调度实践
简介
整体脉络:粗放的资源评估;节点分时复用 ==> 节点超卖,根据负载动态调度(调整超卖比例、动态驱逐等)==> 节点划分资源池,高优池支持绑核、cpu负载控制在50%以下,池间强隔离,不同池运行不同类型的任务,池资源大小随负载动态调整。
- 云上集群:调度层 通过hpa 或ahpa 尽量使得replica 符合真实的高峰低谷,vpa 使得资源申请符合真实需求,ca 使得节点数符合真实需求。再出于防止某个节点load太高考虑 真是node 真实负载做一些descheduler 就很完美了。
- 在固有资源池中,需要进一步提升资源利用率,且负载类型存在互补,就可以考虑用slo差异化,面向qos去做超卖。
- 精细化调度就更是结合硬件,系统能力,与应用特征,最大化单机上的资源效率。混部其实是更高的要求,也是更复杂的,有不少约束,比如系统资源的隔离和控制能力,是很依赖内核能力,以及硬件特性的。
一篇文章搞定大规模容器平台生产落地十大实践 为了实现应用的高可用,需要容器在集群中合理分布
- 拓扑约束依赖 Pod Topology Spread Constraints, 拓扑约束依赖于Node标签来标识每个Node所在的拓扑域。
-
nodeSelector & node Affinity and anti-affinity Node affinity:指定一些Pod在Node间调度的约束。支持两种形式:
- requiredDuringSchedulingIgnoredDuringExecution
- preferredDuringSchedulingIgnoredDuringExecution
IgnoreDuringExecution表示如果在Pod运行期间Node的标签发生变化,导致亲和性策略不能满足,则继续运行当前的Pod。
-
Inter-pod affinity and anti-affinity, 允许用户通过已经运行的Pod上的标签来决定调度策略,如果Node X上运行了一个或多个满足Y条件的Pod,那么这个Pod在Node应该运行在Pod X。有两种类型
- requiredDuringSchedulingIgnoredDuringExecution,刚性要求,必须精确匹配
- preferredDuringSchedulingIgnoredDuringExecution,软性要求
- Taints and Tolerations, Taints和tolerations是避免Pods部署到Node,以及从Node中驱离Pod的灵活方法
让pod 的不同实例别再一个机器或机架上
假设给 每个node 打上机架的标签 kubectl label node 192.168.xx.xx rack=xxx
spec:
topologySpreadConstraints:
- maxSkew: 5 # 机架最最差的情况下,允许存在一个机架上面有5个pod
topologyKey: rack
whenUnsatisfiable: ScheduleAnyway # 实在不满足,允许放宽条件
labelSelector:
matchLabels: # pod选择器
foo: bar
- maxSkew: 1 # 实在不满足允许节点上面跑的pod数量
topologyKey: kubernetes.io/hostname # 不同的主机
whenUnsatisfiable: ScheduleAnyway # 硬性要求不要调度到同一台机器上面
labelSelector:
matchLabels:
foo: bar
亲和性与调度
- 对于Pod yaml进行配置,约束一个 Pod 只能在特定的 Node(s) 上运行,或者优先运行在特定的节点上
- nodeSelector
- nodeAffinity,相对nodeSelector 更专业和灵活一点
- podAffinity,根据 POD 之间的关系进行调度
- 对Node 进行配置。如果一个节点标记为 Taints ,除非 POD 也被标识为可以容忍污点节点,否则该 Taints 节点不会被调度pod。
Node affinity, described here, is a property of pods that attracts them to a set of nodes (either as a preference or a hard requirement). Taints are the opposite – they allow a node to repel(击退) a set of pods.
Taints and Tolerations Kubernetes污点和容忍度
给节点加Taintskubectl taint nodes node1 key=value:NoSchedule
给pod 加加tolerations
tolerations:
- key: "key"
operator: "Equal"
value: "value"
effect: "NoSchedule"
effect 类型
- NoSchedule, This means that no pod will be able to schedule onto node1 unless it has a matching toleration.
