《架构整洁之道》笔记
简介
软件构建过程的三个阶段
- 先让代码工作起来,如果代码不能工作,就不能产生价值
- 然后再试图将它变好,通过对代码进行重构,让我们自己和其他人更好的理解代码,并能按照需求不断地修改代码
- 最后再试着让它运行的更快, 按照性能提升的需求来重构代码
大部分人只实现第一个目标就结束了,但“在实践中学习正确的工作方法, 然后再重写一个更好地版本”才是提高“功力”的最好办法。
架构设计是有一些原则的
总体原则:优秀的设计比糟糕的设计更容易变更。我刚刚做的事情让系统更容易改变,还是更难改变?
余晟:结构化编程 杜绝了goto 导致的混乱,有多少次, 我看到的系统设计图里,根本没有”层次“的概念,各个模块没有一致的接口划分,与子系统交互的不是子系统,而是一盘散沙的接口,甚至接口之间随意互调,带来的就是维护与调试的噩梦,吹散历史的迷雾,不正是古老的goto陷阱的再现吗?
| 开发的三个层次 | |
|---|---|
| 程序员 | 代码跑起来就行 |
| 工程师 | 可读、可扩展、可维护、重用 用工程的方法来写代码 |
| 架构师 |
大多数的人目标不是设计出一个优质的软件或架构,而是快速解决一个具体的问题。但问题就像一个生命体一样,它们会不断地繁殖和进化, 问题的多少和系统的复杂度呈正比,并且是指数级正比,此时越来越难做技术决定,此时有一些资深的工程师开始挑战这些问题,有一些资深的工程师开始站出来挑战这些问题, 有的基于业务分析给出平衡的方案 有的开始尝试设计更高级的技术,有的开始设计更灵活的系统,有的则开始简化和轻量化整个系统,他们就是架构师。
软件架构关注的一个重点是组织结构(structure),不管是讨论组件Component、类Class、函数Function、模块Module,还是层级Layer、服务Service以及微观与宏观的 软件开发过程,软件的组织结构 都是我们的主要关注点。
物理建筑,不管地基是石头还是水泥,形状是高大还是宽阔, 风格是气势恢宏还是小巧玲珑, 其组织结构都一目了然。物理建筑的组织结构 必须遵循“受重力”这一自然规律,同时还要符合建筑材料自身的物理特性。
计算机硬件在过去许多年发生了巨大的变化, 但今天的软件和过去本质上是一样的,都是由if、赋值语句以及while 循环组成的 ==> 软件架构的规则就是 排列组合代码块的规则 ==> 代码块没什么变化,因此排列组合它们的规则也不会变化。
一个软件架构的优劣,可以用它满足用户需求所需要的成本来衡量。 为了在系统构建过程中采用好的设计和架构以便减少构建成本,需要先了解系统架构的各个属性与成本和生产力的关系。 (优劣以成本衡量 ==> 成本来自几个部分 ==> 架构的组成及每个部分和成本的关系)
每个软件系统都可以通过行为和架构两个维度来体现它的实际价值
- 行为价值,按照需求,实现业务,创造价值,并修复出现的bug。这也是大部分程序猿认为的全部工作。
- 架构价值,软件系统必须足够”软“即容易修改。从产品相关的角度看,他们所提出的一系列的变更需求的范畴都是类似的,因此成本也应该是固定的。但从研发者的角度看,系统持续不断地变更需求像是要求他们不停地用一堆不同形状的拼图块拼成一个新的“形状”。如果系统架构设计偏向某种特定的“形状”,新的变更就越来越难以实施。
软件架构师这一职责本身就应更关注系统的整体结构,而不是具体的功能和系统行为的实现。软件架构师必须创建出一个可以让功能实现起来更容易、修改起来更简单、扩展起来更轻松地软件架构。
