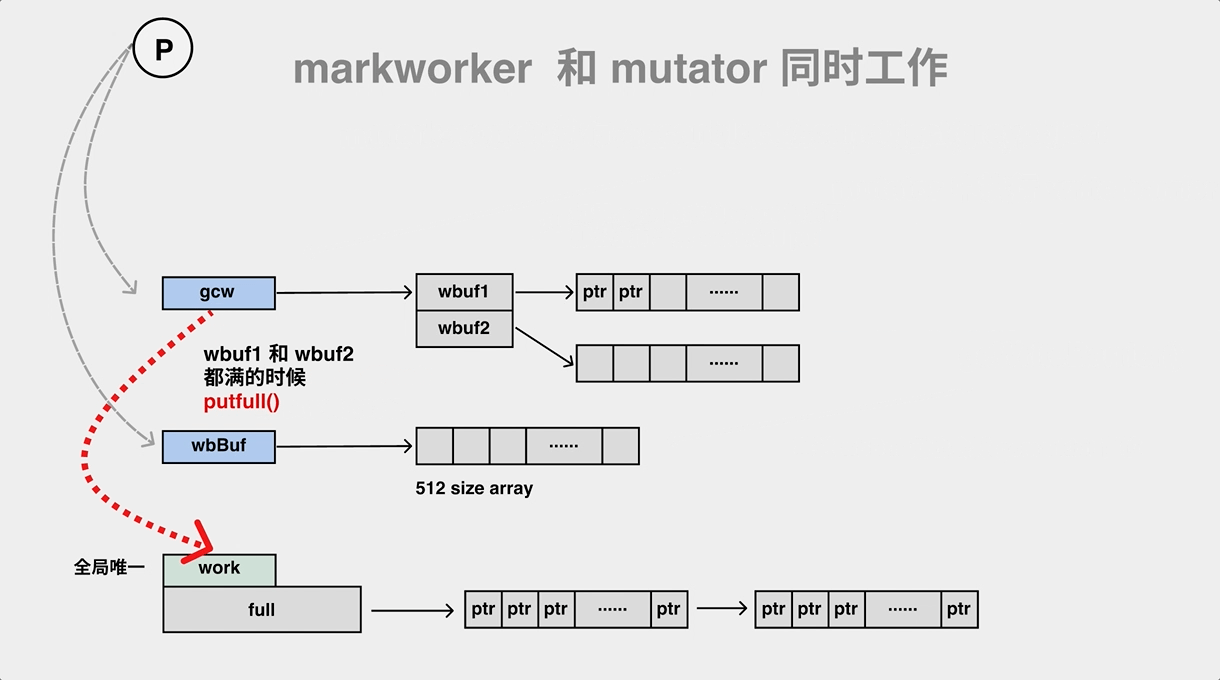
对象的关系是图,对象的标记要遍历对象图,遍历图时需要gcWork/worklist 作为辅助结构。
// 每一个P 都有一个 gcWork
// go/1.15.2/libexec/src/runtime/runtime2.go
type p struct {
// gcw is this P's GC work buffer cache. The work buffer is filled by write barriers, drained by mutator assists, and disposed on certain GC state transitions.
gcw gcWork
wbBuf wbBuf // wbBuf is this P's GC write barrier buffer. write barrier 缓存
...
}
// go/1.15.2/libexec/src/runtime/mgcwork.go
// work poll/worklist 的实现
type gcWork struct {
// wbuf1 is always the buffer we're currently pushing to and popping from and wbuf2 is the buffer that will be discarded next.
