go collection
前言
| go | java | |
|---|---|---|
| list | slice | ArrayList |
| map | map | HashMap |
| 线程安全map | sync.Map | ConcurrentHashMap |
| 对象池 | 对带缓冲的channel进行封装 | commons-pool中的ObjectPool |
hashmap和sync.Map都是unscalable,即参与的cpu越多,性能越差。
数组
Deep Dive into Pointers, Arrays & SliceGo’s arrays are values rather than memory address.
var myarr = [...]int{1,2,3}
fmt.Println(myarr)
fmt.Println(&myarr)
//output
[1 2 3] // 打印的时候直接把值给打印出来了
&[1 2 3]
在 Go 中,与 C 数组变量隐式作为指针使用不同,Go 数组是值类型,赋值和函数传参操作都会复制整个数组数据。值类型还体现在
- 相同维数且包含相同个数元素的数组才可以比较
- 每个元素都相同的才相等
slice
切片与数组的关系非常密切,切片引入了一个抽象层,提供了对数组中部分片段的引用,我们可以在运行区间可以修改它的长度,如果底层的数组长度不足就会触发扩容机制,切片中的数组就会发生变化,不过在上层看来切片是没有变化的,上层只需要与切片打交道不需要关心底层的数组变化。
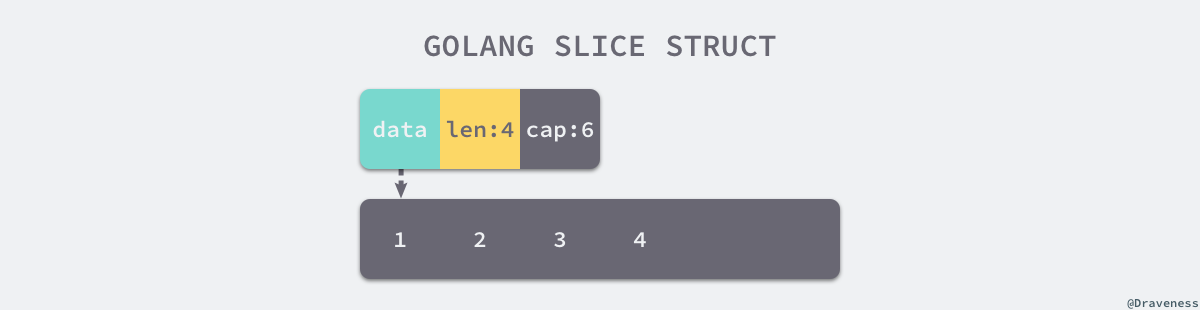
// $GOROOT/src/runtime/slice.go
type slice struct {
array unsafe.Pointer // 指向底层数组的指针
len int // 可以用下标访问的元素个数
cap int // 底层数组长度
}
func makeslice(et *_type, len, cap int) unsafe.Pointer {...}
func makeslice64(et *_type, len64, cap64 int64) unsafe.Pointer {...}
// growslice handles slice growth during append.It is passed the slice element type, the old slice, and the desired new minimum capacity,and it returns a new slice with at least that capacity, with the old data copied into it.
func growslice(et *_type, old slice, cap int) slice {...}
func slicecopy(to, fm slice, width uintptr) int {...}
func slicestringcopy(to []byte, fm string) int {...}
s2 := s1[2:4] (slice 截取) s1 和s2 共用底层数组。
与java ArrayList相比,slice 本身不提供类似 Add/Set/Remove方法。只有一个builtin 的append和切片功能,因为不提供crud方法,slice 更多作为一个“受体”,与数组更近,与“ArrayList”更远。
扩容
扩容的本质过程:扩容实际上就是重新分配一块更大的内存,将原先的Slice数据拷贝到新的Slice中,然后返回新Slice,扩容后再将数据追加进去。
// $GOROOT/src/builtin/builtin.go
// The append built-in function appends elements to the end of a slice. If it has sufficient capacity, the destination is resliced to accommodate the new elements. If it does not, a new underlying array will be allocated. Append returns the updated slice. It is therefore necessary to store the result of append, often in the variable holding the slice itself:
// slice = append(slice, elem1, elem2)
// slice = append(slice, anotherSlice...)