笔者的一个体会是,我们去推动一个事情, 从管理的角度,一方面是给公司带来价值,一方面是锻炼团队水平,进而间接的带来价值。
编程范式
| 编程范式 | 提出时间 | 描述 | 解决的问题 | 对应到泛指的分布式系统 | |
|---|---|---|---|---|---|
| 结构化编程 | 1968 | 对程序控制权的直接转移进行了限制和规范 | 消灭goto | 接口之间随意互调 | 带来的就是维护和调试的噩梦 |
| 面向对象编程 | 1966 | 对程序控制权的间接转移进行了限制和规范 | 利用多态限制对函数指针的使用 通过封装、继承、多态 让代码的”缝隙“大一点 对变更更友好 |
接口的设计非常随意,不是基于行为而是基于特定场景实现 没有做适当的抽象,也没有给未来留有空间 |
|
| 函数式编程 | 1958 | 对程序中的赋值进行了限制和规范 | 隔离可变性、避免状态冲突 | 状态或变量的修改直接暴露,被不经意/恶意修改 | 只提供CR,不提供完整的CRUD操作 |
这三个编程范式都对程序猿提出了新的限制,每个范式都约束了某种编写代码的方式,没有一个编程范式是在增加新能力。也就是说,我们过去50年学到的东西主要是——什么不应该做。
我们必须面对这种不友好的现实:软件构建并不是一个迅速前进的技术。今天构建软件的规则和1946年阿兰.图灵写下电子计算机第一行代码时是一样的。尽管工具变化了,硬件变化了,但软件编程的核心没有变。
结构化编程
- 顺序、分支、循环可以构造任何程序
- 顺序、分支、循环代码的正确性可以被证明
- goto某些用法的正确性无法被证明
我们可以将一个大型问题拆分为一系列高级函数的组合,而这些高级函数各自又可以继续拆分为一系列低级函数,每个被拆分出来的函数都可以用结构化编程范式(顺序、分支、循环)来写。然后再编写相关的测试来试图证明这些函数是错误的,若无法证明,则可以认为这些函数是正确的,进而推导整个程序是正确的。
结构化编程最有价值的地方就是,它赋予了我们创造可证伪程序单元的能力。(作为新世纪的程序猿,我们天然认为是对的,以至于从没看重过这个事儿)这就是为什么现代语言基本已经没有goto了,无论是否自愿,我们都是结构化编程的践行者了。
无论从哪一个层面,从最小的函数到最大的组件,软件开发的过程都和科学研究非常类似,它们都是由证伪驱动的。软件架构师需要定义可以方便地进行证伪(测试)的模块、组件以及服务。为了达到这个目的,它们需要将类似结构化编程的限制方法应用到更高的层面上。
面向对象编程
面向对象的三个特性 相对于 以前 并没有理论创新
- 封装,java、c++相对c 来说,封装性实际上更弱了
- 继承,在面向对象出来以前,对继承的支持已经很久了,面向对象只是更便利一些。
- 多态,多态其实不过是函数指针的一种应用,面向对象通过约束使用方式,消除了函数指针滥用危险性。
笔者的理解:虽然没有理论创新,但面向对象还是从形式上 约束开发有意无意的使用上述三个特性,尤其是多态,使得需求变化时,减少代码的更改或不更改成为可能。毕竟软件开发,一个是应对复杂性,一个是应对变化。
函数式编程

一切并发应用遇到的问题,一切由于使用多线程、多处理器而引起的问题,如果没有可变变量的话都不可能发生。一个架构设计良好的应用程序 应该将状态修改的部分和不需要修改状态的部分隔离成单独的组件,然后用合适的机制来保护可变量。软件架构师应该着力于将大部分处理逻辑都归于不可变组件中,可变状态组件的逻辑应该越少越好。PS:可以看到,函数式编程不是试图取代所有业务逻辑开发,而是仅取代其中不可变组件的开发。