wbuf1, wbuf2 *workbuf
bytesMarked uint64
scanWork int64
flushedWork bool
pauseGen uint32
putGen uint32
pauseStack [16]uintptr
}
gcWork相当于每个 P 的私有缓存空间,存放需要被扫描的对象,为垃圾收集器提供了生产和消费任务的抽象,该结构体持有了两个重要的工作缓冲区 wbuf1 和 wbuf2,当我们向该结构体中增加或者删除对象时,它总会先操作 wbuf1 缓冲区,一旦 wbuf1 缓冲区空间不足或者没有对象,会触发缓冲区的切换,而当两个缓冲区空间都不足或者都为空时,会从全局的工作缓冲区中插入或者获取对象。
从gcRoots找到灰色对象
PS:如何定位GC问题?利用火焰图,可以看到gcBgMarkWorker占用cpu的百分比,一般超过10%就需要优化了。
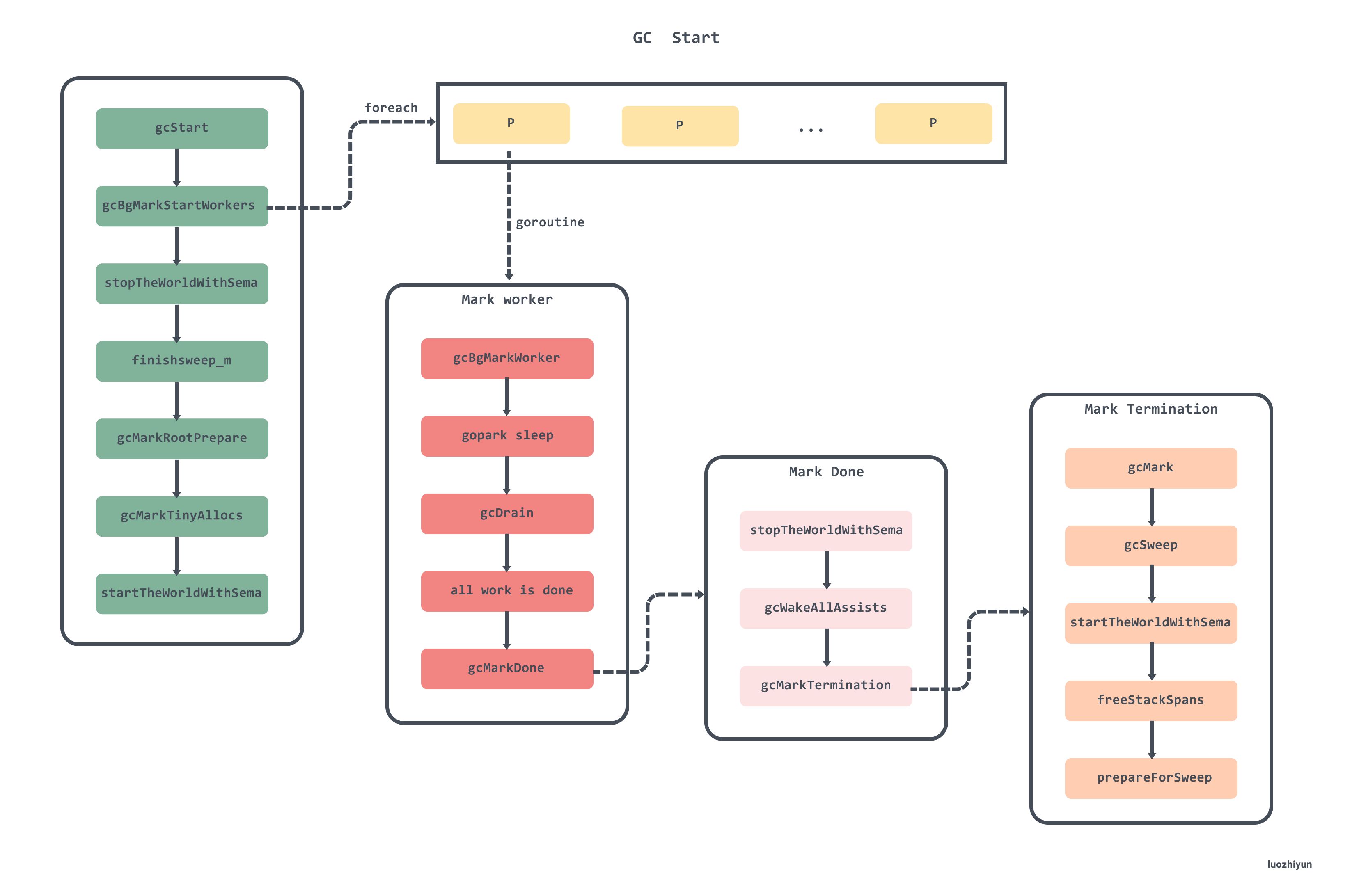
// gcStart starts the GC.
// go/1.15.2/libexec/src/runtime/mgc.go
func gcStart(trigger gcTrigger) {
mp := acquirem()
mode := gcBackgroundMode
...
gcBgMarkStartWorkers()
...
// 设置全局变量中的GC状态为_GCmark
// 然后启用写屏障
setGCPhase(_GCmark)
gcBgMarkPrepare() // Must happen before assist enable.
gcMarkRootPrepare()
...