func append(slice []Type, elems ...Type) []Type
slice 作为函数参数
在 Go 语言中,数组更多是“退居幕后”,承担的是底层存储空间的角色。切片之于数组就像是文件描述符之于文件。也正是因为这一特性,切片才能在函数参数传递时避免较大性能开销。因为我们传递的并不是数组本身,而是数组的“描述符”,而这个描述符的大小是固定的
Go中slice作为函数参数丢失修改的问题:根据我们的直觉,向s中append了一个元素1,s应该是[1, 2, 1],实际上,我们对slice的append的操作的确发生了,这里slice的cap不够,需要进行扩容,数组会被搬迁到一个新的位置,函数中s中的array指针也被赋值了,但是main 函数的s.array 还是指向原来的位置,s.len 也不会变。
func appendToSlice(s []int) { // 传参的时候实际上传的是 struct{unsafe.Pointer}
s = append(s, 1)
s[0] = 1024
}
func main() {
s := []int{1,2}
appendToSlice(s)
fmt.Println(s)
}
对于所有的 range 循环,Go 语言都会在编译期将原切片或者数组(下例中的arr)赋值给一个新的变量 ha,在赋值的过程中就发生了拷贝,所以我们遍历的切片已经不是原始的切片变量(arr)了。
map
与常见编程语言的不同之处:
- 在访问的key不存在时,仍会返回零值,不能通过返回nil 来判断元素是否存在。
-
Map的value 可以是一个方法,与Go的Dock type 方式一起, 可以方便的实现单一方法对象的工厂模式。
m := map[int]func(op int) int{} m[1] = func(op int) int { return op } m[2] = func(op int) int { return op * op } m[3] = func(op int) int { return op * op * op } t.Log(m[1](2), m[2](2), m[3](2)) - Go的内置集合中没有Set实现, 可以
map[type]bool - map 类型对 value 的类型没有限制,但是对 key 的类型却有严格要求,因为 map 类型要保证 key 的唯一性。Go 语言中要求,key 的类型必须支持“==”和“!=”两种比较操作符。PS:类似java 的hashmap key支持equal 和 hashcode
- map 实例不是并发写安全的,也不支持并发读写。Go 1.9 版本中引入了支持并发写安全的 sync.Map 类型
- 考虑到 map 可以自动扩容,map 中数据元素的 value 位置可能在这一过程中发生变化,所以 Go 不允许获取 map 中 value 的地址,这个约束是在编译期间就生效的。
- map 存的是值,put 和 get 操作都是会发生copy的,所以不要放很大的 value。