- PreferNoSchedule, 软性 NoSchedule
- NoExecute, 除了NoSchedule 的效果外,已经运行的pod 也会被驱逐。
集群节点负载不均衡的问题
被集群节点负载不均所困扰?TKE 重磅推出全链路调度解决方案
大型Kubernetes集群的资源编排优化Kubernetes原生的调度器多是基于Pod Request的资源来进行调度的,没有根据Node当前和过去一段时间的真实负载情况进行相关调度的决策。这样就会导致一个问题在集群内有些节点的剩余可调度资源比较多但是真实负载却比较高,而另一些节点的剩余可调度资源比较少但是真实负载却比较低, 但是这时候Kube-scheduler会优先将Pod调度到剩余资源比较多的节点上(根据LeastRequestedPriority策略)。
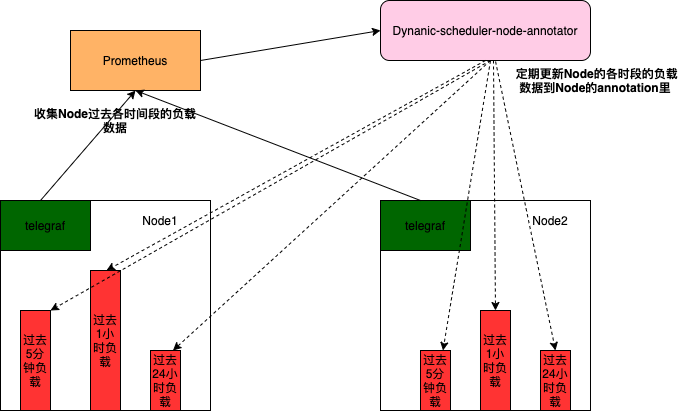
为了将Node的真实负载情况加到调度策略里,避免将Pod调度到高负载的Node上,同时保障集群中各Node的真实负载尽量均衡,腾讯扩展了Kube-scheduler实现了一个基于Node真实负载进行预选和优选的动态调度器(Dynamic-scheduler)。Dynamic-scheduler在调度的时候需要各Node上的负载数据,为了不阻塞动态调度器的调度这些负载数据,需要有模块定期去收集和记录。如下图所示node-annotator会定期收集各节点过去5分钟,1小时,24小时等相关负载数据并记录到Node的annotation里,这样Dynamic-scheduler在调度的时候只需要查看Node的annotation,便能很快获取该节点的历史负载数据。
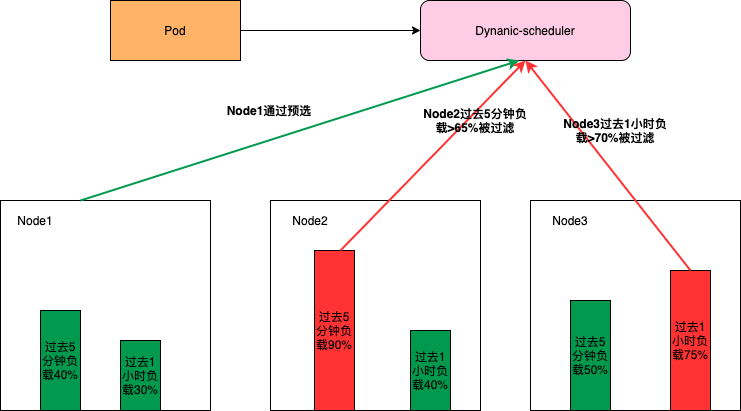
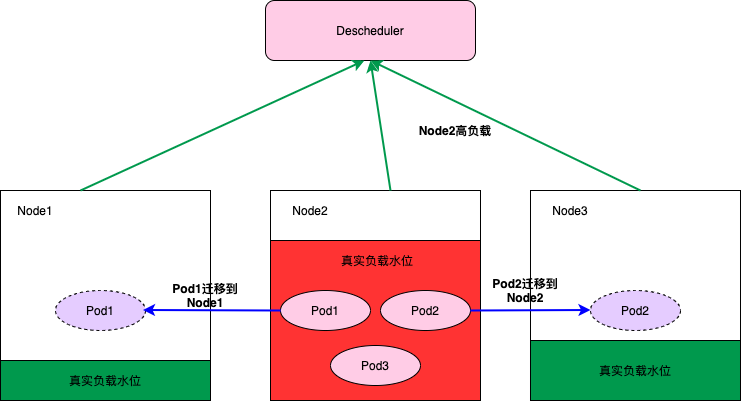
为了避免Pod调度到高负载的Node上,需要先通过预选把一些高负载的Node过滤掉,同时为了使集群各节点的负载尽量均衡,Dynamic-scheduler会根据Node负载数据进行打分, 负载越低打分越高。Dynamic-scheduler只能保证在调度的那个时刻会将Pod调度到低负载的Node上,但是随着业务的高峰期不同Pod在调度之后,这个Node可能会出现高负载。为了避免由于Node的高负载对业务产生影响,我们在Dynamic-scheduler之外还实现了一个Descheduler,它会监控Node的高负载情况,将一些配置了高负载迁移的Pod迁移到负载比较低的Node上。K8s 中 Descheduler 默认策略不够用?扩展之