}
// gcBgMarkStartWorkers 会为全局每个P创建用于执行后台标记任务的 Goroutine,但是可以同时工作的只有25%,调度器在调度循环 runtime.schedule中通过调用 gcController.findRunnableGCWorker方法进行控制。
func gcBgMarkStartWorkers() {
// Background marking is performed by per-P G's. Ensure that each P has a background GC G.
for _, p := range allp {
if p.gcBgMarkWorker == 0 {
go gcBgMarkWorker(p)
}
}
}
func gcBgMarkWorker(_p_ *p) {
gp := getg()
for {
...
systemstack(func() {
switch _p_.gcMarkWorkerMode {
default:
throw("gcBgMarkWorker: unexpected gcMarkWorkerMode")
case gcMarkWorkerDedicatedMode:
gcDrain(&_p_.gcw, gcDrainUntilPreempt|gcDrainFlushBgCredit)
gcDrain(&_p_.gcw, gcDrainFlushBgCredit)
case gcMarkWorkerFractionalMode:
gcDrain(&_p_.gcw, gcDrainFractional|gcDrainUntilPreempt|gcDrainFlushBgCredit)
case gcMarkWorkerIdleMode:
gcDrain(&_p_.gcw, gcDrainIdle|gcDrainUntilPreempt|gcDrainFlushBgCredit)
}
})
...
}
}
// gcDrain scans roots and objects in work buffers, blackening grey objects until it is unable to get more work. It may return before GC is done; it's the caller's responsibility to balance work from other Ps.
// go/1.15.2/libexec/src/runtime/mgcmark.go
func gcDrain(gcw *gcWork, flags gcDrainFlags) {
if !writeBarrier.needed {
throw("gcDrain phase incorrect")
}
gp := getg().m.curg
// Drain root marking jobs.
if work.markrootNext < work.markrootJobs {
...
markroot(gcw, job)
...
}
// Drain heap marking jobs.Stop if we're preemptible or if someone wants to STW.
for !(gp.preempt && (preemptible || atomic.Load(&sched.gcwaiting) != 0)) {