随着硬件的发展,内存越大、处理速度越快,我们对可变状态的依赖就越少。比如某个银行应用程序需要维护客户账户余额信息,当它执行存款事务时,就要同时负责修改余额记录。如果我们不保存具体账户余额,仅仅保存事务日志,当有人查询账户余额时,我们将全部交易记录取出并进行累计, 就不需要维护任何可变变量了。读者听起来也许觉得并不靠谱,但我们现在用的源代码管理程序就是这么工作的。
设计原则 推广到架构设计上
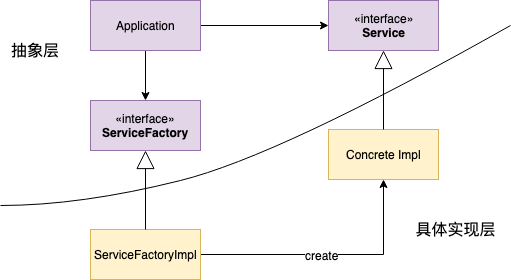
曲线代表了软件架构中抽象层和具体实现层的边界,在这里,所有跨越这条边界源代码级别的依赖关系都应该是单向的,即具体实现层依赖抽象层。
ISP:任何层次的软件设计如果依赖于不需要的东西,都会是有害的。从源代码层次来说, 这样的依赖关系会导致不必要的重新编译和重新部署。对更高层次的软件架构设计来说,问题也是类似的。
变更、聚合、解耦
- OCP 设计良好的软件应该易于扩展,同时抗拒修改
- 如果A组件不想被B组件上发生的修改所影响,那么就应该让B组件依赖于A组件
- CCP 如果某程序中的代码必须要进行某种变更,那么这些变更最好都体现在同一个组件中,而不是分布于很多组件中。 ==> 如果两个类紧密相关,不管是源代码层面还是抽象理念层面,永远都会一起被修改, 那么它们就应该被归属为同一个组件。 ==> 将某一个类变更所涉及的所有类尽量聚合在一处
- 将变更原因(甚至是变更速率)不同的函数纳入到不同的类中 ==> 将变更原因不同的类放入到不同的组件中
- 多个类同时作为某个可复用的抽象定义,这些类应该放在同一个组件中。比如容器类及相关的遍历器类。
- 不依赖不需要用到的东西:不应该出现别人只需要依赖组件的某几个类而不需要其他类的情况 ==> 不要依赖带有不需要函数的类
- 让可变更的组件位于顶层, 同时依赖于底层的稳定组件
什么是软件架构
所有的软件系统 都可以降解为策略和细节这两种主要元素
- 策略体现的是软件中所有的业务规则与操作过程,是系统的真正价值所在
- 而细节是指让操作系统的人、其它系统以及程序员们与策略进行交互,但是又不会影响到策略本身的行为。它们包括IO设备、数据库、web系统、服务器、框架、交互协议等。
软件架构师的目标是创建一种系统形态,该形态会以策略为最基本的元素,并让细节与策略脱离关系。
一个设计良好的架构在行为上对系统最重要的作用就是明确和显式的反应系统设计意图的行为,使其在架构层面上可见。譬如说,一个架构优良的购物车应用看起来就该像是一个购物车应用,这些行为在系统顶层作为主要元素已经明确可见的了,这些元素会以类、函数和模块的形式在架构中占据明显的位置,它们的名字也能够清晰的描述对应的功能。
划分边界
架构师追求的最大目标 是最大限度的降低构建和维护一个系统所需的人力资源 ==> 一个系统最消耗人力资源的是什么 ==> 一个系统中存在的耦合 ==> 过早做出的、不成熟的决策所导致的耦合。 ==> 哪些决策会被认为过早且不成熟的呢? 那些决策与系统的业务需求无关,包括:要采用的框架、数据库、web服务器、工具库、依赖注入等,一个设计良好的系统中,这些细节性的决策都应该是辅助性的,可以被推迟的。
业务逻辑————DDD思想的来源
业务逻辑就是系统中那些真正用于赚钱或省钱的业务逻辑与过程。更严格的讲,无论这些业务是在计算机上实现的,还是人工执行的,它们在赚钱或省钱上的作用是一样的。我们通常称这些业务逻辑为“关键业务逻辑”,关键业务逻辑 通常需要处理一些数据,例如在借贷业务逻辑中,我们需要知道借贷的数量、利率以及还款日程。我们将这些数据称为“关键业务数据”,因为这些数据无论自动化与否都必须要存在。关键业务逻辑和关键业务数据是紧密相关的,所以它们很适合被放在同一个对象中处理,称为业务实体(Entity)。