zhangshunping/dynamicScheduler通过监控获取到各个k8s节点的使用率(cpu,mem等),当超过人为设定的阈值后,给对应节点打上status=presure,根据k8s软亲和性策略(nodeAffinity + preferredDuringSchedulingIgnoredDuringExecution),让pod尽量不调度到打上的presure标签的节点。
kubernetes-sigs/descheduler 会监控Node的高负载情况,将一些配置了高负载迁移的Pod迁移到负载比较低的Node上。 PS:未细读
作业帮 Kubernetes 原生调度器优化实践实时调度器,在调度的时候获取各节点实时数据来参与节点打分,但是实际上实时调度在很多场景并不适用,尤其是对于具备明显规律性的业务来说,比如我们大部分服务晚高峰流量是平时流量的几十倍,高低峰资源使用差距巨大,而业务发版一般选择低峰发版,采用实时调度器,往往发版的时候比较均衡,到晚高峰就出现节点间巨大差异,很多实时调度器往往在出现巨大差异的时候会使用再平衡策略来重新调度,高峰时段对服务 POD 进行迁移,服务高可用角度来考虑是不现实的。显然,实时调度是远远无法满足业务场景的。针对这种情况,需要预测性调度方案,根据以往高峰时候 CPU、IO、网络、日志等资源的使用量,通过对服务在节点上进行最优排列组合回归测算,得到各个服务和资源的权重系数,基于资源的权重打分扩展,也就是使用过去高峰数据来预测未来高峰节点服务使用量,从而干预调度节点打分结果。
如何提高 Kubernetes 集群资源利用率?原生调度器并不感知真实资源的使用情况,需要引入动态资源视图。但会产生一个借用的代价:不稳定的生命周期。因此有两个核心问题要解决:第一,动态资源视图要如何做;第二个单机资源的调配如何保证供给。
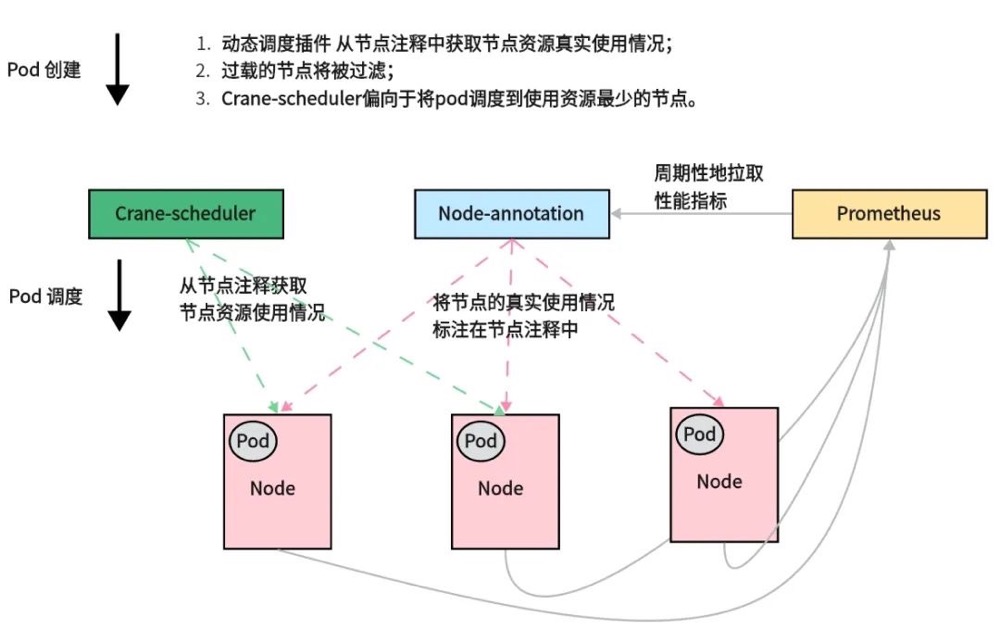
Crane 调度器介绍——一款在 Kubernetes 集群间迁移应用的调度插件crane-sheduler 基于 prometheus 集群真实资源负载进行调度,将其应用于调度过程中的 Filter 和 Score 阶段,能够有效缓解集群资源负载不均的问题。
节点资源预留
Kubernetes 资源预留配置考虑一个场景,由于某个应用无限制的使用节点的 CPU 资源,导致节点上 CPU 使用持续100%运行,而且压榨到了 kubelet 组件的 CPU 使用,这样就会导致 kubelet 和 apiserver 的心跳出问题,节点就会出现 Not Ready 状况了。默认情况下节点 Not Ready 过后,5分钟后会驱逐应用到其他节点,当这个应用跑到其他节点上的时候同样100%的使用 CPU,是不是也会把这个节点搞挂掉,同样的情况继续下去,也就导致了整个集群的雪崩。
$ kubectl describe node ydzs-node4
......