b := gcw.tryGetFast()
if b == 0 {
b = gcw.tryGet()
if b == 0 {
// Flush the write barrier buffer; this may create more work.
wbBufFlush(nil, 0)
b = gcw.tryGet()
}
}
if b == 0 { // Unable to get work.
break
}
scanobject(b, gcw)
...
}
}
标记过程会将白色对象标记,并推进队列中变成灰色对象。在标记过程中,gc mark worker 会一边从工作队列(gcw)中弹出对象,一边把它的子对象 push 到工作队列(gcw)中,如果工作队列满了,则要将一部分元素向全局队列转移。
内存屏障产生灰色对象
barrier 本质是 : snippet of code insert before pointer modify。
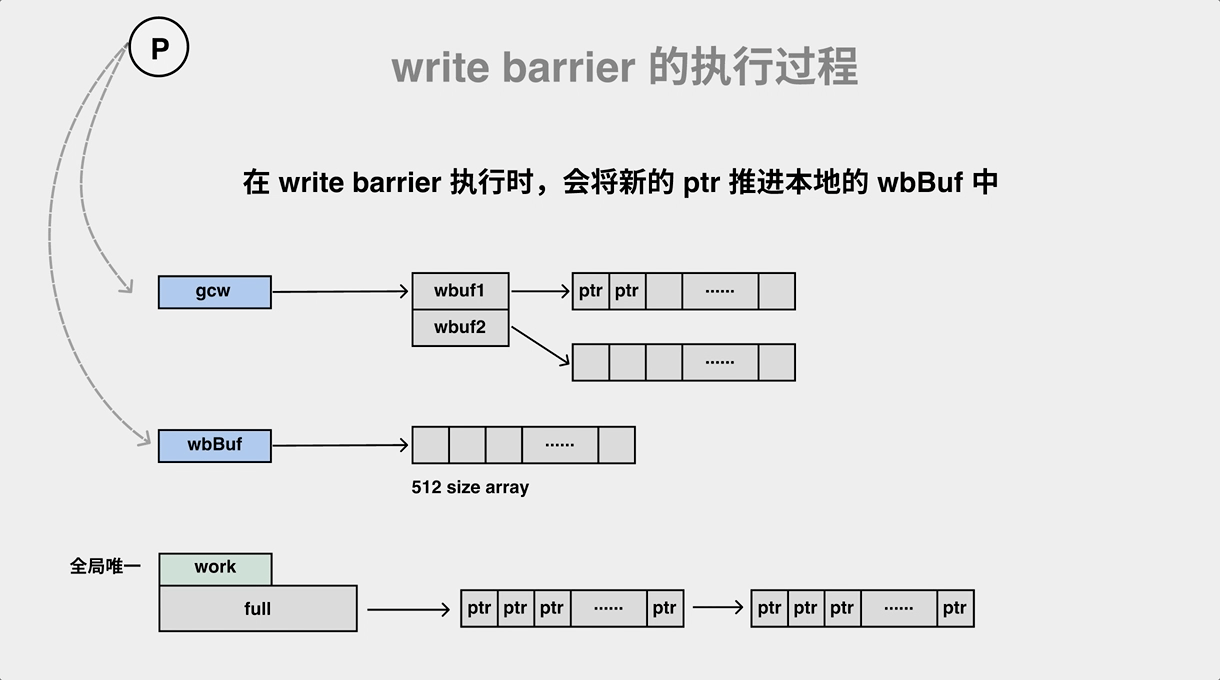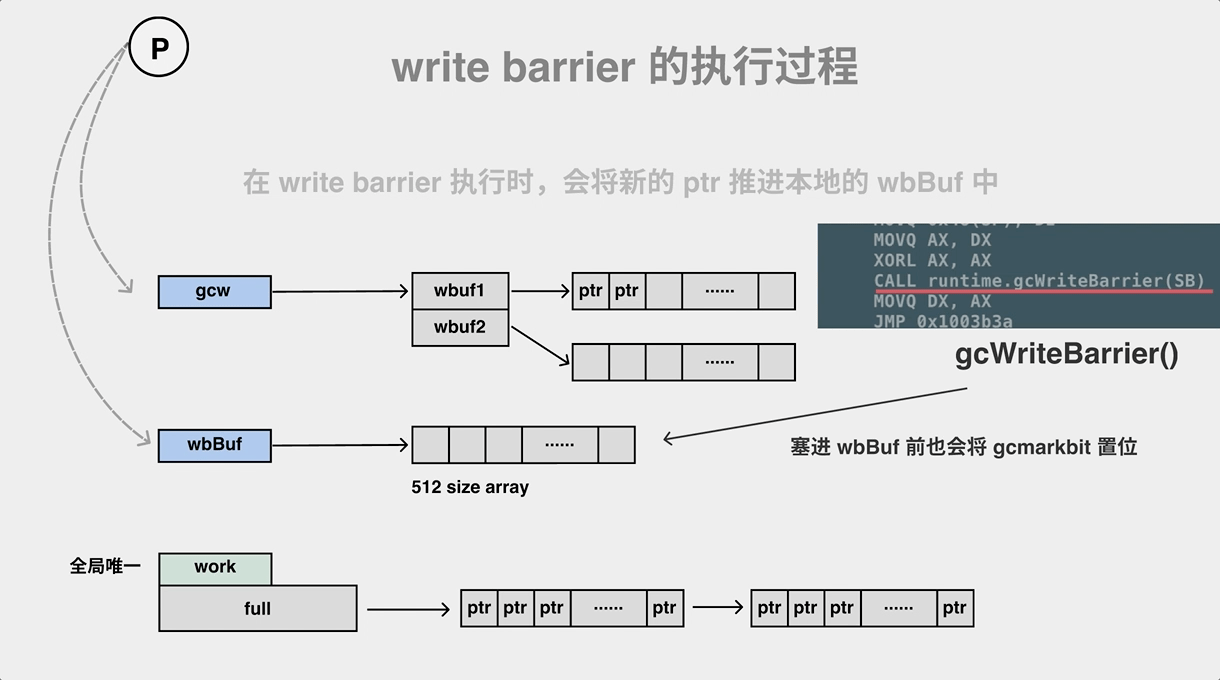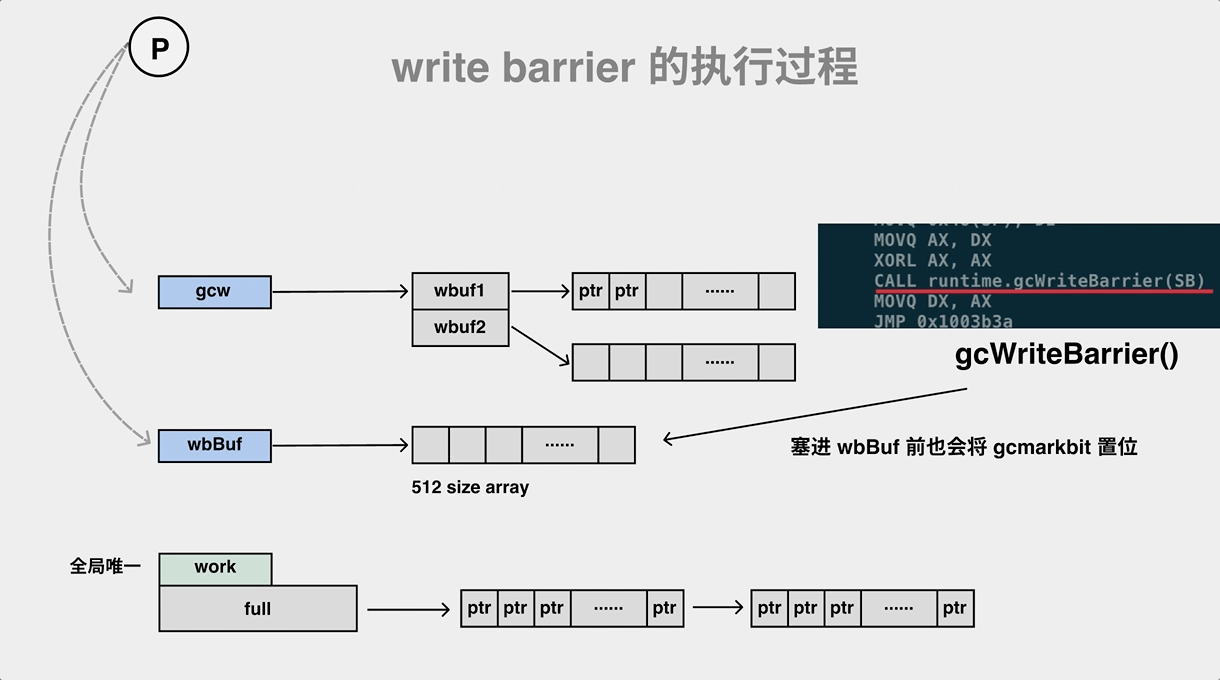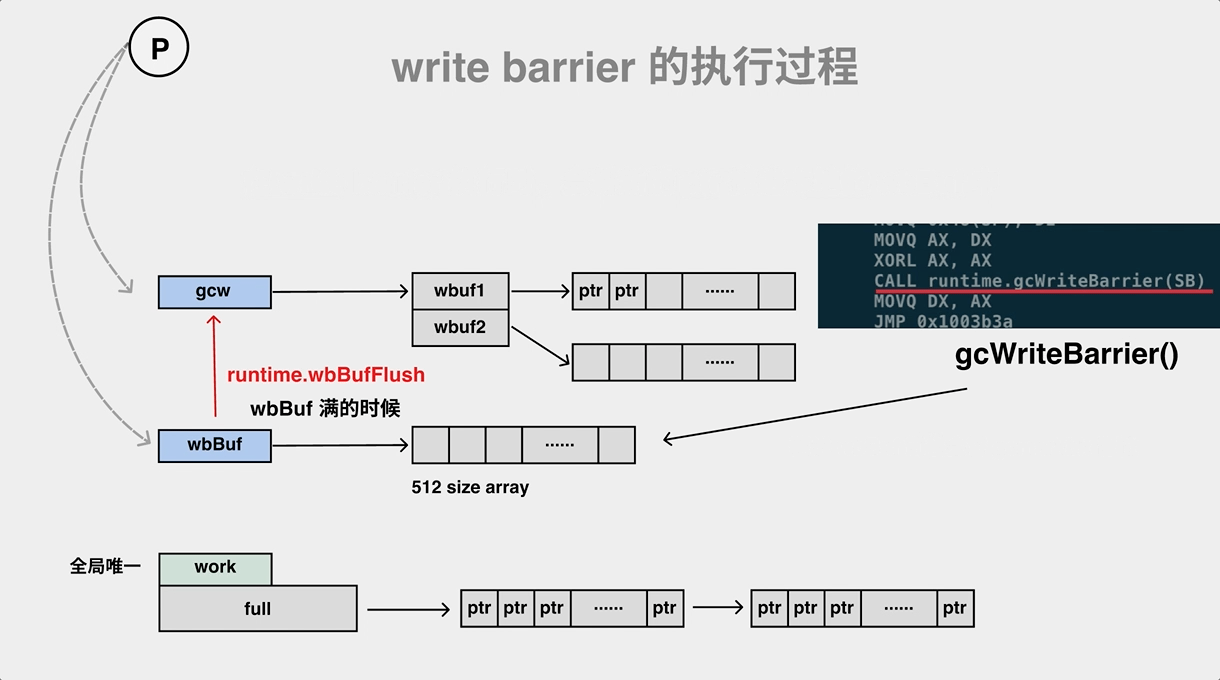
// go/1.15.2/libexec/src/runtime/asm_amd64.s
// gcWriteBarrier performs a heap pointer write and informs the GC.