这些实体对象要么直接包含关键业务数据,要么很容易访问这些数据, 业务实体的接口层则是由那些实现关键业务逻辑,操作关键业务数据的函数组成。当我们创建这样一个类时,就是将软件中具体实现了该关键业务的部分聚合在一起,将其与自动化系统中其它部分隔离区分。这个类独自代表了整个业务逻辑, 它与数据库、用户界面、第三方框架等内容无关。业务逻辑应该是系统中最独立、复用性最高的代码, 不掺杂用户界面(比如httpservletrequest)或者所使用的数据库相关的东西(比如数据model)。
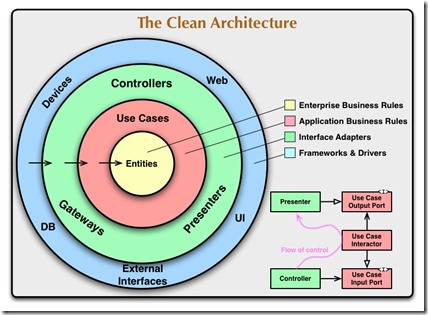
同心圆分别代表了软件系统中的不同层次,通常越靠近中心,其所在的软件层次就越高。 基本上,外层圆代表的是机制, 内层圆代表的是策略。源码中的依赖关系必须只指向同心圆的内层,即由低层机制指向高层策略。换句话说,就是任何属于内层圈中的代码都不应该牵涉外层圆中的代码,比如函数、类、变量等。PS:controller-service-dao 给人的感觉dao 是核心,其实service 是核心(service 之间才会互相调用),controller 和dao 才是外层。
- 很多时候开发的方式大家倾向于,拿到需求后看表怎么设计,然后看代码怎么写,这其实也是面向过程的一个表现。在软件初期,这样的方式复杂度是很低的,没有复用没有扩展,一人吃饱全家不饿。但随着业务的发展系统的演进,复杂度会陡增。
- 一开始通过领域建模方式,以面向对象思维进行软件设计,复杂度的上升可以得到很好的控制。先思考我们领域模型的设计,这是我们业务系统的核心,再逐步外延,到接口到缓存到数据库。但领域的边界,模型的抽象,从刚开始成本是高于数据驱动的。如果刚开始我们直接以数据驱动面向过程的流程式代码,可以很轻松的解决问题,并且之后也不会面向更复杂的场景与业务,那这套模式就是最适合这套系统的架构设计。如果我们的系统会随着业务的发展逐渐复杂,每一次的发布都会提升下一次发布的成本,那么我们应该考虑投入必要的成本来面向领域驱动设计。
面向服务 and 组件维度的多态
架构设计的任务 就是找到高层策略与低层细节之间的架构边界,同时保证这些边界遵守依赖关系规则。所谓的服务本身只是一种比函数调用方式成本稍高的,分割应用程序行为的一种形式,与系统架构无关。服务这种形式说到底 不过是一种跨进程/平台的函数调用,有些服务具有架构上的意义,有些则没有。PS:边界是必须遵守依赖关系的,不是所有的物理“边界”都有边界的内涵。
按功能切分服务的方式,在跨系统的功能变更(比如一个新功能实现涉及到所有组件)时是最脆弱的。在代码设计时,我们可以设计出一系列多态的类以应对扩展。那么服务化也可以做到这一点么?答案是肯定的。服务并不一定必须是小型的单体程序,服务也可以按照SOLID原则来设计, 按照组件结构来部署,这样就可以做到在添加/删除组件时不影响服务中的其他组件。我们可以将Java中的服务看作是一个或多个jar文件中的一组抽象类,而每个新功能或者功能扩展都是另一个jar文件中的类,它们都扩展了之前jar文件中的抽象类。这样一来,部署新功能就不再是部署服务了,而只是简单的在服务的加载路径下增加一个jar文件。在该架构中, 服务仍然和之前一样但都增加了内部结构, 以便使用衍生类添加新功能, 而这些衍生类都有各自所生存的组件。系统的架构边界并不落在服务之间,而是穿透所有服务,在服务内部以组件的形式存在。