- map delete key后不会自动缩容。
对于slice 来说, index, value 可以视为一个kv
for k,v := range map{}
for i,v := range slice{}
实现
深度解密 Go 语言之 map 未读。
map是由 Go 编译器与运行时联合实现的。Go 编译器在编译阶段会将语法层面的 map 操作,重写为运行时对应的函数调用。语法层面 map 类型变量一一对应的是 runtime.hmap 的实例。m := make(map[string]string) 中 m 是一个 *hmap 类型,所以map 不用担心像slice 一样当函数参数且扩容后有丢失修改的问题。
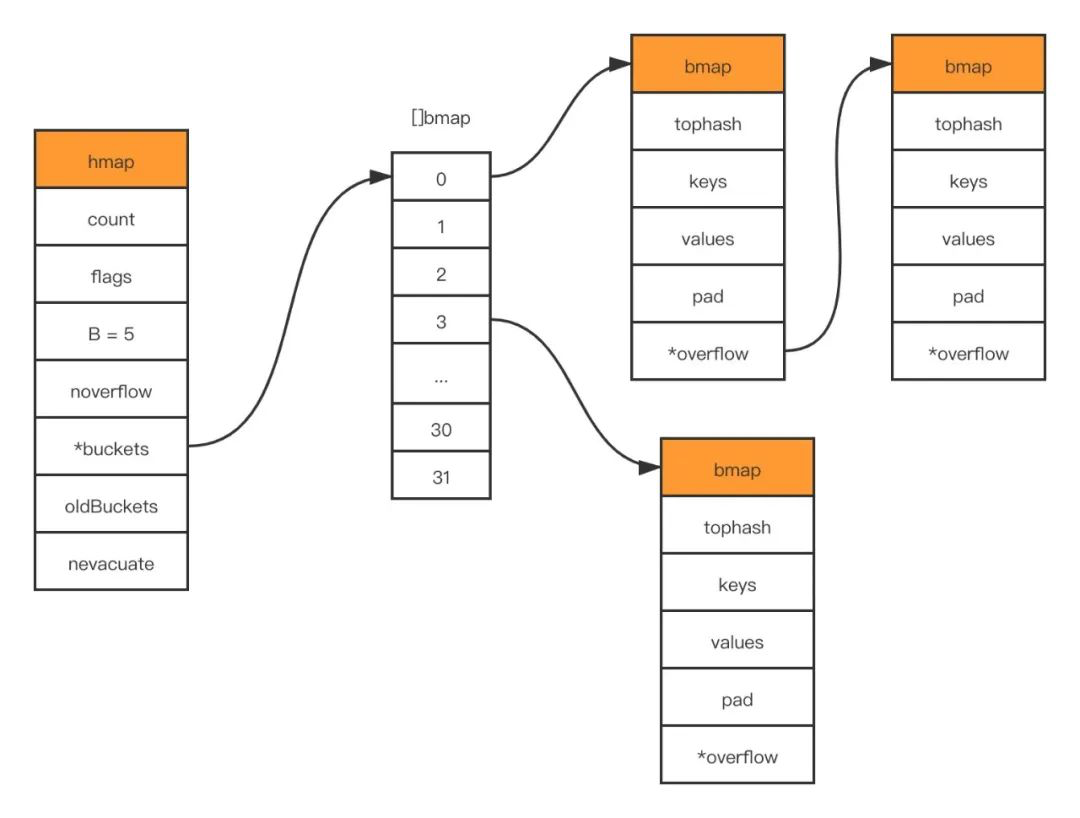
type hmap struct {
// map中存入元素的个数, golang中调用len(map)的时候直接返回该字段
count int
// 状态标记位,通过与定义的枚举值进行&操作可以判断当前是否处于这种状态
flags uint8
B uint8 // 2^B 表示bucket的数量, B 表示取hash后多少位来做bucket的分组
noverflow uint16 // overflow bucket 的数量的近似数
hash0 uint32 // hash seed (hash 种子) 一般是一个素数
buckets unsafe.Pointer // 共有2^B个 bucket ,但是如果没有元素存入,这个字段可能为nil
oldbuckets unsafe.Pointer // 在扩容期间,将旧的bucket数组放在这里, 新buckets会是这个的两倍大
nevacuate uintptr // 表示已经完成扩容迁移的bucket的指针, 地址小于当前指针的bucket已经迁移完成
extra *mapextra // optional fields
}
- 与java map 类似,基于 bucket 数组(
[]bmap),java中数组元素是链表(或指向链表),go map 的数组元素指向bmap(也算一个链表,只是链表节点可以存8个元素)// A bucket for a Go map. type bmap struct { tophash [bucketCnt]uint8 } // 编译期间会给它加料,动态地创建一个新的结构 type bmap struct { topbits [8]uint8 keys [8]keytype values [8]valuetype pad uintptr // 内存对齐使用,可能不需要 overflow uintptr // 一个 bucket 在存储满 8 个元素后,就再也放不下了,这时候会创建新的 bucket,挂在原来的 bucket 的 overflow 指针成员上 } - 定位
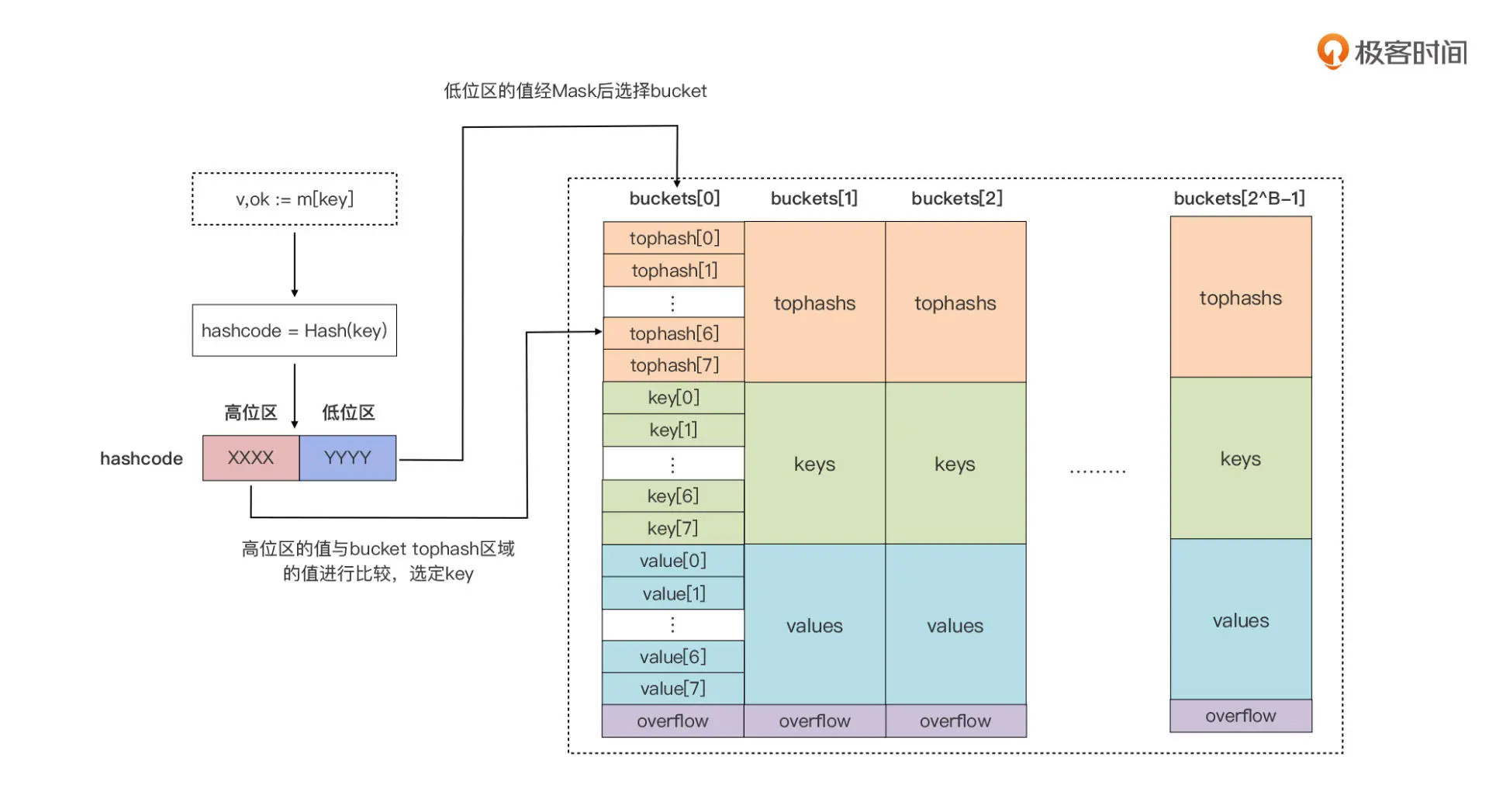