TEXT runtime·gcWriteBarrier(SB),NOSPLIT,$120
...
CALL runtime·wbBufFlush(SB)
...
JMP ret
在执行 Store, Move, Zero 等汇编操作的时候加入写屏障 runtime·gcWriteBarrier。写屏障这里其实也是和并发标记是一样的套路,wbBufFlush1 会遍历write barrier 缓存,然后调用 findObject 查找到对象之后使用标志位进行标记,最后将对象加入到 gcWork队列中进行扫描,并 重置 write barrier 缓存。
// go/1.15.2/libexec/src/runtime/mwbbuf.go
// wbBufFlush flushes the current P's write barrier buffer to the GC workbufs.
func wbBufFlush(dst *uintptr, src uintptr) {
...
systemstack(func() {
...
wbBufFlush1(getg().m.p.ptr())
})
}
func wbBufFlush1(_p_ *p) {
// 获取缓存的指针
start := uintptr(unsafe.Pointer(&_p_.wbBuf.buf[0]))
n := (_p_.wbBuf.next - start) / unsafe.Sizeof(_p_.wbBuf.buf[0])
ptrs := _p_.wbBuf.buf[:n]
_p_.wbBuf.next = 0
gcw := &_p_.gcw
pos := 0
for _, ptr := range ptrs {
// 查找到对象
obj, span, objIndex := findObject(ptr, 0, 0)
if obj == 0 { continue }
mbits := span.markBitsForIndex(objIndex)
// 判断是否已被标记
if mbits.isMarked() { continue }
// 进行标记
mbits.setMarked()
// 标记 span.
arena, pageIdx, pageMask := pageIndexOf(span.base())
if arena.pageMarks[pageIdx]&pageMask == 0 {
atomic.Or8(&arena.pageMarks[pageIdx], pageMask)
}
if span.spanclass.noscan() {
gcw.bytesMarked += uint64(span.elemsize)
continue
}
ptrs[pos] = obj
pos++
}
// 将对象加入到 gcWork队列中
gcw.putBatch(ptrs[:pos])
// 重置 write barrier 缓存
_p_.wbBuf.reset()
}
真正标记灰色对象
// scanobject scans the object starting at b, adding pointers to gcw. b must point to the beginning of a heap object or an oblet. scanobject consults the GC bitmap for the pointer mask and the spans for the size of the object.
func scanobject(b uintptr, gcw *gcWork) {
// Find the bits for b and the size of the object at b.
hbits := heapBitsForAddr(b)
s := spanOfUnchecked(b)
n := s.elemsize
if n > maxObletBytes {
// Large object. Break into oblets for better parallelism and lower latency.
...
}
var i uintptr
for i = 0; i < n; i += sys.PtrSize {
...
// 取出指针的值
obj := *(*uintptr)(unsafe.Pointer(b + i))
if obj != 0 && obj-b >= n {
// 根据地址值去堆中查找对象
if obj, span, objIndex := findObject(obj, b, i); obj != 0 {
// 调用 greyobject 标记对象并把对象放到标记队列中
greyobject(obj, b, i, span, gcw, objIndex)
}
}
}
gcw.bytesMarked += uint64(n)
gcw.scanWork += int64(i)
}
标记 本质是 span.markBitsForIndex
// obj is the start of an object with mark mbits.If it isn't already marked, mark it and enqueue into gcw.
func greyobject(obj, base, off uintptr, span *mspan, gcw *gcWork, objIndex uintptr) {
// obj should be start of allocation, and so must be at least pointer-aligned.
mbits := span.markBitsForIndex(objIndex)
// If marked we have nothing to do.
if mbits.isMarked() {
return
}
mbits.setMarked()
// Mark span.
arena, pageIdx, pageMask := pageIndexOf(span.base())
if arena.pageMarks[pageIdx]&pageMask == 0 {
atomic.Or8(&arena.pageMarks[pageIdx], pageMask)
}
// If this is a noscan object, fast-track it to black instead of greying it.
if span.spanclass.noscan() {
gcw.bytesMarked += uint64(span.elemsize)
return
}
// Queue the obj for scanning.