服务化有助于提高系统的可扩展性和可研发性, 但服务本身却并不能代表整个系统的架构设计。系统的架构是由系统内部的架构边界,以及边界之间的依赖关系所定义的,与系统各组件之间的调用和通信方式无关。一个服务可能是一个独立组件,以系统架构边界的形式隔开。一个服务也可能由几个组件组成,其中的组件以架构边界的形式互相隔离。
可测试性
如果测试代码与系统是强耦合的,它就得随着系统变更而变更。哪怕只是系统中组件的一点小变化,都可以导致许多与之相耦合的测试出现问题,需要做出相应的变更。 一个办法是,系统专门提供为验证业务逻辑的测试API,将应用程序与测试代码解耦,产品代码可以在不影响测试的情况下进行重构和演进。同样的,也允许测试代码在不影响生产代码的情况下进行重构和演进。 ==> 这样设计的测试代码,测试组件和API也是系统重要的组成部分。
数据库只是实现细节
从系统架构的角度看,数据库并不重要。为应用程序设计数据结构很重要,但数据库不是数据模型, 数据库只是一款存取数据的工具。虽然关系型数据库的表模型设计对某一类数据访问需要来说可能很方便, 但是把数据按行组织成表结构本身并没有什么架构意义上的重要性。很多数据访问框架允许将数据行和数据表以对象的形式在系统内部传递,这在系统架构上是完全错误的。
为什么数据库如此流行?硬盘。我们需要的就是某种数据访问和管理系统,过去几十年,业界发展了两种截然不同的系统:文件系统和关系型数据库系统。文件系统是存储整个文档的,当按名字检索时,文档系统很有用, 当需要检索文件内容时,文件系统就没啥用了。数据库系统则主要关注的是内容, 提供的是一种便于内容检索的存储方式。
假设硬件不存在会怎么样?在如今这可不算开玩笑。我们还需要按文件、表组织数据么?当然不,我们会将数据存储为链表、树、哈希表、堆栈、队列等各种数据结构,然后用指针或引用来访问这些数据。
web是实现细节
web技术事实上没有改变任何东西,只是GUI的一种, 只是从1960年来经历的数次震荡的一次。这些震荡一会儿将全部计算资源集中在中央服务器上,一会儿又将计算资源分散在各个终端上。
应用程序框架是实现细节
项目分包
以一个订单系统为例
| 切分方式 | 包的组织 | 优缺点 | |
|---|---|---|---|
| 按层封装 | 水平切分 | com.mycompany.myapp.web OrdersController com.mycompany.myapp.service OrdersService,OrdersServiceImpl com.mycompany.myapp.dao OrdersRepository,JdbcOrdersRepository |
在代码初期很合适 无法体现具体业务领域的信息 |
| 按功能封装 | 垂直切分 | com.mycompany.myapp.orders OrdersController,OrdersService,OrdersServiceImpl,OrdersRepository,JdbcOrdersRepository | |
| 端口和适配器 | 内部代码domain与外部代码Infrastructure分离 | com.mycompany.myapp.web OrdersController com.mycompany.myapp.domain OrdersService,OrdersServiceImpl,Orders com.mycompany.myapp.dao JdbcOrdersRepository |