Capacity:
cpu: 4
ephemeral-storage: 17921Mi
hugepages-2Mi: 0
memory: 8008820Ki
pods: 110
Allocatable:
cpu: 4
ephemeral-storage: 16912377419
hugepages-2Mi: 0
memory: 7906420Ki
pods: 110
......
allocatale = capacity - kube_reserved - system_reserved - eviction_hardNode Capacity 是节点的所有硬件资源,kube-reserved 是给 kube 组件预留的资源,system-reserved 是给系统进程预留的资源,eviction-threshold 是 kubelet 驱逐的阈值设定,allocatable 才是真正调度器调度 Pod 时的参考值(保证节点上所有 Pods 的 request 资源不超过 Allocatable)。
“贪心”的开发者 和超卖
如果资源足够多,那调度系统就没有存在的必要。调度往往都是为了解决业务运行需要的资源与平台可以提供的资源之间的矛盾而存在的,最终超卖会成为常态。
《大数据经典论文解读》大部分情况下,开发者并不会去仔细测试自己的程序到底会使用多少资源,很容易作出“拍脑袋”的决策。而且,一般来说,开发者都会偏向于高估自己所需要使用的资源,这样至少不会出现程序运行出问题的情况。但是,我们使用 Borg 的目的,就是尽量让机器的使用率高一点。每个开发者都给自己留点 Buffer,那我们集群的利用率怎么高得起来呢?所以,面对贪心的都会多给自己申请一点资源的开发者,Borg 是通过这样两个方式,来提升机器的使用率。
- 对资源进行“超卖”。也就是我明明只有 64GB 的内存,但是我允许同时有申明了 80GB 的任务在 Borg 里运行。当然,为了保障所有生产类型的任务一定能够正常运行,Borg 并不会对它们进行超卖。但是,对于非生产类型的任务,比如离线的数据批处理任务,超卖是没有问题的。大不了,其中有些任务在资源不足的时候,会被挂起,或者调度到其他机器上重新运行,任务完成的时间需要久一点而已。
- 对资源进行动态的“回收”。我们所有的生产的 Task,肯定也没有利用满它们所申请的资源。所以,Borg 实际不会为这些 Task 始终预留这么多资源。Borg 会在 Task 开始的时候,先为它分配它所申请的所有资源。然后,在 Task 成功启动 5 分钟之后,它会慢慢减少给 Task 分配的资源,直到最后变成 Task 当前实际使用的资源,以及 Borg 预留的一些 Buffer(削减的资源称为回收资源)。当然,Task 使用的资源可能是动态变化的。比如一个服务是用来处理图片的,平时都是处理的小图片,内存使用很小,忽然来了一张大图片,那么它使用的内存一下子需要大增。这个时候,Borg 会迅速把 Task 分配的资源,增加到它所申请的资源数量。对于回收资源,Borg 只会分配给非生产类型的任务。因为,这部分资源的使用是没有保障的,随时可能因为被回收了资源的生产类型 Task,忽然需要资源,被动态地抢回去。如果我们把这部分资源分配给其他生产类型的 Task,那么就会面临两个生产类型的 Task 抢占资源的问题。
Crane-scheduler:基于真实负载进行调度Crane-scheduler是一个基于scheduler framework 实现的完整调度器。
拓扑感知
梳理
| 解决方案 | 资源设置不合理 | 相同 Pod 资源使用有差异 | 多维度空闲资源碎片化 | 突发流量 | 资源维度有限 |
|---|---|---|---|---|---|
| HPA | × | × | × | √ | × |
| 反亲和性 | × | √ | × | × | × |
| 在离线混布 | × | × | √ | × | × |
| Descheduler | × | √ | × | × | × |
| Dynamic Scheduler | × | √ | × | × | × |
| 高低水位线 | × | √ | √ | × | × |
上述解决方案只是解决了部分问题,没有解决资源设置不合理、资源维度有限这两个问题。此外,缺少一个整体的解决方案来对上述所有问题进行统一优化。
- 资源设置不合理,云原生的调度方式是基于 requests 进行的,为了实现基于 predicts 调度,需要对调度器的功能进行扩展,需要添加一个过滤插件,计算节点已绑定 Pod 的 predicts 和待调度的 Pod predicts 之和,并过滤掉不满足资源需求的节点。
- 资源维度有限,除了 CPU、内存和磁盘大小外,磁盘 IO、网络 IO 对于业务运行也非常重要。所以在收集 Pod 监控数据时,额外收集了这两个维度的数据,在调度时也会计算在内。同时如果业务有其他额外的资源维度,也可以很方便的扩展。这样解决了资源维度有限的问题。
- 整体编排,以我们线上环境的重庆集群为例,当前集群使用了69个节点,在计算部署方案之后,只需要使用27个节点即可满足所有 Pod 的运行,机器成本下降61%。并且为了保证服务质量,计算部署方案时节点各维度资源的最高利用率设置为不超过80%,因此有进一步压缩的可能。同时各资源维度也实现了较好的均衡性。将部署方案实际应用到节点还面临两大挑战:如何将 Pod 调度到方案指定的节点;调度 Pod 时如何保证不影响业务正常运行。PS:有点像一个更复杂的Descheduler
留下评论