if !gcw.putFast(obj) {
gcw.put(obj)
}
}
mark worker 扫描 ptr 并标记(自产自销) 同时消费 mutator 产生的灰色 ptr
后台清扫
相比复杂的标记流程,对象的回收和内存释放就简单多了。进程启动时会有两个特殊 goroutine:
- 一个叫 sweep.g,主要负责清扫死对象,合并相关的空闲页;
- 一个叫 scvg.g,主要负责向操作系统归还内存。
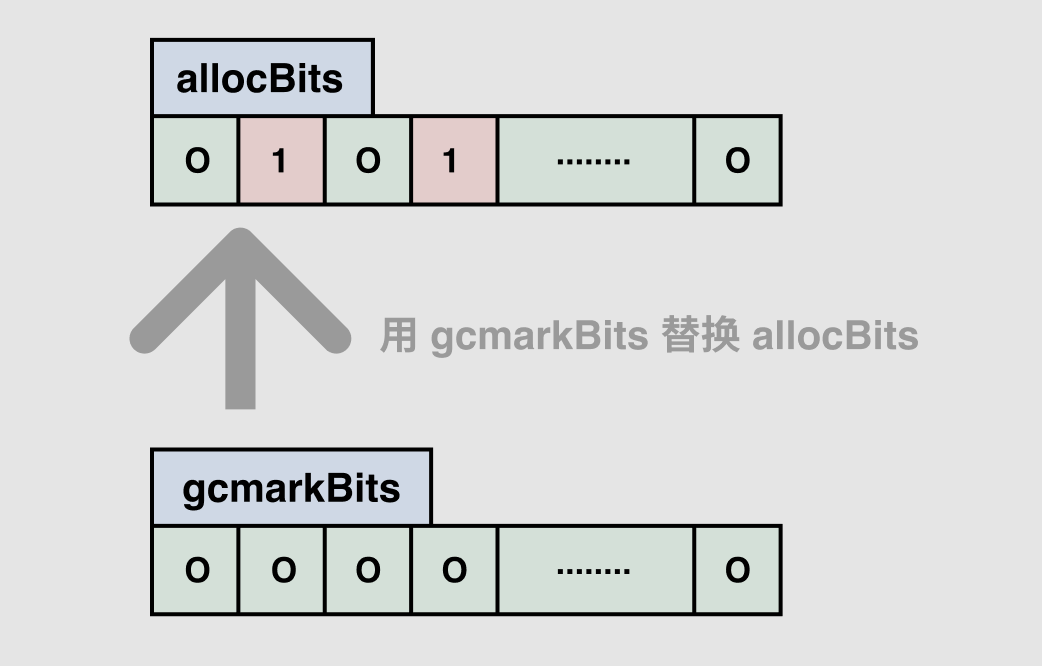
当 GC 的标记流程结束之后,sweep goroutine 就会被唤醒,进行清扫工作,其实就是循环执行 sweepone -> sweep。针对每个 mspan,sweep.g 的工作是将标记期间生成的 bitmap 替换掉分配时使用的 bitmap(用gcmarkBits 替换 allocBits),之后内存块就可以在对象分配时被使用了(实际上不需要 把块内容置0)。
然后根据 mspan 中的槽位情况决定该 mspan 的去向:
- 如果 mspan 中存活对象数 = 0,也就是所有 element 都变成了内存垃圾,那执行 freeSpan -> 归还组成该 mspan 所使用的页,并更新全局的页分配器摘要信息;
- 如果 mspan 中没有空槽,说明所有对象都是存活的,将其放入 fullSwept 队列中;
- 如果 mspan 中有空槽,说明这个 mspan 还可以拿来做内存分配,将其放入 partialSweep 队列中。
之后“清道夫” scvg goroutine 被唤醒,执行线性流程,一路运行到将页内存归还给操作系统,也就是 bgscavenge -> pageAlloc.scavenge -> pageAlloc.scavengeOne -> pageAlloc.scavengeRangeLocked -> sysUnused -> madvise,最终还是要用 madvise 来将内存归还给操作系统。
数据结构
记录seeep 情况的数据结构
var sweep sweepdata
type sweepdata struct {
lock mutex
g *g
parked bool
started bool
nbgsweep uint32 // 记录sweep 情况
npausesweep uint32
}
源码分析
标记终止结束后,会进入 GCoff 阶段,并调用 gcSweep 来并发的使后台清扫器 Goroutine 与mutator并发执行。
回收就是 mheap 自己找到 一个可以回收的mspan,mspan.sweep 回收白色 object。mheap 和mspan 自己管分配和回收逻辑(mspan.markBitsForIndex/mspan.sweep),由runtime 在合适的时机触发。
func gcSweep(mode gcMode) {
// 将 mheap_ 相关的标志位清零
lock(&mheap_.lock)
mheap_.sweepgen += 2
mheap_.sweepdone = 0
...
unlock(&mheap_.lock)
...