|
| 按组件封装 | UI与粗粒度组件分离 | com.mycompany.myapp.web OrdersController com.mycompany.myapp.orders OrdersComponent,OrdersComponentImpl,OrdersRepository,JdbcOrdersRepository |
如果我们将java 中所有程序类型都设置为public,那么包就仅仅是一种组织形式了(类似于文件夹),而不是一种封装方式。由于public 可以在代码库任何位置调用, 我们事实上就可以忽略包的概念,因为它并不提供什么价值。那么想要采用任何架构风格都不重要了, 四种架构方式事实上并没有任何区别。
clean architecture 与项目分包
我做Go项目的一些实战经验 是一篇将项目的分包与clean architecture 和DI结合起来讲的文章,很有见地。在简洁架构里面对我们的项目提出了几点要求(也可以认为是一个比较好的项目分包结构的要求):
- 独立于框架。该架构不依赖于某些功能丰富的软件库的存在。这允许你把这些框架作为工具来使用,而不是把你的系统塞进它们有限的约束中。
- 可测试。业务规则可以在没有 UI、数据库、Web 服务器或任何其他外部元素的情况下被测试。
- 独立于用户界面。UI 可以很容易地改变,而不用改变系统的其他部分。例如,一个 Web UI 可以被替换成一个控制台 UI,而不改变业务规则。
- 独立于数据库。你可以把 Oracle 或 SQL Server 换成 Mongo、BigTable、CouchDB 或其他东西。你的业务规则不受数据库的约束。
- 独立于任何外部机构。事实上,你的业务规则根本不知道外部世界的任何情况。
对于简洁架构来说分为了四层:
- Entities:实体
- Usecase:表达应用业务规则,对应的是应用层,它封装和实现系统的所有用例;
- Interface Adapters:这一层的软件基本都是一些适配器,主要用于将用例和实体中的数据转换为外部系统如数据库或 Web 使用的数据;
- Framework & Driver:最外面一圈通常是由一些框架和工具组成,如数据库 Database、Web 框架等。
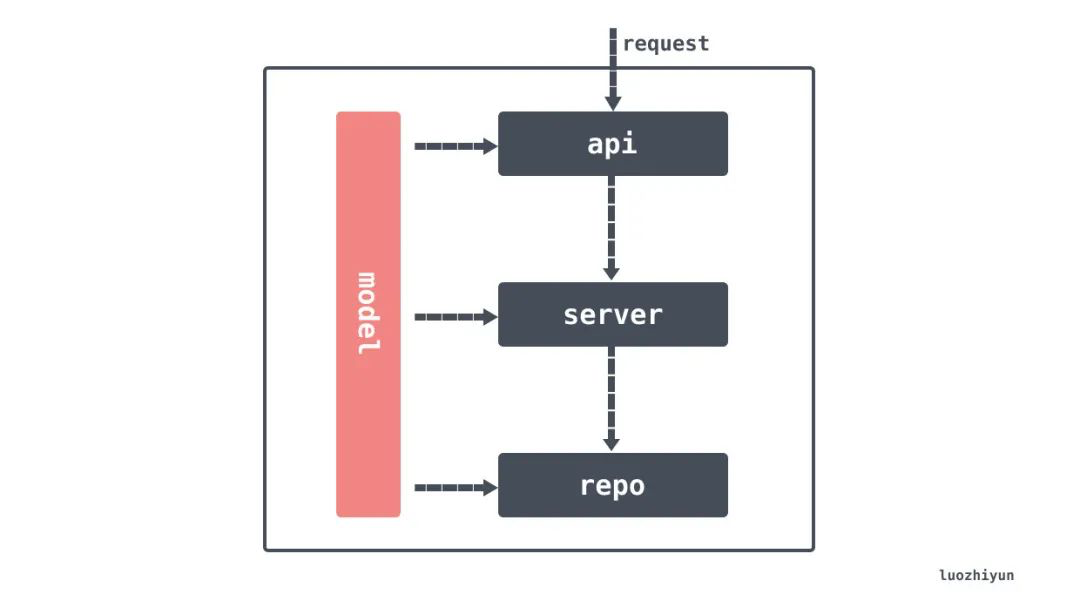
PS:对于业务来说,核心是model 和service/Usecase,对下是基础设施(可能会变),对上是UI接口(可能会变),clean architecture的视角是从内到外,请求的视角是从上到下。model想分就分一下,充血的话就是ddd了。
- 面向接口编程:除了 Models 层,层与层之间应该通过接口交互,而不是实现。如果哪天想要把Mysql换成 MongoDB 来实现我们的存储,只要更改实现就可以。
-
依赖注入,英文名 dependency injection,简称 DI 。DI 以前在 Java 工程里面经常遇到,但是在 Go 里面很多人都说不需要,但是我觉得在大型软件开发过程中还是有必要的,否则只能通过全局变量或者方法参数来进行传递。如果不用 DI 主要有两大不方便的地方,一个是底层类的修改需要修改上层类,在大型软件开发过程中基类是很多的,一条链路改下来动辄要修改几十个文件;另一方面就是就是层与层之间单元测试不太方便。因为采用了依赖注入,在初始化的过程中就不可避免的会写大量的 new,比如我们的项目中需要这样:
func main() { // 初始化db db := app.InitDB() //初始化 repo repository := repo.NewMysqlArticleRepository(db) //初始化service articleService := service.NewArticleService(repository) //初始化api handler := handlers.NewArticleHandler(articleService) //初始化router router := api.NewRouter(handler) //初始化gin engine := app.NewGinEngine() //初始化server server := app.NewServer(engine, router) //启动 server.Start() } - 我们定义好了每一层应该做什么,那么对于每一层我们应该都是可单独测试的,即使另外一层不存在。
- Models 层:这一层就很简单了,由于没有依赖任何其他代码,所以可以直接用 Go 的单测框架直接测试即可;
- Repo 层:对于这一层来说,由于我们使用了 MySQL 数据库,那么我们需要 Mock MySQL,这样即使不用连 MySQL 也可以正常测试,我这里使用 github.com/DATA-DOG/go-sqlmock 这个库来 Mock 我们的数据库;
- Service 层:因为 Service 层依赖了 Repo 层,因为它们之间是通过接口来关联,所以我这里使用 github.com/golang/mock/gomock 来 mock repo 层;
- API 层:这一层依赖 Service 层,并且它们之间是通过接口来关联,所以这里也可以使用 gomock 来 mock service 层。不过这里稍微麻烦了一点,因为我们接入层用的是 gin,所以还需要在单测的时候模拟发送请求。
其它
在大多数产品研发过程中,通常遵循一种瀑布式协作模式,在这个过程中,业务人员首先了解需求,然后由产品经理进行收集和分析,最后传达给技术人员实施。这种模式的问题在于,它使得上游角色更加面向未来,而下游的技术人员则更多地依赖历史经验,处于信息劣势的地位。这种信息的不对等很容易导致上游角色在制定方向和目标时,较少考虑实施路径的可行性。因此,当研发的产品出现问题时,人们往往倾向于归咎于架构的不灵活或缺乏前瞻性。当技术架构团队竭尽全力弥补信息劣势,提出一个相对可靠的架构方案,并能够识别出对未来需求复用有影响的改造点时,他们通常会与业务人员、产品经理一样,主动地自我合理化地认为,这样的架构优化一定会影响项目的上线时间,因此倾向于先实施临时方案,而不是进行架构优化。然而,当项目上线后出现问题,技术架构团队再次主动排查并提出清理和解决历史架构负债的方案时,业务人员和产品经理往往会指责说:这就是一个技术架构问题。
瀑布模型/大型架构像恐龙一样消失了,前期设计够用、后期进行大量重构的思想如小巧玲珑的哺乳动物一样替代了它们,软件架构迎来了响应式设计的时代/大型架构时代让位给易碎型(Fragile Architecture)架构。把架构设计工作交给程序猿的问题就是,程序猿必须学会像架构师一样思考问题。我们的每一项决策都必须为未来的变化敞开大门。就像打台球一样,我们的每一杆击球都不只是为了要把球打进洞里,它也事关下一次击球时所在的位置。让我们现在编写的代码不对未来的代码产生阻碍是一项非常重要的技能,通常需要花费多年时间才能掌握。
留下评论