- 对key 做hashcode ,运行时会把 hashcode“一分为二”来看待,其中低位区的值用于选定 bucket,高位区的值用于在某个 bucket 中确定 key 的位置。每个 bucket 的 tophash 区域其实是用来快速定位 key 位置的,这样就避免了逐个 key 进行比较这种代价较大的操作。尤其是当 key 是 size 较大的字符串类型时,好处就更突出了。这是一种以空间换时间的思路。PS:有点两次hash的意思
- key 和 value 分开存储,而不是采用一个 kv 接着一个 kv 的 kv 紧邻方式存储,这带来的其实是算法上的复杂性,但却减少了因内存对齐带来的内存浪费。例如,有这样一个类型的 map:
map[int64]int8,如果按照key/value/key/value/...这样的模式存储,那在每一个 key/value 对之后都要额外 padding 7 个字节;而将所有的 key,value 分别绑定到一起,这种形式key/key/.../value/value/...,则只需要在最后添加 padding。 - 当我们声明一个 map 类型变量,比如
var m map[string]int时,Go 运行时就会为这个变量对应的特定 map 类型,生成一个 runtime.maptype 实例。 存储key value 类型及类型大小等信息,用以辅助 key value 的定位
- 如果 key 或 value 的数据长度大于一定数值,那么运行时不会在 bucket 中直接存储数据,而是会存储 key 或 value 数据的指针。
- 对于新老bucket,扩容时 真正的排空和迁移工作是在 assign 和 delete 时逐步进行的。在rehash的过程中,oldbuckets到newbuckets是值拷贝,这样开销会比较大。
string
Go原生支持字符串(比如底层结构有专门字段存储字符串长度),string 类型的数据是不可变的,string 是值类型, 其默认初始化值为空字符串,不是nil
// $GOROOT/src/reflect/value.go
// StringHeader是一个string的运行时表示
type StringHeader struct {
Data uintptr // 真实的字符串值数据就存储在一个被 Data 指向的底层数组中
Len int
}
了解了 string 类型的实现原理后,我们还可以得到这样一个结论:那就是我们直接将 string 类型通过函数 / 方法参数传入也不会带来太多的开销。因为传入的仅仅是一个“描述符”,而不是真正的字符串数据。其传递的开销也是恒定的,不会随着字符串大小的变化而变化。PS: go 中都是值传递,是不是可以认为,如果不想因为值传递 copy 太多数据,可以值传递的数据结构 不能直接 包含 指向的数据
与常见编程语言的不同之处:
- string 是数据类型, 不是引用或指针类型
- string 是只读的byte slice,len函数 返回的是byte 数
- string的 byte 数组可以存放任何数据
留下评论