// 唤醒后台清扫任务
if sweep.parked {
sweep.parked = false
ready(sweep.g, 0, true)
}
...
}
func gcenable() {
// Kick off sweeping and scavenging.
c := make(chan int, 2)
// 设置异步清扫
go bgsweep(c)
<-c
}
func bgsweep(c chan int) {
// 设置清扫 Goroutine
sweep.g = getg()
// 循环清扫
for {
// 清扫一个span, 然后进入调度
for sweepone() != ^uintptr(0) {
sweep.nbgsweep++
Gosched()
}
// 释放一些未使用的标记队列缓冲区到heap
for freeSomeWbufs(true) {
Gosched()
}
// 否则让后台清扫任务进入休眠
}
}
func sweepone() uintptr {
var s *mspan
for {
var s *mspan
//查找一个 span 并释放
s = mheap_.nextSpanForSweep()
// 回收内存
s.sweep(false)
...
}
}
对编程的影响
GC友好的代码:避免内存分配和赋值
- 尽量使用引用传递
- 初始化至合适的大小
- 复用内存
Go 语言垃圾回收的关键点:
- 无分代;因为无分代,当我们遇到一些需要在内存中保留几千万 kv map 的场景(比如机器学习的特征系统)时,就需要想办法降低 GC 扫描成本。非移动gc。
- 与应用执行并发;
- 协助标记流程;
- 当应用分配内存过快时,后台的 mark worker 无法及时完成标记工作,这时应用本身需要进行堆内存分配时,会判断是否需要适当协助 GC 的标记过程(gcAssistAlloc),防止应用因为分配过快发生 OOM。
- 因为有协助标记,当应用的 GC 占用的 CPU 超过 25% 时,会触发大量的协助标记,影响应用的延迟,这时也要对 GC 进行优化。
- 并发执行时开启 write barrier。
其它
现代计算机语言大多数都带有自动内存管理功能,也就是垃圾收集(GC)。程序可以使用堆中的内存,但我们没必要手工去释放。垃圾收集器可以知道哪些内存是垃圾,然后归还给操作系统。垃圾收集包括标记-清除、停止-拷贝两大类算法,停止-拷贝算法被认为是最快的垃圾收集算法,但停止-拷贝算法有缺陷STW(Stop-The-World)。 在自动内存管理领域的一个研究的重点,就是如何缩短这种停顿时间。以 Go 语言为例,它的停顿时间从早期的几十毫秒,已经降低到了几毫秒。甚至有一些激进的算法,力图实现不用停顿。增量收集和并发收集算法,就是在这方面的有益探索。
Go 的 GC 有且只会有一个参数进行调优,也就是我们所说的 GOGC,目的是为了防止大家在一大堆调优参数中摸不着头脑。 默认值是 100。这个 100 表示当内存的增加值小于等于 100% 时会强制进行一次垃圾回收。我们可以通过环境变量将这个值修改成 200,表示当内存增加 200% 时强制进行垃圾回收。或者将这个值设置为负数表示不进行垃圾回收。
小时候看动画片《一休》,提到有一次一休的师兄被惩罚去树林里数一下树有多少,结果下雨天摔倒啥的,很容易就忘了刚才数到哪了。后来一休想了个办法,拿来一捆绳子,每棵树上系一根绳子,数一下剩下多少根绳子,就知道有多少棵树了。
字节大规模微服务语言发展之路GC 有很多需要关注的方面,比如吞吐量——GC 肯定会减慢程序,那么它对吞吐量有多大的影响;还有,在一段固定的 CPU 时间里可以回收多少垃圾;另外还有 Stop the World 的时间和频率;以及新申请内存的分配速度;还有在分配内存时,空间的浪费情况;以及在多核机器下,GC 能否充分利用多核等很多方面问题。非常遗憾的是,Golang 在设计和实现时,过度强调了暂停时间有限。但这带来了其他影响:比如在执行的过程当中,堆是不能压缩的,也就是说,对象也是不能移动的;还有它也是一个不分代的 GC。所以体现在性能上,就是内存分配和 GC 通常会占用比较多 CPU 资源。PS:copy gc 可以使用线性分配,分配效率高,mark-sweep 只能采用空闲链表分派,虽然可以分级,就稍微差一些。
Garbage Collection In Go : Part I - Semantics Garbage Collection In Go : Part II - GC Traces Garbage Collection In Go : Part III - GC Pacing
留下评论